本文將展示一種新的時間序列預測方法,
目標資料集
在這個專案中使用的資料是來自北卡羅來納州夏洛特分校的全球能源預測競賽的資料,您可以在這里找到更多資訊:http://www.drhongtao.com/gefcom/2017
你需要知道的是,這些資料是來自能源網路的各種讀數,我們的目標是利用這些資料點預測電網的實時能源需求,資料點還包括露點和干球溫度,因為空調是能源消耗的主力,
我們的目標變數是RTDemand(Real Time energy demand):電網的實時能源需求,資料具有清晰的日周期特征,以下是我們三天的資料:
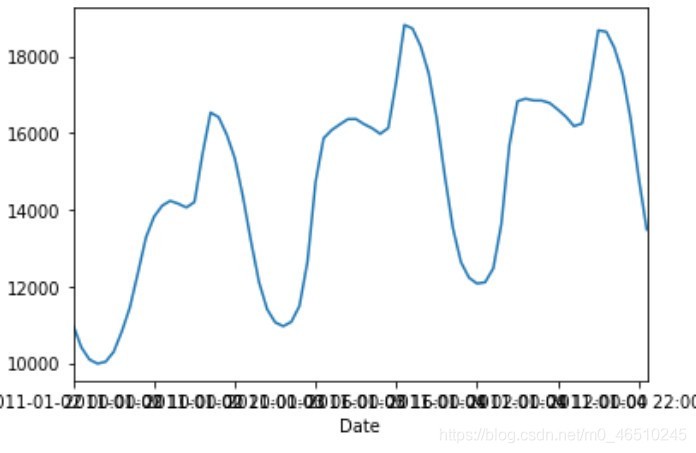
在每個人都在睡覺的半夜里,我們的耗電量達到最低,我們早上醒來,開始作業,當太陽達到峰值強度時,我們的能量消耗達到了最大值,因此可以認為每天的能耗下降與通勤時間相對應,
如果我們再把尺度放大一些,我們可以看到清晰的自相關特性和日趨勢,以下是大約3周的資料:
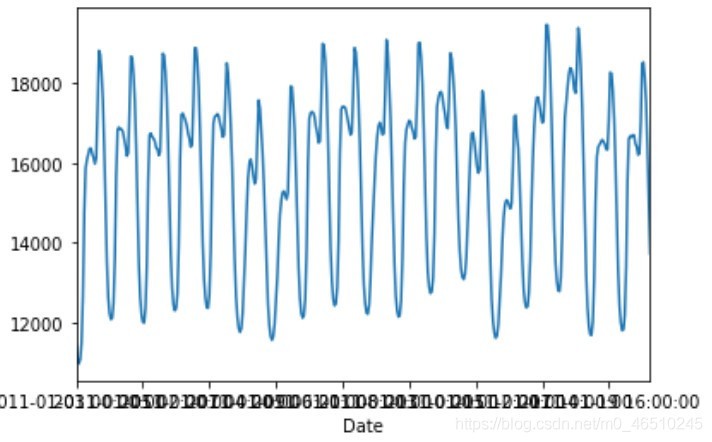
三周內的每小時資料
我們還可以注意到一個更大的季節性趨勢,如果我們進一步縮小并查看一整年的資料:
一年內的每小時資料
由此看見,這是一個相當理想的時間序列資料,可以對其進行預測,
單變數純時間序列預測模型
對于時間序列預測,我們將需要給定一個目標結果的時間序列,在我們的例子中,我選擇72小時作為時間序列的長度,這意味著我們模型的輸入是72個單獨的數字,代表過去72小時的資料,我們希望從模型中得到的目標輸出是它對第73小時的預測,我認為72小時是一個很好的長度,因為它可以很好地捕捉當地的趨勢和晝夜回圈,
以下是我們對模型的輸入(連續三天的資料):
array([
[12055., 11430., 10966., 10725., 10672., 10852., 11255., 11583.,
12238., 12877., 13349., 13510., 13492., 13314., 13156., 13364.,
14632., 15653., 15504., 15088., 14579., 13882., 12931., 11883.,
10978., 10406., 10089., 9982., 10031., 10289., 10818., 11444.,
12346., 13274., 13816., 14103., 14228., 14154., 14055., 14197.,
15453., 16531., 16410., 15954., 15337., 14347., 13178., 12106.,
11400., 11059., 10959., 11073., 11485., 12645., 14725., 15863.,
16076., 16222., 16358., 16362., 16229., 16123., 15976., 16127.,
17359., 18818., 18724., 18269., 17559., 16383., 14881., 13520.],
[11430., 10966., 10725., 10672., 10852., 11255., 11583., 12238.,
12877., 13349., 13510., 13492., 13314., 13156., 13364., 14632.,
15653., 15504., 15088., 14579., 13882., 12931., 11883., 10978.,
10406., 10089., 9982., 10031., 10289., 10818., 11444., 12346.,
13274., 13816., 14103., 14228., 14154., 14055., 14197., 15453.,
16531., 16410., 15954., 15337., 14347., 13178., 12106., 11400.,
11059., 10959., 11073., 11485., 12645., 14725., 15863., 16076.,
16222., 16358., 16362., 16229., 16123., 15976., 16127., 17359.,
18818., 18724., 18269., 17559., 16383., 14881., 13520., 12630.],
[10966., 10725., 10672., 10852., 11255., 11583., 12238., 12877.,
13349., 13510., 13492., 13314., 13156., 13364., 14632., 15653.,
15504., 15088., 14579., 13882., 12931., 11883., 10978., 10406.,
10089., 9982., 10031., 10289., 10818., 11444., 12346., 13274.,
13816., 14103., 14228., 14154., 14055., 14197., 15453., 16531.,
16410., 15954., 15337., 14347., 13178., 12106., 11400., 11059.,
10959., 11073., 11485., 12645., 14725., 15863., 16076., 16222.,
16358., 16362., 16229., 16123., 15976., 16127., 17359., 18818.,
18724., 18269., 17559., 16383., 14881., 13520., 12630., 12223.]
])
輸入陣列中的每一個數字都是RTDemand的讀數:這個特定的發電站每小時需要多少千瓦的電力,每個陣列中都有72個小時的資料,如果你仔細觀察這3個陣列中前8個左右的讀數,你會注意到每一個新的陣列都是一個向前移動了1小時的序列,因此,這72個長度的輸入陣列中的每一個資料都代表了最后72小時對這個能源網實時需求的讀數,
我們需要預測第73小時的需求,所以目標陣列格式如下:
array([[12630.],
[12223.],
[12070.]])
需要注意的是,目標陣列中的第一個資料是輸入陣列中第二個陣列的最后一個資料,目標陣列中的第二個資料是輸入陣列中第三個陣列的最后一個資料,也就是說,我們通過輸入陣列中的第一個陣列來實作對于目標陣列中第一個資料的預測,
資料轉換
一旦我們加載了資料,接下來我們需要將其轉換成一個適當的資料集,用于訓練機器學習模型,首先,縮放所有輸入變數,稍后,我們將討論如何使用資料集的所有12個輸入,但現在將只使用1個變數作為輸入,以便于介紹本文使用的預測方法,本文不會對目標變數Y進行縮放處理,因為它可以使監控模型的進度變得更容易,成本最低,接下來,我們將把資料分為一個訓練集和一個測驗集:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
split = int(0.8 * len(X))
X_train = X[: split - 1]
X_test = X[split:]
y_train = y[: split - 1]
y_test = y[split:]
最后,我們將使用的模型的輸入是(Samples、Timesteps、Features),在第一個模型中,我們只使用時間視窗的目標變數作為輸入,所以,我們只有一個輸入特征Feature,我們的輸入即為(Samples,Timesteps),在進行訓練集和測驗集分割之后,我們現在將對其進行reshape處理:
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], 1))
X_train.shape
(61875, 72, 1)
也就是說,第一個模型的輸入資料為61875個樣本、每個樣本包含有72小時資料以及1個特征,
基線模型
首先,我們建立一個基線模型,我們的優化函式設定為均方誤差/均方根誤差,我們同時也監測R2,不過,如果存在沖突,我們只使用均方誤差作為損失函式和優化目標,
對于基線模型,我們將看到均方誤差和R2的資料情況,這里的基準模型實作的功能是猜測時間序列中先前的值,下面是相關代碼:
# Benchmark model
prev_val = y_test[0]
sse = 0
for n in range(0, len(y_test)-1):
err = y_test[n] — prev_val
sq_err = err ** 2
sse = sse + sq_err
prev_val = y_test[n]
mse = sse / n
mse
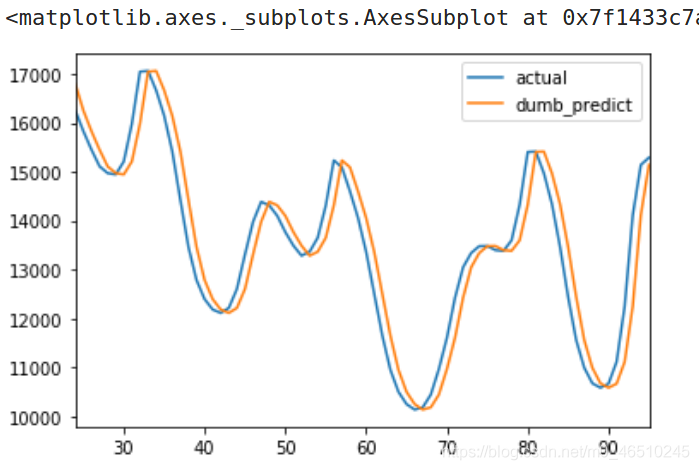
使用我們的測驗資料集,得到的平方根誤差是641.54,也就是說,這個基準模型在給定的一小時內會相對于真實情況相差641.54兆瓦,這是基準模型與實際結果的圖表:
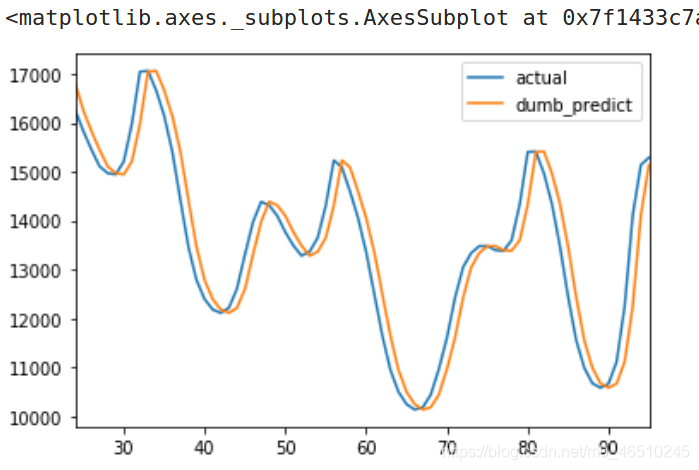
真實資料曲線&基準模型預測曲線
雖然第一個模型很簡單,但是性能上表現出的效果良好,接下來我們嘗試其它的模型方法,
LSTM預測模型
時間序列資料預測常用的模型之一就是LSTM,相對于本文提出的卷積預測模型,它是一個很有意義的對照模型,LSTM預測的相關代碼如下:
def basic_LSTM(window_size=5, n_features=1):
new_model = keras.Sequential()
new_model.add(tf.keras.layers.LSTM(100,
input_shape=(window_size, n_features),
return_sequences=True,
activation=’relu’))
new_model.add(tf.keras.layers.Flatten())
new_model.add(tf.keras.layers.Dense(1500, activation=’relu’))
new_model.add(tf.keras.layers.Dense(100, activation=’linear’))
new_model.add(tf.keras.layers.Dense(1))
new_model.compile(optimizer=”adam”, loss=”mean_squared_error”)
return new_model
ls_model = basic_LSTM(window_size=window_size, n_features=X_train.shape[2])
ls_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 72, 100) 40800
_________________________________________________________________
flatten (Flatten) (None, 7200) 0
_________________________________________________________________
dense (Dense) (None, 1500) 10801500
_________________________________________________________________
dense_1 (Dense) (None, 100) 150100
_________________________________________________________________
dense_2 (Dense) (None, 1) 101
=================================================================
Total params: 10,992,501
Trainable params: 10,992,501
Non-trainable params: 0
通過訓練資料集進行模型訓練,然后通過測驗集進行評價:
ls_model.evaluate(X_test, y_test, verbose=0)
1174830.0587427279
from sklearn.metrics import r2_score
predictions = ls_model.predict(X_test)
test_r2 = r2_score(y_test, predictions)
test_r2
0.8451637094740732
我們得到的結果不是很好,具體地說,我們最終得到的誤差比之前的基準模型更高,下面的圖表可以了解它的預測情況:
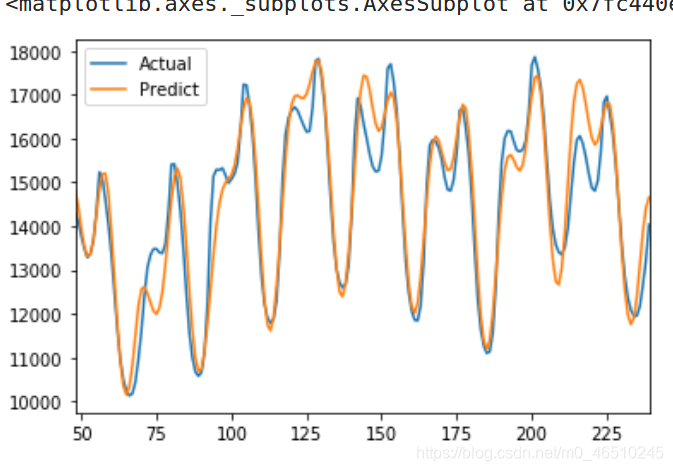
LSTM預測結果
正如上圖所示,LSTM的預測具有較大的不確定性,
1D卷積預測方法
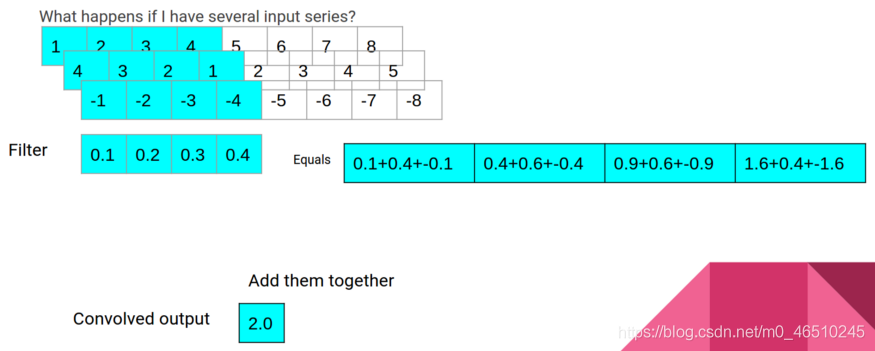
另一種預測時間序列的方法是使用一維卷積模型,1D卷積使用一個過濾視窗并在資料上回圈該視窗以產生新的輸出,根據所學的卷積窗引數,它們可以像移動平均線、方向指示器或模式探測器一樣隨時間變化,

step 1
這里有一個包含8個元素的資料集,過濾器大小為4,過濾器中的四個數字是Conv1D層學習的引數,在第一步中,我們將過濾器的元素乘以輸入資料,并將結果相加以產生卷積輸出,
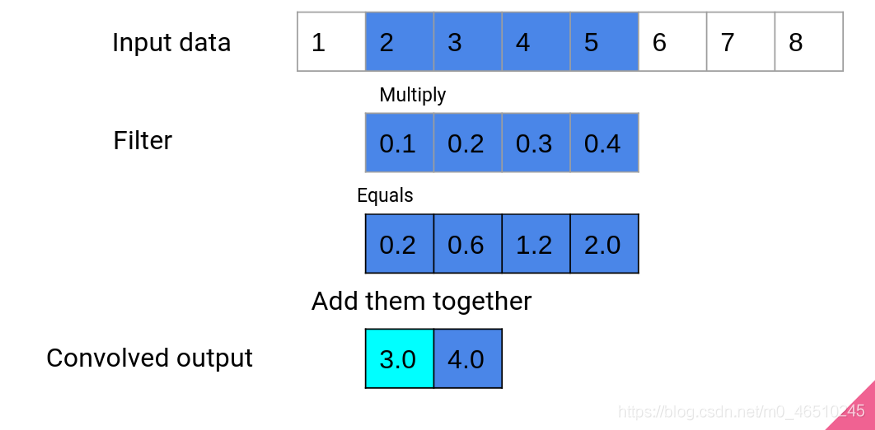
step 2
在卷積的第二步中,視窗向前移動一個,重復相同的程序以產生第二個輸出,
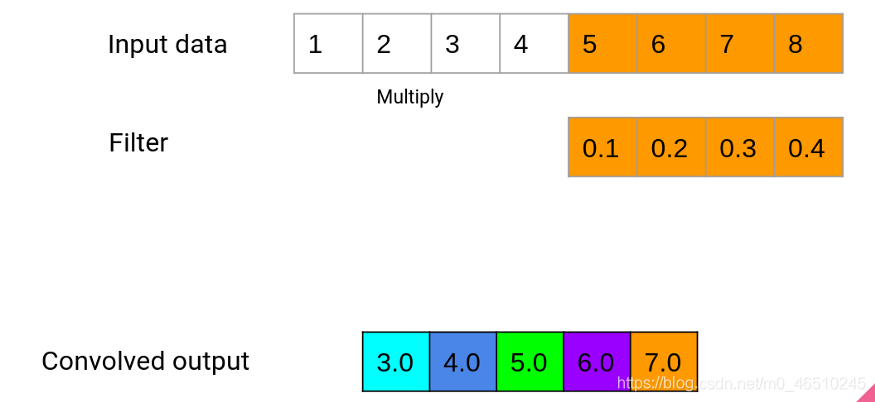
Last step
這個程序一直持續到視窗到達輸入資料的末尾,在我們的例子中,一個輸入資料序列是我們之前設定的72小時的資料,如果我們添加padding=“same”選項,我們的輸入資料將在開始和結束處用零進行填充,以保持輸出長度等于輸入長度,上面的演示使用線性激活,這意味著最后一個多色陣列是我們的輸出,但是,我們可以在這里使用一整套激活函式,這些函式將通過一個額外的步驟來運行這個數字,因此,在下面的例子中,將有一個ReLU激活函式應用于最后的輸出,以產生最終的輸出,
下面展示了建立1D卷積模型的相關代碼:
def basic_conv1D(n_filters=10, fsize=5, window_size=5, n_features=2):
new_model = keras.Sequential()
new_model.add(tf.keras.layers.Conv1D(n_filters, fsize, padding=”same”, activation=”relu”, input_shape=(window_size, n_features)))
# Flatten will take our convolution filters and lay them out end to end so our dense layer can predict based on the outcomes of each
new_model.add(tf.keras.layers.Flatten())
new_model.add(tf.keras.layers.Dense(1800, activation=’relu’))
new_model.add(tf.keras.layers.Dense(100))
new_model.add(tf.keras.layers.Dense(1))
new_model.compile(optimizer=”adam”, loss=”mean_squared_error”)
return new_model
模型情況如下:
univar_model = basic_conv1D(n_filters=24, fsize=8, window_size=window_size, n_features=X_train.shape[2])
univar_model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1d (Conv1D) (None, 72, 24) 216
_________________________________________________________________
flatten_1 (Flatten) (None, 1728) 0
_________________________________________________________________
dense_3 (Dense) (None, 1800) 3112200
_________________________________________________________________
dense_4 (Dense) (None, 100) 180100
_________________________________________________________________
dense_5 (Dense) (None, 1) 101
=================================================================
Total params: 3,292,617
Trainable params: 3,292,617
Non-trainable params: 0
注意,這里有24個卷積視窗,過濾器大小是8,因此,在我們的例子中,輸入資料將是72小時,這將創建一個大小為8的視窗,其中將有24個過濾器,因為我使用padding=“same”,每個過濾器的輸出寬度將是72,就像我們的輸入資料一樣,并且輸出的數量將是24個卷積陣列,最后通過Flatten生成72*24=1728長度的陣列,Flatten的作業程序如下圖所示:
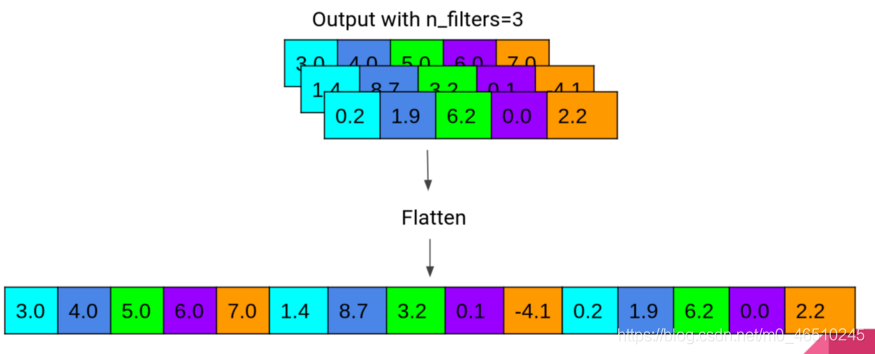
Flatten作業示意圖
對比1D卷積模型、LSTM、基線模型的預測損失如下:
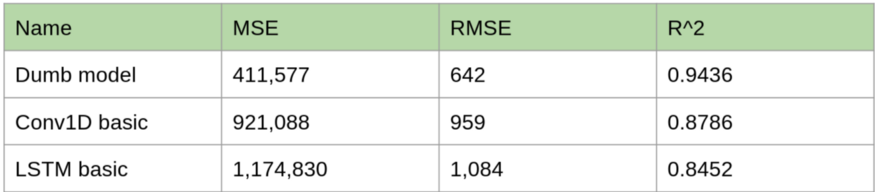
顯然1D卷積方法比LSTM更好一些,但是它仍然沒有達到最初的基準模型更好的效果,當我們看預測效果曲線時,我們可以看到這個模型有明顯的偏差:
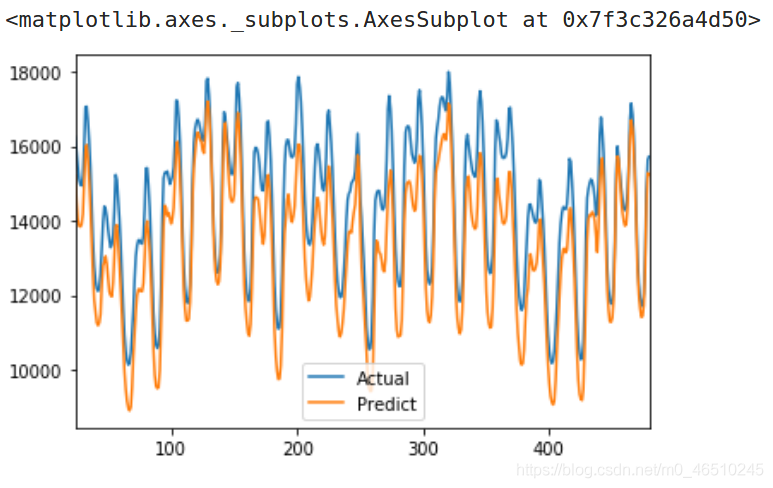
1D卷積預測效果
添加資料維度
在上面的例子中,我們只使用我們想要預測的特性作為我們的輸入變數,然而,我們的資料集有12個可能的輸入變數,我們可以將所有的輸入變數疊加起來,然后一起使用它們來進行預測,由于許多輸入變數與我們的輸出變數具有中等/較強的相關性,因此使用更多的資料進行更好的預測應該是可能的,
多輸入1D卷積
如果我想把一個不同的資料序列疊加到模型中,首先要通過相同的視窗處理程序來生成一組觀測值,每個觀測值都包含變數的最后72個讀數,例如,如果我想在第1列中添加變數DADemand(日前需求,當前前一天的需求),將對其執行以下操作:
(DADemand, _) = window_data(gc_df, window_size, 1, 1)
scaler = StandardScaler()
DADemand = scaler.fit_transform(DADemand)
split = int(0.8 * len(X))
DADemand_train = DADemand[: split — 1]
DADemand_test = DADemand[split:]
DADemand_test.shape
(61875, 72, 1)
然后,可以對所有的12個變數重復這個程序,并將它們堆積成一個單獨的集合,如下所示:
data_train = np.concatenate((X_train, db_train, dew_train, DADemand_train, DALMP_train, DAEC_train, DACC_train, DAMLC_train, RTLMP_train, RTEC_train, RTCC_train, RTMLC_train), axis=2)
data_test = np.concatenate((X_test, db_test, dew_test, DADemand_test, DALMP_test, DAEC_test, DACC_test, DAMLC_test, RTLMP_test, RTEC_test, RTCC_test, RTMLC_test), axis=2)
data_train.shape
(61875, 72, 12)
至此生成了包含61875個樣本、每一個都包含12個不同時間序列的72小時單獨讀數的資料集,我們現在通過一個Conv1D網路來運行它,看看我們得到了什么結果,如果回顧一下我們用于創建這些模型的函式,會注意到其中一個變數是特征feature的數量,因此運行這個新模型的代碼同樣十分簡單,預測誤差結果如下:
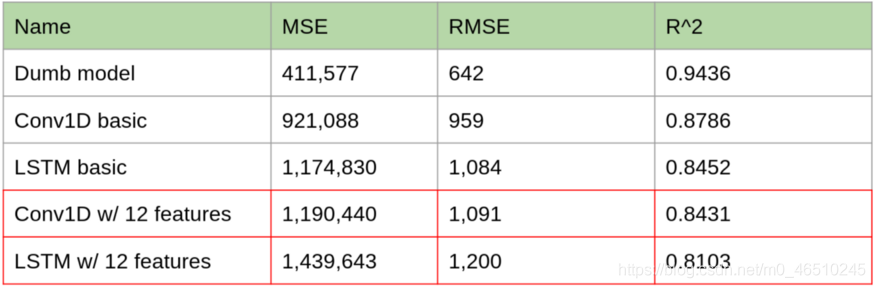
模型的性能實際上隨著其他變數的增加而降低,分析其原因,可能是“模糊”效應(添加更多的資料集往往會“模糊”任何一個特定輸入變化的影響,反而會產生一個不太精確的模型,),
2D卷積
我們實際需要的是一個卷積視窗,它可以查看我們的模型特征并找出哪些特征是有益的,2D卷積可以實作我們想要的效果,
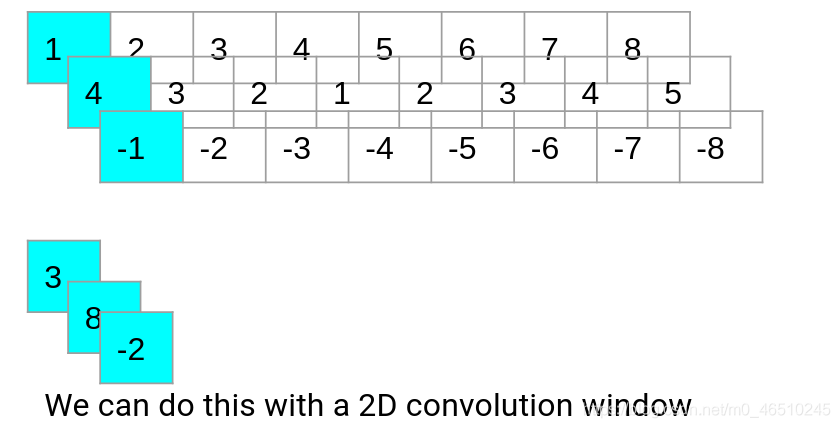
在做了一些嘗試之后,本文將使用(1,filter_size)大小的2D卷積視窗,在上圖中,filter_size=3,回到我們的能源預測問題,我們有12個特點,為了讓它進入二維卷積視窗,我們實際上需要它有4個維度,我們可以通過以下方法得到另一個維度:
data_train_wide = data_train.reshape((data_train.shape[0], data_train.shape[1], data_train.shape[2], 1))
data_test_wide = data_test.reshape((data_test.shape[0], data_test.shape[1], data_test.shape[2], 1))
data_train_wide.shape
(61875, 72, 12, 1)
測驗了不同的視窗尺寸過后,我們發現一次考慮兩個特征效果最好:
def basic_conv2D(n_filters=10, fsize=5, window_size=5, n_features=2):
new_model = keras.Sequential()
new_model.add(tf.keras.layers.Conv2D(n_filters, (1,fsize), padding=”same”, activation=”relu”, input_shape=(window_size, n_features, 1)))
new_model.add(tf.keras.layers.Flatten())
new_model.add(tf.keras.layers.Dense(1000, activation=’relu’))
new_model.add(tf.keras.layers.Dense(100))
new_model.add(tf.keras.layers.Dense(1))
new_model.compile(optimizer=”adam”, loss=”mean_squared_error”)
return new_model
m2 = basic_conv2D(n_filters=24, fsize=2, window_size=window_size, n_features=data_train_wide.shape[2])
m2.summary()
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 72, 12, 24) 72
_________________________________________________________________
flatten_4 (Flatten) (None, 20736) 0
_________________________________________________________________
dense_12 (Dense) (None, 1000) 20737000
_________________________________________________________________
dense_13 (Dense) (None, 100) 100100
_________________________________________________________________
dense_14 (Dense) (None, 1) 101
=================================================================
Total params: 20,837,273
Trainable params: 20,837,273
Non-trainable params: 0
這個模型相當大,在普通CPU上訓練每一個epoch大約需要4分鐘,不過,當它完成后,預測效果如下圖:
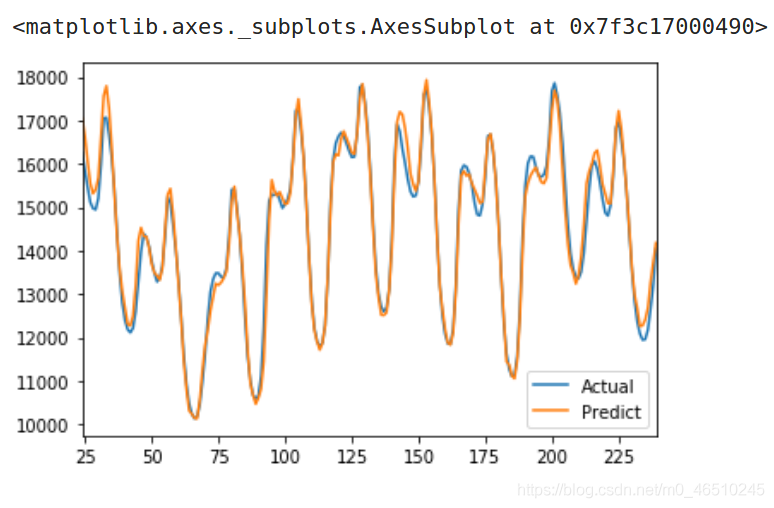
與其他模型對比預測誤差:
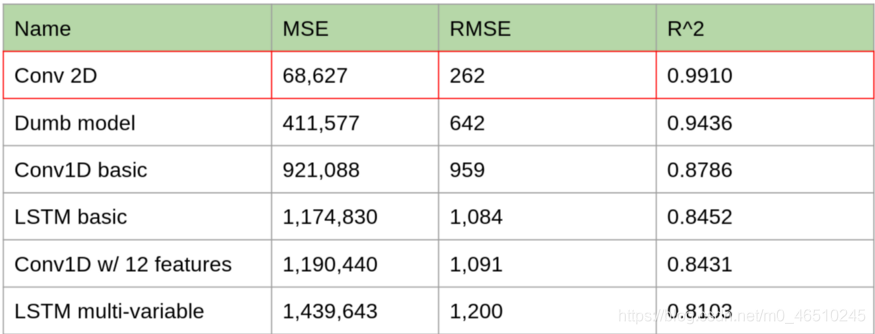
可以看到,2D卷積的效果優于其它所有的預測模型,
補充
如果我們使用類似的想法,但同時用尺寸為(8,1)的濾波器進行卷積運算呢?相關代碼如下:
def deeper_conv2D(n_filters=10, fsize=5, window_size=5, n_features=2, hour_filter=8):
new_model = keras.Sequential()
new_model.add(tf.keras.layers.Conv2D(n_filters, (1,fsize), padding=”same”, activation=”linear”, input_shape=(window_size, n_features, 1)))
new_model.add(tf.keras.layers.Conv2D(n_filters, (hour_filter, 1), padding=”same”, activation=”relu”))
new_model.add(tf.keras.layers.Flatten())
new_model.add(tf.keras.layers.Dense(1000, activation=’relu’))
new_model.add(tf.keras.layers.Dense(100))
new_model.add(tf.keras.layers.Dense(1))
new_model.compile(optimizer=”adam”, loss=”mean_squared_error”)
return new_model
模型預測性能表現很好:
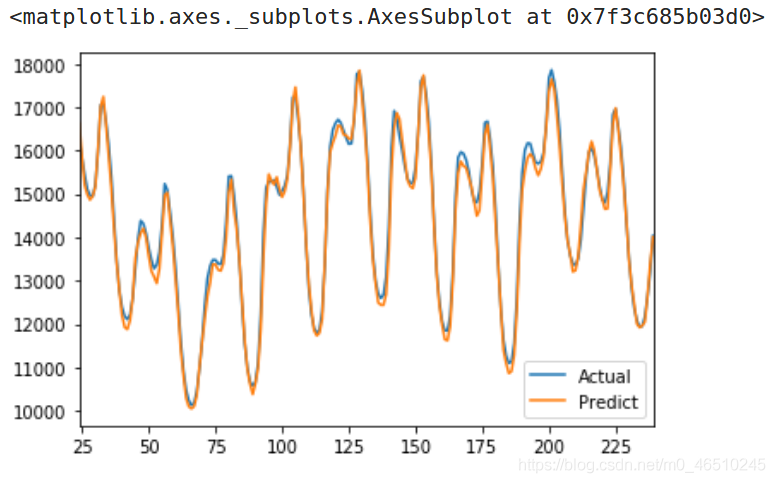
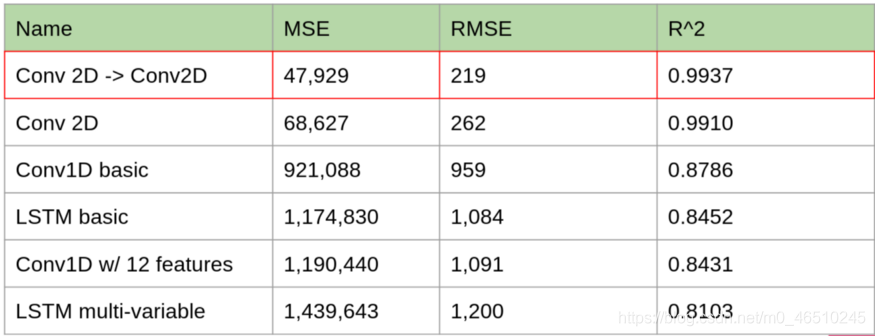
模型預測誤差也進一步降低:
本文所有代碼和資料可以在這里直接下載:
https://github.com/walesdata/2Dconv_pub
作者:Johnny Wales
deephub翻譯組:oliver lee
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/12011.html
標籤:其他