Python爬蟲:多平臺短視頻去水印下載器
- 功能介紹
- 各平臺分解
- 抖音
- 快手
- 微視
- 皮皮搞笑
- 總結
本教程描述的爬取方案定檔與2020年10月26日
鄭重申明:該文章介紹的技術僅供用于學習,不可惡意攻擊各大短視頻平臺,對各大短視頻平臺服務器造成的任何損失,后果自負,
<iframe id="gpav0ZZr-1603685448417" src="https://player.bilibili.com/player.html?aid=755021283" allowfullscreen="true" data-mediaembed="bilibili"></iframe>Python爬蟲:多平臺短視頻去水印下載器
視頻被壓縮了,原視頻高清地址:https://www.bilibili.com/video/BV1cr4y1w7yz/
轉載請標明作者和原文地址~
作者:西涯俠
CSDN個人主頁:是西涯俠
文章地址:https://blog.csdn.net/qq_41707308/article/details/109293116
軟體界面:
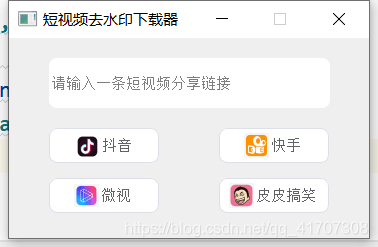
功能介紹
本軟體采用Python撰寫,資料爬取使用requests庫,并使用PyQt5撰寫GUI界面,給普通用戶添加易用性:
- 完美去水印 ,收藏好看的視頻再也不用擔心水印和煩人的片尾;
- 多平臺支持 ,支持抖音,快手,微視,皮皮搞笑,涵蓋大部分用戶常用小視頻軟體;
- GUI界面設計 ,將會帶來快捷易上手體驗,小白也會用;
- 增加了 進度條顯示 功能,你可以直觀的看到程式的運行程序;
- 采取多執行緒獲取進行資料爬取,防止界面假死;
各平臺分解
抖音
首先獲取分享鏈接,打開抖音的的一個視頻(所有分享視頻都可以用同樣方法),選擇右下角分享按鈕,點擊復制鏈接,
獲取鏈接方式:
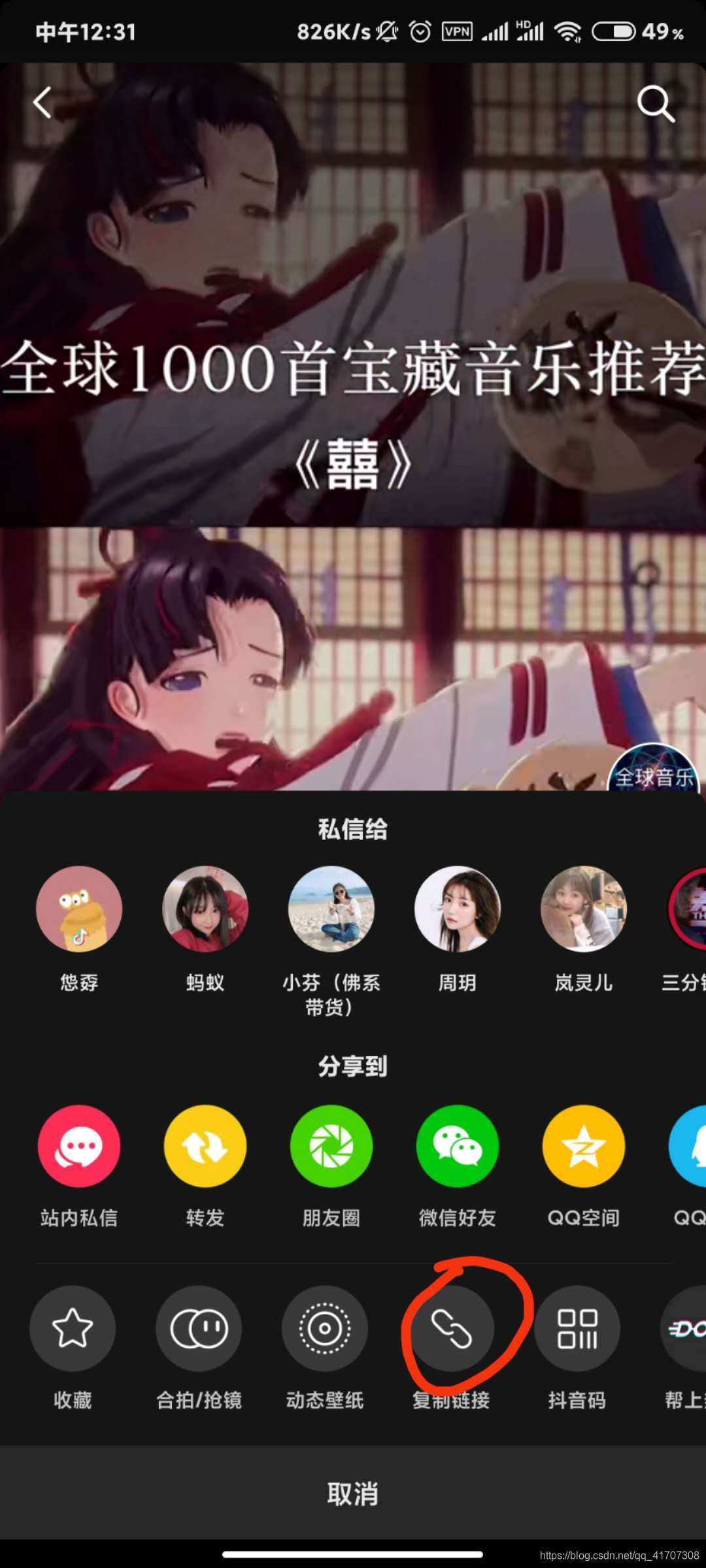
復制的鏈接:

通過查看復制的鏈接可以發現,鏈接中不單單有URL地址,還夾雜著一些文字符號所以,第一步就是先提取復制的鏈接中包含的URL地址和檔案名:
def compile_name_url(url_text):
# 正則匹配分享鏈接,獲取鏈接非空字符前的幾個字符作為檔案名
video_name = re.match(r'\S*', url_text)
if video_name:
video_name = video_name.group()
print(video_name)
# 正則匹配分享鏈接,獲取鏈接
first_url = re.search(r'https://v.douyin.com/.*?/', url_text)
if first_url:
first_url = first_url.group()
print('第一次url==》', first_url)
return first_url, video_name
將鏈接復制到瀏覽器中,抓取資料包分析資料:可以發現,需要的目標視頻鏈接就在第三張圖中回傳的json資料中,只需要獲取對應的欄位就行了,
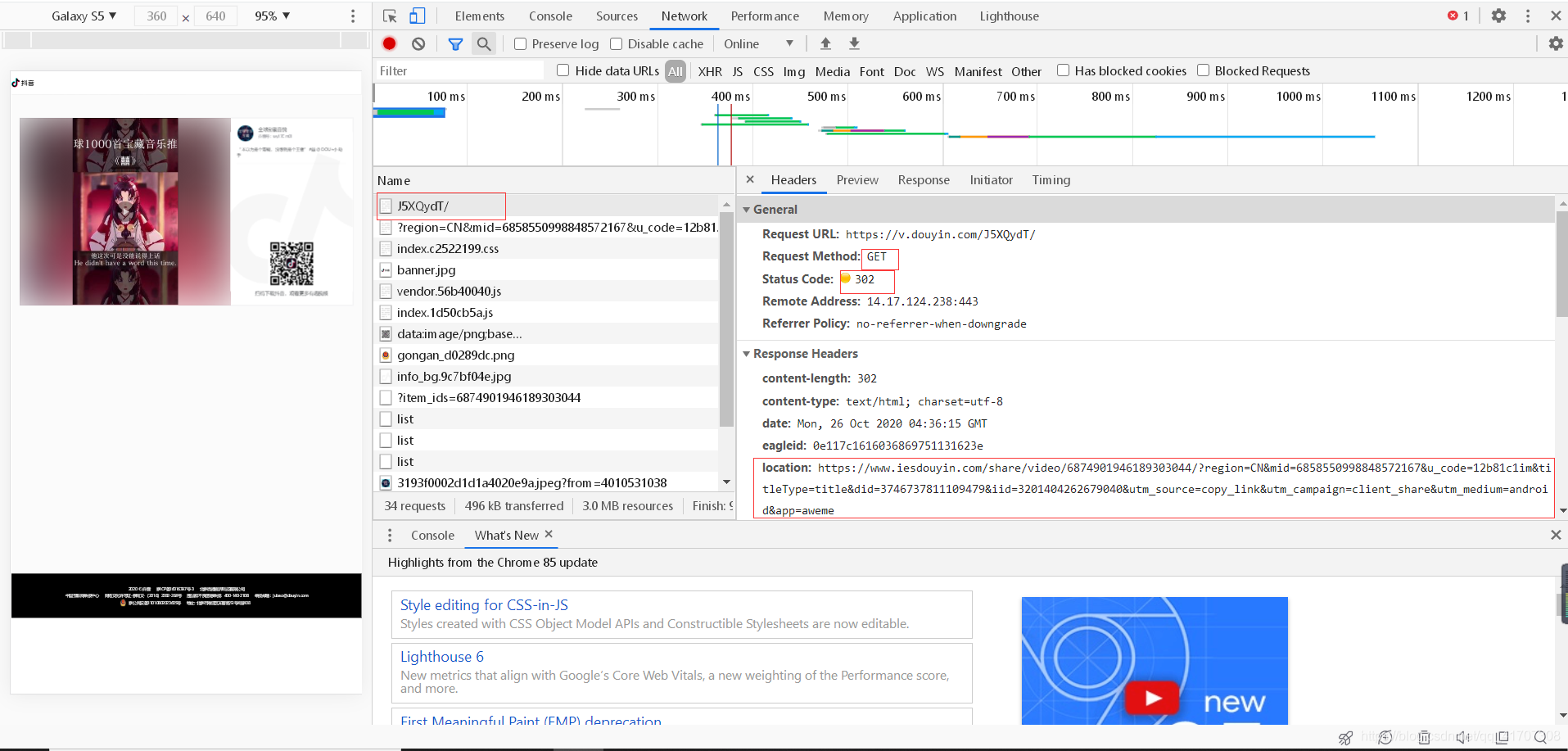
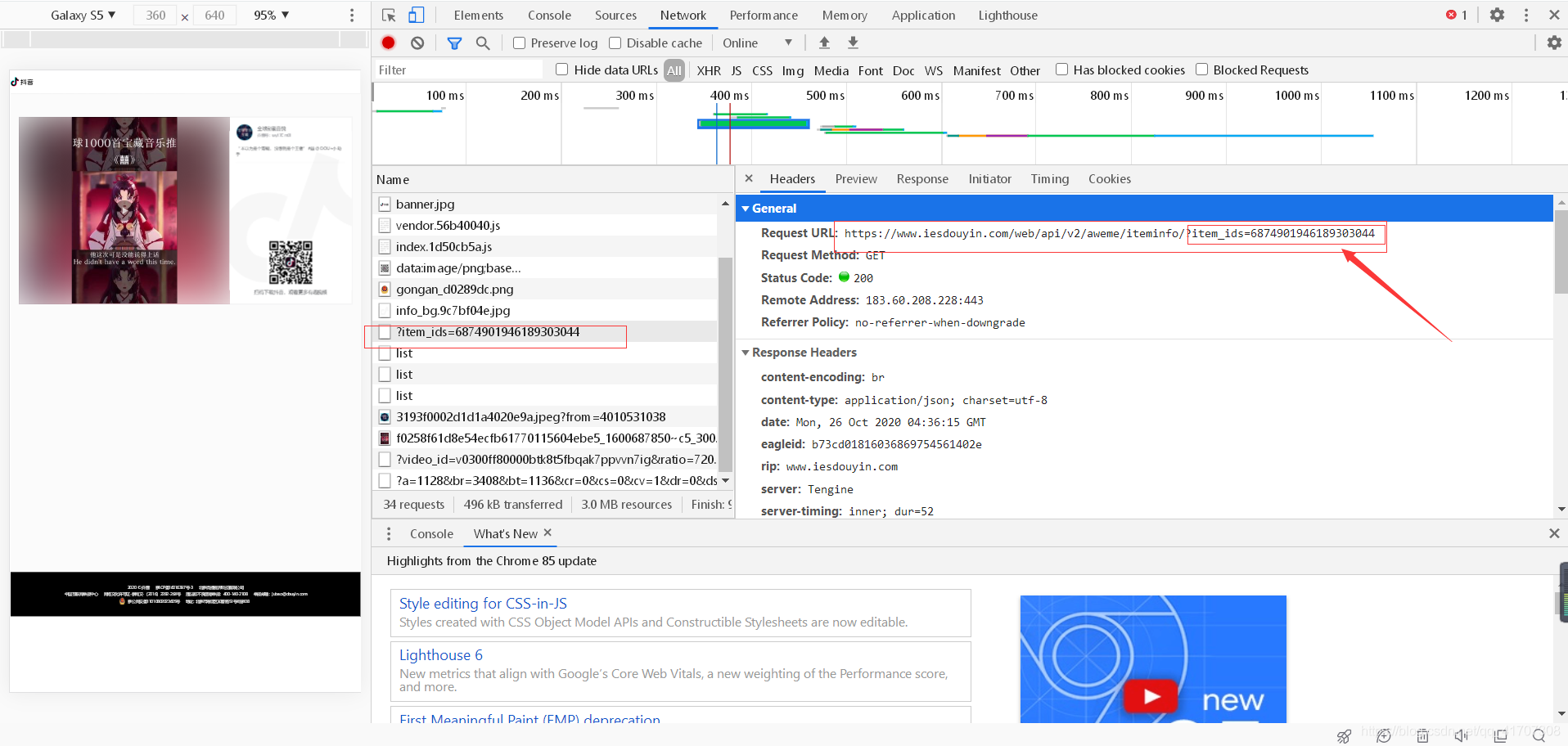
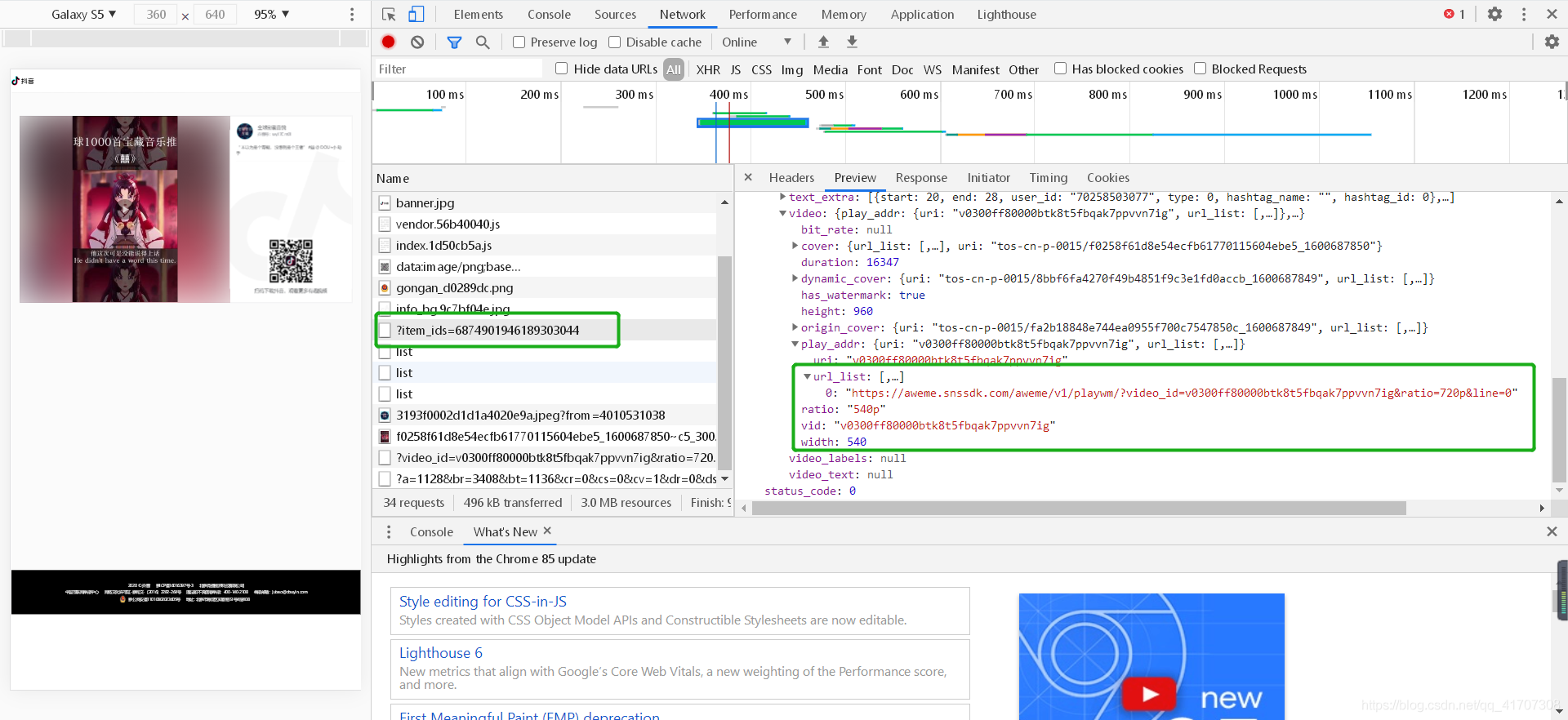
然而事情并沒有我們想象的那么簡單,抓取了鏈接后獲取到的URL直接復制到瀏覽器中展示的結果還是有水印的(如下圖),仔細觀察URL地址,會發現playwm這個欄位,而wm就是water mark的縮寫,也就是水印,把wm去掉后再次訪問,就會得到無水印的地址,大功告成!

代碼實作:
def first_request(first_url):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'sec-fetch-dest': 'document',
'sec-fetch-moe': 'navigate',
'sec-fetch-site': 'none',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4195.1 Mobile Safari/537.36'
}
response = requests.get(first_url, headers=headers)
print('第二次url==》', response.url) # 獲取第一次重定向后的url
# 截取第二次請求需要的引數
content = re.search(r'\d\d*\d', response.url).group()
params = {"item_ids": content}
return params
def second_request(params):
response = requests.get('https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/', params=params)
result = response.json() # 獲得第二次請求的json,并從json中查找第三次請求需要的url
# print(result)
second_url = result['item_list'][0]['video']['play_addr']['url_list'][0]
play_url = re.sub(r'playwm', 'play', second_url)
print('第三次url==》', play_url)
return play_url
快手
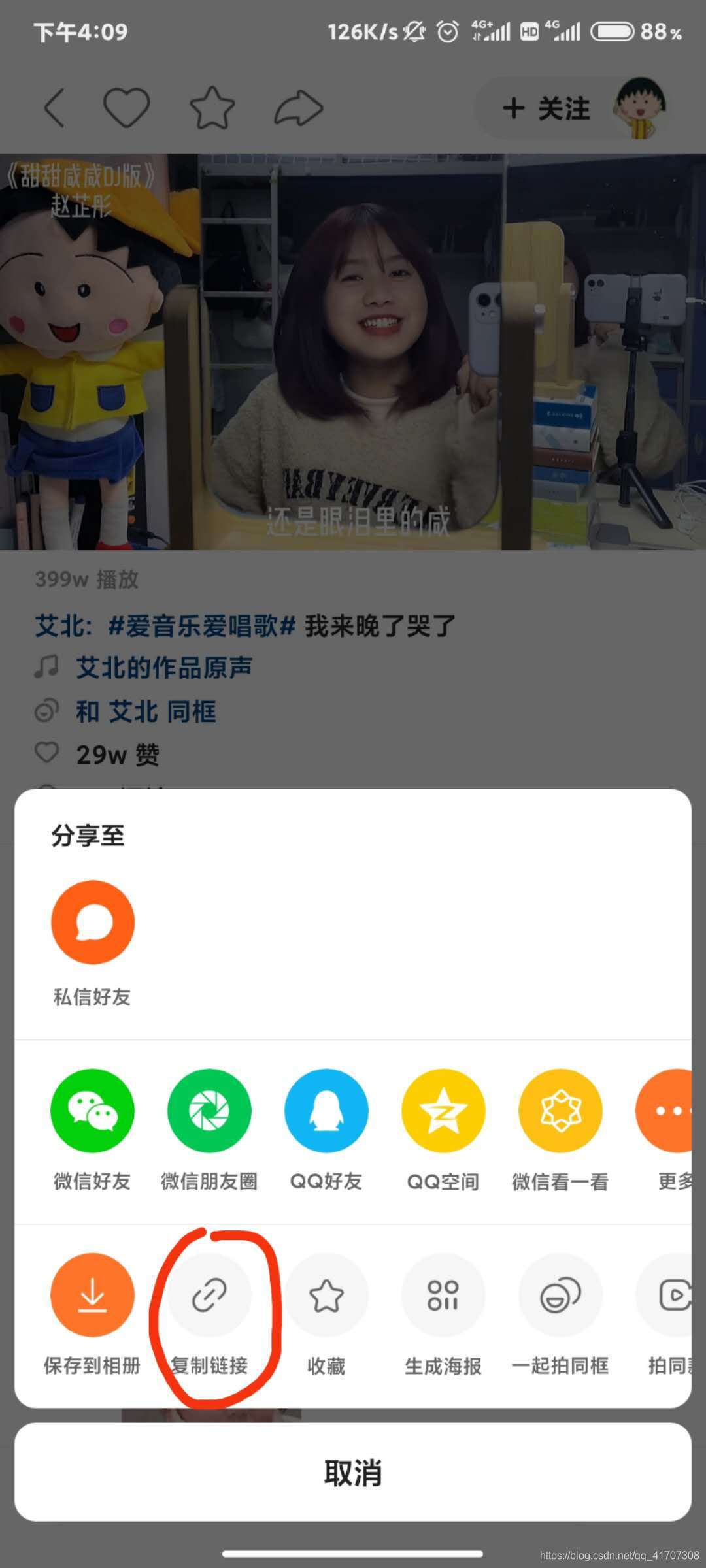
快手平臺的就簡單一些,同樣的獲取鏈接方式:
獲取鏈接方式:
復制的鏈接:
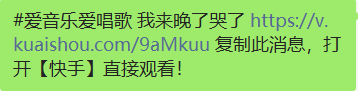
提取URL和視頻名,同抖音一樣的提取方式,這里就不重復展示代碼了,直接開始分析鏈接請求內容:
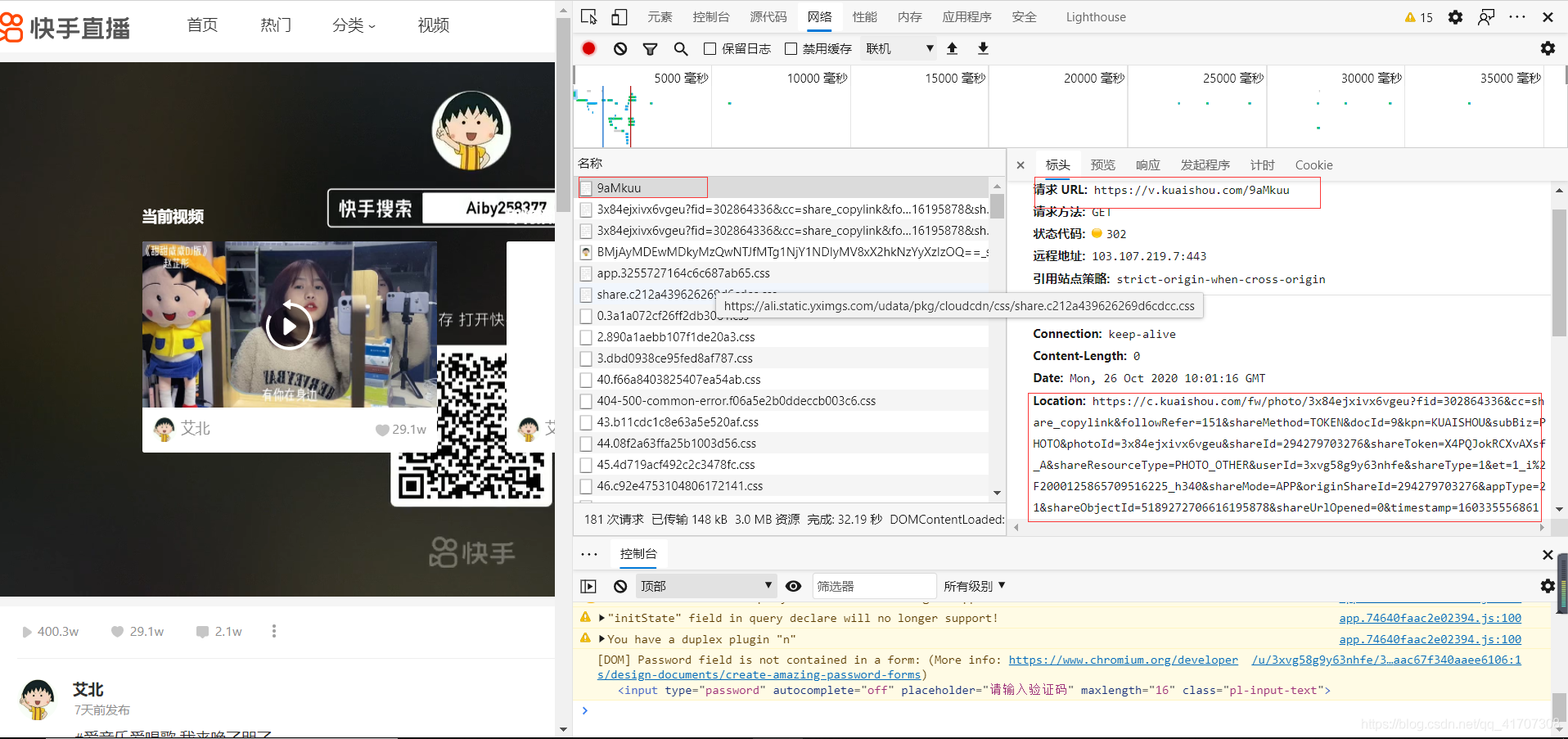
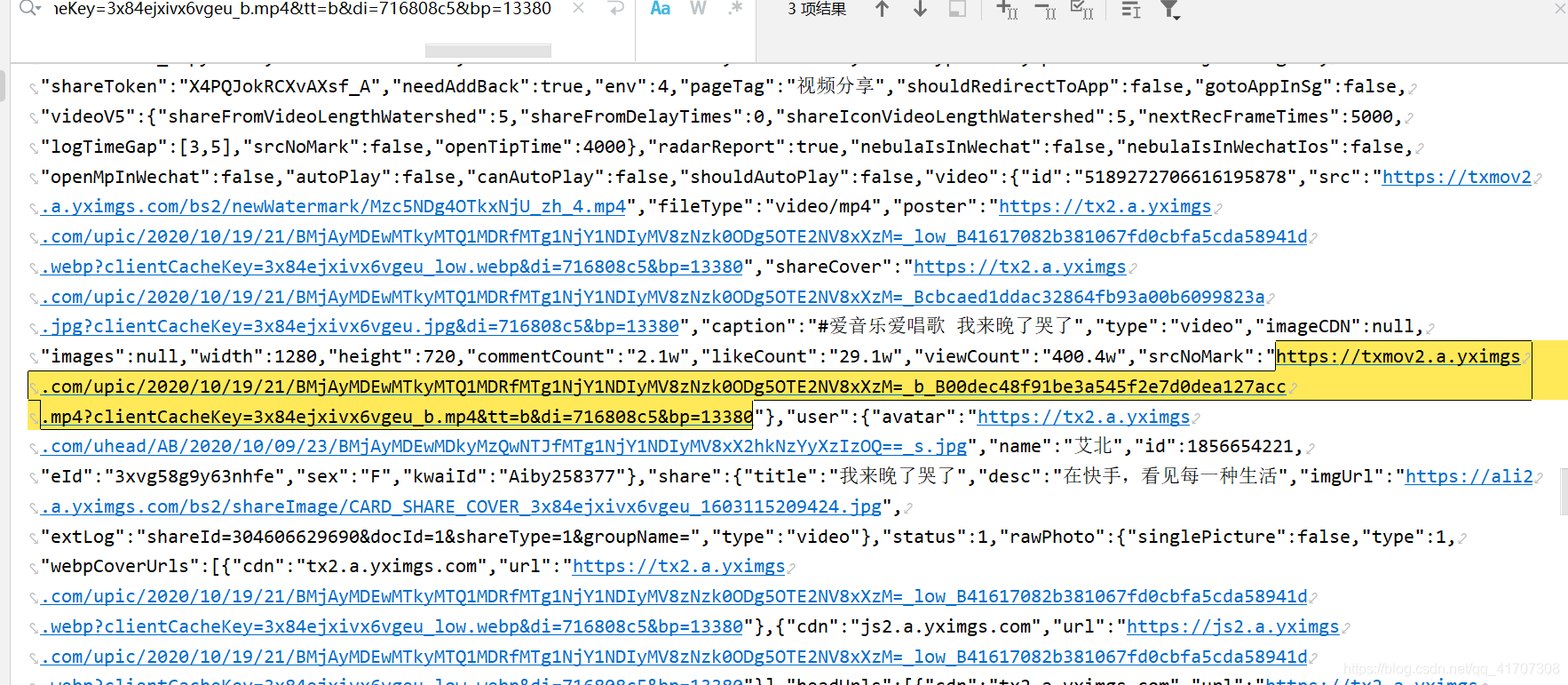
在回傳的文本內容中包含有無水印的視頻,并且名字也很明顯了“srcNoMark”(無水印資源),直接向這個URL發起請求即可,我們就可以欣賞艾北小姐姐唱歌了!!!
代碼實作:
def second_request(second_url):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'did=web_209e6a4e64064f659be838aca3178ec1; didv=1603355622000',
'Host': 'c.kuaishou.com',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4195.1 Mobile Safari/537.36'
}
response = requests.get(second_url, headers=headers)
content = response.text
video_url = re.search(r'"srcNoMark":"https://txmov2.a.yximgs.com/.*?\"', content).group()[13:-1]
print(video_url)
return video_url
微視
同樣的套路,先獲取鏈接:
獲取鏈接方式:
獲取鏈接方式:

接下來,把鏈接復制到瀏覽器,抓包進行分析,可以發現,視頻所在的URL地址就保存在一個請求的json檔案里面,然后我又發現這是個post請求,并且有引數,這個引數就得在網頁中分析
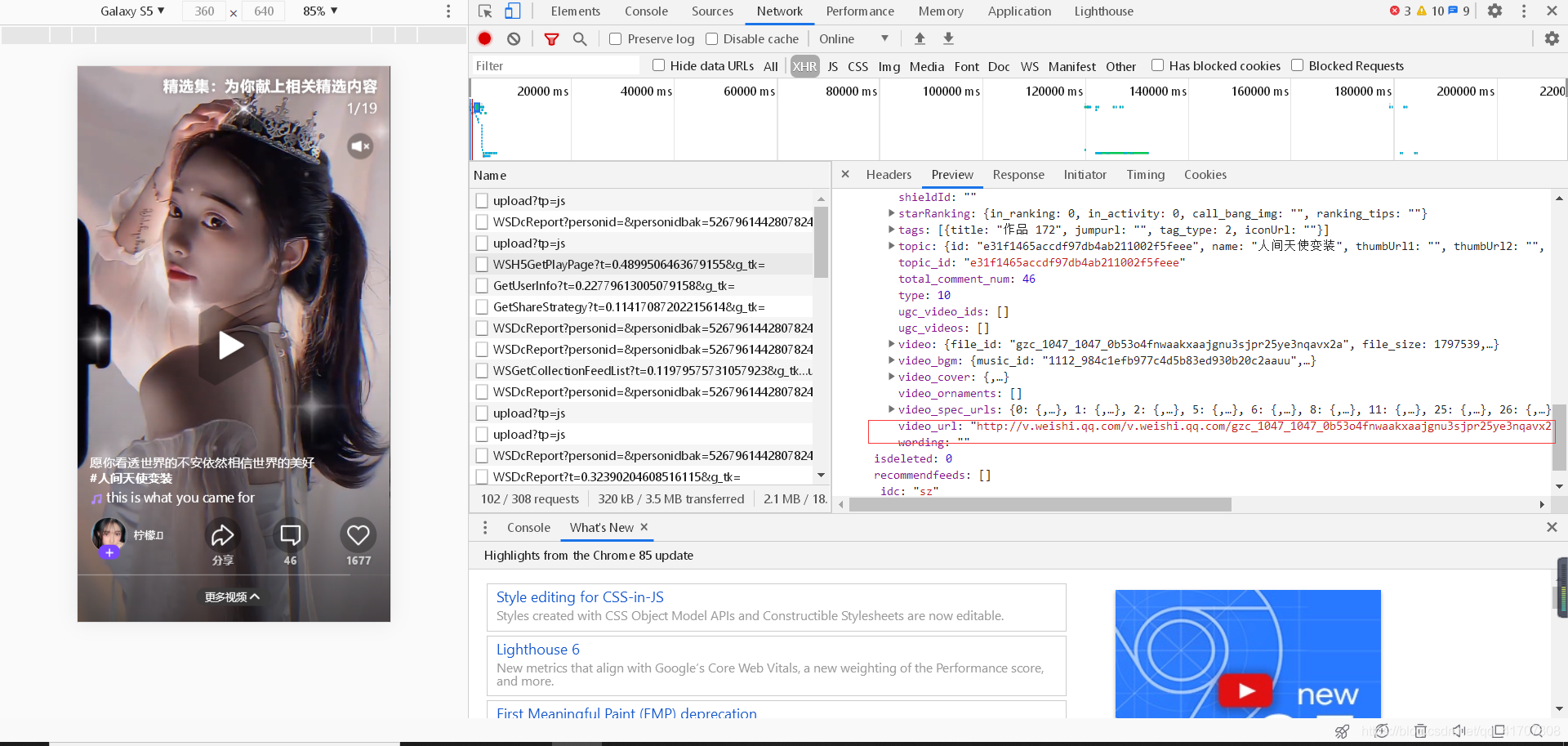
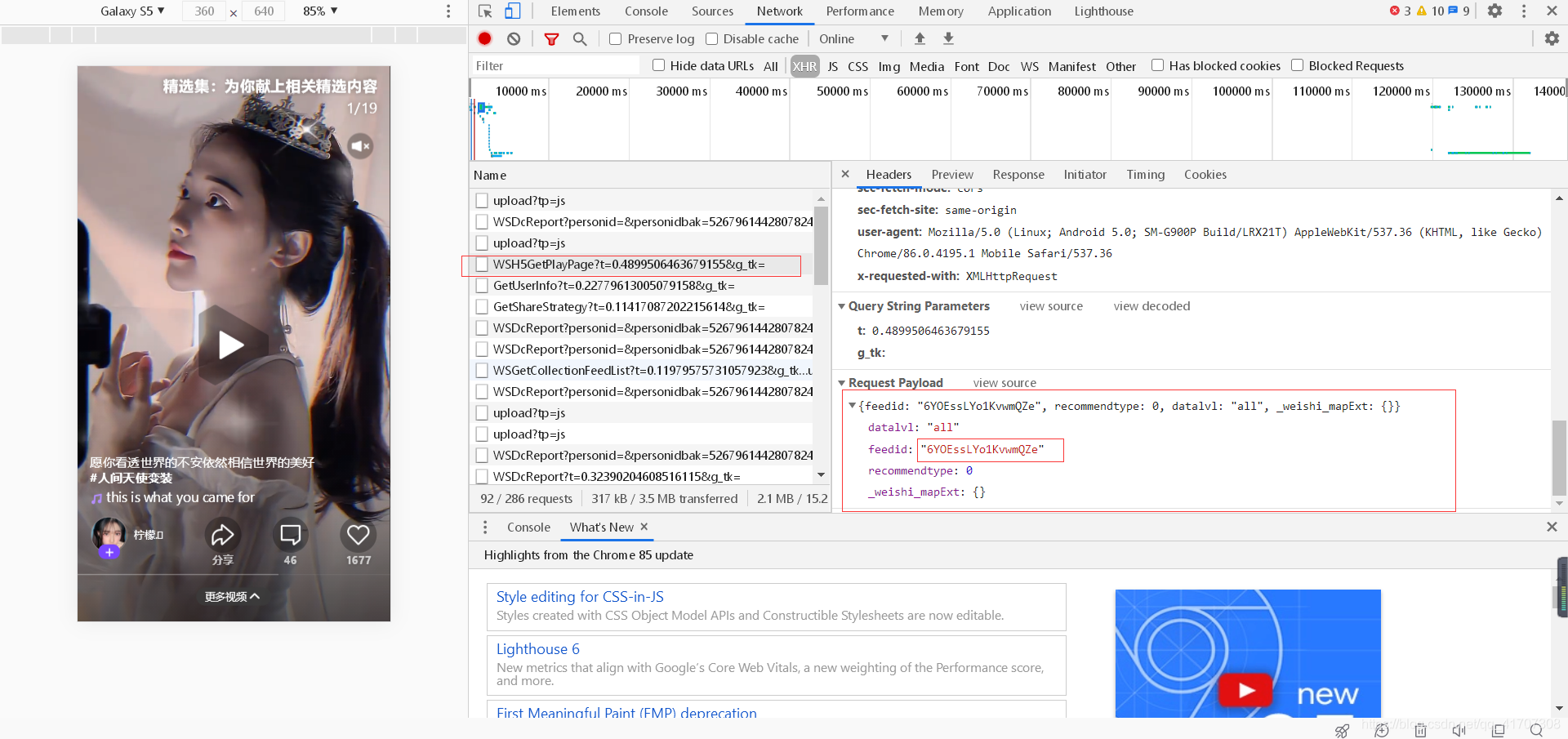
先回到第一個請求中來尋找是否有引數的存在,在仔細觀察下發現,所需要的的引數feedid其實就是一個鏈接中的一部分,所以就得更換一下爬取的策略,先獲取鏈接中的feedid,得到引數后再繼續下一步操作,才能得到視頻,

代碼實作:
def compile_name_url(url_text):
video_name = re.findall(r'(\w*)', url_text)
feedid = re.findall(r'feed/(\w*)', url_text)
if video_name and feedid:
video_name = video_name[0]
feedid = feedid[0]
return feedid, video_name
def first_request(feedid):
headers = {
'accept': 'application/json',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'content-length': '84',
'content-type': 'application/json',
'cookie': 'RK=BuAQ1v+yV3; ptcz=6f7072f84fa03d56ea047b407853df6a5375d719df1031ef066d11b09fb679e4; pgv_pvi=8434466816; pgv_pvid=1643353500; tvfe_boss_uuid=3b10306bf3ae662b; o_cookie=1074566721; pac_uid=1_1074566721; ied_qq=o1074566721; LW_sid=k1Y5n9s3Y0K866h7P246v4k6o8; LW_uid=u1v5i9V3p0L806m7R226s4W7F1; eas_sid=J1p5G9s3A0h8Z6c7l2a6x4E7w7; iip=0; ptui_loginuin=1074566721; person_id_bak=5881015637151283; person_id_wsbeacon=5920911274348544; wsreq_logseq=341295039',
'origin': 'https://h5.weishi.qq.com',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4195.1 Mobile Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
rejson = {
'datalvl': "all",
'feedid': feedid,
'recommendtype': '0',
'_weishi_mapExt': '{}'
}
first_url = 'https://h5.weishi.qq.com/webapp/json/weishi/WSH5GetPlayPage'
response = requests.post(first_url, headers=headers, json=rejson)
result = response.json()
video_url = result['data']['feeds'][0]['video_url']
return video_url
皮皮搞笑
同樣步驟,先獲取鏈接,
獲取鏈接方式:
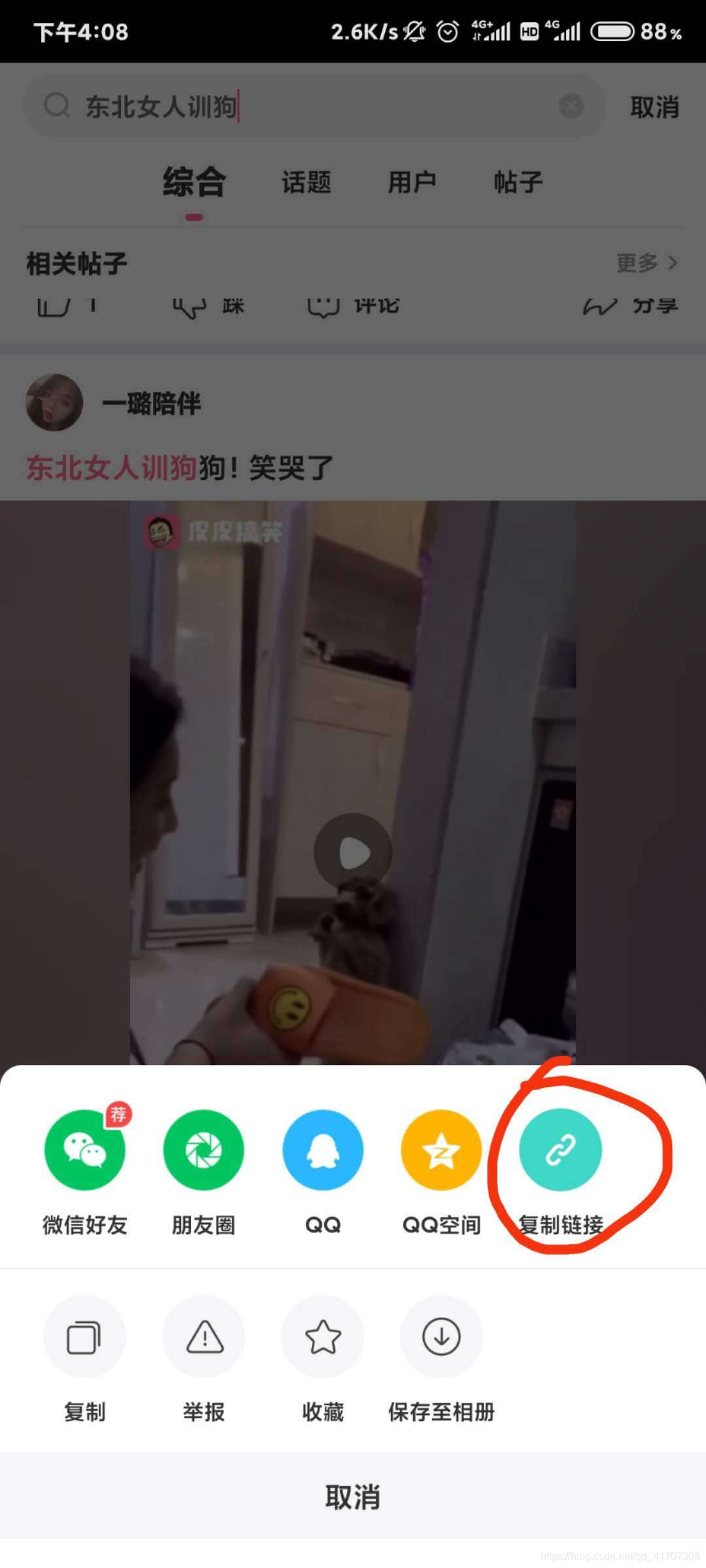
復制的鏈接:

觀察分享的字串可以看得出來,這次并沒有把視頻的名字加進來,所有視頻的名字只能從請求的內容里獲取了,先把鏈接放在瀏覽器中分析一下資料,
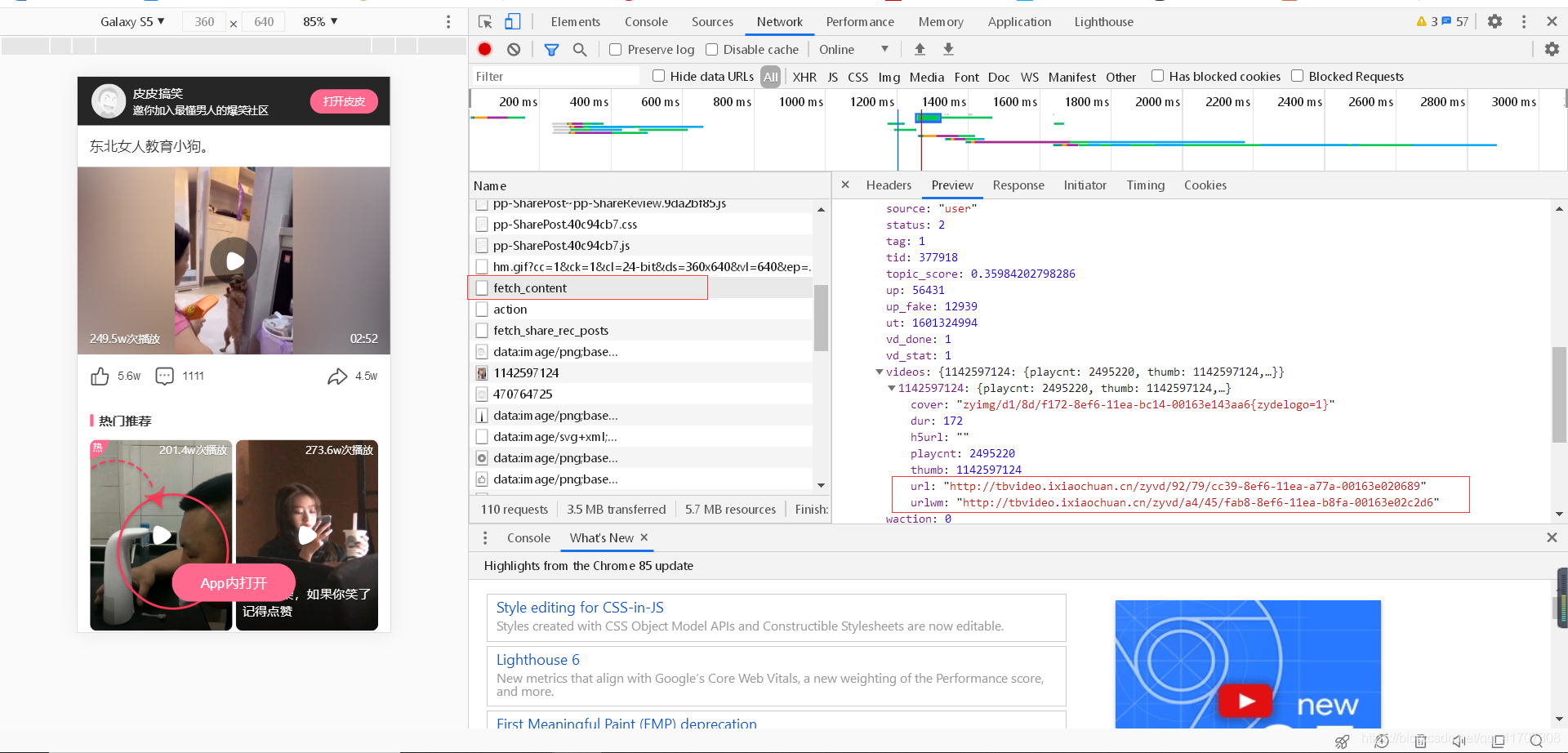
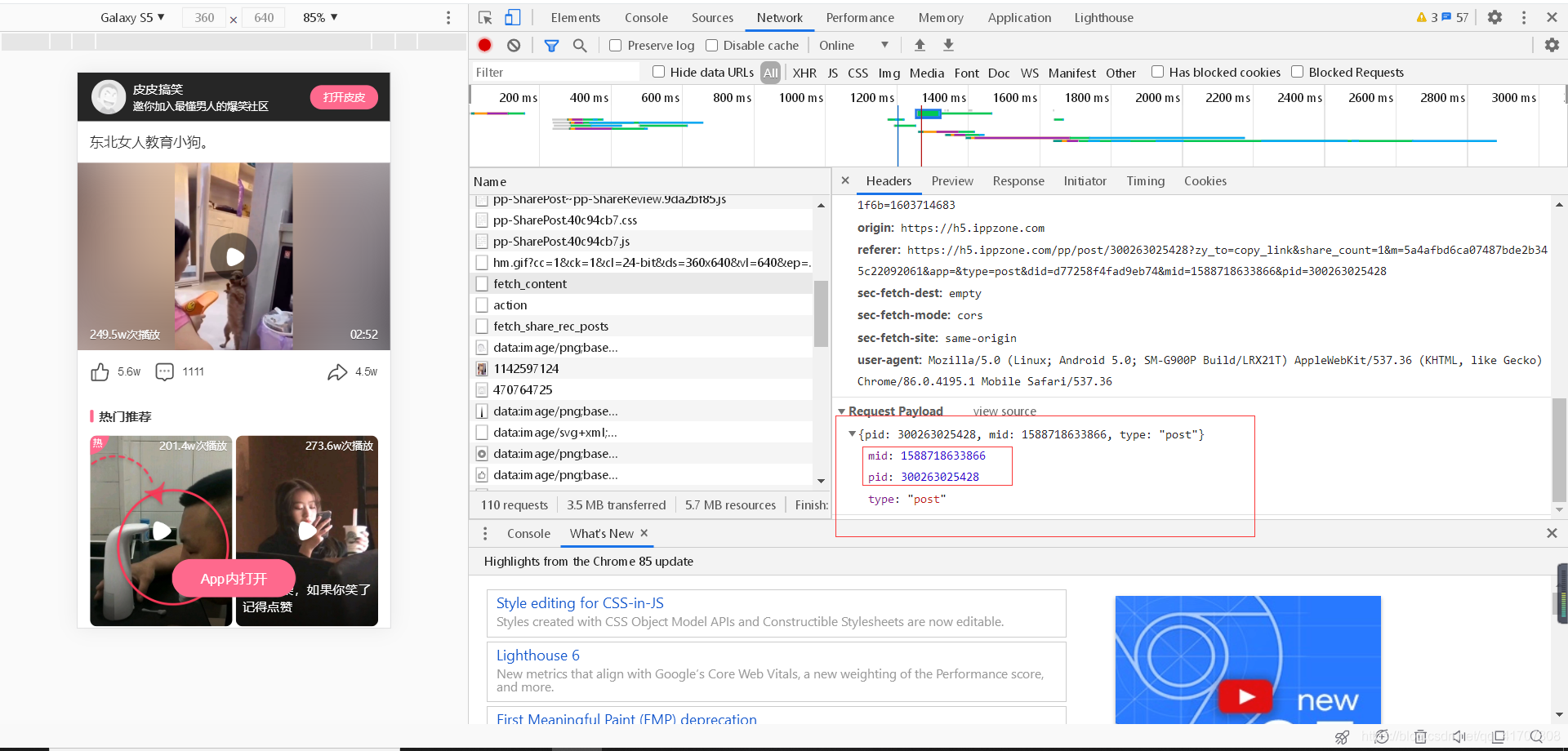
這次同樣發現,這是個post請求,并且同樣需要引數,鑒于微視的經驗,仔細查看了一下原分享鏈接,果然不出所料,所要的兩個變化的引數就隱藏在鏈接中,只要獲取pid和mid兩個引數,然后發起請求就得到視頻了,

代碼實作:
def compile_name_url(url_text):
headers = {
'Host': 'share.ippzone.com',
'Origin': 'http://share.ippzone.com',
'Referer': url_text,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.52'
}
mid = re.findall(r'mid=(\d*)', url_text)
pid = re.findall(r'pid=(\d*)', url_text)
if mid and pid:
mid = int(mid[0])
pid = int(pid[0])
parmer = {
'mid': mid,
'pid': pid,
'type': 'post'
}
url = 'http://share.ippzone.com/ppapi/share/fetch_content'
r = requests.post(url, headers=headers, json=parmer)
result=r.json()
video_name = result['data']['post']['content'].replace(' ', '')
video_url = result['data']['post']['videos'][str(result['data']['post']['imgs'][0]['id'])]['url']
return video_url, video_name
總結
這是作為一個編程初學者第一次寫博客,寫的可能不太好不夠清晰,純屬技術交流分享,所分享內容均只作學習研究用,不可對各大視頻平臺服務器進行惡意攻擊,
最后希望大家轉載請注明出處~
作者:西涯俠
CSDN個人主頁:是西涯俠
文章地址:https://blog.csdn.net/qq_41707308/article/details/109293116
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/194340.html
標籤:其他