通過前兩篇文章大家也看出nacos從使用角度來說功能強大,我們現有的配置支持較友好,對專案的侵入性較小,這也是我繼續研究他的動力,看看到底是否能引入到專案中來,下面三個主題是我接下來研究的主要方向:
- 選舉機制
- 資料同步機制
- 性能
nacos作為配置中心的功能是基于raft協議來實作的,為什么要選raft呢?
答案只有兩個字:簡單,相比paxos協議來說,raft協議要簡單的多,我們日常開發做方案時也應如此,簡潔有效方案省時省力、易于實作、易于維護,我們逐漸培養自己從復雜的業務中抽象出最簡單直接的方案的能力,培養自己化繁為簡的能力,
接下來不在廢話,直接上raft協議中選舉機制部分,
在raft中,任何時候一個服務器可以扮演下面角色之一:
- Leader: 所有請求的處理者,Leader副本接受client的更新請求,本地處理后再同步至多個其他副本;
- Follower: 請求的被動更新者,從Leader接受更新請求,然后寫入本地日志檔案
- Candidate候選人: 如果Follower副本在一段時間內沒有收到Leader副本的心跳,則判斷Leader可能已經故障,此時啟動選主程序,此時副本會變成Candidate狀態,直到選主結束,
- term:這根民主社會的選舉很像,每一屆新的履職期稱之為一屆任期
看到了這里,大家覺的raft的選舉程序是怎樣的呢?此處可以心里默想5分鐘,已檢驗一下自己做方案的能力,然后再看下牛人是怎么實作的,從對比中學習人家的思路,在做事兒之前要現有自己的觀念和看法,先思考一番,先思而后行,這樣做有兩個好處:
1、不會盲從,能去其缺點,學習有點;
2、能鍛煉自己的做事兒做方案的能力,能讓自己更加獨立,不依賴別人,成為團隊的核心、頂梁柱,
選舉程序如下: 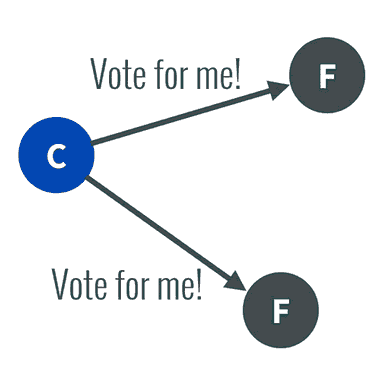
- 系統剛剛啟動,所有節點的任期都是0,大家的role都是follower
- 一個啟動的節點第一個觸發未檢測到心跳超時,自增任期為1,并且重新計時(投票開始時間),給自己投一票,然后向所有的其它節點發起投票
- 其它節點當前的任期都為0,且日志也沒空,肯定會投票給它,而且這些節點因為收到了candidate的投票選舉,清零自己的心跳空白等待時間,未超時前不會發起投票,從而避免多重投票導致無效投票的可能性
- 第一個發起投票的節點收到半數投票,成為leader,
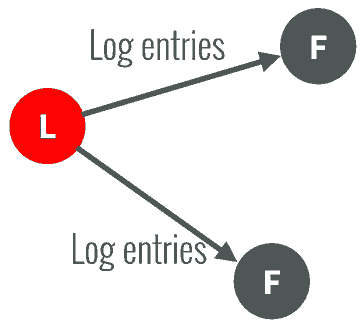
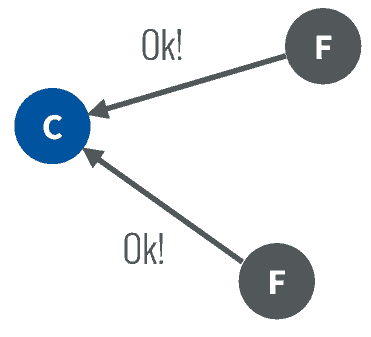
1、每次follower收到leader的一次HeartBeat,都會清零自己的心跳計時器,重新開始計時,如果當前心跳計時器超時了,仍然未收到leader的心跳,就會從follower變成candidate
2、自增當前任期,且開始計時(選舉計時),向其它節點發起投票
3、其它節點會比較 任期和日志的序號,至少不能比自己的資料舊才會投票給第一個發起投票的節點
4、超過半數節點投票成功,才會成為leader,否則要等待選舉超時,再發起第二輪投票,
動態程序: https://raft.github.io/
看到這里大家是否有疑問?個人的疑問:
選取出了主節點之后,從節點如何知道誰是主節點?
任期的時長改怎么設定呢?所有節點都一樣?
從原始碼給大家解釋nacos的實作程序,
raft協議的實作都在RaftCore這個類中,
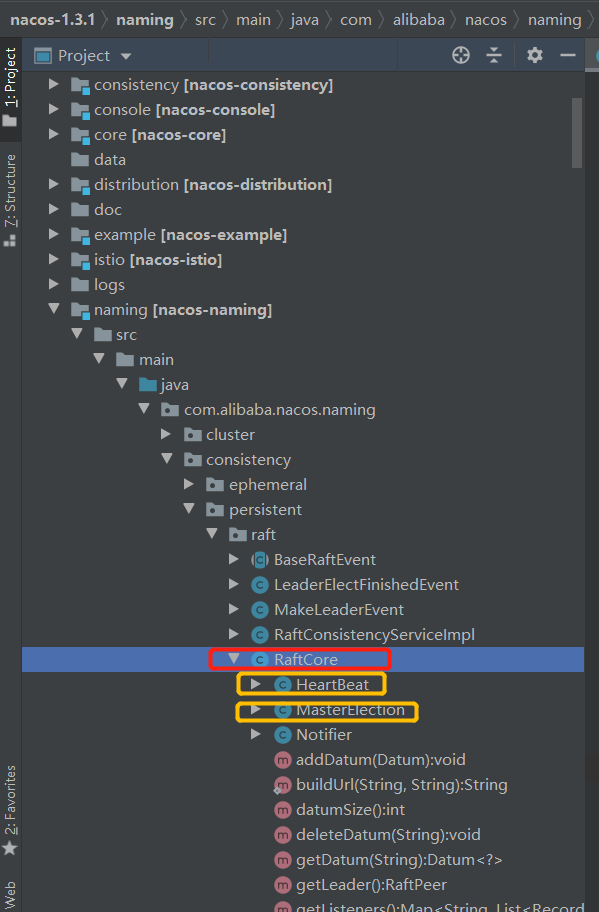
Raft中有兩個子類分被負責選舉和心跳,
1、選舉的入口
public static final long TICK_PERIOD_MS = TimeUnit.MILLISECONDS.toMillis(500L);
public void init() throws Exception {
//省略其他邏輯代碼
....
Loggers.RAFT.info("finish to load data from disk, cost: {} ms.", (System.currentTimeMillis() - start));
GlobalExecutor.registerMasterElection(new MasterElection());
GlobalExecutor.registerHeartbeat(new HeartBeat());
Loggers.RAFT.info("timer started: leader timeout ms: {}, heart-beat timeout ms: {}",
GlobalExecutor.LEADER_TIMEOUT_MS, GlobalExecutor.HEARTBEAT_INTERVAL_MS);
}
public static void registerMasterElection(Runnable runnable) {
NAMING_TIMER_EXECUTOR.scheduleAtFixedRate(runnable, 0, TICK_PERIOD_MS, TimeUnit.MILLISECONDS);
}
public static void registerHeartbeat(Runnable runnable) {
NAMING_TIMER_EXECUTOR.scheduleWithFixedDelay(runnable, 0, TICK_PERIOD_MS, TimeUnit.MILLISECONDS);
}可以看出每隔500ms就會觸發一次選舉任務和心跳任務
2、接下來看一下心跳是如何做的
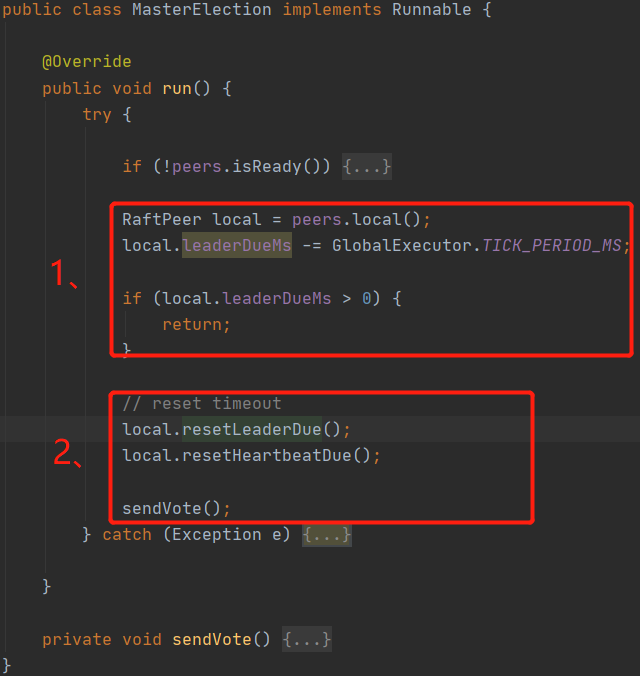
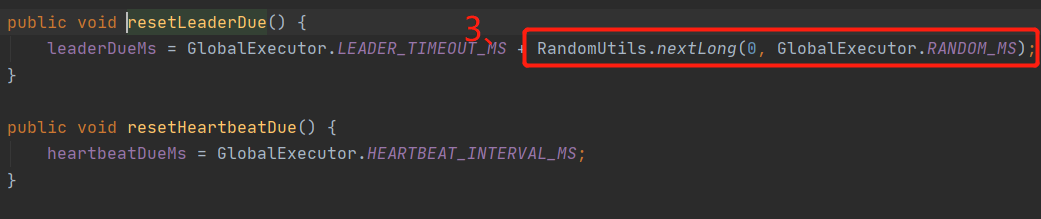
看原始碼“1、”處可以發現,在leaderDue(leader任期)內是不會進行選舉的,只有leaderDue到期之后才會重置leaderDue和heartBeatDue(心跳檢測時長),然后發送起投票,這里有個細節可以關注下,在代碼“3、”處有一個隨機值,大家有沒有想過為什么要加入這個隨機值?
答:隨機值是為了讓每個節點的leaderDueMs不同,也就是每個節點的leader任期不一樣,從而避免大家同時發起投票,提升選舉leader的成功率,換一種說法就是,某個節點leaderDueMs先減為0,先自增term,然后后發起投票,這是該節點由于term+1比其他節點term值大,從而成功成為leader,如果不加隨機值,大家同時發起頭票,同時term+1 這樣在這一輪選舉中就不會有leader,
3、選舉具體程序
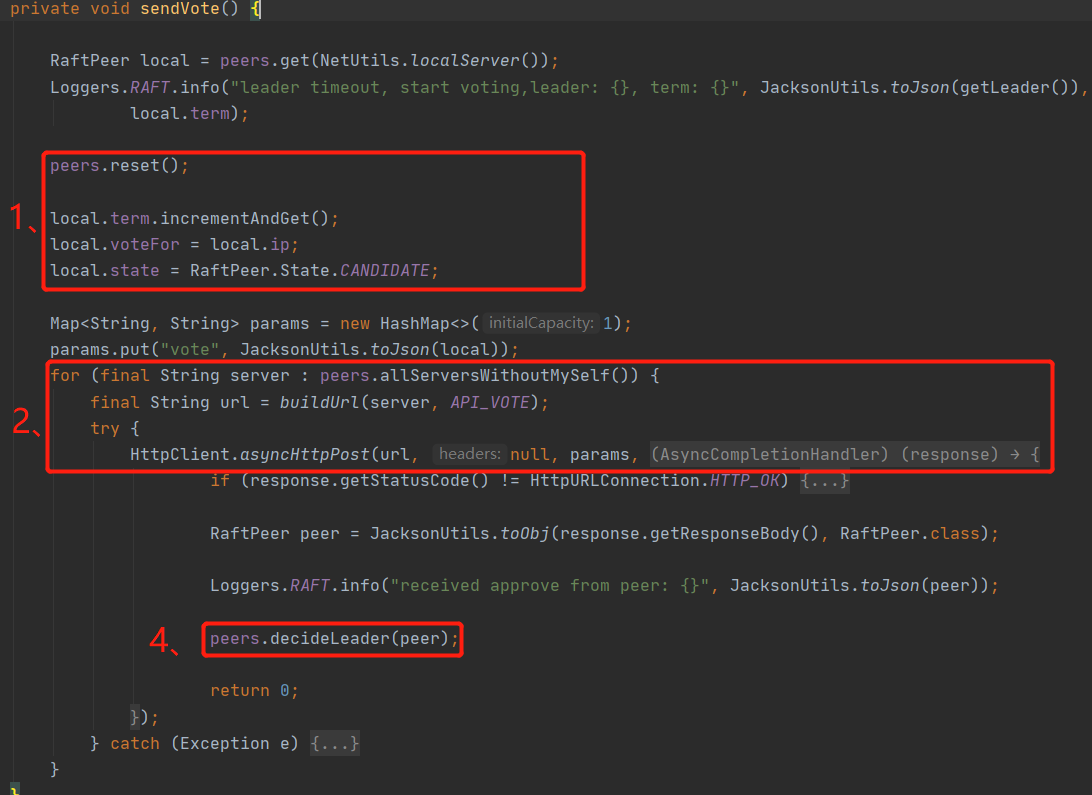
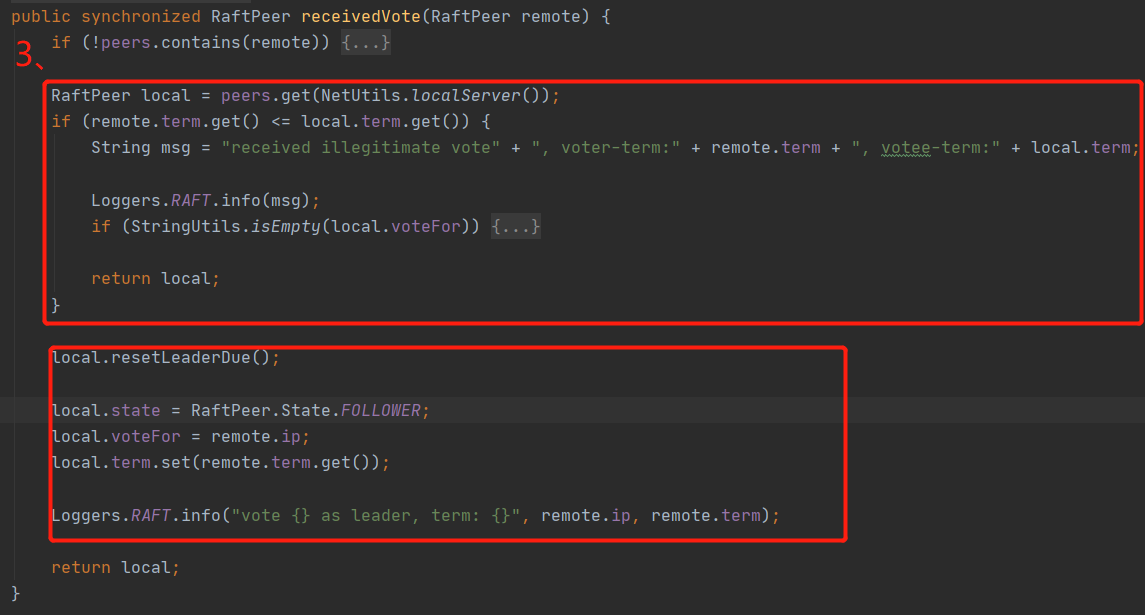
發起頭票的程序為頭票發起方,向不包含自己的其他節點發起頭票請求,其他節點接收到請求后,進行上述代碼處“3、”處的處理,看一下term是否比自己的term他,大則投給他,然后然后將自己的term設定為要發起頭票請求的term,重置leaderDueMs(為了避免自己再發起一輪頭票請求),最后將頭票結果回傳給頭票發起方,頭票發起方接收到頭票結果,然后根據結果有半數頭票的leader成為真正的leader,選舉到此結束,
那么問題來了,其他節點怎么知道這個頭票結果呢?如果是你該以何種方式通知其他節點呢?
這時候其實由于其他節點都選某個節點為主,然后自己leaderDueMs重置,不會發起選舉了,
4、心跳程序
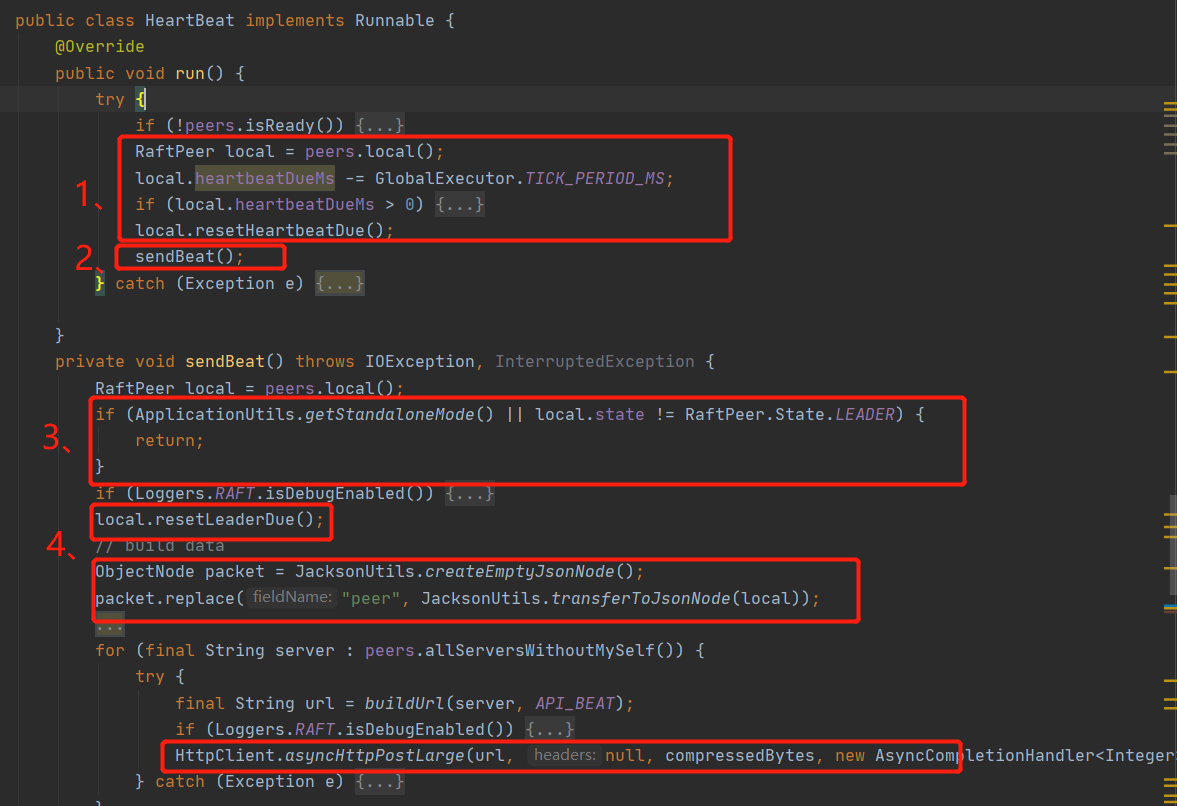
第一步和選舉類似,只有heartBeatDueMs到期之后才會發起心跳處理,這里的心跳處理周期遠遠小于選舉的term周期,而且再心跳處理程序中心跳發起方和接收方都會重置選舉時間,通過時間的延長來阻止各個節點發起頭票請求,
上面代碼地四處解決了某一節點成為leader之后,如何將這個訊息通知給其他節點,答案就行通過心跳的方式將leader傳給其他節點,其他節點接收到心跳請求之后,更新leader,接收心跳請求的代碼如下,
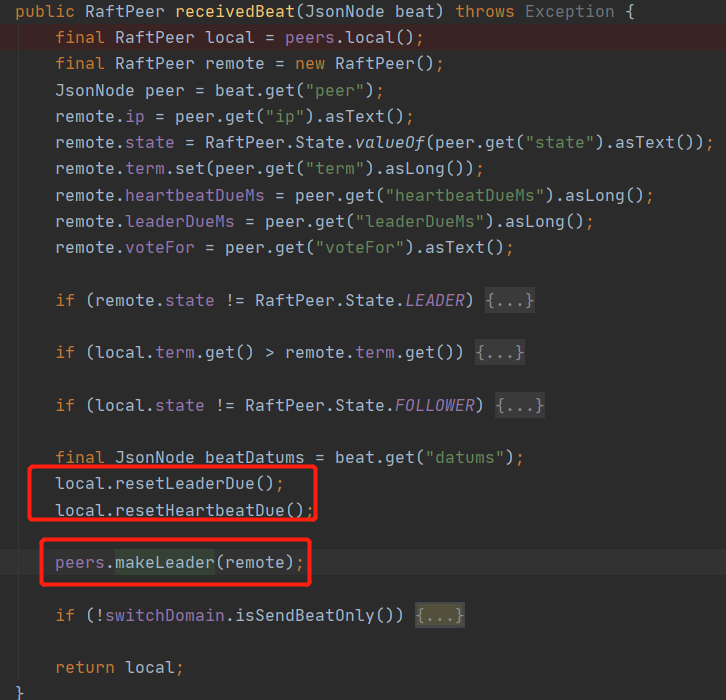
到此選舉機制介紹完畢,
此時有我有產生三個新的問題:
1、follower 超時,有問題嗎?
2、leader 超時,有哦問題嗎?
3、腦裂問題該如何處理?
問題一:
follower超時,自身會重新發起選舉,如果與其他節點不通,則會一直處于選舉狀態,如果超時一段時間后恢復,會通過選舉成為新的leader或者(接收心跳訊息完成了選舉),或者成為原來leader的follower(在發去選舉請求之前接收到了心跳訊息,成為follower),這時候會存在兩個leader,但是由于舊leader的term較小,發送心跳訊息不起效果,最終被新的leader同步為follower,該結論代驗證,僅僅是分析結論
又產生新問題,有兩個leader會影響配置資訊的發布嗎?
問題二:
leader超時重新選舉,差生新的leader,舊leader如果恢復了,也會通過心跳,被同步為follower,
問題三:
腦裂問題通過問題一和問題二的答案可以看出,通過時間續約和term比較最終舊leader被同步為follower,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/196913.html
標籤:其他