????Android Binder通信一次拷貝你真的理解了嗎?
Android Binder框架實作目錄:
Android Binder框架實作之Binder的設計思想
Android Binder框架實作之何為匿名/實名Binder
Android Binder框架實作之Binder中的資料結構
Android Binder框架實作之Binder相關的介面和類
Android Binder框架實作之Parcel詳解之基本資料的讀寫
Android Binder框架實作之Parcel read/writeStrongBinder實作
Android Binder框架實作之servicemanager守護行程
Android Binder框架實作之defaultServiceManager()的實作
Android Binder框架實作之Native層addService詳解之請求的發送
Android Binder框架實作之Native層addService詳解之請求的處理
Android Binder框架實作之Native層addService詳解之請求的反饋
Android Binder框架實作之Binder服務的訊息回圈
Android Binder框架實作之Native層getService詳解之請求的發送
Android Binder框架實作之Native層getService詳解之請求的處理
Android Binder框架實作之Native層getService詳解之請求的反饋
Android Binder框架實作之Binder Native Service的Java呼叫流程
Android Binder框架實作之Java層Binder整體框架設計
Android Binder框架實作之Framework層Binder服務注冊程序原始碼分析
Android Binder框架實作之Java層Binder服務跨行程呼叫原始碼分析
Android Binder框架實作之Java層獲取Binder服務原始碼分析
引言
最近有讀者在詢問一個關于Binder通信"一次拷貝"的問題,說在學習Binder驅動的實作中看到有多次呼叫了copy_from_user和copy_to_user來進行資料的跨用戶空間和內核空間的拷貝,但是為啥Android官方和絕大部分的博客還是說只進行了一次拷貝呢!這就是本篇博客的由來!
??對于從事Android開發的coder來說Binder應該不會陌生了(如果對它概念都沒有的話,那估計大概率是個假的開發者了)!按照現在比較流行的段位排序來說,青銅選手(初級開發者)肯定知道Binder是Android提供的可以進行跨行程的IPC通信機制,而白銀選手(中級開發者)肯定應該知道Binder跨行程IPC通信原理是通過記憶體映射實作的,而這也是Binder相對于其他傳統行程間通信方式的優點之一(即我們總說的Binder只需要做“一次拷貝”,而其他傳統方式需要“兩次拷貝”的核心了)!
對于這里的排位沒有歧視或者任何其它的意思啊(僅僅是為了文字的描述),聞道有先后術有專攻而已,而已啊!
不對啊,王者排序還沒有結束啊!是的,這不我們的Binder的進階打怪不是也沒有結束嗎,所以不要著急!,對于想繼續進階的王者段位(高階開發者來說)肯定會再進一步思考深入,一定會遇到兩個繞不開的的關于Binder的問題:
- 這所謂的“一次拷貝”到底是發生在什么地方?
這個問題,對于有研究過Binder驅動原始碼的讀者來說一定會有體會,因為在Binder驅動的原始碼中有多次copy_from_user和copy_to_user的呼叫,根本不止"一次拷貝",但是很多的書籍包括Android官方都多宣稱只有一次拷貝,這是為什么呢,是它們錯了,還是我們理解不到位呢!
- 這"一次拷貝“的到底是什么東西?
而很不幸的是絕大部分介紹Android的Binder的文章會重點強調“一次拷貝”是其優點之一,但對上面的兩個問題要么一筆帶過,要么就是回答的并不完全正確,從而給讀者造成一些理解上的混亂(感覺被欺騙了的感覺),所以本篇文章會從兩個維度來闡述這個問題:
- 第一個維度:對于青銅開發者,將帶領讀者了解為啥Binder跨行程IPC通信只需要"一次拷貝",而傳統的IPC通信為啥需要兩次拷貝(當然想深入嗎,可以先從我上面的Android Binder框架實作目錄開啟,不是打廣告!)
- 第二個維度:對于想繼續進階的開發者,我將帶領大伙解決上面列舉的兩個疑問點(這個階段就需要讀者對Binder驅動的作業程序和Binder驅動原始碼有一個大致的了解,如果沒有那就只能是解決第一階段目標了)
注意,本篇博客的原始碼是基于Android 7來進行的,其中后續分析涉及的原始碼路徑如下:
--- kernel/drivers/staging/android/binder.c
--- kernel/include/linux/list.h
--- kernel/drivers/staging/android/uapi/binder.h
--- external/kernel-headers/original/uapi/linux/android/binder.h
--- framework/native/cmds/servicemanager/binder.c
--- frameworks/native/cmds/servicemanager/service_manager.c
--- frameworks/native/include/binder/Parcel.h
--- frameworks/native/include/binder/IPCThreadState.h
--- frameworks/native/libs/binder/IPCThreadState.cpp
--- frameworks/native/include/binder/ProcessState.h
--- frameworks/native/libs/binder/ProcessState.cpp
一.前期知識準備
注意,注意,注意重要的事情說三篇!
這一大章節主要是針對青銅讀者進行入門使用的,如果你已經是白銀段位或者王者段位的,這個章節可以跳過,直接進入下一環節!
??Android的Binder是一個跨多種技術的集大成者(特別是Linux相關的技術),所以在回答分析今天的博客標題所提出來的問題之前,我們非常有必要了解科普一些相關的知識,特別是Linux中傳統的跨行程IPC通信的(注意這里的措辭是科普和了解,因為想要深入這塊的知識,不是本篇博客也不是一兩篇博客能做到的,而且說實話讀者本人也就了解個大概,了解)!
1.1 Linux系統中行程模型
??我們知道Linux中的行程是被隔離不能直接進行通信的,而Android的應用程式作為特殊的Linxu行程也遵循了這一原則,所以這里我們要必要先了解一下Linux中的行程模型,然后擴散到涉及的一些基本概念,再然后逐步展開,讓大家先行掌握傳統LInux行程通信,然后發散到Android的Binder IPC行程通信!
啥也不說了,翠花上酸菜!我們先看下Linux中行程模型圖,如下:
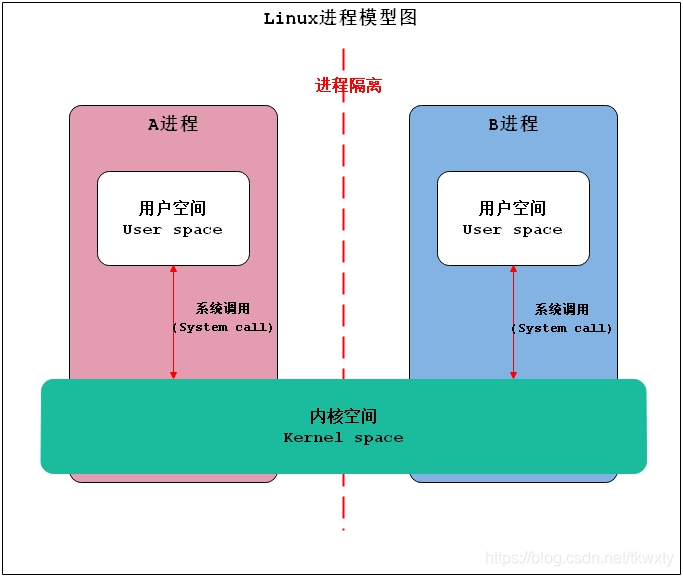
上面的圖示向我們傳遞了Linux行程模型中幾個非常重要的概念(這個幾個概念和后續的Linux跨行程通資訊息相關):
- 行程隔離
- 用戶空間(User space)
- 內核空間(Kernel space)
- 系統呼叫(System call)
下面讓我們對上述幾個概念一一介紹,各個了解,走起約起!
1.2 Linux行程隔離
提到行程隔離讓我莫名的想到了種群隔離,扯多了言歸正傳!我們從如下幾個維度來簡單說說行程隔離:
- 行程隔離的概念:行程隔離簡單的說就是Linux作業系統設計的一種機制使行程之間不能共享資料,保持各自資料的獨立性即A行程不能訪問B行程資料,同理B行程也不能訪問A行程資料
- 行程隔離的實作原理:行程隔離的實作使用到了虛擬記憶體技術(這個后面簡單說下)
- 行程隔離的目的:當然是通過虛擬記憶體技術,達到Linux行程中資料不能共享,從而保持獨立的功能
正是由于上述提到的行程隔離,從而導致Linux行程之間要進行資料互動就得采用特殊的通信機制行程間IPC通信!
1.3 Linux虛擬記憶體
虛擬記憶體顧名思義就是一種實際上并不存在的記憶體,是虛擬出來的,它是Linux作業系統為了進行記憶體管理而設計的一種記憶體管理機制,總之就是虛擬記憶體是被虛擬出來的,是為了實作更好的記憶體管理而創建出來的最后它會通過一定的機制和物理記憶體映射起來的,并且這個映射的程序對應用程式來說是透明的!
感覺有點整不下去了,因為這個涉及到作業系統的相關原理了,!讀者如果有興趣的請參閱博客Linux虛擬記憶體和物理記憶體的理解和Linux虛擬記憶體,網上有很多關于這方面的知識,這里我就先撤了,
1.4 Linux行程空間(內核空間和用戶空間)
??我們前面提到了虛擬記憶體的概念,而Linux行程空間就是通過虛擬記憶體來實作的,我們知道現在作業系統都是采用虛擬存盤器,那么對32位作業系統而言,它的尋址空間(虛擬存盤空間)為4G(2的32次方),操心系統的核心是內核,獨立于普通的應用程式,可以訪問受保護的記憶體空間,也有訪問底層硬體設備的所有權限,為了保證用戶行程不能直接操作內核,保證內核的安全,操心系統將虛擬空間劃分為兩部分,一部分為內核空間,一部分為用戶空間,
針對linux作業系統而言,將最高的1G位元組(從虛擬地址0xC0000000到0xFFFFFFFF),供內核使用,稱為內核空間,而將較低的3G位元組(從虛擬地址0x00000000到0xBFFFFFFF),供各個行程使用,稱為用戶空間,每個行程可以通過系統呼叫進入內核,因此,Linux內核由系統內的所有行程共享,于是,從具體行程的角度來看,每個行程可以擁有4G位元組的虛擬空間,
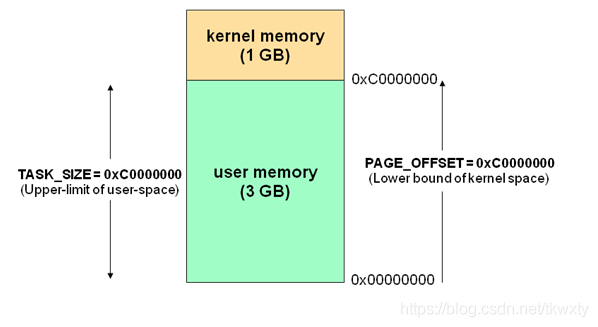
關于行程空間有如下幾個點需要注意:
1.內核空間中存放的是內核代碼和資料,而行程的用戶空間中存放的是用戶程式的代碼和資料,不管是內核空間還是用戶空間,它們都處于虛擬記憶體中的(當然肯定會在實際使用中映射到實際的物理記憶體上面去的),
2.為了保證系統的安全,用戶空間和內核空間是天然隔離的
3.內核空間是被所有的行程所共享的,這個從最上面的行程模型也可以看出來
4.為啥要將行程空間劃分為用戶空間和內核空間呢,且之間有隔離,用戶空間不能隨意操作內核空間呢,這個最最主要的原因是為了安全方面考慮的,因為內核擁有對底層設備的所有訪問權限,為了安全用戶行程是不能直接訪問內核行程的
1.5 Linux行程空間系統呼叫
??雖然作業系統從邏輯上進行了用戶空間和內核空間的劃分,但不可避免的用戶空間需要訪問內核資源,比如檔案操作、訪問網路等等,為了突破隔離限制,就需要借助系統呼叫來實作,系統呼叫是用戶空間訪問內核空間的唯一方式,保證了所有的資源訪問都是在內核的控制下進行的,避免了用戶程式對系統資源的越權訪問,提升了系統安全性和穩定性,
而在實際的操作中所有的系統資源管理都是在內核空間中完成的,比如讀寫磁盤檔案,分配回收記憶體,從網路介面讀寫資料等等,我們的應用程式是無法直接進行這樣的操作的,但是我們可以通過內核提供的介面來完成這樣的任務這就是所謂的系統呼叫了,比如應用程式要讀取磁盤上的一個檔案,它可以向內核發起一個 “系統呼叫” 告訴內核:“我要讀取磁盤上的某某檔案”,其實就是通過一個特殊的指令讓行程從用戶態進入到內核態(到了內核空間),在內核空間中,CPU 可以執行任何的指令,當然也包括從磁盤上讀取資料,具體程序是先把資料讀取到內核空間中,然后再把資料拷貝到用戶空間并從內核態切換到用戶態,此時應用程式已經從系統呼叫中回傳并且拿到了想要的資料,可以開開心心的往下執行了,其切換的示意圖如下:
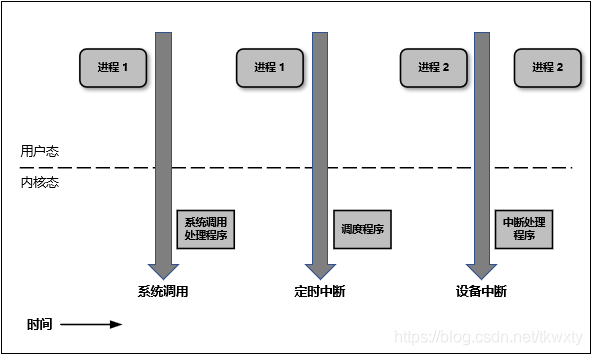
這里簡單說下什么是內核態與用戶態:
(1)當一個任務(行程)執行系統呼叫而陷入內核代碼中執行時,稱行程處于內核運行態(內核態),此時處理器處于特權級最高的(0級)內核代碼中執行,當行程處于內核態時,執行的內核代碼會使用當前行程的內核堆疊,每個行程都有自己的內核堆疊,
(2)當行程在執行用戶自己的代碼時,則稱其處于用戶運行態(用戶態),此時處理器在特權級最低的(3級)用戶代碼中運行,當正在執行用戶程式而突然被中斷程式中斷時,此時用戶程式也可以象征性地稱為處于行程的內核態,因為中斷處理程式將使用當前行程的內核堆疊,
并且Linux使用兩級保護機制:0級供系統內核使用,3級供用戶程式使用
1.6 Linux行程空間跨行程通信常用的系統呼叫函式
??到這里不容易啊,概念性的東西就是這么枯燥且乏味(當然深入了,那就是另外一說了啊)!而我們今天的博客重點兩字就是"通信",這里我們先重點看下Linux行程空間是重點通過那幾個函式實作用戶空間和內核空間的資料互動的,
1.6.1 用戶空間向內核空間傳遞資料常用函式
這里主要用到了兩個函式,分別是copy_from_user()和get_user(),它們拷貝的資料流向如下:
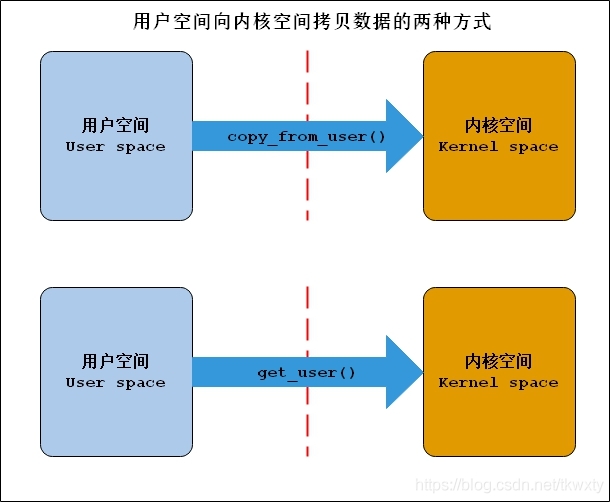
1.6.2 用戶空間向內核空間傳遞資料常用函式
這里主要用到了兩個函式,分別是copy_to_user()和put_user(),它們拷貝的資料流向如下:
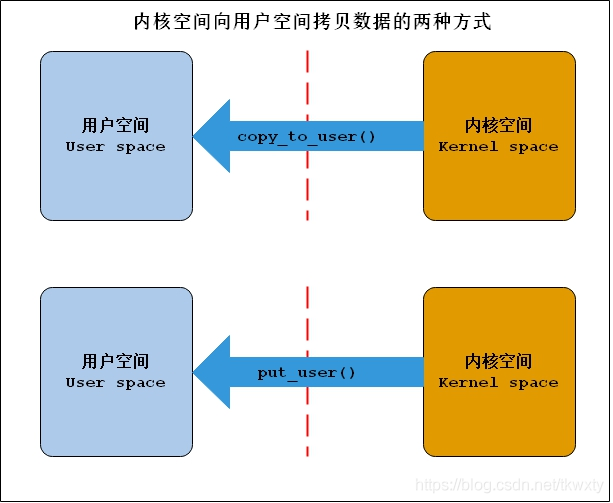
這里關于上述四個函式(宏)就不一一列舉出來了啊,可以詳見博客copy_to_user 、copy_from_user函式實作內核空間資料與用戶空間資料的相互訪問,
1.7 Linux記憶體映射概念
前面一口氣介紹了這么多的Linux相關概念,這還沒有完,還有一個非常重要重要的知識點沒有介紹完畢,那就是Linux的記憶體映射概念,這里讀者可以先緩緩,先理解理解前面的概念,心里有個譜,然后繼續征戰!
記憶體映射是系統呼叫函式mmap()的中文翻譯,其本質是一種行程虛擬記憶體的映射方法,它可以將一個檔案、一段物理記憶體或者其它物件(也包括內核空間)映射到行程的虛擬記憶體地址空間,實作這樣的映射關系后,行程就可以采用指標的方式來讀寫操作這一段記憶體,進而完成對檔案(或者其它被映射的物件)的操作,而不必再呼叫 read/write 等系統呼叫函式了,所以正是因為有如上的特點記憶體映射能減少資料拷貝次數,實作用戶空間和內核空間的高效互動,當映射成功以后,兩個空間各自的修改能直接反映在映射的記憶體區域,從而被對方空間及時感知,也正因為如此,記憶體映射能夠提供對行程間通信的支持,其模型如下所示:
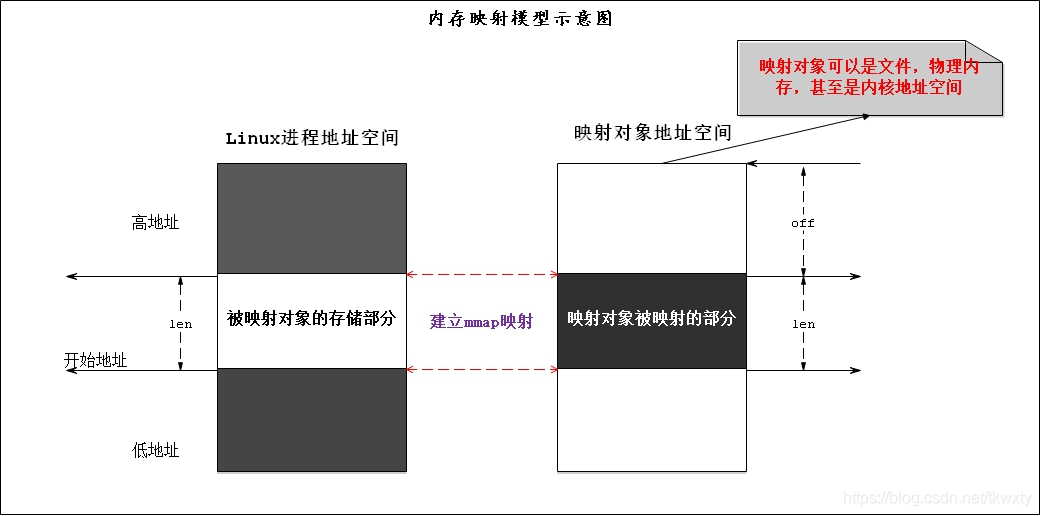
看到上述的描述可以減少拷貝次數,估計讀者眼前一亮了!難不成Binder通信只拷貝依次的秘密武器就是它,是的Binder通信少拷貝一次的秘密武器就是它,這里我們先不帶入Binder通信的概念,只重點了解一下記憶體映射的原理!
關于這一塊的具體底層原理讀者可以想見博客Android-記憶體映射mmap和Linux作業系統原理—記憶體—mmap行程虛擬記憶體映射這兩篇博客,
1.8 Linux動態內核加載模塊技術與Binder驅動簡介
1.8.1 Linux動態內核加載模塊技術
??通過前面的理論知識的補充,我們知道了Linux行程空間中的用戶空間和內核空間在絕大部分情況下是隔離的,它們之間的通信是可以通過系統呼叫來實作的,而傳統的行程IPC通信模式都是如下接著內核來實作的譬如如管道,socket,訊息佇列等,而它們都已經作為Linux的內核一部分了,所以Linux是天然支持如上幾種IPC通信模式的,
但是我們的Android中引入的Binder通信概念中的Binder驅動并不是Linux系統標準內核的一部分,那怎么實作加載和使用呢?這就得益于Linux的動態內核可加載模塊(Loadable Kernel Module,LKM)的機制;模塊是具有獨立功能的程式,它可以被單獨編譯,但是不能獨立運行,它在運行時被鏈接到內核作為內核的一部分運行,這樣,Android系統就可以通過動態添加一個內核模塊運行在內核空間,用戶行程之間通過這個內核模塊作為橋梁來實作通信,
1.8.2 Binder驅動簡介
在介紹Binder驅動之前我們先了解一下驅動的基本概念,驅動是一種使用實作對硬體進行相關操作,并屏蔽硬體特性的一種軟體技術!并且Linux將驅動分為三大類:字符設備驅動,塊設備驅動以及網路設備驅動,
這里對于驅動的概念就不做過多的介紹了,關于驅動的詳細介紹可以參見博客Linux驅動簡介及分類,
好了上面我們對驅動有了一定的了解了,這里我們簡單介紹一下Binder驅動,Binder驅動是一種虛擬的字符設備(重點它是虛擬出來的,實際上Binder驅動并沒有操作相關的硬體),注冊在/dev/binder中,如下所示:
其定義了一套Binder通信協議,負責建立行程間的Binder通信,提供了資料包在行程之間傳遞的一系列底層支持,當然Binder驅動是Android特有的,所以它不是Linux標準內核攜帶的必須通過動態內核加載進行加載的,既然Binder驅動屬于內核層所以應用層對于它訪問也是通過系統呼叫實作的,
二.Linux傳統IPC通信原理和Binder通信原理
這個章節主要是從理論層面解釋Linux傳統IPC通信原理和Binder通信原理關于拷貝次數差異的原因所在,讓讀者從可以瞬間從青銅進階成白銀(如果這關讀者已經打通,可以直接跳過進入下一章節了),至于想變成最后的王者唄,那必須是待最后的分析了!
有了前面知識的鋪墊,是時候來點真家伙了!讓我們一起來揭開Binder IPC通信所謂"一次拷貝"和其它IPC通信“兩次拷貝“的真實面紗!
2.1 Linux傳統跨行程IPC通信原理
Linux傳統行程IPC通信由于Linux行程設計的原因,通常需要如下的步驟進行跨行程IPC通信(共享記憶體除外):
-
對于訊息的發送端行程:
- 通常傳統的IPC通信(Socket,管道,訊息佇列)首先將訊息發送方將要發送的資料存放在記憶體快取區中
- 然后通過前面所說系統呼叫進入內核態,然后作業系統為Linux發送方行程在內核空間分配記憶體,開辟一塊內核快取區,呼叫 copy_from_user()函式將資料從用戶空間的記憶體快取區拷貝到內核空間的內核快取區中
-
對于訊息的接收端行程:
- 首先在進行接收資料時在自己的用戶空間開辟一塊記憶體快取區
- 然后作業系統為Linux接收方行程在內核空間中呼叫 copy_to_user() 函式將資料從內核快取區拷貝到接收行程的記憶體快取區,這樣資料發送方行程和資料接收方行程就完成了一次資料傳輸,我們稱完成了一次行程間通信
Linux傳統跨行程IPC通信的模型可以使用如下的示意圖來完整表示,如下:
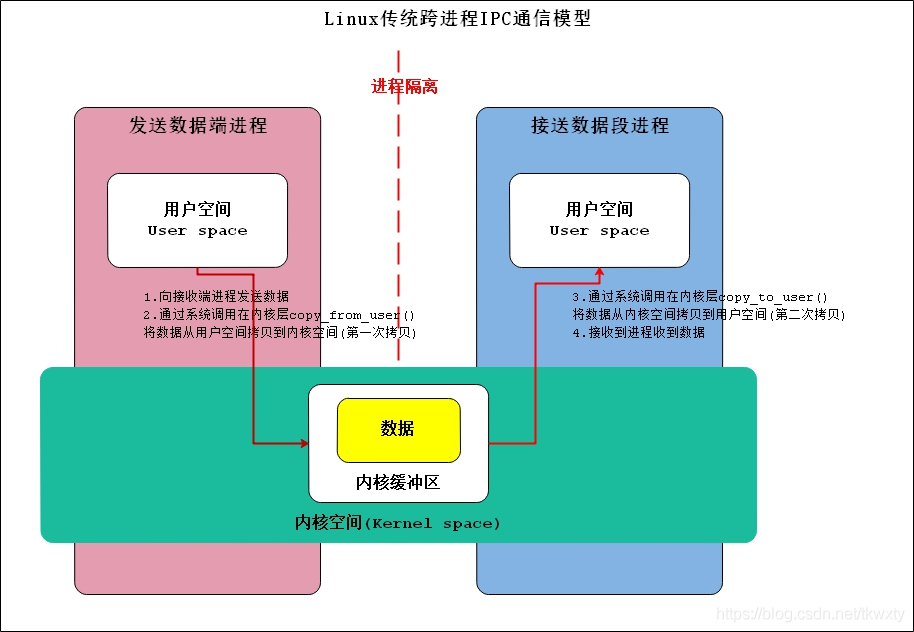
好嗎,說到這里不說下Linux傳統跨行程IPC通信模型的缺點好像過意不去,必須吐槽一下(注意,此處僅僅就IPC通信資料傳輸效率,以及資源占用角度出發):
1.傳統IPC通信模型傳輸效率比較低,拷貝次數過多需要兩次(這個僅是對于Binder和匿名共享記憶體而言),第一次是從發送方用戶空間拷貝到內核快取區,第二次是從內核快取區拷貝到接收方用戶空間,
2.接收資料的快取區由資料接收行程提供,但是接收行程并不知道需要多大的空間來存放將要傳遞過來的資料,因此只能開辟盡可能大的記憶體空間或者先呼叫API接收訊息頭來獲取訊息體的大小,這兩種做法不是浪費空間就是浪費時間,
2.2 Binder跨行程IPC通信原理
??傳統Linux行程的跨行程IPC通信原理介紹完畢,是時候來介紹Binder跨行程IPC通信原理了!前面我們知道了傳統的IPC通信采用的是發送端Linux行程用戶空間記憶體-區–>內核空間—>接收端Linux行程用戶空間記憶體區的"兩次拷貝"方式,那么Binder跨行程IPC通信是怎么做到了節約一次記憶體拷貝只需要一次的呢?
細心的的讀者肯定想到了博主在前面知識儲備章節說到的記憶體映射mmap方式了,并且博主在介紹mmap的時候有強調了一個關鍵點就是記憶體映射不僅可以將檔案映射到行程的用戶空間(從而減少資料的拷貝次數,用記憶體讀寫取代I/O讀寫,提高檔案讀取效率),而且也可以將內核空間的一塊區域映射到行程的用戶空間,而我們這里的Binder跨行程IPC通信正是借助了記憶體映射的方法,在內核空間和接收方用戶空間的資料快取區之間做了一層記憶體映射,這樣一來,從發送方用戶空間拷貝到內核空間快取區的資料,就相當于直接拷貝到了接收方用戶空間的資料快取區,從而減少了一次資料拷貝(在這里不得不說聲設計的真的巧妙啊),
一次完整的 Binder IPC 通信程序通常如下所示:
- 對于Binder服務端行程而言:
- Binder服務端(Service)在啟動之后,通過系統呼叫Binde驅動在內核空間創建一個資料接收快取區(呼叫binder_oepn方法執行相關的操作)
- 接著Binder服務端行程空間的內核接收到系統呼叫的指令,進而呼叫binder_mmap函式進行對應的處理,首先申請一塊物理記憶體,然后建立Binder服務端(Service端)的用戶空間和內核空間一塊區域的映射關系(這樣上述兩塊區域就映射在一起了)
- 對于請求端(Client)行程而言:
- Client向服務端發送通信發送請求,這個請求資料打包完畢之后通過系統呼叫先到驅動中,然后在驅動中通過copy_from_user()將資料從用戶空間拷貝到內核空間的快取區中(注意這塊內核空間和Binder服務端的用戶空間存在映射關系)
- 由于內核快取區和接收行程的用戶空間存在記憶體映射,因此也就相當于把資料發送到了接收行程的用戶空間(只需要進行一定的偏移操作即可),這樣便完成了一次行程間的通信,從而達到了省去一次拷貝的操作
Binder跨行程IPC通信(資料傳輸)的模型可以使用如下的示意圖來完整表示,如下:
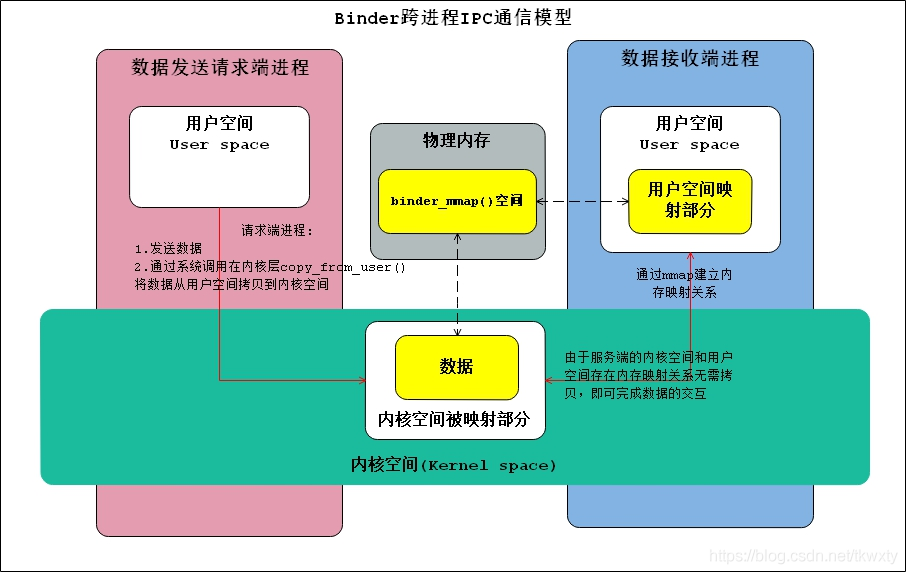
這里Binder就資料傳入效率和資源包占用角度來說,相關傳統的IPC通信有如下的優點:
1.減少了資料的拷貝次數,用記憶體讀寫取代 I/O 讀寫,提高了檔案讀取效率
2.作為Binder服務端開辟的資料接收區大小是固定的(對于普通的BInder服務端和servicemanager端有一定的區別,都是都沒有大于1M的空間)
三.Binder通信"一次拷貝"原始碼大揭秘
??通過前面的不懈努力,為我們的原始碼事業貢獻無數青春和汗水的情況下(有點夸張啊)終于我們將Linux傳統跨行程IPC通信原理和Binder跨行程IPC通信原理給弄清楚了,可喜可賀啊!但是如果想要真的掌握好了Binder通信"一次拷貝"的真正精髓,那還得深入研究一番,而這個章節的博客的目的正是如此帶領讀者從白銀選手走向終極王者巔峰!在這大章節中我們將要重點掌握的是如下兩個的關鍵知識點:
- 內核中服務端記憶體映射的建立
- 在Binder驅動原始碼中有多次呼叫了copy_from_user()和copy_to_user()這兩個函式(注意這里強調的是多次呼叫),這里我們將要帶領讀者搞清楚每次呼叫都是在拷貝些什么東西,拷貝到哪里去了
- 既然上面存在了多次拷貝,那為啥Binder通信又鋪天蓋地的說只進行了“一次拷貝”呢,這個是不是有問題呢,或者是我們的理解有問題呢?
- 發送端資料通過一次拷貝到內核,怎么和接收服務端的映射空間建立連接
在后續原始碼的分析中,我們會主要集中火力在和Binder實作的記憶體操作相關的原始碼分析中,Binder其它的相關邏輯就忽略帶過了,并且這一章節對讀者的Binder知識有一定高度的要求,如果讀者沒有相關方面的知識儲備可以從本篇博客最開始的Binder框架目錄中的文章開始!
3.1 Binder預備知識準備
前途是光明的,道路是曲折的!所以如果想要深入探究Binder通信"一次拷貝"的真正原理,在開始相關的原始碼分析前還是有必要梳理梳理一下將要涉及的相關Binder知識,來點儲備,走起,梳理起:
- 由于在后續的博客分析中會牽涉到Binder通信中資料的封裝和打包,這里我們有必要了解一下Binder傳入資料協議的的封裝邏輯,具體的可以參見博客Android Binder框架實作之Binder中的資料結構和Android Binder框架實作之Native層addService詳解之請求的發送這兩篇博客,其Binder傳入資料的打包封裝基本模型如下所示:
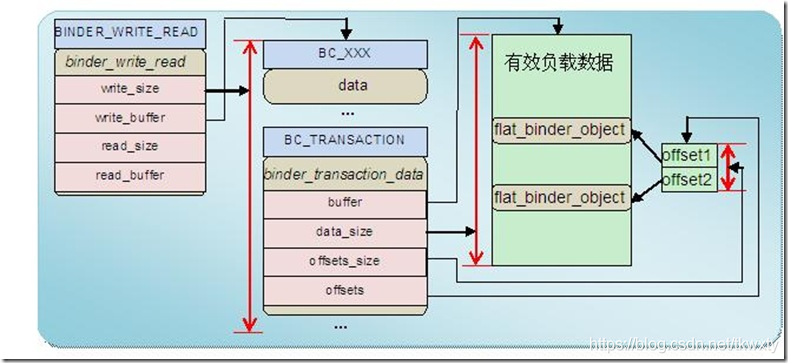
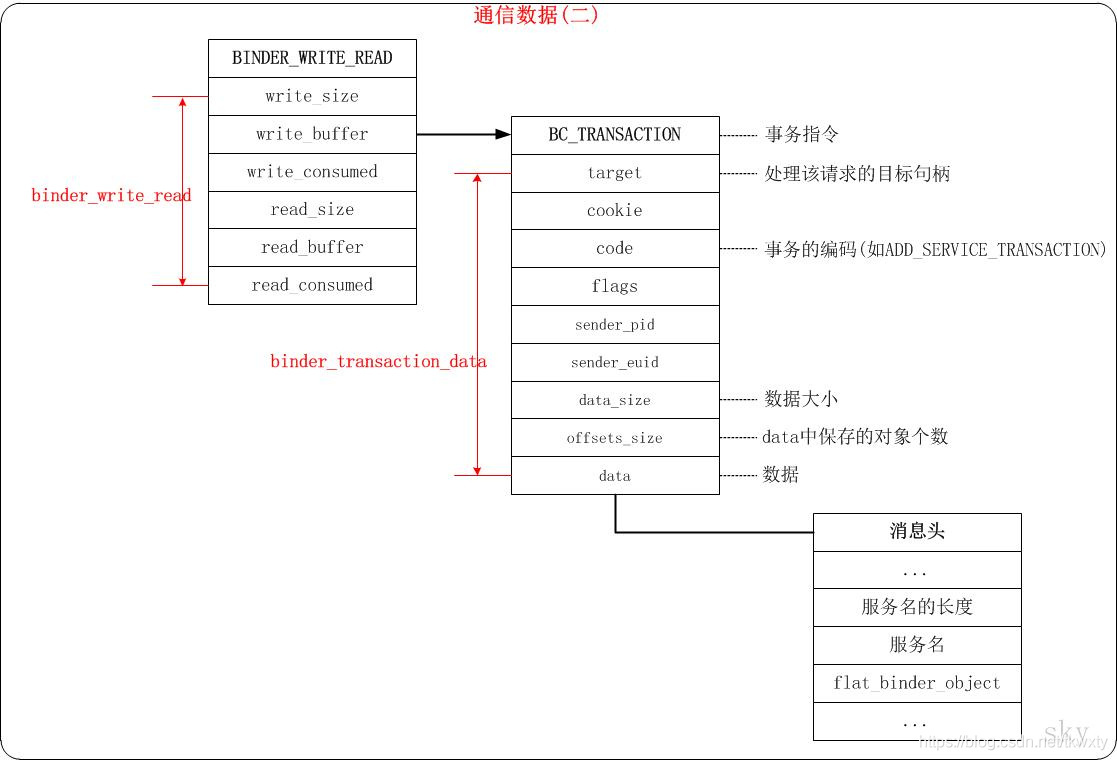
- 參與Binder通訊的行程,無論是請求端還是服務器端,他們都會通過呼叫ProcessState::self()函式來建立自己的初步映射(這也是為什么說Android行程是天生就支持Binder通信的所在),而我們本章節博客重點也是從此處開始
對于上述流程還有不是很清楚的讀者請參見如下博客:
Android Binder框架實作之servicemanager守護行程
Android Binder框架實作之defaultServiceManager()的實作
Android Binder框架實作之Native層addService詳解之請求的發送
3.2 服務端(接收)行程Binder建立記憶體映射
其實這個標題,應該是Binder行程建立記憶體映射,但是這里為了形成一個整體的鏈路所以特意寫的是服務端(接收)行程,
??前面我們知道了Binder記憶體映射建立是從ProcessState::self()函式開始,該函式使用典型的單列模式:如已創建該實體則直接回傳,如果沒有創建,則創建回傳這個實體,這里需要鎖來防止創建兩個同型別的實體,該函式還是static型別的,所以可以在系統的任何地方呼叫,先上原始碼,一起燥起來!
//[ProcessState.cpp]
sp<ProcessState> ProcessState::self()
{
Mutex::Autolock _l(gProcessMutex);
if (gProcess != NULL) {
return gProcess;
}
gProcess = new ProcessState;
return gProcess;
}
上述原始碼邏輯沒有啥好說的(主要就是判斷是否已經初始化過了gProcess而已),我們接著看ProcessState的構造方法,如下:
//[ProcessState.cpp]
#define BINDER_VM_SIZE ((1*1024*1024) - (4096 *2))
ProcessState::ProcessState()
: mDriverFD(open_driver())
, mVMStart(MAP_FAILED)
, mThreadCountLock(PTHREAD_MUTEX_INITIALIZER)
, mThreadCountDecrement(PTHREAD_COND_INITIALIZER)
, mExecutingThreadsCount(0)
, mMaxThreads(DEFAULT_MAX_BINDER_THREADS)
, mStarvationStartTimeMs(0)
, mManagesContexts(false)
, mBinderContextCheckFunc(NULL)
, mBinderContextUserData(NULL)
, mThreadPoolStarted(false)
, mThreadPoolSeq(1)
{
if (mDriverFD >= 0) {
//mmap()函式原型
//void *mmap(void *addr, size_t length int " prot ", int " flags , int fd, off_t offset);
// mmap the binder, providing a chunk of virtual address space to receive transactions.
mVMStart = mmap(0, BINDER_VM_SIZE, PROT_READ, MAP_PRIVATE | MAP_NORESERVE, mDriverFD, 0);
if (mVMStart == MAP_FAILED) {
// *sigh*
ALOGE("Using /dev/binder failed: unable to mmap transaction memory.\n");
close(mDriverFD);
mDriverFD = -1;
}
}
LOG_ALWAYS_FATAL_IF(mDriverFD < 0, "Binder driver could not be opened. Terminating.");
}
可以看到在ProcessState的建構式中,它有進行一系列的初始化(這種初始化的方式在C++中運用的比較普遍),其中比較重要的有如下兩步:
-
通過open_driver()打開"/open/binder",并將檔案句柄賦值給mDriverFD(關于這部分不是本篇博客的重點,就不花費過多的時間分析了,如果還有不清楚的可以詳見博客Android Binder框架實作之defaultServiceManager()的實作的2.2.2 open_driver()章節)
-
通過呼叫mmap()映射記憶體,最后會通過系統呼叫呼叫內核空間驅動的binder_mmap()函式,這里我們先mmap()的入參分析一下(如果對于mmap()有不清楚的,請參見章節1.7 Linux記憶體映射概念中關于mmap()函式的說明):
- 第一個引數是映射記憶體的起始地址,0代表讓系統自動選定地址
- mapsize表示映射空間的大小,這里的取值1M-8K的
- PROT_READ表示映射區域是可讀的
- MAP_PRIVATE表示建立一個寫入時拷貝的私有映射(即,當行程中對該記憶體區域進行寫入時,是寫入到映射的拷貝中)
- mDriverFD是"/dev/binder"句柄
- 而0表示偏移
這里有幾點我要重點強調說明一下:
1.重點注意mmap上方的注釋,已經說的很清楚了,這塊記憶體映射只是作為接收transactions來使用的,也就是說往驅動寫資料的時候是與記憶體映射無關的,記住這一點
2.mmap()函式是怎么通過系統呼叫到binder_mmap()來的,這個說來話長了(如果讀者是從事驅動開發的應該就很容易理解了),可以詳見博客Android binder中的mmap到binder_mmap呼叫流程和博客Android Binder框架實作之servicemanager守護行程的章節3.3以及mmap系統呼叫(內核空間到用戶空間的映射就OK了,
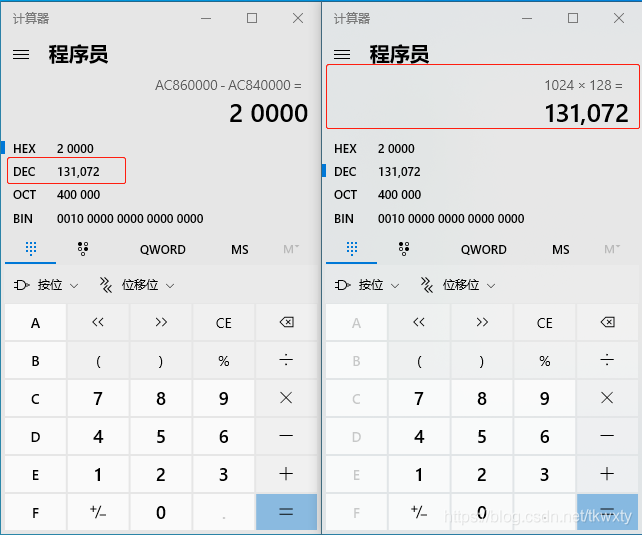
分析到這里,我來給讀者提一個問題是不是所有的Binder行程映射的記憶體空間大小都是固定的呢?譬如這里的1M-8K大小!我想對于Binder框架熟悉的讀者肯定能很快的回答出來,不是的!因為有一個特例就是 servicemanager行程,它的Binder映射空間大小只有128K,這個要怎么來確定呢,我們可以通過如下的簡單命令來驗證一下:

xxx:/ # ps | grep servicemanager
system 419 1 4912 1400 binder_thr ac9d562c S /system/bin/servicemanager
xxx:/ # cat /proc/419/maps | grep binder
ac840000-ac860000 r--p 00000000 00:0b 8600 /dev/binder
xxx:/ #
可以看到很明顯,這里的計算結果表明servicemanager行程的Binder映射空間大小只有128K(計算方法這里就不需要強調了嗎,0xac840000-0xac860000虛擬地址長度),
我們接下來看下普通行程的Binder地址長度,這里我們以mediaserver為例說明,如下:

xxx:/ # ps | grep mediaserver
media 571 1 43028 6964 binder_thr aa45362c S /system/bin/mediaserver
xxx:/ # cat /proc/571/maps | grep binder
aa202000-aa300000 r--p 00000000 00:0b 9864 /dev/binder
aabb7000-aac07000 r-xp 00000000 b3:15 1485 /system/lib/libbinder.so
aac08000-aac11000 r--p 00050000 b3:15 1485 /system/lib/libbinder.so
aac11000-aac12000 rw-p 00059000 b3:15 1485 /system/lib/libbinder.so
xxx:/ #
老規矩,我們來計算一下被映射的Binder地址空間大小是不是1M-8K,見證奇跡的時候到了,如下:
3.2.1 內核空間對Binder映射的處理
??通過前面我們知道行程空間的用戶空間mmap操作最后會通過系統呼叫到內核空間的binder_mmap()中去,所以讓我們深入內核層看看binder_mmap()的處理邏輯是什么,我們先看下binder_mmap()函式的定義,如下:
static int binder_mmap(struct file *filp, struct vm_area_struct *vma);
我們先看下該函式的引數的定義,其中struct vm_area_struct *vma就是內核為我們找到的用戶空間的行程虛擬記憶體區域,這就是我驅動程式需要映射到設備記憶體的地址,而該引數的vma->vm_start和vma->vm_end即為此次映射內核為我們分配的開始地址和結束地址,他們差值就是系統呼叫mmap中的length的值,而vma->vm_start的則是系統呼叫mmap呼叫的回傳值,需要注意的是vma->vm_start和vma->vm_end都是呼叫行程的用戶空間的虛擬地址,他們地址范圍可以通過如下命令:cat /proc/pid/maps | grep "/dev/binder"看到,如上圖所示mediaserver行程對應的vma->vm_start和vma->vm_end的值分別為:aa202000和aa300000,
該了解的不該了解的都已經了解了,我們直接來看binder_mmap()的原始碼實作,
//[kernel/drivers/staging/android/binder.c]
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
//內核進入這個函式時,就已經預先為此次映射分配好了呼叫行程在用戶空間的虛擬地址范圍
//(vma->vm_start,vma->vm_end)
struct binder_buffer *buffer;
// 有效性檢查:映射的記憶體不能大于4M
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
...
vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE;
mutex_lock(&binder_mmap_lock);
//為行程所在的內核空間申請與用戶空間同樣長度的虛擬地址空間,這段空間用于內核來訪問和管理binder記憶體區域
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
...
// 將內核空間地址賦值給proc->buffer,即保存到行程背景關系中,對應內核虛擬地址的開始,即為binder記憶體的開始地址
proc->buffer = area->addr;
// 計算 "內核空間地址" 和 "行程虛擬地址" 的偏移
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
mutex_unlock(&binder_mmap_lock);
// 為proc->pages分配記憶體,用于存放內核分配的物理頁的頁描述指標:struct page,每個物理頁對應這樣一個struct page結構
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
...
// 內核空間的記憶體大小 = 行程虛擬地址區域(用戶空間)的記憶體大小
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
// 將 proc(行程背景關系資訊) 賦值給vma私有資料
vma->vm_private_data = proc;
// 通過呼叫binder_update_page_range()來分配物理頁面,
// 即,將物理記憶體映射到內核空間 以及 用戶空間
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
goto err_alloc_small_buf_failed;
}
buffer = proc->buffer;
INIT_LIST_HEAD(&proc->buffers);
// 將物理記憶體添加到proc->buffers鏈表中進行管理,
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;
// 把分配好記憶體插入到對應的表中(空閑記憶體表)
binder_insert_free_buffer(proc, buffer);
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(proc->tsk);
// 將用戶空間地址資訊保存到proc中
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
return 0;
...
}
這里可以看到binder_mmap的作用是進行記憶體映射,當應用呼叫到記憶體的binder_mmap()映射記憶體到行程虛擬地址時,該函式會進行兩個操作
- 第一,將指定大小的"物理記憶體" 映射到 “用戶空間”(即,行程的虛擬地址中)
- 第二,將該"物理記憶體" 也映射到 “內核空間(即,內核的虛擬地址中)”,簡單來說,就是"將行程虛擬地址空間和內核虛擬地址空間映射同一個物理頁面"
這樣在Binder通信機制中,binder_mmap()會將Server行程的虛擬地址和內核虛擬地址映射到同一個物理頁面,那么當Client行程向Server行程發送請求時,只需要將Client的資料拷貝到內核空間即可!由于Server行程的地址和內核空間映射到同一個物理頁面,因此,Client中的資料拷貝到內核空間時,也就相當于拷貝到了Server行程中,因此,Binder通信機制中,資料傳輸時,只需要1次記憶體拷貝!這就是Binder通信原理的精髓所在!
上面binder_update_page_range函式就是為行程的內核空間和行程的用戶空間針對同一塊物理記憶體建立映射,這樣行程的用戶空間和內核空間就可以共享該物理記憶體了,對于它我就不展開了,感興趣的可以參見博客Android binder中的mmap到binder_mmap呼叫流程和博客Android Binder框架實作之servicemanager守護行程的章節3.3以及mmap系統呼叫(內核空間到用戶空間的映射就OK了,
3.3 請求端行程資料傳輸程序
??本大章節的主題是Binder通信"一次拷貝"原始碼大揭秘,而其中我們需要要解決的是Binder通信傳輸的一次拷貝的本質,所以我們這里對Binder的其它枝節不予關系,只重點關注其中記憶體和資料的處理,而一次完整的Binder傳輸需要涉及到發送端和接收端行程(Binder也可以同一個行程通信,這種模式不在我們這里討論范圍之內),所以這里我們先從請求端行程開始分析起!
并且這里的分析,我們只關注資料的處理部分,發送端行程是怎么從業務邏輯呼叫到傳輸邏輯我們就不贅述了,有不清楚的詳見博客Android Binder框架實作之請求資料的發送,里面有關于Binder通信資料傳入的完整流程!
3.3.1 請求端用戶空間對傳輸資料的處理
在行程的用戶空間,我們知道BInder資料最后都會統一通過IPCThreadState::writeTransactionData對傳入的資料進行處理,我們看下它對傳入資料的處理邏輯,如下:
IPCThreadState::writeTransactionData
//[IPCThreadState.cpp]
//對于Binder實作有一定掌握的讀者,這里的代碼一定看著很親切嗎
status_t IPCThreadState::writeTransactionData(int32_t cmd, uint32_t binderFlags,
int32_t handle, uint32_t code, const Parcel& data, status_t* statusBuffer)
{
binder_transaction_data tr;
tr.target.ptr = 0; /* Don't pass uninitialized stack data to a remote process */
tr.target.handle = handle;
tr.code = code;
tr.flags = binderFlags;
tr.cookie = 0;
tr.sender_pid = 0;
tr.sender_euid = 0;
const status_t err = data.errorCheck();
..
tr.data_size = data.ipcDataSize(); //資料大小(對應mDataSize)
tr.data.ptr.buffer = data.ipcData(); //資料的起始地址(對應mData)
tr.offsets_size = data.ipcObjectsCount()*sizeof(binder_size_t); // data中保存的物件個數(對應mObjectsSize)
tr.data.ptr.offsets = data.ipcObjects(); // data中保存的物件的偏移地址陣列(對應mObjects)
...
// 將tr寫入mOut,
mOut.writeInt32(cmd);
mOut.write(&tr, sizeof(tr));
return NO_ERROR;
}
這里的binder_transaction_data資料結構存盤的是相關Binder傳入的資料和一些相關的控制指令,然后被 統一打包到了Parcel實體物件mOut中去了,關于Binder傳入涉及的資料結構binder_transaction_data其資料模型可以參見章節3.1的介紹!Binder要傳輸的資料打包完畢后,發送端行程會呼叫IPCThreadState::talkWithDriver函式繼續處理資料,我們接著往下看!
IPCThreadState::talkWithDriver
status_t IPCThreadState::talkWithDriver(bool doReceive)
{
binder_write_read bwr;
...
bwr.write_size = outAvail;
bwr.write_buffer = (uintptr_t)mOut.data();
// 這里我們先暫且忽略發送端讀取資料涉及的資料互動
if (doReceive && needRead) {
bwr.read_size = mIn.dataCapacity();
bwr.read_buffer = (uintptr_t)mIn.data();
} else {
...
}
....
bwr.write_consumed = 0;
bwr.read_consumed = 0;
status_t err;
. ...
//呼叫ioctl,然后通過系統呼叫到binder_ioctl
if (ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr) >= 0)
return err;
}
這里的處理邏輯也比較簡單,就是對前面的封裝的binder_transaction_data的資料又進行了一次的封裝,這里使用的是binder_write_read資料結構實體物件bwr,其中bwr.write_buffer保存了指向mOut.data()的指標,通過前面章節我們也知道了指向了前面的binder_transaction_data物件實體tr,
此處的資料封裝,一定要搞清楚,對于前面的資料模型一定要清楚,
3.3.2 請求端用戶空間對傳輸資料的處理
最終ioctl對通過系統呼叫到內核層的binder_ioctl進行下一步的處理,我們接著往下看(第一次拷貝要出現了),
//[kernel/drivers/staging/android/binder.c]
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
...
void __user *ubuf = (void __user *)arg;
....
switch (cmd) {
case BINDER_WRITE_READ: {
struct binder_write_read bwr;
if (size != sizeof(struct binder_write_read)) {
ret = -EINVAL;
goto err;
}
/*
第一次拷貝,將ubuf的資料從用戶空間拷貝到內核空間bwr中
注意此時的ubuf表示的是binder_write_read資料結構,即把它從“用戶空間”拷貝到“內核空間”
*/
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto err;
}
if (bwr.write_size > 0) {
//繼續
ret = binder_thread_write(proc, thread, bwr.write_buffer, bwr.write_size, &bwr.write_consumed);
...
}
...
}
這里我們遇到了第一個copy_from_user()呼叫,通過這個呼叫會把用戶空間的bwr指向的資料給拷貝到內核空間中,通過前面章節1.6我們知道copy_from_user()的第一個入參是拷貝的目標地址,這里給的是&bwr,bwr是binder_write_read 的實體物件,是對Binder傳輸資料的最外層封裝 ,所以此時還是沒有和服務端被映射的記憶體扯上關系,
難道我們這么快就找到了Binder框架實作中被重點強調的"一次拷貝"嗎?大家不要高興的這么早嗎,不然我這篇博客不就要和讀者說再見了嗎,
此處的從用戶空間拷貝到內核空間的資料bwr是前面我們在用戶空間封裝的協議的最外層,并不是發送端行程真正要傳遞的資料,它封裝的是一些傳入協議,如果真的要說bwr中攜帶了要傳遞的資料那也就是存盤了指向binder_transaction_data的指標資訊(這里或者換另外一種說法,就是對于Binder傳遞的資料內核中是分段多次拷貝的所以給人造成一種感覺是有執行了多次拷貝,有點像我們實際生活中多多餐少食和一餐多食其實吃的食量是一樣的!),
上述讀者一定要悟透,搞懂,不然會有一種越學越糊涂的感覺,尼瑪內核中不止一次拷貝啊!
接下來就進入binder_thread_write,其中涉及到資料傳入的引數bwr.write_buffer,這里我們需要重點關心的是write_buffer資料的指向,它指向的是那里,指向的是用戶空間的binder_transaction_data實體物件tr,
binder_thread_write
//[kernel/drivers/staging/android/binder.c]
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
uint32_t cmd;
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error == BR_OK) {
//從用戶空間獲取write_buffer指向的記憶體資料
if (get_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
...
switch (cmd) {
...
case BC_TRANSACTION:
case BC_REPLY: {
struct binder_transaction_data tr;
//這里又來了一次拷貝
if (copy_from_user(&tr, ptr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
binder_transaction(proc, thread, &tr, cmd == BC_REPLY);
break;
}
...
}
}
}
內核層怎么對傳入資料的決議這里我們就不分析了,在上述原始碼中我們遇到了第二個copy_from_user(),通過這次拷貝會把用戶空間的那個tr,也就是IPCThreadState.mOut,給拷貝到內核中來(注意此時binder_transaction_data并沒有真正的存盤要傳輸“”實際資料“”,它也是對Binder資料的一層封裝而已,它的data指標指向了真正的資料),所以此時還是沒有和服務端被映射的記憶體扯上關系,我們繼續往下分析binder_transaction()函式,看看它的處理流程,
binder_transaction函式
//[kernel/drivers/staging/android/binder.c]
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply)
{
//Binder事物
struct binder_transaction *t;
...
t->sender_euid = proc->tsk->cred->euid;
t->to_proc = target_proc;//事物的目標行程
t->to_thread = target_thread;//事物的目標執行緒
t->code = tr->code;//事物代碼
t->flags = tr->flags;
t->priority = task_nice(current);//執行緒的優先級的遷移
trace_binder_transaction(reply, t, target_node);
t->buffer = binder_alloc_buf(target_proc, tr->data_size,//從target行程的binder記憶體空間分配所需的記憶體大小(tr->data_size+tr->offsets_size),并且分配好的空間是已經被映射好的
tr->offsets_size, !reply && (t->flags & TF_ONE_WAY));
if (t->buffer == NULL) {
return_error = BR_FAILED_REPLY;
goto err_binder_alloc_buf_failed;
}
t->buffer->allow_user_free = 0;
t->buffer->debug_id = t->debug_id;
t->buffer->transaction = t;//該binder_buffer對應的事務
t->buffer->target_node = target_node;//該事物對應的目標binder物體
offp = (binder_size_t *)(t->buffer->data +
ALIGN(tr->data_size, sizeof(void *)));
if (copy_from_user(t->buffer->data, (const void __user *)(uintptr_t)
tr->data.ptr.buffer, tr->data_size)) {
...
}
if (copy_from_user(offp, (const void __user *)(uintptr_t)
tr->data.ptr.offsets, tr->offsets_size)) {
...
}
off_end = (void *)offp + tr->offsets_size;
...
}
這里牽涉到Binder事物傳遞流程,我們知道在進行Binder事物的傳遞時,如果一個Binder事物(用struct binder_transaction結構體表示需要使用到記憶體,就會呼叫binder_alloc_buf函式分配此次Binder事物需要的記憶體空間(并且這里我們需要注意它的第一個引數target_proc,此時binder_alloc_buf會從前面服務端行程的記憶體映射好的空間中劃分出一塊分配好的記憶體出來,然后t->buffer就指向這塊有映射的記憶體,此處是關鍵所在這塊牽涉的邏輯比較多,我們不糾結于此,感興趣的可以參見博客Android Binder 分析——記憶體管理),
接下來可以看到這里呼叫了兩次的copy_from_user()函式:
- 其中一次是copy parcel的data資料操作,此次就是把發起方用戶空間的資料直接拷貝到了接收方內核的記憶體映射中,這就是所謂“一次拷貝”的關鍵點(而這也是我認為Android所宣傳的一次拷貝的核心點)
- 另外一次copy parcel里flat_binder_object的偏移地址的資料(這次拷貝的資料體量上來講與前面一次拷貝資料的體量相比不是主要矛盾),所以這里我們就將就認為"一次拷貝"就指代這里吧,這里就把發送端行程從用戶空間傳遞過來的資料(parcel 打包)copy到內核空間了,而且這個內核空間的記憶體是接收服務端端提供的,更加重要的是這個塊內核空間還和接收端行程的 的用戶空間共同映射到了同一塊物理記憶體上了,這樣接收端就不需要再進行一次拷貝將資料從內核空間拷貝到用戶空間了
上述流程處理完畢之后,Binder驅動內核空間會將該次事物放到接收端執行緒所在的todo串列中,然后喚醒接收端目標執行緒對傳輸的資料進行下一步處理,我們也接著繼續跟進下看看服務端行程是怎么對發送端發過來的資料處理,
3.4 服務(接收)端行程資料傳輸程序
??我們知道Binder服務端行程在添加Binder服務到servicemanager行程以后,會開啟loop回圈然后阻塞在binder_thread_read函式中的thread->wait等待佇列上的目標執行緒,由于此時有事物的到來會被被喚醒,喚醒后從自己的thread->todo雙向串列中取出在binder_transaction()函式放入到該佇列的事務(struct binder_transaction),并用這個結構體來初始化struct binder_transaction_data結構體(關于此處不清楚的可以參見博客 Android Binder框架實作之Binder服務的訊息回圈),
3.4.1 服務(接收端)內核空間對傳輸資料的處理
如果說前面發送的流程是從用戶空間通過系統呼叫到內核空間,那么接收端則是相反的是先從內核空間開始處理的,這里我們來看下接收端行程內核中的處理流程,即呼叫binder_thread_read讀取資料,
binder_thread_read
//[kernel/drivers/staging/android/binder.c]
static int binder_thread_read(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed, int non_block)
{
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
...
tr.data_size = t->buffer->data_size;//事物對應的資料的大小
tr.offsets_size = t->buffer->offsets_size;
//得到事物對應的內核資料在用戶空間的訪問地址
tr.data.ptr.buffer = (binder_uintptr_t)(
(uintptr_t)t->buffer->data +
proc->user_buffer_offset);
//得到事務對應的資料在用戶空間的訪問地址
tr.data.ptr.offsets = tr.data.ptr.buffer +
ALIGN(t->buffer->data_size,
sizeof(void *));
if (put_user(cmd, (uint32_t __user *)ptr))//拷貝回傳命令
return -EFAULT;
ptr += sizeof(uint32_t);
//注意:只是拷貝了命令對應的固定大小的tr引數,并沒有拷貝tr.data.ptr.buffer指向的內容
if (copy_to_user(ptr, &tr, sizeof(tr)))
return -EFAULT;
...
}
這里我們遇到了第一個copy_to_user()呼叫,這里是把前面發送端行程傳遞過來的事物binder_transaction_data實體物件tr給拷貝到接收方的用戶空間的binder_write_read.read_buffer中(在此之前把內核映射的資料地址指標轉換為用戶空間的指標賦值給tr.data.ptr.buffer),所以此時我們的接收端行程的用戶空間可以直接使用tr.data.ptr.buffer的值就可以訪問到遠端傳遞過來的資料,而不需要繼續做拷貝動作將內核的資料通過copy_to_user來拷貝到用戶空間,同樣的道理用戶空間直接使用tr.data.ptr.offsets的值就可以直接訪問binder物件的偏移陣列,
此處接收端行程可以和前面發送端行程拷貝進行對比!
對于發送端行程需要從用戶空間向內核空間拷貝如下四個資料:
1. binder_write_read
2. binder_transaction_data
3. copy parcel的data資料操作
4. copy parcel里flat_binder_object的偏移地址的資料
而對于接收端行程而言,只要進行前面兩次拷貝就OK了,后面兩個通過記憶體映射的方式省去了
接著接收端行程從binder_thread_read函式中回傳,呼叫binder_ioctl方法繼續下一步的處理,我們接著往下看,
binder_ioctl
//[kernel/drivers/staging/android/binder.c]
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
...
void __user *ubuf = (void __user *)arg;
....
switch (cmd) {
case BINDER_WRITE_READ: {
if (bwr.read_size > 0) {
//接收端行程呼叫binder_thread_read
ret = binder_thread_read(proc, thread, bwr.read_buffer, bwr.read_size, &bwr.read_consumed, filp->f_flags & O_NONBLOCK);
...
}
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto err;
}
...
}
在這里我們看到了第二個copy_to_user(),它的功能主要是將把內核空間的bwr拷貝回用戶空間的ubuf中(注意此時bwr內包含指向tr的指標,也就是bwr.read_buffer是指向這個tr,或者說IPCThreadState.mIn),如上流程執行完畢以后就會回到接收端的用戶空間接著呼叫IPCThreadState::executeCommand執行下一步的處理邏輯,
3.4.1 服務(接收端)用戶空間對傳輸資料的處理
這里沒有啥好說的了,直接上原始碼看看IPCThreadState::executeCommand的處理邏輯,如下:
IPCThreadState::executeCommand
//[IPCThreadState.cpp]
status_t IPCThreadState::executeCommand(int32_t cmd)
{
...
case BR_TRANSACTION:
{
binder_transaction_data tr;
result = mIn.read(&tr, sizeof(tr));
...
Parcel buffer;
buffer.ipcSetDataReference(
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t), freeBuffer, this);
...
error = reinterpret_cast<BBinder*>(tr.cookie)->transact(tr.code, buffer, &reply, tr.flags);
}
...
}
這里首先把binder_transaction_data從mIn里面讀出來,然后就直接就把記憶體映射過來的指標tr.data.ptr.buffer也就是那“一次拷貝”過來的地址賦值給給buffer這個Parcel,這樣后續的物體Binder就可以呼叫transact來處理發起方傳過來的資料了,至此Android Binder通信的"一次拷貝"的原理到這里就結束了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/248631.html
標籤:其他