我被一個問題困擾了幾天。我做了一個腳本:
- 從 CSV 檔案中獲取資料 - 按資料檔案第一列中的相同值對其進行排序 - 在不同模板文本檔案的特定欄位行中插入排序的資料 - 將檔案保存在盡可能多的副本中,因為資料檔案中的第一列中有不同的值下圖顯示了它是如何作業的:
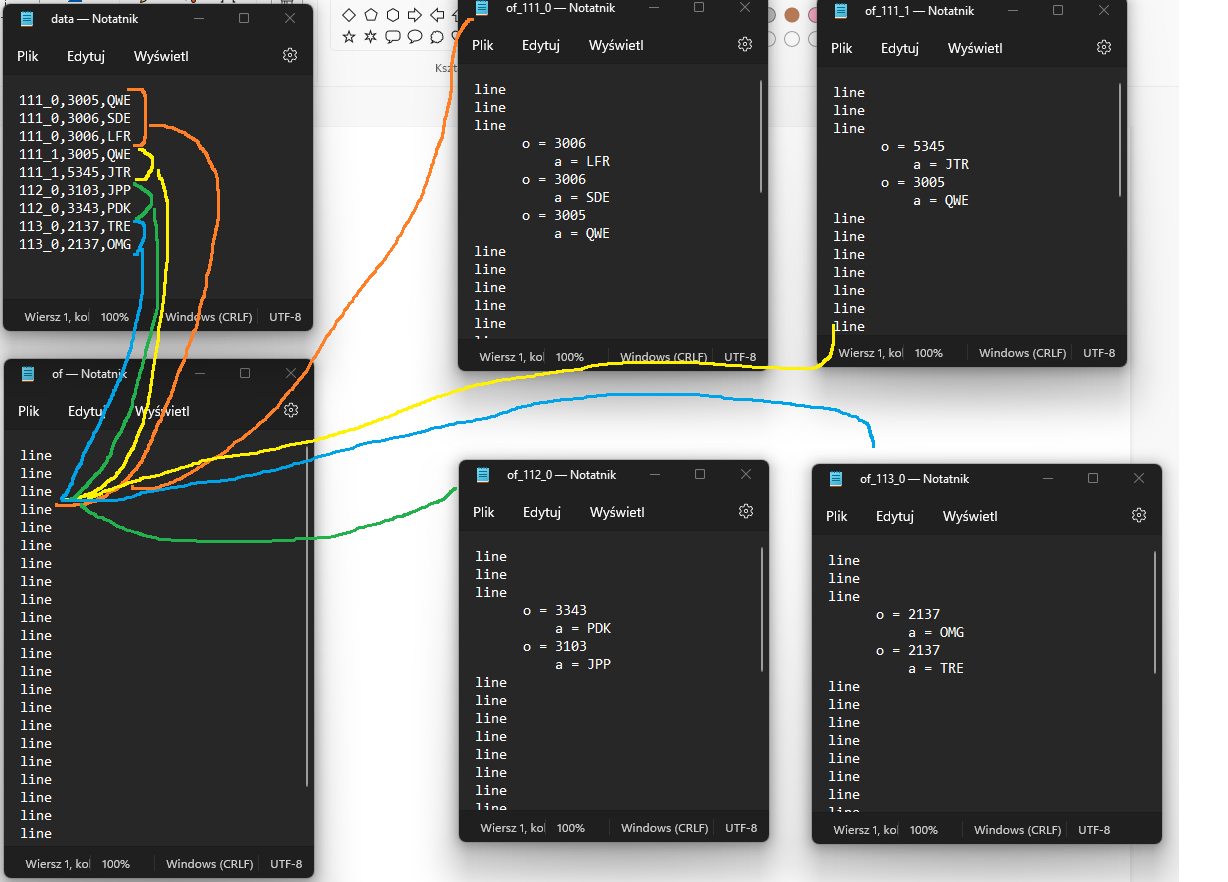
但是我還需要做兩件事。當在如上所示的單獨檔案中時,資料檔案的第二列中有一些相同的值,那么這個檔案應該從第三列插入值,而不是從第二列重復相同的值。在下面的圖片中,我展示了它的外觀:
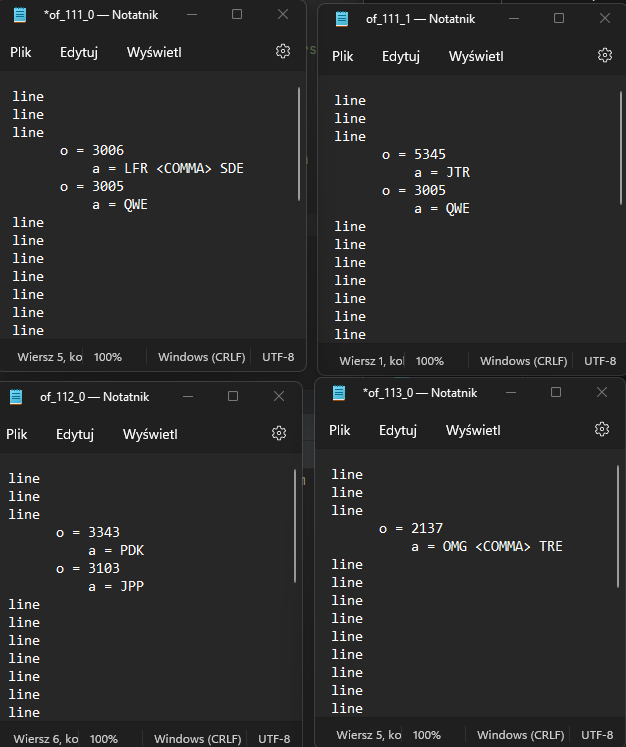
我還需要通過“_”從資料檔案中添加第一列的某處分隔值。
有資料檔案:
111_0,3005,QWE
111_0,3006,SDE
111_0,3006,LFR
111_1,3005,QWE
111_1,5345,JTR
112_0,3103,JPP
112_0,3343,PDK
113_0,2137,TRE
113_0,2137,OMG
我做了代碼:
import shutil
with open("data.csv") as f:
contents = f.read()
contents = contents.splitlines()
values_per_baseline = dict()
for line in contents:
key = line.split(',')[0]
values = line.split(',')[1:]
if key not in values_per_baseline:
values_per_baseline[key] = []
values_per_baseline[key].append(values)
for file in values_per_baseline.keys():
x = 3
shutil.copyfile("of.txt", (f"of_%s.txt" % file))
filename = f"of_%s.txt" % file
for values in values_per_baseline[file]:
with open(filename, "r") as f:
contents = f.readlines()
contents.insert(x, ' o = ' values[0] '\n ' 'a = ' values[1] '\n')
with open(filename, "w") as f:
contents = "".join(contents)
f.write(contents)
f.close()
我一直在嘗試制作類似于串列字典的字典,但我無法以正確的方式實作它以使其正常作業。任何幫助或建議將不勝感激。
uj5u.com熱心網友回復:
當我運行您的代碼時,我收到此錯誤:
contents.insert(x, ' o = ' values[0] '\n ' 'a = ' values[3] '\n')
IndexError: list index out of range
讓我們想想這個錯誤是從哪里來的。這是一個IndexError在名單上。這條線上使用的唯一串列values似乎是一個開始尋找的好地方。
要除錯,您可以考慮在吐出錯誤的行之前添加類似這樣的內容:
print(values)
print(values[0])
print(values[3])
這使
['3005', 'QWE']
3005
Traceback (most recent call last):
File "qqq.py", line 25, in <module>
print(values[3])
IndexError: list index out of range
所以問題在于values[3],這是有道理的,因為len(values)==2和 所以索引需要是0和1。如果我們更改values[3]為,values[1]那么我認為您會得到您想要的。例如:
$ cat of_111_0.txt
line
line
line
o = 3006
a = LFR
o = 3006
a = SDE
o = 3005
a = QWE
line
line
line
line
line
為了解決問題的下一步,我建議您將第一個回圈更改為:
for line in contents:
key = line.split(',')[0]
values = line.split(',')[1:]
if key not in values_per_baseline:
values_per_baseline[key] = {}
if values[0] not in values_per_baseline[key]:
values_per_baseline[key][values[0]] = values[1]
else:
values_per_baseline[key][values[0]] = '<COMMA>' values[1]
這使您的字典成為:
{'111_0': {'3005': 'QWE',
'3006': 'SDE<COMMA>LFR'},
'111_1': {'3005': 'QWE',
'5345': 'JTR'},
'112_0': {'3103': 'JPP',
'3343': 'PDK'},
'113_0': {'2137': 'TRE<COMMA>OMG'}}
然后在寫入檔案時,您需要將回圈更改為:
for key in values_per_baseline[file]:
contents.insert(x, f'{6*sp}o = {key}\n{10*sp}a = {values_per_baseline[file][key]}\n')
你的檔案現在看起來像:
line
line
line
o = 3006
a = SDE<COMMA>LFR
o = 3005
a = QWE
line
line
line
line
line
你可以做的其他事情
現在,您可以采取一些措施來簡化代碼,同時保持其可讀性。*
- On lines 10 and 11, there is no need to use
line.splittwice. Just add a line that has something likesplit_line = line.split(',')and then havekey = split_line[0]andvalues = split_line[1:]. (You could do away withkeyandvaluesall together and just referencesplit_line[0]andsplit_line[1]but that would make your code less readable. - On line 17, you are defining
xin every loop. Just take it out of the loop. - On lines 12 and 13, you are first using
(f"of_%s.txt" % file)and then defining it in a file on the next line. Suggest you definefilenamefirst and then just haveshutil.copyfile("of.txt", filename). Also, you are using f-strings incorrectly. You could just writefilename = f"of_{file}.txt". - On line 23, you could change your
insertcommand to an f-string (if you find it more readable). For example:contents.insert(x, f'{6*sp}o = {values[0]}\n{10*sp}a = {values[1]}\n') - At the end, in your
for values in values_per_baseline.keys()loop, you are opening and closing files way more than you need to. You can reorder your operations:
with open(filename, "r") as f:
contents = f.readlines()
for values in values_per_baseline[file]:
contents.insert(x, ' o = ' values[0] '\n ' 'a = ' values[1] '\n')
with open(filename, "w") as f:
contents = "".join(contents)
f.write(contents)
f.close()
*For a short script like this, I would argue that making sure it is readable is more important than making sure it is efficient, since you will want to be able to come back in 3 weeks or 3 years and understand what you did. For that reason, I would also recommend you comment what you did.
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/451073.html