
日常跳轉:
- 匯入與簡介
- 方法一
- 分析與主要代碼:
- 代碼
- 關于代碼的一些注解:
- 方法二
- 分析與主要代碼:
- 代碼
- 關于代碼的一些注解:
- 方法三
- 全部原始碼
- BIG福利
匯入與簡介
轉載請標明作者和原文鏈接!!!
CSDN個人主頁: 高智商白癡
原文地址: https://blog.csdn.net/qq_44700693/article/details/108828909
規則更新日期: 2020-9-27
說起B站,肯定人人都知道吧,B站的反扒機制并不是太嚴格,所以今天我準備給大家說說我能想到的幾種方式,目前大概想到了三種方式:
- 1、模擬手機端請求,視頻鏈接就添加在原始碼中,(最簡單、但清晰度不好)
- 2、通過呼叫別人的介面來下載視頻,(根據介面的破解難度而定,可選擇清晰度)
- 3、直接通過B站的網頁版來抓取,(難度稍大)
那么接下來我就來依次給大家介紹介紹我的方法!
方法一
為了方便分析,先拿一個鏈接作為測驗:
https://www.bilibili.com/video/BV1R54y1e7J3?spm_id_from=333.5.b_646f7567615f6d6164.4
分析與主要代碼:
既然方法一已經確定是模擬手機端的方式去請求,那么我們就直接開始分析:
對該鏈接進行抓包,找了半天,并沒有找到什么有用的資訊,所以我就直接去查看網頁原始碼: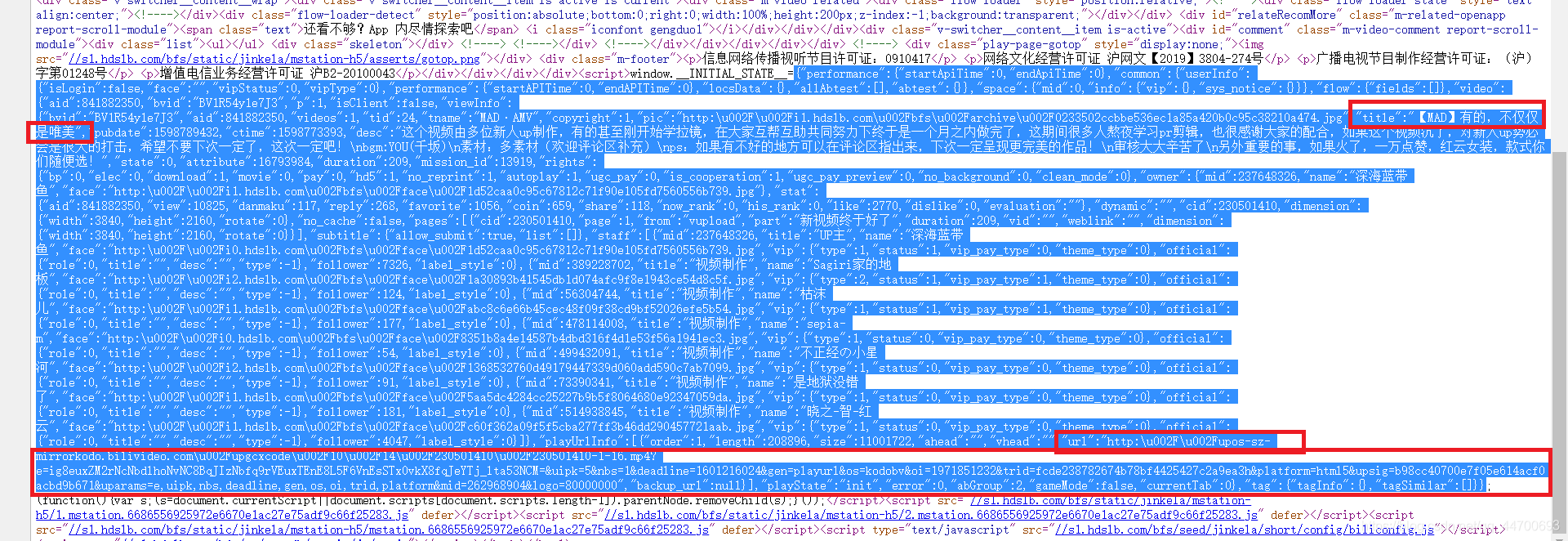
在仔細地查看原始碼后,就發現了如上所示的資訊,視頻的 MP4 鏈接和視頻名就加載在原始碼之中,
因為這些資訊都儲存在 <script>…</script> 標簽中,雖然能夠將所有內容提取出來,再轉換為 JSON 格式進行提取,但是這樣的話就顯得有些麻煩了,我們直接用正則運算式來提取:
代碼
class BiLiBiLi_phone():
def __init__(self,s_url):
self.url=s_url
self.headers={
'origin': 'https://m.bilibili.com',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)'
}
def bili_Download(self):
r = requests.get(self.url, proxies=proxy, headers=self.headers)
video_name=re.findall(',"title":"(.*?)","pubdate":', r.text)[0]
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = re.findall(',"url":"(.*?)","backup_url"', r.text)[0].encode('utf-8').decode('unicode_escape')
r=requests.get(video_url,proxies=proxy,headers=self.headers)
with open(path+video_name+'.mp4','wb')as f:
f.write(r.content)
print("【BiLiBiLi】: {} 下載完成!".format(video_name))
關于代碼的一些注解:
- video_url = re.findall(’,“url”:"(.*?)",“backup_url”’, r.text)[0] .encode(‘utf-8’).decode(‘unicode_escape’)
標黃字體之前的代碼為正則運算式的基本操作,而標黃的字體的原因是:
從原始碼中提取的到的鏈接為:
http:\u002F\u002Fupos-sz-mirrorkodo.bilivideo.com \u002F upgcxcode \u002F 10 \u002F 14 \u002F 230501410 \u002F 230501410-1-16.mp4?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfq9rVEuxTEnE8L5F6VnEsSTx0vkX8fqJeYTj_lta53NCM=&uipk=5&nbs=1&deadline=1601216024&gen=playurl&os=kodobv&oi=1971851232&trid=fcde238782674b78bf4425427c2a9ea3h&platform=html5&upsig=b98cc40700e7f05e614acf0acbd9b671&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=262968904&logo=80000000
鏈接中包含了大量的 \u002F 欄位,這是因為原始碼中加載的是轉換為 Unicode 編碼后的鏈接,所以要進行編碼轉化,

方法二
為了方便分析,我還是拿之前的鏈接來作為測驗:
https://www.bilibili.com/video/BV1R54y1e7J3?spm_id_from=333.5.b_646f7567615f6d6164.4
分析與主要代碼:
對于方法二,我們首先需要找到一個第三方的網站來決議視頻,然后將整個程序進行包裝,
不同的網站有不同的決議方式,我這里只寫出我隨便選擇的一個網站,清晰度就還行吧,
介于這個網站的特殊性:當輸入鏈接為:
https://www.bilibili.com/video/BV1R54y1e7J3?spm_id_from=333.5.b_646f7567615f6d6164.4 時會出現以下報錯
所以需要將后面的部分資訊去掉!

將準備好的鏈接放到決議網站可以得到以下資訊:
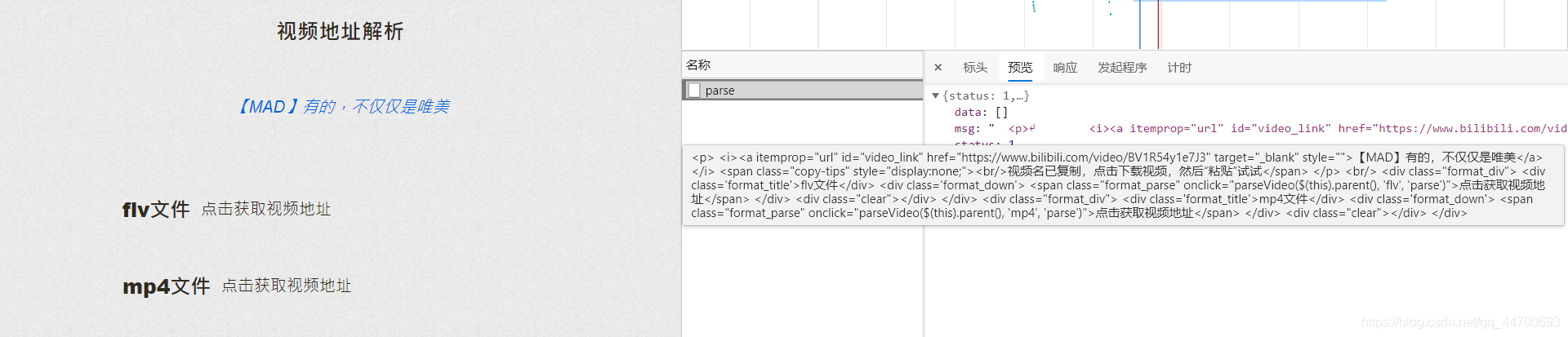
由于網站的特殊性,若選取 MP4檔案 ,有時會出現視頻分成多個的情況,所以我在這里主要選取 FLV檔案 ,
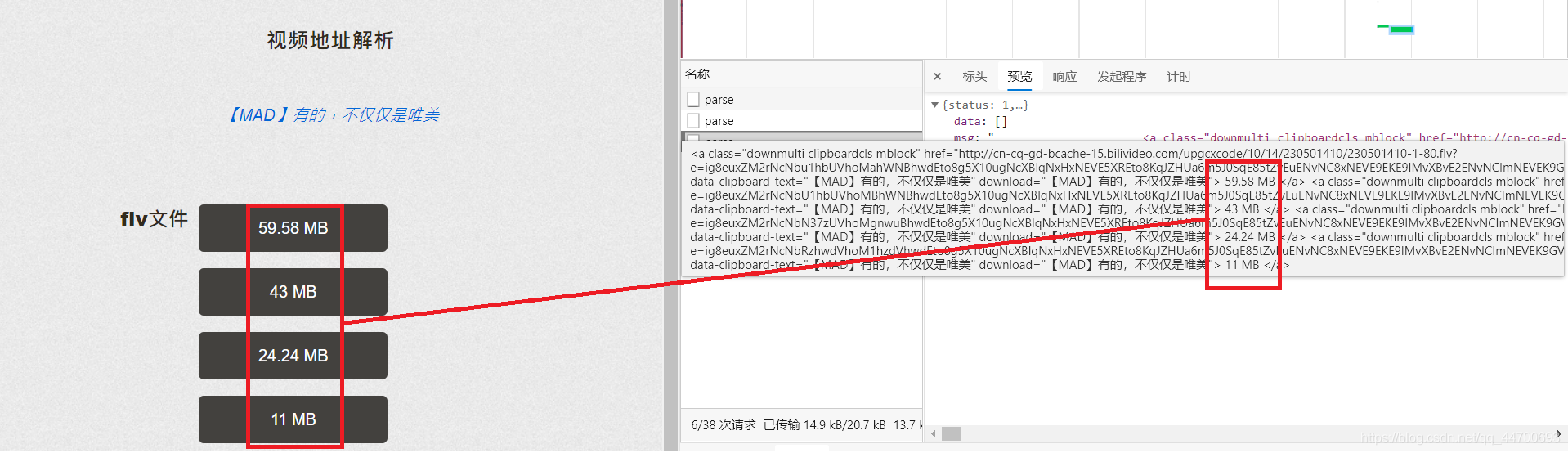
我們可以很清楚的看到,該介面回傳的內容中,是一些屬于 HTML標簽 的資訊,在這里不撰寫清晰度選擇的代碼,有需要的可以自行撰寫,直接選取清晰度最好的一個來決議,
代碼
這是為了防止這個 B 站視頻決議服務網站被濫用,在這里我對該決議網站進行了隱藏,想要使用這個決議服務的地址,可以私信我,
這種決議網站的一種特點就是,知道的人越多,它失效的也就越快,
希望這樣,它可以盡量活得久一點點,
class BiLiBiLi_api():
def __init__(self, s_url):
self.url = s_url.split('?')[0]
self.header1 = {
'Host': 'www.****.com',
'Origin': 'http://www.****.com',
'Referer': quote('http://www.****.com/video?url={}&page=video&submit=視頻下載'.format(self.url)),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
self.data = {
'url': self.url,
'format': 'flv',
'from': 'parse',
'retry': '1'
}
self.header2 = {
'origin': 'https://www.bilibili.com/',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
def BL_api_Download(self):
r = requests.post('http://www.****.com/parse', proxies=proxy, data=self.data, headers=self.header1)
video_name = re.findall('data-clipboard-text="(.*?)"', r.json()['msg'])[0]
video_url = re.findall('href="(.*?)"', r.json()['msg'])[0].replace('amp;', '')
r1 = requests.get(video_url, proxies=proxy, headers=self.header2)
with open(path + video_name + '.flv', 'wb')as f:
f.write(r1.content)
print("【BiLiBiLi】: {} 下載完成!".format(video_name))
關于代碼的一些注解:
- 初始化中為什么含有兩個請求頭資訊,
1、header1 的請求頭資訊為決議網站時所需要的一些資訊,
2、header2 的請求頭資訊為下載視頻時所需要的一些資訊,
請求頭為什么要分開寫成兩個:
第一個請求頭所需的資訊就不用多說,都是常規操作,第二個請求頭所需是資訊時因為該網站所決議出的視頻鏈接為B站中的原鏈接,所以要帶上關于B站資訊的請求頭來進行下載,否則服務器將會 拒絕 我們訪問,
- data資料是什么:
在上述決議網站的操作程序中我們還記得,在請求完決議鏈接后,仍然需要選擇視頻檔案的格式,我們才能得到視頻的鏈接,而當我們選擇完格式以后,會再次對原鏈接進行請求,并且會攜帶上固定格式的data資料,
- quote(‘http://www.****.com/video?url={}&page=video&submit=視頻下載’.format(self.url))
為什么要進行編碼轉換:
網站就是這樣,不更換編碼,它要報錯,嘿嘿嘿,
- video_url = re.findall(‘href="(.*?)"’, r.json()[‘msg’])[0] .replace(‘amp;’, ‘’)
同之前所說的,未標黃的部分也還是基本操作,就是利用正則運算式來提取資訊,而對于所標黃的部分,這是因為所決議到的鏈接中含有 HTML的轉移字符:
http://cn-cq-gd-bcache-15.bilivideo.com/upgcxcode/10/14/230501410/230501410-1-80.flv?e=ig8euxZM2rNcNbu1hbUVhoMahWNBhwdEto8g5X10ugNcXBlqNxHxNEVE5XREto8KqJZHUa6m5J0SqE85tZvEuENvNC8xNEVE9EKE9IMvXBvE2ENvNCImNEVEK9GVqJIwqa80WXIekXRE9IMvXBvEuENvNCImNEVEua6m2jIxux0CkF6s2JZv5x0DQJZY2F8SkXKE9IB5QK & deadline=1601220310 & gen=playurl & nbs=1 & oi=1696943910 & os=bcache & platform=pc & trid=380e02a6015c4f6c89df5944e35a87a8 & uipk=5 & upsig=062c2af07c4454f8641dc7552b1c1f3e & uparams=e,deadline,gen,nbs,oi,os,platform,trid,uipk & mid=0
方法三
撰寫中…(遇到了點小麻煩!)
全部原始碼
import random
import re
from urllib.parse import quote
import requests
url = 'https://ip.jiangxianli.com/api/proxy_ip'
r = requests.get(url)
proxy = {'HTTP': 'http://' + r.json()['data']['ip'] + ':' + r.json()['data']['port']}
print(proxy)
path = 'C:/Users/Jackson-art/Desktop/'
class BiLiBiLi_phone():
def __init__(self, s_url):
self.url = s_url
self.headers = {
'origin': 'https://m.bilibili.com',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)'
}
def bili_Download(self):
r = requests.get(self.url, proxies=proxy, headers=self.headers)
video_name = re.findall(',"title":"(.*?)","pubdate":', r.text)[0]
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = re.findall(',"url":"(.*?)","backup_url"', r.text)[0].encode('utf-8').decode('unicode_escape')
r = requests.get(video_url, proxies=proxy, headers=self.headers)
with open(path + video_name + '.mp4', 'wb')as f:
f.write(r.content)
print("【BiLiBiLi】: {} 下載完成!".format(video_name))
class BiLiBiLi_api():
def __init__(self, s_url):
self.url = s_url.split('?')[0]
self.header1 = {
'Host': 'www.****.com',
'Origin': 'http://www.****.com',
'Referer': quote('http://www.****.com/video?url={}&page=video&submit=視頻下載'.format(self.url)),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
self.data = {
'url': self.url,
'format': 'flv',
'from': 'parse',
'retry': '1'
}
self.header2 = {
'origin': 'https://www.bilibili.com/',
'referer': self.url,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63'
}
def BL_api_Download(self):
r = requests.post('http://www.****.com/parse', proxies=proxy, data=self.data, headers=self.header1)
video_name = re.findall('data-clipboard-text="(.*?)"', r.json()['msg'])[0]
video_url = re.findall('href="(.*?)"', r.json()['msg'])[0].replace('amp;', '')
r1 = requests.get(video_url, proxies=proxy, headers=self.header2)
with open(path + video_name + '.flv', 'wb')as f:
f.write(r1.content)
print("【BiLiBiLi】: {} 下載完成!".format(video_name))
def user_ui():
print('*' * 10 + '\t BiLiBiLi視頻下載\t' + '*' * 10)
print('*' * 5 + "\t\tAuthor: 高智商白癡\t\t" + '*' * 5)
share_url = input('請輸入分享鏈接: ')
choice = int(input("1、模擬手機端下載 2、呼叫介面下載 3、直接下載\n選擇下載方式:"))
if choice == 1:
BiLiBiLi_phone(share_url).bili_Download()
if choice == 2:
BiLiBiLi_api(share_url).BL_api_Download()
if choice == 3:
print("撰寫中,,,")
if __name__ == '__main__':
user_ui()
BIG福利
雖然這篇博客還沒有寫完,不過我已經迫不及待的給大家分享我在尋早資源的程序中發現的好多西:B站的壁紙
其實B站有一個官方號,上面全是一些2233娘的一些壁紙,嘿嘿嘿~
話不多說,鏈接奉上:壁紙娘
這里面全是高清大圖,美不勝收,當然我也給大家準備了一個官方介面(貌似好像是官方的),也是我在找資源的程序中發現的,其實,這個介面能夠讓我們很方便的呼叫并下載壁紙:https://api.vc.bilibili.com/link_draw/v1/doc/doc_list?uid=6823116&page_num=0&page_size=500&biz=all
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/138214.html
標籤:其他
上一篇:Python識別驗證碼