文章目錄
- 寫在前面
- 一、Beautiful Soup庫入門
- 1.Beautifu Soup的安裝
- 2.Beautifu Soup的基本元素
- 3.基于bs4庫的HTML內容遍歷方法
- 4.基于bs4庫的HTML格式化和編碼
- 二、資訊組織與提取方法
- 1.資訊標記的三種形式
- 2.三種資訊標記形式的比較
- 3.資訊提取的一般方法
- 4.基于bs4庫的HTML內容查找方法
- 三、實體:中國大學排名定向爬蟲
- 參考源自
- 寫在最后
寫在前面
??因為最近在中國大學MOOC網上學習嵩天老師(北京理工大學)的爬蟲課程,所以為了方便自己以后編程時查找相關函式和方法,也為了方便各位小伙伴們學習,整理這篇關于爬蟲中BeautifulSoup庫的基本知識點,本篇涉及圖的地方,我會截取課程內容的截圖(因為我實在是懶得畫圖了),涉及表的地方我會重新制作,一是為了美觀,二是為了加深印象,因為函式和方法太多不常用的話就會遺網,好了,話不多說,開干!
一、Beautiful Soup庫入門
1.Beautifu Soup的安裝
??工欲善其事必先利其器,學習bs4庫的第一步是安裝他,很簡單,首先我們win+R,輸入cmd進入命令列,輸入如下代碼
pip install beautifulsoup4
敲下回車,只需等待片刻即可安裝成功~
Beautiful Soup庫的使用如下:

2.Beautifu Soup的基本元素
(1) Beautiful Soup庫的理解
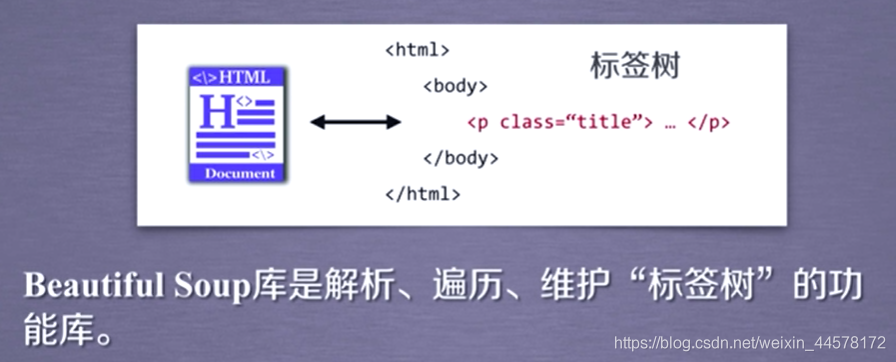

(2)Beautiful Soup類

Beautiful Soup類對應一個HTML/XML檔案的全部內容
(3)Beautiful Soup庫決議器
| 決議器 | 使用方法 | 條件 |
|---|---|---|
| bs4的HTML決議器 | BeautifulSoup(mk,‘html.parser’) | 安裝bs4庫 |
| lxml的HTML決議器 | BeautifulSoup(mk,‘lxml’) | pip install lxml |
| lxml的XML決議器 | BeautifulSoup(mk,‘xml’) | pip install lxml |
| html5lib的決議器 | BeautifulSoup(mk,‘html5lib’) | pip install html5lib |
(4)Beautiful Soup庫的基本元素
| 基本元素 | 說明 |
|---|---|
| Tag | 標簽,最基本的資訊組織單元,分別用<>和</>表明開頭和結尾 |
| Name | 標簽的名字,的名字是’p’,格式:.name |
| Attributes | 標簽的屬性,字典的組織形式,格式:.attrs |
| NavigableString | 標簽內非屬性字串,<>…</>中的字串,格式:.string |
| Comment | 標簽內字串的注釋部分,一種特殊的Comment型別 |
3.基于bs4庫的HTML內容遍歷方法
(1)HTML基本格式
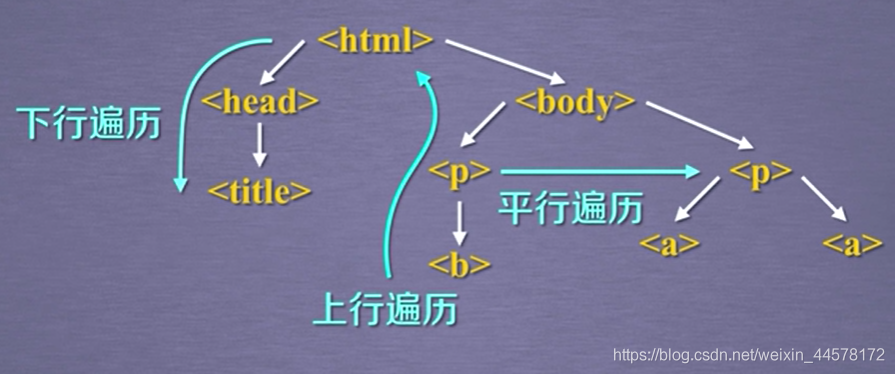
(2)標簽樹的下行遍歷
| 屬性 | 說明 |
|---|---|
| .contents | 子節點串列,將所有兒子節點存入串列 |
| .children | 子節點的迭代型別,與.contents類似,用于回圈遍歷兒子節點 |
| .descendants | 子孫節點的迭代型別,包含所有子孫節點,用于回圈遍歷 |
注:.contents回傳的是串列型別,后兩個回傳的是迭代型別
(3)標簽樹的上行遍歷
| 屬性 | 說明 |
|---|---|
| .parent | 節點的父親標簽 |
| .parents | 節點先輩標簽的迭代型別,用于回圈 遍歷先輩節點 |
(4)標簽樹的平行遍歷
| 屬性 | 說明 |
|---|---|
| .next_sibling | 回傳按照HTML文本順序的下一個平行節點標簽 |
| .previous_sibling | 回傳按照HTML文本順序的上一個平行節點標簽 |
| .next _siblings | 迭代型別,回傳按照HTML文本順序的后續所有平行節點標簽 |
| .previous_siblings | 迭代型別,回傳按照HTML文本順序的前續所有平行節點標簽 |
注:后兩個是迭代型別
4.基于bs4庫的HTML格式化和編碼
(1)格式化
prettify():為html格式的內容和文本增加換行符,也可以對每一個標簽做相關的處理,
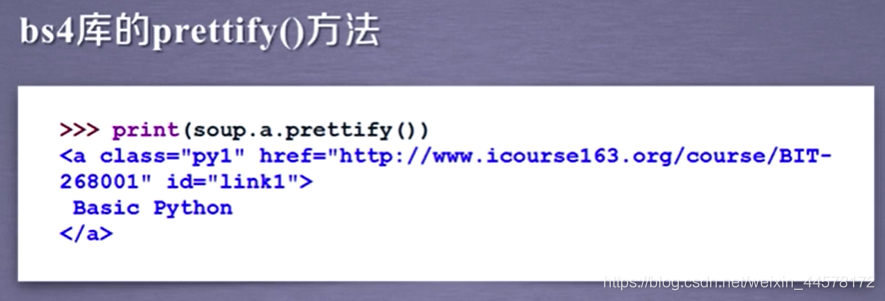
(2)編碼
bs4庫將任何讀入的html檔案或字串都轉換成"UTF-8"編碼
二、資訊組織與提取方法
1.資訊標記的三種形式
資訊的標記

(1)XML


(2)JSON
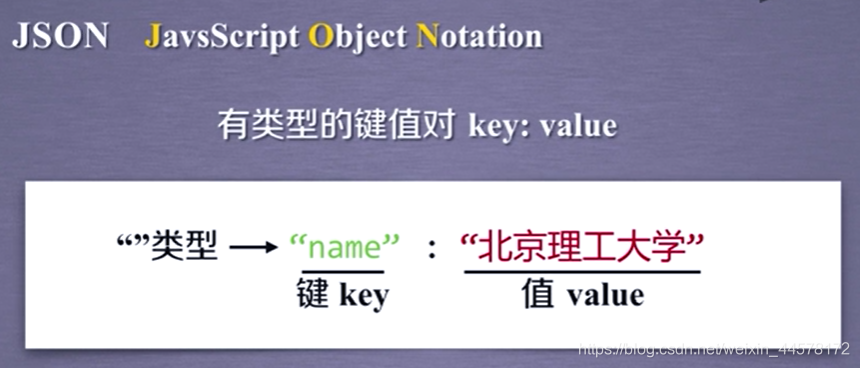
鍵值對之間可以嵌套使用:

(3)YAML

可以用縮進的形式表示所屬關系:

用-(減號)表達并列關系:

|(豎線)表示整塊資料 #表示注釋

2.三種資訊標記形式的比較
| 名稱 | 優缺點 | 作用 |
|---|---|---|
| XML | 最早的通用資訊標記語言,可擴展性好,但是繁瑣 | Internet上的資訊互動與傳遞 |
| JSON | 資訊有型別,適合程式處理,較XML簡潔 | 移動應用云端和節點的資訊通信,無注釋 |
| YAML | 資訊無型別,文本資訊比例最高,可讀性好 | 各類系統組態檔有注釋易讀 |
3.資訊提取的一般方法
(1)完整決議資訊的標記形式,再提取關鍵資訊,XML,JSON,YAML
需要標記決議器,如bs4庫的標簽樹遍歷,優點是資訊決議準確,缺點是提取程序繁瑣
(2)無滑鼠記資訊,直接搜索關鍵資訊,搜索
使用對資訊的文本查找函式即可,優點是提取程序簡潔,速度快,缺點是提取資訊的準確性與資訊內容直接相關,
(3)融合方法:完整形式決議+搜索,提取關鍵資訊,需要標記決議器及文本查找函式,
4.基于bs4庫的HTML內容查找方法
(1)提取HTML所有URL鏈接
思路:搜索到所有a標簽,決議a標簽格式,提取href后的鏈接內容
url = "http://python123.io/ws/demo.html"
r = requests.get(url)
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
for link in soup.find_all('a'):
print(link.get('href'))
--------------out---------------
http://www.icourse163.org/course/BIT-268001
http://www.icourse163.org/course/BIT-1001870001
(2)bs4庫中HTML內容的查找方法:
<>.find_all(self, name=None, attrs={}, recursive=True, text=None, limit=None, **kwargs)
#回傳一個串列型別,存盤查找的結果
name:對標簽名稱的檢索字串
attrs:對標簽屬性值的檢索字串,可標注屬性檢索
recursive:是否對子孫全部搜索,默認為True
string: <>...</>中字串區域的檢索字串
soup.find_all('a')
soup.find_all(['a','b'])
soup.find_all(True) #回傳所有標簽
soup.find_all('p', 'course') #所有屬性是course的p標簽
soup.find_all(id='link1') #查找包含屬性id='link1'的標簽
簡寫形式:
<tag>(..) 等價于 <tag>.find_all(..)
三、實體:中國大學排名定向爬蟲
??這個實體我在博客中有寫過完整的決議,感興趣的小伙伴可以點過去看一下,傳送門送給大家,
鏈接: https://blog.csdn.net/weixin_44578172/article/details/109340255
參考源自
中國大學MOOC Python網路爬蟲與資訊提取
https://www.icourse163.org/course/BIT-1001870001
CSDN博客:
https://blog.csdn.net/songhui1024/article/details/84575575
寫在最后
??本篇屬于整理總結型別文章,如果對你有幫助的話,歡迎收藏喔~
ps:一鍵三連更好啦~
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/205228.html
標籤:其他
上一篇:一個bug引發的人生感悟
下一篇:QT之QUdpSocket學習