深度學習之強化學習(1)強化學習案例
- 強化學習案例
- 1. 平衡桿游戲
- 2. 策略網路
- 3. 梯度更新
- 4. 平衡桿游戲實戰
- 完整代碼
?強化學習時機器學習領域除有監督學習、無監督學習外的另一個研究分支,它主要利用智能體與環境進行互動,從而學習到能獲得良好結果的策略,與有監督學習不同,強化學習的動作并沒有明確的標注資訊,只有來自環境的反饋的獎勵資訊,它通常具有一定的滯后性,用于反映動作的“好與壞”,
?隨著深度學習神經網路的興起,強化學習這一領域也獲得了蓬勃的發展,2015年,英國DeepMind公司提出了基于深度神經網路的強化學習DQN,在太空入侵者、打磚塊、乒乓球等49個Atari游戲中取得了與人類相當的游戲水平;2017年,DeepMind提出的AlphaGo程式以3:0的比分戰勝當時圍棋世界排名第一的選手柯潔;同年,AlphaGo的新版本AlphaGo Zero在無任何人類知識的條件下,通過自我博弈訓練的方式以100:0戰勝了AlphaGo;2019年,OpenAI Five程式以2:0戰勝Dota2世界冠軍OG隊伍,盡管這次比賽的游戲規則有所限制,但是對于Dota2這種對于需要超強個體只能水平和良好團隊協作的游戲,這次勝利無疑再次堅定了人類對于AGI的信念,
?本章我們將介紹強化學習中的主流演算法,其中包含在太空入侵者等游戲上取得類人水平的DQN演算法、制勝Dota2的主要功臣PPO演算法等,
強化學習案例
?強化學習演算法的設計與傳統的有監督學習不太一樣,包含了大量的新的數學公式推導,在進入強化學習演算法的學習程序之前,我們先通過一個簡單的例子來感受強化學習演算法的魅力,
?此節不需要掌握每個細節,以直觀感受為主,獲得第一印象即可,
1. 平衡桿游戲
?平衡桿游戲系統包含了三個物體:滑軌、小車和桿,如圖1所示,小車可以自由在滑軌上移動,桿的一側通過軸承固定在小車上,在初始狀態,小車位于滑軌中央,桿豎直立在小車上,智能體通過控制小車的左右移動來控制桿的平衡,當桿與豎直方向的角度大于某個角度或者小車偏離滑軌中心位置一定距離后視為游戲結束,游戲時間越長,游戲給予的回報也就越多,智能體的操控水平也越高,
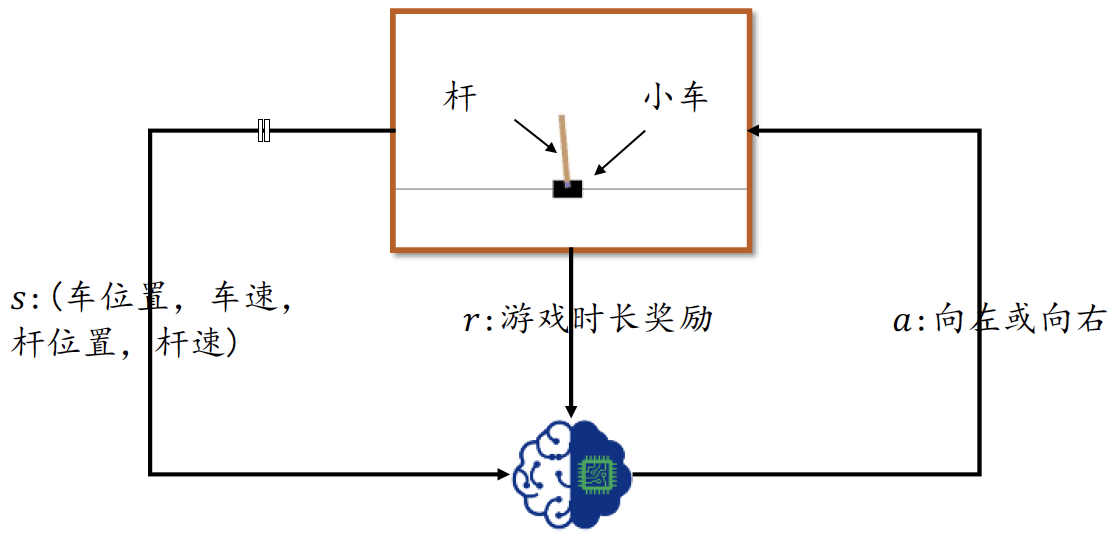
?為了簡化環境狀態的表示,我們這里直接取高層的環境特征向量s作為智能體的輸入,它一共包含了四個高層特征,分別為:小車位置、小車速度、桿角度和桿的速度,智能體的輸出動作
a
a
a為向左移動或者向右移動,動作施加在平衡桿系統上會產生一個新的狀態,同時系統也會回傳一個獎勵值,這個獎勵值可以簡單的記為1,即時長加1,在每個時間戳
t
t
t上面,智能體通過觀察環境狀態
s
t
s_t
st?而產生動作
a
t
a_t
at?,環境接收動作后狀態改變為
s
t
+
1
s_{t+1}
st+1?,并回傳獎勵
r
t
r_t
rt?,
2. 策略網路
?下面我們來探討強化學習中最為關鍵的環節:如何判斷和決策?我們把判斷和決策叫做策略(Policy),策略的輸入是狀態
s
s
s,輸出為某具體的動作
a
a
a或動作的分布
π
θ
(
a
∣
s
)
π_θ (a|s)
πθ?(a∣s),其中
θ
θ
θ為策略函式
π
π
π的引數,可以利用神經網路來引數化
π
θ
π_θ
πθ?函式,如圖2所示:
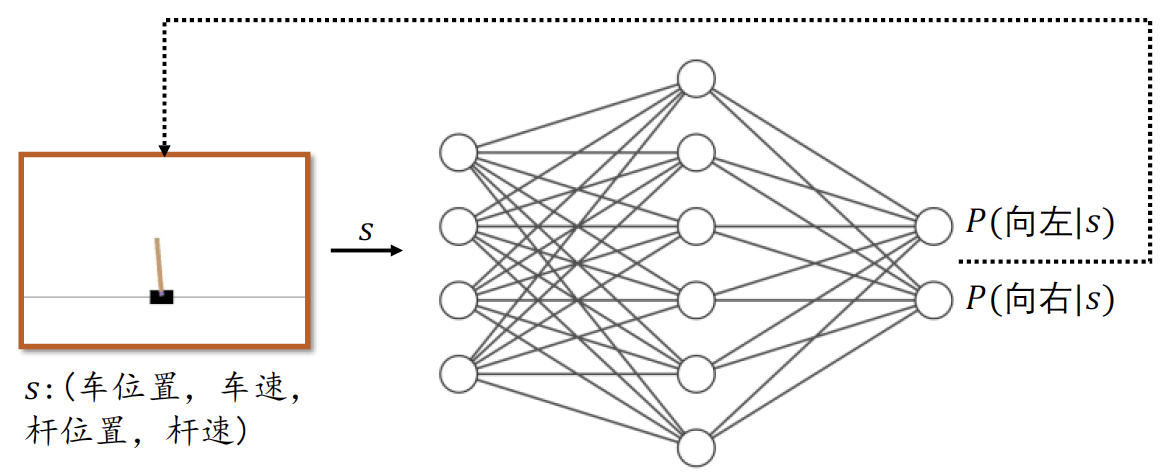
?圖中神經網路
π
θ
π_θ
πθ?的輸入為平衡桿系統的狀態
s
s
s,即長度為4的向量,輸出為所有動作的概率
π
θ
(
a
∣
s
)
π_θ (a|s)
πθ?(a∣s):向左的概率
P
(
向
左
∣
s
)
P(向左|s)
P(向左∣s)和向右的概率
P
(
向
右
∣
s
)
P(向右|s)
P(向右∣s),并滿足所有動作概率之和為1的關系:
∑
a
∈
A
π
θ
(
a
∣
s
)
=
1
∑_{a∈A}π_θ (a|s)=1
a∈A∑?πθ?(a∣s)=1
其中
A
A
A為所有動作的集合,
π
θ
π_θ
πθ?網路代表了智能體的策略,稱為策略網路,很自然地,我們可以將策略函式具體化為輸入節點為4個,中間多個全連接隱藏層,輸出層的輸出節點數為2的神經網路,代表了這兩個動作的概率分布,在互動時,選擇概率最大的動作
a
t
=
argmax
a
?
π
θ
(
a
∣
s
t
)
a_t=\underset{a}{\text{argmax}}?\ π_θ (a|s_t)
at?=aargmax?? πθ?(a∣st?)
作為決策結果,作用與環境中,并得到新的狀態
s
t
+
1
s_{t+1}
st+1?和獎勵
r
t
r_t
rt?,如此回圈往復,直至游戲回合結束,
?我們將策略網路實作為一個2層的全連接網路,第一層將長度為4的向量轉換為長度為128的向量,第二層將128的向量轉換為2的向量,即動作的概率分布,和普通的神經網路的創建程序一樣,代碼如下:
class Policy(keras.Model):
# 策略網路,生成動作的概率分布
def __init__(self):
super(Policy, self).__init__()
self.data = [] # 存盤軌跡
# 輸入為長度為4的向量,輸出為左、右2個動作,指定W張量的初始化方案
self.fc1 = layers.Dense(128, kernel_initializer='he_normal')
self.fc2 = layers.Dense(2, kernel_initializer='he_normal')
# 網路優化器
self.optimizer = optimizers.Adam(lr=learning_rate)
def call(self, inputs, training=None):
# 狀態輸入s的shape為向量:[4]
x = tf.nn.relu(self.fc1(inputs))
x = tf.nn.softmax(self.fc2(x), axis=1) # 獲得動作的概率分布
return x
?在互動時,我們將每個時間戳上的狀態輸入
s
t
s_t
st?,動作分布輸出
a
t
a_t
at?,環境獎勵
r
t
r_t
rt?和新狀態
s
t
+
1
s_{t+1}
st+1?作為一個4元組item記錄下來,用于策略網路的訓練,代碼如下:
def put_data(self, item):
# 記錄r,log_P(a|s)
self.data.append(item)
3. 梯度更新
?如果需要利用梯度下降演算法來優化網路,需要知道每個輸入
s
t
s_t
st?的標注資訊
a
t
a_t
at?,并且確保從輸入到損失值是連續可導的,但是強化學習與傳統的有監督學習并不相同,主要體現為強化學習在每一個時間戳
t
t
t上面的動作
a
t
a_t
at?并沒有一個明確的好與壞的標準,獎勵
r
t
r_t
rt?可以在一定程度上反映動作的好壞,但不能直接決定動作的好壞,甚至有些游戲互動程序只有一個最終的代表游戲結果的獎勵
r
t
r_t
rt?信號,如圍棋,那么給每個狀態定義一個最優動作
a
t
?
a_t^*
at??作為神經網路輸入
s
t
s_t
st?的標注可行嗎?首先是游戲中的狀態總數通常是巨大的,如圍棋的狀態數共有約
1
0
170
10^{170}
10170之多,再者每個狀態很難定義一個最優動作,有些動作雖然短期回報不高,但是長期回報卻是較好的,而且有時候甚至連人類自己都不知道哪個動作才是最優的,
?因此,策略的優化目標不應該是讓輸入
s
t
s_t
st?的輸出盡可能地逼近標注動作,而是要最大化總回報的期望值,總回報可以定義為從游戲會和開始到游戲結束前的激勵之和
∑
r
t
∑r_t
∑rt? ,一個好的策略,應能夠在環境上面取得的總的回報的期望值
J
(
π
θ
)
J(π_θ)
J(πθ?)最高,根據梯度上升演算法的原理,我們如果能夠求出
?
J
(
θ
)
?
θ
\frac{?J(θ)}{?θ}
?θ?J(θ)?,那么策略網路只需要按照
θ
′
=
θ
+
η
?
?
J
(
θ
)
?
θ
θ'=θ+η\cdot\frac{?J(θ)}{?θ}
θ′=θ+η??θ?J(θ)?
即可迭代優化策略網路,從而忽的較大的期望總回報,
?很遺憾的是,總回報期望
J
(
θ
)
J(θ)
J(θ)是由游戲環境給出的,如果無法得知環境模型,那么
?
J
(
θ
)
?
θ
\frac{?J(θ)}{?θ}
?θ?J(θ)?是不能通過自動微分計算的,那么即使
J
(
θ
)
J(θ)
J(θ)運算式未知,能不能直接求解偏導數
?
J
(
θ
)
?
θ
\frac{?J(θ)}{?θ}
?θ?J(θ)?呢?
?答案是肯定的,我們這里直接給出
?
J
(
θ
)
?
θ
\frac{?J(θ)}{?θ}
?θ?J(θ)?的推導結果,具體的推導程序會在梯度推導的小節里詳細介紹:
?
J
(
θ
)
?
θ
=
E
τ
~
p
θ
(
τ
)
[
(
∑
t
=
1
T
?
?
θ
log
?
π
θ
(
a
t
│
s
t
)
)
R
(
τ
)
]
\frac{?J(θ)}{?θ}=\mathbb E_{τ\sim p_θ (τ) }\bigg [\Big(∑_{t=1}^T\frac{?}{?θ} \text{log}?π_θ (a_t│s_t )\Big)R(τ)\bigg]
?θ?J(θ)?=Eτ~pθ?(τ)?[(t=1∑T??θ??log?πθ?(at?│st?))R(τ)]
利用上式,只需要計算出
?
?
θ
log
?
π
θ
(
a
t
│
s
t
)
\frac{?}{?θ} \text{log}?π_θ (a_t│s_t )
?θ??log?πθ?(at?│st?),并乘以
R
(
τ
)
R(τ)
R(τ)即可更新出
?
J
(
θ
)
?
θ
\frac{?J(θ)}{?θ}
?θ?J(θ)?,按照
θ
′
=
θ
?
η
?
?
L
(
θ
)
?
θ
θ'=θ-η\cdot\frac{?\mathcal L(θ)}{?θ}
θ′=θ?η??θ?L(θ)?方式更新策略網路,即可最大化
J
(
θ
)
J(θ)
J(θ)函式,其中
R
(
τ
)
R(τ)
R(τ)為某次互動的總回報,
τ
τ
τ為互動軌跡
s
1
,
a
1
,
r
1
,
s
2
,
a
2
,
r
2
,
…
,
s
T
s_1,a_1,r_1,s_2,a_2,r_2,…,s_T
s1?,a1?,r1?,s2?,a2?,r2?,…,sT?,
T
T
T是互動的時間戳數量或步數,
log
?
π
θ
(
a
t
│
s
t
)
\text{log}?π_θ (a_t│s_t )
log?πθ?(at?│st?)為策略網路的輸出中
a
t
a_t
at?動作的概率值取
log
\text{log}
log函式,
log
?
π
θ
(
a
t
│
s
t
)
\text{log}?π_θ (a_t│s_t )
log?πθ?(at?│st?)可以通過TensorFlow自動微分求解出網路的梯度,這一部分是連續可導的,
?損失函式的代碼實作為:
for r, log_prob in self.data[::-1]: # 逆序取軌跡資料
R = r + gamma * R # 累加計算每個時間戳上的回報
# 每個時間戳都計算一次梯度
# grad_R=-log_P*R*grad_theta
loss = -log_prob * R
完整的訓練及更新代碼如下:
def train_net(self, tape):
# 計算梯度并更新策略網路引數,tape為梯度記錄器
R = 0 # 終結狀態的初始回報為0
for r, log_prob in self.data[::-1]: # 逆序取軌跡資料
R = r + gamma * R # 累加計算每個時間戳上的回報
# 每個時間戳都計算一次梯度
# grad_R=-log_P*R*grad_theta
loss = -log_prob * R
with tape.stop_recording():
# 優化策略網路
grads = tape.gradient(loss, self.trainable_variables)
# print(grads)
self.optimizer.apply_gradients(zip(grads, self.trainable_variables))
self.data = [] # 清空軌跡
4. 平衡桿游戲實戰
我?們一共訓練400個回合,在回合的開始,復位游戲狀態,通過送入輸入狀態來采樣動作,從而與環境進行互動,并記錄每一個時間戳的資訊,直至游戲回合結束,
?互動和訓練部分代碼如下:
for n_epi in range(400):
s = env.reset() # 回到游戲初始狀態,回傳s0
with tf.GradientTape(persistent=True) as tape:
for t in range(501): # CartPole-v1 forced to terminates at 500 step.
# 送入狀態向量,獲取策略
s = tf.constant(s, dtype=tf.float32)
# s: [4] => [1,4]
s = tf.expand_dims(s, axis=0)
prob = pi(s) # 動作分布:[1,2]
# 從類別分布中采樣1個動作, shape: [1]
a = tf.random.categorical(tf.math.log(prob), 1)[0]
a = int(a) # Tensor轉數字
s_prime, r, done, info = env.step(a)
# 記錄動作a和動作產生的獎勵r
# prob shape:[1,2]
pi.put_data((r, tf.math.log(prob[0][a])))
s = s_prime # 重繪狀態
score += r # 累積獎勵
if n_epi >1000:
env.render()
# im = Image.fromarray(s)
# im.save("res/%d.jpg" % info['frames'][0])
if done: # 當前episode終止
break
# episode終止后,訓練一次網路
pi.train_net(tape)
del tape
模型的訓練程序如圖3所示,橫軸為訓練回合數量,縱軸為回合的平均回報值,可以看到隨著訓練的進行,網路獲得的平均回報越來越高,策略越來越好,實際上,強化學習演算法對引數及其敏感,甚至修改隨機種子都會導致截然不同的性能表現,在實作的程序中需要精調引數才能發揮出演算法的潛力,
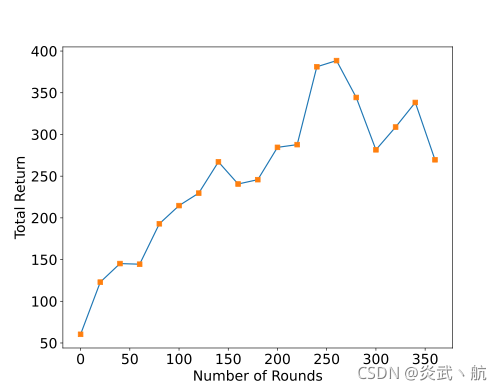
?通過這個例子,我們對強化學習演算法和強化學習的互動程序有了初步的印象和了解,接下來我們來正式化描述強化學習問題,
完整代碼
import gym
import os
import numpy as np
import matplotlib
from matplotlib import pyplot as plt
# Default parameters for plots
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, losses
from PIL import Image
matplotlib.rcParams['font.size'] = 18
matplotlib.rcParams['figure.titlesize'] = 18
matplotlib.rcParams['figure.figsize'] = [9, 7]
matplotlib.rcParams['font.family'] = ['KaiTi']
matplotlib.rcParams['axes.unicode_minus'] = False
env = gym.make('CartPole-v1') # 創建游戲環境
env.seed(2333)
tf.random.set_seed(2333)
np.random.seed(2333)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
learning_rate = 0.0002
gamma = 0.98
class Policy(keras.Model):
# 策略網路,生成動作的概率分布
def __init__(self):
super(Policy, self).__init__()
self.data = [] # 存盤軌跡
# 輸入為長度為4的向量,輸出為左、右2個動作,指定W張量的初始化方案
self.fc1 = layers.Dense(128, kernel_initializer='he_normal')
self.fc2 = layers.Dense(2, kernel_initializer='he_normal')
# 網路優化器
self.optimizer = optimizers.Adam(lr=learning_rate)
def call(self, inputs, training=None):
# 狀態輸入s的shape為向量:[4]
x = tf.nn.relu(self.fc1(inputs))
x = tf.nn.softmax(self.fc2(x), axis=1) # 獲得動作的概率分布
return x
def put_data(self, item):
# 記錄r,log_P(a|s)
self.data.append(item)
def train_net(self, tape):
# 計算梯度并更新策略網路引數,tape為梯度記錄器
R = 0 # 終結狀態的初始回報為0
for r, log_prob in self.data[::-1]: # 逆序取軌跡資料
R = r + gamma * R # 累加計算每個時間戳上的回報
# 每個時間戳都計算一次梯度
# grad_R=-log_P*R*grad_theta
loss = -log_prob * R
with tape.stop_recording():
# 優化策略網路
grads = tape.gradient(loss, self.trainable_variables)
# print(grads)
self.optimizer.apply_gradients(zip(grads, self.trainable_variables))
self.data = [] # 清空軌跡
def main():
pi = Policy() # 創建策略網路
pi(tf.random.normal((4, 4)))
pi.summary()
score = 0.0 # 計分
print_interval = 20 # 列印間隔
returns = []
for n_epi in range(400):
s = env.reset() # 回到游戲初始狀態,回傳s0
with tf.GradientTape(persistent=True) as tape:
for t in range(501): # CartPole-v1 forced to terminates at 500 step.
# 送入狀態向量,獲取策略
s = tf.constant(s, dtype=tf.float32)
# s: [4] => [1,4]
s = tf.expand_dims(s, axis=0)
prob = pi(s) # 動作分布:[1,2]
# 從類別分布中采樣1個動作, shape: [1]
a = tf.random.categorical(tf.math.log(prob), 1)[0]
a = int(a) # Tensor轉數字
s_prime, r, done, info = env.step(a)
# 記錄動作a和動作產生的獎勵r
# prob shape:[1,2]
pi.put_data((r, tf.math.log(prob[0][a])))
s = s_prime # 重繪狀態
score += r # 累積獎勵
if n_epi > 1000:
env.render()
# im = Image.fromarray(s)
# im.save("res/%d.jpg" % info['frames'][0])
if done: # 當前episode終止
break
# episode終止后,訓練一次網路
pi.train_net(tape)
del tape
if n_epi % print_interval == 0 and n_epi != 0:
returns.append(score/print_interval)
print(f"# of episode :{n_epi}, avg score : {score/print_interval}")
score = 0.0
env.close() # 關倍訓境
plt.plot(np.arange(len(returns))*print_interval, returns)
plt.plot(np.arange(len(returns))*print_interval, returns, 's')
plt.xlabel('Number of Rounds') # 回合數
plt.ylabel('Total Return') # 總回報
plt.savefig('reinforce-tf-cartpole.svg')
plt.show()
if __name__ == '__main__':
main()
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/326024.html
標籤:其他