我是 Python 的新手,現在我被一個問題困住了幾天。我做了一個腳本:
- 從 CSV 檔案中獲取資料 - 按資料檔案第一列中的相同值對其進行排序 - 在不同模板文本檔案的特定欄位行中插入排序的資料 - 將檔案保存在盡可能多的副本中,因為資料檔案中的第一列中有不同的值下圖顯示了它是如何作業的:
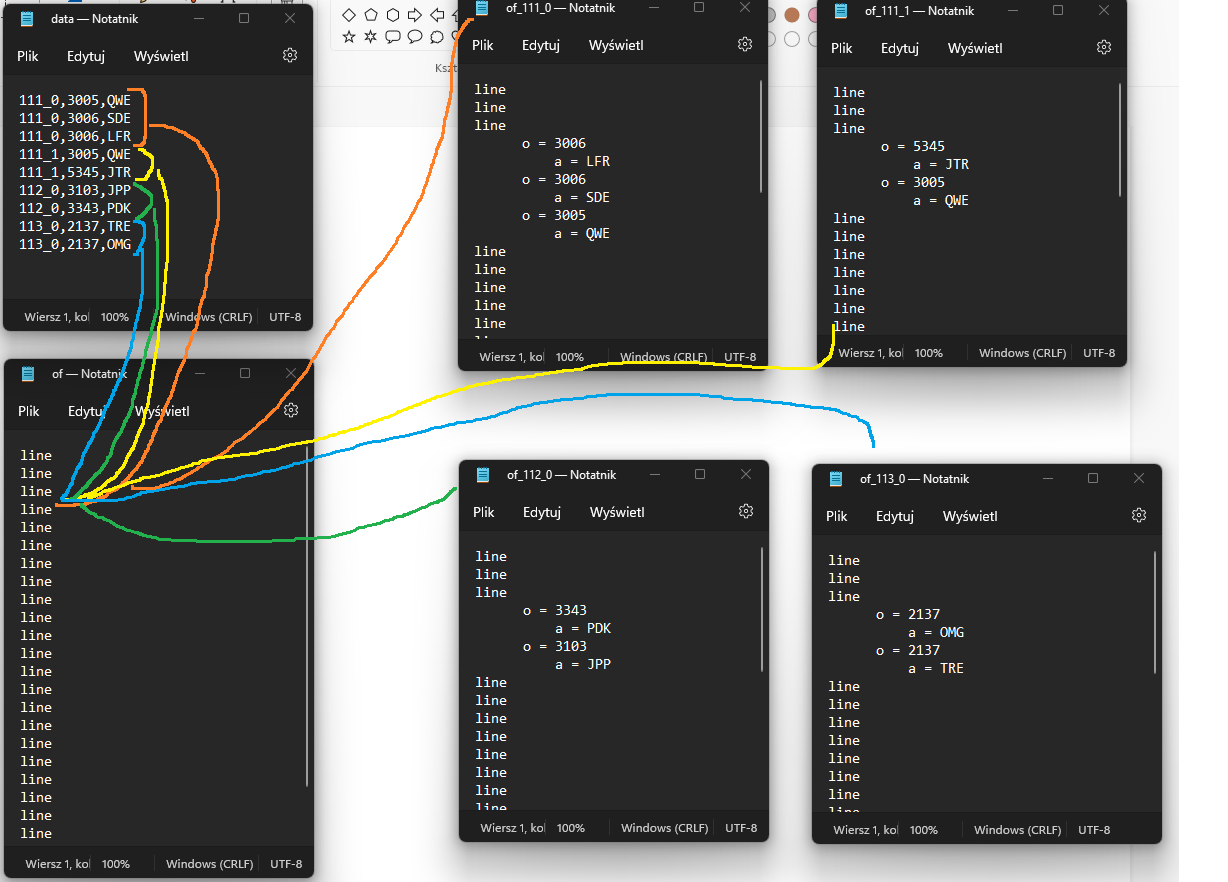
但是我還需要做兩件事。當在如上所示的單獨檔案中時,資料檔案的第二列中有一些相同的值,那么這個檔案應該從第三列插入值,而不是從第二列重復相同的值。在下面的圖片中,我展示了它的外觀:
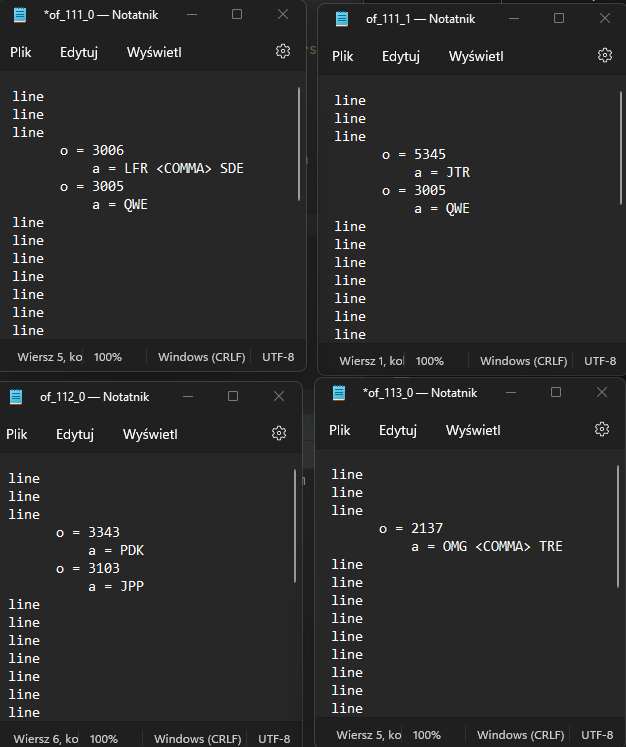
我還需要通過“_”從資料檔案中添加第一列的某處分隔值。
有資料檔案:
111_0,3005,QWE
111_0,3006,SDE
111_0,3006,LFR
111_1,3005,QWE
111_1,5345,JTR
112_0,3103,JPP
112_0,3343,PDK
113_0,2137,TRE
113_0,2137,OMG
我做了代碼:
import shutil
with open("data.csv") as f:
contents = f.read()
contents = contents.splitlines()
values_per_baseline = dict()
for line in contents:
key = line.split(',')[0]
values = line.split(',')[1:]
if key not in values_per_baseline:
values_per_baseline[key] = []
values_per_baseline[key].append(values)
for file in values_per_baseline.keys():
x = 3
shutil.copyfile("of.txt", (f"of_%s.txt" % file))
filename = f"of_%s.txt" % file
for values in values_per_baseline[file]:
with open(filename, "r") as f:
contents = f.readlines()
contents.insert(x, ' o = ' values[0] '\n ' 'a = ' values[1] '\n')
with open(filename, "w") as f:
contents = "".join(contents)
f.write(contents)
f.close()
我一直在嘗試制作類似于串列字典的字典,但我無法以正確的方式實作它以使其正常作業。任何幫助或建議將不勝感激。
uj5u.com熱心網友回復:
您可以嘗試以下方法:
import csv
from collections import defaultdict
values_per_baseline = defaultdict(lambda: defaultdict(list))
with open("data.csv", "r") as file:
for key1, key2, value in csv.reader(file):
values_per_baseline[key1][key2].append(value)
x = 3
for filekey, content in values_per_baseline.items():
with open("of.txt", "r") as fin,\
open(f"of_{filekey}.txt", "w") as fout:
fout.writelines(next(fin) for _ in range(x))
for key, values in content.items():
fout.write(
f' o = {key}\n'
' a = '
' <COMMA> '.join(values)
'\n'
)
fout.writelines(fin)
輸入讀取部分使用csv標準庫中的模塊(為方便起見)和defaultdict. 該檔案被讀入嵌套字典。
uj5u.com熱心網友回復:
內容datafile.csv:
111_0,3005,QWE
111_0,3006,SDE
111_0,3006,LFR
111_1,3005,QWE
111_1,5345,JTR
112_0,3103,JPP
112_0,3343,PDK
113_0,2137,TRE
113_0,2137,OMG
可能的解決方案如下:
def nested_list_to_dict(lst):
result = {}
subgroup = {}
if all(len(l) == 3 for l in lst):
for first, second, third in lst:
result.setdefault(first, []).append((second, third))
for k, v in result.items():
for item1, item2 in v:
subgroup.setdefault(item1, []).append(item2.strip())
result[k] = subgroup
subgroup = {}
else:
print("Input data must have 3 items like '111_0,3005,QWE'")
return result
with open("datafile.csv", "r", encoding="utf-8") as f:
content = f.read().splitlines()
data = nested_list_to_dict([line.split(',') for line in content])
print(data)
# ... rest of your code ....
印刷
{'111_0': {'3005': ['QWE'], '3006': ['SDE', 'LFR']},
'111_1': {'3005': ['QWE'], '5345': ['JTR']},
'112_0': {'3103': ['JPP'], '3343': ['PDK']},
'113_0': {'2137': ['TRE', 'OMG']}}
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/451074.html