想在面試、作業中脫穎而出?想在最短的時間內快速掌握 Java 的核心基礎知識點?想要成為一位優秀的 Java工程師?本篇文章能助你一臂之力!正所謂萬丈高樓平地起,只有把基礎掌握的牢固,才能走的更遠,面對不斷更新的技術才能快速掌握,同時在面試、作業中也更能脫穎而出!

說明:以下所有答案均為個人的理解和網上的一些資料的整合
1.List 和 Set 的區別
另外本人整理了20年面試題大全,包含spring、并發、資料庫、Redis、分布式、dubbo、JVM、微服務等方面總結,下圖是部分截圖,需要的話點這里點這里,暗號CSDN,
List , Set 都是繼承自 Collection 介面 List 特點:元素有放入順序,元素可重復 ,
Set 特點:元素無放入順序,元素不可重復,重復元素會覆寫掉,(元素雖然無放入順序,但是元素在set中的位置是有該元素的 HashCode 決定的,其位置其實是固定的,加入Set 的 Object 必須定義 equals ()方法 ,另外list支持for回圈,也就是通過下標來遍歷,也可以用迭代器,但是set只能用迭代,因為他無序,無法用下標來取得想要的值,)
Set和List對比
- Set:檢索元素效率低下,洗掉和插入效率高,插入和洗掉不會引起元素位置改變,
- List:和陣列類似,List可以動態增長,查找元素效率高,插入洗掉元素效率低,因為會引起其他元素位置改變
2.HashSet 是如何保證不重復的
向 HashSet 中 add ()元素時,判斷元素是否存在的依據,不僅要比較hash值,同時還要結合 equles 方法比較,HashSet 中的 add ()方法會使用 HashMap 的 add ()方法,以下是 HashSet 部分原始碼:
private static final Object PRESENT = new Object();
private transient HashMap<E,Object> map;
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
HashMap 的 key 是唯一的,由上面的代碼可以看出 HashSet 添加進去的值就是作為 HashMap 的key,所以不會重復( HashMap 比較key是否相等是先比較 hashcode 在比較 equals ),
3.HashMap 是執行緒安全的嗎,為什么不是執行緒安全的(最好畫圖說明多執行緒 環境下不安全)?
不是執行緒安全的;
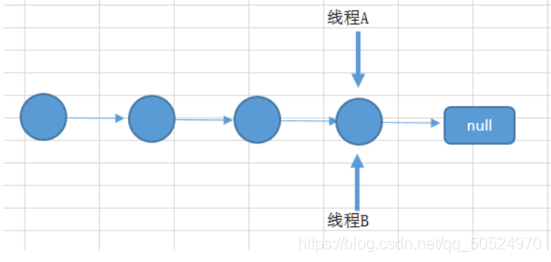
如果有兩個執行緒A和B,都進行插入資料,剛好這兩條不同的資料經過哈希計算后得到的哈希碼是一樣的,且該位置還沒有其他的資料,所以這兩個執行緒都會進入我在上面標記為1的代碼中,假設一種情況,執行緒A通過if判斷,該位置沒有哈希沖突,進入了if陳述句,還沒有進行資料插入,這時候 CPU 就把資源讓給了執行緒B,執行緒A停在了if陳述句里面,執行緒B判斷該位置沒有哈希沖突(執行緒A的資料還沒插入),也進入了if陳述句,執行緒B執行完后,輪到執行緒A執行,現在執行緒A直接在該位置插入而不用再判斷,這時候,你會發現執行緒A把執行緒B插入的資料給覆寫了,發生了執行緒不安全情況,本來在 HashMap 中,發生哈希沖突是可以用鏈表法或者紅黑樹來解決的,但是在多執行緒中,可能就直接給覆寫了,
上面所說的是一個圖來解釋可能更加直觀,如下面所示,兩個執行緒在同一個位置添加資料,后面添加的資料就覆寫住了前面添加的,

如果上述插入是插入到鏈表上,如兩個執行緒都在遍歷到最后一個節點,都要在最后添加一個資料,那么后面添加資料的執行緒就會把前面添加的資料給覆寫住,則
在擴容的時候也可能會導致資料不一致,因為擴容是從一個陣列拷貝到另外一個陣列,
4.HashMap 的擴容程序
當向容器添加元素的時候,會判斷當前容器的元素個數,如果大于等于閾值(知道這個閾字怎么念嗎?不念 fa 值,念 yu 值四聲)—即當前陣列的長度乘以加載因子的值的時候,就要自動擴容啦,
擴容( resize )就是重新計算容量,向 HashMap 物件里不停的添加元素,而 HashMap 物件內部的陣列無法裝載更多的元素時,物件就需要擴大陣列的長度,以便能裝入更多的元素,當然 Java 里的陣列是無法自動擴容的,方法是使用一個新的陣列代替已有的容量小的陣列,就像我們用一個小桶裝水,如果想裝更多的水,就得換大水桶,
HashMap hashMap=new HashMap(cap);
cap =3, hashMap 的容量為4;
cap =4, hashMap 的容量為4;
cap =5, hashMap 的容量為8;
cap =9, hashMap 的容量為16;
如果 cap 是2的n次方,則容量為 cap ,否則為大于 cap 的第一個2的n次方的數,
5.HashMap 1.7 與 1.8 的 區別,說明 1.8 做了哪些優化,如何優化的?
HashMap結構圖
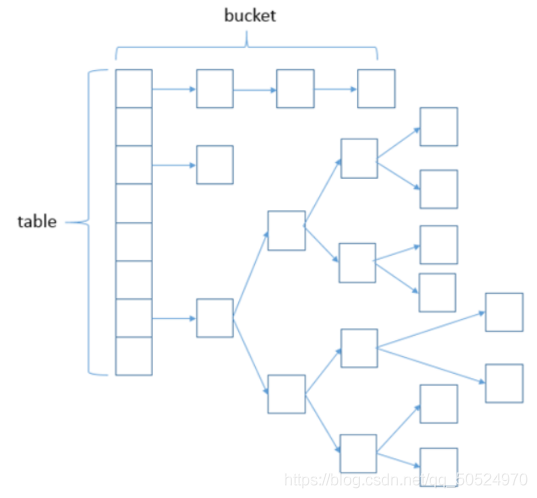
在 JDK1.7 及之前的版本中, HashMap 又叫散列鏈表:基于一個陣列以及多個鏈表的實作,hash值沖突的時候,就將對應節點以鏈表的形式存盤,
JDK1.8 中,當同一個hash值( Table 上元素)的鏈表節點數不小于8時,將不再以單鏈表的形式存盤了,會被調整成一顆紅黑樹,這就是 JDK7 與 JDK8 中 HashMap 實作的最大區別,
其下基于 JDK1.7.0_80 與 JDK1.8.0_66 做的分析
JDK1.7中
使用一個 Entry 陣列來存盤資料,用key的 hashcode 取模來決定key會被放到陣列里的位置,如果 hashcode 相同,或者 hashcode 取模后的結果相同( hash collision ),那么這些 key 會被定位到 Entry 陣列的同一個格子里,這些 key 會形成一個鏈表,
在 hashcode 特別差的情況下,比方說所有key的 hashcode 都相同,這個鏈表可能會很長,那么 put/get 操作都可能需要遍歷這個鏈表,也就是說時間復雜度在最差情況下會退化到 O(n),
JDK1.8中
使用一個 Node 陣列來存盤資料,但這個 Node 可能是鏈表結構,也可能是紅黑樹結構
- 如果插入的 key 的 hashcode 相同,那么這些key也會被定位到 Node 陣列的同一個格子里,
- 如果同一個格子里的key不超過8個,使用鏈表結構存盤,
- 如果超過了8個,那么會呼叫 treeifyBin 函式,將鏈表轉換為紅黑樹,
那么即使 hashcode 完全相同,由于紅黑樹的特點,查找某個特定元素,也只需要O(log n)的開銷
也就是說put/get的操作的時間復雜度最差只有 O(log n)
聽起來挺不錯,但是真正想要利用 JDK1.8 的好處,有一個限制:
key的物件,必須正確的實作了 Compare 介面
如果沒有實作 Compare 介面,或者實作得不正確(比方說所有 Compare 方法都回傳0)
那 JDK1.8 的 HashMap 其實還是慢于 JDK1.7 的
簡單的測驗資料如下:
向 HashMap 中 put/get 1w 條 hashcode 相同的物件
JDK1.7: put 0.26s , get 0.55s
JDK1.8 (未實作 Compare 介面): put 0.92s , get 2.1s
但是如果正確的實作了 Compare 介面,那么 JDK1.8 中的 HashMap 的性能有巨大提升,這次 put/get 100W條hashcode 相同的物件
JDK1.8 (正確實作 Compare 介面,): put/get 大概開銷都在320 ms 左右
6.final finally finalize
- final可以修飾類、變數、方法,修飾類表示該類不能被繼承、修飾方法表示該方法不能被重寫、修飾變數表示該變數是一個常量不能被重新賦值,
- finally一般作用在try-catch代碼塊中,在處理例外的時候,通常我們將一定要執行的代碼方法finally代碼塊中,表示不管是否出現例外,該代碼塊都會執行,一般用來存放一些關閉資源的代碼,
- finalize是一個方法,屬于Object類的一個方法,而Object類是所有類的父類,該方法一般由垃圾回收器來呼叫,當我們呼叫 System.gc() 方法的時候,由垃圾回收器呼叫finalize(),回收垃圾,一個物件是否可回收的最后判斷,
7.Java獲取反射的三種方法
1.通過new物件實作反射機制
2.通過路徑實作反射機制
3.通過類名實作反射機制
public class Student {
private int id;
String name;
protected boolean sex;
public float score;
}
public class Get {
//獲取反射機制三種方式
public static void main(String[] args) throws ClassNotFoundException {
//方式一(通過建立物件)
Student stu = new Student();
Class classobj1 = stu.getClass();
System.out.println(classobj1.getName());
//方式二(所在通過路徑-相對路徑)
Class classobj2 = Class.forName("fanshe.Student");
System.out.println(classobj2.getName());
//方式三(通過類名)
Class classobj3 = Student.class;
System.out.println(classobj3.getName());
}
}
8.Java反射機制
Java 反射機制是在運行狀態中,對于任意一個類,都能夠獲得這個類的所有屬性和方法,對于任意一個物件都能夠呼叫它的任意一個屬性和方法,這種在運行時動態的獲取資訊以及動態呼叫物件的方法的功能稱為 Java 的反射機制,
Class 類與 java.lang.reflect 類別庫一起對反射的概念進行了支持,該類別庫包含了Field,Method,Constructor 類 (每個類都實作了 Member 介面),這些型別的物件時由 JVM 在運行時創建的,用以表示未知類里對應的成員,
這樣你就可以使用 Constructor 創建新的物件,用 get() 和 set() 方法讀取和修改與 Field 物件關聯的欄位,用invoke() 方法呼叫與 Method 物件關聯的方法,另外,還可以呼叫 getFields() getMethods() 和
getConstructors() 等很便利的方法,以回傳表示欄位,方法,以及構造器的物件的陣列,這樣匿名物件的資訊就能在運行時被完全確定下來,而在編譯時不需要知道任何事情,
import java.lang.reflect.Constructor;
public class ReflectTest {
public static void main(String[] args) throws Exception {
Class clazz = null;
clazz = Class.forName("com.jas.reflect.Fruit");
Constructor<Fruit> constructor1 = clazz.getConstructor();
Constructor<Fruit> constructor2 = clazz.getConstructor(String.class);
Fruit fruit1 = constructor1.newInstance();
Fruit fruit2 = constructor2.newInstance("Apple");
}
}
class Fruit{
public Fruit(){
System.out.println("無參構造器 Run...........");
}
public Fruit(String type){
System.out.println("有參構造器 Run..........." + type);
}
}
運行結果: 無參構造器 Run………… 有參構造器 Run…………Apple
9.陣列在記憶體中如何分配
對于 Java 陣列的初始化,有以下兩種方式,這也是面試中經常考到的經典題目:
靜態初始化:初始化時由程式員顯式指定每個陣列元素的初始值,由系統決定陣列長度,如:
//只是指定初始值,并沒有指定陣列的長度,但是系統為自動決定該陣列的長度為4
String[] computers = {"Dell", "Lenovo", "Apple", "Acer"}; //①
//只是指定初始值,并沒有指定陣列的長度,但是系統為自動決定該陣列的長度為3
String[] names = new String[]{"多啦A夢", "大雄", "靜香"}; //②
動態初始化:初始化時由程式員顯示的指定陣列的長度,由系統為資料每個元素分配初始值,如:
//只是指定了陣列的長度,并沒有顯示的為陣列指定初始值,但是系統會默認給陣列陣列元素分配初始值為null
String[] cars = new String[4]; //③
因為 Java 陣列變數是參考型別的變數,所以上述幾行初始化陳述句執行后,三個陣列在記憶體中的分配情況如下圖所示:
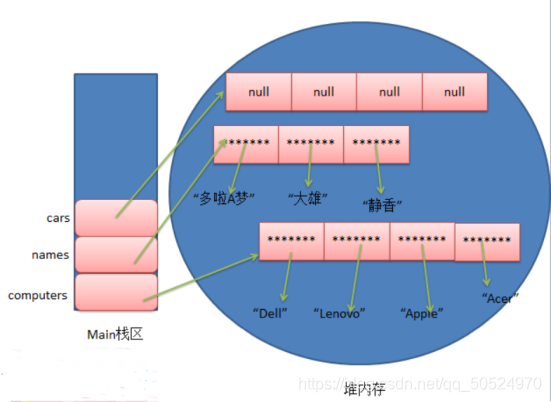
由上圖可知,靜態初始化方式,程式員雖然沒有指定陣列長度,但是系統已經自動幫我們給分配了,而動態初始化方式,程式員雖然沒有顯示的指定初始化值,但是因為 Java 陣列是參考型別的變數,所以系統也為每個元素分配了初始化值 null ,當然不同型別的初始化值也是不一樣的,假設是基本型別int型別,那么為系統分配的初始化值,也是對應的默認值0,
10.Cloneable 介面實作原理
Cloneable介面是Java開發中常用的一個介面, 它的作用是使一個類的實體能夠將自身拷貝到另一個新的實體中,注意,這里所說的“拷貝”拷的是物件實體,而不是類的定義,進一步說,拷貝的是一個類的實體中各欄位的值,
在開發程序中,拷貝實體是常見的一種操作,如果一個類中的欄位較多,而我們又采用在客戶端中逐欄位復制的方法進行拷貝操作的話,將不可避免的造成客戶端代碼繁雜冗長,而且也無法對類中的私有成員進行復制,而如果讓需要具備拷貝功能的類實作Cloneable介面,并重寫clone()方法,就可以通過呼叫clone()方法的方式簡潔地實作實體拷貝功能
深拷貝(深復制)和淺拷貝(淺復制)是兩個比較通用的概念,尤其在C++語言中,若不弄懂,則會在delete的時候出問題,但是我們在這幸好用的是Java,雖然Java自動管理物件的回收,但對于深拷貝(深復制)和淺拷貝(淺復制),我們還是要給予足夠的重視,因為有時這兩個概念往往會給我們帶來不小的困惑,
淺拷貝是指拷貝物件時僅僅拷貝物件本身(包括物件中的基本變數),而不拷貝物件包含的參考指向的物件,深拷貝不僅拷貝物件本身,而且拷貝物件包含的參考指向的所有物件,舉例來說更加清楚:物件 A1 中包含對 B1 的參考, B1 中包含對 C1 的參考,淺拷貝 A1 得到 A2 , A2 中依然包含對 B1 的參考, B1 中依然包含對 C1 的參考,深拷貝則是對淺拷貝的遞回,深拷貝 A1 得到 A2 , A2 中包含對 B2 ( B1 的 copy )的參考, B2 中包含對 C2 ( C1 的 copy )的參考,
若不對clone()方法進行改寫,則呼叫此方法得到的物件即為淺拷貝
大廠面試總結
互聯網大廠比較喜歡的人才特點:對技術有熱情,強硬的技識訓礎實力;主動,善于團隊協作,善于總結思考,技識訓礎以及的問題多看看書準備,不懂的直接說不懂沒關系的;在專案細節上多把關一下,根據專案有針對性的談自己的技術亮點,能表達清楚,可以引導面試官來問你比較擅長的技術問題,
另外本人整理收藏了20年多家公司面試知識點整理 以及各種知識點整理 下面有部分截圖 想要資料的話點擊795983544暗號CSDN
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/196705.html
標籤:其他
上一篇:java語言的入門開始介紹