本篇文章結合參考資料中的幾篇CMDB的文章再加上目前公司的現狀談一談CMDB,
CMDB概述
CMDB:configuration management database,配置管理資料庫,CMDB本質上是一個資料庫,提供資料的存盤、查詢、校驗等操作,是一個集中式的資料托管中心,托管的內容包含所有的軟硬體資產(configuration items),各個部門各個團隊各個系統下屬的各種重要的軟硬體資產都屬于CMDB統一管理的內容,
公司運維現狀
資產現狀
全國各地區內網不互通,這個就是現狀了,因為公司產品是為國家服務,所以全國各地的環境都在各自的內網中,安全性極高,在這種情況下,每個地區都配置了幾個運維手工維護當地的環境,內外網完全隔離,
運維情況現狀
由于公司資產地域分散且網路不互通,因此公司的自動化運維程度基本為0,整體上來說沒有運維開發的崗位,目前的運維仍然停留在人工運維結合shell腳本的時代,這些其實都算不上自動化運維,前段時間,開始搞ansible自動化部署和升級的事情,整個程序都是shell腳本完成,為了控制人力成本,甚至否認一些用新技術,拿Python這門語言來說,本身很適合自動化運維,用于自動化升級那是再適合不過了,雖然底層會依賴shell,但是Python寫出來的邏輯必然會更清楚,但是上層考慮到后續維護人員需要掌握Python和shell兩種技術,最侄訓是否定了Python,其實也就是否定了自動化運維,轉而幾種人員去研究日志中心和nagios監控,自動化運維的事情也自然不了了之,
CMDB現狀
目前公司里面還沒有產生建設CMDB的萌芽,資產管理部門和運維中心團隊有自己的配置庫,也就是自建庫,但是并沒有將產品團隊的軟體資產列入配置管理的范圍,各個產品團隊使用Confluence檔案服務器或者Excel表格(這種情況較多)管理自己的軟硬體資源,并稱之為資源臺賬,就服務器而言,經常不知道一個ip對應的服務器是否正在使用,由誰使用,這些資訊一無所知,如果各個團隊使用自建庫,而不是通過檔案形式來管理,那這種CMDB最多也只能算是各自為政的CMDB,并不是集中式的資料托管,
CMDB設計
最簡單的設計:一種配置一個表
比如,ip單獨成表,host單獨成表
優點:配置簡單直觀
缺點:一旦某種配置需要修改欄位,就需要修改代碼,代碼維護成本太高
復雜點的設計:列式資料存盤
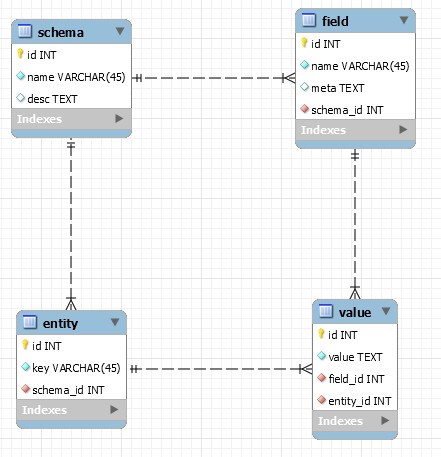
表名,列名,列值,行分開存放到四張張表(schema, filed, value, entity)
- schema:一個配置表在schema中就是一條記錄,記錄表的資訊和描述,
- field:每一列的列名和列相關的meta資訊都存放在field表中,
- entity:當作rowid使用,表示唯一衡量傳統意義上的一行資料,
- value:存放每一條記錄的每一列的值,即一個entity和一個field既可以確定一個值,
表的設計如下圖:
整個設計的sql如下:
-- MySQL Workbench Forward Engineering
SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0;
SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0;
SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='TRADITIONAL,ALLOW_INVALID_DATES';
-- -----------------------------------------------------
-- Schema mydb
-- -----------------------------------------------------
-- -----------------------------------------------------
-- Schema mydb
-- -----------------------------------------------------
CREATE SCHEMA IF NOT EXISTS `mydb` DEFAULT CHARACTER SET utf8 ;
USE `mydb` ;
-- -----------------------------------------------------
-- Table `mydb`.`schema`
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `mydb`.`schema` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(45) NOT NULL,
`desc` TEXT NULL,
PRIMARY KEY (`id`),
UNIQUE INDEX `name_UNIQUE` (`name` ASC))
ENGINE = InnoDB;
-- -----------------------------------------------------
-- Table `mydb`.`field`
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `mydb`.`field` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(45) NOT NULL,
`meta` TEXT NULL,
`schema_id` INT NOT NULL,
PRIMARY KEY (`id`),
INDEX `fk_field_schema_idx` (`schema_id` ASC),
CONSTRAINT `fk_field_schema`
FOREIGN KEY (`schema_id`)
REFERENCES `mydb`.`schema` (`id`)
ON DELETE NO ACTION
ON UPDATE NO ACTION)
ENGINE = InnoDB;
-- -----------------------------------------------------
-- Table `mydb`.`entity`
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `mydb`.`entity` (
`id` INT NOT NULL AUTO_INCREMENT,
`key` VARCHAR(45) NOT NULL,
`schema_id` INT NOT NULL,
PRIMARY KEY (`id`),
INDEX `fk_entity_schema1_idx` (`schema_id` ASC),
CONSTRAINT `fk_entity_schema1`
FOREIGN KEY (`schema_id`)
REFERENCES `mydb`.`schema` (`id`)
ON DELETE NO ACTION
ON UPDATE NO ACTION)
ENGINE = InnoDB;
-- -----------------------------------------------------
-- Table `mydb`.`value`
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `mydb`.`value` (
`id` INT NOT NULL AUTO_INCREMENT,
`value` TEXT NOT NULL,
`field_id` INT NOT NULL,
`entity_id` INT NOT NULL,
PRIMARY KEY (`id`),
INDEX `fk_value_field1_idx` (`field_id` ASC),
INDEX `fk_value_entity1_idx` (`entity_id` ASC),
INDEX `ux_value` (`field_id` ASC, `entity_id` ASC),
CONSTRAINT `fk_value_field1`
FOREIGN KEY (`field_id`)
REFERENCES `mydb`.`field` (`id`)
ON DELETE NO ACTION
ON UPDATE NO ACTION,
CONSTRAINT `fk_value_entity1`
FOREIGN KEY (`entity_id`)
REFERENCES `mydb`.`entity` (`id`)
ON DELETE NO ACTION
ON UPDATE NO ACTION)
ENGINE = InnoDB;
SET SQL_MODE=@OLD_SQL_MODE;
SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS;
SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS;
資料庫查詢時需要提供(entity, schema, field, value)這樣一個四元組才能得到結果,
優點:在線定義,表有變動時不需要修改代碼,增加一列只需要向field表中插入一個欄位,
缺點:復雜,增刪改查時需要同時操作多個表,對資料的約束需要在應用層去實作,需要自己封裝ORM,每一列的約束資訊存放在field表的meta欄位中,
更復雜的設計:資料多版本和回滾
增加資料多版本
CMDB存放的資訊都是非常重要的資訊,因此不允許修改資料,每一次修改資料都單獨增加一條記錄,這樣就可以保證資料多版本,因此可以增加一個snapshot快照表,用來存放各個歷史版本的資料,snapshot表的具體設計較復雜,暫不使用,
增加回滾
增加資料多版本之后對應的就可以增加一個回滾的功能,多版本基礎上的回滾功能可以參考git的實作,
CMDB使用結論
強烈反對大型集中式CMDB,CMDB團隊執行力不強,需求多變,短期內看不到價值等多種原因導致在大多數互聯網公司CMDB是無法落地的,到目前為止除了華為也沒幾家公司能把CMDB落地直到發揮CMDB的價值(華為都花了7年的時間,更別說別的公司了),
如果一定要使用CMDB,那只能使用分散式的各自為政的,各個團隊使用各個團隊的自建庫,比如管IP庫的就專門設計IP庫,管賬號庫的就專門設計賬號庫,資料庫之間通過各自提供的api通訊,但是分散式的缺點是從領導的角度看,看不到全域的資料,因此還需要做一個集中化的dashboard,
CMDB替代方案
CMDB在大多數互聯網公司不可行,因此很多公司都另辟蹊徑,比如一種方式常用的方式 Mesos
- Mesos:托管于Apache下C++開發的開源分布式資源管理系統
Mesos的調度框架可以有多種語言開發,包括Python,
參考
- 冰與火之歌,華為CMDB是如何煉成的
- 維基-Configuration management database
- CMDB經驗分享之 – 剖析CMDB的設計程序
記得幫我點贊哦!
精心整理了計算機各個方向的從入門、進階、實戰的視頻課程和電子書,按照目錄合理分類,總能找到你需要的學習資料,還在等什么?快去關注下載吧!!!

念念不忘,必有回響,小伙伴們幫我點個贊吧,非常感謝,
我是職場亮哥,YY高級軟體工程師、四年作業經驗,拒絕咸魚爭當龍頭的斜杠程式員,
聽我說,進步多,程式人生一把梭
如果有幸能幫到你,請幫我點個【贊】,給個關注,如果能順帶評論給個鼓勵,將不勝感激,
職場亮哥文章串列:更多文章

本人所有文章、回答都與著作權保護平臺有合作,著作權歸職場亮哥所有,未經授權,轉載必究!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/170831.html
標籤:其他
上一篇:結合公司現狀淺談CMDB