上一篇文章介紹了3道常見的SQL筆試題,反響還算是不錯,于是乎,接下來的幾天,菌哥將每天為大家分享一些關于大資料面試的殺招,祝小伙伴們都能早日找到合適的作業~

一、什么是Hive,為什么要用Hive,你是如何理解Hive?
面試官往往一上來就一個“靈魂三連問”,很多沒有提前準備好的小伙伴基本回答得都磕磕絆絆,效果不是很好,下面貼出菌哥的回答:
Hive是基于Hadoop的一個資料倉庫工具,可以將結構化的資料檔案映射為一張資料庫表,并提供類SQL查詢功能(HQL),Hive本質是將SQL轉換為MapReduce的任務進行運算,
個人理解:hive存的是和hdfs的映射關系,hive是邏輯上的資料倉庫,實際操作的都是hdfs上的檔案,HQL就是用sql語法來寫的mr程式,
二、介紹一下Hive的架構
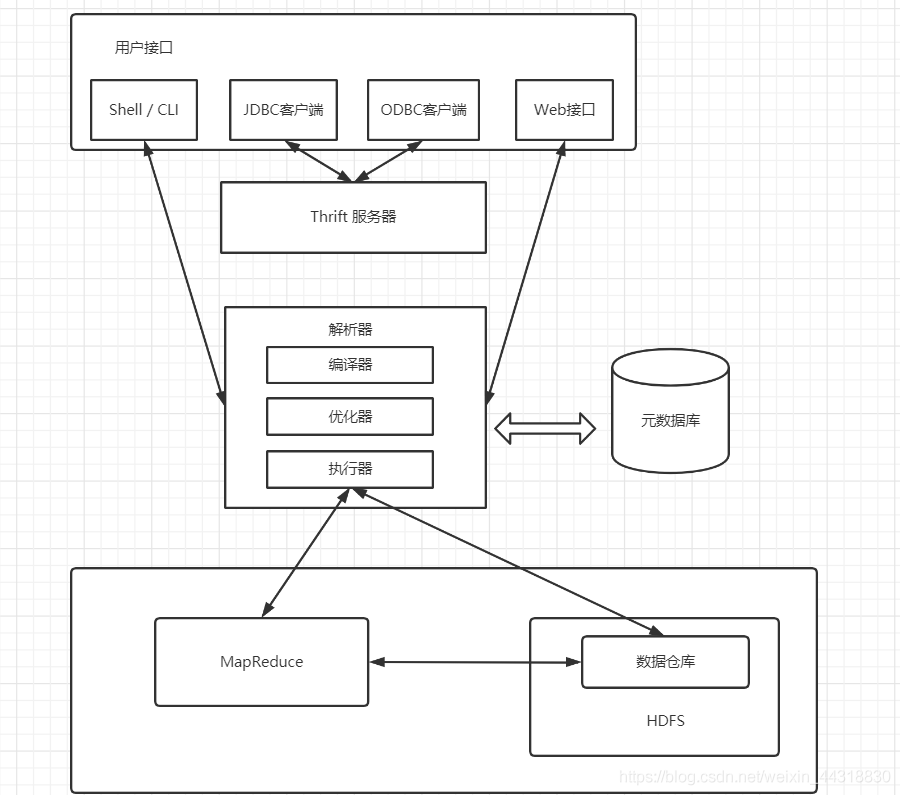
- Hive可以通過CLI,JDBC和 ODBC 等客戶端進行訪問,除此之外,Hive還支持 WUI 訪問
- Hive內部執行流程:決議器(決議SQL陳述句)、編譯器(把SQL陳述句編譯成MapReduce程式)、優化器(優化MapReduce程式)、執行器(將MapReduce程式運行的結果提交到HDFS)
- Hive的元資料保存在資料庫中,如保存在MySQL,SQLServer,PostgreSQL,Oracle及Derby等資料庫中,Hive中的元資料資訊包含表名,列名,磁區及其屬性,表的屬性(包括是否為外部表),表資料所在目錄等,
- Hive將大部分 HiveSQL陳述句轉化為MapReduce作業提交到Hadoop上執行;少數HiveSQL陳述句不會轉化為MapReduce作業,直接從DataNode上獲取資料后按照順序輸出,
三、Hive和資料庫比較
Hive 和 資料庫 實際上并沒有可比性,除了擁有類似的查詢語言,再無類似之處,
- 資料存盤位置
Hive 存盤在HDFS,資料庫將資料保存在塊設備或者本地檔案系統中,
- 資料更新
Hive中不建議對資料的改寫,而資料庫中的資料通常是需要經常進行修改的,
- 執行延遲
Hive 執行延遲較高,資料庫的執行延遲較低,當然,這個是有條件的,即資料規模較小,當資料規模大到超過資料庫的處理能力的時候,Hive的并行計算顯然能體現出優勢,
- 資料規模
Hive支持很大規模的資料計算;資料庫可以支持的資料規模較小,
四、了解和使用過哪些Hive函式
這個可以回答的內容就非常多了
例如常見的關系函式 =,<>,<,LIKE,
日期函式to_date,year,second,weekofyear,datediff,
條件函式IF,CASE,NVL
字串函式length,reverse,concat…
更多的基本函式不一一列舉了,感覺面試官更想聽的是開窗函式,例如:rank,row_number,dense_rank…
而開窗函式的使用可以說是大資料筆試的熱門考點,所以說嘛,你們都懂得~
五、內部表和外部表的區別,以及各自的使用場景
這個感覺出現的頻率也很高,基本在面試中都會被問到,
- 內部表
如果Hive中沒有特別指定,則默認創建的表都是管理表,也稱內部表,由Hive負責管理表中的資料,管理表不共享資料,洗掉管理表時,會洗掉管理表中的資料和元資料資訊,
- 外部表
當一份資料需要被共享時,可以創建一個外部表指向這份資料,
洗掉該表并不會洗掉掉原始資料,洗掉的是表的元資料,當表結構或者磁區數發生變化時,需要進行一步修復的操作,
六、Sort By,Order By,Distrbute By,Cluster By 的區別
這是一道很容易混淆的題目,就算不被問到,也是必須要掌握清楚的,
- Sort By:磁區內有序
- Order By:全域排序,只有一個Reducer
- Distrbute By:類似MR中Partition,進行磁區,結合sort by使用
- Cluster By:當Distribute by和Sorts by欄位相同時,可以使用Cluster by方式,Cluster by除了具有Distribute by的功能外還兼具Sort by的功能,但是排序只能是升序排序,不能指定排序規則為ASC或者DESC,
七、Hive視窗函式的區別
- RANK() 排序相同時會重復,總數不會變,例如
1224 - DENSE_RANK() 排序相同時會重復,總數會減少,例如
1223 - ROW_NUMBER() 會根據順序去計算,例如
1234
八、是否自定義過UDF,UDTF,簡述步驟
這個時候,面試官可能看你面試得挺順利的,打算問你點“難題”:
在專案中是否自定義過UDF、UDTF函式,以及用他們處理了什么問題,及自定義步驟?
你可以這么回答:
<1> 自定義過
<2> 我一般用UDF函式決議公共欄位;用UDTF函式決議事件欄位
具體的步驟對應如下:
自定義UDF:繼承UDF,重寫evaluate方法
自定義UDTF:繼承自GenericUDTF,重寫3個方法:initialize(自定義輸出的列名和型別),process(將結果回傳forward(result)),close
為什么要自定義UDF/UDTF?
因為自定義函式,可以自己埋點Log列印日志,出錯或者資料例外,方便除錯
九、請介紹下你熟知的Hive優化
當被問到優化,你應該慶幸自己這趟面試來得值了,為啥?就沖著菌哥給你分析下面的這九大步,面試官還不得當場呆住,這波穩了的節奏~
- MapJoin
如果不指定MapJoin或者不符合MapJoin的條件,那么Hive決議器會將Join操作轉換成Common Join,即:在Reduce階段完成join,容易發生資料傾斜,可以用MapJoin把小表全部加載到記憶體在map端進行join,避免reducer處理,
- 行列過濾
列處理:在SELECT中,只拿需要的列,如果有,盡量使用磁區過濾,少用SELECT *,
行處理:在磁區剪裁中,當使用外關聯時,如果將副表的過濾條件寫在Where后面,那么就會先全表關聯,之后再過濾,
- 合理設定Map數
是不是map數越多越好?
答案是否定的,如果一個任務有很多小檔案(遠遠小于塊大小128m),則每個小檔案也會被當做一個塊,用一個map任務來完成,而一個map任務啟動和初始化的時間遠遠大于邏輯處理的時間,就會造成很大的資源浪費 ,而且,同時可執行的map數是受限的,此時我們就應該減少map數量,
- 合理設定Reduce數
Reduce個數并不是越多越好
(1)過多的啟動和初始化Reduce也會消耗時間和資源;
(2)另外,有多少個Reduce,就會有多少個輸出檔案,如果生成了很多個小檔案,那么如果這些小檔案作為下一個任務的輸入,則也會出現小檔案過多的問題;
在設定Reduce個數的時候也需要考慮這兩個原則:處理大資料量利用合適的Reduce數;使單個Reduce任務處理資料量大小要合適;
- 嚴格模式
嚴格模式下,會有以下特點:
①對于磁區表,用戶不允許掃描所有磁區
②使用了order by陳述句的查詢,要求必須使用limit陳述句
③限制笛卡爾積的查詢
- 開啟map端combiner(不影響最終業務邏輯)
這個就屬于配置層面上的優化了,需要我們手動開啟 set hive.map.aggr=true;
- 壓縮(選擇快的)
設定map端輸出中間結、果壓縮,(不完全是解決資料傾斜的問題,但是減少了IO讀寫和網路傳輸,能提高很多效率)
- 小檔案進行合并
在Map執行前合并小檔案,減少Map數:CombineHiveInputFormat具有對小檔案進行合并的功能(系統默認的格式),HiveInputFormat沒有對小檔案合并功能,
- 其他
列式存盤,采用磁區技術,開啟JVM重用…類似的技術非常多,大家選擇一些方便記憶的就OK,
十、了解過資料傾斜嗎,是如何產生的,你又是怎么解決的?
資料傾斜和第九步談到的的性能調優,但凡有點作業經驗的老工程師都會告訴你,這都是面試必問的!那怎么才能回答好呢,慢慢往下看~
- 概念:
資料的分布不平衡,某些地方特別多,某些地方又特別少,導致的在處理資料的時候,有些很快就處理完了,而有些又遲遲未能處理完,導致整體任務最終遲遲無法完成,這種現象就是資料傾斜
- 如何產生
① key的分布不均勻或者說某些key太集中
② 業務資料自身的特性,例如不同資料型別關聯產生資料傾斜
③ SQL陳述句導致的資料傾斜
- 如何解決
① 開啟map端combiner(不影響最終業務邏輯)
② 開啟資料傾斜時負載均衡
③ 控制空值分布
將為空的key轉變為字串加亂數或純亂數,將因空值而造成傾斜的資料分配到多個Reducer
④ SQL陳述句調整
a ) 選用join key 分布最均勻的表作為驅動表,做好列裁剪和filter操作,以達到兩表join的時候,資料量相對變小的效果,
b ) 大小表Join:使用map join讓小的維度表(1000條以下的記錄條數)先進記憶體,在Map端完成Reduce,
c ) 大表Join大表:把空值的Key變成一個字串加上一個亂數,把傾斜的資料分到不同的reduce上,由于null值關聯不上,處理后并不影響最終的結果,
d ) count distinct大量相同特殊值:count distinct 時,將值為空的情況單獨處理,如果是計算count distinct,可以不用處理,直接過濾,在最后結果中加1,如果還有其他計算,需要進行group by,可以先將值為空的記錄單獨處理,再和其他計算結果進行union,
十一、磁區表和分桶表各自的優點能介紹一下嗎?
前面剛被問到內部表與外部表的區別,現在終于到了磁區表和分桶表~作為Hive常用的幾種管理表,被問到也是意料之中!
- 磁區表
- 介紹
1、磁區使用的是表外欄位,需要指定欄位型別
2、磁區通過關鍵字partitioned by(partition_name string)宣告
3、磁區劃分粒度較粗
- 優點
將資料按區域劃分開,查詢時不用掃描無關的資料,加快查詢速度
- 分桶表
- 介紹
1、分桶使用的是表內欄位,已經知道欄位型別,不需要再指定,
2、分桶表通過關鍵字clustered by(column_name) into … buckets宣告
3、分桶是更細粒度的劃分、管理資料,可以對表進行先磁區再分桶的劃分策略
- 優點
用于資料取樣;能夠起到優化加速的作用
回答到這里已經非常不錯,面試官可能又問了:
小伙幾,能講解一下分桶的邏輯嗎?
哈哈哈,好吧~誰讓我看了菌哥寫的殺招,有備而來,絲毫不懼!!!
分桶邏輯:對分桶欄位求哈希值,用哈希值與分桶的數量取余,余幾,這個資料就放在那個桶內,
十二、了解過動態磁區嗎,它和靜態磁區的區別是什么?能簡單講下動態磁區的底層原理嗎?
都到了這一步,沒有撤退可言,
- 靜態磁區與動態磁區的主要區別在于靜態磁區是手動指定,而動態磁區是通過資料來進行判斷
- 詳細來說,靜態磁區的列是在編譯時期,通過用戶傳遞來決定的;動態磁區只有在 SQL 執行時才能決定
- 簡單理解就是靜態磁區是只給固定的值,動態磁區是基于查詢引數的位置去推斷磁區的名稱,從而建立磁區
十三、使用過Hive的視圖和索引嗎,簡單介紹一下
可能有的朋友在學習的程序中沒機會使用到視圖和索引,這里菌哥就簡單介紹一下如何在面試的時候回答,更詳細的實操應該等著你們后面去實踐喲~
- Hive視圖
視圖是一種使用查詢陳述句定義的虛擬表,是資料的一種邏輯結構,創建視圖時不會把視圖存盤到磁盤上,定義視圖的查詢陳述句只有在執行視圖的陳述句時才會被執行,
通過引入視圖機制,可以簡化查詢邏輯,提高了用戶效率與用戶滿意度,
注意:視圖是只讀的,不能向視圖中插入或是加載資料
- Hive索引
和關系型資料庫中的索引一樣,Hive也支持在表中建立索引,適當的索引可以優化Hive查詢資料的性能,但是索引需要額外的存盤空間,因此在創建索引時需要考慮索引的必要性,
注意:Hive不支持直接使用DROP TABLE陳述句洗掉索引表,如果創建索引的表被洗掉了,則其對應的索引和索引表也會被洗掉;如果表的某個磁區被洗掉了,則該磁區對應的磁區索引也會被洗掉,
彩蛋
為了能鼓勵大家多學會總結,菌在這里貼上自己平時做的思維導圖,需要的朋友,可以關注博主個人微信公眾號【猿人菌】,后臺回復“思維導圖”即可獲取,
結語
本篇純當試個水,有任何好的想法或者建議可以在評論區留言,或者直接私信我也ok,后期會考慮出一些大資料面試的場景題,在最美的年華,做最好的自己,我是00后Alice,我們下一期見~~
一鍵三連,養成習慣~
文章持續更新,可以微信搜一搜「 猿人菌 」第一時間閱讀,思維導圖,大資料書籍,大資料高頻面試題,海量一線大廠面經…期待您的關注!
 CSDN認證博客專家
CSDN博客專家
大資料學者
追夢人
CSDN認證博客專家
CSDN博客專家
大資料學者
追夢人
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/176635.html
標籤:其他