本文主要分享一些組織管理機器學習專案的實踐經驗,
Python
Python 是機器學習專案開發的主要使用語言之一,它包含了大量的庫/包可以用于機器學習:
- numpy:適用于多維陣列、數值計算,常用于資料處理,
- pandas:資料分析常用庫,pandas dataframes本質上是numpy陣列,它用描述性字串作為行和列標簽,資料在pandas dataframes里可以很容易進行排序、過濾、分組、連接等操作,這對資料處理很有用,
- PyTorch:用于構建神經網路,包括許多預訓練模型和計算機視覺資料集,Pytorch鼓勵使用面向物件的編程,用Pytorch撰寫代碼很快,而且Pytorch默認支持快速執行,因此可以與Python除錯器一起使用,
- TensorFlow:在工業上更受歡迎的Pytorch的替代品,Pytorch更適合做研究,如果您想使用TensorFlow,并且想要一個更高級別的介面,那么可以使用Keras,
- scikit-learn:這是一個很好的庫,用于回歸、支持向量機、k近鄰、隨機森林、計算混淆矩陣等,
- matplotlib、seaborn:用于資料可視化的常用庫之一,
Git
Git版本控制對于機器學習專案的組織管理非常有用,
Git是一種可以用來跟蹤對代碼所做的所有更改的工具,Git“repository”是一個包含代碼檔案的目錄,Git使用節省存盤空間的技術,因此它不存盤代碼的多個副本,而是存盤舊檔案和新檔案之間的相對更改,Git有助于保持代碼檔案目錄的整潔和組織,因為只有最新版本才顯示存在(盡管您可以隨時輕松訪問代碼的任何版本),使用者可以選擇發生的更改,使用“commit”將代碼的特定更改與相關的書面描述捆綁在一起,Git存盤庫也使共享代碼和協作變得更加容易,總的來說,比起保存“myscript_v1.py”、“dataprocessing_v56.py”、“utils_73.py”等上百萬個不同版本的代碼,Git是一個更好的方法來保存舊代碼,
Git版本控制可以通過GitHub、GitLab和Bitbucket來實作,我最常使用GitHub,

使用GitHub的方法如下:
- 安裝Git: https://git-scm.com/downloads
- 注冊一個GitHub賬戶:www.github.com
- 通過SSH鏈接個人GitHub賬戶和個人電腦,以便于隨時能夠將代碼上傳并保存在云端,
- 單擊概要檔案的“Repositories”部分中的綠色“new”按鈕,在GitHub上創建一個新的存盤庫,
- 使個人計算機能夠將代碼推送到該存盤庫(以下是示例命令):
echo "# pytorch-computer-vision" >> README.md
git init
git add README.md
git commit -m "first commit"
git branch -M master
git remote add origin https://github.com/rachellea/pytorch-computer-vision.git
git push -u origin master
假設現在myeditedscript.py有代碼做出了更改,可以通過commit進行版本管理:
git add myeditedscript.py
git commit -m 'added super useful functionality'
git push origin master
Anaconda
Anaconda支持創建不同的環境,這些環境可能包含不同的Python版本和不同的包版本,當我們在處理多個具有沖突依賴關系的專案時,Anaconda特別有用,
使用Anaconda很簡單:
首先,安裝Anaconda: https://docs.anaconda.com/anaconda/install/
然后,創建環境,用所在的專案來命名環境是比較好的,例如,如果該專案是關于使用神經網路進行胸部x光分類的,則該環境可以稱為chestxraynn:
conda create --name chestxraynn python=3.5
請注意,避免在環境名稱周圍加引號,否則引號字符本身將是環境名稱的一部分,此外,可以選擇任何版本的Python,它不一定是python3.5,
一旦環境被創建,就是激活環境的時候了,“激活”僅僅意味著你將被“放入環境中”,這樣你就可以使用安裝在里面的所有軟體,Windows激活命令如下:
activate chestxraynn
Linux/macOS激活命令如下:
source activate chestxraynn
使用“conda install”命令在環境中安裝包,以安裝matplotlib為例:
conda install -c conda-forge matplotlib
從技術上講,在conda環境中,也可以使用pip安裝包,但這可能會導致問題,因此應盡量避免,
Anaconda將負責確保環境中所有內容的版本都是兼容的,更多命令見Conda Cheat Sheet,
也可以直接使用別人的命令檔案創建conda環境,在GitHub中https://github.com/rachellea/pytorch-computer-vision, 有一個tutorial_environment.yml檔案,此檔案指定運行教程代碼所需的依賴項,要基于此檔案創建conda環境,只需在Anaconda提示符中運行以下命令:
conda env create -f tutorial_environment.yml
代碼管理:類和函式
代碼管理非常重要,當數千行的代碼,沒有檔案說明,中間到處都是重復的代碼塊,一些代碼塊沒有解釋就注釋掉了,還有各種奇怪的變數名,這簡直就是一場災難,
而Pytorch實作中通常看到的所有代碼都是有組織的,并且有很好的說明記錄,
從長遠來看,如果為自己的專案撰寫高質量的代碼,將節省大量時間,高質量代碼的一個方面是它在模塊中的組織和管理,
代碼管理建議:
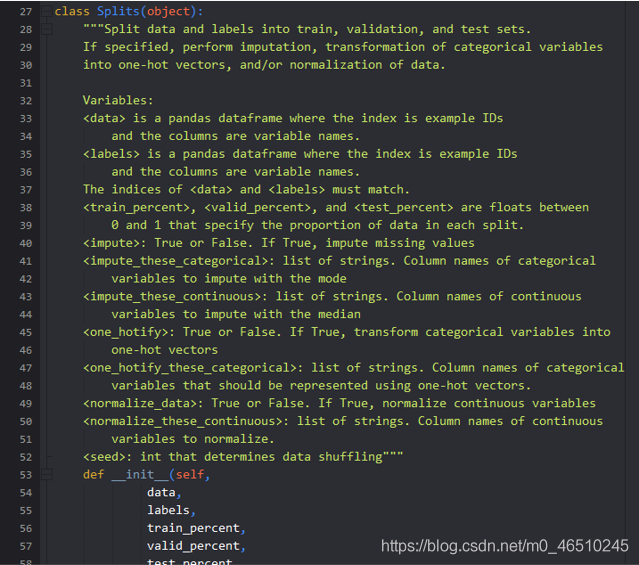
- 面向物件編程,強烈推薦使用PyTorch機器學習框架,因為它有助于為所有事情使用面向物件的編程,Pytorch中,模型是一個類,資料集也是一個類,
- 使用函式,如果你寫的東西不能作為一個類很好地作業,那么把代碼組織成函式,函式是可重用的,
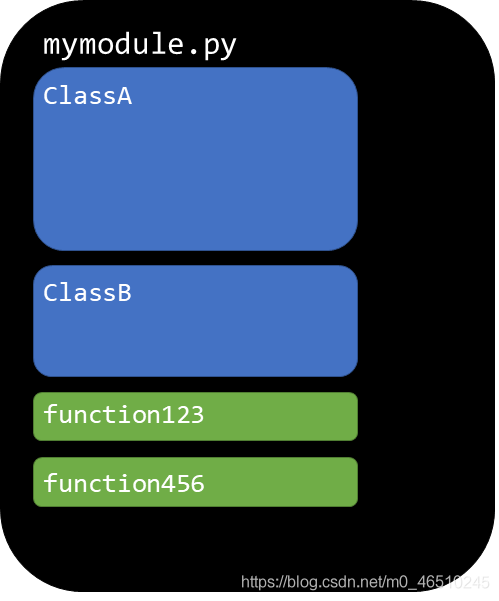
代碼管理:目錄
使用多個模塊來組織代碼,并將這些模塊組織到目錄中,以一個簡單的專案為例:
總體組織如下:
- 一個訓練-評估-測驗回圈模塊(src/run_experiment.py)
- 一個用于計算性能指標的模塊(src/evaluate.py)
- 一個(或多個)用于資料處理的模塊(load_dataset/custom-pascal.py、 load_dataset_custom_tiny.py)
- 一個(或多個)模型模塊(models/custom_models_base.py)

請注意,雖然在這個存盤庫中存盤了一個資料集(在“train”、“val”和“test”目錄中的png圖片),但一般來說,將資料集放入存盤庫并不是一個好主意,此存盤庫中存在資料集的唯一原因是,它是為演示目的而創建的小型資料集,除非資料非常小,否則不應將其放入存盤庫中,
匯入檔案
請注意,需要在每個子目錄中都有一個名為_init_.py的空檔案,以便模塊可以從這些目錄匯入檔案,
下面是如何根據彼此所在的目錄讓一個模塊awesomecode.py呼叫名為helpercode.py的模塊:

說明檔案
寫說明檔案是很好的,記錄所有函式、方法和類,有時在撰寫函式之前對其進行檔案記錄,如果檔案有時比代碼長也可以,“過于清晰”比不夠清晰要好,
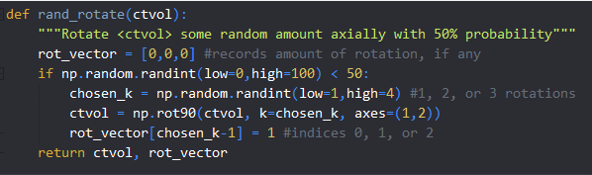
上面的影像是一個簡單的函式rand_rotate(),它隨機旋轉表示CT體積的3D numpy陣列,這些注釋很有幫助,因為它們解釋了為什么旋轉的向量使用(k-1)——這是因為所選的k是1、2或3,而Python是零索引的,像這樣簡單的說明可以防止以后的混亂,
檔案將確保回顧舊代碼時,可以快速回憶代碼和函式的作用,檔案可以防止使用者在看到一些看起來很奇怪的東西時意外地破壞自己的代碼,并且有更改它的本能,檔案也將使其他人能夠理解和使用您的代碼,
變數命名
始終使用描述性變數名,“volumetric_attn_gr_truth”是一個比“truth”更好的變數名,
即使在行和列上迭代,也要使用“row”和“col”作為變數名,而不是“i”和“j”,有一次我花了一整天的時間尋找一個非常奇怪的bug,結果發現它是由于錯誤地迭代2D陣列而導致的,因為我在數百行代碼中只切換了一行“I”和“j”,那是我最后一次使用單字母變數名,
模塊測驗
很多人聲稱他們沒有時間為他們的代碼撰寫測驗,因為這只是為了研究,我認為測驗研究代碼更重要,因為研究的全部意義在于你不知道“正確答案”是什么,如果你不知道生成答案的代碼是否正確那么如何確保答案是正確的呢?
每次我花一天時間為我的代碼撰寫單元測驗時,我都會發現一些錯誤——有些無關緊要,有些則相當重要,如果你撰寫單元測驗,將發現代碼中的錯誤,如果你為別人的代碼撰寫單元測驗,你也會在他們的代碼中發現錯誤,
除了促進代碼的正確性,單元測驗還可以通過阻止撰寫一次做太多事情的“上帝函式”來幫助實施良好的代碼組織管理,上帝函式通常是測驗的噩夢,我們應該將其分解成更小、更易于管理的函式,
至少,最好對代碼中最關鍵的部分進行單元測驗,例如復雜的資料處理或模型中奇怪的張量排列,確保代碼是正確的決不是浪費時間,
這些單元測驗包括對一些內置PyTorch函式的測驗,以便進行演示,
可視化糾錯
特別是在計算機視覺中,使用可視化來執行健全性檢查是很有用的,
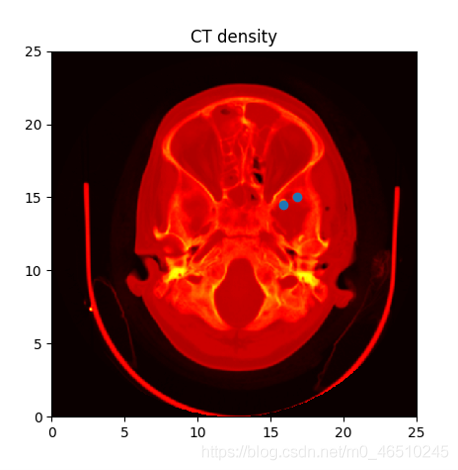
matplotlib非常適合查看影像、分割圖、帶邊框的影像等,下面是一個通過將matplotlib的imshow()函式應用于輸入影像而產生的可視化效果的示例:
seaborn是為統計資料可視化而設計的,它對于制作熱力圖和生成性能指標的復雜可視化非常有用,下面是一些在seaborn中可以用大約一行代碼繪制的繪圖示例:
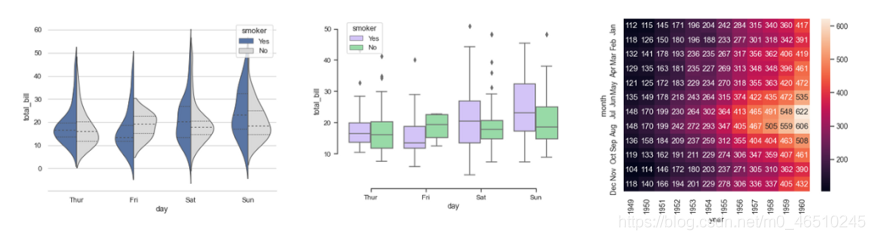
matplotlib和seaborn都可以用來創建可視化效果,即時顯示輸入資料是否合理、基本真實情況是否合理、資料處理是否沒有意外出錯、模型的輸出是否有意義等,
單元測驗和可視化
Demo-0-Unit-Tests-and-Visualization.py 首先運行 src/unit_tests.py中的單元測,然后對PASCAL VOC 2012資料集影像分割進行可視化,
為了運行演示的可視化部分,請更改demo-0-Unit-Tests-and-visualization.py到計算機上的一個檔案夾內,在其中存盤PASCAL VOC 2012資料集,一旦資料集下載完成,你就可以運行可視化程式,實作可視化的代碼位于load_dataset/custom_pascal.py中. 目前,在演示檔案中,“images_to_visualize”的總數設定為3;如果希望可視化更多影像,可以進一步增加該數量,例如增加到100,
可視化結果如下:
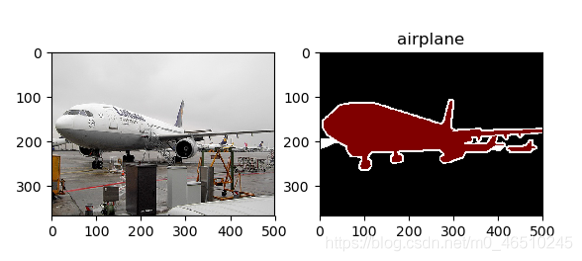
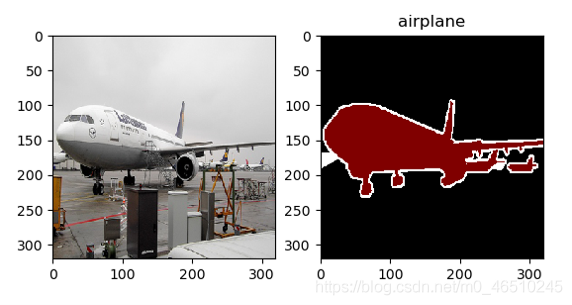
從可視化結果中我們可以推斷出一些有用的東西:
- 輸入影像與影像分割之間的映射是正確的,
- 用于定義像素級分割的整數與標簽描述字串之間的映射是正確的,比如:1正確地映射為“飛機”,
- 重采樣步驟并沒有“破壞”輸入影像或分割影像,
在終端進行可視化
如果處于“非互動式環境”(即沒有圖形用戶界面的終端),則需要關閉互動式顯示并保存圖形,以便在其他地方打開:
import seaborn
import matplotlib
matplotlib.use('agg')
import matplotlib.pyplot as plt
plt.ioff()
#seaborn figure:
heatmap = seaborn.heatmap(some_dataframe, cmap = 'Blues', square=True, center=0)
heatmap.get_figure().savefig('Descriptive_Figure_Name.png',bbox_inches='tight')
plt.close()
#matplotlib figure:
plt.imshow(chest_x_ray,cmap='gray')
plt.savefig('Other_Descriptive_Figure_Name.png')
plt.close()
Python 除錯器
Python除錯器是一個非常有用的工具,因為它允許在程式崩潰的地方檢查變數或物件的狀態,并在程式崩潰的地方運行代碼片段,以便可以嘗試可能的解決方案,使用Python除錯器比使用print陳述句除錯效率更高,它將為節省數小時的時間,Python除錯器也可以與PyTorch一起使用,檢查張量、梯度、記錄dataframes等,
要使用Python除錯器在終端中以互動方式運行腳本,請使用以下命令:
python -m pdb myscript.py
輸入上述命令后,將看到(Pdb)提示符出現,鍵入“c”繼續,(這只是一個單獨的小寫字母c,表示continue),
要退出Python除錯器,請使用’q’(這是一個單獨的小寫字母q,表示quit),有時候可能需要使用q兩次才能完全退出,
如果要在程式中的某個特定點停止,則可以在相關模塊中匯入pdb,然后將“pdb.set_trace()“在你想要停止的特定點,或者,如果不想費心匯入pdb,也可以在想停止的地方輸入“assert False”,這樣可以保證程式在指定的地方結束(盡管這不是使用Python除錯器的正式方式),
不要使用Jupyter Notebooks
考慮到前面的所有部分,本文建議不要將jupyter notebooks用于機器學習專案,或者真正用于任何需要花費數天以上時間的編碼專案,
為什么?
- jupyter notebooks 鼓勵你把所有的東西都放在全域命名空間中,這樣就產生了一個巨大的怪物模塊,它可以做所有的事情,而且沒有函式、類和任何結構,
- jupyter notebooks 使代碼的重用變得更加困難,函式是可重用的;而單元格5、10和13中的代碼是不可重用的,
- jupyter notebooks 使單元測驗變得困難,函式和方法可以進行單元測驗,單元格5、10和13中的代碼不能進行單元測驗,
- 代碼越有條理(也就是說,越細分為類和函式),jupyter notebooks 的互動性就越差,互動性是人們喜歡jupyter notebook的主要原因,jupyter notebooks 吸引人的互動特性與高度結構化、組織良好的代碼本質上是對立的,
- jupyter notebooks 很難正確使用Git版本控制,jupyter notebooks只是大量的JSON檔案,因此正確地合并它們或用它們執行提交請求基本上是不可能的,
- jupyter notebooks 使人們很難與他人合作,你必須“輪流”在jupyter notebooks上作業(而不是像使用“常規代碼”那樣從同一個rep中push/pull),
- jupyter notebooks 有一個非線性的作業流程,這與可重復的研究完全相反,
那么jupyter notebooks有什么用?一些可能適用的場景是初始資料可視化、家庭作業、互動式演示,
代碼撰寫標準
兩個實用的代碼撰寫標準是:
- 撰寫正確易懂的代碼,如果你的代碼是正確的,你的模型就更有可能產生好的結果,你的研究結論是正確的,你將創造出一些實際有用的東西,
- 確保任何人都可以復制你所做的一切——例如模型、結果、圖形——通過在終端中運行一個命令(例如“python main.py”). 將有助于其他人在你的作業基礎上再接再厲,也有助于“未來的你”在自己的作業基礎上再接再厲,
總結
- Python是一種很好的機器學習語言
- Git版本控制有助于跟蹤不同版本的代碼,它可以通過GitHub獲得,
- Anaconda是一個包管理器,它支持創建不同的環境,這些環境可能包含不同的Python版本和包,在處理具有沖突依賴關系的多個專案時,它非常有用,
- 將代碼組織成模塊中的類和函式,在Git存盤庫中以分層目錄結構組織模塊,
- 用注釋和docstring記錄代碼
- 使用描述性變數名,不要使用單字母變數名,
- 撰寫單元測驗,特別是對于資料處理和模型中最復雜或最關鍵的部分,
- 使用matplotlib和seaborn可視化顯示資料集、模型輸出和模型性能
- 使用Python除錯器進行快速、高效的除錯
- 不要將jupyter notebooks 用于機器學習專案
作者:Rachel Lea Ballantyne Draelos
deephub翻譯組:Oliver Lee
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/135215.html
標籤:其他
上一篇:結構光三維測量(數字光柵投影)