我有一個很長的資料框,里面有很多NA's。
我想找到 A 列和 D 列的值的比率。如何只選擇 A 列和 D 列中都有資料的行?
例如,在此影像中,我只想比較 A 列和 D 列的第 2、4、6 行的值。
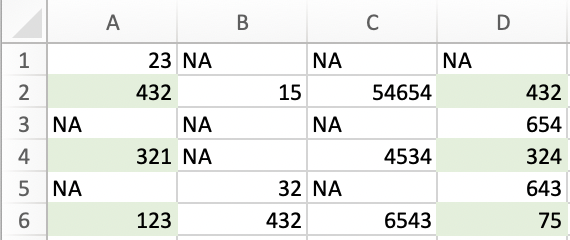
我可以na.omit在每一行上使用,但我不確定如何讓 R 找到兩列中都存在資料的行。
uj5u.com熱心網友回復:
像這樣:
library(tidyverse)
df <- data.frame(col1=c(1, NA, 7), col2=c(NA, 2, 5))
# col1 col2
# 1 1 NA
# 2 NA 2
# 3 7 5
df %>%
filter(!is.na(col1) & !is.na(col2))
#
# col1 col2
# 1 7 5
uj5u.com熱心網友回復:
以下是一些使用基礎R 的選項。
使用is.na():
df[!is.na(df$A) & !is.na(df$D), ]
# A B C D
# 1 432 15 54654 432
# 2 321 NA 4534 324
# 3 123 432 6543 75
使用complete.cases():
df[complete.cases(df$A, df$D), ]
# A B C D
# 1 432 15 54654 432
# 2 321 NA 4534 324
# 3 123 432 6543 75
使用subset():
subset(df, complete.cases(A, D))
# A B C D
# 1 432 15 54654 432
# 2 321 NA 4534 324
# 3 123 432 6543 75
以下是使用tidyverse的其他幾個選項。
使用drop_na()自tidyr:
library(dplyr)
library(tidyr)
df %>%
drop_na(A, D)
# A B C D
# 1 432 15 54654 432
# 2 321 NA 4534 324
# 3 123 432 6543 75
使用complete.cases()與filter()來自dplyr(這個其實是我偏愛的可讀性):
library(dplyr)
df %>%
filter(complete.cases(A, D))
# A B C D
# 1 432 15 54654 432
# 2 321 NA 4534 324
# 3 123 432 6543 75
資料:
df <- data.frame(A = c(23, 432, NA, 321, NA, 123),
B = c(NA, 15, NA, NA, 32, 432),
C = c(NA, 54654, NA, 4534, NA, 6543),
D = c(NA, 432, 654, 324, 643, 75))
uj5u.com熱心網友回復:
要僅獲取值,您可以簡單地:
(df$A / df$D)[!is.na(df$A / df$D)]
[1] 1.0000000 0.9907407 1.6400000
這將值作為附加列:
cbind( df, df$A / df$D )
A B C D df$A/df$D
1 23 NA NA NA NA
2 432 15 54654 432 1.0000000
3 NA NA NA 654 NA
4 321 NA 4534 324 0.9907407
5 NA 32 NA 643 NA
6 123 432 6543 75 1.6400000
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/351304.html