orangepi 4B利用python3使用snowboy實作語音喚醒以及使用騰訊AI api實作語音識別、回復以及合成
- 一個月來經歷無數個坑,終于完成教程,整理不易,轉載請注明出處,謝謝
- 準備作業
- 基本知識與儲備
- 硬體方面準備
- 準備材料
- 鏡像下載地址
- 鏡像安裝方法
- 軟體方面準備
- 騰訊AI開放平臺注冊開發者
- 仔細查看開發檔案以及完成應用創建
- 正式開始操作
- 登錄以及環境配置
- 切換中文環境以及安裝中文輸入法
- 時區設定與中文支持
- python3安裝及snowboy編譯
- 安裝python3以及pip3
- 安裝portaudio、pyaudio以及其他python3的支持包(重點,不安裝無法使用pyaudio,更無法使用語音識別)
- 安裝swig以及ATLAS依賴
- 獲取snowboySDK以及snowboy的編譯(注:4B需要修改的地方是重點否則無法完成編譯)
- 利用騰訊AI api完成語音識別,回復,以及語音合成
- 用到的python模塊以及引數設定
- 用來生成需要位數的隨機字符
- 介面鑒權撰寫
- 利用wave模塊保存錄音
- 使用pyaudio錄音
- 使用pyaudio播放
- 語音識別
- 得到回答
- 語音合成
- 測驗snowboy以及修改demo
- 測驗snowboy熱詞喚醒功能
- 修改Demo
- 后續延伸
- 語音控制智能機器人
- 語音控制家庭智能家居中心
一個月來經歷無數個坑,終于完成教程,整理不易,轉載請注明出處,謝謝
準備作業
基本知識與儲備
1.python基本語法、模塊庫的呼叫、常用模塊熟練呼叫
2.Linux環境的使用,熟悉apt,pip,git下載,python3環境配置
3.一顆能堅持下來的耐心
4.遇到問題能主動去找百度,而不是放棄
硬體方面準備
準備材料
一張16Gclass10SD卡、一個USB2.0或3.0的讀卡器、一個orangepi4B主板、一個USB麥克風(淘寶10塊還包郵那種)、一個支持AUX音響(沒有可以用耳機代替)、一個支持HDMI的顯示幕、一個鍵盤、一個滑鼠以及一個USB擴展塢
下面是我準備的SD卡以及讀卡器

鏡像下載地址
我使用的是香橙派官方ubuntu-npu鏡像地址:香橙派官網.
選擇下載用戶手冊和原理圖在檔案中找到這個檔案OrangePi_4_ubuntu_bionic_desktop_linux4.4.179_npu_v1.3.tar.gz
也可以直接在這個鏈接下載: https://pan.baidu.com/s/17549ZGbNTLuJANoiJAA7JQ 提取碼: sja5
同時下載官方工具包找到Win32DiskImager以及SDFormatter或者百度自行下載

鏡像安裝方法
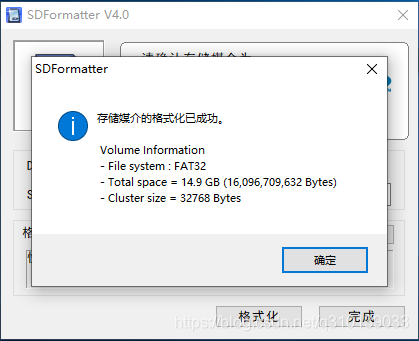
首先使用SDFormatter將SD卡格式化(這里請備份好自己的資料)
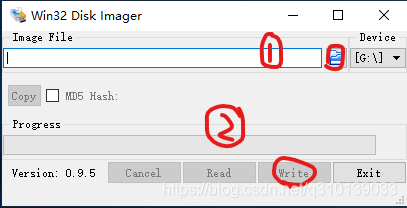
接下來使用Win32DiskImager寫入鏡像到SD卡
等待提示完成,拔出SD卡,插入opi4b卡槽插上顯示幕鍵盤滑鼠然后插上電源開機,先使用賬號為root密碼為orangepi登錄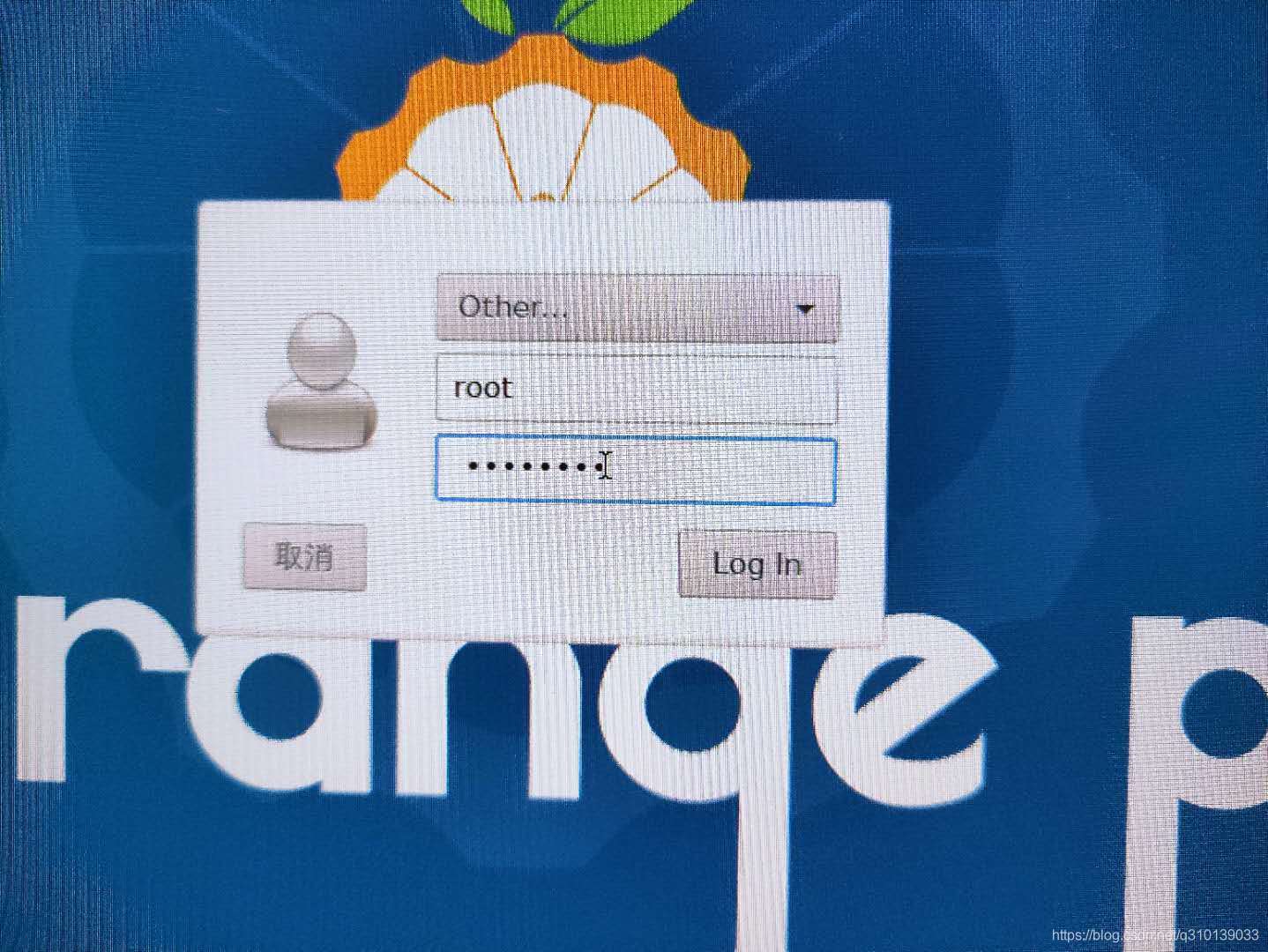
打開LX終端
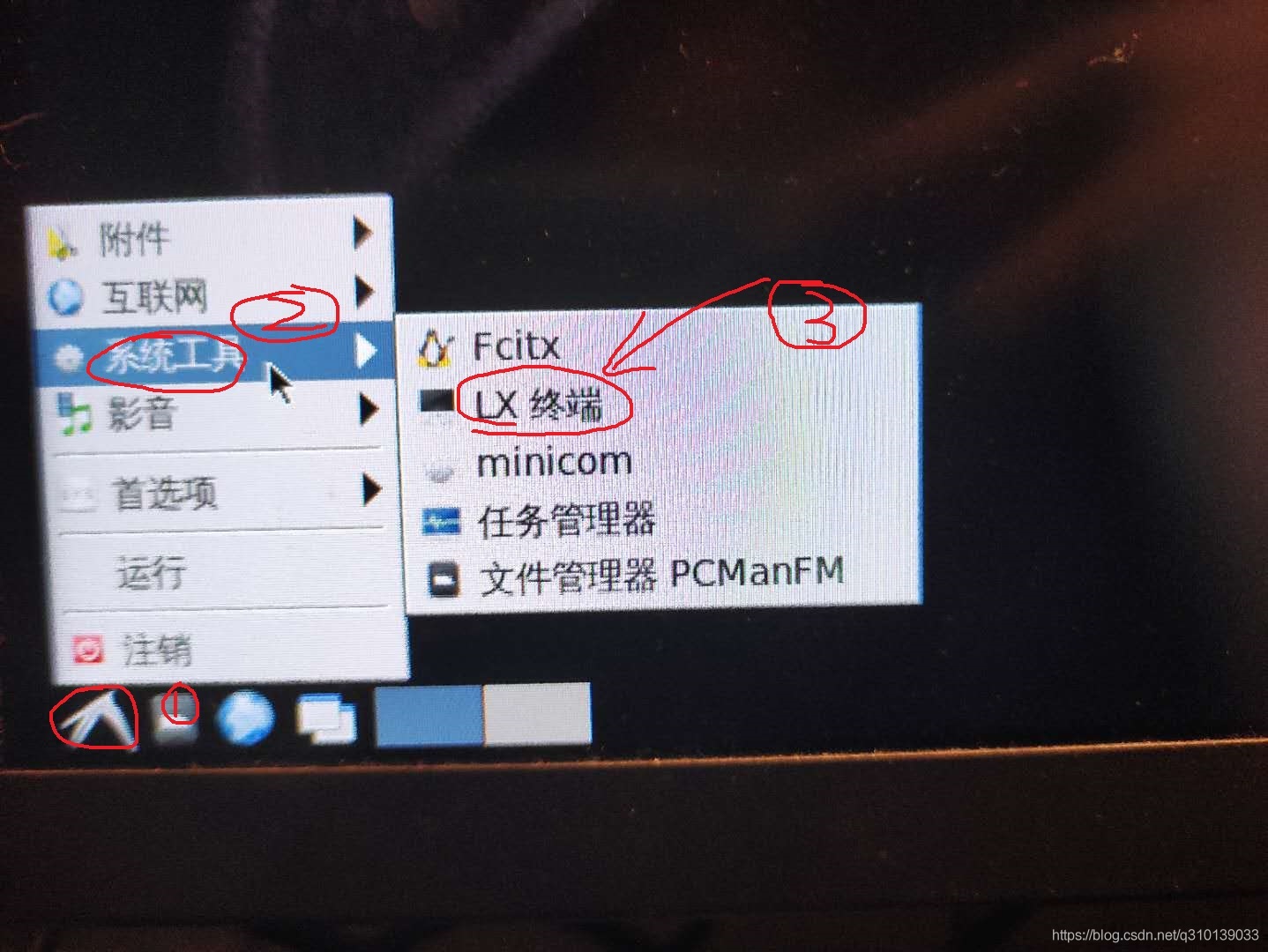
使用install_to_emmc命令將鏡像燒錄至emmc(期間會提示輸入一次Y)
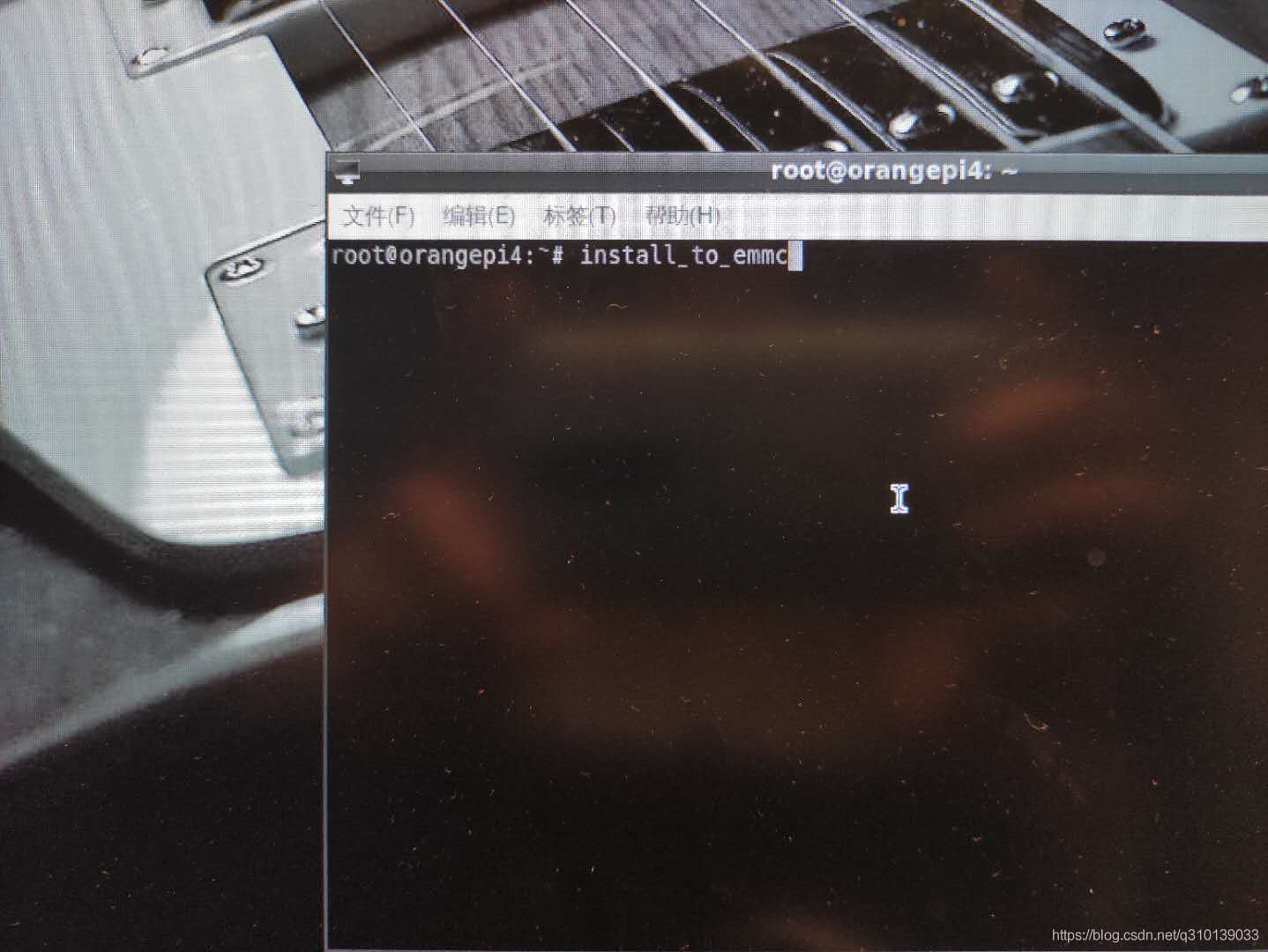
提示燒錄完成執行reboot命令重啟香橙派,同時拔出SD卡
至此完成鏡像燒錄以及準備作業
軟體方面準備
騰訊AI開放平臺注冊開發者
很簡單,百度一大堆,自己也可以摸索,這里就不贅述了
仔細查看開發檔案以及完成應用創建
###################################################
正式開始操作
登錄以及環境配置
切換中文環境以及安裝中文輸入法
打開LX終端執行sudo apt-get install ttf-wqy-zenhei安裝中文字庫
執行sudo apt-get install fcitx fcitx-googlepinyin fcitx-module-cloudpinyin fcitx-sunpinyin
安裝中文輸入法
然后重啟就可以看到輸入法安裝完成(中英文切換方式為)
時區設定與中文支持
在LX終端設定上海時間
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
中文環境設定, 打開終端, 輸入以下命令
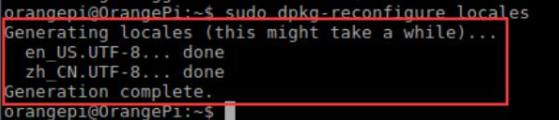
sudo dpkg-reconfigure locales
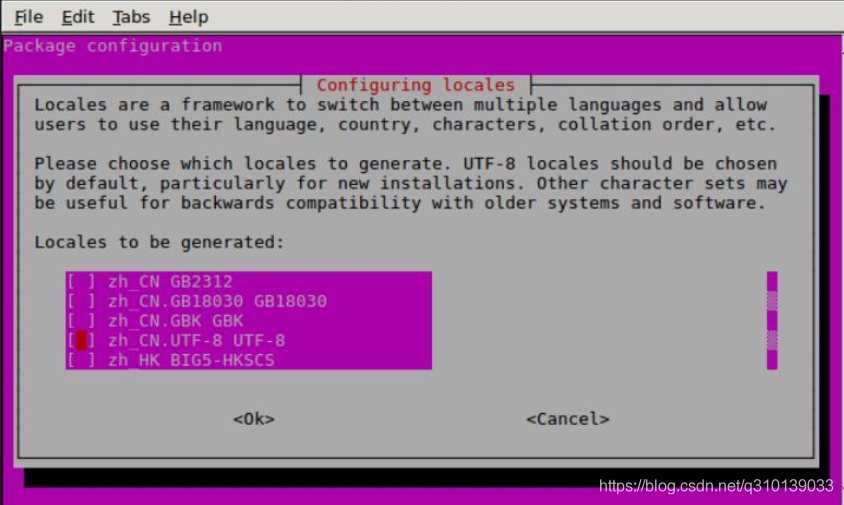
然后往下找(鍵盤-按下鍵) , 在較后面, 找到 en_US.UTF-8 UTF-8,zh_CN.UTF-8 UTF-8,zh_CN.GBK GBK 如上圖所示,按空格選中, 按回車確定,
然后來到如下界面, 選擇 zh_CN.UTF-8, 確定, 按下回車鍵,
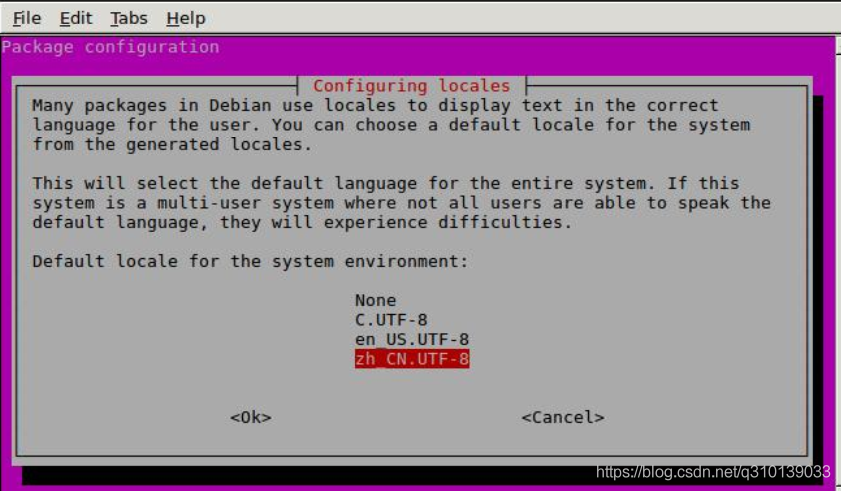
出現如下資訊, 配置完成,重啟系統即可,
python3安裝及snowboy編譯
安裝python3以及pip3
終端執行
sudo apt-get install python3 python3-pip3
安裝portaudio、pyaudio以及其他python3的支持包(重點,不安裝無法使用pyaudio,更無法使用語音識別)
終端執行
sudo apt-get install portaudio19-dev python-all-dev python3-all-dev jackd1 portaudio19-doc jack-tools meterbridge liblo-dev
sudo apt-get install pyaudio
安裝swig以及ATLAS依賴
終端執行
sudo apt-get install swig
sudo apt-get install libatlas-base-dev
獲取snowboySDK以及snowboy的編譯(注:4B需要修改的地方是重點否則無法完成編譯)
終端執行
git clone https://github.com/Kitt-AI/snowboy.git
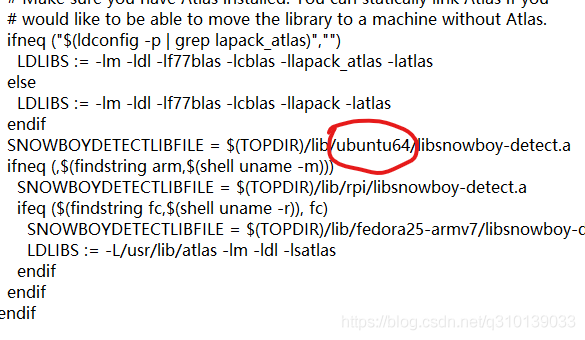
需要修改的地方①在snowboy/swig/Python3中的makefile
找到下圖中位置將ubuntu64替換為aarch64-ubuntu1604
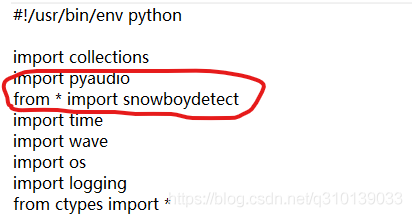
地方②在snowboy/examples/Python3中的snowboydecoder.py檔案
將from * import snowboydetect 修改為import snowboydetect
在snowboy/swig/Python3檔案夾打開終端執行make
至此snowboy編譯完成,
利用騰訊AI api完成語音識別,回復,以及語音合成
用到的python模塊以及引數設定
import base64
import json
import operator
import random
import time
import wave
from urllib import parse
import hashlib
import snowboydecoder
import signal
from contextlib import contextmanager
import requests
from pyaudio import PyAudio, paInt16
CHUNK = 1024 # wav檔案是由若干個CHUNK組成的,CHUNK我們就理解成資料包或者資料片段,
FORMAT = paInt16 # 表示我們使用量化位數 64位來進行錄音
CHANNELS = 1 # 代表的是聲道,1是單聲道,2是雙聲道,
RATE = 16000 # 采樣率 一秒內對聲音信號的采集次數,常用的有8kHz, 16kHz, 32kHz, 48kHz,11.025kHz, 22.05kHz, 44.1kHz,
RECORD_SECONDS = 5 # 錄制時間這里設定了5秒
app_id = '你的appid' # 從開發者平臺得到
appkey = '你的appkey ' # 從開發者平臺得到
用來生成需要位數的隨機字符
def roda(num):
a = ''
for i in range(0, num):
a = a + random.choice('abcdefghijklmnopqrstuvwxyz123456789')
return a
介面鑒權撰寫
官方解釋
用于計算簽名的引數在不同介面之間會有差異,但演算法程序固定如下4個步驟,
1…將<key, value>請求引數對按key進行字典升序排序,得到有序的引數對串列N
2.將串列N中的引數對按URL鍵值對的格式拼接成字串,得到字串T(如:key1=value1&key2=value2),URL鍵值拼接程序value部分需要URL編碼,URL編碼演算法用大寫字母,例如%E8,而不是小寫%e8
3.將應用密鑰以app_key為鍵名,組成URL鍵值拼接到字串T末尾,得到字串S(如:key1=value1&key2=value2&app_key=密鑰)
4.對字串S進行MD5運算,將得到的MD5值所有字符轉換成大寫,得到介面請求簽名
實際撰寫
def sortDict(data):
return dict(sorted(data.items(), key=operator.itemgetter(0), reverse=False))
def getReqSign(params, appkey):
# 1. 字典升序排序
params1=sortDict(params)
# 2. 拼按URL鍵值對
str1 = parse.urlencode(params1)
# 3. 拼接app_key
str1 = str1 + '&' + 'app_key=' + appkey
# 4. MD5運算并轉換大寫,回傳請求簽名
m = hashlib.md5()
m.update(str1.encode())
str_md5 = m.hexdigest()
return str_md5.upper()
利用wave模塊保存錄音
def save_wave_file(pa, filename, data):
wf = wave.open(filename, 'wb')
wf.setnchannels(1)
wf.setsampwidth(pa.get_sample_size(paInt16))
wf.setframerate(16000)
print(type(data))
wf.writeframes(b"".join(data))
wf.close()
使用pyaudio錄音
def get_audio(filepath): # 錄音實作
print("請開始說話:") # 提示文本
pa = PyAudio()
stream = pa.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK)
print("*" * 10, "開始錄音:請在5秒內輸入語音")
frames = [] # 定義一個串列
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): # 回圈,采樣率 44100 / 1024 * 5
data = stream.read(CHUNK) # 讀取chunk個位元組 保存到data中
frames.append(data) # 向串列frames中添加資料data吃
print("*" * 10, "錄音結束\n")
stream.stop_stream()
stream.close() # 關閉
pa.terminate() # 終結
save_wave_file(pa, filepath, frames)
使用pyaudio播放
def play(fname):
ding_wav = wave.open(fname, 'rb')
ding_data = ding_wav.readframes(ding_wav.getnframes())
with no_alsa_error():
audio = PyAudio()
stream_out = audio.open(
format=audio.get_format_from_width(ding_wav.getsampwidth()),
channels=ding_wav.getnchannels(),
rate=ding_wav.getframerate(), input=False, output=True)
stream_out.start_stream()
stream_out.write(ding_data)
time.sleep(0.2)
stream_out.stop_stream()
stream_out.close()
audio.terminate()
語音識別
1.請求引數
| 引數名稱 | 是否必選 | 資料型別 | 資料約束 | 示例資料 | 描述 |
|---|---|---|---|---|---|
| app_id | 是 | int | 正整數 | 1000001 | 應用標識(AppId) |
| time_stamp | 是 | int | 正整數 | 1493468759 | 請求時間戳(秒級) |
| nonce_str | 是 | string | 非空且長度上限32位元組 | fa577ce340859f9fe | 隨機字串 |
| sign | 是 | string | 非空且長度固定32位元組 | 簽名資訊,詳見介面鑒權 | |
| format 是 | int | 正整數 | 2 | 語音壓縮格式編碼,定義見下文描述 | |
| speech | 是 | string | 語音資料的Base64編碼,非空且長度上限8MB | 待識別語音(時長上限15s) | |
| rate | 否 | int | 正整數 | 16000 | 語音采樣率編碼,定義見下文描述,(不傳)默認即16KHz |
語音壓縮格式編碼
| 格式名稱 | 格式編碼 |
|---|---|
| PCM | 1 |
| WAV | 2 |
| AMR | 3 |
| SILK | 4 |
語音采樣率編碼
| 采樣率 | 編碼 |
|---|---|
| 8KHz | 8000 |
| 16KHz | 16000 |
2. 回應引數
| 引數名稱 | 是否必選 | 資料型別 | 描述 |
|---|---|---|---|
| ret | 是 | int | 回傳碼; 0表示成功,非0表示出錯 |
| msg | 是 | string | 回傳資訊;ret非0時表示出錯時錯誤原因 |
| data | 是 | object | 回傳資料;ret為0時有意義 |
| + format | 是 | int | API請求中的格式編碼 |
| + rate | 是 | int | API請求中的采樣率編碼 |
| + text | 是 | string | 語音識別結果(UTF-8編碼) |
撰寫示例
def get_text():
get_audio('ceshi.wav') # 錄音
fwave = open('ceshi.wav', mode='rb').read() # 打開錄音檔案
base64Wav = base64.b64encode(fwave).decode('utf8') # 進行編碼(騰訊api要求base64編碼)
params = {'app_id': app_id,
'format': '2',
'rate': '16000',
'speech': base64Wav, # base64編碼的語音資料
'time_stamp': int(time.time()), # 時間戳
'nonce_str': roda(10)}
params['sign'] = getReqSign(params, appkey) # 得到介面鑒權
# print(params)
url = 'https://api.ai.qq.com/fcgi-bin/aai/aai_asr'
resp = requests.post(url, params) # post請求
return json.loads(resp.text).get('data').get('text') #回傳識別到的文本
得到回答
1. 請求引數
| 引數名稱 | 是否必選 | 資料型別 | 資料約束 | 示例資料 | 描述 |
|---|---|---|---|---|---|
| app_id | 是 | int | 正整數 | 1000001 | 應用標識(AppId) |
| time_stamp | 是 | int | 正整數 | 1493468759 | 請求時間戳(秒級) |
| nonce_str | 是 | string | 非空且長度上限32位元組 | fa577ce340859f9fe | 隨機字串 |
| sign | 是 | string | 非空且長度固定32位元組 | 簽名資訊,詳見介面鑒權 | |
| session | 是 | string | UTF-8編碼,非空且長度上限32位元組 | 10000 | 會話標識(應用內唯一) |
| question | 是 | string | UTF-8編碼,非空且長度上限300位元組 | 你叫啥 | 用戶輸入的聊天內容 |
2. 回應引數
| 引數名稱 | 是否必選 | 資料型別 | 描述 |
|---|---|---|---|
| ret | 是 | int | 回傳碼; 0表示成功,非0表示出錯 |
| msg | 是 | string | 回傳資訊;ret非0時表示出錯時錯誤原因 |
| data | 是 | object | 回傳資料;ret為0時有意義 |
| session | 是 | string | UTF-8編碼,非空且長度上限32位元組 |
| answer | 是 | string | UTF-8編碼,非空 |
撰寫示例
def get_chat_text(text): # 得到回答
paramsd = {
'app_id': app_id,
'session': '10000',
'question': text, # 問題文本
'time_stamp': int(time.time()),
'nonce_str': roda(17),
}
paramsd['sign'] = getReqSign(paramsd, appkey)
urld = 'https://api.ai.qq.com/fcgi-bin/nlp/nlp_textchat'
respd = requests.post(urld, paramsd)
return json.loads(respd.text).get('data').get('answer') # 回傳回答文本
語音合成
1. 請求引數
| 引數名稱 | 是否必選 | 資料型別 | 資料約束 | 示例資料 | 描述 |
|---|---|---|---|---|---|
| app_id | 是 | int | 正整數 | 1000001 | 應用標識(AppId) |
| time_stamp | 是 | int | 正整數 | 1493468759 | 請求時間戳(秒級) |
| nonce_str | 是 | string | 非空且長度上限32位元組 | fa577ce340859f9fe | 隨機字串 |
| sign | 是 | string | 非空且長度固定32位元組 | 簽名資訊,詳見介面鑒權 | |
| speaker | 是 | int | 正整數 | 1 | 語音發音人編碼,定義見下文描述 |
| format | 是 | int | 正整數 | 2 | 合成語音格式編碼,定義見下文描述 |
| volume | 是 | int | [-10, 10] | 0 | 合成語音音量,取值范圍[-10, 10],如-10表示音量相對默認值小10dB,0表示默認音量,10表示音量相對默認值大10dB |
| speed | 是 | int | [50, 200] | 100 | 合成語音語速,默認100 |
| text | 是 | string | UTF-8編碼,非空且長度上限150位元組 | 騰訊,你好! | 待合成文本 |
| aht | 是 | int | [-24, 24] | 0 | 合成語音降低/升高半音個數,即改變音高,默認0 |
| apc | 是 | int | [0, 100] | 58 | 控制頻譜翹曲的程度,改變說話人的音色,默認58 |
語音發音人編碼
| 發音人 | 編碼 |
|---|---|
| 普通話男聲 | 1 |
| 靜琪女聲 | 5 |
| 歡馨女聲 | 6 |
| 碧萱女聲 | 7 |
合成語音格式編碼
| 格式名稱 | 編碼 |
|---|---|
| PCM | 1 |
| WAV | 2 |
| MP3 | 3 |
2. 回應引數
| 引數名稱 | 是否必選 | 資料型別 | 描述 |
|---|---|---|---|
| ret | 是 | int | 回傳碼; |
| msg | 是 | string | 回傳資訊;ret非0時表示出錯時錯誤原因 |
| data | 是 | object | 回傳資料;ret為0時有意義 |
| + format | 是 | int | API請求中的格式編碼 |
| + speech | 是 | string | 合成語音的base64編碼資料 |
| + md5sum | 是 | string | 合成語音的md5摘要(base64編碼之前) |
base64解碼及寫入檔案
def ToFile(voicex, file):
base64_data = voicex
ori_image_data = base64.b64decode(base64_data)
fout = open(file, 'wb')
fout.write(ori_image_data)
fout.close()
撰寫示例
def get_voice(text):
test = {
'app_id': app_id,
'speaker': '6',
'format': '2',
'volume': '0',
'speed': '100',
'text': text,
'aht': '0',
'apc': '58',
'time_stamp': int(time.time()),
'nonce_str': roda(17),
}
test['sign'] = getReqSign(test, appkey)
url2 = 'https://api.ai.qq.com/fcgi-bin/aai/aai_tts'
resp2 = requests.post(url2, test)
voicex=json.loads(resp2.text).get('data').get('speech')
ToFile(str(voicex), 'audio.txt')
ToFile(voicex, 'audio.mp3')
return 'audio.mp3'
測驗snowboy以及修改demo
測驗snowboy熱詞喚醒功能
終端打開目錄 snowboy/examples/Python3
cd snowboy/examples/Python3
開始運行,喊一聲snowboy就可以聽到叮的一聲
python3 demo.py resources/models/snowboy.umdl
修改Demo
interrupted = False
def signal_handler(signal, frame):
global interrupted
interrupted = True
def interrupt_callback():
global interrupted
return interrupted
# 回呼函式,語音識別在這里實作,修改也是在這里
def callbacks():
global detector
time.sleep(0.2)
your_text=['哎,我在,你說','我來啦,我來啦,我來啦~','我是你的語音助手小貝']
a=random.randint(1,3)
print('小貝'+your_text[a])
play('huda/xiaobeihuida'+ str(a) +'.wav') # 為喚醒詞事先準備好的回答
time.sleep(0.2)
try:
a = get_text()
if a =='嗯' or '':
continue
print('你:'+a)
b =get_chat_text(a)
print('小貝:'+b)
c = get_voice(b)
play(c)
except Exception:
print('exception happened...')
@contextmanager
def no_alsa_error():
try:
asound = cdll.LoadLibrary('libasound.so')
asound.snd_lib_error_set_handler(c_error_handler)
yield
asound.snd_lib_error_set_handler(None)
except:
yield
pass
def wake_up():
global detector
model = 'xiaobeixiaobei.pmdl' # 我的喚醒詞為 小貝小貝
# 終止方法為ctrl+c
signal.signal(signal.SIGINT, signal_handler)
# 喚醒詞檢測函式,調整sensitivity引數可修改喚醒詞檢測的準確性
detector = snowboydecoder.HotwordDetector(model, sensitivity=0.5)
print('正在聆聽... 請說喚醒詞:小貝小貝')
# main loop
# 回呼函式 detected_callback=snowboydecoder.play_audio_file
# 修改回呼函式可實作我們想要的功能
detector.start(detected_callback=callbacks, # 自定義回呼函式
interrupt_check=interrupt_callback,
sleep_time=0.03)
# 釋放資源
detector.terminate()
#程式入口
if __name__ == "__main__":
wake_up()
后續延伸
修改回呼函式可以完成更多作業
語音控制智能機器人
與arduino使用uart通信可實作智能控制機器人
等待后續更新
已經更新傳送門
語音控制家庭智能家居中心
加入mqtt可以作為語音控制家庭智能家居中心
等待后續更新
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/146446.html
標籤:其他
上一篇:玩轉華為云,ModelArts深度學習建模最全搭建手冊
下一篇:縱橫美國思維導圖學習