一.線性回歸的基本概念
1.1 什么是回歸問題?
回歸是應用于經濟,投資等領域的一種統計學方法,它嘗試確定一個因變數(通常由 y y y表示)與一系列其他變數(稱為自變數,通常用 x x x表示)之間關系,然后通過這個關系來進行相關的預測,例如我們根據一個地區的若干年的PM2.5數值變化來估計某一天該地區的PM2.5值大小,也就是說,回歸問題就是確定一個模型 f f f,使得 y = f ( x ) y=f(x) y=f(x),若 y y y與 x x x之間是一次函式關系,則稱其為線性回歸問題(狹義上的),
1.2 一元線性回歸
給定一個資料集
D
=
(
x
?
1
,
y
1
)
,
(
x
?
2
,
y
2
)
,
.
.
.
,
(
x
?
m
,
y
m
)
D={(\vec x_1,y_1),(\vec x_2,y_2),...,(\vec x_m,y_m)}
D=(x
1?,y1?),(x
2?,y2?),...,(x
m?,ym?),后面的討論都是基于假想的資料集
D
D
D,當自變數
x
x
x只包含單個特征時,我們稱該線性回歸為一元線性回歸,其數學形式如下所示:
y
=
w
x
+
b
y=wx+b
y=wx+b
實際上一元線性回歸的數學形式就是我們所熟悉的直線方程,例如下面就是根據
y
=
x
+
1.2
y=x+1.2
y=x+1.2加上隨機誤差人工生成的一組
(
x
i
,
y
i
)
(x_i,y_i)
(xi?,yi?),顯然
x
i
x_i
xi?與
y
i
y_i
yi?之間的關系明顯滿足一元線性模型的要求,
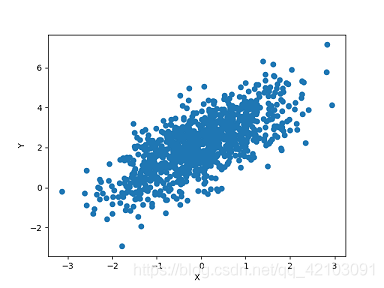
上圖資料的生成代碼如下:
size=1000
x = np.random.randn(size,1)
y = x + np.random.randn(size,1) + 2.2
1.3 多元線性回歸
多元線性回歸與一元線性回歸類似,只不過自變數
x
x
x由標量變成了向量,即
x
?
=
(
x
1
,
x
2
,
.
.
.
,
x
d
)
\vec x=(x_1,x_2,...,x_d)
x
=(x1?,x2?,...,xd?),多元線性回歸的數學形式如下:
y
=
w
1
x
1
+
w
2
x
2
+
w
3
x
3
+
.
.
.
+
w
d
x
d
+
b
y=w_1x_1+w_2x_2+w_3x_3+...+w_dx_d+b
y=w1?x1?+w2?x2?+w3?x3?+...+wd?xd?+b
同樣的,這里也給出一個能利用多元線性回歸求解的模型,下圖是基于
y
=
x
1
+
x
2
+
5.2
y=x_1+x_2 + 5.2
y=x1?+x2?+5.2(三維空間中的平面
x
+
y
+
5.2
=
z
x+y+5.2=z
x+y+5.2=z)加上隨機誤差生成的一組
(
x
?
i
,
y
i
)
(\vec x_i,y_i)
(x
i?,yi?),
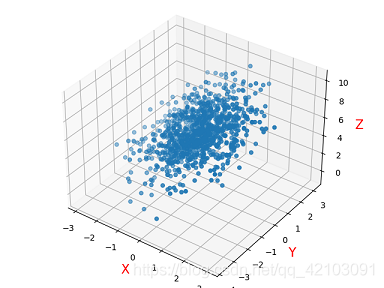
其資料生成代碼如下:
size=1000
x1 = np.random.randn(size,1)
x2 = np.random.randn(size,1)
y = x1 + x2 + np.random.randn(size,1) + 5.2
二.模型的確定
在1.2,1.3兩節中我分別基于 y = x + 1.2 y=x+1.2 y=x+1.2和 y = x 1 + x 2 + 5.2 y=x_1+x_2 + 5.2 y=x1?+x2?+5.2生成了兩個資料集,因此兩個資料集分別對應的線性回歸模型各自的理想引數分別為 w = 1 , b = 1.2 w=1,b=1.2 w=1,b=1.2和 w 1 = 1 , w 2 = 1 , b = 5.2 w_1=1,w_2=1,b=5.2 w1?=1,w2?=1,b=5.2,但在實際中,我們事先是不知道資料集所對應的模型的,那么對于一個適用于線性回歸問題的資料集來說,我們如何來尋找適合其的模型呢?另外,對于一個模型我們需要如何判斷其是否適合呢?
2.1 線性回歸模型的度量
線性回歸模型有許多的度量方式,其中均方誤差(MSE,Mean-Square-Error)是線性回歸最常用的性能度量,
2.1.1 一元線性模型的均方誤差
設一元線性模型為
f
(
x
)
=
w
x
+
b
f(x)=wx+b
f(x)=wx+b,資料集仍為
D
D
D,對于某個資料
(
x
i
,
y
i
)
(x_i,y_i)
(xi?,yi?),
y
i
y_i
yi?為真實標簽,
f
(
x
i
)
f(x_i)
f(xi?)為預測值,則均方誤差
L
L
L定義如下:
L
=
∑
i
=
1
m
(
f
(
x
i
)
?
y
i
)
2
=
∑
i
=
1
m
(
w
x
i
+
b
?
y
i
)
2
L=\sum_{i=1}^m( f(x_i) - y_i) ^2=\sum_{i=1}^{m}( wx_i+b-y_i) ^2
L=i=1∑m?(f(xi?)?yi?)2=i=1∑m?(wxi?+b?yi?)2
由上式可知,當均方誤差衡量的是預測值與真實標簽間的”差距“,當一個模型的均方誤差越小時,模型的預測就越接近真實值,模型也就越理想,
2.1.2 多元線性模型的均方誤差
對于多元線性回歸,通常會將其表示為矩陣的形式,參照周志華機器學習中的表示方式,先將
w
w
w和
b
b
b吸收入向量形式
w
^
=
(
w
;
b
)
\widehat{w}=(w;b)
w
=(w;b),相應的,資料集
D
D
D表示為一個
m
×
(
d
+
1
)
m\times(d+1)
m×(d+1)大小的矩陣
X
X
X,即
X
=
(
x
11
x
12
.
.
.
x
1
d
1
x
21
x
22
.
.
.
x
2
d
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
x
m
1
x
m
2
.
.
.
x
m
d
1
)
=
(
x
1
T
1
x
2
T
1
.
.
.
.
.
.
x
m
T
1
)
X=\left( \begin{matrix} x_{11}& x_{12}& ...& x_{1d}& 1\\ x_{21}& x_{22}& ...& x_{2d}& 1\\ ...& ...& ...& ...& ...\\ x_{m1}& x_{m2}& ...& x_{md}& 1\\ \end{matrix} \right) =\left( \begin{matrix} x_1^T& 1\\ x_2^T& 1\\ ...& ...\\ x_m^T& 1\\ \end{matrix} \right)
X=?????x11?x21?...xm1??x12?x22?...xm2??............?x1d?x2d?...xmd??11...1??????=?????x1T?x2T?...xmT??11...1??????
同樣資料集
D
D
D的標簽也也寫成向量形式
y
=
(
y
1
;
y
2
;
.
.
.
;
y
m
)
y=(y_1;y_2;...;y_m)
y=(y1?;y2?;...;ym?),即
m
×
1
m\times1
m×1矩陣,則均方誤差可以表示為:
L
=
(
y
?
X
w
^
)
T
(
y
?
X
w
^
)
L=(y-X\widehat{w})^T(y-X\widehat{w})
L=(y?Xw
)T(y?Xw
)
注:一元線性模型也可以采用多元線性模型的表示形式,
2.2 如何求解 w w w和 b b b
既然已經知道如何對線性回歸模型進行評價了,那接下來的任務就變成了如何確定一組超級引數 w w w和 b b b使得均方誤差 L L L最小化,可知 L L L是一個凸函式,根據微積分可知,當導數為0時, L L L取最小值,因此需要對 w w w和b求偏導并令其為0,
2.2.1 一元線性模型的超級引數
? L ? w = ∑ i = 1 m 2 ( w x i + b ? y i ) x i = 2 ( w ∑ i = 1 m x i 2 ? ∑ i = 1 m ( y i ? b ) x i ) = 0 ? L ? b = ∑ i = 1 m 2 ( w x i + b ? y i ) = 2 ( m b ? ∑ i = 1 m y i ? w x i ) = 0 \frac{\partial L}{\partial w} = \sum_{i=1}^m{2( wx_i+b-y_i) x_i} =2(w\sum_{i=1}^m{x_i}^2-\sum_{i=1}^m{(y_i-b)x_i})=0 \\ \frac{\partial L}{\partial b} = \sum_{i=1}^m{2( wx_i+b-y_i)} = 2(mb-\sum_{i=1}^m{y_i-wx_i})=0 ?w?L?=i=1∑m?2(wxi?+b?yi?)xi?=2(wi=1∑m?xi?2?i=1∑m?(yi??b)xi?)=0?b?L?=i=1∑m?2(wxi?+b?yi?)=2(mb?i=1∑m?yi??wxi?)=0
可得
w
w
w和b的最優解為:
w
=
∑
i
=
1
m
y
i
(
x
i
?
x
 ̄
)
∑
i
=
1
m
x
i
2
?
1
m
(
∑
i
=
1
m
x
i
)
2
b
=
1
m
∑
i
=
1
m
(
y
i
?
w
x
i
)
w=\frac{\sum_{i=1}^m{y_i\left( x_i-\overline{x} \right)}}{\sum_{i=1}^m{x_{\mathrm{i}}^2-\frac{1}{m}\left( \sum_{i=1}^m{xi} \right) ^2}} \\ b=\frac{1}{m}\sum_{i=1}^m{\left( y_i-wx_i \right)}
w=∑i=1m?xi2??m1?(∑i=1m?xi)2∑i=1m?yi?(xi??x)?b=m1?i=1∑m?(yi??wxi?)
其中
x
 ̄
=
1
m
∑
i
=
1
m
(
x
i
)
\overline{x}=\frac{1}{m}\sum_{i=1}^m(x_i)
x=m1?∑i=1m?(xi?),即為
x
x
x的均值,
2.2.2 多元線性模型的超級引數
損失函式
L
L
L對
w
^
\widehat{w}
w
的求偏導并令其為0,即:
?
L
?
w
^
=
2
X
T
(
X
w
^
?
y
)
=
0
\frac{\partial L}{\partial \widehat{w}}=2X^T\left( X\widehat{w}-y \right)=0
?w
?L?=2XT(Xw
?y)=0
因此
w
^
\widehat{w}
w
的最優解:
w
^
=
(
X
T
X
)
?
1
X
T
y
\widehat{w}=(X^TX)^{-1}X^Ty
w
=(XTX)?1XTy
三.代碼實作
根據2.3節的針對一元線性模型和二元線性模型超級引數的求解實作代碼如下(其中一元線性模型也轉換成了矩陣形式進行求解嘗試):
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def loadDataset1(size=1000):
"""
功能:生成一元線性模型資料集
size:資料集大小
"""
x = np.random.randn(size,1)
y = x + np.random.randn(size,1) + 1.2
return x,y
def loadDataset2(size=1000):
"""
功能:生成多元線性模型資料集
size:資料集大小
"""
x1 = np.random.randn(size,1)
x2 = np.random.randn(size,1)
x3 = np.random.randn(size,1)
y = 0.8*x1 + 1.7*x2 + 6.6*x3 + np.random.randn(size,1) + 5.2
ones = np.ones(shape=(size,1))
#構造(w,b)形式
x = np.hstack((x1,x2,x3,ones))
return x,y
if __name__ == "__main__":
size = 1000
x1,y1 = loadDataset1(size=size)
#一元線性模型引數求解方法
w1 = np.dot(y1.T,x1-np.mean(x1)) / (np.sum(x1**2) - 1.0 /size * np.sum(x1)**2)
b1 = 1.0 / size * np.sum((y1-w1*x1))
print(w1[0,0],b1)
#一元線性模型劃為矩陣形式后進行求解
ones = np.ones(shape=(size,1))
#構造(w,b)形式
x1 = np.hstack((x1,ones))
print(np.linalg.inv(x1.T.dot(x1)).dot(x1.T).dot(y1))
#多元線性模型超級引數求解
x2,y2 = loadDataset2(size=size)
print(np.linalg.inv(x2.T.dot(x2)).dot(x2.T).dot(y2))
"""
0.9837945577476686 1.2292211441168228
[[0.98379456]
[1.22922114]]
[[0.83507322]
[1.66517019]
[6.67787326]
[5.18590384]]
"""
可以看出根據資料集預測的超級引數和實際的引數已經十分接近了,
參考博客
- 用人話講明白線性回歸LinearRegression
- 回歸分析|筆記整理(6)——多元線性回歸(上)
以上便是本文的全部內容,如果覺得不錯的話就點個贊或關注一下博主吧,你們的支持是博主創作的不竭動力,倘若有任何問題也敬請批評指正!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/193723.html
標籤:其他