第四屆工業大資料創新競賽-水電站入庫流量預測
成績排名:
初賽線上第一段2月份25.4分,第二段最高分10.0分,第三段不好意思說,可看文章末尾我的提交結果記錄,第一次9月8號提交第六名,當時開心的要死,之后排名一路下降,大佬們太強了
代碼和資料檔案、提交結果檔案已上傳到我的下載:
代碼和特征檔案打包
優化思路:
1、單獨處理出2,8,11月的資料去訓練
2、加入更多的時序特征
3、把歷年同一時段的資料用來做特征
4、構建多個模型,采用不同的特征去預測
5、周期性信號分解,季節特性,這些角度降低資料的非平穩度
6、對各個遙測站與電廠之間資料的關聯關系進行分析,就可以得到各個測站的一個距離情況了
7、比如去年和今年的水情會有類似之處
8、到底下雨了還是沒下雨,要么就去預測遙測站降雨
9、當天8:00AM至次日8:00AM,降雨預報資料需要調整
10、分時段預測,用2點的資料訓練模型,預測2點的入庫流量
11、模型融合,樹模型、神經網路模型、時序預測模型等
主要訓練和預測的代碼,邊訓練邊預測
import csv
import os
import warnings
warnings.filterwarnings("ignore", "(?s).*MATPLOTLIBDATA.*", category=UserWarning)
import numpy as np
from rukuliuliang.data_model import build_model_etr, score_model, \
write_mae, get_test, test17, build_model_rf, properties12_1212, build_model_lgb, build_model_xgb
warnings.filterwarnings('ignore')
import pandas as pd
from sklearn.metrics import mean_squared_error
def writeOneCsv(relate_record, src):
try:
with open(src, 'a', newline='\n') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(relate_record)
except Exception as e:
print(e)
print(relate_record)
np.random.seed(2020)
os.chdir(r'E:\project\python\jianguiyuan\data\\')
X_data, Y_data = properties12_1212()
# 訓練集測驗集劃分調參,對結果影響很大
for train_start in range(1, 12, 50):
print(train_start)
x_train = X_data[train_start:, ]
x_val = X_data[:train_start, ]
y_train = Y_data[train_start:]
y_val = Y_data[:train_start]
# 可以合理注釋某個效果不好的模型
model_lgb = build_model_lgb(x_train, y_train)
val_lgb = model_lgb.predict(x_val)
model_xgb = build_model_xgb(x_train, y_train)
val_xgb = model_xgb.predict(x_val)
model_etr = build_model_etr(x_train, y_train)
val_etr = model_etr.predict(x_val)
model_rf = build_model_rf(x_train, y_train)
val_rf = model_rf.predict(x_val)
# Starking 第一層
train_etr_pred = model_etr.predict(x_train)
print('etr訓練集,mse:', mean_squared_error(y_train, train_etr_pred))
write_mae('etr', '訓練集', mean_squared_error(y_train, train_etr_pred))
train_lgb_pred = model_lgb.predict(x_train)
print('lgb訓練集,mse:', mean_squared_error(y_train, train_lgb_pred))
write_mae('lgb', '訓練集', mean_squared_error(y_train, train_lgb_pred))
train_xgb_pred = model_xgb.predict(x_train)
print('xgb訓練集,mse:', mean_squared_error(y_train, train_xgb_pred))
write_mae('xgb', '訓練集', mean_squared_error(y_train, train_xgb_pred))
train_rf_pred = model_rf.predict(x_train)
print('rf訓練集,mse:', mean_squared_error(y_train, train_rf_pred))
write_mae('rf', '訓練集', mean_squared_error(y_train, train_rf_pred))
Strak_X_train = pd.DataFrame()
Strak_X_train['Method_1'] = train_rf_pred
Strak_X_train['Method_2'] = train_lgb_pred
Strak_X_train['Method_3'] = train_etr_pred
Strak_X_train['Method_4'] = train_xgb_pred
Strak_X_val = pd.DataFrame()
Strak_X_val['Method_1'] = val_rf
Strak_X_val['Method_2'] = val_lgb
Strak_X_val['Method_3'] = val_etr
Strak_X_val['Method_4'] = val_xgb
# 第二層
model_Stacking = build_model_etr(Strak_X_train, y_train)
val_pre_Stacking = model_Stacking.predict(Strak_X_val)
score_model(Strak_X_val, y_val, val_pre_Stacking, model_Stacking, '驗證集')
def predict12():
for m in [1]:
print(m + 1)
x_test1 = test17()[m].reshape(1, 12)
x_test_d = get_test()[56 * m:56 * (m + 1), ]
vec = [m + 1]
for i in range(0, 7):
for n in range(0, 8):
x_test1[:, 5:12] = x_test_d[i * 7 + n]
etr = model_etr.predict(x_test1)
lgb = model_lgb.predict(x_test1)
rf = model_rf.predict(x_test1)
xgb = model_xgb.predict(x_test1)
Strak_X_test = pd.DataFrame()
Strak_X_test['Method_1'] = etr
Strak_X_test['Method_2'] = lgb
Strak_X_test['Method_3'] = rf
Strak_X_test['Method_4'] = xgb
pred = model_Stacking.predict(Strak_X_test)
print(pred[0])
# 邊預測邊把預測值作為時序特征
x_test1[0][4] = x_test1[0][3]
x_test1[0][3] = x_test1[0][2]
x_test1[0][2] = x_test1[0][1]
x_test1[0][1] = x_test1[0][0]
x_test1[0][0] = pred[0]
x_test_list = x_test1[0].tolist()
# 把特征資料記錄下來
writeOneCsv(x_test_list, 'rf_etr_xgb_lgb_12_2_' + str(m + 1) + '.csv')
vec.append(pred[0])
writeOneCsv(vec, 'submission1011_2.csv')
predict12()
模型訓練sklearn包:決策樹,隨機森林,極端隨機森林,多層感知機,lgb,xgb,GBDT,邏輯回歸等等好的機器學習演算法
import csv
import os
import numpy as np
import pandas as pd
from lightgbm import LGBMRegressor
from ngboost import NGBoost
from ngboost.distns import Normal
from ngboost.learners import default_tree_learner
from ngboost.scores import MLE
from sklearn import linear_model
from sklearn.ensemble import GradientBoostingRegressor, RandomForestRegressor, ExtraTreesRegressor, AdaBoostRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error
from sklearn.model_selection import GridSearchCV
from sklearn.svm import LinearSVR, SVR
from sklearn.tree import DecisionTreeRegressor
from xgboost import XGBRegressor
from catboost import CatBoostRegressor
def writeOneCsv(relate_record, src):
try:
with open(src, 'a', newline='\n') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(relate_record)
# csvFile.close()
except Exception as e:
print(e)
print(relate_record)
# writeCsvGBK(relate_record,bus)
os.chdir(r'E:\project\python\jianguiyuan\data\\')
src = r'E:\專案檔案\水電站流量預測\data\important\調參記錄\\'
hour = [0, 0.14285714285714285, 0.2857142857142857, 0.4285714285714285, 0.5714285714285714, 0.7142857142857143,
0.8571428571428571, 0.9999999999999999]
def submission_predict(model):
for m in [0, 1, 2]:
print(m + 1)
x_test1 = test12()[m].reshape(1, 12)
x_test_d = get_test()[7 * m:7 * (m + 1), ]
vec = [m + 1]
for i in range(0, 7):
x_test1[0, 5:10] = x_test_d[i]
for n in hour:
x_test1[0][11] = n
pred = model.predict(x_test1)
print(pred[0])
x_test1[0][4] = x_test1[0][3]
x_test1[0][3] = x_test1[0][2]
x_test1[0][2] = x_test1[0][1]
x_test1[0][1] = x_test1[0][0]
x_test1[0][0] = pred[0]
x_test_list = x_test1[0].tolist()
writeOneCsv(x_test_list, 'x_test_cnn12_' + str(m + 1) + '.csv')
vec.append(pred[0])
writeOneCsv(vec, 'lstm_submission.csv')
def get_properties_hour():
data = pd.read_csv('properties_hour.csv', usecols=[2, 3, 4, 5, 6, 7, 10, 11, 12, 13, 14, 15, 16])
return data.values[:, 1:], data.values[:, 0]
def properties_hour11():
data = pd.read_csv('properties_hour.csv', usecols=[2, 3, 4, 5, 6, 10, 11, 12, 13, 14, 15, 16])
return data.values[:, 1:], data.values[:, 0]
def properties12_11():
data = pd.read_csv('properties12_11.csv', usecols=[2, 3, 4, 5, 6, 7, 10, 11, 12, 13, 14, 15, 16])
return data.values[:, 1:], data.values[:, 0]
def properties12_489():
data = pd.read_csv('properties17_489.csv',
usecols=[2, 3, 4, 5, 6, 7, 10, 11, 12, 13, 14, 15, 16, 17])
return data.values[:, 1:], data.values[:, 0]
def properties12_1212():
data = pd.read_csv('properties12_2.csv',
usecols=[2, 3, 4, 5, 6, 7, 10, 11, 12, 13, 14, 15, 16])
return data.values[:, 1:], data.values[:, 0]
def test_hour11():
df1 = pd.read_csv('three_test', dtype=float, usecols=[1, 2, 3, 4, 6, 7, 8, 9, 10, 11, 12], engine='python')
return df1.values
def get_properties():
data = pd.read_csv('properties.csv', usecols=[2, 3, 4, 5, 6, 7, 10, 11, 12, 13, 14, 15])
return data.values[:, 1:], data.values[:, 0]
def get_tz():
data = pd.read_csv('lstm_tezheng.csv', usecols=[2, 3, 4, 5, 6, 7, 10, 11, 12, 13, 14])
return data.values[:, 1:], data.values[:, 0]
def get_test():
df1 = pd.read_csv('change_properties.csv', dtype=float)
return df1.values
def get_test12():
df1 = pd.read_csv('change_properties.csv', dtype=float)
return df1.values[:, :-4]
def get_test17():
df1 = pd.read_csv('change_properties.csv', dtype=float)
return df1.values
def test12():
df1 = pd.read_csv('three_test.csv', dtype=float, usecols=range(1, 14), sep=',', engine='python')
return df1.values
build_model_dt(x_train, y_train):
estimator = DecisionTreeRegressor(random_state=7)
param_grid = {
'max_depth': range(40, 45, 5),
'criterion': ['mse'],
}
model = GridSearchCV(estimator, param_grid, cv=5)
model.fit(x_train, y_train)
print('dt')
print(model.best_params_)
writeParams('dt', model.best_params_)
return model
def build_model_lgb(x_train, y_train):
estimator = LGBMRegressor()
param_grid = {
'learning_rate': [0.05],
'n_estimators': range(68, 69, 5),
'num_leaves': range(65, 69, 5)
}
gbm = GridSearchCV(estimator, param_grid)
gbm.fit(x_train, y_train.ravel())
print('lgb')
print(gbm.best_params_)
writeParams('lgb', gbm.best_params_)
return gbm
def build_model_xgb(x_train, y_train):
estimator = XGBRegressor(gamma=0, colsample_bytree=0.9, subsample=0.91)
param_grid = {
'learning_rate': [0.18],
'max_depth': range(44, 48, 5),
'n_estimators': range(87, 88, 5),
}
model = GridSearchCV(estimator, param_grid, cv=3)
model.fit(x_train, y_train)
print('xgb')
print(model.best_params_)
writeParams('xgb', model.best_params_)
return model
def build_model_rf(x_train, y_train):
estimator = RandomForestRegressor(criterion='mse')
param_grid = {
'max_depth': range(48, 66, 5),
'n_estimators': range(91, 92, 5),
}
model = GridSearchCV(estimator, param_grid, cv=5, n_jobs=-1, verbose=10)
model.fit(x_train, y_train)
print('rf')
print(model.best_params_)
writeParams('rf', model.best_params_)
return model
def build_model_etr(x_train, y_train):
# 極端隨機森林回歸 n_estimators 即ExtraTreesRegressor最大的決策樹個數
estimator = ExtraTreesRegressor(criterion='mse')
param_grid = {
'max_depth': range(38, 49, 10),
'n_estimators': range(113, 115, 5),
}
model = GridSearchCV(estimator, param_grid, cv=5, n_jobs=-1, verbose=10)
model.fit(x_train, y_train)
print('etr')
print(model.best_params_)
writeParams('etr', model.best_params_)
return model
def train_cat(x_train, y_train):
estimator = CatBoostRegressor(loss_function='RMSE')
param_grid = {
'iterations': range(1, 2, 1),
'learning_rate': [0.23, 0.25, 0.19],
'depth': range(1, 2, 1),
}
model = GridSearchCV(estimator, param_grid, cv=5, n_jobs=-1, verbose=10)
model.fit(x_train, y_train)
print('cat')
print(model.best_params_)
writeParams('cat', model.best_params_)
return model
def train_ng(x_train, y_train):
ngb = NGBoost(Base=default_tree_learner, Dist=Normal, Score=MLE(), natural_gradient=True,
verbose=False)
ngb.fit(x_train, y_train)
print('ngb')
return ngb
def build_model_mlpr(x_train, y_train):
from sklearn.neural_network import MLPRegressor
'''激活函式用relu,梯度下降方法用lbfgs,效果是最好的'''
mlp = MLPRegressor(activation='relu', solver='lbfgs')
param_grid = {
'alpha': [0.002, 0.003, 0.004],
'hidden_layer_sizes': [(40, 20), (36, 18), (38, 19)],
'max_iter': range(65, 76, 5),
}
model = GridSearchCV(mlp, param_grid, cv=3)
model.fit(x_train, y_train.ravel())
print('mlpr')
print(model.best_params_)
writeParams('mlpr', model.best_params_)
return model
def build_model_ada(x_train, y_train):
estimator = AdaBoostRegressor()
param_grid = {
'learning_rate': [0.23, 0.17, 0.15],
'n_estimators': range(10, 20, 5),
}
model = GridSearchCV(estimator, param_grid, cv=3)
model.fit(x_train, y_train)
print('ada')
print(model.best_params_)
writeParams('ada', model.best_params_)
return model
def build_model_gbdt(x_train, y_train):
estimator = GradientBoostingRegressor(min_samples_leaf=0.1, min_samples_split=10, subsample=0.998)
param_grid = {
'learning_rate': [0.75],
'max_depth': range(25, 30, 5),
'n_estimators': range(80, 85, 5)
}
gbdt = GridSearchCV(estimator, param_grid, cv=3)
gbdt.fit(x_train, y_train.ravel())
print('gbdt')
print(gbdt.best_params_)
writeParams('gbdt', gbdt.best_params_)
return gbdt
def build_model_liner_svr(x_train, y_train):
svm_reg = LinearSVR()
param_grid = {
'C': range(1, 2, 2),
}
model = GridSearchCV(svm_reg, param_grid, cv=3)
model.fit(x_train, y_train)
print('LSVR')
print(model.best_params_)
return model
def build_model_svr(x_train, y_train):
model = SVR()
param_grid = {
'C': range(1, 2, 2),
'kernel': ['poly', 'rbf', 'linear', 'precomputed'],
'cache_size': range(200, 210, 20),
}
model = GridSearchCV(model, param_grid, cv=3)
model.fit(x_train, y_train.ravel())
print('SVR')
print(model.best_params_)
return model
def build_model_lr(x_train, y_train):
reg_model = linear_model.LinearRegression()
reg_model.fit(x_train, y_train)
return reg_model
def score_model(train, test, predict, model, data_type):
score = model.score(train, test)
print(data_type + ",R^2,", round(score, 6))
writeOneCsv(['staking', data_type, 'R^2', round(score, 6)], src + '調參記錄.csv')
mae = mean_absolute_error(test, predict)
print(data_type + ',MAE,', round(mae, 6))
writeOneCsv(['staking', data_type, 'MAE', round(mae, 6)], src + '調參記錄.csv')
mse = mean_squared_error(test, predict)
print(data_type + ",MSE,", round(mse, 6))
writeOneCsv(['staking', data_type, 'MSE', round(mse, 6)], src + '調參記錄.csv')
def fit_size(x, y):
from sklearn import preprocessing
x_MinMax = preprocessing.MinMaxScaler()
y_MinMax = preprocessing.MinMaxScaler()
y = np.array(y).reshape(len(y), 1)
x = x_MinMax.fit_transform(x)
y = y_MinMax.fit_transform(y)
return x, y
def scatter_line(y_val, y_pre):
import matplotlib.pyplot as plt
xx = range(0, len(y_val))
plt.scatter(xx, y_val, color="red", label="Sample Point", linewidth=3)
plt.plot(xx, y_pre, color="orange", label="Fitting Line", linewidth=2)
plt.legend()
plt.show()
def writeParams(model, best):
if model in ['gbdt', 'xgb']:
writeOneCsv([model, best['max_depth'], best['n_estimators'], best['learning_rate']], src + '調參記錄.csv')
elif model == 'mlpr':
writeOneCsv([model, best['hidden_layer_sizes'], best['max_iter'], best['alpha']], src + '調參記錄.csv')
elif model == 'ada':
writeOneCsv([model, 0, best['n_estimators'], best['learning_rate']], src + '調參記錄.csv')
elif model == 'lgb':
writeOneCsv([model, best['num_leaves'], best['n_estimators'], best['learning_rate']], src + '調參記錄.csv')
elif model == 'dt':
writeOneCsv([model, best['max_depth'], 0, best['criterion']], src + '調參記錄.csv')
elif model == 'cat':
writeOneCsv([model, best['depth'], best['iterations'], best['learning_rate']], src + '調參記錄.csv')
else:
writeOneCsv([model, best['max_depth'], best['n_estimators'], 0], src + '調參記錄.csv')
def write_mae(model, data_type, mae):
writeOneCsv([model, data_type, 'mae', mae], src + '調參記錄.csv')
資料特征工程代碼
import os
from datetime import timedelta
from sklearn import preprocessing
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, chi2
from utils.read_write import pdReadCsv, writeOneCsv, writeCsv, readCsv
import pandas as pd
import numpy as np
from utils.time_change import str_datetime, str_date, str_date_1
os.chdir(r'E:\專案檔案\水電站流量預測\data\important\\')
from utils.read_write import eachFile
def buildData():
file = '四川省各河流水系流量1.csv'
main_data = pd.read_csv(file, sep=',')
dir = 'E:\專案檔案\水電站流量預測\data\四川省公共氣象服務產品2020-7-2\\'
files = eachFile(dir)
for file in files:
date = file.split('_')[-1].split('.')[0][:8]
one = pdReadCsv(file, ',')
merge_data = pd.merge(main_data, one, left_on='站址', right_on='氣象站')
print(merge_data)
def change_date():
src = r'E:\專案檔案\水電站流量預測\data\important\提交結果\stacking_keras17_1212\\'
save = 'submission.csv'
df1 = readCsv(r'E:\project\python\jianguiyuan\data\submission.csv')
one1 = [1]
one2 = [2]
one3 = [3]
for i in range(0,len(df1)):
if i <56:
one1.append(float(df1[i][0]))
elif i <112:
one2.append(float(df1[i][0]))
else:
one3.append(float(df1[i][0]))
writeOneCsv(one1,src+save)
writeOneCsv(one2,src+save)
writeOneCsv(one3,src+save)
# change_date()
def join_data():
src = r'E:\專案檔案\水電站流量預測\data\important\\時間降雨流量hour\\'
df = pd.read_excel('入庫流量資料.xlsx')
df1 = pd.read_excel('遙測站降雨資料.xlsx')
for i in range(1, 24):
df1['TimeStample'] = df1['TimeStample'].map(lambda x: x + timedelta(hours=i))
merge = pd.merge(df1, df, on='TimeStample')
merge.to_csv(src + '時間降雨流量hour_' + str(i) + '.csv')
def join_t():
src = r'E:\專案檔案\水電站流量預測\data\important\\時間降雨流量hour\\'
save = r'E:\專案檔案\水電站流量預測\data\important\\時間降雨流量環境\\'
files = eachFile(src)
df1 = pd.read_csv(r'E:\project\python\jianguiyuan\data\huanjing.txt', sep='\t', parse_dates=['TimeStample'],
engine='python')
for file in files:
df = pd.read_csv(src + file, engine='python', usecols=range(1, 42))
df['date'] = df['TimeStample'].map(lambda x: str_date(x[:10]))
merge = pd.merge(df1, df, left_on='TimeStample', right_on='date')
merge.to_csv(save + file, index=False)
# 當天8:00AM至次日8:00AM
def join_predicate():
src = r'E:\專案檔案\水電站流量預測\data\important\\'
df1 = pdReadCsv(src + '預報.csv', ',')
df1['TimeStample'] = df1['TimeStample'].map(lambda x: str_date_1(x).date())
for index, one in df1.iterrows():
data = [one[0] + timedelta(days=4), one[5], df1.iloc[index + 1, 4], df1.iloc[index + 2, 3],
df1.iloc[index + 3, 2], df1.iloc[index + 4, 1]]
writeOneCsv(data, 'E:\project\python\jianguiyuan\data\\yubao.csv')
# join_predicate()
def pca_data():
df = pd.read_csv('時間降雨流量.csv', engine='python', usecols=range(2, 41, 1))
X = df.values.copy()
pca = PCA(n_components=39)
newX = pca.fit_transform(X)
print(newX)
print(pca.explained_variance_ratio_)
def params_selection(x, y):
x = SelectKBest(chi2, k=22).fit_transform(x, y)
return x
def build_test():
save = r'E:\專案檔案\水電站流量預測\data\important\test_2018\\'
df1 = pd.read_excel('遙測站降雨資料.xlsx')
for i in range(0, 24):
df1['TimeStample'] = df1['TimeStample'].map(lambda x: x + timedelta(hours=i))
df1['date'] = df1['TimeStample'].map(lambda x: x.date())
df1 = df1[(df1['date'] >= str_date('2018-02-01').date()) & (df1['date'] <= str_date('2018-02-07').date())]
df1.to_csv(save + '時間降雨test02_hour_' + str(i) + '.csv', index=False)
df1 = df1[(df1['date'] >= str_date('2018-08-01').date()) & (df1['date'] <= str_date('2018-08-07').date())]
df1.to_csv(save + '時間降雨test08_hour_' + str(i) + '.csv', index=False)
df1 = df1[(df1['date'] >= str_date('2018-11-01').date()) & (df1['date'] <= str_date('2018-11-07').date())]
df1.to_csv(save + '時間降雨test11_hour_' + str(i) + '.csv', index=False)
def build_lstm_data():
df = pd.read_excel('入庫流量資料.xlsx')['Qi']
TimeStample = pd.read_excel('入庫流量資料.xlsx')['TimeStample']
data_csv = pd.DataFrame(df, dtype=float)
# TimeStample = pd.DataFrame(TimeStample, dtype=datetime64)
# 總共15020
yt = data_csv.iloc[0:15019, 0]
# TimeStample = TimeStample.iloc[0:15019, 0]
# 用緊鄰的5個歷史資料預測下一時刻
yt_1 = yt.shift(1)
yt_2 = yt.shift(2)
yt_3 = yt.shift(3)
yt_4 = yt.shift(4)
yt_5 = yt.shift(5)
yt_6 = yt.shift(6)
yt_7 = yt.shift(7)
yt_8 = yt.shift(8)
yt_9 = yt.shift(9)
yt_10 = yt.shift(10)
data = pd.concat([TimeStample, yt, yt_1, yt_2, yt_3, yt_4, yt_5, yt_6, yt_7, yt_8, yt_9, yt_10], axis=1)
data.columns = ['TimeStample', 'yt', 'yt_1', 'yt_2', 'yt_3', 'yt_4', 'yt_5', 'yt_6', 'yt_7', 'yt_8', 'yt_9,',
'yt_10']
data = data.dropna() # 除去NULL,因為序列的起始點是沒有歷史的
data.to_csv('yt10.csv')
# build_lstm_data()
def time_pre():
data = pd.read_csv('yt10.csv')
df1 = pd.read_csv('yubao.csv', encoding='gbk', names=['datetime', 'd5', 'd4', 'd3', 'd2', 'd1'])
df1['date'] = df1['datetime'].map(lambda x: str_date(x).date())
data['date'] = data['TimeStample'].map(lambda x: str_datetime(x).date())
data = pd.merge(data, df1, on='date')
data['hour'] = data['TimeStample'].map(lambda x: str_datetime(x).hour)
scaler_x = preprocessing.MinMaxScaler(feature_range=(0, 1))
new = np.array(data['hour']).reshape((data.shape[0], 1))
data['hour'] = scaler_x.fit_transform(new)
data['month'] = data['TimeStample'].map(lambda x: str_datetime(x).month)
data = data[data['month'] == 11]
scaler_x = preprocessing.MinMaxScaler(feature_range=(0, 1))
new = np.array(data['month']).reshape((data.shape[0], 1))
data['month'] = scaler_x.fit_transform(new)
data.to_csv(r'E:\project\python\jianguiyuan\data\\' + 'property17_11.csv', index=False)
# time_pre()
def month_tz():
import numpy as np
src = 'E:\project\python\jianguiyuan\data\\'
data = pd.read_csv(src + 'lstm_tezheng.csv')
data['month'] = data['TimeStample'].map(lambda x: str_datetime(x).month)
scaler_x = preprocessing.MinMaxScaler(feature_range=(0, 1))
new = np.array(data['month']).reshape((data.shape[0], 1))
data['month'] = scaler_x.fit_transform(new)
data['hour'] = data['TimeStample'].map(lambda x: str_datetime(x).hour)
scaler_x = preprocessing.MinMaxScaler(feature_range=(0, 1))
new = np.array(23).reshape((1, 1))
data['hour'] = scaler_x.fit_transform(new)
data.to_csv('properties.csv', index=False)
def hour_tz():
src = 'E:\project\python\jianguiyuan\data\\'
data = pd.read_csv(src + 'properties.csv')
data['hour'] = data['TimeStample'].map(lambda x: str_datetime(x).hour)
scaler_x = preprocessing.MinMaxScaler(feature_range=(0, 1))
new = np.array(23).reshape((1, 1))
hour = scaler_x.fit_transform(new)
print(hour)
# data.to_csv(src + 'properties_hour.csv', index=False)
def extra_month():
src = 'E:\project\python\jianguiyuan\data\\'
data = pd.read_csv(src + 'properties_hour.csv')
data['month1'] = data['TimeStample'].map(lambda x: str_datetime(x).month)
# data2 = data[data['month1'] == 2]
# data8 = data[data['month1'] == 8]
data11 = data[data['month1'].isin([4, 8, 9])]
# data2.to_csv(src + 'properties12_2.csv', index=False)
# data8.to_csv(src + 'properties12_8.csv', index=False)
data11.to_csv(src + 'properties12_489.csv', index=False)
# extra_month()
def add_properties():
src = 'E:\project\python\jianguiyuan\data\\'
data = pd.read_csv(src + 'properties_hour.csv')
data['datetime'] = data['TimeStample'].map(lambda x: str_datetime(x))
data = data[data['datetime'] >= str_date('2014-01-01').date()]
data['day'] = data['datetime'].map(lambda x: x.day)
new_data = data[['datetime', 'month', 'hour', 'day', 'yt']]
df1 = pd.merge(new_data, new_data, on=['month', 'hour', 'day'])
groups = df1.groupby('datetime_x')
finish = []
for name, group in groups:
if group.shape[0] > 3:
data1 = [name, group.iloc[0, 6], group.iloc[1, 6], group.iloc[2, 6],
group.iloc[3, 6]]
finish.append(data1)
datafrmae = pd.DataFrame(finish, columns=['datetime', 'yt_14', 'yt_15', 'yt_16', 'yt_17'])
data = pd.merge(data, datafrmae, on='datetime')
# data['month1'] = data['datetime'].map(lambda x: x.month)
# data2 = data[data['month1'].isin([1, 2, 12])]
# data8 = data[data['month1'].isin([4, 8, 9])]
# data11 = data[data['month1'].isin([10, 11, 12])]
# data2.to_csv(src + 'properties16_1212.csv', index=False)
data.to_csv(src + 'properties16.csv', index=False)
# data11.to_csv(src + 'properties16_101112.csv', index=False)
# add_properties()
def extra_jj():
src = 'E:\project\python\jianguiyuan\data\\'
data = pd.read_csv(src + 'competition1.json')
data['month1'] = data['datetime'].map(lambda x: str_datetime(x).month)
data2 = data[data['month1'].isin([1, 2, 12])]
data8 = data[data['month1'].isin([4, 8, 9])]
data2.to_csv(src + 'properties17_1212.csv', index=False)
data8.to_csv(src + 'properties17_489.csv', index=False)
# for name, one in data.groupby('month'):
# print(name)
# print(data['yt_14'].sum())
# print(data['yt_15'].sum())
# print(data['yt_16'].sum())
# print(data['yt_17'].sum())
def properties12_13():
src = 'E:\project\python\jianguiyuan\data\\'
path = r'E:\專案檔案\水電站流量預測\data\important\time\\'
data = pd.read_csv(src + 'properties12_2.csv')
properties_2015_1231 = pd.read_csv(path + 'properties_2015_1231.csv')
# data['datetime'] = data['TimeStample'].map(lambda x: str_datetime(x))
# data['datetime'] = data['TimeStample'].map(lambda x: str_datetime(x))
df1 = pd.merge(data, properties_2015_1231, on='TimeStample')
df1.to_csv(src + 'properties17_2.csv', index=False)
# properties12_13()
# extra_jj()
# add_properties()
# extra_month()
# hour_tz()
# month_tz()
# time_pre()
# build_test()
# join_predicate()
# params_selection()
# join_t()
# join_data()
# pca_data()
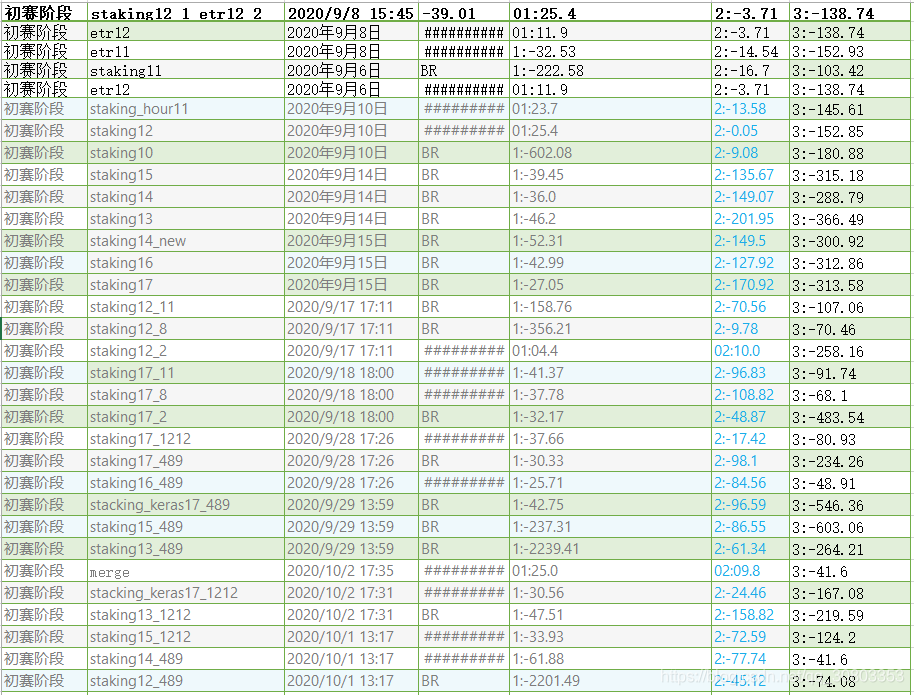
# buildData()附上我的提交結果分數記錄:
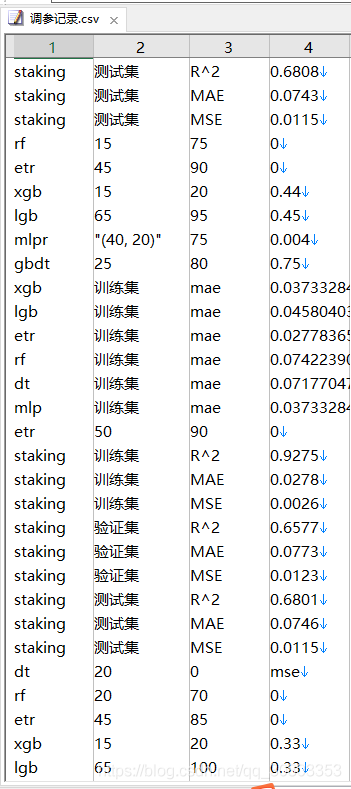
我的調參記錄也有意思:
代碼寫的有點冗長復雜,沒太多時間優化和洗掉無用的代碼,各位見笑了,如有疑問可以評論,比較急的話可以去我其他文章找我的qq號
AI信仰者
資料挖掘專家
機器學習專家
AI領軍人物
擅長人工智能,包括不限于資料挖掘和機器學習擅長Java、Python、Javascript等編程語言在金融、交通、傳媒、大資料等領域有豐富的專案經驗
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/200945.html
標籤:其他