Requests 是一個 Python 的 HTTP 客戶端庫,
Request支持HTTP連接保持和連接池,支持使用cookie保持會話,支持檔案上傳,支持自動回應內容的編碼,支持國際化的URL和POST資料自動編碼,
在python內置模塊的基礎上進行了高度的封裝從而使得python進行網路請求時,變得人性化,使用Requests可以輕而易舉的完成瀏覽器可有的任何操作,現代,國際化,友好,
requests會自動實作持久連接keep-alive
開源地址:https://github.com/kennethreitz/requests
中文檔案:http://docs.python-requests.org/zh_CN/latest/index.html
目錄
一、Requests基礎
二、發送請求與接收回應(基本GET請求)
三、發送請求與接收回應(基本POST請求)
四、response屬性
五、代理
六、cookie和session
七、案例
一、Requests基礎
1.安裝Requests庫
pip install requests
2.使用Requests庫
import requests
二、發送請求與接收回應(基本GET請求)
response = requests.get(url)
1.傳送 parmas引數
- 引數包含在url中
response = requests.get("http://httpbin.org/get?name=zhangsan&age=22")
print(response.text)
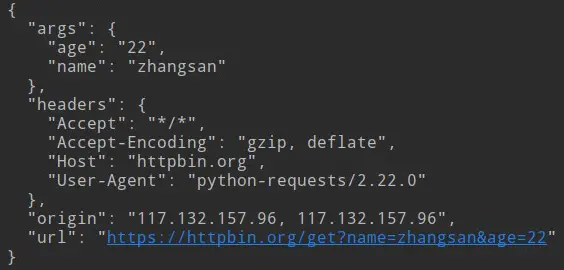
- 通過get方法傳送引數
data = {
"name": "zhangsan",
"age": 30
}
response = requests.get("http://httpbin.org/get", params=data)
print(response.text)
2.模擬發送請求頭(傳送headers引數)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
response = requests.get("http://httpbin.org/get", headers=headers)
print(response.text)
三、發送請求與接收回應(基本POST請求)
response = requests.post(url, data = data, headers=headers)
四、response屬性
| 屬性 | 描述 |
|---|---|
| response.text | 獲取str型別(Unicode編碼)的回應 |
| response.content | 獲取bytes型別的回應 |
| response.status_code | 獲取回應狀態碼 |
| response.headers | 獲取回應頭 |
| response.request | 獲取回應對應的請求 |
五、代理
proxies = {
"http": "https://175.44.148.176:9000",
"https": "https://183.129.207.86:14002"
}
response = requests.get("https://www.baidu.com/", proxies=proxies)
六、cookie和session
- 使用的cookie和session好處:很多網站必須登錄之后(或者獲取某種權限之后)才能能夠請求到相關資料,
- 使用的cookie和session的弊端:一套cookie和session往往和一個用戶對應.請求太快,請求次數太多,容易被服務器識別為爬蟲,從而使賬號收到損害,
1.不需要cookie的時候盡量不去使用cookie,
2.為了獲取登錄之后的頁面,我們必須發送帶有cookies的請求,此時為了確保賬號安全應該盡量降低資料
采集速度,
1.cookie
(1)獲取cookie資訊
response.cookies
2.session
(1)構造session回話物件
session = requests.session()
示例:
def login_renren():
login_url = 'http://www.renren.com/SysHome.do'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
session = requests.session()
login_data = {
"email": "賬號",
"password": "密碼"
}
response = session.post(login_url, data=login_data, headers=headers)
response = session.get("http://www.renren.com/971909762/newsfeed/photo")
print(response.text)
login_renren()
七、案例

案例1:百度貼吧頁面爬取(GET請求)
import requests
import sys
class BaiduTieBa:
def __init__(self, name, pn, ):
self.name = name
self.url = "http://tieba.baidu.com/f?kw={}&ie=utf-8&pn={}".format(name, pn)
self.headers = {
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
# 使用較老版本的請求頭,該瀏覽器不支持js
"User-Agent": "Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)"
}
self.url_list = [self.url + str(pn*50) for pn in range(pn)]
print(self.url_list)
def get_data(self, url):
"""
請求資料
:param url:
:return:
"""
response = requests.get(url, headers=self.headers)
return response.content
def save_data(self, data, num):
"""
保存資料
:param data:
:param num:
:return:
"""
file_name = "./pages/" + self.name + "_" + str(num) + ".html"
with open(file_name, "wb") as f:
f.write(data)
def run(self):
for url in self.url_list:
data = self.get_data(url)
num = self.url_list.index(url)
self.save_data(data, num)
if __name__ == "__main__":
name = sys.argv[1]
pn = int(sys.argv[2])
baidu = BaiduTieBa(name, pn)
baidu.run()
案例2:金山詞霸翻譯(POST請求)
import requests
import sys
import json
class JinshanCiBa:
def __init__(self, words):
self.url = "http://fy.iciba.com/ajax.php?a=fy"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"X-Requested-With": "XMLHttpRequest"
}
self.post_data = {
"f": "auto",
"t": "auto",
"w": words
}
def get_data(self):
"""
請求資料
:param url:
:return:
"""
response = requests.post(self.url, data=self.post_data, headers=self.headers)
return response.text
def show_translation(self):
"""
顯示翻譯結果
:param data:
:param num:
:return:
"""
response = self.get_data()
json_data = json.loads(response, encoding='utf-8')
if json_data['status'] == 0:
translation = json_data['content']['word_mean']
elif json_data['status'] == 1:
translation = json_data['content']['out']
else:
translation = None
print(translation)
def run(self):
self.show_translation()
if __name__ == "__main__":
words = sys.argv[1]
ciba = JinshanCiBa(words)
ciba.run()

案例3:百度貼吧圖片爬取
(1)普通版
從已下載頁面中提取url來爬取圖片(頁面下載方法見案例1)
from lxml import etree
import requests
class DownloadPhoto:
def __init__(self):
pass
def download_img(self, url):
response = requests.get(url)
index = url.rfind('/')
file_name = url[index + 1:]
print("下載圖片:" + file_name)
save_name = "./photo/" + file_name
with open(save_name, "wb") as f:
f.write(response.content)
def parse_photo_url(self, page):
html = etree.parse(page, etree.HTMLParser())
nodes = html.xpath("//a[contains(@class, 'thumbnail')]/img/@bpic")
print(nodes)
print(len(nodes))
for node in nodes:
self.download_img(node)
if __name__ == "__main__":
download = DownloadPhoto()
for i in range(6000):
download.parse_photo_url("./pages/校花_{}.html".format(i))
(2)多執行緒版
main.py
import requests
from lxml import etree
from file_download import DownLoadExecutioner, file_download
class XiaoHua:
def __init__(self, init_url):
self.init_url = init_url
self.download_executioner = DownLoadExecutioner()
def start(self):
self.download_executioner.start()
self.download_img(self.init_url)
def download_img(self, url):
html_text = file_download(url, type='text')
html = etree.HTML(html_text)
img_urls = html.xpath("//a[contains(@class,'thumbnail')]/img/@bpic")
self.download_executioner.put_task(img_urls)
# 獲取下一頁的連接
next_page = html.xpath("//div[@id='frs_list_pager']/a[contains(@class,'next')]/@href")
next_page = "http:" + next_page[0]
self.download_img(next_page)
if __name__ == '__main__':
x = XiaoHua("http://tieba.baidu.com/f?kw=校花&ie=utf-8")
x.start()
file_download.py
import requests
import threading
from queue import Queue
def file_download(url, type='content'):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
r = requests.get(url, headers=headers)
if type == 'text':
return r.text
return r.content
class DownLoadExecutioner(threading.Thread):
def __init__(self):
super().__init__()
self.q = Queue(maxsize=50)
# 圖片保存目錄
self.save_dir = './img/'
# 圖片計數
self.index = 0
def put_task(self, urls):
if isinstance(urls, list):
for url in urls:
self.q.put(url)
else:
self.q.put(urls)
def run(self):
while True:
url = self.q.get()
content = file_download(url)
# 截取圖片名稱
index = url.rfind('/')
file_name = url[index+1:]
save_name = self.save_dir + file_name
with open(save_name, 'wb+') as f:
f.write(content)
self.index += 1
print(save_name + "下載成功! 當前已下載圖片總數:" + str(self.index))
(3)執行緒池版
main.py
import requests
from lxml import etree
from file_download_pool import DownLoadExecutionerPool, file_download
class XiaoHua:
def __init__(self, init_url):
self.init_url = init_url
self.download_executioner = DownLoadExecutionerPool()
def start(self):
self.download_img(self.init_url)
def download_img(self, url):
html_text = file_download(url, type='text')
html = etree.HTML(html_text)
img_urls = html.xpath("//a[contains(@class,'thumbnail')]/img/@bpic")
self.download_executioner.put_task(img_urls)
# 獲取下一頁的連接
next_page = html.xpath("//div[@id='frs_list_pager']/a[contains(@class,'next')]/@href")
next_page = "http:" + next_page[0]
self.download_img(next_page)
if __name__ == '__main__':
x = XiaoHua("http://tieba.baidu.com/f?kw=校花&ie=utf-8")
x.start()
file_download_pool.py
import requests
import concurrent.futures as futures
def file_download(url, type='content'):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
r = requests.get(url, headers=headers)
if type == 'text':
return r.text
return r.content
class DownLoadExecutionerPool():
def __init__(self):
super().__init__()
# 圖片保存目錄
self.save_dir = './img_pool/'
# 圖片計數
self.index = 0
# 執行緒池
self.ex = futures.ThreadPoolExecutor(max_workers=30)
def put_task(self, urls):
if isinstance(urls, list):
for url in urls:
self.ex.submit(self.save_img, url)
else:
self.ex.submit(self.save_img, urls)
def save_img(self, url):
content = file_download(url)
# 截取圖片名稱
index = url.rfind('/')
file_name = url[index+1:]
save_name = self.save_dir + file_name
with open(save_name, 'wb+') as f:
f.write(content)
self.index += 1
print(save_name + "下載成功! 當前已下載圖片總數:" + str(self.index))
作者:Recalcitrant
鏈接:https://www.jianshu.com/p/140012f88f8eRequests 是一個 Python 的 HTTP 客戶端庫,
Request支持HTTP連接保持和連接池,支持使用cookie保持會話,支持檔案上傳,支持自動回應內容的編碼,支持國際化的URL和POST資料自動編碼,
在python內置模塊的基礎上進行了高度的封裝,從而使得python進行網路請求時,變得人性化,使用Requests可以輕而易舉的完成瀏覽器可有的任何操作,現代,國際化,友好,
requests會自動實作持久連接keep-alive

開源地址:https://github.com/kennethreitz/requests
中文檔案:http://docs.python-requests.org/zh_CN/latest/index.html
目錄
一、Requests基礎
二、發送請求與接收回應(基本GET請求)
三、發送請求與接收回應(基本POST請求)
四、response屬性
五、代理
六、cookie和session
七、案例
一、Requests基礎
1.安裝Requests庫
pip install requests
2.使用Requests庫
import requests
二、發送請求與接收回應(基本GET請求)
response = requests.get(url)
1.傳送 parmas引數
- 引數包含在url中
response = requests.get("http://httpbin.org/get?name=zhangsan&age=22")
print(response.text)
- 通過get方法傳送引數
data = {
"name": "zhangsan",
"age": 30
}
response = requests.get("http://httpbin.org/get", params=data)
print(response.text)
2.模擬發送請求頭(傳送headers引數)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
response = requests.get("http://httpbin.org/get", headers=headers)
print(response.text)
三、發送請求與接收回應(基本POST請求)
response = requests.post(url, data = data, headers=headers)
四、response屬性
| 屬性 | 描述 |
|---|---|
| response.text | 獲取str型別(Unicode編碼)的回應 |
| response.content | 獲取bytes型別的回應 |
| response.status_code | 獲取回應狀態碼 |
| response.headers | 獲取回應頭 |
| response.request | 獲取回應對應的請求 |
五、代理
proxies = {
"http": "https://175.44.148.176:9000",
"https": "https://183.129.207.86:14002"
}
response = requests.get("https://www.baidu.com/", proxies=proxies)
六、cookie和session
- 使用的cookie和session好處:很多網站必須登錄之后(或者獲取某種權限之后)才能能夠請求到相關資料,
- 使用的cookie和session的弊端:一套cookie和session往往和一個用戶對應.請求太快,請求次數太多,容易被服務器識別為爬蟲,從而使賬號收到損害,
1.不需要cookie的時候盡量不去使用cookie,
2.為了獲取登錄之后的頁面,我們必須發送帶有cookies的請求,此時為了確保賬號安全應該盡量降低資料
采集速度,
1.cookie
(1)獲取cookie資訊
response.cookies
2.session
(1)構造session回話物件
session = requests.session()
示例:
def login_renren():
login_url = 'http://www.renren.com/SysHome.do'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
session = requests.session()
login_data = {
"email": "賬號",
"password": "密碼"
}
response = session.post(login_url, data=login_data, headers=headers)
response = session.get("http://www.renren.com/971909762/newsfeed/photo")
print(response.text)
login_renren()
七、案例
案例1:百度貼吧頁面爬取(GET請求)
import requests
import sys
class BaiduTieBa:
def __init__(self, name, pn, ):
self.name = name
self.url = "http://tieba.baidu.com/f?kw={}&ie=utf-8&pn={}".format(name, pn)
self.headers = {
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
# 使用較老版本的請求頭,該瀏覽器不支持js
"User-Agent": "Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)"
}
self.url_list = [self.url + str(pn*50) for pn in range(pn)]
print(self.url_list)
def get_data(self, url):
"""
請求資料
:param url:
:return:
"""
response = requests.get(url, headers=self.headers)
return response.content
def save_data(self, data, num):
"""
保存資料
:param data:
:param num:
:return:
"""
file_name = "./pages/" + self.name + "_" + str(num) + ".html"
with open(file_name, "wb") as f:
f.write(data)
def run(self):
for url in self.url_list:
data = self.get_data(url)
num = self.url_list.index(url)
self.save_data(data, num)
if __name__ == "__main__":
name = sys.argv[1]
pn = int(sys.argv[2])
baidu = BaiduTieBa(name, pn)
baidu.run()
案例2:金山詞霸翻譯(POST請求)
import requests
import sys
import json
class JinshanCiBa:
def __init__(self, words):
self.url = "http://fy.iciba.com/ajax.php?a=fy"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"X-Requested-With": "XMLHttpRequest"
}
self.post_data = {
"f": "auto",
"t": "auto",
"w": words
}
def get_data(self):
"""
請求資料
:param url:
:return:
"""
response = requests.post(self.url, data=self.post_data, headers=self.headers)
return response.text
def show_translation(self):
"""
顯示翻譯結果
:param data:
:param num:
:return:
"""
response = self.get_data()
json_data = json.loads(response, encoding='utf-8')
if json_data['status'] == 0:
translation = json_data['content']['word_mean']
elif json_data['status'] == 1:
translation = json_data['content']['out']
else:
translation = None
print(translation)
def run(self):
self.show_translation()
if __name__ == "__main__":
words = sys.argv[1]
ciba = JinshanCiBa(words)
ciba.run()
案例3:百度貼吧圖片爬取
(1)普通版
從已下載頁面中提取url來爬取圖片(頁面下載方法見案例1)
from lxml import etree
import requests
class DownloadPhoto:
def __init__(self):
pass
def download_img(self, url):
response = requests.get(url)
index = url.rfind('/')
file_name = url[index + 1:]
print("下載圖片:" + file_name)
save_name = "./photo/" + file_name
with open(save_name, "wb") as f:
f.write(response.content)
def parse_photo_url(self, page):
html = etree.parse(page, etree.HTMLParser())
nodes = html.xpath("//a[contains(@class, 'thumbnail')]/img/@bpic")
print(nodes)
print(len(nodes))
for node in nodes:
self.download_img(node)
if __name__ == "__main__":
download = DownloadPhoto()
for i in range(6000):
download.parse_photo_url("./pages/校花_{}.html".format(i))
(2)多執行緒版
main.py
import requests
from lxml import etree
from file_download import DownLoadExecutioner, file_download
class XiaoHua:
def __init__(self, init_url):
self.init_url = init_url
self.download_executioner = DownLoadExecutioner()
def start(self):
self.download_executioner.start()
self.download_img(self.init_url)
def download_img(self, url):
html_text = file_download(url, type='text')
html = etree.HTML(html_text)
img_urls = html.xpath("//a[contains(@class,'thumbnail')]/img/@bpic")
self.download_executioner.put_task(img_urls)
# 獲取下一頁的連接
next_page = html.xpath("//div[@id='frs_list_pager']/a[contains(@class,'next')]/@href")
next_page = "http:" + next_page[0]
self.download_img(next_page)
if __name__ == '__main__':
x = XiaoHua("http://tieba.baidu.com/f?kw=校花&ie=utf-8")
x.start()
file_download.py
import requests
import threading
from queue import Queue
def file_download(url, type='content'):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
r = requests.get(url, headers=headers)
if type == 'text':
return r.text
return r.content
class DownLoadExecutioner(threading.Thread):
def __init__(self):
super().__init__()
self.q = Queue(maxsize=50)
# 圖片保存目錄
self.save_dir = './img/'
# 圖片計數
self.index = 0
def put_task(self, urls):
if isinstance(urls, list):
for url in urls:
self.q.put(url)
else:
self.q.put(urls)
def run(self):
while True:
url = self.q.get()
content = file_download(url)
# 截取圖片名稱
index = url.rfind('/')
file_name = url[index+1:]
save_name = self.save_dir + file_name
with open(save_name, 'wb+') as f:
f.write(content)
self.index += 1
print(save_name + "下載成功! 當前已下載圖片總數:" + str(self.index))
(3)執行緒池版
main.py
import requests
from lxml import etree
from file_download_pool import DownLoadExecutionerPool, file_download
class XiaoHua:
def __init__(self, init_url):
self.init_url = init_url
self.download_executioner = DownLoadExecutionerPool()
def start(self):
self.download_img(self.init_url)
def download_img(self, url):
html_text = file_download(url, type='text')
html = etree.HTML(html_text)
img_urls = html.xpath("//a[contains(@class,'thumbnail')]/img/@bpic")
self.download_executioner.put_task(img_urls)
# 獲取下一頁的連接
next_page = html.xpath("//div[@id='frs_list_pager']/a[contains(@class,'next')]/@href")
next_page = "http:" + next_page[0]
self.download_img(next_page)
if __name__ == '__main__':
x = XiaoHua("http://tieba.baidu.com/f?kw=校花&ie=utf-8")
x.start()
file_download_pool.py
import requests
import concurrent.futures as futures
def file_download(url, type='content'):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
r = requests.get(url, headers=headers)
if type == 'text':
return r.text
return r.content
class DownLoadExecutionerPool():
def __init__(self):
super().__init__()
# 圖片保存目錄
self.save_dir = './img_pool/'
# 圖片計數
self.index = 0
# 執行緒池
self.ex = futures.ThreadPoolExecutor(max_workers=30)
def put_task(self, urls):
if isinstance(urls, list):
for url in urls:
self.ex.submit(self.save_img, url)
else:
self.ex.submit(self.save_img, urls)
def save_img(self, url):
content = file_download(url)
# 截取圖片名稱
index = url.rfind('/')
file_name = url[index+1:]
save_name = self.save_dir + file_name
with open(save_name, 'wb+') as f:
f.write(content)
self.index += 1
print(save_name + "下載成功! 當前已下載圖片總數:" + str(self.index))
作者:Recalcitrant
鏈接:https://www.jianshu.com/p/140012f88f8e
在線練習:https://www.520mg.com/it

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/171361.html
標籤:其他