假設概率分布的密度核為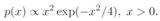 ,我可以使用哪些蒙特卡羅方法來估計分布的均值和方差?
,我可以使用哪些蒙特卡羅方法來估計分布的均值和方差?
uj5u.com熱心網友回復:
我們可以在這里使用數值方法。首先,我們創建了一個函式來表示您的概率密度函式(盡管它還沒有進行縮放,因此其在整個域上的積分為 1):
pdf <- function(x) x^2 * exp(-x^2/4)
plot(pdf, xlim = c(0, 10))
為了獲得將其轉換為真正的 pdf 的縮放因子,我們可以在其域上集成此函式c(0, Inf)。
integrate(pdf, 0, Inf)$value
#> [1] 3.544908
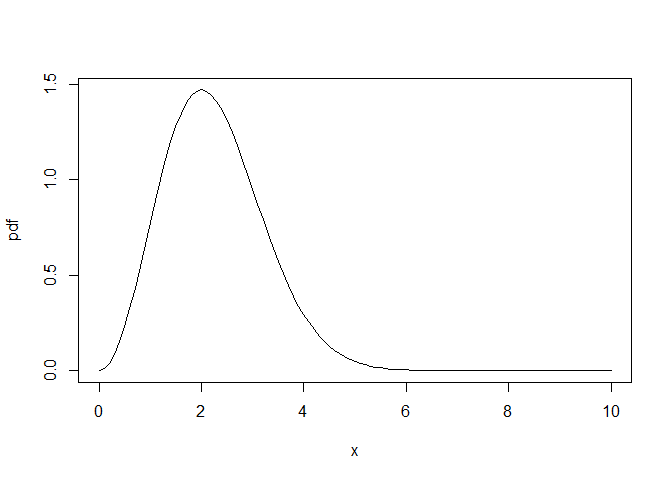
所以現在我們可以通過將原始pdf除以這個數量來生成一個真正的pdf:
pdf <- function(x) x^2 * exp(-x^2/4) / 3.544908
plot(pdf, xlim = c(0, 10))
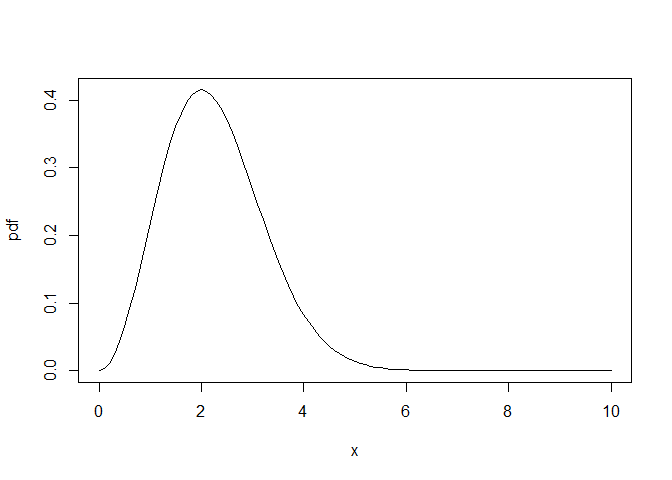
現在我們有了一個 pdf,我們可以創建一個帶有數值積分的 cdf:
cdf <- function(x) sapply(x, \(i) integrate(pdf, 0, i)$value)
plot(cdf, xlim = c(0, 10))
我們需要 cdf 的倒數,以便能夠將從 0 和 1 之間的均勻分布中抽取的樣本轉換為從我們的新分布中抽取的樣本。我們可以創建這個反函式,uniroot用于查找 cdf 的輸出與 0 和 1 之間的任意數字匹配的位置:
inverse_cdf <- function(p)
{
sapply(p, function(i) {
uniroot(function(a) {cdf(a) - i}, c(0, 100))$root
})
}
逆 cdf 如下所示:
plot(inverse_cdf, xlim = c(0, 0.99))
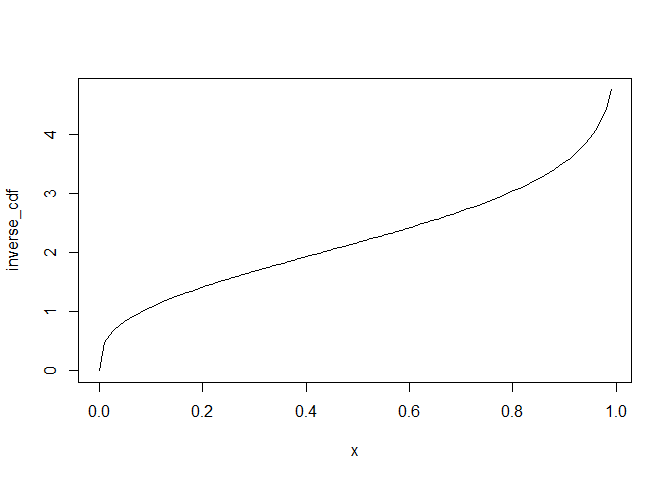
We are now ready to draw a sample from our distribution:
set.seed(1) # Makes this draw reproducible
x_sample <- inverse_cdf(runif(1000))
Now we can plot a histogram of our sample and ensure it matches the pdf:
hist(x_sample, freq = FALSE)
plot(function(x) pdf(x), add = TRUE, xlim = c(0, 6))
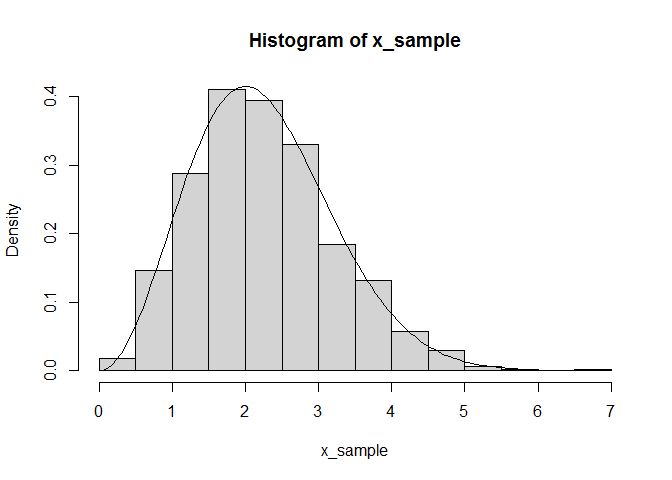
Now that we have a sample drawn from x, we can use the sample mean and variance as estimates for the distribution's mean and variance:
mean(x_sample)
#> [1] 2.264438
var(x_sample)
#> [1] 0.9265678
We can increase the accuracy of these estimates by taking larger and larger samples in our call to inverse_cdf(runif(1000)), by increasing the 1000 to a larger number.
Created on 2021-11-06 by the reprex package (v2.0.0)
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/351305.html