Module 6: Advanced text processing 2
- 前言
- question1:The first "the"
- question2:The letter "e"
- Question3:Ouput abrigdements
- Question4:The use of semicolons
- 總結
前言
我盡可能做詳細,每個步驟講清楚,答案不止一種,有大神可以留言,其他章節在我的主頁可以查看,文中空行和#注釋不算講解的代碼行數,查代碼行數的時候可以直接跳過,
question1:The first “the”
The most common word in the English language is the definite article “the”, according to an analysis of the Oxford English text corpus. In our novel, the most common word is in fact “the”, with a word frequency of about 4.2%.
In which part of a sentence is the word “the” most commonly used? Write a program that iterates over the provided jane_eyre_sentences.txt file and prints out the position of the first occurrence of the word “the” in each sentence.
For sentences that don’t contain “the”, print out the word “missing”. Your program should be case-insensitive, such that upper case as well as lower case words get counted.
The provided file contains the first 20 sentences of the novel. Here’s what the output of your program for these sentences should look like:
The first sentence doesn’t contain “the”, so your program should print missing here. Then, the next sentence,
We had been wandering indeed in the leafless shrubbery
has “the” appearing as the sixth word (starting to count from zero), so your program should print out the index 6. Make sure your program finds the “The”'s at the beginning of sentences as well - those will have the index 0.
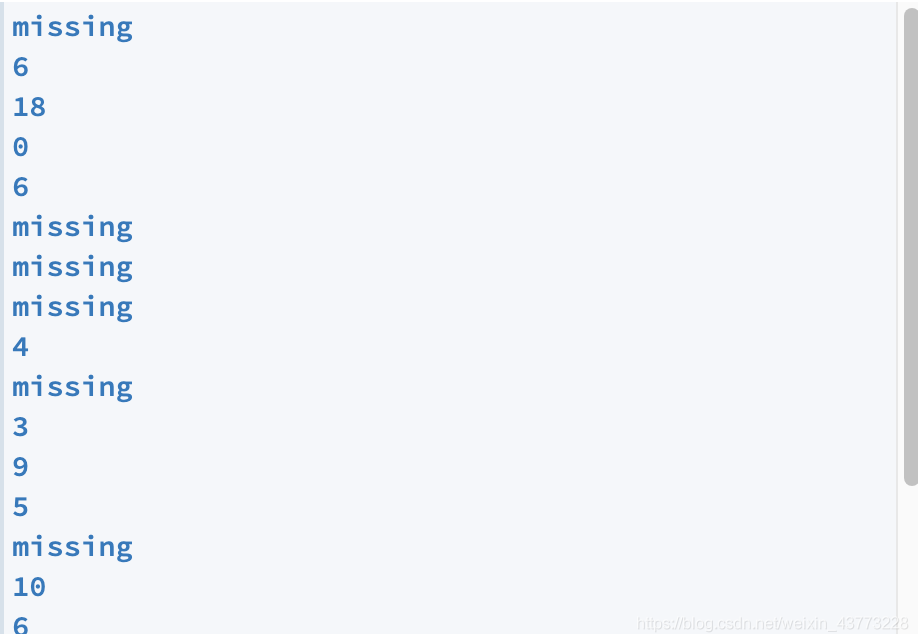
要求: 打開文本檔案,列印出每個句子中第一次出現單詞“ the”的位置,對于不包含“ the”的句子,請列印出“ missing”一詞,您的程式應不區分大小寫,這樣就可以同時計算大小寫單詞,
for line in open("jane_eyre_sentences.txt"):
line_strip = line.strip()
line_lower = line_strip.lower()
words = line_lower.split()
if "the" in words:
print(words.index("the"))
else:
print("missing")
line1: for in 回圈打開檔案,
line2: 去掉文本的首位空格部分,用strip()函式,
line3: 把文本變成小寫,用lower()函式,
line4: 把文本變成串列形式,方便后面索引找出單詞位置,用split()函式,
line5-line6: 條件判斷the在不在變數words里,如果在輸出the的位置,用index()獲取串列索引的位置,
line7-line8: 條件判斷其余項,說明這些是沒有the 的句子,列印輸出missing,
question2:The letter “e”
With the letter “e” being the most common letter in the English language, let’s have a look how many sentences consist mostly of words which don’t contain this letter.
Write a program that iterates over the provided jane_eyre_sentences.txt file and counts the number of words without an “e”, including both upper and lower case. For each sentence in which the relative amount of words without “e” is over 70%, print out how many words in that sentence contain no “e”, and how many words there are in total. Also, let your program print out the corresponding line number (starting to count from zero).
The provided file contains the first 50 sentences of the novel. Here’s what the output of your program for these sentences should look like:
For the first line, 9 out of 10 words contain no “e”, which makes 90% of the words in this sentence “e”-less.

要求: 打開文本檔案進行迭代,計算出不帶’e’的數量,每行不帶‘e’的單詞數量超過70%計算出來,輸出結果不包含’e’單詞數量,一共多少單詞和在第幾行(從0行開始計算),分成兩個部分講make it easy.
#第一部分
line_count=0 #line1
for line in open('jane_eyre_sentences.txt'): #line2
words=line.split() #line3
count=0 #line4
for word in words: #line5
if 'e' not in word: #line6
count+=1 #line7
ans=count/len(words)*100 #line8
#第二部分
if ans>70: #line9
print(str(line_count)+': '+str(count)+' out of '+str(len(words))+" words contain no 'e'.") #line10
line_count+=1 #line11
第一部分:
line1: 在打開檔案前設定一個計數回圈的變數,用來計算出在第幾行,
line2: 用for in回圈打開文本檔案,
line3: 將單詞變成串列,儲存給新的變數words,
line4: 設定一個計數回圈來計算沒有’e’的單詞有多少個,
line5: 新的回圈來遍歷串列,
line6-line7: 條件判斷,如果‘e’不在串列單詞里,計數尋回圈加一,
line8: 設定新的變數ans來計算單詞的比例,count是沒有‘e’單詞的數量,len(words)是單行單詞的數量,
第二部分:
line9: 條件判斷,如果單詞比例超過70就輸出下面陳述句塊,
line10: 輸出最終結果,str(line_count)為計算在第幾行,str(count)計算沒有’e’單詞的數量,str(len(words))計算一行有多少個單詞,
line11: 計數回圈為了求在第幾行,每遍歷一次回圈計數加一,注意計數是從0開始和代碼塊縮進是和第第三行對其,
Question3:Ouput abrigdements
You might have noticed that the sentences in our novel, and classic English literature in general, can get quite long. In order to extract the relevant information out of literature, data scientists write clever abrigdement algorithms which reduce the number of words without compromising the information stored in the text too much.
A first step to developing such algorithms is to be able to rearrange words in an arbitrary way to form new sentences. Using the supplied jane_eyre_sentences.txt file which contains one of the two ballads in that novel, your task is to transform each sentence such that we only keep the words between the third and the third-last word (inclusive) and skip every second word on the way.
For example, using the following sentence,
Your program should transform this sentence to the following, new sentence:
Here the sentence starts from the third word (remember that indexing starts at 0) and then contains every second word of the original sentence up to the third last.
Here’s what the first lines of your output should look like:



要求: 打開文本檔案,每一行的前三個和后兩個單詞不輸出,中間的單詞每隔一個輸出一個
for line in open("jane_eyre_sentences.txt"):
words = line.split()
print(" ".join(words[2:-2:2]))
line1: 打開檔案
line2: 轉換成串列的格式
line3: 用join()函式將word[2:-2:2]的單詞獲得給" "空白格,
鏈接: 串列索引切片用法.
Question4:The use of semicolons
The semicolon is a popular stylistic element to connect two closely related ideas with equal position or rank. Charlotte Bront? also makes ample use of semicolons; you can find about 3460 semicolons in the 7460 sentences of the Jane Eyre novel.
Your task is to find sentences which contain a semicolon, and find the number of words before and after the semicolon. Use the jane_eyre_sentences.txt, which contains an excerpt from the first chapter with complete punctuation.
Your program should print out the line number, and then the number of words before and after the semicolon, separated by a semicolon. For example, for the following sentence, which is the third sentence from the file,
Be seated somewhere; and until you can speak pleasantly, remain silent."
your program should print:
There are three words before the semicolon, and then another eight afterwards.
For the entire file, the output of your program should look like this:
Hint
You can use the split method to split up each sentence at the semicolon. This should give you a list with two strings - when you call split again on both elements of the list, you get two individual lists of words before and after the semicolon.
There are no sentences in the file with more than one semicolon.


要求: 查找帶有分號的句子,并查找分號之前和之后的單詞數,
count = 0
for line in open("jane_eyre_sentences.txt"):
if ";" in line:
line_split = line.split(";")
words_before = line_split[0].split()
words_after = line_split[1].split()
print("Line " + str(count) + ": "+str(len(words_before)) + \
";" + str(len(words_after)))
count += 1
line1: 設定一個計數回圈,來計算在第幾行,
line2: 打開文本,
line3: 條件判斷’;‘是否在文本里,
line4: 用split(’;’)函式將分號前后分離,并變成串列形式,
line5: line_split[0]求分號前的單詞,.split()函式將他們分離成串列格式,方便輸出的時候查詢單詞數量,
line6: line_split[1]求分號后的單詞,.split()函式將他們分離成串列格式,方便輸出的時候查詢單詞數量,(在此文本里,每行最多出現一個分號)
line7: 輸出理想答案,str(count)用來計算行數,str(len(var))來求出番號前后的單詞數量,
line8: 沒回圈一次,不管什么結果回圈計數加一來求出在第幾行,
總結
第6章節不是很難,用細細心看看代碼就會,更新的有點慢,我會加速的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/166097.html
標籤:其他