上一篇文章為大家總結了一些關于Hive的熱門考點,得到了一些朋友的肯定與轉發,菌菌就覺得花時間去做這些知識整合是非常有價值,有意義的一件事,本篇文章,讓我們有幸一起來閱讀一下,該怎么準備Hadoop的內容,才有機會在面試程序占據上風,

一、什么是Hadoop?
這是一個看著不起眼,實則“送命題”的典型,往往大家關于大資料的其他內容準備得非常充分,反倒問你什么是Hadoop卻有點猝不及防,回答磕磕絆絆,給面試官的印象就很不好,另外,回答這個問題,一定要從事物本身上升到廣義去介紹,面試官往往通過這個問題來判斷你是否具有最基本的認知能力,
Hadoop是一個能夠對大量資料進行分布式處理的軟體框架,以一種可靠、高效、可伸縮的方式進行資料處理,主要包括三部分內容:Hdfs,MapReduce,Yarn
Hadoop在廣義上指一個生態圈,泛指大資料技術相關的開源組件或產品,如HBase,Hive,Spark,Zookeeper,Kafka,flume…

二、能跟我介紹下Hadoop和Spark的差異嗎?
被問到也不要驚訝,面試官往往通過你對于不同技術的差異描述,就能看出你是不是真的具有很強的學習能力,
| Hadoop | Spark | |
|---|---|---|
| 型別 | 基礎平臺,包含計算,存盤,調度 | 分布式計算工具 |
| 場景 | 大規模資料集上的批處理 | 迭代計算,互動式計算,流計算 |
| 價格 | 對機器要求低,便宜 | 對記憶體有要求,相對較貴 |
| 編程范式 | MapReduce,API 較為底層,演算法適應性差 | RDD組成DAG有向無環圖,API較為頂層,方便使用 |
| 資料存盤結構 | MapReduce中間計算結果存在HDFS磁盤上,延遲大 | RDD中間運算結果存在記憶體中,延遲小 |
| 運行方式 | Task以行程方式維護,任務啟動慢 | Task以執行緒方式維護,任務啟動快 |
三、Hadoop常見的版本有哪些,分別有哪些特點,你一般是如何進行選擇的?
這個完全就是基于個人的經驗之談的,如果平時沒有細致研究過這些,這個問題一定是答不好的,
由于Hadoop的飛速發展,功能不斷更新和完善,Hadoop的版本非常多,同時也顯得雜亂,目前市面上,主流的是以下幾個版本:
- Apache 社區版本
Apache 社區版本 完全開源,免費,是非商業版本,Apache社區的Hadoop版本分支較多,而且部分Hadoop存在Bug,在選擇Hadoop、Hbase、Hive等時,需要考慮兼容性,同時,這個版本的Hadoop的部署對Hadoop開發人員或運維人員的技術要求比較高,
- Cloudera版本
Cloudera 版本 開源,免費,有商業版和非商業版本,是在Apache社區版本的Hadoop基礎上,選擇相對穩定版本的Hadoop,進行開發和維護的Hadoop版本,由于此版本的Hadoop在開發程序中對其他的框架的集成進行了大量的兼容性測驗,因此使用者不必考慮Hadoop、Hbase、Hive等在使用程序中版本的兼容性問題,大大節省了使用者在除錯兼容性方面的時間成本,
- Hortonworks版本
Hortonworks 版本 的 Hadoop 開源、免費,有商業和非商業版本,其在 Apache 的基礎上修改,對相關的組件或功能進行了二次開發,其中商業版本的功能是最強大,最齊全的,
所以基于以上特點進行選擇,我們一般剛接觸大資料用的就是CDH,在作業中大概率用 Apache 或者 Hortonworks,
四、能簡單介紹Hadoop1.0,2.0,3.0的區別嗎?
一般能問出這種問題的面試官都是“狠人”,基本技術都不差,他們往往是更希望應聘者能在這些“細節”問題上脫穎而出,
Hadoop1.0由分布式存盤系統HDFS和分布式計算框架MapReduce組成,其中HDFS由一個NameNode和多個DateNode組成,MapReduce由一個JobTracker和多個TaskTracker組成,在Hadoop1.0中容易導致單點故障,拓展性差,性能低,支持編程模型單一的問題,
Hadoop2.0即為克服Hadoop1.0中的不足,提出了以下關鍵特性:
- Yarn:它是Hadoop2.0引入的一個全新的通用資源管理系統,完全代替了Hadoop1.0中的JobTracker,在MRv1 中的 JobTracker 資源管理和作業跟蹤的功能被抽象為 ResourceManager 和 AppMaster 兩個組件,Yarn 還支持多種應用程式和框架,提供統一的資源調度和管理功能
- NameNode 單點故障得以解決:Hadoop2.2.0 同時解決了 NameNode 單點故障問題和記憶體受限問題,并提供 NFS,QJM 和 Zookeeper 三種可選的共享存盤系統
- HDFS 快照:指 HDFS(或子系統)在某一時刻的只讀鏡像,該只讀鏡像對于防止資料誤刪、丟失等是非常重要的,例如,管理員可定時為重要檔案或目錄做快照,當發生了資料誤刪或者丟失的現象時,管理員可以將這個資料快照作為恢復資料的依據
- 支持Windows 作業系統:Hadoop 2.2.0 版本的一個重大改進就是開始支持 Windows 作業系統
- Append:新版本的 Hadoop 引入了對檔案的追加操作
同時,新版本的Hadoop對于HDFS做了兩個非常重要的增強,分別是支持異構的存盤層次和通過資料節點為存盤在HDFS中的資料提供記憶體緩沖功能
相比于Hadoop2.0,Hadoop3.0 是直接基于 JDK1.8 發布的一個新版本,同時,Hadoop3.0引入了一些重要的功能和特性
- HDFS可擦除編碼:這項技術使HDFS在不降低可靠性的前提下節省了很大一部分存盤空間
- 多NameNode支持:在Hadoop3.0中,新增了對多NameNode的支持,當然,處于Active狀態的NameNode實體必須只有一個,也就是說,從Hadoop3.0開始,在同一個集群中,支持一個 ActiveNameNode 和 多個 StandbyNameNode 的部署方式,
- MR Native Task優化
- Yarn基于cgroup 的記憶體和磁盤 I/O 隔離
- Yarn container resizing
限于篇幅原因,這還都只是部分特性,大家多注意菌哥標記顏色的部分,就足以應對面試了,
五、說下Hadoop常用的埠號
Hadoop常用的埠號總共就那么幾個,大家選擇好記的幾個就OK了
- dfs.namenode.http-address:50070
- dfs.datanode.http-address:50075
- SecondaryNameNode:50090
- dfs.datanode.address:50010
- fs.defaultFS:8020 或者9000
- yarn.resourcemanager.webapp.address:8088
- 歷史服務器web訪問埠:19888
六、簡單介紹一下搭建Hadoop集群的流程
這個問題實在基礎,這里也簡單概述下,
在正式搭建之前,我們需要準備以下6步:
準備作業
- 關閉防火墻
- 關閉SELINUX
- 修改主機名
- ssh無密碼拷貝資料
- 設定主機名和IP對應
- jdk1.8安裝
搭建作業:
- 下載并解壓Hadoop的jar包
- 配置hadoop的核心檔案
- 格式化namenode
- 啟動…
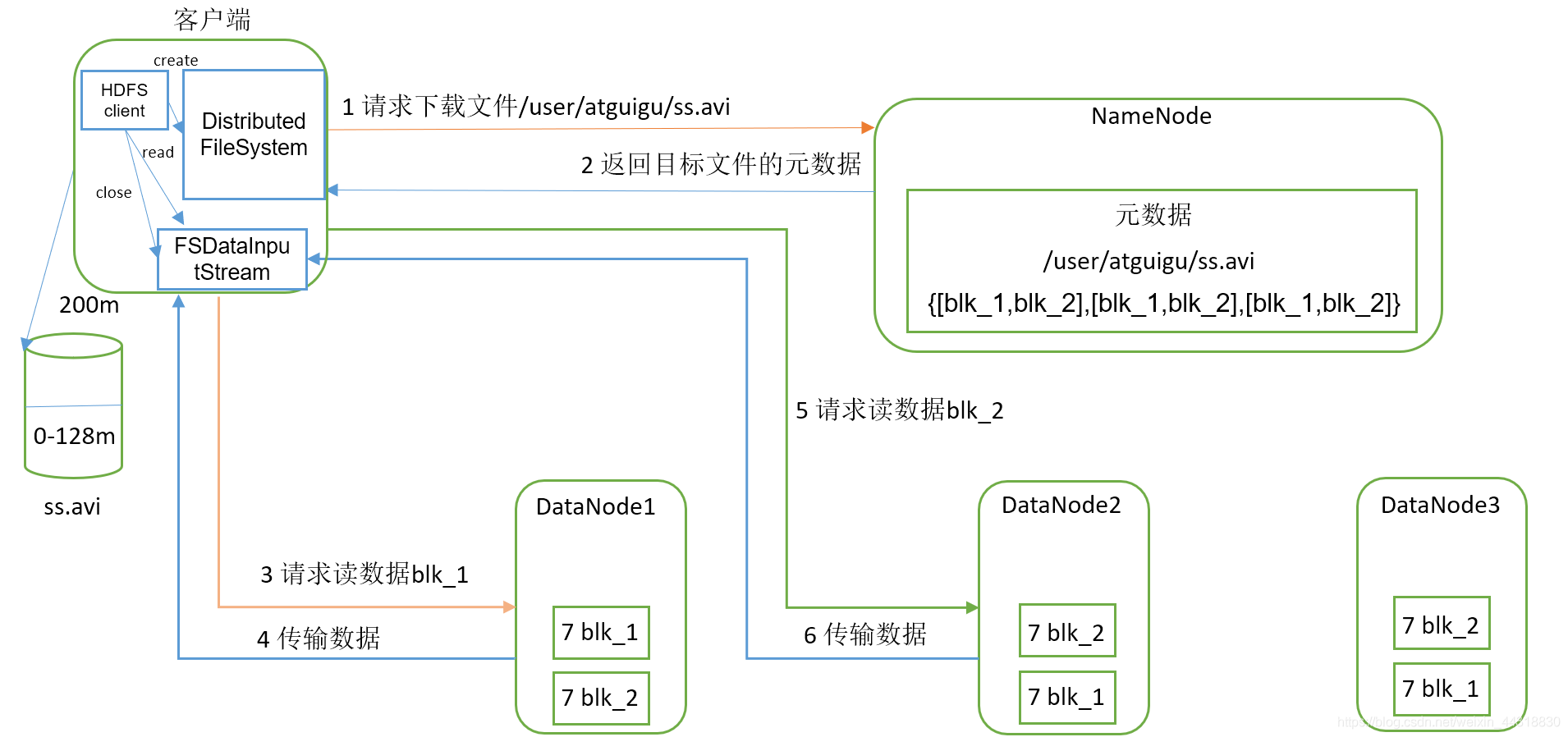
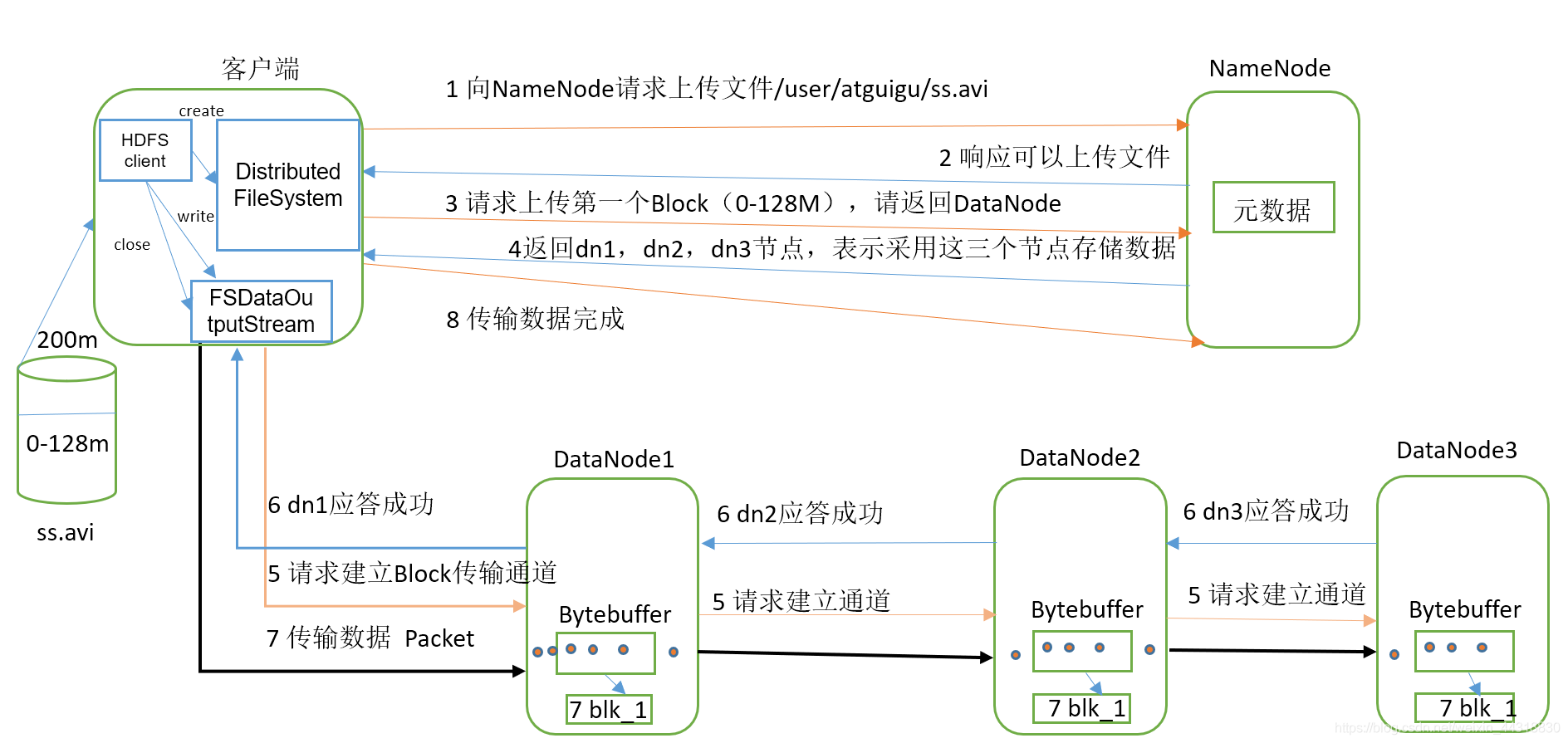
七、介紹一下HDFS讀寫流程
這個問題非常基礎,同時出現的頻率也是例外的高,但是大家也不要被HDFS的讀寫流程嚇到,相信看到這里的朋友,應該不是第一次背HDFS讀寫繁多的步驟了,菌哥在這里也不建議大家去背那些文字,這里貼上兩張圖,大家要學會做到心中有圖,萬般皆易,
- HDFS讀資料流程
- HDFS的寫資料流程
八、介紹一下MapReduce的Shuffle程序,并給出Hadoop優化的方案(包括:壓縮、小檔案、集群的優化)
MapReduce資料讀取并寫入HDFS流程實際上是有10步

其中最重要,也是最不好講的就是 shuffle 階段,當面試官著重要求你介紹 Shuffle 階段時,可就不能像上邊圖上寫的那樣簡單去介紹了,
你可以這么說:
1) Map方法之后Reduce方法之前這段處理程序叫Shuffle
2) Map方法之后,資料首先進入到磁區方法,把資料標記好磁區,然后把資料發送到環形緩沖區;環形緩沖區默認大小100m,環形緩沖區達到80%時,進行溢寫;溢寫前對資料進行排序,排序按照對key的索引進行字典順序排序,排序的手段快排;溢寫產生大量溢寫檔案,需要對溢寫檔案進行歸并排序;對溢寫的檔案也可以進行Combiner操作,前提是匯總操作,求平均值不行,最后將檔案按照磁區存盤到磁盤,等待Reduce端拉取,
3)每個Reduce拉取Map端對應磁區的資料,拉取資料后先存盤到記憶體中,記憶體不夠了,再存盤到磁盤,拉取完所有資料后,采用歸并排序將記憶體和磁盤中的資料都進行排序,在進入Reduce方法前,可以對資料進行分組操作,
講到這里你可能已經口干舌燥,想緩一緩,
但面試官可能對你非常欣賞:
小伙幾,看來你對MapReduce的Shuffle階段掌握很透徹啊,那你跟我再介紹一下你是如何基于MapReduce做Hadoop的優化的,可以給你個提示,可以從壓縮,小檔案,集群優化層面去考慮哦~
可能你心里仿佛有一萬只草泥馬在奔騰,但是為了順利拿下本輪面試,你還是不得不開始思考,如何回答比較好:
1)HDFS小檔案影響
- 影響NameNode的壽命,因為檔案元資料存盤在NameNode的記憶體中
- 影響計算引擎的任務數量,比如每個小的檔案都會生成一個Map任務
2)資料輸入小檔案處理
- 合并小檔案:對小檔案進行歸檔(Har)、自定義Inputformat將小檔案存盤成SequenceFile檔案,
- 采用ConbinFileInputFormat來作為輸入,解決輸入端大量小檔案場景
- 對于大量小檔案Job,可以開啟JVM重用
3)Map階段
- 增大環形緩沖區大小,由100m擴大到200m
- 增大環形緩沖區溢寫的比例,由80%擴大到90%
- 減少對溢寫檔案的merge次數,(10個檔案,一次20個merge)
- 不影響實際業務的前提下,采用Combiner提前合并,減少 I/O
4)Reduce階段
- 合理設定Map和Reduce數:兩個都不能設定太少,也不能設定太多,太少,會導致Task等待,延長處理時間;太多,會導致 Map、Reduce任務間競爭資源,造成處理超時等錯誤,
- 設定Map、Reduce共存:調整
slowstart.completedmaps引數,使Map運行到一定程度后,Reduce也開始運行,減少Reduce的等待時間 - 規避使用Reduce,因為Reduce在用于連接資料集的時候將會產生大量的網路消耗,
- 增加每個Reduce去Map中拿資料的并行數
- 集群性能可以的前提下,增大Reduce端存盤資料記憶體的大小
5) IO 傳輸
- 采用資料壓縮的方式,減少網路IO的的時間
- 使用SequenceFile二進制檔案
6) 整體
- MapTask默認記憶體大小為1G,可以增加MapTask記憶體大小為4
- ReduceTask默認記憶體大小為1G,可以增加ReduceTask記憶體大小為4-5g
- 可以增加MapTask的cpu核數,增加ReduceTask的CPU核數
- 增加每個Container的CPU核數和記憶體大小
- 調整每個Map Task和Reduce Task最大重試次數
7) 壓縮
壓縮,可以參考這張圖
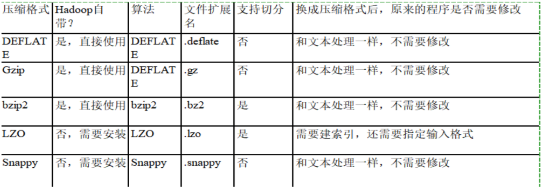
提示:如果面試程序問起,我們一般回答壓縮方式為Snappy,特點速度快,缺點無法切分(可以回答在鏈式MR中,Reduce端輸出使用bzip2壓縮,以便后續的map任務對資料進行split)
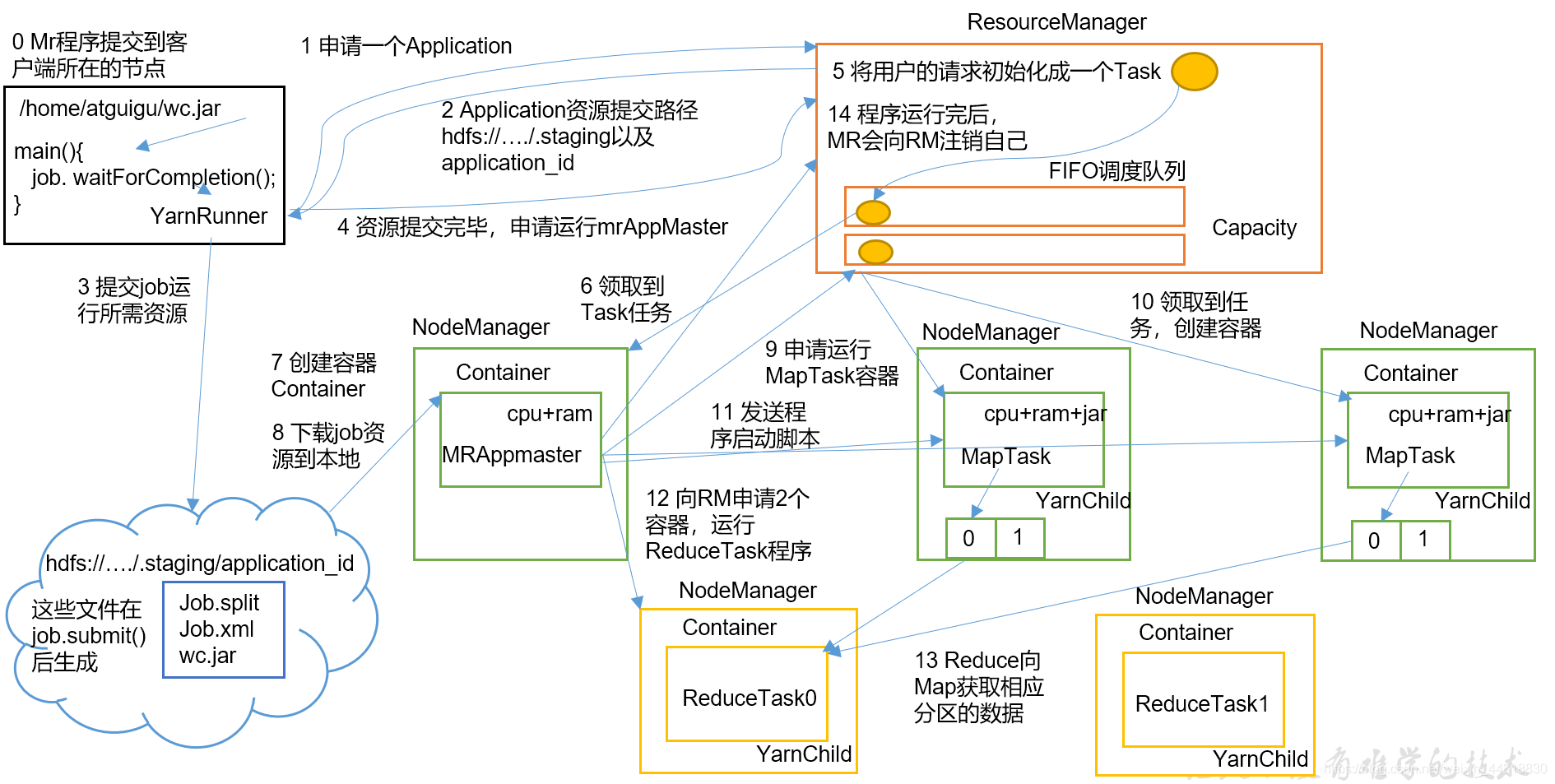
九、介紹一下 Yarn 的 Job 提交流程
這里一共也有兩個版本,分別是詳細版和簡略版,具體使用哪個還是分不同的場合,正常情況下,將簡略版的回答清楚了就很OK,詳細版的最多做個內容的補充:
- 詳細版
- 簡略版
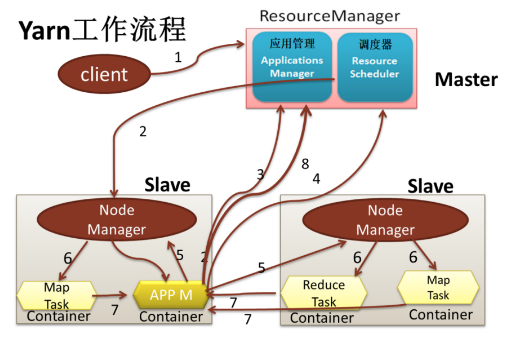
其中簡略版對應的步驟分別如下:
- client向RM提交應用程式,其中包括啟動該應用的ApplicationMaster的必須資訊,例如ApplicationMaster程式、啟動ApplicationMaster的命令、用戶程式等
- ResourceManager啟動一個container用于運行ApplicationMaster
- 啟動中的ApplicationMaster向ResourceManager注冊自己,啟動成功后與RM保持心跳
- ApplicationMaster向ResourceManager發送請求,申請相應數目的container
- 申請成功的container,由ApplicationMaster進行初始化,container的啟動資訊初始化后,AM與對應的NodeManager通信,要求NM啟動container
- NM啟動container
- container運行期間,ApplicationMaster對container進行監控,container通過RPC協議向對應的AM匯報自己的進度和狀態等資訊
- 應用運行結束后,ApplicationMaster向ResourceManager注銷自己,并允許屬于它的container被識訓
十、介紹下Yarn默認的調度器,調度器分類,以及它們之間的區別
關于Yarn的知識點考察實際上在面試中占的比重并的不多,像面試中常問的無非就Yarn的Job執行流程或者調度器的分類,答案往往也都差不多,以下回答做個參考:
1)Hadoop調度器主要分為三類:
- FIFO Scheduler:先進先出調度器:優先提交的,優先執行,后面提交的等待【生產環境不會使用】
- Capacity Scheduler:容量調度器:允許看創建多個任務對列,多個任務對列可以同時執行,但是一個佇列內部還是先進先出,【Hadoop2.7.2默認的調度器】
- Fair Scheduler:公平調度器:第一個程式在啟動時可以占用其他佇列的資源(100%占用),當其他佇列有任務提交時,占用資源的佇列需要將資源還給該任務,還資源的時候,效率比較慢,【CDH版本的yarn調度器默認】
十一、了解過哪些Hadoop的引數優化
前面付訓答完Hadoop基于壓縮,小檔案,IO的集群優化,現在又要回答引數優化,真的好煩啊(T▽T)如果你把自己放在實習生這個level,你 duck 不必研究這么多關于性能調優這塊的內容,畢竟對于稍有作業經驗的工程師來說,調優這塊是非常重要的
我們常見的Hadoop引數調優有以下幾種:
- 在hdfs-site.xml檔案中配置多目錄,最好提前配置好,否則更改目錄需要重新啟動集群
- NameNode有一個作業執行緒池,用來處理不同DataNode的并發心跳以及客戶端并發的元資料操作
dfs.namenode.handler.count=20 * log2(Cluster Size)
比如集群規模為10臺時,此引數設定為60
- 編輯日志存盤路徑dfs.namenode.edits.dir設定與鏡像檔案存盤路徑dfs.namenode.name.dir盡量分開,達到最低寫入延遲
- 服務器節點上YARN可使用的物理記憶體總量,默認是8192(MB),注意,如果你的節點記憶體資源不夠8GB,則需要調減小這個值,而YARN不會智能的探測節點的物理記憶體總量
- 單個任務可申請的最多物理記憶體量,默認是8192(MB)
十二、了解過Hadoop的基準測驗嗎?
這個完全就是基于專案經驗的面試題了,暫時回答不上來的朋友可以留意一下:
我們搭建完Hadoop集群后需要對HDFS讀寫性能和MR計算能力測驗,測驗jar包在hadoop的share檔案夾下,
十三、你是怎么處理Hadoop宕機的問題的?
相信被問到這里,一部分的小伙伴已經堅持不下去了

但言歸正傳,被問到了,我們總不能說俺不知道,灑家不會之類的吧?(?????)?下面展示一種回答,給大家來個Demo,
如果MR造成系統宕機,此時要控制Yarn同時運行的任務數,和每個任務申請的最大記憶體,調整引數:yarn.scheduler.maximum-allocation-mb(單個任務可申請的最多物理記憶體量,默認是8192MB),
如果寫入檔案過量造成NameNode宕機,那么調高Kafka的存盤大小,控制從Kafka到HDFS的寫入速度,高峰期的時候用Kafka進行快取,高峰期過去資料同步會自動跟上,
十四、你是如何解決Hadoop資料傾斜的問題的,能舉個例子嗎?
性能優化和資料傾斜,如果在面試前不好好準備,那就準備在面試時吃虧吧~其實掌握得多了,很多方法都有相通的地方,下面貼出一種靠譜的回答,大家可以借鑒下:
1)提前在map進行combine,減少傳輸的資料量
在Mapper加上combiner相當于提前進行reduce,即把一個Mapper中的相同key進行了聚合,減少shuffle程序中傳輸的資料量,以及Reducer端的計算量,
如果導致資料傾斜的key 大量分布在不同的mapper的時候,這種方法就不是很有效了
2)資料傾斜的key 大量分布在不同的mapper
在這種情況,大致有如下幾種方法:
- 區域聚合加全域聚合
第一次在map階段對那些導致了資料傾斜的key 加上1到n的隨機前綴,這樣本來相同的key 也會被分到多個Reducer 中進行區域聚合,數量就會大大降低,
第二次mapreduce,去掉key的隨機前綴,進行全域聚合,
思想:二次mr,第一次將key隨機散列到不同 reducer 進行處理達到負載均衡目的,第二次再根據去掉key的隨機前綴,按原key進行reduce處理,
這個方法進行兩次mapreduce,性能稍差,
- 增加Reducer,提升并行度
JobConf.setNumReduceTasks(int)
- 實作自定義磁區
根據資料分布情況,自定義散列函式,將key均勻分配到不同Reducer
彩蛋
為了能鼓勵大家多學會總結,菌在這里貼上自己平時做的思維導圖,需要的朋友,可以關注博主個人微信公眾號【猿人菌】,后臺回復“思維導圖”即可獲取,
結語
很高興能看到這里的朋友,有任何好的想法或者建議都可以在評論區留言,或者直接私信我也ok,后期會考慮出一些大資料面試的場景題,在最美的年華,做最好的自己,我是00后Alice,我們下一期見~~
一鍵三連,養成習慣~
文章持續更新,可以微信搜一搜「 猿人菌 」第一時間閱讀,思維導圖,大資料書籍,大資料高頻面試題,海量一線大廠面經…期待您的關注!
 CSDN認證博客專家
CSDN博客專家
大資料學者
追夢人
CSDN認證博客專家
CSDN博客專家
大資料學者
追夢人
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/178700.html
標籤:其他
下一篇:利用簡單電阻分壓原理自動測量電阻