序言
map 是go 中一種很重要的 映射查找的資料結構,通過 key 的hash 運算來找到 值,這在各個語言中都不少見,這篇我們主要講go map 的使用和其內部實作,
正文
map的使用
關于 map的使用問題, 如下
map的宣告為
/* 宣告變數,默認 map 是 nil */ var map_variable map[key_data_type]value_data_type /* 使用 make 函式 */ map_variable := make(map[key_data_type]value_data_type) |
沒有初始化的map不能進行插入操作,需要用make 函式進行初始化后才能進行操作,
map 的簡單函式操作,curd為
var emptyMap map[string]int
var initMap = make(map[string]int)
//emptyMap["ok"]=1
initMap["init"] = 2
initMap["ok"] = 4
delete(initMap, "init")
for k, v := range initMap {
fmt.Printf("%v ,%v\n", k, v)
}
_,texist := initMap["fine"]
fmt.Printf("exists find key is %v\n",texist)
fmt.Printf("%v ,%v,not init map is nil %v \n", emptyMap, initMap, emptyMap == nil) |
輸出情況為
[1 ok [2 3 4]] ok ,4 exists find key is false map[] ,map[ok:4],not init map is nil true |
map的操作都很簡單,在這里不講了,
值得注意的是,這里的map 是非執行緒安全的,如果需要執行緒安全的map ,需要使用 sync.Map 或者自己用 sync.RWMute 自己來做鎖保護,
map 的實作結構
通過搜索 hmap 的結構定義,我們在 reflect 中找到 hmap的定義,這個也就是 go 中map的實際記憶體結構定義, 在 runtime\map.go 中能找到相關定義
// A header for a Go map.
const ( // 關鍵的變數
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits // 一個桶最多存盤8個key-value對
loadFactorNum = 13 // 擴散因子:loadFactorNum / loadFactorDen = 6.5,
loadFactorDen = 2 // 即元素數量 >= (hash桶數量(2^hmp.B) * 6.5 / 8) 時,觸發擴容
)
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8 // 記錄幾個特殊的位標記,如當前是否有別的執行緒正在寫map、當前是否為相同大小的增長(擴容/縮容?)
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // 指向2^B個桶組成的陣列的指標,資料存在這里
oldbuckets unsafe.Pointer // 指向擴容前的舊buckets陣列,只在map增長時有效
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // 保存溢位桶的鏈表和未使用的溢位桶陣列的首地址
}
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and elem do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap // 為溢位的桶保留鏈表
}
// A bucket for a Go map.
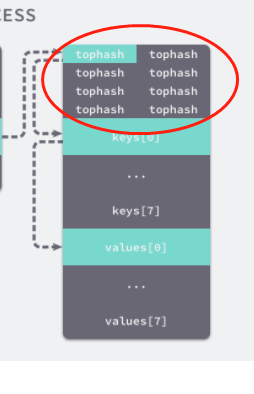
type bmap struct {
// tophash存盤桶內每個key的hash值的高位元組
// tophash[0] < minTopHash表示桶的疏散狀態
// 當前版本bucketCnt的值是8,一個桶最多存盤8個key-value對
tophash [bucketCnt]uint8
// 特別注意:
// 實際分配記憶體時會申請一個更大的記憶體空間A,A的前8位元組為bmap
// 后面依次跟8個key、8個value、1個溢位指標
// map的桶結構實際指的是記憶體空間A
}
|
可以看到 map的定義相比 slice 實在是復雜不少,我們盯著其中一點來寫,map的實作結構無非就是桶機制,我們看看它的桶是怎么實作的,給一張圖
具體點 bmap 容器的記憶體結構應該是這樣
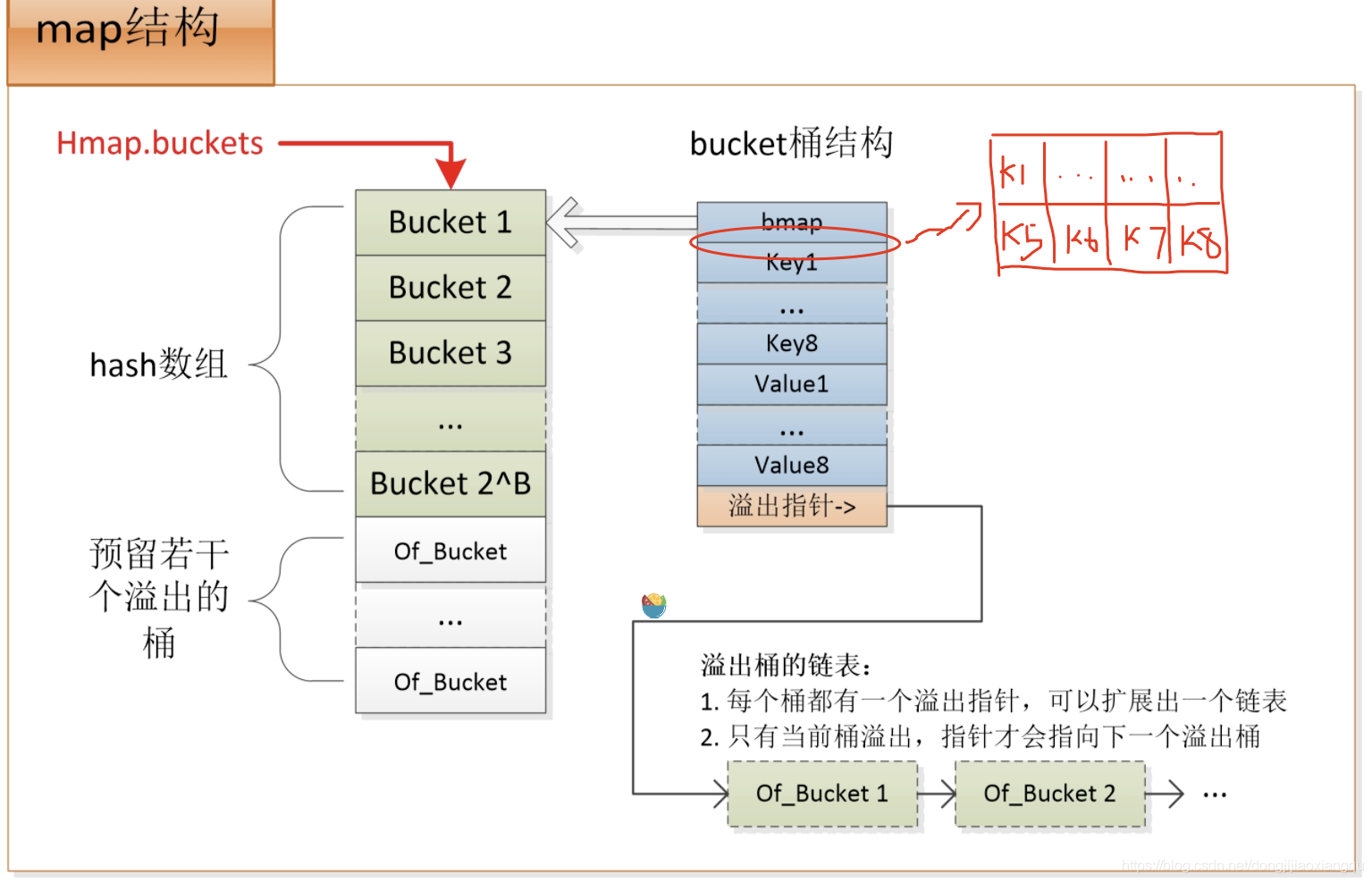
我們簡單看下, 通過 key 獲取值的流程
附上原始碼
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapaccess1)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if t.key.equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
|
核心在那個for 回圈取值那,簡單而言就是
- 取得 hash 運算的 值 x, 通過 x 的低8位找到對應的bucket 桶號,
- 然后獲得 x的高8位 ,依次和 bucket 里面的8個 高位key 做對比, 如果沒找到匹配,然后和這個bucket 的溢位桶做對比,同樣的流程,
- 如果找到高8位相同,通過 指標運算直接找到 bucket那個key記憶體位置的值, 對比 bucket 中的key 和 輸入的key值,如果相等那就算找到,如果不等,還得重復這個流程繼續找,
emptyResult 表示 高8位沒有賦值,也就是這個 bucket之后 里面的某些key 和 value還沒有塞入值,
map 的初始化
使用make(map[k]v, hint)創建map時會呼叫makemap()函式,代碼邏輯比較簡單,
值得注意的是,makemap()創建的hash陣列,陣列的前面是hash表的空間,當hint >= 4時后面會追加2^(hint-4)個桶,之后再記憶體頁幀對齊又追加了若干個桶(參見2.2章節結構圖的hash陣列部分)
所以創建map時一次記憶體分配既分配了用戶預期大小的hash陣列,又追加了一定量的預留的溢位桶,還做了記憶體對齊,一舉多得,
// make(map[k]v, hint), hint即預分配大小
// 不傳hint時,如用new創建個預設容量為0的map時,makemap只初始化hmap結構,不分配hash陣列
func makemap(t *maptype, hint int, h *hmap) *hmap {
// 省略部分代碼
// 隨機hash種子
h.hash0 = fastrand()
// 2^h.B 為大于hint*6.5(擴容因子)的最小的2的冪
B := uint8(0)
// overLoadFactor(hint, B)只有一行代碼:return hint > bucketCnt && uintptr(hint) > loadFactorNum*(bucketShift(B)/loadFactorDen)
// 即B的大小應滿足 hint <= (2^B) * 6.5
// 一個桶能存8對key-value,所以這就表示B的初始值是保證這個map不需要擴容即可存下hint個元素對的最小的B值
for overLoadFactor(hint, B) {
B++
}
h.B = B
// 這里分配hash陣列
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// makeBucketArray()會在hash陣列后面預分配一些溢位桶,
// h.extra.nextOverflow用來保存上述溢位桶的首地址
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
// 分配hash陣列
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b) // base代表用戶預期的桶的數量,即hash陣列的真實大小
nbuckets := base // nbuckets表示實際分配的桶的數量,>= base,這就可能會追加一些溢位桶作為溢位的預留
if b >= 4 {
// 這里追加一定數量的桶,并做記憶體對齊
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
// 后面的代碼就是申請記憶體空間了,此處省略
// 這里大家可以思考下這個陣列空間要怎么分配,其實就是n*sizeof(桶),所以:
// 每個桶前面是8位元組的tophash陣列,然后是8個key,再是8個value,最后放一個溢位指標
// sizeof(桶) = 8 + 8*sizeof(key) + 8*sizeof(value) + 8
return buckets, nextOverflow
} |
寫入值和擴容
插入
- 引數合法性檢測,計算hash值
unc mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// 不熟悉指標操作的同學,用指標傳參往往會踩空指標的坑
// 這里大家可以思考下,為什么h要非空判斷?
// 如果一定要在這里支持空map并檢測到map為空時自動初始化,應該怎么寫?
// 提示:指標的指標
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// 在這里做并發判斷,檢測到并發寫時,拋例外
// 注意:go map的并發檢測是偽檢測,并不保證所有的并發都會被檢測出來,而且這玩意是在運行期檢測,
// 所以對map有并發要求時,應使用sync.map來代替普通map,通過加鎖來阻斷并發沖突
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
hash := alg.hash(key, uintptr(h.hash0)) // 這里得到uint32的hash值
h.flags ^= hashWriting // 置Writing標志,key寫入buckets后才會清除標志
if h.buckets == nil { // map不能為空,但hash陣列可以初始是空的,這里會初始化
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
... |
2. 定位key在hash表中的位置
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
again:
bucket := hash & bucketMask(h.B) // 這里用hash值的低階位定位hash陣列的下標偏移量
if h.growing() {
growWork(t, h, bucket) // 這里是map的擴容縮容操作,我們在第4章單獨講
}
// 通過下標bucket,偏移定位到具體的桶
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash) // 這里取高8位用于在桶內定位鍵值對
...
} |
3. 進一步定位key可以插入的桶及桶中的位置
- 兩輪回圈,外層回圈遍歷hash桶及其指向的溢位鏈表,內層回圈則在桶內遍歷(一個桶最多8個key-value對)
- 有可能正好鏈表上的桶都滿了,這時inserti為nil,第4步會鏈接一個新的溢位桶進來
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
var inserti *uint8 // tophash插入位置
var insertk unsafe.Pointer // key插入位置
var val unsafe.Pointer // value插入位置
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
// 找到個空位,先記錄下tophash、key、value的插入位置
// 但要遍歷完才能確定要不要插入到這個位置,因為后面有可能有重復的元素
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
if b.tophash[i] == emptyRest {
break bucketloop // 遍歷完整個溢位鏈表,退出回圈
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if !alg.equal(key, k) {
continue
}
// 走到這里說明map里找到一個重復的key,更新key-value,跳到第5步
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done // 更新Key后跳到第5步
}
ovf := b.overflow(t)
if ovf == nil {
break // 遍歷完整個溢位鏈表,沒找到能插入的空位,結束回圈,下一步再追加一個溢位桶進來
}
b = ovf // 繼續遍歷下一個溢位桶
}
...
} |
4. 插入key
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
// 擴容相關
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
if inserti == nil { // inserti == nil說明上1步沒找到空位,整個鏈表是滿的,這里添加一個新的溢位桶上去
newb := h.newoverflow(t, b) // 分配新溢位桶,優先用3.1章節預留的溢位桶,用完了則分配一個新桶記憶體
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
// 當key或value的型別大小超過一定值時,桶只存盤key或value的指標,這里分配空間并取指標
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectvalue() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(val) = vmem
}
typedmemmove(t.key, insertk, key) // 在桶中對應位置插入key
*inserti = top // 插入tophash,hash值高8位
h.count++ // 插入了新的鍵值對,h.count數量+1
...
} |
5. 結束插入
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting // 釋放hashWriting標志位
if t.indirectvalue() {
val = *((*unsafe.Pointer)(val))
}
return val // 回傳value可插入位置的指標,注意,value還沒插入
} |
mapassign()只插入tophash和key,并回傳val指標,編譯器會在呼叫mapassign()后用匯編往val插入value
擴容
關于擴容相關代碼在 mapassign 那里
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
...
}
// overLoadFactor()回傳true則觸發擴容,即map的count大于hash桶數量(2^B)*6.5
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
// tooManyOverflowBuckets(),顧名思義,溢位桶太多了觸發縮容
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
} |
解釋:
map只在插入元素即mapassign()函式中對是否擴容縮容進行觸發,條件即是上面這段代碼:
- 條件1:當前不處在growing狀態
- 條件2-1:觸發擴容:map的資料量count大于hash桶數量(2B)*6.5,注意這里的(2B)只是hash陣列大小,不包括溢位的桶
- 條件2-2:觸發縮容:溢位的桶數量noverflow>=32768(1<<15)或者>=hash陣列大小,
map 縮容是偽縮容
現在可以解釋為什么我把map的縮容叫做偽縮容了:因為縮容僅僅針對溢位桶太多的情況,觸發縮容時hash陣列的大小不變,即hash陣列所占用的空間只增不減,
也就是說,如果我們把一個已經增長到很大的map的元素挨個全部洗掉掉,hash表所占用的記憶體空間也不會被釋放,
所以如果要實作“真縮容”,需自己實作縮容搬遷,即創建一個較小的map,將需要縮容的map的元素挨個搬遷過來:
// go map縮容代碼示例
myMap := make(map[int]int, 1000000)
// 假設這里我們對bigMap做了很多次插入,之后又做了很多次洗掉,此時bigMap的元素數量遠小于hash表大小
// 接下來我們開始縮容
smallMap := make(map[int]int, len(myMap))
for k, v := range myMap {
smallMap[k] = v
}
myMap = smallMap // 縮容完成,原來的map被我們丟棄,交給gc去清理 |
洗掉元素操作
代碼為
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
...
b.tophash[i] = emptyOne // 先標記洗掉
// 如果b.tophash[i]不是最后一個元素,則暫時先占著坑,emptyOne標記的位置暫時不能被插入新元素(見3.2章節插入函式)
if i == bucketCnt-1 {
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
if b.tophash[i+1] != emptyRest {
goto notLast
}
}
for { // 如果b.tophash[i]是最后一個元素,則把末尾的emptyOne全部清除置為emptyRest
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break // beginning of initial bucket, we're done.
}
// Find previous bucket, continue at its last entry.
c := b
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}
...
} |
洗掉與插入類似,前面的步驟都是引數和狀態判斷、定位key-value位置,然后clear對應的記憶體,不展開說,以下是幾個關鍵點:
- 洗掉程序中也會置hashWriting標志
- 當key/value過大時,hash表里存盤的是指標,這時候用軟洗掉,置指標為nil,資料交給gc去刪,當然,這是map的內部處理,外層是無感知的,拿到的都是值拷貝
- 無論Key/value是值型別還是指標型別,洗掉操作都只影響hash表,外層已經拿到的資料不受影響,尤其是指標型別,外層的指標還能繼續使用
由于定位key位置的方式是查找tophash,所以洗掉操作對tophash的處理是關鍵:
- map首先將對應位置的tophash[i]置為emptyOne,表示該位置已被洗掉
- 如果tophash[i]不是整個鏈表的最后一個,則只置emptyOne標志,該位置被洗掉但未釋放,后續插入操作不能使用此位置
- 如果tophash[i]是鏈表最后一個有效節點了,則把鏈表最后面的所有標志為emptyOne的位置,都置為emptyRest,置為emptyRest的位置可以在后續的插入操作中被使用,
- 這種洗掉方式,以少量空間來避免桶鏈表和桶內的資料移動,事實上,go 資料一旦被插入到桶的確切位置,map是不會再移動該資料在桶中的位置了,
總結
Go 語言使用拉鏈法來解決哈希碰撞的問題實作了哈希表,它的訪問、寫入和洗掉等操作都在編譯期間轉換成了運行時的函式或者方法,
map 底層是hash實作,資料結構為hash陣列 + 桶 + 溢位的桶鏈表,每個桶存盤最多8個key-value對
查找和插入的原理:key的hash值(低階位)與桶數量相與,得到key所在的hash桶,再用key的高8位與桶中的tophash[i]對比,相同則進一步對比key值,key值相等則找到
go map不支持并發,插入、洗掉、搬遷等操作會置writing標志,檢測到并發直接panic
每次擴容hash表增大1倍,hash表只增不減
支持有限縮容,delete操作只置洗掉標志位,釋放溢位桶的空間依靠觸發縮容來實作,
map在使用前必須初始化,否則panic:已初始化的map是make(map[key]value)或make(map[key]value, hint)這兩種形式,而new或var xxx map[key]value這兩種形式是未初始化的,直接使用會panic,
go采用的hash演算法應是很成熟的演算法,極端情況暫不考慮,所以綜合情況下go map的時間復雜度應為O(1)
空間復雜度分析:
首先我們不考慮因洗掉大量元素導致的空間浪費情況(這種情況現在go是留給程式員自己解決),只考慮一個持續增長狀態的map的一個空間使用率:
由于溢位桶數量超過hash桶數量時會觸發縮容,所以最壞的情況是資料被集中在一條鏈上,hash表基本是空的,這時空間浪費O(n),
最好的情況下,資料均勻散列在hash表上,沒有元素溢位,這時最好的空間復雜度就是擴散因子決定了,當前go的擴散因子由全域變數決定,即loadFactorNum/loadFactorDen = 6.5,即平均每個hash桶被分配到6.5個元素以上時,開始擴容,所以最小的空間浪費是(8-6.5)/8 = 0.1875,即O(0.1875n)
結論:go map的空間復雜度(指除去正常存盤元素所需空間之外的空間浪費)是O(0.1875n) ~ O(n)之間,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/215337.html
標籤:其他