目錄
1 任務
2 程序
2.1 熟悉常用的 Hadoop 命令
2.2 Hadoop環境搭建
1.SSH登錄權限設定
2.安裝Java環境
3.Hadoop的安裝
4.偽分布式安裝配置
2.3 Wordcount實體
2.4 搭建eclipse環境編程實作Wordcount程式
1、安裝eclipse
2.配置Hadoop-Eclipse-Plugin
3.在Eclipse中操作HDFS中的檔案
4.在Eclipse中創建MapReduce專案
5.通過 Eclipse 運行 MapReduce
2.5基于Hadoop的資料去重實體實作
1.實體描述
2.設計思路
3.程式部分代碼
4.實驗結果
3 總結
1 任務
- 熟悉常用的 Hadoop 命令
- 運行 Wordcount 實體
- 搭建 Eclipse 編程環境
- 編程實作 Wordcount 程式
2 程序
2.1 熟悉常用的 Hadoop 命令
1.利用Shell命令操作
Hadoop支持很多Shell命令,其中fs是HDFS最常用的命令,利用fs可以查看HDFS檔案系統的目錄結構、上傳和下載資料、創建檔案等,
注意
有三種shell命令方式的區別:
(1) hadoop fs
(2) hadoop dfs
(3) hdfs dfs
hadoop fs適用于任何不同的檔案系統,比如本地檔案系統和HDFS檔案系統
hadoop dfs只能適用于HDFS檔案系統
hdfs dfs跟hadoop dfs的命令作用一樣,也只能適用于HDFS檔案系統
我們可以在終端輸入如下命令,查看fs總共支持了哪些命令
./bin/hadoop fs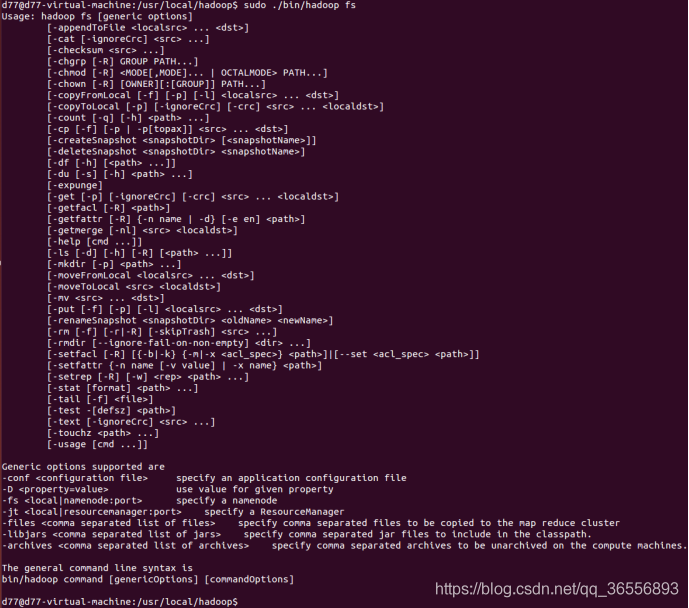
2.查看help命令如何使用

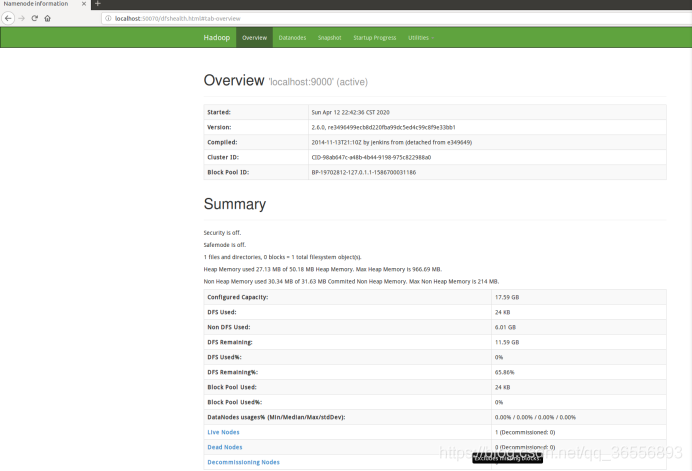
3.利用HDFS的Web界面管理
2.2 Hadoop環境搭建
1.SSH登錄權限設定
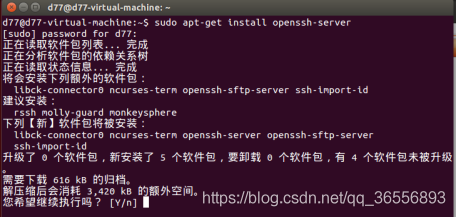
(1) Ubuntu 默認已安裝了 SSH client,現在安裝 SSH server:
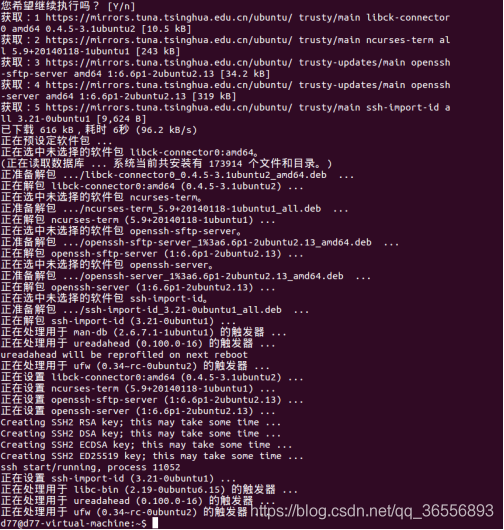
(2)安裝成功后
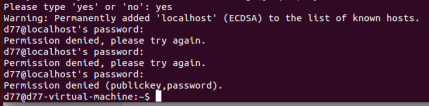
(3)登錄
![]()
(4)登錄成功
2.安裝Java環境
(1)下載JDK1.7.0
(2)下載成功

(3)環境變數的配置

(4)保存.bashrc檔案并退出vim編輯器并命令讓.bashrc檔案的配置立即生效
![]()
(5)查看是否安裝成功

3.Hadoop的安裝
(1)在計算機中建立一個共享檔案夾,并將hadoop下載到其中,并解壓
(2)將檔案名改為hadoop
![]()
(3)修改檔案權限
![]()
(4)檢查版本資訊

4.偽分布式安裝配置
(1)修改組態檔core-site.xml
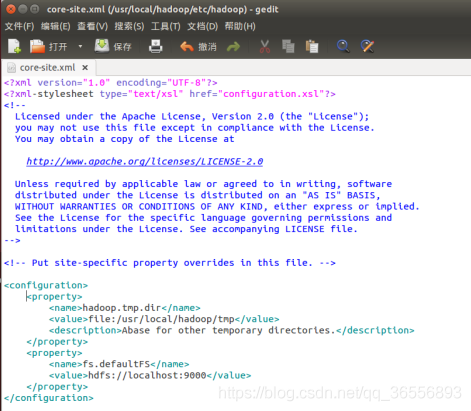
(2)修改組態檔hdfs-site.xml
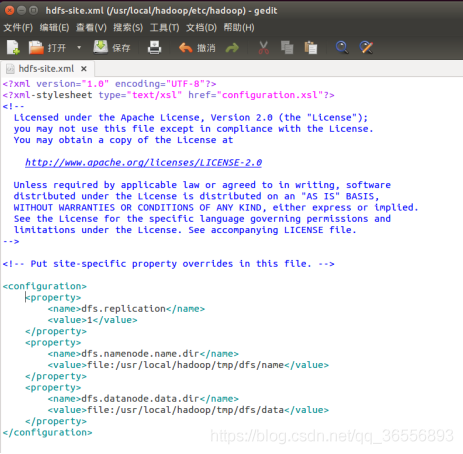
(3)初始化檔案系統
![]()
(4)初始化程序中出現環境變數配置問題,因此我們打開hadoop-env.sh檔案進行修改
![]()
(5)修改后,再次進行初始化
(6)初始化成功
2.3 Wordcount實體
1.格式化namenode
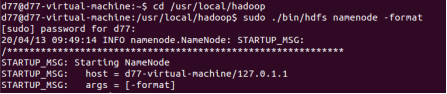
2.格式化成功
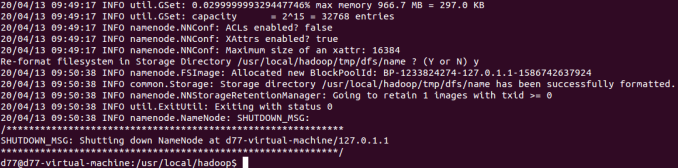
3.啟動行程

4.查看行程

5.把本地到hadoop/input (自己建立的)檔案夾中到檔案上傳到hdfs檔案系統到input檔案夾下
![]()
6.查看檔案是否上傳成功
![]()
7.運行wordcount實體
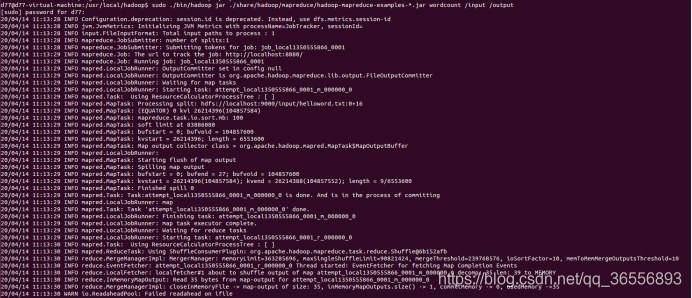
8.查看mapreduce進度

9.查看運行結果

10.將運行結果取回本地檔案系統

11.關閉行程
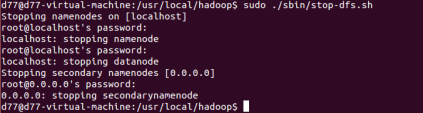
2.4 搭建eclipse環境編程實作Wordcount程式
1、安裝eclipse
(1) 下載eclipse
(2)安裝并創建快捷方式

(3)下載并安裝Hadoop-Eclipse-Plugin,在共享檔案夾中下載,再解壓
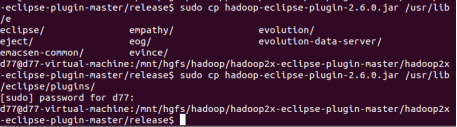
2.配置Hadoop-Eclipse-Plugin
(1)啟動eclipse
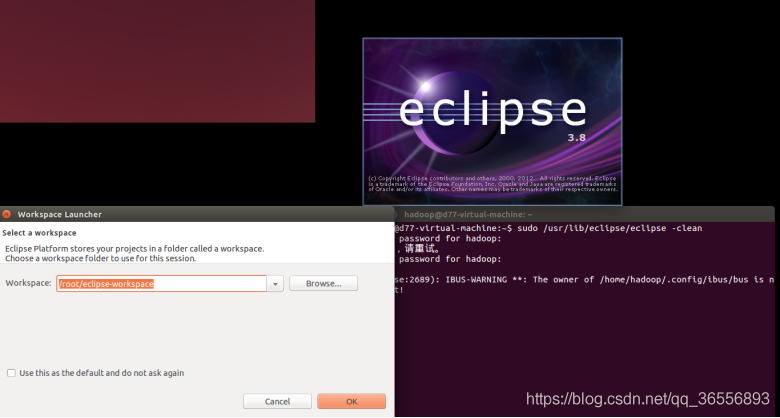
(2)安裝好Hadoop-Eclipse-Plugin插件的效果
(3)對插件的進一步配置
① 選擇Hadoop的安裝目錄
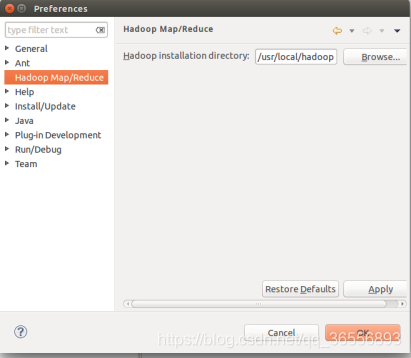
② 切換Map/Reduce開發視圖
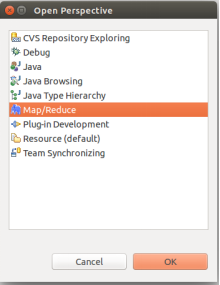
③ Hadoop Location的設定
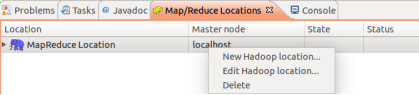
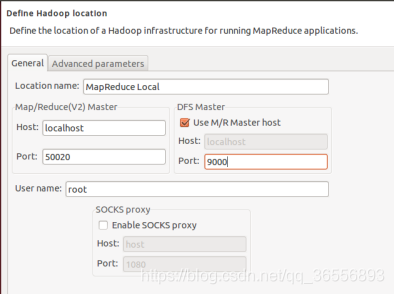
④ 建立與Hadoop集群的連接
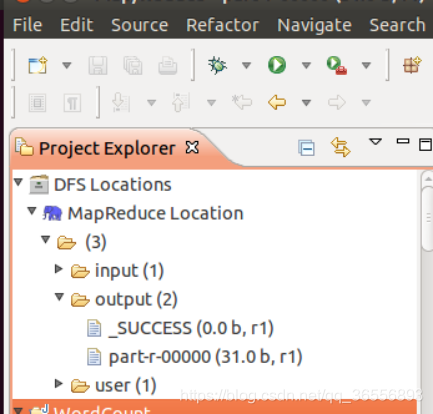
3.在Eclipse中操作HDFS中的檔案
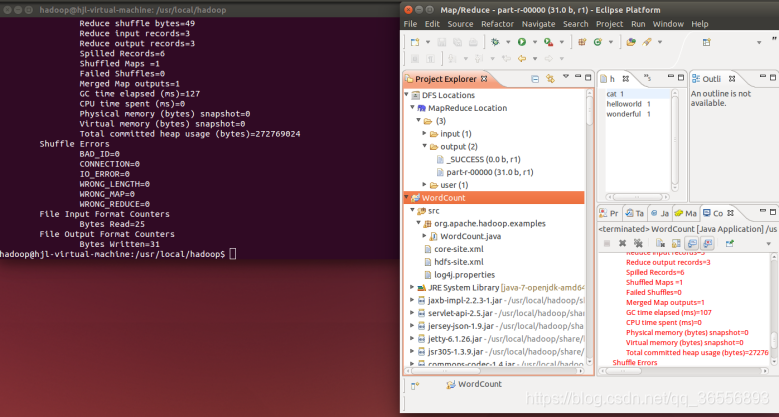
配置好后,點擊左側 Project Explorer 中的 MapReduce Location (點擊三角形展開)就能直接查看 HDFS 中的檔案串列了(HDFS 中要有檔案,如下圖是 WordCount 的輸出結果),雙擊可以查看內容,右鍵點擊可以上傳、下載、洗掉 HDFS 中的檔案,無需再通過繁瑣的 hdfs dfs -ls 等命令進行操作了,
以下output/part-r-00000檔案記錄了輸出結果,
4.在Eclipse中創建MapReduce專案
(1) 創建Project
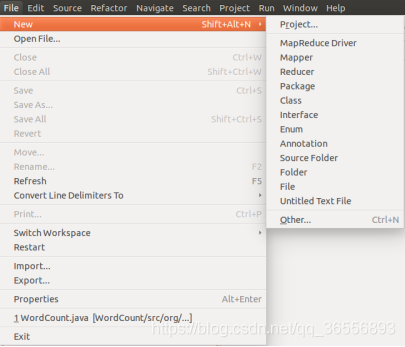
(2)創建MapReduce專案
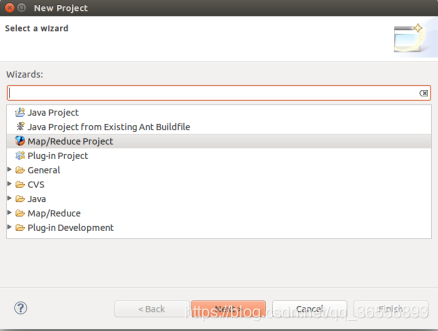
(3)填寫專案名
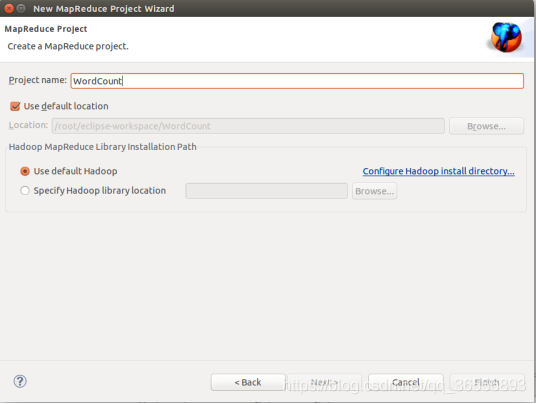
(4)專案創建完成
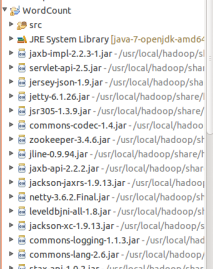
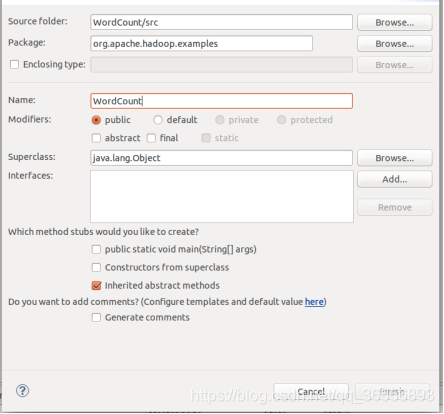
(5)新建Class
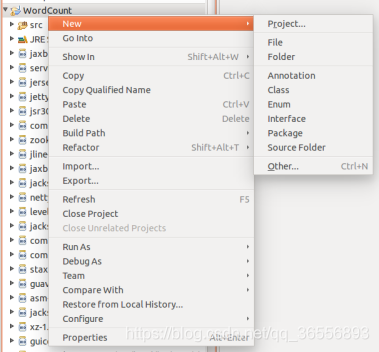
(6)填寫Class資訊
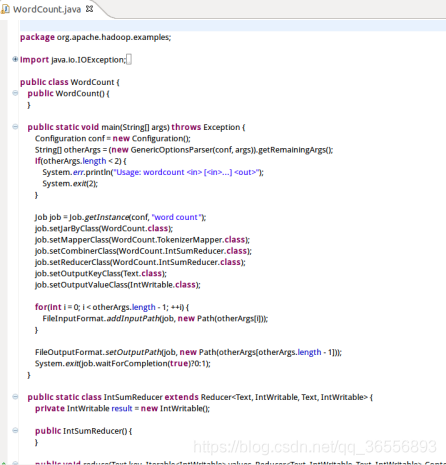
(7)編輯WordCount.java檔案
5.通過 Eclipse 運行 MapReduce
(1) 將 /usr/local/hadoop/etc/hadoop 中將有修改過的組態檔(如偽分布式需要 core-site.xml 和 hdfs-site.xml),以及 log4j.properties 復制到WordCount 專案下的 src 檔案夾
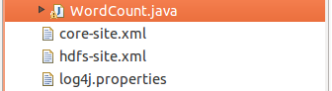
(2)Wordcount運行結果同shell指令結果對比
2.5基于Hadoop的資料去重實體實作
1.實體描述
"資料去重"主要是為了掌握和利用并行化思想來對資料進行有意義的篩選,統計大資料集上的資料種類個數、從網站日志中計算訪問地等這些看似龐雜的任務都會涉及資料去重,
對資料檔案中的資料進行去重,資料檔案中的每行都是一個資料,
2.設計思路
資料去重的最終目標是讓原始資料中出現次數超過一次的資料在輸出檔案中只出現一次,我們自然而然會想到將同一個資料的所有記錄都交給一臺reduce機器,無論這個資料出現多少次,只要在最終結果中輸出一次就可以了,具體就是reduce的輸入應該以資料作為key,而對value-list則沒有要求,當reduce接收到一個<key,value-list>時就直接將key復制到輸出的key中,并將value設定成空值,
在MapReduce流程中,map的輸出<key,value>經過shuffle程序聚集成<key,value-list>后會交給reduce,所以從設計好的reduce輸入可以反推出map的輸出key應為資料,value任意,繼續反推,map輸出資料的key為資料,而在這個實體中每個資料代表輸入檔案中的一行內容,所以map階段要完成的任務就是在采用Hadoop默認的作業輸入方式之后,將value設定為key,并直接輸出(輸出中的value任意),map中的結果經過shuffle程序之后交給reduce,reduce階段不會管每個key有多少個value,它直接將輸入的key復制為輸出的key,并輸出就可以了(輸出中的value被設定成空了),
3.程式部分代碼
public class WordCountDatededuplication {
//map將輸入中的value復制到輸出資料的key上,并直接輸出
public static class Map extends Mapper<Object,Text,Text,Text>{
private static Text line=new Text();//每行資料
//實作map函式
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
line=value;
context.write(line, new Text(""));
}
}
//reduce將輸入中的key復制到輸出資料的key上,并直接輸出
public static class Reduce extends Reducer<Text,Text,Text,Text>{
//實作reduce函式
public void reduce(Text key,Iterable<Text> values,Context context)
throws IOException,InterruptedException{
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
//這句話很關鍵
conf.set("mapred.job.tracker", "192.168.1.2:9001");
String[] ioArgs=new String[]{"dedup_in","dedup_out"};
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Data Deduplication <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "Data Deduplication");
job.setJarByClass(Dedup.class);
//設定Map、Combine和Reduce處理類
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
//設定輸出型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//設定輸入和輸出目錄
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}4.實驗結果
(1)準備測驗資料
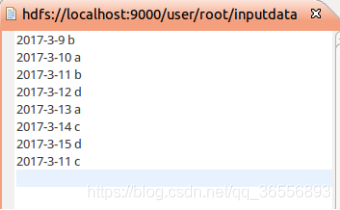
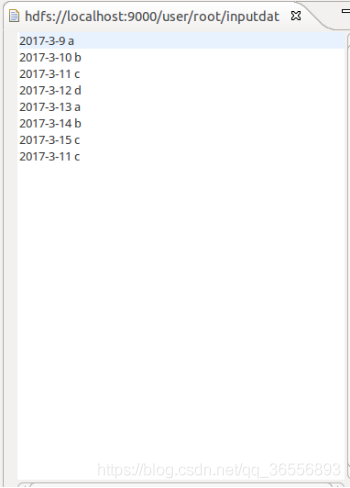
創建檔案夾inputdatadeduplication,并在該檔案夾下創建兩個檔案data1.txt和data2.txt

data1.txt檔案:
data2.txt檔案:
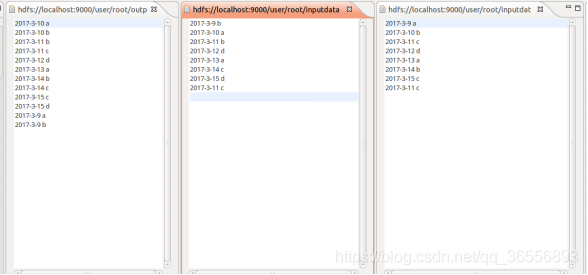
(2)查看運行結果
3 總結
首先我們啟動eclipse需要管理員的權限,這樣我們在運行這個程式時,避免了“無法訪問”的錯誤,
MapReduce實體實作的主要難點是代碼的撰寫.
希望各位既可以掌握Hadoop偽分布式的搭建程序,也熟悉一些Linux指令,鍛煉動手能力,
 CSDN認證博客專家
深度學習
神經網路
Pytorch
CSDN認證博客專家
深度學習
神經網路
Pytorch
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/191004.html
標籤:其他