arr = np.arange(16).reshape((2, 2, 4))
arr.strides
(32, 16, 4)
所以,根據我的知識,我相信在記憶體中它會類似于下圖。步幅與軸一起標記(在箭頭上)。
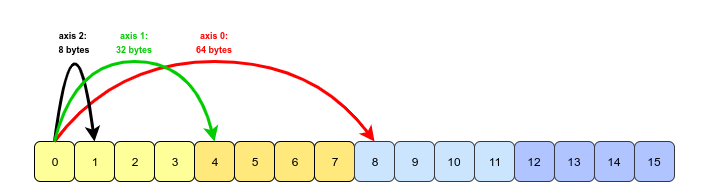
這就是我在使用命令轉置軸之一后的想法:
arr.transpose((1, 0, 2))
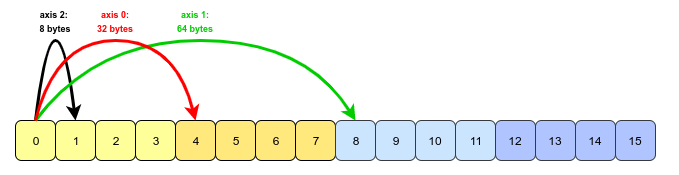
我知道記憶體塊沒有變化,但我無法理解 strides 究竟如何幫助遍歷記憶體塊中的陣列以生成預期的陣列。(它是否以相反的順序遍歷不同軸上的元素?)
[[[ 0 1 2 3]
[ 4 5 6 7]]
[[ 8 9 10 11]
[12 13 14 15]]]
我嘗試通過 C 中的官方 numpy 代碼來理解,但我無法理解。
如果有人能以更簡單的方式提供解釋,那就太好了。
uj5u.com熱心網友回復:
除非明確要求(例如使用axis引數),否則 Numpy 總是從最大的軸到最小的軸(即降序)遍歷軸。因此,在您的示例中,它首先讀取記憶體中偏移量 0 處的視圖專案,然后添加軸 2 的步幅(此處為 4)并讀取下一個專案,依此類推,直到到達軸的末端。然后將軸 1 的步幅添加一次并再次重復之前的回圈,以此類推。
內部 Numpy C 代碼的行為如下:
// Numpy array are not strongly typed internally.
// The raw memory buffer is always contiguous.
char* data = view.rawData;
const size_t iStride = view.stride[0];
const size_t jStride = view.stride[1];
const size_t kStride = view.stride[2];
for(int i=0 ; i<view.shape[0] ; i) {
for(int j=0 ; j<view.shape[1] ; j) {
for(int k=0 ; k<view.shape[2] ; k) {
// Compute the offset from the view strides
const size_t offset = iStride * i jStride * j kStride * k;
// Extract an item at the memory offset
Type item = (Type*)(data offset);
// Do something with item here (eg. print it)
}
}
}
當您應用換位時,Numpy 會更改步幅,以便iStride和jStride交換。它還更新形狀(view.shape[0]并且view.shape[1]也被交換)。代碼將像交換兩個回圈一樣執行,但記憶體訪問效率較低,因為它們不太連續。下面是一個例子:
arr = np.arange(16).reshape((2, 2, 4))
arr.strides # (32, 16, 4)
view = arr.transpose((1, 0, 2))
view.strides # (16, 32, 4) <-- note that 16 and 32 have been swapped
請注意,步幅以位元組為單位(而不是專案數量)。
uj5u.com熱心網友回復:
根據我的經驗,通過 C 代碼作業太多了。簡單地找到相關函式是最難的部分。 strides無論尺寸或“轉置”如何,作業方式都相同。
從更簡單的東西開始,例如 (2,3) 陣列,其轉置步幅將為 (8,24)。想象一下穿過平面 [0,1,2...]。
樣本陣列,大小為 1 個位元組,因此順序步幅僅為 1
In [635]: x=np.arange(6,dtype='uint8')
In [636]: x
Out[636]: array([0, 1, 2, 3, 4, 5], dtype=uint8)
In [637]: x.strides
Out[637]: (1,)
現在重塑它:
In [638]: y=x.reshape(2,3)
In [639]: y
Out[639]:
array([[0, 1, 2],
[3, 4, 5]], dtype=uint8)
In [640]: y.strides
Out[640]: (3, 1)
為了跨越列,我們仍然只是一步一步地通過共享x資料緩沖區。往下走,我們從 3、0 到 3、2 到 5。
In [641]: z = y.transpose()
In [642]: z
Out[642]:
array([[0, 3],
[1, 4],
[2, 5]], dtype=uint8)
In [643]: z.strides
Out[643]: (1, 3)
現在往下走,我們一步一步地走,一步步地穿過 3。
但是隨后您對影像進行了相同的推論(我們應該正式忽略它:))
那么你的問題是什么?如果您在瀏覽某些特定C代碼時遇到問題,則需要顯示它,或者至少參考它。
遍歷陣列的方法有很多種。對于平坦的步幅并不重要,它只是一次通過資料緩沖區一項。
但是如果例如我們在第一個維度上迭代,
In [687]: for i in y:print(i)
[0 1 2]
[3 4 5]
步 3 以獲取下一行。
In [688]: for i in z:print(i)
[0 3]
[1 4]
[2 5]
而這一步步 1。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/383416.html
標籤:麻木的 记忆 numpy-ndarray 大步
下一篇:根據條件從現有資料框創建新資料框