序
特征工程之后,我們基本了解了資料集的概貌,通過缺失值處理、例外值處理、歸一化、獨熱編碼、特征構造等一系列方法對資料進行了預處理,并根據不同模型的資料要求對資料進行了一定的轉化,從而進行下一步模型的學習程序,以下就是對資料進行處理后,訓練模型的程序代碼,其實可以先使用隨機森林等方法先做一步特征篩選的作業,我這里沒有做特征的篩選,而且先復現了資料準備,模型構造和調參的程序,若是模型初步表現不錯且較穩定,我會后續做特征篩選或特征構造,進一步提高模型的分數,
資料準備
匯入第三方庫
import pandas as pd
import numpy as np
import lightgbm as lgb
import warnings
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.model_selection import KFold, train_test_split, cross_val_score, GridSearchCV, StratifiedKFold
from sklearn.metrics import roc_auc_score
from bayes_opt import BayesianOptimization
import datetime
import pickle
import seaborn as sns
'''
sns 相關設定
@return:
"""
# 宣告使用 Seaborn 樣式
sns.set()
# 有五種seaborn的繪圖風格,它們分別是:darkgrid, whitegrid, dark, white, ticks,默認的主題是darkgrid,
sns.set_style("whitegrid")
# 有四個預置的環境,按大小從小到大排列分別為:paper, notebook, talk, poster,其中,notebook是默認的,
sns.set_context('talk')
# 中文字體設定-黑體
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解決保存影像是負號'-'顯示為方塊的問題
plt.rcParams['axes.unicode_minus'] = False
# 解決Seaborn中文顯示問題并調整字體大小
sns.set(font='SimHei')
'''
warnings.filterwarnings('ignore')
pd.options.display.max_columns = None
pd.set_option('display.float_format', lambda x: '%.2f' % x)
讀取資料
train = pd.read_csv(r'D:\Users\Felixteng\Documents\Pycharm Files\loanDefaultForecast\data\train.csv')
testA = pd.read_csv(r'D:\Users\Felixteng\Documents\Pycharm Files\loanDefaultForecast\data\testA.csv')
壓縮資料
def reduce_mem_usage(df):
'''
遍歷DataFrame的所有列并修改它們的資料型別以減少記憶體使用
:param df: 需要處理的資料集
:return:
'''
start_mem = df.memory_usage().sum() / 1024 ** 2 # 記錄原資料的記憶體大小
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtypes
if col_type != object: # 這里只過濾了object格式,如果代碼中還包含其他型別,要一并過濾
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int': # 如果是int型別的話,不管是int64還是int32,都加入判斷
# 依次嘗試轉化成in8,in16,in32,in64型別,如果資料大小沒溢位,那么轉化
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else: # 不是整形的話,那就是浮點型
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else: # 如果不是數值型的話,轉化成category型別
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024 ** 2 # 看一下轉化后的資料的記憶體大小
print('Memory usage after optimization is {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem)) # 看一下壓縮比例
return df
train = reduce_mem_usage(train)
testA = reduce_mem_usage(testA)
del testA['n2.2']
del testA['n2.3']
簡單建模
'''
Tips1:金融風控的實際專案多涉及到信用評分,因此需要模型特征具有較好的可解釋性,所以目前在實際專案中多還是以邏輯回歸作為基礎模型,
但是在比賽中以得分高低為準,不需要嚴謹的可解釋性,所以大多基于集成演算法進行建模,
Tips2:因為邏輯回歸的演算法特性,需要提前對例外值、缺失值資料進行處理(參考task3部分)
Tips3:基于樹模型的演算法特性,例外值、缺失值處理可以跳過,但是對于業務較為了解的同學也可以自己對缺失例外值進行處理,效果可能會更優于模型處理的結果,
注:以下建模的源資料參考baseline進行了相應的特征工程,對于例外缺失值未進行相應的處理操作
'''
建模之前的資料處理
為了方便起見,把訓練集和測驗集合并處理
data = pd.concat([train, testA], axis=0, ignore_index=True)
category特征不能直接訓練,需要處理轉換
'''
['grade', 'subGrade', 'employmentLength', 'issueDate', 'earliesCreditLine']
先處理'employmentLength', 'issueDate', 'earliesCreditLine'這三個特征;'grade'和'subGrade'做one-hot編碼
'''
‘employmentLength’ - 轉換為數值
data.groupby('employmentLength')['id'].count()
'''10年以上算10年,1年一下算0年'''
data['employmentLength'].replace(to_replace='10+ years', value='10 years', inplace=True)
data['employmentLength'].replace(to_replace='< 1 year', value='0 year', inplace=True)
def employmentLength_to_int(s):
if pd.isnull(s):
return s
else:
return np.int8(s.split()[0])
data['employmentLength'] = data['employmentLength'].apply(employmentLength_to_int)
‘earliesCreditLine’ - 分別提取年份和月份做拼接
data['earliesCreditLine_year'] = data['earliesCreditLine'].apply(lambda x: x[-4:])
data['earliesCreditLine_month'] = data['earliesCreditLine'].apply(lambda x: x[0:3])
def month_re(x):
if x == 'Jan':
return '01'
elif x == 'Feb':
return '02'
elif x == 'Mar':
return '03'
elif x == 'Apr':
return '04'
elif x == 'May':
return '05'
elif x == 'Jun':
return '06'
elif x == 'Jul':
return '07'
elif x == 'Aug':
return '08'
elif x == 'Sep':
return '09'
elif x == 'Oct':
return '10'
elif x == 'Nov':
return '11'
else:
return '12'
data['earliesCreditLine_month'] = data['earliesCreditLine_month'].apply(lambda x: month_re(x))
data['earliesCreditLine_date'] = data['earliesCreditLine_year'] + data['earliesCreditLine_month']
data['earliesCreditLine_date'] = data['earliesCreditLine_date'].astype('int')
del data['earliesCreditLine']
del data['earliesCreditLine_year']
del data['earliesCreditLine_month']
‘issueDate’ - 從資料可以看出,issueDate從2017年6月1日開始;資料按照此節點統計天數
data['issueDate'] = pd.to_datetime(data['issueDate'], format='%Y-%m-%d')
startdate = datetime.datetime.strptime('2007-06-01', '%Y-%m-%d')
data['issueDateDt'] = data['issueDate'].apply(lambda x: x - startdate).dt.days
del data['issueDate']
除了本身是category型別的特征,還有一些數值特征表現出的也是類別型的
'''將1類以上且非高維稀疏的特征進行one-hot編碼'''
cate_features = ['grade', 'subGrade', 'employmentTitle', 'homeOwnership', 'verificationStatus', 'purpose',
'postCode', 'regionCode', 'applicationType', 'initialListStatus', 'title', 'policyCode']
for cate in cate_features:
print(cate, '型別數', data[cate].nunique())
'''
grade 型別數 7
subGrade 型別數 35
employmentTitle 型別數 298101
homeOwnership 型別數 6
verificationStatus 型別數 3
purpose 型別數 14
postCode 型別數 935
regionCode 型別數 51
applicationType 型別數 2
initialListStatus 型別數 2
title 型別數 6712
policyCode 型別數 1
不適合做one-hot編碼的是
employmentTitle 型別數 298101
postCode 型別數 935
title 型別數 6712
regionCode 型別數 51 - 大于50的先不處理了,維度還是比較高的
policyCode 型別數 1 - 無分析價值,可直接洗掉
'''
del data['policyCode']
one-hot編碼
data = pd.get_dummies(data, columns=['grade', 'subGrade', 'homeOwnership', 'verificationStatus',
'purpose', 'applicationType', 'initialListStatus'], drop_first=True)
對于高維類別特征,進行轉換,取他們同型別的數量值和排名值
for f in ['employmentTitle', 'postCode', 'regionCode', 'title']:
data[f + '_counts'] = data.groupby([f])['id'].transform('count')
data[f + '_rank'] = data.groupby([f])['id'].rank(ascending=False).astype(int)
del data[f]
準備訓練集和測驗集
features = [f for f in data.columns if f not in ['id', 'isDefault']]
train = data[data.isDefault.notnull()].reset_index(drop=True)
testA = data[data.isDefault.isnull()].reset_index(drop=True)
x_train = train[features]
y_train = train['isDefault']
x_testA = testA[features]
五折交叉驗證準備
folds = 5
seed = 2020
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
建模 - Lightgbm
將訓練集分為5份,4份作為訓練集,1份作為驗證集
X_train_split, X_val, y_train_split, y_val = train_test_split(x_train, y_train, test_size=0.2)
將資料集轉化成能用于lgb訓練的形式
train_split_matrix = lgb.Dataset(X_train_split, label=y_train_split)
val_matrix = lgb.Dataset(X_val, label=y_val)
初步自定義lgb引數
params = {
'boosting_type': 'gbdt', 'objective': 'binary', 'learning_rate': 0.1, 'metric': 'auc', 'min_child_weight': 1e-3,
'num_leaves': 31, 'max_depth': -1, 'reg_lambda': 0, 'reg_alpha': 0, 'feature_fraction': 1, 'bagging_fraction': 1,
'bagging_freq': 0, 'seed': 2020, 'nthread': 8, 'verbose': -1
}
將訓練集丟入lgb模型訓練
model = lgb.train(params, train_set=train_split_matrix, valid_sets=val_matrix, num_boost_round=20000,
verbose_eval=1000, early_stopping_rounds=200)
'''
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[419] valid_0's auc: 0.735017
'''
用訓練好的模型預測驗證集
val_pre_lgb = model.predict(X_val, num_iteration=model.best_iteration)
計算roc的相關指標
'''
真正類率(True Positive Rate)TPR: TP / (TP + FN),代表分類器預測的正類中實際正實體占所有正實體的比例
縱軸TPR:TPR越大,預測正類中實際正類越多
負正類率(False Positive Rate)FPR: FP / (FP + TN),代表分類器預測的正類中實際負實體占所有負實體的比例
橫軸FPR:FPR越大,預測正類中實際負類越多
理想目標:TPR=1,FPR=0,即roc圖中的(0,1)點,故ROC曲線越靠攏(0,1)點,越偏離45度對角線越好,Sensitivity、Specificity越大效果越好
'''
fpr, tpr, threshold = metrics.roc_curve(y_val, val_pre_lgb)
roc_auc = metrics.auc(fpr, tpr)
print('未調參前lgb在驗證集上的AUC: {}'.format(roc_auc))
'''未調參前lgb在驗證集上的AUC: 0.7350165705811689'''
畫出roc曲線
plt.figure(figsize=(8, 8))
plt.title('Val ROC')
plt.plot(fpr, tpr, 'b', label='Val AUC = %0.4f' % roc_auc) # 保留四位小數
plt.ylim(0, 1)
plt.xlim(0, 1)
plt.legend(loc='best')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.plot([0, 1], [0, 1], 'r--') # 對角線
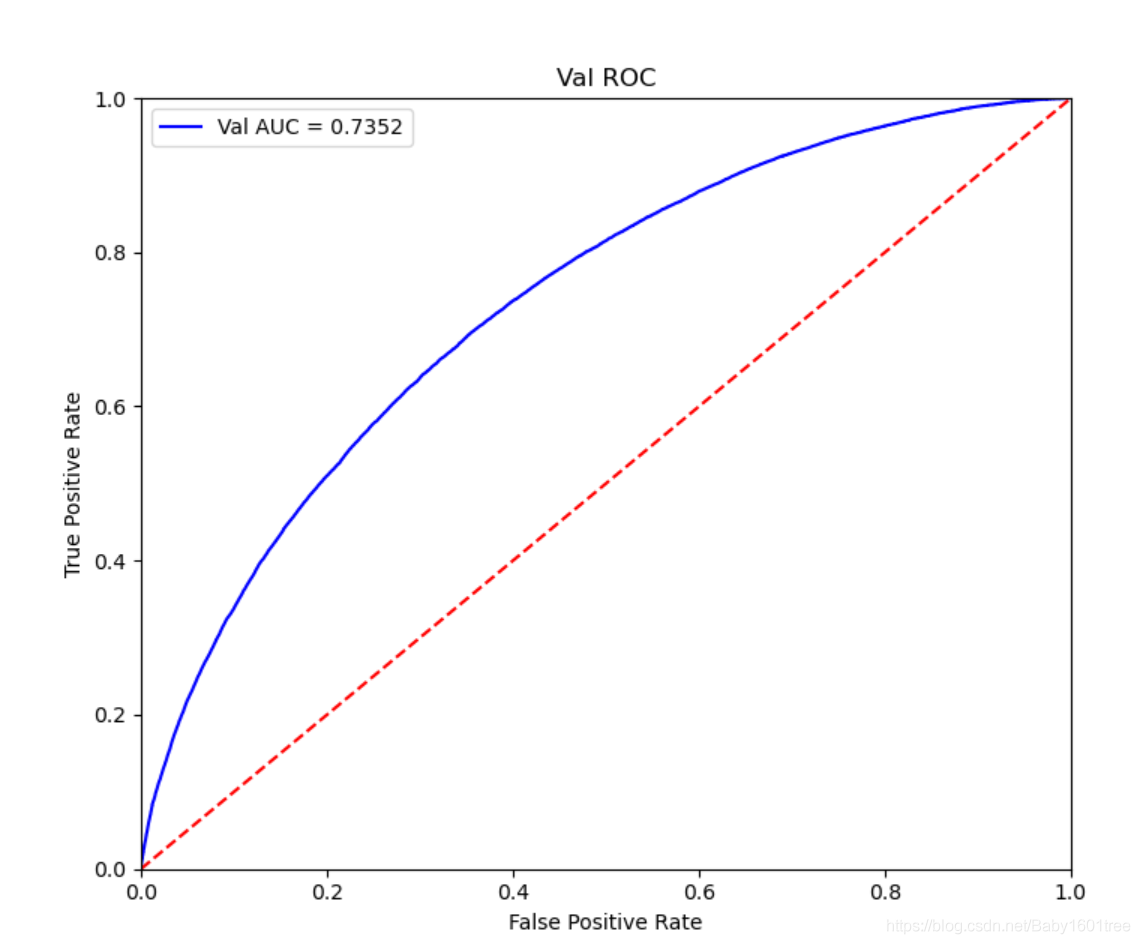
使用5折交叉驗證進行模型性能評估
cv_scores = [] # 用于存放每次驗證的得分
# ## 五折交叉驗證評估模型
for i, (train_index, val_index) in enumerate(kf.split(x_train, y_train)):
print('*** {} ***'.format(str(i+1)))
X_train_split, y_train_split, X_val, y_val = x_train.iloc[train_index], y_train[train_index], \
x_train.iloc[val_index], y_train[val_index]
'''劃分訓練集和驗證集'''
train_matrix = lgb.Dataset(X_train_split, label=y_train_split)
val_matrix = lgb.Dataset(X_val, label=y_val)
'''轉換成lgb訓練的資料形式'''
params = {
'boosting_type': 'gbdt', 'objective': 'binary', 'learning_rate': 0.1, 'metric': 'auc', 'min_child_weight': 1e-3,
'num_leaves': 31, 'max_depth': -1, 'reg_lambda': 0, 'reg_alpha': 0, 'feature_fraction': 1,
'bagging_fraction': 1,
'bagging_freq': 0, 'seed': 2020, 'nthread': 8, 'verbose': -1
}
'''給定lgb引數'''
model = lgb.train(params, train_set=train_matrix, num_boost_round=20000, valid_sets=val_matrix, verbose_eval=1000,
early_stopping_rounds=200)
'''訓練模型'''
val_pre_lgb = model.predict(X_val, num_iteration=model.best_iteration)
'''預測驗證集結果'''
cv_scores.append(roc_auc_score(y_val, val_pre_lgb))
'''將auc加入串列'''
print(cv_scores)
'''
*** 1 ***
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[480] valid_0's auc: 0.735706
[0.7357056028032594]
*** 2 ***
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[394] valid_0's auc: 0.732804
[0.7357056028032594, 0.7328044319912592]
*** 3 ***
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[469] valid_0's auc: 0.736296
[0.7357056028032594, 0.7328044319912592, 0.736295686606251]
*** 4 ***
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[480] valid_0's auc: 0.735153
[0.7357056028032594, 0.7328044319912592, 0.736295686606251, 0.7351530881059898]
*** 5 ***
Training until validation scores don't improve for 200 rounds
Early stopping, best iteration is:
[481] valid_0's auc: 0.734523
[0.7357056028032594, 0.7328044319912592, 0.736295686606251, 0.7351530881059898, 0.7345226943030314]
'''
調參
貪心調參
先使用當前對模型影響最大的引數進行調優,達到當前引數下的模型最優化,再使用對模型影響次之的引數進行調優,如此下去,直到所有的引數調整完畢,
這個方法的缺點就是可能會調到區域最優而不是全域最優,但是只需要一步一步的進行引數最優化除錯即可,容易理解,
需要注意的是在樹模型中引數調整的順序,也就是各個引數對模型的影響程度,列舉一下日常調參程序中常用的引數和調參順序:
max_depth、num_leaves
min_data_in_leaf、min_child_weight
bagging_fraction、 feature_fraction、bagging_freq
reg_lambda、reg_alpha
min_split_gain
objective
best_obj = dict()
objective = ['regression', 'regression_l2', 'regression_l1', 'huber', 'fair', 'poisson',
'binary', 'lambdarank', 'multiclass']
for obj in objective:
model = lgb.LGBMRegressor(objective=obj)
score = cross_val_score(model, x_train, y_train, cv=5, scoring='roc_auc').mean()
best_obj[obj] = score
'''針對每種學習目標引數,分別把5次交叉驗證的結果取平均值放入字典'''
'''
{'regression': 0.7317571771311902, 'regression_l2': 0.7317571771311902, 'regression_l1': 0.5254673662915372,
'huber': 0.7317930010205694, 'fair': 0.7299013530452948, 'poisson': 0.7276315321558192,
'binary': 0.7325703837580402, 'lambdarank': nan, 'multiclass': nan}
分數最高的objective是'binary': 0.7325703837580402
'''
max_depth
best_depth = dict()
max_depth = [4, 6, 8, 10, 12]
for depth in max_depth:
model = lgb.LGBMRegressor(objective='binary', max_depth=depth)
score = cross_val_score(model, x_train, y_train, cv=5, scoring='roc_auc').mean()
best_depth[depth] = score
'''
{4: 0.7289917272476384, 6: 0.7318582290988798, 8: 0.7326689825432566,
10: 0.7327216337284277, 12: 0.7326861296973519}
分數最高的depth是 10: 0.7327216337284277
'''
num_leaves - 為了防止過擬合,num_leaves要小于2max_depth(210=1024)
best_leaves = dict()
num_leaves = [60, 80, 100, 120, 140, 160, 180, 200]
for leaf in num_leaves:
model = lgb.LGBMRegressor(objective='binary', max_depth=10, num_leaves=leaf)
score = cross_val_score(model, x_train, y_train, cv=5, scoring='roc_auc').mean()
best_leaves[leaf] = score
'''
{60: 0.7338063124202595, 80: 0.7340086888735147, 100: 0.7340517113255459, 120: 0.7339504337283304,
140: 0.733943621732856, 160: 0.7340382165600425, 180: 0.7335684540056998, 200: 0.7331373764276772}
分數最高的num_leaves是 num_leaves 100: 0.7340517113255459
'''
min_data_in_leaf
best_min_leaves = dict()
min_data_in_leaf = [14, 18, 22, 26, 30, 34]
for min_leaf in min_data_in_leaf:
model = lgb.LGBMRegressor(objective='binary', max_depth=10, num_leaves=100, min_data_in_leaf=min_leaf)
score = cross_val_score(model, x_train, y_train, cv=5, scoring='roc_auc').mean()
best_min_leaves[min_leaf] = score
'''
{14: 0.7338644336034048, 18: 0.7340150561766138, 22: 0.7340158598138881, 26: 0.7341871752335695,
30: 0.7340615684229571, 34: 0.7340519101378781}
分數最高的 min_leaf是 26: 0.7341871752335695
'''
min_child_weight
best_weight = dict()
min_child_weight = [0.002, 0.004, 0.006, 0.008, 0.010, 0.012]
for min_weight in min_child_weight:
model = lgb.LGBMRegressor(objective='binary', max_depth=10, num_leaves=100, min_data_in_leaf=26,
min_child_weight=min_weight)
score = cross_val_score(model, x_train, y_train, cv=5, scoring='roc_auc').mean()
best_weight[min_weight] = score
'''
{0.002: 0.7341871752335695, 0.004: 0.7341871752335695, 0.006: 0.7341871752335695, 0.008: 0.7341871752335695,
0.01: 0.7341871752335695, 0.012: 0.7341871752335695}
都一樣,說明min_data_in_leaf和min_child_weight應該是對應的?
'''
bagging_fraction + bagging_freq
'''
bagging_fraction+bagging_freq引數必須同時設定,bagging_fraction相當于subsample樣本采樣,可以使bagging更快的運行,同時也可以降擬合,
bagging_freq默認0,表示bagging的頻率,0意味著沒有使用bagging,k意味著每k輪迭代進行一次bagging
'''
best_bagging_fraction = dict()
bagging_fraction = [0.5, 0.6, 0.7, 0.8, 0.9, 0.95]
for bagging in bagging_fraction:
model = lgb.LGBMRegressor(objective='binary', max_depth=10, num_leaves=100, min_data_in_leaf=26,
bagging_fraction=bagging)
score = cross_val_score(model, x_train, y_train, cv=5, scoring='roc_auc').mean()
best_bagging_fraction[bagging] = score
'''
{0.5: 0.7341871752335695, 0.6: 0.734187175233
5695, 0.7: 0.7341871752335695, 0.8: 0.7341871752335695, 0.9: 0.7341871752335695, 0.95: 0.7341871752335695}
沒變化
'''
feature_fraction
best_feature_fraction = dict()
feature_fraction = [0.5, 0.6, 0.7, 0.8, 0.9, 0.95]
for feature in feature_fraction:
model = lgb.LGBMRegressor(objective='binary', max_depth=10, num_leaves=100, min_data_in_leaf=26,
feature_fraction=feature)
score = cross_val_score(model, x_train, y_train, cv=5, scoring='roc_auc').mean()
best_feature_fraction[feature] = score
'''
{0.5: 0.7341332691040499, 0.6: 0.7342461204659492, 0.7: 0.7340950793860553, 0.8: 0.734168394330798,
0.9: 0.7342417001187209, 0.95: 0.7340419425131396}
雖然0.6會高一些,但是出于樣本特征的使用率我還是想用0.9
'''
reg_lambda
best_reg_lambda = dict()
reg_lambda = [0, 0.001, 0.01, 0.03, 0.08, 0.3, 0.5]
for lam in reg_lambda:
model = lgb.LGBMRegressor(objective='binary', max_depth=10, num_leaves=100, min_data_in_leaf=26,
feature_fraction=0.9, reg_lambda=lam)
score = cross_val_score(model, x_train, y_train, cv=5, scoring='roc_auc').mean()
best_reg_lambda[lam] = score
'''
{0: 0.7342417001187209, 0.001: 0.7340521878374329, 0.01: 0.7342087379791171,
0.03: 0.7342072587501143, 0.08: 0.7341178131960189, 0.3: 0.7342923823693306, 0.5: 0.7342815855243002}
reg_lambda 最優值為 0.3: 0.7342923823693306
'''
reg_alpha
best_reg_alpha = dict()
reg_alpha = [0, 0.001, 0.01, 0.03, 0.08, 0.3, 0.5]
for alp in reg_alpha:
model = lgb.LGBMRegressor(objective='binary', max_depth=10, num_leaves=100, min_data_in_leaf=26,
feature_fraction=0.9, reg_lambda=0.3, reg_alpha=alp)
score = cross_val_score(model, x_train, y_train, cv=5, scoring='roc_auc').mean()
best_reg_alpha[alp] = score
'''
{0: 0.7342923823693306, 0.001: 0.7342141300723407, 0.01: 0.7342716599336013, 0.03: 0.7342356374031566,
0.08: 0.7342509380457417, 0.3: 0.7341836259662214, 0.5: 0.7342654379571296}
reg_alpha 為0時最高
'''
learning_rate
best_learning_rate = dict()
learning_rate = [0.01, 0.05, 0.08, 0.1, 0.12]
for learn in learning_rate:
model = lgb.LGBMRegressor(objective='binary', max_depth=10, num_leaves=100, min_data_in_leaf=26,
feature_fraction=0.9, reg_lambda=0.3, learning_rate=learn)
score = cross_val_score(model, x_train, y_train, cv=5, scoring='roc_auc').mean()
best_learning_rate[learn] = score
'''
{0.01: 0.719100817422237, 0.05: 0.7315198412233572, 0.08: 0.733713956417723, 0.1: 0.7342923823693306,
0.12: 0.7341688215024998}
learning_rate 為0.1時最好
'''
網格調參
網格調參+五折交叉驗證非常非常非常耗時,建議開始步長選大一點,我步長較小,導致調參耗時非常可怕
'''
sklearn 提供GridSearchCV用于進行網格搜索,只需要把模型的引數輸進去,就能給出最優化的結果和引數,
相比起貪心調參,網格搜索的結果會更優,但是網格搜索只適合于小資料集,一旦資料的量級上去了,很難得出結果
'''
def get_best_cv_params(learning_rate=0.1, n_estimators=800, num_leaves=100, max_depth=10, feature_fraction=0.9,
min_data_in_leaf=26, reg_lambda=0.3, reg_alpha=0, objective='binary', param_grid=None):
cv_fold = StratifiedKFold(n_splits=5, random_state=2020, shuffle=True)
'''設定五折交叉驗證'''
model_lgb = lgb.LGBMRegressor(learning_rate=learning_rate, n_estimators=n_estimators, num_leaves=num_leaves,
max_depth=max_depth, feature_fraction=feature_fraction,
min_data_in_leaf=min_data_in_leaf, reg_lambda=reg_lambda, reg_alpha=reg_alpha,
objective=objective, n_jobs=-1)
grid_search = GridSearchCV(estimator=model_lgb, cv=cv_fold, param_grid=param_grid, scoring='roc_auc')
grid_search.fit(x_train, y_train)
print('模型當前最優引數為: {}'.format(grid_search.best_params_))
print('模型當前最優得分為: {}'.format(grid_search.best_score_))
先調 max_depth和 num_leaves
lgb_params = {'num_leaves': range(80, 120, 5), 'max_depth': range(6, 14, 2)}
get_best_cv_params(param_grid=lgb_params)
'''
模型當前最優引數為: {'max_depth': 6, 'num_leaves': 80}
模型當前最優得分為: 0.7349883936428184
'''
min_data_in_leaf和min_child_weight
lgb_params = {'min_data_in_leaf': range(20, 60, 5)}
get_best_cv_params(param_grid=lgb_params, max_depth=6, num_leaves=80)
'''
模型當前最優引數為: {'min_data_in_leaf': 45}
模型當前最優得分為: 0.7352238437118113
'''
feature_fraction
lgb_params = {'feature_fraction': [i / 10 for i in range(5, 10, 1)]}
get_best_cv_params(param_grid=lgb_params, max_depth=6, num_leaves=80, min_data_in_leaf=45)
'''
模型當前最優引數為: {'feature_fraction': 0.5}
模型當前最優得分為: 0.7357516064800039
'''
reg_lambda 和 reg_alpha
lgb_params = {'reg_alpha': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6], 'reg_lambda': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6]}
get_best_cv_params(param_grid=lgb_params, max_depth=6, num_leaves=80, min_data_in_leaf=45, feature_fraction=0.5, )
'''
模型當前最優引數為: {'reg_alpha': 0.5, 'reg_lambda': 0.4}
模型當前最優得分為: 0.7358840540809432
'''
總之,看似每一個引數的選擇非常簡短快速,實際調參程序非常漫長,建議增大步長縮小范圍以后再精細調參,
貝葉斯調參
'''
貝葉斯優化是一種用模型找到函式最小值方法
貝葉斯方法與隨機或網格搜索的不同之處在于:它在嘗試下一組超引數時,會參考之前的評估結果,因此可以省去很多無用功
貝葉斯調參法使用不斷更新的概率模型,通過推斷過去的結果來'集中'有希望的超引數
貝葉斯優化問題的四個部分
1.目標函式 - 機器學習模型使用該組超引數在驗證集上的損失
它的輸入為一組超引數,輸出需要最小化的值(交叉驗證損失)
2.域空間 - 要搜索的超引數的取值范圍
在搜索的每次迭代中,貝葉斯優化演算法將從域空間為每個超引數選擇一個值
當我們進行隨機或網格搜索時,域空間是一個網格
而在貝葉斯優化中,不是按照順序()網格)或者隨機選擇一個超引數,而是按照每個超引數的概率分布選擇
3.優化演算法 - 構造替代函式并選擇下一個超引數值進行評估的方法
4.來自目標函式評估的存盤結果,包括超引數和驗證集上的損失
'''
定義目標函式,我們要這個目標函式輸出的值最大
def rf_cv_lgb(num_leaves, max_depth, bagging_fraction, feature_fraction, bagging_freq, min_data_in_leaf,
min_child_weight, min_split_gain, reg_lambda, reg_alpha):
val = cross_val_score(
lgb.LGBMRegressor(
boosting_type='gbdt', objective='binary', metrics='auc', learning_rate=0.1, n_estimators=5000,
num_leaves=int(num_leaves), max_depth=int(max_depth), bagging_fraction=round(bagging_fraction, 2),
feature_fraction=round(feature_fraction, 2), bagging_freq=int(bagging_freq),
min_data_in_leaf=int(min_data_in_leaf), min_child_weight=min_child_weight,
min_split_gain=min_split_gain, reg_lambda=reg_lambda, reg_alpha=reg_alpha, n_jobs=-1
), x_train, y_train, cv=5, scoring='roc_auc'
).mean()
return val
定義優化引數(域空間)
rf_bo = BayesianOptimization(
rf_cv_lgb,
{
'num_leaves': (10, 200),
'max_depth': (3, 20),
'bagging_fraction': (0.5, 1.0),
'feature_fraction': (0.5, 1.0),
'bagging_freq': (0, 100),
'min_data_in_leaf': (10, 100),
'min_child_weight': (0, 10),
'min_split_gain': (0.0, 1.0),
'reg_alpha': (0.0, 10),
'reg_lambda': (0.0, 10)
}
)
開始優化,這里我會有15次迭代后的得分,我取了最高的一次貼上來
rf_bo.maximize(n_iter=10)
'''
| iter | target | baggin... | baggin... | featur... | max_depth | min_ch... | min_da... | min_sp... | num_le...
| reg_alpha | reg_la... |
| 14 | 0.7367 | 0.8748 | 21
.07 | 0.9624 | 4.754 | 0.3129 | 21.14 | 0.4187 | 178.2
| 9.991 | 9.528 |
'''
根據優化后的引數建立新的模型,降低學習率并尋找最優模型迭代次數
'''調整一個較小的學習率,并通過cv函式確定當前最優的迭代次數'''
base_params_lgb = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'learning_rate': 0.01,
'num_leaves': 178,
'max_depth': 5,
'min_data_in_leaf': 21,
'min_child_weight': 0.31,
'bagging_fraction': 0.88,
'feature_fraction': 0.96,
'bagging_freq': 21,
'reg_lambda': 9.5,
'reg_alpha': 10,
'min_split_gain': 0.42,
'nthread': 8,
'seed': 2020,
'silent': True,
'verbose': -1
}
train_matrix = lgb.Dataset(x_train, label=y_train)
cv_result_lgb = lgb.cv(
train_set=train_matrix,
early_stopping_rounds=1000,
num_boost_round=20000,
nfold=5,
stratified=True,
shuffle=True,
params=base_params_lgb,
metrics='auc',
seed=2020
)
print('迭代次數 {}'.format(len(cv_result_lgb['auc-mean'])))
print('最終模型的AUC為 {}'.format(max(cv_result_lgb['auc-mean'])))
'''
迭代次數 9364
最終模型的AUC為 0.7378500759884923
'''
模型引數已經確定,建立最終模型并對驗證集進行驗證
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(x_train, y_train)):
print('*** {} ***'.format(str(i+1)))
x_train_split, y_train_split, x_valid, y_valid = x_train.iloc[train_index], y_train[train_index], \
x_train.iloc[valid_index], y_train[valid_index]
train_matrix = lgb.Dataset(x_train_split, label=y_train_split)
valid_matrix = lgb.Dataset(x_valid, label=y_valid)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'learning_rate': 0.01,
'num_leaves': 178,
'max_depth': 5,
'min_data_in_leaf': 21,
'min_child_weight': 0.31,
'bagging_fraction': 0.88,
'feature_fraction': 0.96,
'bagging_freq': 21,
'reg_lambda': 9.5,
'reg_alpha': 10,
'min_split_gain': 0.42,
'nthread': 8,
'seed': 2020,
'silent': True,
'verbose': -1
}
model = lgb.train(params, train_set=train_matrix, num_boost_round=9364, valid_sets=valid_matrix,
verbose_eval=1000, early_stopping_rounds=200)
val_pred = model.predict(x_valid, num_iteration=model.best_iteration)
cv_scores.append(roc_auc_score(y_valid, val_pred))
print(cv_scores)
print('lgb_scotrainre_list: {}'.format(cv_scores))
print('lgb_score_mean: {}'.format(np.mean(cv_scores)))
print('lgb_score_std: {}'.format(np.std(cv_scores)))
'''
lgb_scotrainre_list: [0.7386297996035015, 0.7356995636689628, 0.73900352698853, 0.7382979036633256, 0.7369681848895435]
lgb_score_mean: 0.7377197957627727
lgb_score_std: 0.0012211910753377566
'''
使用訓練集資料進行模型訓練
final_model_lgb = lgb.train(base_params_lgb, train_set=train_matrix, valid_sets=valid_matrix, num_boost_round=13000,
verbose_eval=1000, early_stopping_rounds=200)
預測,并計算roc的相關指標
val_pred_lgb = final_model_lgb.predict(x_valid)
fpr, tpr, threshold = metrics.roc_curve(y_valid, val_pred_lgb)
roc_auc = metrics.auc(fpr, tpr)
print('調參后lgb在驗證集上的AUC: {}'.format(roc_auc))
'''調參后lgb在驗證集上的AUC: 0.7369681848895435'''
plt.figure(figsize=(8, 8))
plt.title('Validation ROC')
plt.plot(fpr, tpr, 'b', label='Val AUC = %0.4f' % roc_auc)
plt.ylim(0, 1)
plt.xlim(0, 1)
plt.legend(loc='best')
plt.title('ROC')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.plot([0, 1], [0, 1], 'r--')
我的圖片沒有保存,總之結果和調參前相差不大
保存模型到本地
pickle.dump(final_model_lgb, open('model/model_lgb_1.pkl', 'wb'))
總結
這次調參下來,發現費了很大的功夫,模型的效果提升微乎其微,所以調參的優先級應該排在特征工程之后,選擇什么樣的模型,以及選擇哪些資料作為特征訓練,特征應該進行怎樣的處理,這些特征工程對于分數的提高應該更大,
下一節在嘗試模型融合之前,我會嘗試用不同的模型先簡單測驗,看一下哪些模型適合該場景,另外在訓練前,我需要先根據特征的重要性做一個特征的篩選,最后訓練2-3個模型后再進行融合,希望分數能有一個大的提高,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/128068.html
標籤:其他