1973年BS期權定價模型的誕生標志著期權定價進入精確的數量化測度階段,但是BS模型假設標的資產波動率為常數,這與現實市場觀測到的“波動率微笑”曲線嚴重不符,
heston假設標的資產的價格服從如下程序,其中波動率為時變函式[1]:
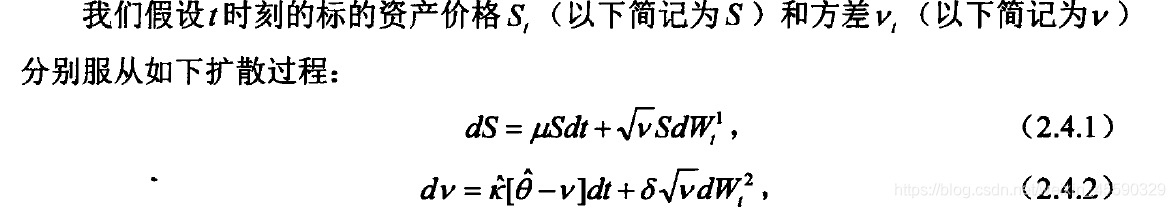
并且求出了歐式看漲期權定價公式[2]:
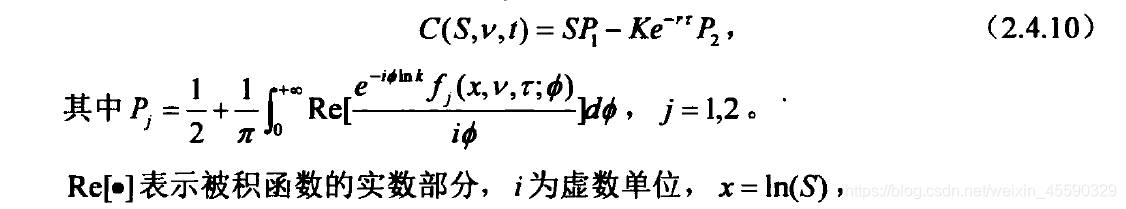
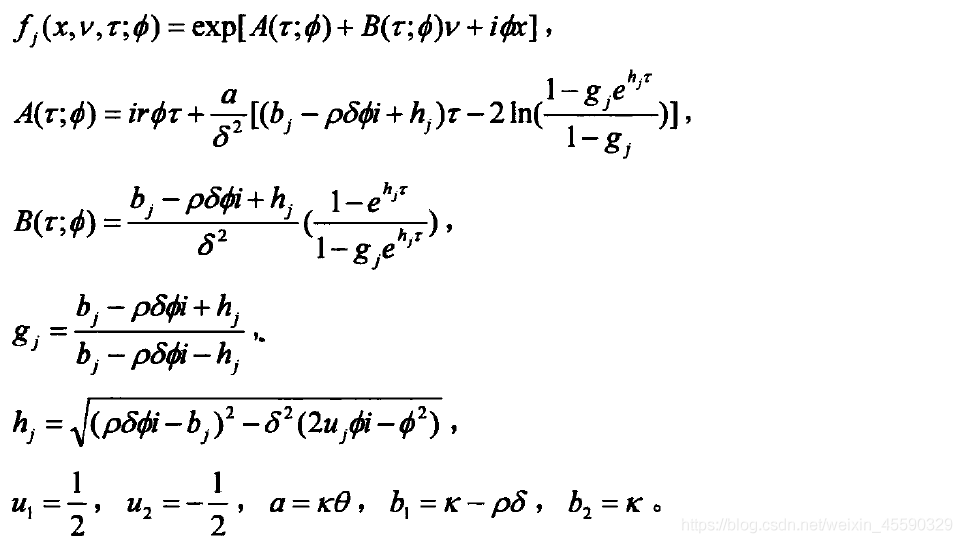
本文使用python實作了上述定價公式,該公式需要輸入一共九個引數,其中[v0,kappa,theta,sigma,rho]需要提前自行設定并填入,另外四個 [K,t,s0,r]:[執行價格,剩余時間,標的資產價格,無風險利率] 則是期權價格資料,BS模型定價同樣需要這幾個引數,
sv_model.py
"""heston期權定價模型計算期權價格"""
import numpy as np
import scipy.integrate as spi
class SV():
"""計算Heston隨機波動率模型下的期權價格"""
def __init__(self,K:float,t:float,s0:float,r:float,v0:float=0.01,kappa:float=2,theta:float=0.1,sigma:float=0.1,rho:float=-0.5):
"""輸入期權資料和基礎引數
#期權資料
k -期權執行價格
t -期權剩余到期時間(年)
s0 -標的資產初始價格
r -無風險收益率
#初始引數
v0
kappa
theta
sigma
rho
"""
# 期權資料
self.K = K
self.t = t
self.s0 = s0
self.r = r
# 初始引數
self.v0 = v0
self.kappa = kappa
self.theta = theta
self.sigma = sigma
self.rho = rho
# 特征函式
def characteristic_function(self,phi, type):
if type == 1:
u = 0.5
b = self.kappa - self.rho * self.sigma
else:
u = -0.5
b = self.kappa
a = self.kappa * self.theta
x = np.log(self.s0)
d = np.sqrt((self.rho * self.sigma * phi * 1j - b) ** 2 - self.sigma ** 2 * (2 * u * phi * 1j - phi ** 2))
g = (b - self.rho * self.sigma * phi * 1j + d) / (b - self.rho * self.sigma * phi * 1j - d)
D = self.r * phi * 1j * self.t + (a / self.sigma ** 2) * (
(b - self.rho * self.sigma * phi * 1j + d) * self.t - 2 * np.log((1 - g * np.exp(d * self.t)) / (1 - g)))
E = ((b - self.rho * self.sigma * phi * 1j + d) / self.sigma ** 2) * (1 - np.exp(d * self.t)) / (1 - g * np.exp(d * self.t))
return np.exp(D + E * self.v0 + 1j * phi * x)
# 積分部分
def integral_function(self,phi,type):
integral = (np.exp(-1 * 1j * phi * np.log(self.K)) * self.characteristic_function(phi, type=type))
return integral
# p值函式
def sv_P_Value(self,type):
"""
"""
ifun = lambda phi: self.integral_function(phi,type=type) / (1j * phi)
return 0.5 + (1 / np.pi) * spi.quad(ifun, 0, 1000)[0]
def sv_Call_Value(self):
"""
"""
P1 = self.s0 * self.sv_P_Value(type=1)
P2 = self.K * np.exp(-self.r * self.t) * self.sv_P_Value(type=2)
if np.isnan(P1-P2):return 1000000#如果初始引數使定價結果為nan,就返還巨大的值,視為報錯!巨大的期權價格會拉大定價誤差
else:return P1 - P2
#方便檢測定價結果
@classmethod
def test_multiple(cls,option_params:list,init_params:list):
"""
輸入:
option_params -list,期權價格引數
[K,t,s0,r]
init_params -list,sv模型引數
[v0,kappa,theta,sigma,rho]
輸出:
sv模型期權價格
示例:
sv=SV(K =2.15,t = 0.05924,s0 = 2.143896,r = 0.03043)
sv.test_multiple([2.15,0.059,2.143896,0.03043],[0.01,2,0.1,0.1,-0.5])#通過直接輸入兩個串列,很方便的計算期權價格
"""
sv=cls(option_params[0],option_params[1],option_params[2],option_params[3],
init_params[0],init_params[1],init_params[2],init_params[3],init_params[4])
c_sv=sv.sv_Call_Value()
return c_sv
if __name__=='__main__':
sv=SV(K =2.15,t = 0.05924,s0 = 2.143896,r = 0.03043)
sv.sv_Call_Value()
由于heston模型中有五個引數需要估計,傳統的線性最小二乘法失效,本文采用退火模擬演算法估計這五個引數,說實話,這五個引數非常難估計,
首先寫出模擬退火演算法的類:
myNG.py
"""模擬退火演算法"""
import numpy as np
import matplotlib.pyplot as plt
import copy
from randomrange import random_range
"""
部分名詞:
新解:在某輪回圈中通過自變數隨機變動產生的新解
新接受解:由于新解導致函式值變小,或者由于概率而接受的新解
歷史最優解:在整個回圈中產生的最優解
"""
class NG():
def __init__(self,func,x0):
"""
x0 -串列:函式的初始值
[v0,kappa,theta,sigma,rho]
func -待求解函式
"""
self.x=x0
self.dim_x=len(x0)#解的維度
self.func=func
self.f = func(self.x)#計算y值
self.x_best=self.x#記錄下來歷史最優解,即所有回圈中的最優解
self.f_best=self.f
self.times_stay=0#連續未接受新解的次數
self.times_stay_max=400#當連續未接受新解超過這個次數,終止回圈
self.T=100#初始溫度:初始溫度越高,前期接受新解的概率越大
self.speed=0.7#退火速度:溫度下降速度越快,后期溫度越低,接受新解的概率越小,從而最終穩定在某個解附件
self.T_min=1e-6#最低溫度:當低于該溫度時,終止全部回圈
self.xf_best_T={}#記錄下接受的所有新解
# 最初若函式值變動為delta,則認為函式值變動很大,可以產生p_expec概率接受新解
#若在初期便產生巨大的概率接受新解,則前期尋找新解的程序將變成盲目的隨機漫步毫無意義,因此利用alpha調節概率
self.p_expec = 0.9
self.delta_standard = 0.7
self.alpha =self.find_alpha()#調節概率因子
self.times_delta_samller = 0#統計新舊最優值之差絕對值連續小于某值的次數
self.delta_min=0.001#當新舊最優值之差絕對值連續小于此值達到某一次數時,終止該溫度回圈
self.times_delta_min=100#當新舊最優值之差絕對值連續小于此值達到這個次數時,終止該溫度回圈
self.times_max=500#當每個溫度下回圈超過這個次數,終止該溫度回圈
self.times_cycle=0#記錄演算法回圈總次數
self.times_p=0#統計因為p值較大而接受新解的次數
self.xf_all={self.times_cycle:[self.x,self.f]}#記錄下來每一次回圈產生的新解和函式值
self.xf_best_all={self.times_cycle:[self.x,self.f]}#記錄下來每一次回圈接受的新解和函式值
#溫度下降,產生新溫度
def T_change(self):
self.T=self.T*self.speed
print('當前溫度為{},大于最小溫度{}'.format(self.T,self.T_min))#展示當前溫度和最小溫度
# 將所有的x和f、回圈次數存盤下來
def save_xy(self):
self.xf_all[self.times_cycle]=[self.x,self.f]
#將所有的最優x,y、回圈次數存盤下來
def save_best_xy(self):
self.xf_best_all[self.times_cycle]=[self.x,self.f]
# 當調節因子為alpha時,函式值變動值為delta產生的接受新解概率
def __p_delta(self,alpha):
return np.exp(-self.delta_standard / (self.T * alpha))
# 用二分法尋找方程解
def __find_solver(self,func, f0):
"""
輸入:
func -待求解方程的函式
f0 -float,預期函式值
輸出:
mid -float,函式=預期函式值 的解
"""
up = 100
down = 0.00001
mid = (up + down) / 2
while abs(func(mid) - f0) > 0.0001:
if func(down) < f0 < func(mid):
up = mid
mid = (mid + down) / 2
elif func(up) > f0 > func(mid):
down = mid
mid = (up + down) / 2
else:
print('error!')
break
return mid
# 最初若函式值變動為delta,則認為函式值變動很大,可以產生p_expec概率接受新解
def find_alpha(self):
return self.__find_solver(self.__p_delta, self.p_expec)
#獲得新的x
def get_x_new(self):
random=np.random.normal(0,1,self.dim_x)#新的隨機增量
return self.x+random
#判斷是否可以接受新的解
def judge(self):
if self.delta<0:#如果函式值變動幅度小于0,則接受新解
self.x=self.x_new
self.f_last=self.f#在最優解函式值更新之前將其記錄下來
self.f=self.f_new
self.save_best_xy()#記錄每次回圈接受的新解
self.get_history_best_xy()#更新歷史最優解
self.times_stay = 0 # 由于未接受新解,將連續未接受新解的次數歸零
print('由于函式值變小新接受解{}:{}'.format(self.f,self.x))#展示當前接受的新解
else:
p=np.exp(-self.delta/(self.T*self.alpha))#接受新解的概率
p_=np.random.random()#判斷標準概率
if p>p_:#如果概率足夠大,接受新解
self.x = self.x_new
self.f_last = self.f # 在接受的新解更新之前將其記錄下來
self.f = self.f_new
self.save_best_xy()#記錄每次回圈接受的新解
self.get_history_best_xy() # 更新歷史最優解
print('由于概率{}大于{},新接受解{}:{}'.format(p,p_,self.f, self.x))#展示當前接受的新解
self.times_p+=1#統計因為概率而接受新解的次數
self.times_stay=0#由于未接受新解,將連續未接受新解的次數歸零
else:
self.times_stay+=1#連續接受新解次數加1
print('連續未接受新解{}次'.format(self.times_stay))
#獲得歷史最優解
def get_history_best_xy(self):
x_array = list(np.array(list(self.xf_best_all.values()))[:, 0]) # 從歷史所有的最優x和f中獲得所有的x
f_array=list(np.array(list(self.xf_best_all.values()))[:, 1])#從歷史所有的最優x和f中獲得所有的f
self.f_best=min(f_array)#從每階段最優的f中獲得最優的f
self.x_best=x_array[f_array.index(self.f_best)]#利用最優f反推最優x
return self.x_best,self.f_best
#繪制函式值降低記錄
def plot(self,x,y):
plt.figure(figsize=(13,8))
plt.plot(x,y)
plt.xlabel('回圈次數',fontsize=15)
plt.ylabel('函式值', fontsize=15)
plt.title('函式值變化程序')
#繪制最優值變化程序
def plot_best(self):
times_cycle_array=list(self.xf_best_all.keys())#獲得接受新解時的回圈次數
f_array = np.array(list(self.xf_best_all.values()))[:, 1] # 從所有接受的新解中獲得所有的函式值
self.plot(times_cycle_array,f_array)#繪制回圈次數與函式值的折線圖
#統計新舊函式值之差的絕對值連續小于此值的次數
def count_times_delta_smaller(self):
if self.delta_best<self.delta_min:
self.times_delta_samller+=1#如果新舊函式值之差絕對值小于某值,則次數加1,否則歸零
else:
self.times_delta_samller=0
print('差值{}連續小于{}達到{}次'.format(self.delta_best,self.delta_min,self.times_delta_samller))
#終止回圈條件
def condition_end(self):
if self.times_delta_samller>self.times_delta_min:#如果新舊函式值之差絕對值連續小于某值次數超過某值,終止該溫度回圈
return True
elif self.times_stay>self.times_stay_max:#當連續未接受新解超過這個次數,終止回圈
return True
#在某一特定溫度下進行回圈
def run_T(self):
for time_ in range(self.times_max):
self.x_new=self.get_x_new()#獲得新解
self.f_new=self.func(self.x_new)#獲得新的函式值
self.save_xy()#將新解和函式值記錄下來
self.delta=self.f_new-self.f#計算函式值的變化值
self.judge()#判斷是否接受新解
self.times_cycle+=1#統計回圈次數
self.delta_best=np.abs(self.f-self.f_last)#上次函式值與這次函式值的差值絕對值
self.count_times_delta_smaller()#統計新舊函式值之差的絕對值連續小于此值的次數
if self.condition_end()==True:#如果滿足終止條件,終止該溫度回圈
print('滿足終止條件:接受新解后的函式值變化連續小于{}達到次數'.format(self.delta_min))
break
print('當前歷史最優解{}:{}'.format(self.f_best,self.x_best))#展示當前最優值
print('當前接受的新解{}:{}'.format(self.f, self.x)) # 展示當前接受的新解
print('當前新解{}:{}'.format(self.f_new, self.x_new)) # 展示當前新產生的解
print('當前溫度為{}'.format(self.T))#展示當前溫度
#當每個溫度下的回圈結束時,有一定概率將當前接受的新解替換為歷史最優解
def accept_best_xf(self):
if np.random.random()>0.75:
self.x=self.x_best
self.f=self.f_best
def run(self):
while self.T>self.T_min:
self.run_T()#回圈在該溫度下的求解
self.xf_best_T[self.T] = [self.get_history_best_xy()]#記錄在每一個溫度下的最優解
self.T_change()#溫度繼續下降
self.accept_best_xf()#當每個溫度下的回圈結束時,有一定概率將當前接受的新解替換為歷史最優解
if self.condition_end()==True:#如果滿足終止條件,終止該溫度回圈
break
if __name__=='__main__':
# 待檢測函式1
def func_target(list_x):
x1 = list_x[0]
x2 = list_x[1]
return 3 * (x1 - 5) ** 2 + 6 * (x2 - 6) ** 2 - 7
ng=NG(func=func_target,x0=[8,9])
ng.run()
x,f=ng.get_history_best_xy()#查看歷史最優解
ng.plot_best()#繪制最優解變化程序
這是個一般性的模擬退火演算法類,解決如上所示的二次凸函式最優化非常簡單,但是在解決高度復雜的heston模型時就非常困難了,為了解決heston模型的引數估計,基于以上模型專門寫一個模擬退火演算法子類,該子類的作用主要是將五個引數限制在一定范圍內,因為在引數估計程序中發現部分引數取值過大時會出現 nan 型別的python無法表示的浮點數
randomrange.py
"""某一個數在指定范圍內隨機變動"""
import matplotlib.pyplot as plt
import numpy as np
#將x增加一個隨機變動量,但會把x限制在a,b之內
def random_range(x,a,b):
random=np.random.normal(0,0.01*(b-a),1)[0]
if x+random>b :random=-np.abs(random)#如果新值超越最大值,就將增量變為負數
elif x+random<a:random=np.abs(random)#如果新值超越最小值,就將增量變為正數
return x+random
if __name__=='__main__':
x=0.3;a=0;b=4
sum_False=0
x_all=[]
for i in range(1000):
x=random_range(x,a,b)
x_all.append(x)
print(x)
if x>b or x<a:
sum_False+=1
plt.plot(x_all)
myNG.py
#專門用于求解sv模型引數的退火演算法
class NGSV(NG):
def __init__(self,func,x0):
super().__init__(func,x0)
self.T=90
self.T_min=1e-7#由于演算法耗時太長,故小做一段模擬試試看
self.times_max=500
#sv模型的各個引數由于存在取值范圍,因此在獲得新的引數估計值時需要對其取值范圍加以限制
def get_x_new(self):
"""
[v0,kappa,theta,sigma,rho]
其中:
v0,kappa,theta,sigma>0
-1<rho<1
2kappa*theta>sigma**2
"""
x=copy.deepcopy(self.x)#使用深copy,否則self.x會隨著x一起變動
x[0]=random_range(x[0],0,5)
x[1] =random_range(x[1],0,1)
x[2] =random_range(x[2],0,1)
x[3] =random_range(x[3],0,3)
x[4]=random_range(x[4],-1,1)
return x
利用上面的heston模型定價類和模擬退火演算法類,寫一個利用模擬退火演算法解決heston模型引數估計的類
sv_sa.py
"""使用模擬退火演算法求解期權價格"""
from sv_model import SV
#from sko.SA import SA
import pandas as pd
import numpy as np
from scipy.optimize import minimize
from myNG import NG,NGSV
import copy
#讀取初始資料
# data=pd.read_excel('期權資料.xlsx')
# data_option=data.ix[(data['call_put']=='C')&(data['type_in_out']==4)&(data['type_time']==3)][['exercise_price','time','ETF50','shibor','close']]
#
# data_option.columns=['K','t','s0','r','c']
# data_option.index=range(len(data_option))
# data_option.to_excel('待測驗資料.xlsx')
data_option=pd.read_excel('待測驗資料.xlsx',index_col=0)
data_option=data_option.ix[:100,:]
class SV_SA():
def __init__(self,data,v0:float=0.01,kappa:float=2,theta:float=0.1,sigma:float=0.1,rho:float=-0.5):
"""輸入資料
data -pandas.core.frame.DataFrame格式資料,具體樣式如下:
K t s0 r c
30 2.150 0.194444 2.111919 0.031060 0.0546
31 2.150 0.198413 2.115158 0.031120 0.0666
32 2.150 0.202381 2.107673 0.031210 0.0627
33 2.150 0.214286 2.122269 0.031250 0.0531
90 3.240 0.202381 3.181339 0.047446 0.0724
"""
self.data=data
self.init_params=[v0,kappa,theta,sigma,rho]# 初始引數串列
self.cycle=0#計算模擬退火演算法輪數
self.error=0.000000
def error_mean_percent(self,init_params:list):
"""計算heston模型期權定價的百分比誤差均值
百分比誤差均值=絕對值((理論值-實際值)/實際值)/樣本個數
輸入:
init_params -初始引數,串列格式
[v0,kappa,theta,sigma,rho]
回傳: -誤差百分點數 例如:回傳5,表示5%
"""
v0,kappa,theta,sigma,rho=init_params
list_p_sv=[]
for i in self.data.index:
K,t,s0,r,p_real=self.data.ix[i,:].tolist()
sv = SV(K=K, t=t, s0=s0, r=r,
v0=v0, kappa=kappa, theta=theta, sigma=sigma, rho=rho)
p_sv = sv.sv_Call_Value() # sv模型期權價格
list_p_sv.append(p_sv)
self.error = np.average(np.abs((np.array(list_p_sv) - self.data['c']) / self.data['c']))#sv模型的期權價格和實際價格的百分比誤差均值
print('\n')
print('第{}輪,誤差:{}'.format(self.cycle, self.error))#展示本輪的誤差
self.cycle += 1
return self.error
def error_mean(self,init_params:list):
"""計算heston模型期權定價的均方誤差
init_params -初始引數,串列格式
[v0,kappa,theta,sigma,rho]
"""
v0,kappa,theta,sigma,rho=init_params
list_p_sv=[]
for i in self.data.index:
K,t,s0,r,p_real=self.data.ix[i,:].tolist()
sv = SV(K=K, t=t, s0=s0, r=r,
v0=v0, kappa=kappa, theta=theta, sigma=sigma, rho=rho)
p_sv = sv.sv_Call_Value() # sv模型期權價格
list_p_sv.append(p_sv)
self.error=np.sqrt(np.sum((np.array(list_p_sv)-self.data['c'])**2)/len(self.data))#sv模型的期權價格和實際價格的均方誤差
print('\n')
print('第{}輪,誤差:{}'.format(self.cycle, self.error))#展示本輪的誤差
self.cycle += 1
return self.error
def test_error_mean(self,multiple_parmas:dict):
"""將多組初始引數輸入,計算各組引數的均方誤差
multiple_parmas -dict,多組初始引數
{
1:[0.01,2,0.1,0.1,-0.5],
2:[0.01,2,0.1,0.1,-0.5],
3:[0.01,2,0.1,0.1,-0.5]
}
回傳: -dict,記錄各組初始引數的均方誤差
"""
dict_={}#用于記錄各組初始引數的均方誤差
for i in multiple_parmas.keys():
dict_[i]=self.error_mean(multiple_parmas[i])
return dict_
def test_option_price(self,multiple_parmas:dict):
"""將多組期權資料和初始引數輸入,將期權價格合并在表格旁邊
multiple_parmas -dict,多組初始引數
multiple_parmas={
1:[1.5932492661058346, 3.3803420203705365, 0.3333248435472669, 5.622092726036617, 0.044881506437356666],
2:[1.1070063457234607, 3.501301312245266, 0.6276009140316863, 9.383112611111134, -0.6092511548040354],
3:[0.5675877305927083, 3.736229838972323, 0.21803303626214537, 8.74231319248172, 0.09393882921335006]
}
回傳: -dict,記錄各組初始引數的均方誤差
"""
data_option_=copy.deepcopy(data_option)
for i in multiple_parmas.keys():
#i=3
data_option_['第{}組引數'.format(i)]=0.000000
init_params = multiple_parmas[i]
for j in data_option_.index:
#j=8
option_params=data_option_.ix[j,:4].tolist()
sv=SV(option_params[0],option_params[1],option_params[2],option_params[3],
init_params[0],init_params[1],init_params[2],init_params[3],init_params[4])
c_sv=sv.sv_Call_Value()
data_option_.ix[j,'第{}組引數'.format(i)]=c_sv
print('已經完成第{}組'.format(i))
return data_option_
def sa(self):
"""對均方誤差函式用模擬退火演算法計算最優值
"""
# 實體化演算法,并加入初始解
# opt = minimize(self.error_mean, self.init_params, method='Nelder-Mead', tol=1e-6)#單純形法求最優解
# self.best_params=opt.x
#self.x_star, self.y_star,self.list_,self.info = MySA(self.error_mean, self.init_params)
self.ng=NGSV(func=self.error_mean_percent,x0=self.init_params)
self.ng.run()
self.x_star,self.y_star=self.ng.get_history_best_xy()
print(self.x_star, self.y_star)# 生成最優解x和最優值y
if __name__=='__main__':
model=SV_SA(data=data_option)
model.sa()
model.ng.get_history_best_xy()
所有代碼及資料:
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/200948.html
標籤:其他
上一篇:學習分享——基于深度學習的NILM負荷分解(四)深度學習實作,代碼講解
下一篇:竟然可以這樣學python!!