前言
我們做演算法的,一定不能成為調包俠,我們每做一個操作,每寫一段代碼都要知道為什么要寫這段代碼,最終要使模型的預測效果可解釋,以前的我年少無知,現已悔改,故有此系類文章,絕不斷更,刷了幾遍面試題的總結和日常見到的一些小問題,加入了自己的理解,不足之處請見諒,
1. 為什么我們要使用資料歸一化及其適用范圍
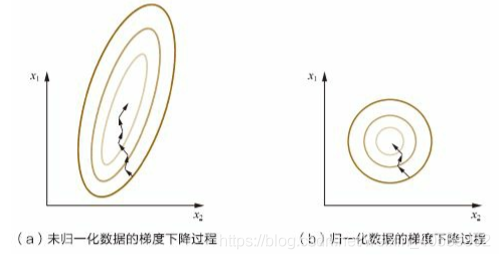
在學習速率相同的情況下,范圍大的特征更新速度會大于范圍小的特征,這樣會導致找到最優解迭代次數增加,
適用范圍:包括線性回歸,邏輯回歸,支持向量機、神經網路,但并不適用于決策樹,為什么呢?因為決策樹每次選擇特征只考慮一個變數,不考慮變數之間的相關性,
注:很多學生搞不清楚正則化,標準化和歸一化的區別,簡單說一下:
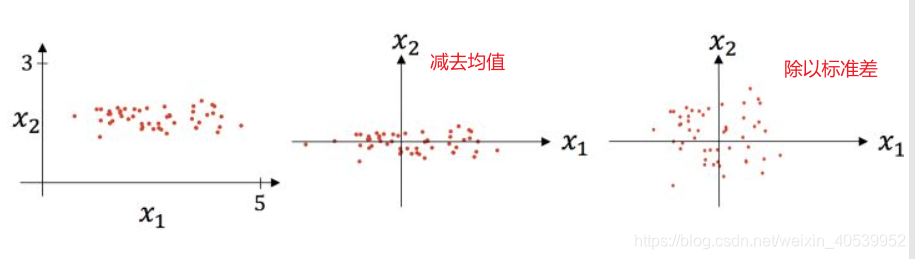
歸一化:將資料都縮放到[0-1]區間內,防止量綱不同導致部分特征起主導作用,如上文解釋,加快模型收斂速度,但是歸一化對例外點較為敏感,適用于小樣本,大樣本上效果不如標準化,
標準化:最常見的是Z-Score標準化,標準化也可以做成歸一化,但其不是為了方便與其他資料進行比較,它是為了方便下一步處理,比如使用標準化將資料化為標準正態分布進行處理,這樣同樣可以加快模型收斂速度,舉個栗子,BN就是通過一定的規范化手段,把每層神經網路任意神經元這個輸入值的分布強行拉回到均值為0方差為1的標準正態分布,從而加快神經網路的訓練速度,
正則化:加入正則項防止模型過擬合,常見的有正則項有 L1 正則 和 L2 正則 以及 Dropout ,其中 L2 正則 的控制過擬合的效果比 L1 正則 的好,
###################歸一化
data = np.random.uniform(0, 100, 10)[:, np.newaxis]
mm = MinMaxScaler()
mm_data = mm.fit_transform(data)
origin_data = mm.inverse_transform(mm_data)
print('data is ',data)
print('after Min Max ',mm_data)
print('origin data is ',origin_data)
###################標準化
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
x = iris.data
y = iris.target
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=666)
#sklearn處理歸一化的模塊
from sklearn.preprocessing import StandardScaler
stand = StandardScaler()
stand.fit(x_train)
# 注意使用train的均值和方差進行test的標準化
x_train = stand.transform(x_train)
x_test = stand.transform(x_test)
#現在就是處理好的資料,可以拿來直接用
###################正則化
#注意以下的操作不是很多,大多都是在模型訓練時候添加penalty引數,
x = np.array([[1.,-1.,2.],
[2.,0.,0.],
[0.,1.,-1.]])
x_normalized = preprocessing.normalize(x,norm='l2')
print(x_normalized)
# 可以使用processing.Normalizer()類實作對訓練集和測驗集的擬合和轉換
normalizer = preprocessing.Normalizer().fit(x)
print(normalizer)
normalizer.transform(x)
推薦閱讀:一些其他的標準化和正則化的手段,模型中的正則化,
2. 如何處理類別特征
序號編碼、獨熱編碼、二進制編碼(維數大大少于獨熱編碼)
##############序號編碼
import numpy as np
import sklearn.preprocessing as sp
# 準備資料
raw_samples = np.array(["audi", "ford", "audi", "toyota",
"ford", "bmw", "ford", "redflag", "audi"])
print(raw_samples)
# 訓練之前 需要標簽編碼
lbe = sp.LabelEncoder()
result = lbe.fit_transform(raw_samples)
print("-----編碼后\n", result)
# 編碼 反向推導
test = [0, 0, 1, 1, 4]
print("-----編碼反推\n", lbe.inverse_transform(test))
##############OneHot編碼
import numpy as np
import sklearn.preprocessing as sp
samples = np.array([
[1, 3, 2],
[7, 5, 4],
[1, 8, 6],
[7, 3, 9]
])
# 獨熱編碼 sparse 是否采用稀疏矩陣
ohe = sp.OneHotEncoder(sparse=False, dtype="int32")
result = ohe.fit_transform(samples)
# 00列對1和7進行獨熱編碼 2位,01列 3位,02列4位
print(result)
3. 如何尋找組合特征
使用決策樹進行特征組合,每一條從根節點到葉子節點的路徑都可以看作一種特征組合的方式,決策樹如何構建呢,常見的梯度決策樹的辦法都可以,例如

1-4就是特征,我們給定一條樣本,就可以產生一個組合特征表示[1,1,1,0]表示符合1,2,3條件,
#coding:utf-8
############ 組合特征實戰小栗子
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn.tree import DecisionTreeClassifier
def iris_type(s):
it={'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2}
return it[s]
iris_feature = u'花萼長度', u'花萼寬度', u'花瓣長度', u'花瓣寬度'
if __name__ == "__main__":
mpl.rcParams['font.sans-serif']=[u'SimHei'] #黑體 FangSong/KaiTi
mpl.rcParams['axes.unicode_minus']=False
path = '10.iris.data'
#加載資料 converters={4:iris_type} 將第四列資料替換成iris_type函式回傳的值
data=np.loadtxt(path,dtype=float,delimiter=',',converters={4:iris_type})
#前4列是特征向量 賦給x_prime,最后一列標簽列賦給y
x_prime,y=np.split(data,(4,),axis=1)
#(0,1)表示取第0列和第1列,以此類推,交叉抽取特征列
# 這是組合特征的重點!!!!!!
feature_pairs=[(0, 1), (0, 2), (0, 3), (1, 2), (1, 3), (2, 3)]
plt.figure(figsize=(10,9),facecolor='#FFFFFF')
for i,pair in enumerate(feature_pairs):
#準備資料
x=x_prime[:,pair]
#決策樹學習 criterion表示特征選擇標準,可以是gini,entropy 即gini系數,資訊增益
#min_samples_leaf 葉子節點最少樣本數
clf=DecisionTreeClassifier(criterion='entropy',min_samples_leaf=3)
#根據 feature_pairs中不同列的組合來訓練模型
dt_clf=clf.fit(x,y)
#畫圖
N,M=500,500 #縱橫各采樣多少個值
x1_min,x1_max=x[:,0].min(),x[:,0].max() #第0列的范圍
x2_min,x2_max=x[:,1].min(),x[:,1].max() #第1列的范圍
t1=np.linspace(x1_min,x1_max,N) #構造500 個從x1_min到x1_max之間的等引數列
t2=np.linspace(x2_min,x2_max,M)
x1,x2=np.meshgrid(t1,t2)#生成網格采樣點
x_test=np.stack((x1.flat,x2.flat),axis=1) #測驗點
#訓練集上的預測結果
y_hat=dt_clf.predict(x)
y=y.reshape(-1)
c=np.count_nonzero(y_hat==y)#統計預測正確的個數
print '特征: ', iris_feature[pair[0]], ' + ', iris_feature[pair[1]],
print '\t預測正確數目:', c,
print '\t準確率: %.2f%%' % (100 * float(c) / float(len(y)))
#顯示
cm_light=mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark=mpl.colors.ListedColormap(['g','r','b'])
y_hat=dt_clf.predict(x_test) #預測值
y_hat=y_hat.reshape(x1.shape)#使之與輸入的形狀相同
plt.subplot(2, 3, i + 1)
plt.pcolormesh(x1, x2, y_hat, cmap=cm_light) # 預測值
plt.scatter(x[:, 0], x[:, 1], c=y, edgecolors='k', cmap=cm_dark) # 樣本
plt.xlabel(iris_feature[pair[0]], fontsize=14)
plt.ylabel(iris_feature[pair[1]], fontsize=14)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid()
plt.suptitle(u'決策樹對鳶尾花資料的兩特征組合的分類結果', fontsize=18)
plt.tight_layout(2)
plt.subplots_adjust(top=0.92)
plt.show()
4. 有哪些文本表示模型,各有什么優缺點,
TF-IDF:沒有考慮語意,單純的將文本進行split
主題模型:例如LDA,主流前沿的LDA都在實行大規模并行化,LDA的一些發展
Embedding:將稀疏向量映射到一個Dense Vector中,(包括Word2Vec和LDA)
###########TF-IDF實作
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
x_train = ['TF-IDF 主要 思想 是','演算法 一個 重要 特點 可以 脫離 語料庫 背景',
'如果 一個 網頁 被 很多 其他 網頁 鏈接 說明 網頁 重要']
x_test=['原始 文本 進行 標記','主要 思想']
#該類會將文本中的詞語轉換為詞頻矩陣,矩陣元素a[i][j] 表示j詞在i類文本下的詞頻
vectorizer = CountVectorizer(max_features=10)
#該類會統計每個詞語的tf-idf權值
tf_idf_transformer = TfidfTransformer()
#將文本轉為詞頻矩陣并計算tf-idf
tf_idf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(x_train))
#將tf-idf矩陣抽取出來,元素a[i][j]表示j詞在i類文本中的tf-idf權重
x_train_weight = tf_idf.toarray()
#對測驗集進行tf-idf權重計算
tf_idf = tf_idf_transformer.transform(vectorizer.transform(x_test))
x_test_weight = tf_idf.toarray() # 測驗集TF-IDF權重矩陣
print('輸出x_train文本向量:')
print(x_train_weight)
print('輸出x_test文本向量:')
print(x_test_weight)
推薦閱讀::TF-IDF的實作;
5. 常見的Word2Vec及其與LDA的聯系
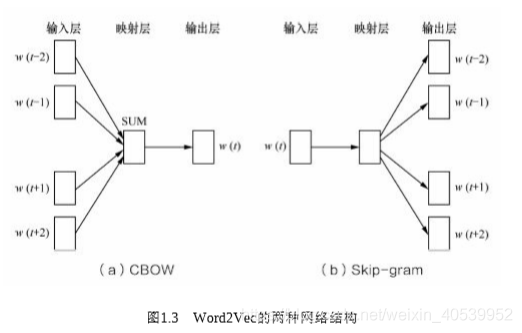
CBOW和Skip-Gram是常見的Word2Vec的兩種結構,簡單來說前者是根據背景關系預測單詞,后者是根據單詞預測背景關系,大家有沒有發現這玩意和神經網路特別像,輸入的都是Embedding后的單詞,前者取argmax,后者取SoftMax,
LDA和Word2Vec的聯系和區別:前者是根據檔案-單詞矩陣進行分解,得到檔案-主題矩陣和主題-單詞矩陣,后者是根據背景關系的單詞進行學習,前者是基于概率圖模型的生成模型,后者是基于神經網路學習權重得到單詞的稠密向量表示,(其實Embedding層現在已經封裝好了,但還是建議看一下,)
推薦學習:Word2Vec實作;Word2Vec數學推導;LDA實戰
6. 如何緩解資料訓練樣本不足的問題
問題:過擬合問題
解決辦法:基于模型的就是簡化模型,例如非線性轉換成線性,添加約束項,集成學習,Dropout,基于資料的就是資料擴充(旋轉,平移,縮放,裁剪,填充,左右翻轉,這玩意已經被封裝在Tensorflow的ImageDataGenerator中了,注意只對訓練資料實行資料擴充哈),加入噪聲,顏色變化,改變影像亮度和對比度,最新的資料擴充目前看到一個WSDAN,還有基于遷移學習的方法,具體有王大佬的知乎可以參考,王大佬,
當然了,這里要注意ImageDataGenerator,每次輸入的都是一個iter,當資料回圈完畢后,迭代下一個iter的時候會進行資料轉換/增強,
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
import matplotlib.pyplot as plt
#第一步:對測驗資料和訓練資料分別構造一個ImageDataGenerator物件
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
推薦學習:CNN分類實戰;實戰Tensorflow; 斯嘉麗資料增強
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/206850.html
標籤:其他
上一篇:漫談壓力測驗