前言
大家如果想自己組裝電腦的話,肯定需要購買一個 CPU,但是存盤器方面的設備,分類比較多,那我們肯定不能只買一種存盤器,比如你除了要買記憶體,還要買硬碟,而針對硬碟我們還可以選擇是固態硬碟還是機械硬碟,
相信大家都知道記憶體和硬碟都屬于計算機的存盤設備,斷電后記憶體的資料是會丟失的,而硬碟則不會,因為硬碟是持久化存盤設備,同時也是一個 I/O 設備,
但其實 CPU 內部也有存盤資料的組件,這個應該比較少人注意到,比如暫存器、CPU L1/L2/L3 Cache 也都是屬于存盤設備,只不過它們能存盤的資料非常小,但是它們因為靠近 CPU 核心,所以訪問速度都非常快,快過硬碟好幾個數量級別,
問題來了,那機械硬碟、固態硬碟、記憶體這三個存盤器,到底和 CPU L1 Cache 相比速度差多少倍呢?
在回答這個問題之前,我們先來看看「存盤器的層次結構」,好讓我們對存盤器設備有一個整體的認識,
正文
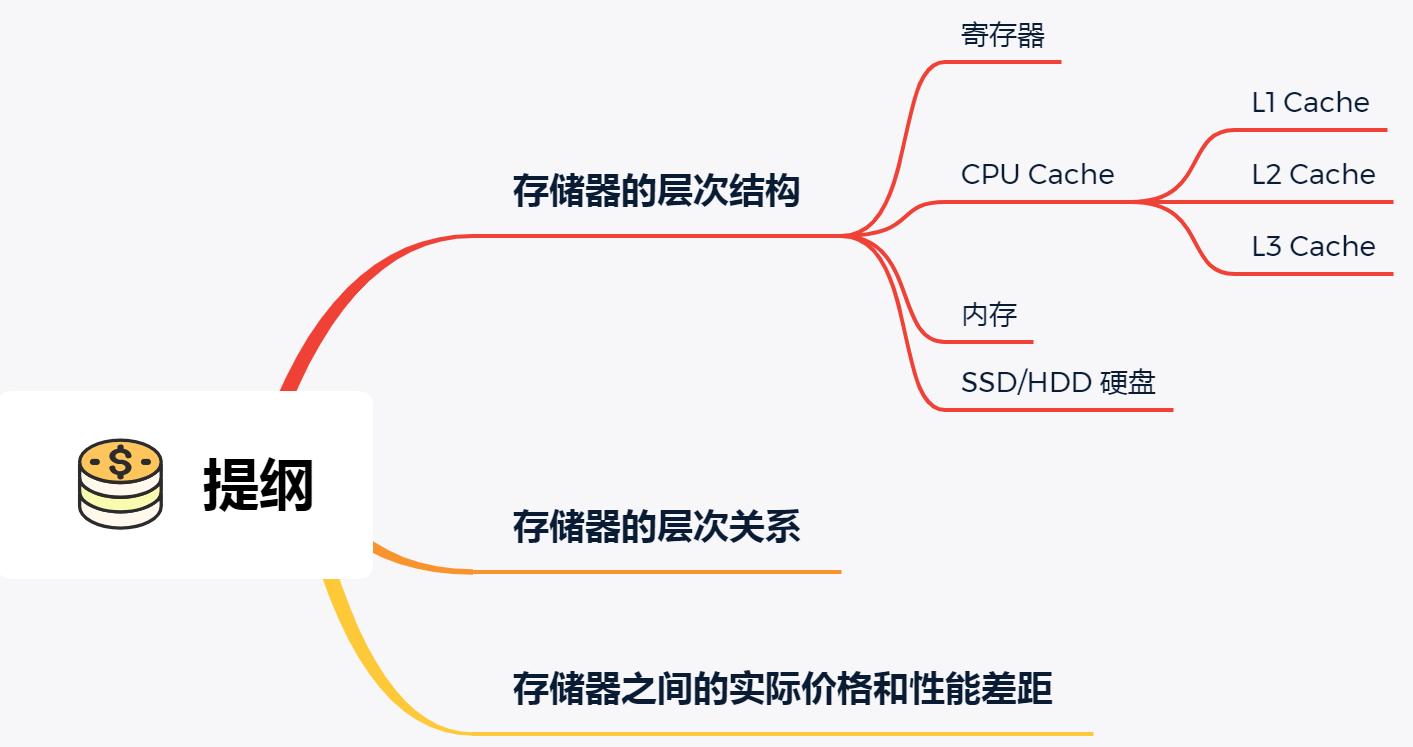
存盤器的層次結構
我們想象中一個場景,大學期末準備考試了,你前去圖書館臨時抱佛腳,那么,在看書的時候,我們的大腦會思考問題,也會記憶知識點,另外我們通常也會把常用的書放在自己的桌子上,當我們要找一本不常用的書,則會去圖書館的書架找,
就是這么一個小小的場景,已經把計算機的存盤結構基本都涵蓋了,
我們可以把 CPU 比喻成我們的大腦,大腦正在思考的東西,就好比 CPU 中的暫存器,處理速度是最快的,但是能存盤的資料也是最少的,畢竟我們也不能一下同時思考太多的事情,除非你練過,
我們大腦中的記憶,就好比 CPU Cache,中文稱為 CPU 高速快取,處理速度相比暫存器慢了一點,但是能存盤的資料也稍微多了一些,
CPU Cache 通常會分為 L1、L2、L3 三層,其中 L1 Cache 通常分成「資料快取」和「指令快取」,L1 是距離 CPU 最近的,因此它比 L2、L3 的讀寫速度都快、存盤空間都小,我們大腦中短期記憶,就好比 L1 Cache,而長期記憶就好比 L2/L3 Cache,
暫存器和 CPU Cache 都是在 CPU 內部,跟 CPU 挨著很近,因此它們的讀寫速度都相當的快,但是能存盤的資料很少,畢竟 CPU 就這么丁點大,
知道 CPU 內部的存盤器的層次分布,我們放眼看看 CPU 外部的存盤器,
當我們大腦記憶中沒有資料的時候,可以從書桌或書架上拿書來閱讀,那我們桌子上的書,就好比記憶體,我們雖然可以一伸手就可以拿到,但讀寫速度肯定遠慢于暫存器,那圖書館書架上的書,就好比硬碟,能存盤的資料非常大,但是讀寫速度相比記憶體差好幾個數量級,更別說跟暫存器的差距了,
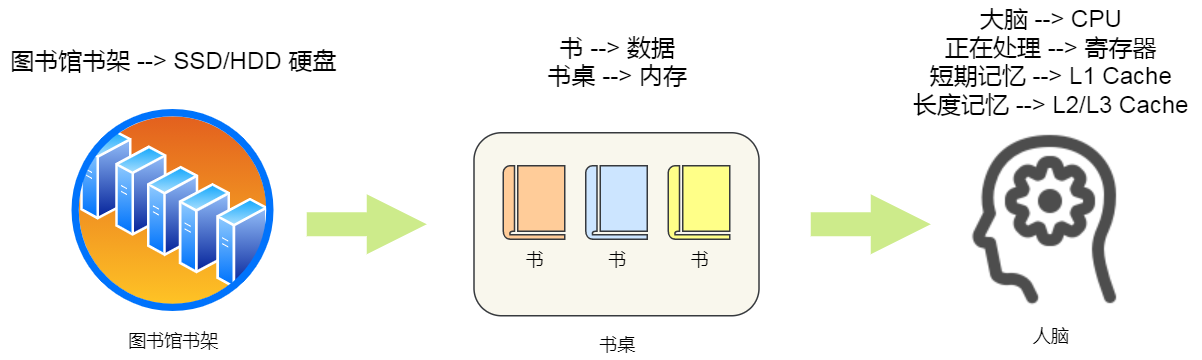
我們從圖書館書架取書,把書放到桌子上,再閱讀書,我們大腦就會記憶知識點,然后再經過大腦思考,這一系列程序相當于,資料從硬碟加載到記憶體,再從記憶體加載到 CPU 的暫存器和 Cache 中,然后再通過 CPU 進行處理和計算,
對于存盤器,它的速度越快、能耗會越高、而且材料的成本也是越貴的,以至于速度快的存盤器的容量都比較小,
CPU 里的暫存器和 Cache,是整個計算機存盤器中價格最貴的,雖然存盤空間很小,但是讀寫速度是極快的,而相對比較便宜的記憶體和硬碟,速度肯定比不上 CPU 內部的存盤器,但是能彌補存盤空間的不足,
存盤器通常可以分為這么幾個級別:
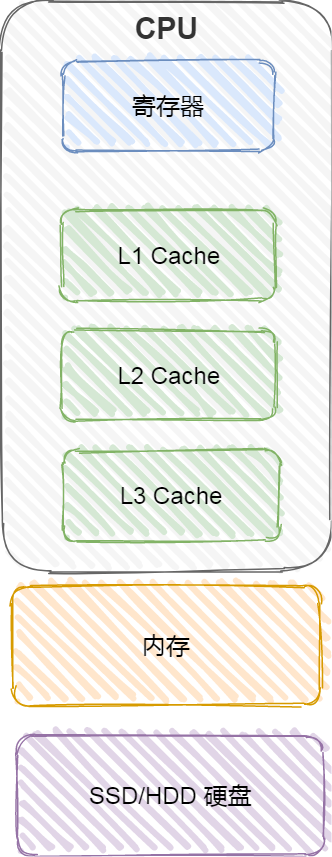
- 暫存器;
- CPU Cache;
- L1-Cache;
- L2-Cache;
- L3-Cahce;
- 記憶體;
- SSD/HDD 硬碟
暫存器
最靠近 CPU 的控制單元和邏輯計算單元的存盤器,就是暫存器了,它使用的材料速度也是最快的,因此價格也是最貴的,那么數量不能很多,
存盤器的數量通常在幾十到幾百之間,每個暫存器可以用來存盤一定的位元組(byte)的資料,比如:
- 32 位 CPU 中大多數暫存器可以存盤
4個位元組; - 64 位 CPU 中大多數暫存器可以存盤
8個位元組,
暫存器的訪問速度非常快,一般要求在半個 CPU 時鐘周期內完成讀寫,CPU 時鐘周期跟 CPU 主頻息息相關,比如 2 GHz 主頻的 CPU,那么它的時鐘周期就是 1/2G,也就是 0.5ns(納秒),
CPU 處理一條指令的時候,除了讀寫暫存器,還需要解碼指令、控制指令執行和計算,如果暫存器的速度太慢,則會拉長指令的處理周期,從而給用戶的感覺,就是電腦「很慢」,
CPU Cache
CPU Cache 用的是一種叫 SRAM(Static Random-Access Memory,靜態隨機存盤器) 的芯片,
SRAM 之所以叫「靜態」存盤器,是因為只要有電,資料就可以保持存在,而一旦斷電,資料就會丟失了,
在 SRAM 里面,一個 bit 的資料,通常需要 6 個晶體管,所以 SRAM 的存盤密度不高,同樣的物理空間下,能存盤的資料是有限的,不過也因為 SRAM 的電路簡單,所以訪問速度非常快,
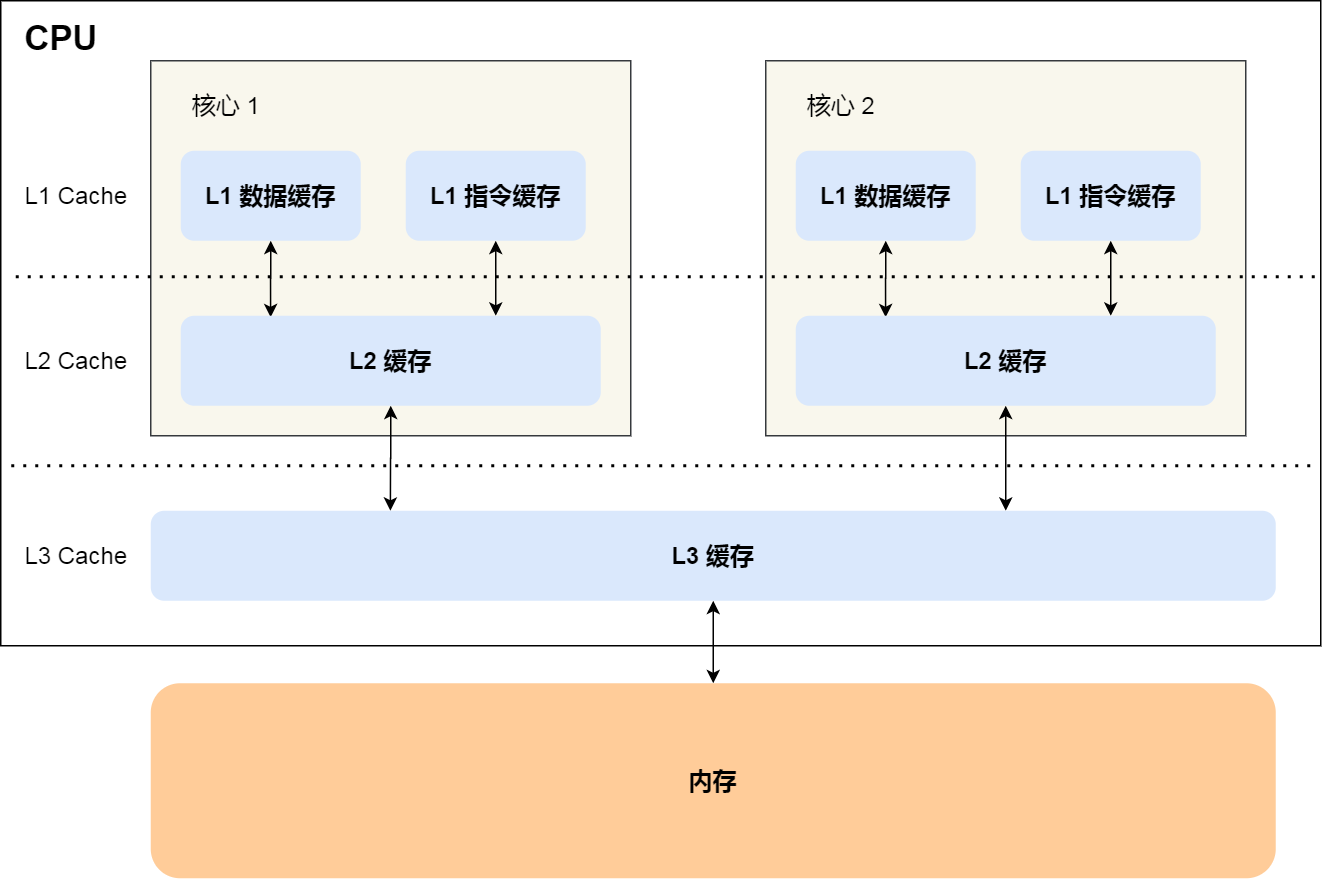
CPU 的高速快取,通常可以分為 L1、L2、L3 這樣的三層高速快取,也稱為一級快取、二次快取、三次快取,
L1 高速快取
L1 高速快取的訪問速度幾乎和暫存器一樣快,通常只需要 2~4 個時鐘周期,而大小在幾十 KB 到幾百 KB 不等,
每個 CPU 核心都有一塊屬于自己的 L1 高速快取,指令和資料在 L1 是分開存放的,所以 L1 高速快取通常分成指令快取和資料快取,
在 Linux 系統,我們可以通過這條命令,查看 CPU 里的 L1 Cache 「資料」快取的容量大小:
$ cat /sys/devices/system/cpu/cpu0/cache/index0/size
32K
而查看 L1 Cache 「指令」快取的容量大小,則是:
$ cat /sys/devices/system/cpu/cpu0/cache/index1/size
32K
L2 高速快取
L2 高速快取同樣每個 CPU 核心都有,但是 L2 高速快取位置比 L1 高速快取距離 CPU 核心 更遠,它大小比 L1 高速快取更大,CPU 型號不同大小也就不同,通常大小在幾百 KB 到幾 MB 不等,訪問速度則更慢,速度在 10~20 個時鐘周期,
在 Linux 系統,我們可以通過這條命令,查看 CPU 里的 L2 Cache 的容量大小:
$ cat /sys/devices/system/cpu/cpu0/cache/index2/size
256K
L3 高速快取
L3 高速快取通常是多個 CPU 核心共用的,位置比 L2 高速快取距離 CPU 核心 更遠,大小也會更大些,通常大小在幾 MB 到幾十 MB 不等,具體值根據 CPU 型號而定,
訪問速度相對也比較慢一些,訪問速度在 20~60個時鐘周期,
在 Linux 系統,我們可以通過這條命令,查看 CPU 里的 L3 Cache 的容量大小:
$ cat /sys/devices/system/cpu/cpu0/cache/index3/size
3072K
記憶體
記憶體用的芯片和 CPU Cache 有所不同,它使用的是一種叫作 DRAM (Dynamic Random Access Memory,動態隨機存取存盤器) 的芯片,
相比 SRAM,DRAM 的密度更高,功耗更低,有更大的容量,而且造價比 SRAM 芯片便宜很多,
DRAM 存盤一個 bit 資料,只需要一個晶體管和一個電容就能存盤,但是因為資料會被存盤在電容里,電容會不斷漏電,所以需要「定時重繪」電容,才能保證資料不會被丟失,這就是 DRAM 之所以被稱為「動態」存盤器的原因,只有不斷重繪,資料才能被存盤起來,
DRAM 的資料訪問電路和重繪電路都比 SRAM 更復雜,所以訪問的速度會更慢,記憶體速度大概在 200~300 個 時鐘周期之間,
SSD/HDD 硬碟
SSD(Solid-state disk) 就是我們常說的固體硬碟,結構和記憶體類似,但是它相比記憶體的優點是斷電后資料還是存在的,而記憶體、暫存器、高速快取斷電后資料都會丟失,記憶體的讀寫速度比 SSD 大概快 10~1000 倍,
當然,還有一款傳統的硬碟,也就是機械硬碟(Hard Disk Drive, HDD),它是通過物理讀寫的方式來訪問資料的,因此它訪問速度是非常慢的,它的速度比記憶體慢 10W 倍左右,
由于 SSD 的價格快接近機械硬碟了,因此機械硬碟已經逐漸被 SSD 替代了,
存盤器的層次關系
現代的一臺計算機,都用上了 CPU Cahce、記憶體、到 SSD 或 HDD 硬碟這些存盤器設備了,
其中,存盤空間越大的存盤器設備,其訪問速度越慢,所需成本也相對越少,
CPU 并不會直接和每一種存盤器設備直接打交道,而是每一種存盤器設備只和它相鄰的存盤器設備打交道,
比如,CPU Cache 的資料是從記憶體加載過來的,寫回資料的時候也只寫回到記憶體,CPU Cache 不會直接把資料寫到硬碟,也不會直接從硬碟加載資料,而是先加載到記憶體,再從記憶體加載到 CPU Cache 中,
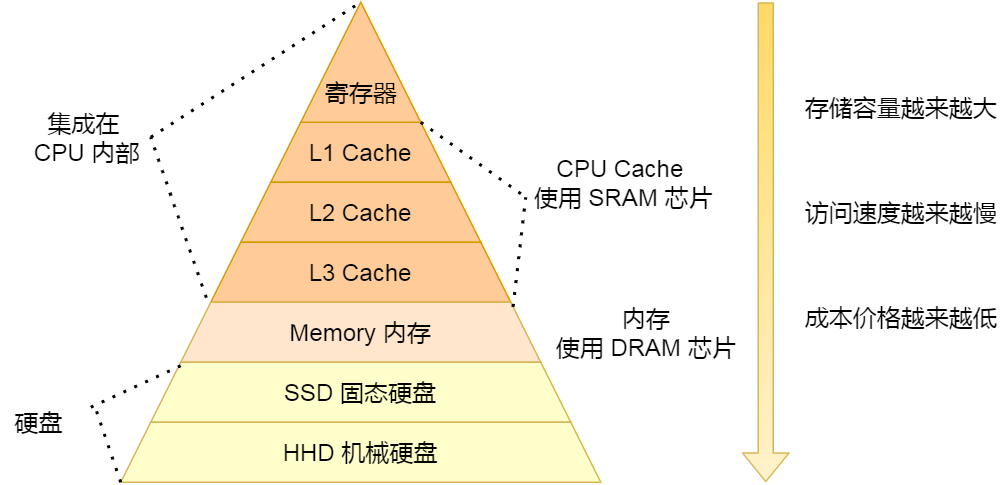
所以,每個存盤器只和相鄰的一層存盤器設備打交道,并且存盤設備為了追求更快的速度,所需的材料成本必然也是更高,也正因為成本太高,所以 CPU 內部的暫存器、L1\L2\L3 Cache 只好用較小的容量,相反記憶體、硬碟則可用更大的容量,這就我們今天所說的存盤器層次結構,
另外,當 CPU 需要訪問記憶體中某個資料的時候,如果暫存器有這個資料,CPU 就直接從暫存器取資料即可,如果暫存器沒有這個資料,CPU 就會查詢 L1 高速快取,如果 L1 沒有,則查詢 L2 高速快取,L2 還是沒有的話就查詢 L3 高速快取,L3 依然沒有的話,才去記憶體中取資料,
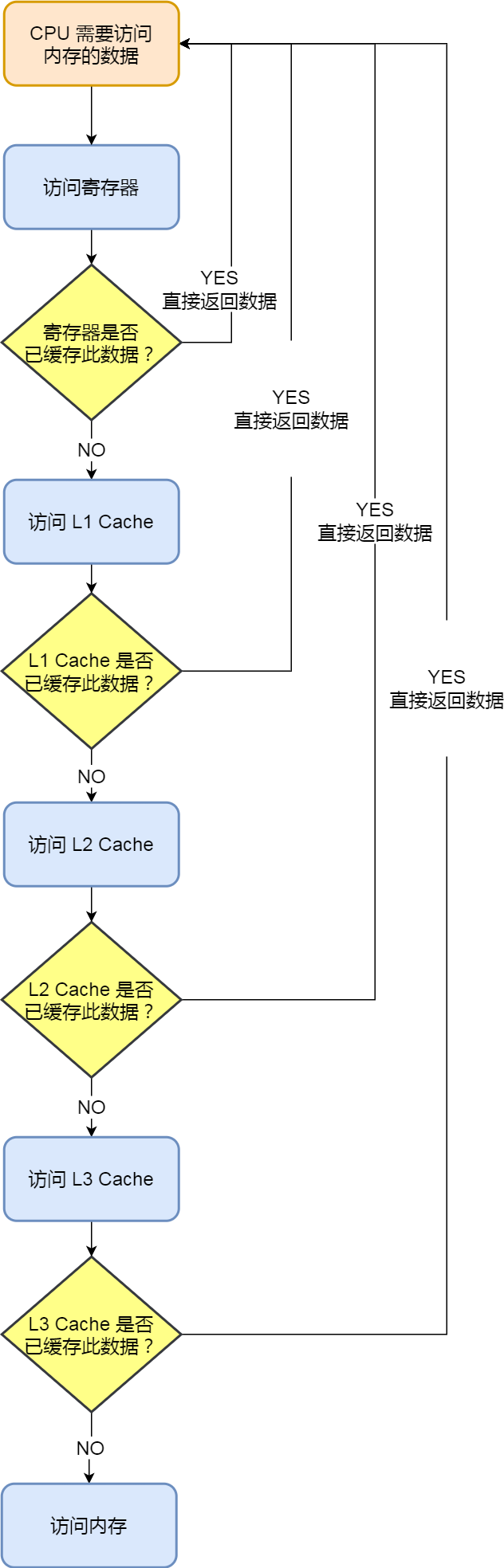
所以,存盤層次結構也形成了快取的體系,
存盤器之間的實際價格和性能差距
前面我們知道了,速度越快的存盤器,造價成本往往也越高,那我們就以實際的資料來看看,不同層級的存盤器之間的性能和價格差異,
下面這張表格是不同層級的存盤器之間的成本對比圖:
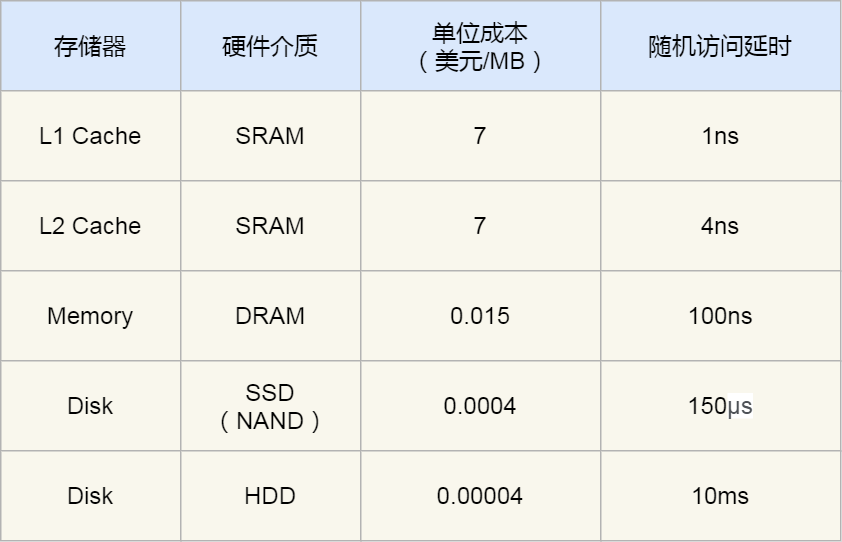
你可以看到 L1 Cache 的訪問延時是 1 納秒,而記憶體已經是 100 納秒了,相比 L1 Cache 速度慢了 100 倍,另外,機械硬碟的訪問延時更是高達 10 毫秒,相比 L1 Cache 速度慢了 10000000 倍,差了好幾個數量級別,
在價格上,每生成 MB 大小的 L1 Cache 相比記憶體貴了 466 倍,相比機械硬碟那更是貴了 175000 倍,
我在某東逛了下各個存盤器設備的零售價,8G 記憶體 + 1T 機械硬碟 + 256G 固態硬碟的總價格,都不及一塊 Intle i5-10400 的 CPU 的價格,這款 CPU 的高速快取的總大小也就十多 MB,
總結
各種存盤器之間的關系,可以用我們在圖書館學習這個場景來理解,
CPU 可以比喻成我們的大腦,我們當前正在思考和處理的知識的程序,就好比 CPU 中的暫存器處理資料的程序,速度極快,但是容量很小,而 CPU 中的 L1-L3 Cache 好比我們大腦中的短期記憶和長期記憶,需要小小花費點時間來調取資料并處理,
我們面前的桌子就相當于記憶體,能放下更多的書(資料),但是找起來和看起來就要花費一些時間,相比 CPU Cache 慢不少,而圖書館的書架相當于硬碟,能放下比記憶體更多的資料,但找起來就更費時間了,可以說是最慢的存盤器設備了,
從 暫存器、CPU Cache,到記憶體、硬碟,這樣一層層下來的存盤器,訪問速度越來越慢,存盤容量越來越大,價格也越來越便宜,而且每個存盤器只和相鄰的一層存盤器設備打交道,于是這樣就形成了存盤器的層次結構,
再來回答,開頭的問題:那機械硬碟、固態硬碟、記憶體這三個存盤器,到底和 CPU L1 Cache 相比速度差多少倍呢?
CPU L1 Cache 隨機訪問延時是 1 納秒,記憶體則是 100 納秒,所以 CPU L1 Cache 比記憶體快 100 倍左右,
SSD 隨機訪問延時是 150 微妙,所以 CPU L1 Cache 比 SSD 快 150000 倍左右,
最慢的機械硬碟隨機訪問延時已經高達 10 毫秒,我們來看看機械硬碟到底有多「龜速」:
- SSD 比機械硬碟快 70 倍左右;
- 記憶體比機械硬碟快 100000 倍左右;
- CPU L1 Cache 比機械硬碟快 10000000 倍左右;
我們把上述的時間比例差異放大后,就能非常直觀感受到它們的性能差異了,如果 CPU 訪問 L1 Cache 的快取時間是 1 秒,那訪問記憶體則需要大約 2 分鐘,隨機訪問 SSD 里的資料則需要 1.7 天,訪問機械硬碟那更久,長達近 4 個月,
可以發現,不同的存盤器之間性能差距很大,構造存盤器分級很有意義,分級的目的是要構造快取體系,
絮叨
大家好,我是小林,一個專為大家圖解的工具人,歡迎微信搜索「小林coding」,關注公眾號,這里有好多圖解等著你呢!
另外,如果覺得文章對你有幫助,歡迎分享給你的朋友,也給小林點個「點和收藏」,這對小林非常重要,謝謝你們,給各位小姐姐小哥哥們抱拳了,我們下次見!*
推薦閱讀
CPU 執行程式的秘密,藏在了這 15 張圖里
原來 8 張圖,就可以搞懂「零拷貝」了
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/172226.html
標籤:其他
上一篇:論文閱讀:Fixation Prediction for 360° Video Streaming in Head-Mounted Virtual Reality
下一篇:計算機網路——計算機網路和因特網