基于FCN的深度學習極化SAR影像處理
本次想要做一個關于深度學習的極化SAR影像處理系列(我們關于極化SAR影像處理現在更多的是語意分割)FCN (已完成)U-net(還在寫)、Deeplab(已完成)、Yolo(正在學習),
想做這件事的主要有如下三個原因:
一、是對剛開始一年的合肥工業大學研究生學習生活中一些基礎知識的總結,
二、在學習程序中受到了中科大等前輩的指導,讓我覺得學習程序中有人適當的幫助可以加快進度,
三、希望在CSDN大佬的幫助下能夠學到更多知識,我們往往在研究生生活中只關注自己方向、而忽視其他學習的可能性,
需要的軟體:Polsarpro(最強極化SAR影像處理軟體)我主要用他來做影像特征的提取,也可以做一些傳統的分類比如SVM(支持向量機)、Wishart監督分類、非監督分類等,
華東師大的禾欠水前輩—做過相關介紹與指導,
Polsarpro的使用
Pycharm:Python開發平臺,Python應該學會python基礎的使用以及tensorflow、cv2、matplotlib、numpy、一些機器學習的基礎知識,
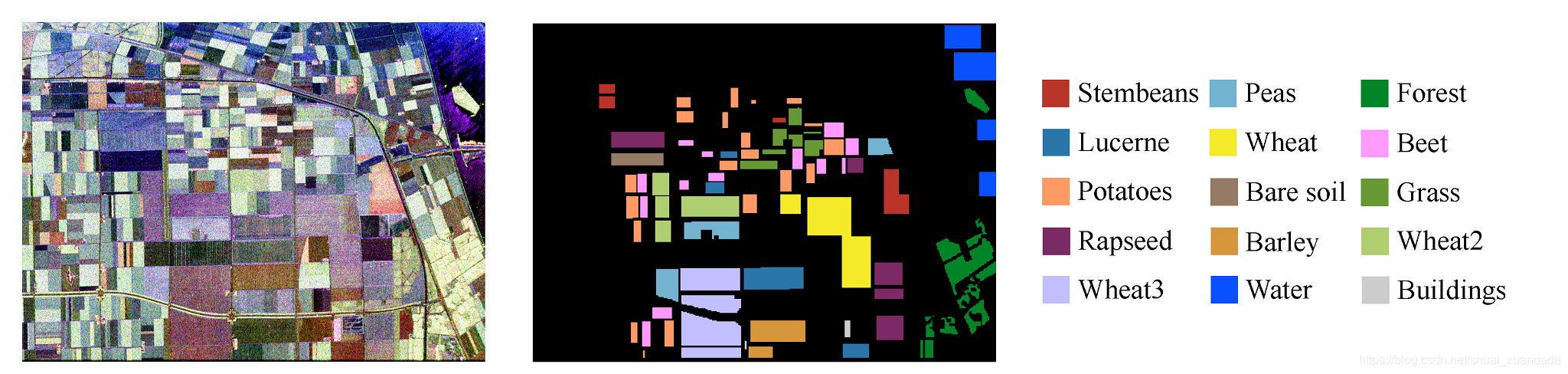
標簽工具:學會如何使用labelme工具,效果如下
硬體配置部分:i7處理器、英偉達P4000 GPU 、32G物理記憶體
文章參考了:中科大前輩的代碼(在這感謝科大前輩)
CreateBig先生的框架書寫
這里介紹了CNN與FCN之間的對比
《Fully Convolutional Networks for Semantic Segmentation》一文介紹了FCN的全部原理,是一篇非常經典的論文,
《改進型 DeepLab 的極化 SAR 果園分類》這篇論文清楚的告訴了我如何系統性,設計一個代碼程序的思路,
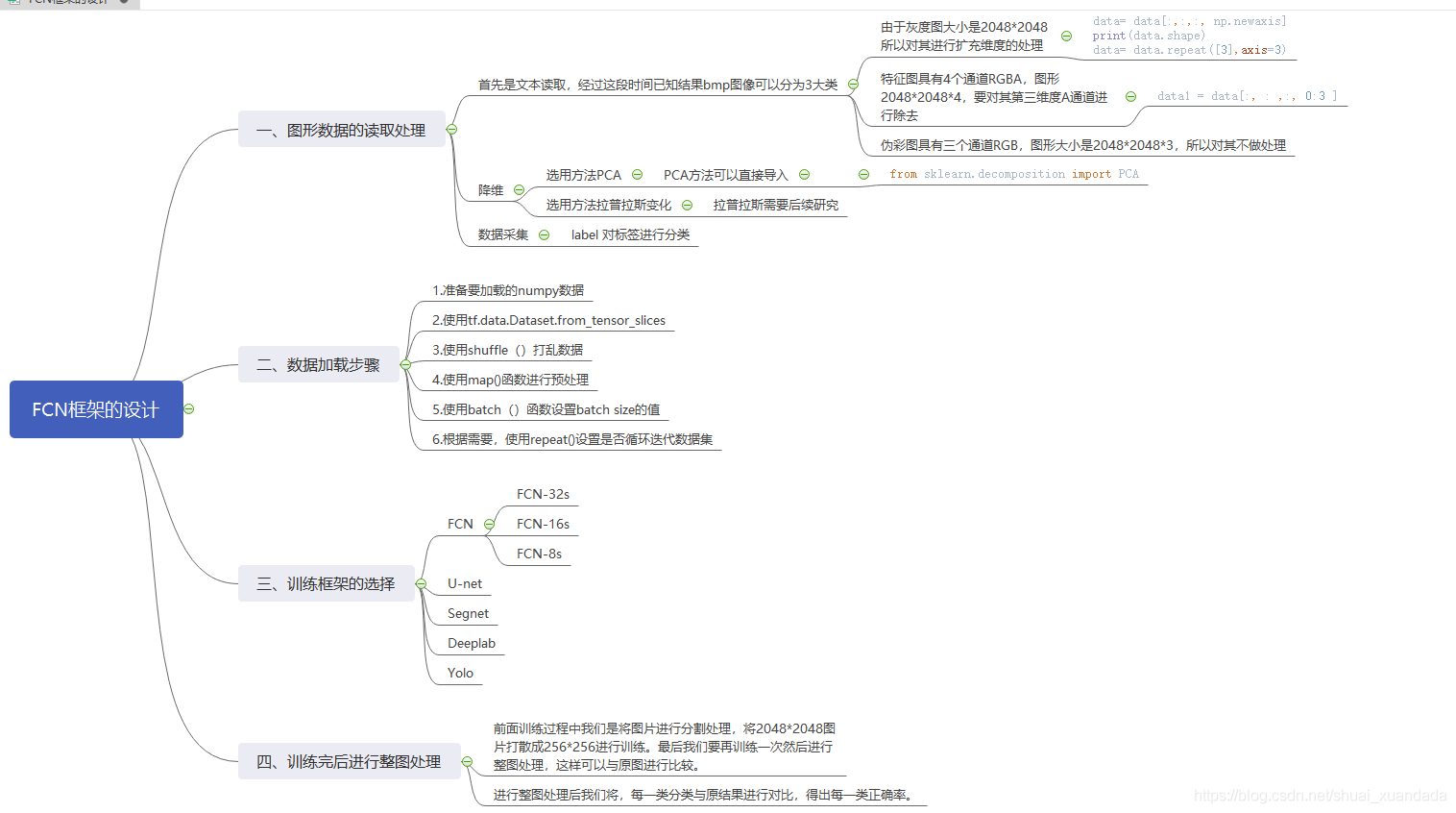
整個框架大致的操作程序,我做了一個簡易的思維導圖
代碼部分:
#trains 部分
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import matplotlib.image as mpimg
import numpy as np
import tensorflow as tf
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import cv2
from transition import convert
from numpy import random
from tensorflow.keras import optimizers
from FCN_model import MyModel
from data_procession import padding,cut_image,combination
def main():
data1 = []
data2 = []
data3 = []
img_w = 256
img_h = 256
Buffer_size = 100
Batch_size =8
path = r'特征提取處'
for i in os.walk(r'特征提取處'):
print(i)
i = i[2]
for j in range(5): # 多少個特征自己設定
a = mpimg.imread(path + '\\%s' % i[j])
#a = np.array(a)
if a.shape == (2048,2048):
data1.append(a)
elif a.shape == (2048,2048,3):
data2.append(a)
else:
data3.append(a)
data1 = np.array(data1)
data2 = np.array(data2)
data3 = np.array(data3)
data1 = data1[:, :, :, np.newaxis] #灰度圖擴充維度
data1 = data1.repeat([3], axis=3)
data3 =data3[:,:,:,0:3] #特征圖RGBA四通道,除去A通道
data4 = np.row_stack((data1, data2))
data4 = np.row_stack((data4, data3))
print(data4.shape)
#進行降維措施
data5 = data4.reshape(5,-1)
data5 = np.transpose(data5)
pca = PCA(n_components=3)
data6 = pca.fit_transform(data5)
print(data6.shape)
data6 = np.transpose(data6)
print(data6.shape)
data7 = data6.reshape(3,2048,2048,3) #重新重組成三個圖片
a = data7[0]
b = data7[1]
c = data7[2]
print(tf.reduce_max(a))
print(tf.reduce_max(b))
print(tf.reduce_max(c))#根據你得圖片最大的像素來得到值,進行歸一化處理.
d = a / 257
e = b / 248
f = c / 229
d = d.astype(np.float32)
e = e.astype(np.float32)
f = f.astype(np.float32)
#開始進行繪圖處理進行灰度圖處理,將 2048*2048*3 --> 2048 * 2048
map1 = cv2.cvtColor(d, cv2.COLOR_RGB2GRAY)
map2= cv2.cvtColor(e, cv2.COLOR_RGB2GRAY)
map3 = cv2.cvtColor(f, cv2.COLOR_RGB2GRAY)
plt.figure('grey-scale map1',figsize=(12,12),dpi=80)
plt.imshow(map1)
plt.figure('grey-scale map2',figsize=(12,12),dpi=80)
plt.imshow(map2)
plt.figure('grey-scale map3',figsize=(12,12),dpi=80)
plt.imshow(map2)
plt.show()
set = [map1,map2,map3]
data_train = []
for i in range(3):
data_train.append(set[i])
data_train = np.array(data_train) #data_train:(3,2048,2048)
data_train = data_train.reshape(3,-1)
data_train = np.transpose(data_train)
data_train = data_train.reshape(2048,2048,3) #(2048,2048,3)
img_l = tf.io.read_file(r'label.png')
img_l = tf.image.decode_png(img_l)
img_l = np.array(img_l)
l = cv2.cvtColor(img_l,cv2.COLOR_RGB2GRAY)#將標簽圖 也做成RGB灰度圖
b = [15, 38, 53, 75, 90, 113]
converted = convert(l,b) #生成標簽的程序
print('converted:\n',converted.shape)
#這一段就是資料采集、訓練集合生成的程序 可以按照個人喜好隨機分配
print('Ground Truth(label) and dataset: ')
count = 0
judgement = 0
train = []
test = []
label_train = []
label_test = []
X_height, X_width ,Channel= data_train.shape #一次性賦予像素及通道
print(data_train.shape)
while count < 4000:
if judgement % 2 == 0:
random_width = random.randint(0, X_width - img_w -1)
random_height = random.randint(0, X_height - img_h - 1)
else:
random_height = random.randint(0, X_height - img_h -1)
random_width = random.randint(0, X_width - img_w -1)
judgement += 1
count += 1
data_collect = data_train[random_height : random_height + img_h , random_width :random_width + img_w, :]
label_collect = converted[random_height : random_height + img_h , random_width :random_width + img_w]
if count <= 3000:
train.append(data_collect)
label_train.append(label_collect)
else:
test.append(data_collect)
label_test.append(label_collect)
#訓練集像素值轉換到(-1,1)之間
train = tf.cast(train, tf.float32) * 2 -1
test = tf.cast(test, tf.float32) * 2 -1
label_train = np.expand_dims(label_train, axis =3)
print(label_train.shape)
label_test = np.expand_dims(label_test, axis =3) #4個維度分別是:圖片數量、影像高度、影像寬帶、標簽0-7
print(label_test.shape)
dataset_train = tf.data.Dataset.from_tensor_slices((train, label_train))
dataset_test = tf.data.Dataset.from_tensor_slices((test, label_test))
print(dataset_train)
print(dataset_test) #((256,256,3),(256,256,1)),types:(tf.float32,tf.uint8)>
dataset_train = dataset_train.shuffle(Buffer_size).batch(Batch_size)
dataset_train = dataset_train.prefetch(buffer_size = tf.data.experimental.AUTOTUNE)
dataset_test = dataset_test.batch((Batch_size))
for img,musk in dataset_train.take(1):
plt.figure('256*256 picture and 256*256Ground Truth: ',figsize = (12,12), dpi = 80)
plt.subplot(4, 2 ,1)
plt.imshow(tf.keras.preprocessing.image.array_to_img(img[0]))
plt.subplot(4, 2, 2)
plt.imshow(tf.keras.preprocessing.image.array_to_img(musk[0]))
plt.subplot(4, 2 ,3)
plt.imshow(tf.keras.preprocessing.image.array_to_img(img[1]))
plt.subplot(4, 2, 4)
plt.imshow(tf.keras.preprocessing.image.array_to_img(musk[1]))
plt.subplot(4, 2, 5)
plt.imshow(tf.keras.preprocessing.image.array_to_img(img[2]))
plt.subplot(4, 2, 6)
plt.imshow(tf.keras.preprocessing.image.array_to_img(musk[2]))
plt.subplot(4, 2, 7)
plt.imshow(tf.keras.preprocessing.image.array_to_img(img[3]))
plt.subplot(4, 2, 8)
plt.imshow(tf.keras.preprocessing.image.array_to_img(musk[3]))
plt.show()
conv_net = MyModel(7)
optimizer = optimizers.Adam(lr=1e-4)
variables = conv_net.trainable_variables
for epoch in range(200):
for step, (x, y) in enumerate(dataset_train):
with tf.GradientTape() as tape:
# [b, 256, 256, 3] => [b, 256, 256, 7]
logits = conv_net(x)
# 計算總共的損失總量,然后求平均
loss = tf.losses.sparse_categorical_crossentropy(y, logits, from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(grads, variables))
if step % 100 == 0:
print(epoch, step, 'loss:', float(loss))#當前的迭代次數,當前的步驟,以及當前步驟的損失總量
total_num = 0
total_correct = 0
for x, y in dataset_test:
logits = conv_net(x)
prob = tf.nn.softmax(logits, axis=3)
pred = tf.argmax(prob, axis=3)
pred = tf.cast(pred, dtype=tf.int32)
#經過conv_net、softmax以及argmax資料形狀以及從[8,256,256,,3]-->[8,256,256,7]-->[8,256,256]
y = tf.squeeze(y, axis=3)
#所以這里的情況就是將y的形狀從[8,256,256,1]-->[8,256,256]
y = tf.cast(y, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num / x.shape[1] / x.shape[2]
print(epoch, 'acc:', acc)
for image, mask in dataset_test.take(1):
pred_mask = conv_net.predict(image)
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
num = 3
plt.figure('256*256picture、label、pred:',figsize=(10, 10),dpi=80)
for i in range(num):
plt.subplot(num, 3, i * num + 1)
plt.imshow(tf.keras.preprocessing.image.array_to_img(image[i]))
plt.subplot(num, 3, i * num + 2)
plt.imshow(tf.keras.preprocessing.image.array_to_img(mask[i]))
plt.subplot(num, 3, i * num + 3)
plt.imshow(tf.keras.preprocessing.image.array_to_img(pred_mask[i]))
plt.show()
#前面代碼,我們將一張完整的圖片隨機取樣、打散選取4000張圖片然后進行訓練、預測,這一段代碼我們將圖片進行補全、剪切、以及最終合成一張圖片
data_train = padding(data_train,2048)
plt.imshow(tf.keras.preprocessing.image.array_to_img(data_train))
plt.show()#這里可以展示一下我們所有提取出來的特征圖融合成一張圖片三通道偽彩圖的樣子
data_train = tf.cast(data_train, tf.float32) * 2 - 1
data_train = cut_image(data_train, 256)
data_train = np.array(data_train)
print('data_train.shape:\n', data_train.shape)
data_all = tf.data.Dataset.from_tensor_slices(data_train)
data_all = data_all.batch(Batch_size)
s = []
for x in data_all:
logits = conv_net(x)
prob = tf.nn.softmax(logits, axis =3)
pred = tf.argmax(prob, axis =3)
pred = tf.cast(pred, dtype = tf.int32)
s.append(pred)
s = np.array(s)
s = s.reshape(64, 256, 256)
print(s.shape)
s = combination(s)
s = np.array(s)
print(s.shape)
print(np.unique(s))
x1 = converted
x2 = s
color1 = [0, 0, 0, 0, 0, 0, 0]
color2 = [0, 0, 0, 0, 0, 0, 0]
color3 = [0, 0, 0, 0, 0, 0, 0]
color4 = [0, 0, 0, 0, 0, 0, 0]
color5 = [0, 0, 0, 0, 0, 0, 0]
color6 = [0, 0, 0, 0, 0, 0, 0]
color7 = [0, 0, 0, 0, 0, 0, 0]
for i in range(2048):
for j in range(2048):
if (x1[i][j] == x2[i][j]):
if (x1[i][j] == 0):
color1[0] += 1
elif (x1[i][j] == 1):
color2[1] += 1
elif (x1[i][j] == 2):
color3[2] += 1
elif (x1[i][j] == 3):
color4[3] += 1
elif (x1[i][j] == 4):
color5[4] += 1
elif (x1[i][j] == 5):
color6[5] += 1
elif (x1[i][j] == 6):
color7[6] += 1
for i in range(2048):
for j in range(2048):
if (x1[i][j] != x2[i][j]):
if (x1[i][j] == 0):
if (x2[i][j] == 1):
color1[1] += 1
elif (x2[i][j] == 2):
color1[2] += 1
elif (x2[i][j] == 3):
color1[3] += 1
elif (x2[i][j] == 4):
color1[4] += 1
elif (x2[i][j] == 5):
color1[5] += 1
elif (x2[i][j] == 6):
color1[6] += 1
if (x1[i][j] == 1):
if (x2[i][j] == 0):
color2[0] += 1
elif (x2[i][j] == 2):
color2[2] += 1
elif (x2[i][j] == 3):
color2[3] += 1
elif (x2[i][j] == 4):
color2[4] += 1
elif (x2[i][j] == 5):
color2[5] += 1
elif (x2[i][j] == 6):
color2[6] += 1
elif (x1[i][j] == 2):
if (x2[i][j] == 0):
color3[0] += 1
elif (x2[i][j] == 1):
color3[1] += 1
elif (x2[i][j] == 3):
color3[3] += 1
elif (x2[i][j] == 4):
color3[4] += 1
elif (x2[i][j] == 5):
color3[5] += 1
elif (x2[i][j] == 6):
color3[6] += 1
elif (x1[i][j] == 3):
if (x2[i][j] == 0):
color4[0] += 1
elif (x2[i][j] == 1):
color4[1] += 1
elif (x2[i][j] == 2):
color4[2] += 1
elif (x2[i][j] == 4):
color4[4] += 1
elif (x2[i][j] == 5):
color4[5] += 1
elif (x2[i][j] == 6):
color4[6] += 1
elif (x1[i][j] == 4):
if (x2[i][j] == 0):
color5[0] += 1
elif (x2[i][j] == 1):
color5[1] += 1
elif (x2[i][j] == 2):
color5[2] += 1
elif (x2[i][j] == 3):
color5[3] += 1
elif (x2[i][j] == 5):
color5[5] += 1
elif (x2[i][j] == 6):
color5[6] += 1
elif (x1[i][j] == 5):
if (x2[i][j] == 0):
color6[0] += 1
elif (x2[i][j] == 1):
color6[1] += 1
elif (x2[i][j] == 2):
color6[2] += 1
elif (x2[i][j] == 3):
color6[3] += 1
elif (x2[i][j] == 4):
color6[4] += 1
elif (x2[i][j] == 6):
color5[6] += 1
elif (x1[i][j] == 6):
if (x2[i][j] == 0):
color7[0] += 1
elif (x2[i][j] == 1):
color7[1] += 1
elif (x2[i][j] == 2):
color7[2] += 1
elif (x2[i][j] == 3):
color7[3] += 1
elif (x2[i][j] == 4):
color7[4] += 1
elif (x2[i][j] == 5):
color7[5] += 1
print('color1顏色的準確率:', color1[0] / np.sum(color1))
print('color2顏色的準確率:', color2[1] / np.sum(color2))
print('color3顏色的準確率:', color3[2] / np.sum(color3))
print('color4顏色的準確率:', color4[3] / np.sum(color4))
print('color5顏色的準確率:', color5[4] / np.sum(color5))
print('color6顏色的準確率:', color6[5] / np.sum(color6))
print('color7顏色的準確率:', color7[6] / np.sum(color7))
s = np.expand_dims(s, axis=2)
plt.imshow(tf.keras.preprocessing.image.array_to_img(s))
plt.show()
if __name__ == '__main__':
main()#FCN_model部分
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, Conv2DTranspose, Add
from tensorflow.keras.layers import Dropout, Input
from tensorflow.keras.initializers import Constant
def bilinear_upsample_weights(factor, number_of_classes):
filter_size = factor * 2 - factor % 2
factor = (filter_size + 1) // 2
if filter_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:filter_size, :filter_size]
upsample_kernel = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)
weights = np.zeros((filter_size, filter_size, number_of_classes, number_of_classes),
dtype=np.float32)
for i in range(number_of_classes):
weights[:, :, i, i] = upsample_kernel
return weights
class MyModel(tf.keras.Model):
def __init__(self, NUM_OF_CLASSESS):
super().__init__()
vgg16_model = self.load_vgg()
self.conv1_1 = vgg16_model.layers[1]
self.conv1_2 = vgg16_model.layers[2]
self.pool1 = vgg16_model.layers[3]
# (128,128)
self.conv2_1 = vgg16_model.layers[4]
self.conv2_2 = vgg16_model.layers[5]
self.pool2 = vgg16_model.layers[6]
# (64,64)
self.conv3_1 = vgg16_model.layers[7]
self.conv3_2 = vgg16_model.layers[8]
self.conv3_3 = vgg16_model.layers[9]
self.pool3 = vgg16_model.layers[10]
# (32,32)
self.conv4_1 = vgg16_model.layers[11]
self.conv4_2 = vgg16_model.layers[12]
self.conv4_3 = vgg16_model.layers[13]
self.pool4 = vgg16_model.layers[14]
# (16,16)
self.conv5_1 = vgg16_model.layers[15]
self.conv5_2 = vgg16_model.layers[16]
self.conv5_3 = vgg16_model.layers[17]
self.pool5 = vgg16_model.layers[18]
self.conv6 = Conv2D(4096, (7, 7), (1, 1), padding="same", activation="relu")
self.drop6 = Dropout(0.5)
self.conv7 = Conv2D(4096, (1, 1), (1, 1), padding="same", activation="relu")
self.drop7 = Dropout(0.5)
self.score_fr = Conv2D(NUM_OF_CLASSESS, (1, 1), (1, 1), padding="valid", activation="relu")
self.score_pool4 = Conv2D(NUM_OF_CLASSESS, (1, 1), (1, 1), padding="valid", activation="relu")
self.conv_t1 = Conv2DTranspose(NUM_OF_CLASSESS, (4, 4), (2, 2), padding="same")
self.fuse_1 = Add()
self.conv_t2 = Conv2DTranspose(NUM_OF_CLASSESS, (4, 4), (2, 2), padding="same")
self.score_pool3 = Conv2D(NUM_OF_CLASSESS, (1, 1), (1, 1), padding="valid", activation="relu")
self.fuse_2 = Add()
self.conv_t3 = Conv2DTranspose(NUM_OF_CLASSESS, (16, 16), (8, 8), padding="same", activation="sigmoid",
kernel_initializer=Constant(bilinear_upsample_weights(8, NUM_OF_CLASSESS)))
def call(self, input):
x = self.conv1_1(input)
x = self.conv1_2(x)
x = self.pool1(x)
x = self.conv2_1(x)
x = self.conv2_2(x)
x = self.pool2(x)
x = self.conv3_1(x)
x = self.conv3_2(x)
x = self.conv3_3(x)
x_3 = self.pool3(x)
x = self.conv4_1(x_3)
x = self.conv4_2(x)
x = self.conv4_3(x)
x_4 = self.pool4(x)
x = self.conv5_1(x_4)
x = self.conv5_2(x)
x = self.conv5_3(x)
x = self.pool5(x)
x = self.conv6(x)
x = self.drop6(x)
x = self.conv7(x)
x = self.drop7(x)
x = self.score_fr(x) # 第5層pool分類結果
x_score4 = self.score_pool4(x_4) # 第4層pool分類結果
x_dconv1 = self.conv_t1(x) # 第5層pool分類結果上采樣
x = self.fuse_1([x_dconv1, x_score4]) # 第4層pool分類結果+第5層pool分類結果上采樣
x_dconv2 = self.conv_t2(x) # 第一次融合后上采樣
x_score3 = self.score_pool3(x_3) # 第三次pool分類
x = self.fuse_2([x_dconv2, x_score3]) # 第一次融合后上采樣+第三次pool分類
x = self.conv_t3(x) # 上采樣
return x
def load_vgg(self):
# 加載vgg16模型,其中注意input_tensor,include_top
vgg16_model = tf.keras.applications.vgg16.VGG16(weights='imagenet', include_top=False,
input_tensor=Input(shape=(256, 256, 3)))
for layer in vgg16_model.layers[:18]:
layer.trainable = True
vgg16_model.summary()
return vgg16_model
#data_procession部分
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import numpy as np
def padding(a,target_length):#將圖片進行處理,如果原始影像就是正方形-->這一步就不做處理
a_height, a_width, a_channel = a.shape
if a_height < target_length:
b = [[[0 for channel in range(a_channel)] for col in range(a_width)] for row in range(target_length - a_height)]
a = np.concatenate((a,b), axis = 0)
elif a_width < target_length:
b = [[[0 for channel in range(a_channel)] for col in range(target_length - a_width)] for row in range(a_height)]
a = np.concatenate((a, b), axis=1)
return a
#將完整的2048*2048圖片切成256*256進行訓練
def cut_image(image,child_length):
a_height, a_width, channels = image.shape
data = []
num = a_height // child_length
for i in range(num):
for j in range(num):
b = image[i*child_length:(i+1)*child_length,j*child_length:(j+1)*child_length]
data.append(b)
c = np.array(data)
print('剪切過后的data形狀', c.shape)
return data
#我們之所以見資料剪切是因為,我們設定的FCN框架是[256,256,3],但是我們希望展示的是一個整圖的設計,所以我們將圖片安裝順序拼接,前面是隨機打散,但是這里是正常順序
def combination(a):
total_num, a_height, a_width = a.shape #64,256,256
num = np.sqrt(total_num)
num = int(num)
row_num = num * a_height
col_num = num * a_width
data = [[0 for col in range(col_num)] for row in range(row_num)]
data = np.array(data)
for i in range(num):
for j in range(num):
data[i * a_height:(i + 1) * a_height, j * a_width:(j + 1) * a_width] = a[i * num + j]
return data
#transition部分
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import matplotlib.pyplot as plt
import cv2
import tensorflow as tf
import numpy as np
def convert(a,b):
c = np.array(b)
q = len(c)
map_width,map_height = a.shape #2048,2048
for i in range(map_width):
for j in range(map_height):
for k in range(q):
if a[i][j] == b[k]:
a[i][j] = k+1
return a #這個步驟的根本原因就在于把像素轉換成對應的標簽,由于黑色等同于 0 所以最終得到保留,比如我這里設定的是六類標簽實際 會得到7項0—6的數值
def main():
img = tf.io.read_file(r'label.png')
img = tf.image.decode_png(img) #解壓資料得到標簽的像素值
img = np.array(img)
img_label = cv2.cvtColor(img,cv2.COLOR_RGB2GRAY)
print(np.unique(img_label))#可以到每一個標簽的像素值方便人們比較,得到數值不用取0 ,方便后續做標簽,
plt.figure('label.shape',figsize=(15,15), dpi=80)
plt.imshow(img_label)
plt.show()
if __name__ == '__main__':
main()轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/161841.html
標籤:其他