前言:學習本章前先閱讀之前我寫的關于JVM系列的前兩篇文章:
JVM類加載機制深入淺出分析--JVM系列(1)
JVM記憶體模型--JVM系列(2)
一.聊聊物件創建主要流程
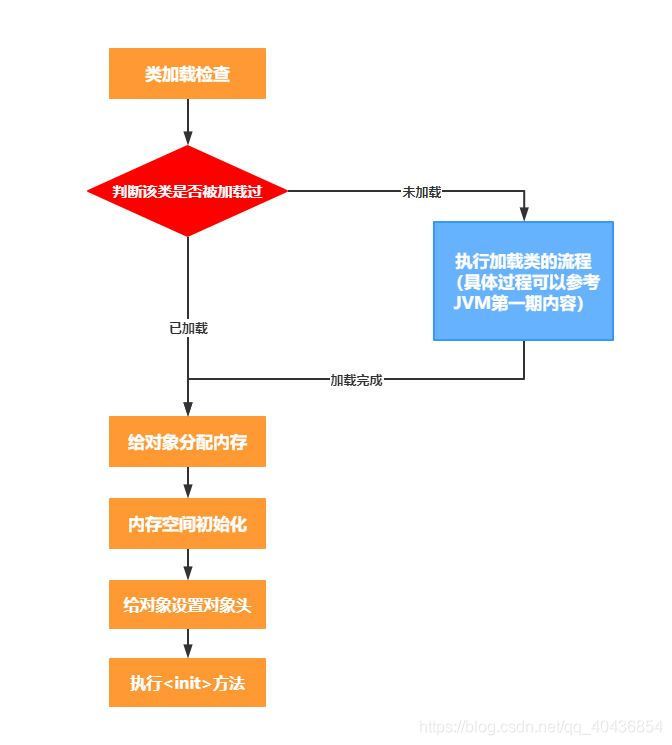
1.類加載檢查:
當JVM遇到一條創建物件的指令時(例如:利用反射創建物件、呼叫new陳述句創建物件、呼叫物件的clone方法創建物件、利用反序列法手段創建物件),首先會去檢查該指令的引數能否在常量池中定位到該物件對應的類的符號參考,并且會去檢查這個符號參考代表的類是否已經被加載、驗證、決議和初始化,假如沒有加載則會先執行相應的類加載程序,
2.給物件分配記憶體:
通過類加載檢查后,物件的所需要的記憶體的大小就確定了,JVM將會給新的物件分配記憶體,給物件分配記憶體空間的程序就是在Java堆中劃分一塊物件所需大小的空間給物件,
這里就會有小伙伴A問怎么劃分記憶體的呢?這里就涉及到記憶體劃分的兩種方式:
(1)指標碰撞法(Bump the Pointer):默認使用這種方法,該方法適合Java堆中記憶體規整的情況,也就是已經被用的記憶體都在一邊,而還沒有用的記憶體都在另一邊,指標就放在其中間作為這兩個磁區的分界指示器(相當于工具人),那么當下一次要分配記憶體空間時,這個指標(工具指標)就會被無情的挪動一段距離(這個距離大小等于物件所需記憶體的大小),
這里又會有小伙伴B問,假如遇到并發的場景,執行緒1利用指標碰撞法給一個物件分配記憶體完畢但指標還沒開始偏移,這時執行緒2進來給另一個物件分配記憶體正好用到了還未來得及偏移的指標咋個辦?
針對于這種并發問題也有兩種解決方法:
- CAS(Compare And Swap):JVM應用 CAS + 失敗重試的機制對分配記憶體空間的動作做同步,來確保更新動作的原子性,
- 本地執行緒分配緩沖(TLAB):給每個執行緒在Java堆中預先分配一小塊記憶體空間,而記憶體分配的動作就可以在每個執行緒自己的記憶體空間中進行,設定JVM使用TLAB(默認會開啟)可以通過設定引數-XX:+UseTLAB,指定TLAB大小使用引數-XX:TLABSize,
(2)空閑串列(Free List):這種方法可以說是指標碰撞法的補充,針對于Java堆記憶體不規整、有記憶體碎片的情況(已用記憶體和未用的記憶體相互混雜),對于這種情況顯然指標碰撞沒辦法處理了,故此時空閑串列(工具表)就來了,空閑表由JVM負責維護,主要用于記錄了堆中可用的記憶體地址,當要給物件分配記憶體的時候就會從空閑串列中找到一塊足夠大的空間給物件實體,同時更新空閑串列上的記錄,
3.記憶體空間初始化:
記憶體分配完畢后,JVM需要將分配到的記憶體空間都初始化為零值(這里的初始化是設定最原始的默認值,而非指定的初始值,同時這個初始化不包括物件頭),如果使用的是TLAB,這一作業程序也可以提前至TLAB分配時進行,這一步操作保證了物件的實體欄位在Java代碼中可以不賦初始值就可以直接使用,程式能訪問到這些欄位資料型別對應的默認值,
4.設定物件頭:
既然說到了物件頭,那就有必要聊一聊一個物件在記憶體中的結構了,在HotSpot虛擬機中,一個物件在記憶體中的存盤結構主要分為3個區域,如下圖所示:
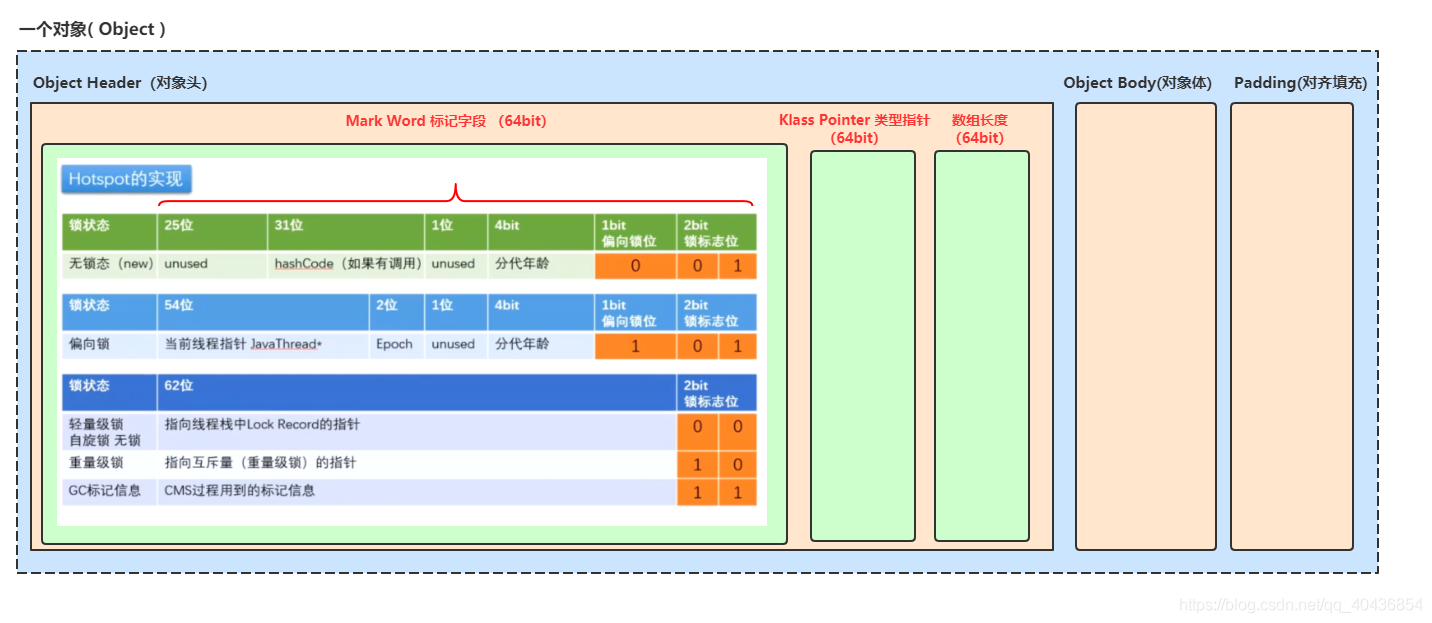
Object Header(物件頭):物件頭又包含三個部分 ——
- Mark Word(標記欄位)(這里是64位占8個位元組,如果是32位物件頭就占4個位元組)—— 講人話就是自身運行時資料:比如鎖狀態,哈希值,GC分代年齡,當前執行緒指標,偏向鎖的時間戳(Epoch),細節點:圖中可以看出GC分代年齡為4bit,這也是為什么minor GC(young GC)默認為15歲的原因,
- Klass Pointer(型別指標)(為了節省空間64位的JVM默認開啟指標壓縮占4個位元組,不開啟壓縮占8個位元組)—— 就是指向方法區中的類元資料的指標,這樣該物件可隨時知道自己是哪個Class的實體,
- 陣列長度(注意點:這部分只有陣列物件才有,同時在64位JVM中原本也是占8個位元組,但是默認會開啟指標壓縮,所以只會占4個位元組)
Object Body(物件體):物件體是用于保存物件屬性和值的主體部分,占用記憶體空間取決于物件的屬性數量和型別,
Padding(位元組對齊):在64位作業系統中保證物件是8個位元組的整數倍,對于大部分處理器,物件以8位元組整數倍來對齊填充都是最高效的存取方式,位元組對齊深層次原因是:各個硬體平臺對存盤空間的處理上有很大的不同,一些平臺對某些特定型別的資料只能從某些特定地址開始存取,比如有些架構的CPU在訪問一個沒有進行對齊的變數的時候會發生錯誤,那么在這種架構下編程必須保證位元組對齊.其他平臺可能沒有這種情況,但是最常見的是如果不按照適合其平臺要求對資料存放進行對齊,會在存取效率上帶來損失,比如有些平臺每次讀都是從偶地址開始,如果一個int型(假設為32位系統)如果存放在偶地址開始的地方,那么一個讀周期就可以讀出這32bit,而如果存放在奇地址開始的地方,就需要2個讀周期,并對兩次讀出的結果的高低位元組進行拼湊才能得到該32bit資料,顯然在讀取效率上下降很多,
5.執行<init>方法:
執行<init>方法,就是物件按照開發者的設定的初始值進行初始化,也就是為屬性賦值,然后執行構造方法,
二.聊聊物件大小與指標壓縮
怎么查看物件大小呢?博主這里推薦一款查看物件大小的神器 —— jol-core包
引入依賴:
<!-- 物件大小可以用jol-core包查看-->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>測驗代碼:
public class JOLTest {
public static void main(String[] args) {
ClassLayout layout1 = ClassLayout.parseInstance(new int[]{});
System.out.println(layout1.toPrintable());
ClassLayout layout2 = ClassLayout.parseInstance(new Object());
System.out.println(layout2.toPrintable());
ClassLayout layout3 = ClassLayout.parseInstance(new User());
System.out.println(layout3.toPrintable());
}
// -XX:+UseCompressedOops 默認開啟的壓縮所有指標
// -XX:+UseCompressedClassPointers 默認開啟的壓縮物件頭里的型別指標Klass Pointer
// Oops : Ordinary Object Pointers
public static class User {
//8個位元組 Mark Word(標記欄位)
//4個位元組 Klass Pointer(型別指標) 如果關閉壓縮-XX:-UseCompressedClassPointers或-XX:-UseCompressedOops,則占用8個位元組
byte b; //1個位元組
Object o; //4個位元組 如果關閉壓縮-XX:-UseCompressedOops,則占用8個位元組
int id; //4個位元組
String name; //4個位元組 如果關閉壓縮-XX:-UseCompressedOops,則占用8個位元組
}
}列印結果:
[I object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1) // Mark Word 標記欄位
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) // Mark Word 標記欄位
8 4 (object header) 6d 01 00 20 (01101101 00000001 00000000 00100000) (536871277) // Klass Pointer 型別指標
12 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) // 陣列長度
16 0 int [I.<elements> N/A
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5) // Mark Word 標記欄位
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) // Mark Word 標記欄位
8 4 (object header) e5 01 00 20 (11100101 00000001 00000000 00100000) (536871397) // Klass Pointer 型別指標
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
com.cggeeker.jvm.JOLTest$User object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) a1 cc 00 20 (10100001 11001100 00000000 00100000) (536923297)
12 4 int User.id 0
16 1 byte User.b 0
17 3 (alignment/padding gap)
20 4 java.lang.Object User.o null
24 4 java.lang.String User.name null
28 4 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 3 bytes internal + 4 bytes external = 7 bytes total
Process finished with exit code 0關于指標壓縮的 jvm配置引數,啟用指標壓縮:-XX:+UseCompressedOops(默認開啟),禁止指標壓縮:-XX:-UseCompressedOops ; -XX:+PrintFlagsFinal,驗證UseCompressedOops的值,查看是否開啟指標壓縮,
什么是java物件的指標壓縮?
就是用4個位元組表示32G的記憶體空間,大白話就是開源節流,用最少的人干最多的事,
比如4個位元組,32位,可以表示2^32個地址,那么由于CPU尋址的最小單位是byte,所以最多也就只能表示4G的記憶體空間(2^32 byte = 4GB),那么想要表示更大的記憶體空間就只能對位數做增量使用64位的指標來表示,可是真的采用64位的指標來表示記憶體空間確實能夠表示更大的記憶體空間,但也同時帶來一些問題:
(1)增加了GC開銷:64位物件參考需要占用更多的堆空間,留給其他資料的空間將會減少,從而加快了GC的發生,更頻繁的進行GC,
(2)降低CPU快取命中率:64位物件參考增大了,CPU能快取的oop(ordinary object pointer 物件指標)將會更少,從而降低了CPU快取的效率,
為解決以上問題,JVM就做了折中處理,引入了"指標壓縮"這一概念,JVM將堆記憶體進行了塊劃分,以8個位元組為最小單位進行劃分,不再是真實的作業系統記憶體地址,而是Java進行8Byte映射之后的地址,所以也相對于作業系統的指標進行的8倍的擴容,所以還是使用32位的指標但是此時表示的記憶體空間卻達到了32G(4G * 8),

為什么要進行指標壓縮?
- 在64位平臺的HotSpot中使用32位指標(實際存盤用64位),記憶體使用會多出1.5倍左右,使用較大指標在主記憶體和快取之間移動資料,占用較大寬帶,同時GC也會承受較大壓力,
- 為了減少64位平臺下記憶體的消耗,啟用指標壓縮功能,
- 在jvm中,32位地址最大支持4G記憶體(2的32次方),可以通過對物件指標的存入堆記憶體時壓縮編碼、取出到cpu暫存器后解碼方式進行優化(物件指標在堆中是32位,在暫存器中是35位,2的35次方=32G),使得jvm只用32位地址就可以支持更大的記憶體配置(小于等于32G),
- 堆記憶體小于4G時,不需要啟用指標壓縮,jvm會直接去除高32位地址,即使用低虛擬地址空間
- 堆記憶體大于32G時,壓縮指標會失效,會強制使用64位(即8位元組)來對java物件尋址,這就會出現(1)的問題,所以堆記憶體不要大于32G為好
注意:32G是個近似值,這個臨界值跟JVM和平臺有關,當我們線上真正啟動服務的時候直接設定 -Xmx=32GB 的時候很可能導致 CompressedOop 失效,那我們怎么確定當前環境下最大記憶體設定多大才且最大限度的使用記憶體才能啟動 CompressedOop 呢?我們可以通過增加JVM引數 -XX:+PrintFlagsFinal,驗證UseCompressedOops的值,從而得知,到底是不是真的開啟了壓縮指標,還是壓縮指標失效!
三.聊聊物件記憶體分配(僅對HotSpot討論)
物件記憶體分配流程圖:
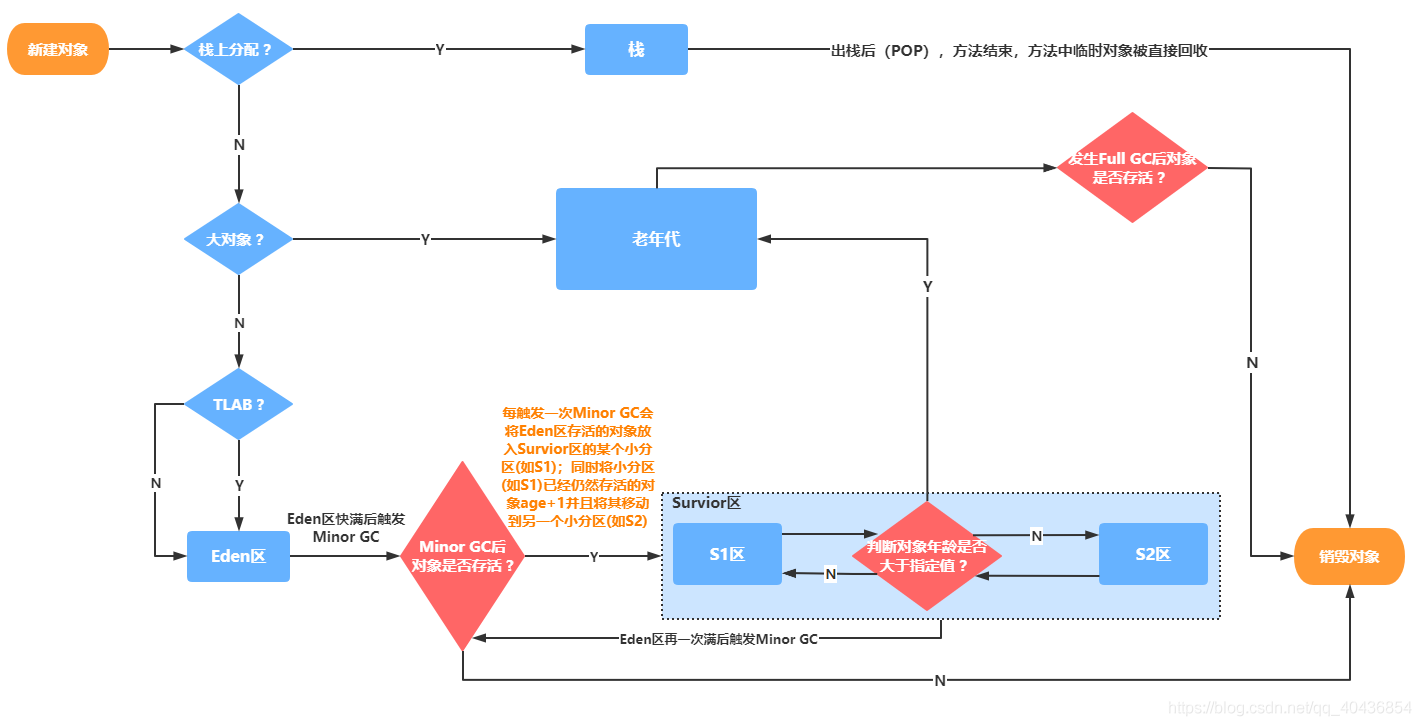
1.物件在堆疊上分配?
按照正常的套路物件不都是在堆上進行分配的嗎?其實這句話說對了一半,一個物件除了可以在堆上分配在一定條件下還可以在堆疊(執行緒堆疊)上分配,如果非得給個原因:
假如在JVM中物件都是在堆上分配,那么當物件沒有在參考鏈上就變成了"游離物件",面臨被GC回收的命運,問題是很多垃圾物件都是“臨時工”,用了就會被直接回收掉,這種“臨時工”物件一多起來,那還得了,很可能造成GC一直回收垃圾物件,這樣就會影響程式性能,所以JVM設計者為了減少臨時物件在堆內分配的數量,從而減少GC次數提升程式性能,JVM通過逃逸分析確定一個物件會不會被外部訪問,如果不會被外部訪問(也就是不會逃逸)就可以將該物件在堆疊上分配記憶體,這樣這個物件所占用的記憶體空間就可以隨堆疊幀出堆疊而銷毀,減輕了垃圾回收的壓力,
物件逃逸分析:就是分析物件動態作用域,當一個物件在方法中被定義后,它可能被外部方法所參考,例如被當成回傳值給一個變數賦值或者作為呼叫引數傳遞到其他地方中,
public User method1(){
User user = new User();
user.setId(58);
user.setName("CGgeeker");
return user;
}
public void method2(){
User user = new User();
user.setId(58);
user.setName("CGgeeker");
}從上面的代碼中可以看出,method1方法中創建的user物件被當作回傳值了,所以這個user物件的作用域范圍不能確定(有可能是個“逃逸物件”);而method2方法中的user物件可以確定是個“臨時工”,當這個方法結束后這個user物件就成為無效物件,所以對于這樣的物件就可以將其在堆疊上分配,讓其在方法結束時隨堆疊記憶體一起被回收,
自JDK7之后JVM默認開啟了逃逸分析來優化物件記憶體分配位置,具體是通過標量替換優先在堆疊上分配,開啟逃逸分析加入引數 -XX:+DoEscapeAnalysis;關閉逃逸分析使用引數 -XX:-DoEscapeAnalysis ,
標量替換:通過逃逸分析判斷出某個物件不會被外部訪問,并且這個物件可進一步進行分解時(一般是聚合量分解成標量),JVM不會創建這個物件,而是將這個方法中使用到的這個物件的成員變數分解出來,那么這個物件就被分解出來的成員變數代替,這些代替的成員變數在堆疊幀或暫存器上分配空間,這樣既節省了一部分創建物件的空間又不會因為沒有一大塊連續空間導致物件記憶體不夠分配,變數替換可謂是“以小換大”,JDK7之后默認開啟了變數替換,也可以通過設定引數關閉變數替換:-XX:+EliminateAllocations ,
注意標量和聚合量這兩個概念,標量是指不可以進一步分解的量,比如Java的基本資料型別就是標量;聚合量是指可以被進一步分解的量,比如物件,
下面我將用代碼分別驗證兩個觀點:
- 驗證不開啟逃逸分析和變數替換將會產生大量GC(采用控制變數法進行測驗);
- 驗證堆疊上分配的方式只對非逃逸物件有效;
開始證明第一個觀點:
(1)設定引數關閉逃逸分析和變數替換:-XX:-DoEscapeAnalysis -XX:-EliminateAllocations
/**
* 堆疊上分配,標量替換
* 代碼呼叫了1億次userMethod(),如果是分配到堆上,大概需要1GB以上堆空間,具體計算參照[美]RobertSedgewickKevinWa撰寫的《演算法》一書
* 如果堆空間小于該值(我這里將堆記憶體設定為100M),必然會觸發GC,
*
* 使用如下引數不會發生GC
* -Xmx100m -Xms100m -XX:+DoEscapeAnalysis -XX:+EliminateAllocations -XX:+PrintGC
* 使用如下引數都會發生大量GC
* -Xmx100m -Xms100m -XX:-DoEscapeAnalysis -XX:+EliminateAllocations -XX:+PrintGC
* -Xmx100m -Xms100m -XX:+DoEscapeAnalysis -XX:-EliminateAllocations -XX:+PrintGC
* -Xmx100m -Xms100m -XX:-DoEscapeAnalysis -XX:-EliminateAllocations -XX:+PrintGC
*/
public class EscapeAnalysisTest {
public static void main(String[] args) {
// 回圈呼叫1億次userMethod方法
for(int i = 0 ; i < 100000000 ; i++){
userMethod();
}
System.out.println("------運行結束------");
}
public static void userMethod(){
User user = new User();
user.setId(58);
user.setName("CGgeeker");
}
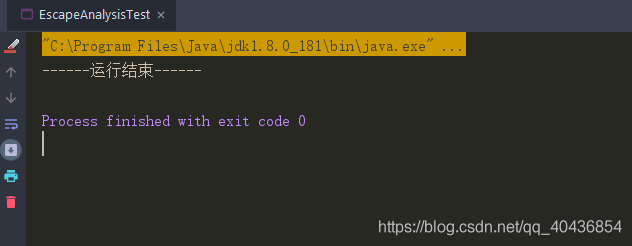
}運行結果可以看出控制臺列印了大量GC日志:
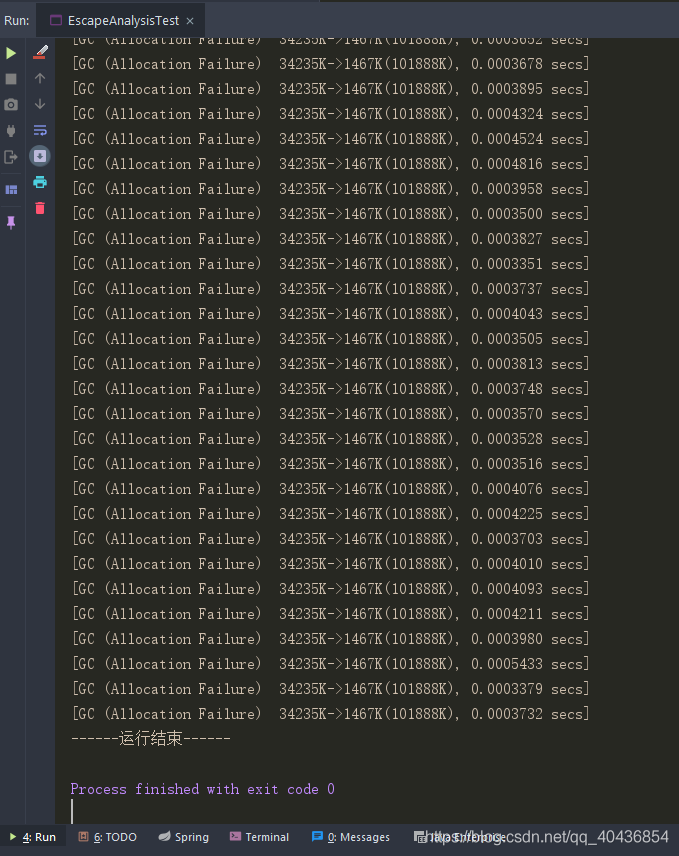
(2)設定引數關閉逃逸分析和變數替換:-XX:+DoEscapeAnalysis -XX:+EliminateAllocations
運行結果可以看出程式沒有產生GC日志:
開始證明第二個觀點:
/**
* 堆疊上分配,標量替換
* 代碼呼叫了1億次userMethod(),如果是分配到堆上,大概需要1GB以上堆空間,具體計算參照[美]RobertSedgewickKevinWa撰寫的《演算法》一書
* 如果堆空間小于該值(我這里將堆記憶體設定為100M),必然會觸發GC,
*
* 使用如下引數不會發生GC
* -Xmx100m -Xms100m -XX:+DoEscapeAnalysis -XX:+EliminateAllocations -XX:+PrintGC
* 使用如下引數都會發生大量GC
* -Xmx100m -Xms100m -XX:-DoEscapeAnalysis -XX:+EliminateAllocations -XX:+PrintGC
* -Xmx100m -Xms100m -XX:+DoEscapeAnalysis -XX:-EliminateAllocations -XX:+PrintGC
* -Xmx100m -Xms100m -XX:-DoEscapeAnalysis -XX:-EliminateAllocations -XX:+PrintGC
*/
public class EscapeAnalysisTest {
public static void main(String[] args) {
User user = null;
// 回圈呼叫1億次userMethod方法
for(int i = 0 ; i < 100000000 ; i++){
// userMethod();
/**
* 此時userMethod2方法中的臨時user物件被當作回傳值且被外界的另一個user變數參考,
* 所以臨時user物件成了“逃逸物件”,無法在堆疊上進行記憶體分配,
* 這時即使開啟了逃逸分析和標量替換引數也會產生大量GC日志!!!
*/
user = userMethod2();
}
System.out.println("列印user:" + user);
System.out.println("------運行結束------");
}
public static User userMethod2(){
User user = new User();
user.setId(58);
user.setName("CGgeeker");
return user;
}
/* public static void userMethod(){
User user = new User();
user.setId(58);
user.setName("CGgeeker");
}*/
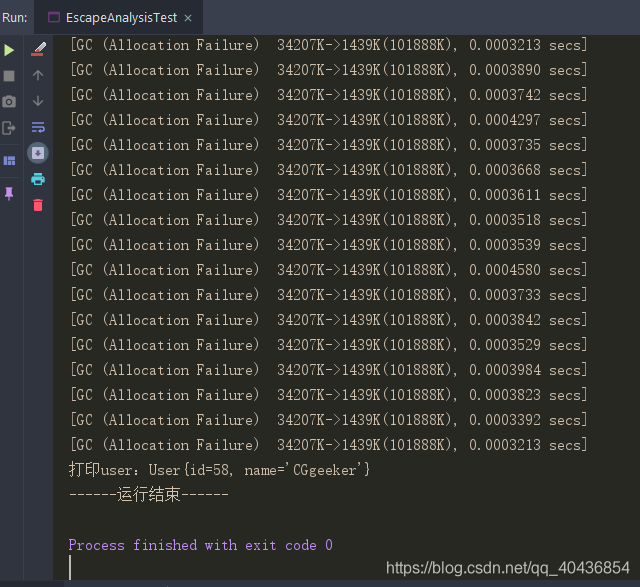
}
從運行結果看到控制臺列印了大量的GC日志,從而論證了逃逸物件不會在堆疊上分配的結論,
2.物件在Eden區分配
大多數情況下,物件在新生代中 Eden 區分配,當 Eden 區沒有足夠空間進行分配時,JVM將發起一次Minor GC,
Minor GC 和 Full GC:
- Minor GC/Young GC:指發生新生代的的垃圾收集動作,Minor GC非常頻繁,回收速度一般也比較快,
- Major GC/Full GC:一般會回收老年代 ,年輕代,方法區的垃圾,Major GC的速度一般會比Minor GC的慢10倍以上,
Eden與Survivor區默認8:1:1
大量的物件被分配在eden區,eden區滿了后會觸發minor gc,可能會有90%以上的物件成為垃圾被回收掉,剩余存活的物件會被挪到為空的那塊survivor區,下一次eden區滿了后又會觸發minor gc,把eden區和survivor區垃圾物件回收,把剩余存活的物件一次性挪動到另外一塊為空的survivor區,因為新生代的物件都是朝生夕死的,存活時間很短,所以JVM默認的8:1:1的比例是很合適的(注意:這個比例是經過大量測驗得到的比較合適的一個比例),讓eden區盡量的大,survivor區夠用即可,
JVM默認有這個引數-XX:+UseAdaptiveSizePolicy(默認開啟),會導致這個8:1:1比例自動變化,如果不想這個比例有變化可以設定引數-XX:-UseAdaptiveSizePolicy
示例:
// 我設定了這些引數: -Xmx120m -Xms120m -XX:-UseAdaptiveSizePolicy -XX:+PrintGCDetails
public class MinorGCTest {
public static void main(String[] args) throws InterruptedException {
byte[] arr1, arr2, arr3, arr4, arr5, arr6;
arr1 = new byte[25 * 1024 * 1024]; // 大概25M ,25 * 1024K
// arr2 = new byte[1 * 1024 * 1024]; // 大概1M ,1024K
/* arr3 = new byte[1* 1024 * 1024];
arr4 = new byte[1* 1024 * 1024];
arr5 = new byte[1* 1024 * 1024];
arr6 = new byte[1* 1024 * 1024];*/
}
}我感覺我把列印結果放上來,很多小伙伴都會對這個結果產生疑惑,
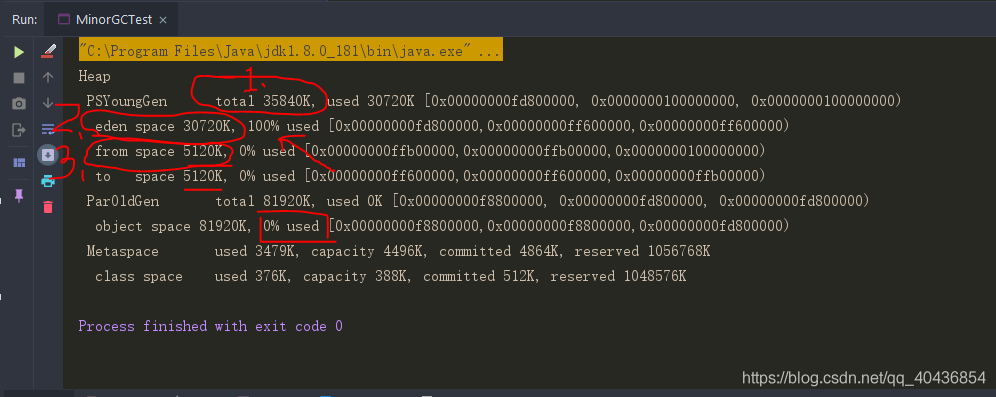
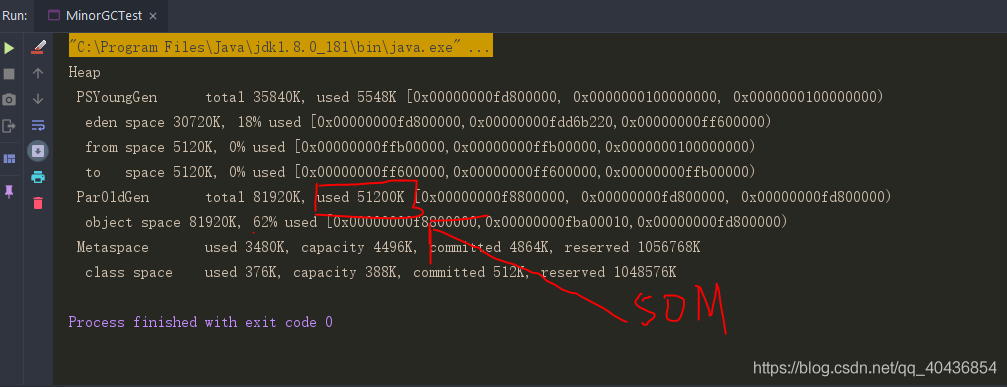
- 疑惑1:為什么設定了引數 -Xmx120m -Xms120m 后,按理說給堆分配了120M的記憶體空間,新生代和老年代按照 1:2的比例分配后,那新生代也應該有40M空間才對啊,怎么上圖中1處這里只有35840K,大概35M的樣子?what fuck?
- 解釋1:上圖中的total 35840K 實際上只是 eden區 + survior區中的一個小磁區(from區 / to區) ,所以這里的35840K實際上就只是 eden space的30720K + from space的5120K,
- 疑惑2:為什么我設定了引數 -XX:-UseAdaptiveSizePolicy eden區和survior區比例卻不是8:1:1?按理說關閉比例自動變化應該是8:1:1啊,怎么是6:1:1? what fuck?
- 解釋2:宣告一點啊,我這里具體的原因我也不清楚,但是不妨礙我們思考的方向,可能原因是要么就是這個引數必須在特定的垃圾收集器下使用,否則不生效;還可能就是默認比例調整了,
- 疑惑3:為什么eden space使用率就直接飆滿達到100%了?不是在程式中 ”arr1 = new byte[25 * 1024 * 1024];“ 大概也就25M啊,按理說eden space空間是30M,25M還沒達到30M怎么就是100%呢?
- 解釋3:原因是即使程式什么也不做,新生代也會使用至少幾M記憶體(小生不才,暫時也不知道這幾M資料具體是什么,等之后閱讀Hotspot原始碼后來填坑吧),不過驗證的程序還是寫下面:
那我們干脆一點把所有變數中注釋掉:
// 我設定了這些引數: -Xmx120m -Xms120m -XX:-UseAdaptiveSizePolicy -XX:+PrintGCDetails
public class MinorGCTest {
public static void main(String[] args) throws InterruptedException {
// byte[] arr1, arr2, arr3, arr4, arr5, arr6;
// arr1 = new byte[25 * 1024 * 1024]; // 大概25M ,25 * 1024K
// arr2 = new byte[1 * 1024 * 1024]; // 大概1M ,1024K
/* arr3 = new byte[1* 1024 * 1024];
arr4 = new byte[1* 1024 * 1024];
arr5 = new byte[1* 1024 * 1024];
arr6 = new byte[1* 1024 * 1024];*/
}
}控制臺輸出結果如下,那丟失的5M找到了!
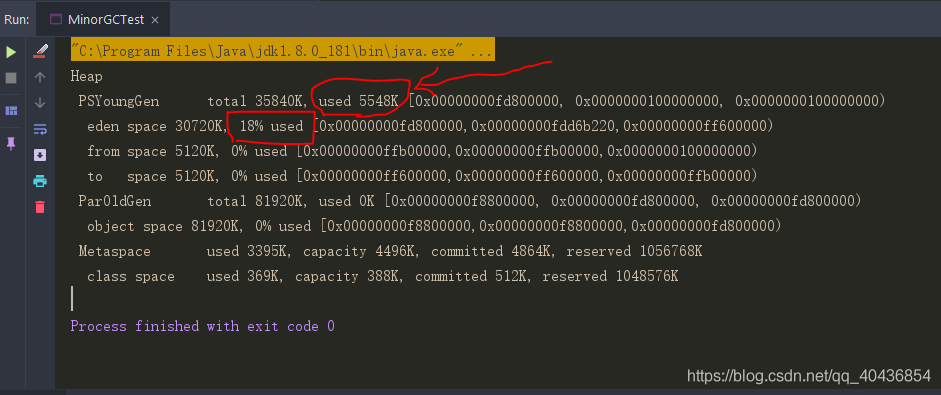
我們繼續研究當eden區滿后再向堆中創建資料會發生什么:
// 我設定了這些引數: -Xmx120m -Xms120m -XX:-UseAdaptiveSizePolicy -XX:+PrintGCDetails
public class MinorGCTest {
public static void main(String[] args) throws InterruptedException {
byte[] arr1, arr2, arr3, arr4, arr5, arr6;
arr1 = new byte[25 * 1024 * 1024]; // 大概25M ,25 * 1024K
arr2 = new byte[1 * 1024 * 1024]; // 大概1M ,1024K
/* arr3 = new byte[1* 1024 * 1024];
arr4 = new byte[1* 1024 * 1024];
arr5 = new byte[1* 1024 * 1024];
arr6 = new byte[1* 1024 * 1024];*/
}
}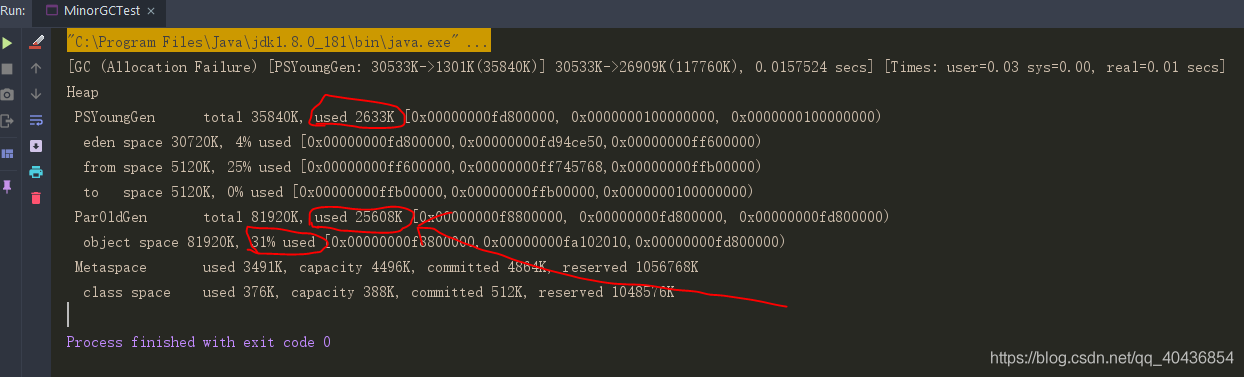
通過控制臺列印可以看出:因為給arr2分配記憶體的時候eden區記憶體幾乎已經被分配完了,當Eden區沒有足夠空間進行分配時,虛擬機將發起一次Minor GC,GC期間虛擬機又發現arr1無法存入Survior空間,所以只好把新生代的物件提前轉移到老年代中去,老年代上的空間足夠存放arr1,所以不會出現Full GC,執行Minor GC后,后面分配的物件如果能夠存在eden區的話,還是會在eden區分配記憶體,可以執行如下代碼驗證:
// 我設定了這些引數: -Xmx120m -Xms120m -XX:-UseAdaptiveSizePolicy -XX:+PrintGCDetails
public class MinorGCTest {
public static void main(String[] args) throws InterruptedException {
byte[] arr1, arr2, arr3, arr4, arr5, arr6;
arr1 = new byte[25 * 1024 * 1024]; // 大概25M ,25 * 1024K
arr2 = new byte[1 * 1024 * 1024]; // 大概1M ,1024K
arr3 = new byte[1* 1024 * 1024];
arr4 = new byte[1* 1024 * 1024];
arr5 = new byte[1* 1024 * 1024];
arr6 = new byte[1* 1024 * 1024];
}
}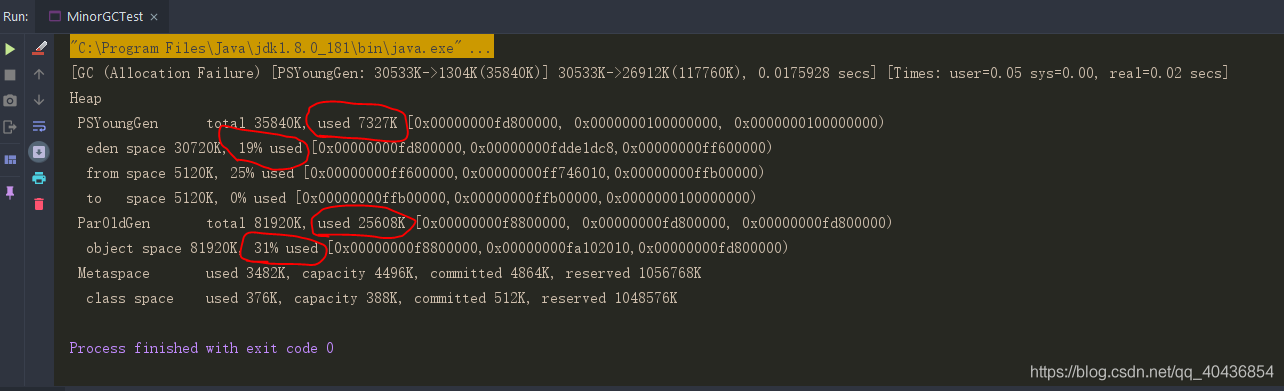
從上圖看出:由于新生的物件在eden區還可以放下,所以不會挪到老年代,
3.大物件直接進入老年代
大物件就是需要大量連續記憶體空間的物件(比如:字串、陣列),JVM引數 -XX:PretenureSizeThreshold 可以設定大物件的大小,這個引數只在 Serial 和ParNew兩個收集器下有效,如果物件超過設定大小會直接進入老年代,不會進入年輕代,這樣做是為了避免為大物件分配記憶體時的復制操作而降低效率,
證明程序如下:我們直接將arr1的值設定為50M的樣子,這樣就比年輕代總空間40M大了,但是比老年代80M小(保證了不會發生Full GC),所以這個物件會被直接挪到老年代,
// 我設定了這些引數: -Xmx120m -Xms120m -XX:-UseAdaptiveSizePolicy -XX:+PrintGCDetails
public class MinorGCTest {
public static void main(String[] args) throws InterruptedException {
byte[] arr1, arr2, arr3, arr4, arr5, arr6;
arr1 = new byte[50 * 1024 * 1024]; // 大概50M ,50 * 1024K
}
}
4.長期存活的物件將進入老年代
虛擬機采用了分代收集的思想來管理記憶體,那么記憶體回收時就必須能識別哪些物件應放在新生代,哪些物件應放在老年代中,為了做到這一點,虛擬機給每個物件一個物件年齡(Age)計數器,
如果物件在 Eden 出生并經過第一次 Minor GC 后仍然能夠存活,并且能被 Survivor 容納的話,將被移動到 Survivor 空間中,并將物件年齡設為1,物件在 Survivor 中每熬過一次 MinorGC,年齡就增加1歲,當它的年齡增加到一定程度(默認為15歲,CMS收集器默認6歲,不同的垃圾收集器會略微有點不同),就會被晉升到老年代中,物件晉升到老年代的年齡閾值,可以通過引數 -XX:MaxTenuringThreshold 來設定,
5.物件動態年齡判斷
當前放物件的Survivor區域里(其中一塊區域,放物件的那塊S區),一批物件的總大小大于這塊Survivor區域記憶體大小的50%(-XX:TargetSurvivorRatio可以指定),那么此時大于等于這批物件年齡最大值的物件,就可以直接進入老年代了,例如Survivor區域里現在有一批物件,年齡1歲 + 年齡2歲 + 年齡n歲的多個年齡物件總和超過了Survivor區域的50%,此時就會把年齡n歲(含)以上的物件都放入老年代,這個規則其實是希望那些可能是長期存活的物件,盡早進入老年代,物件動態年齡判斷機制一般是在Minor GC之后觸發的,
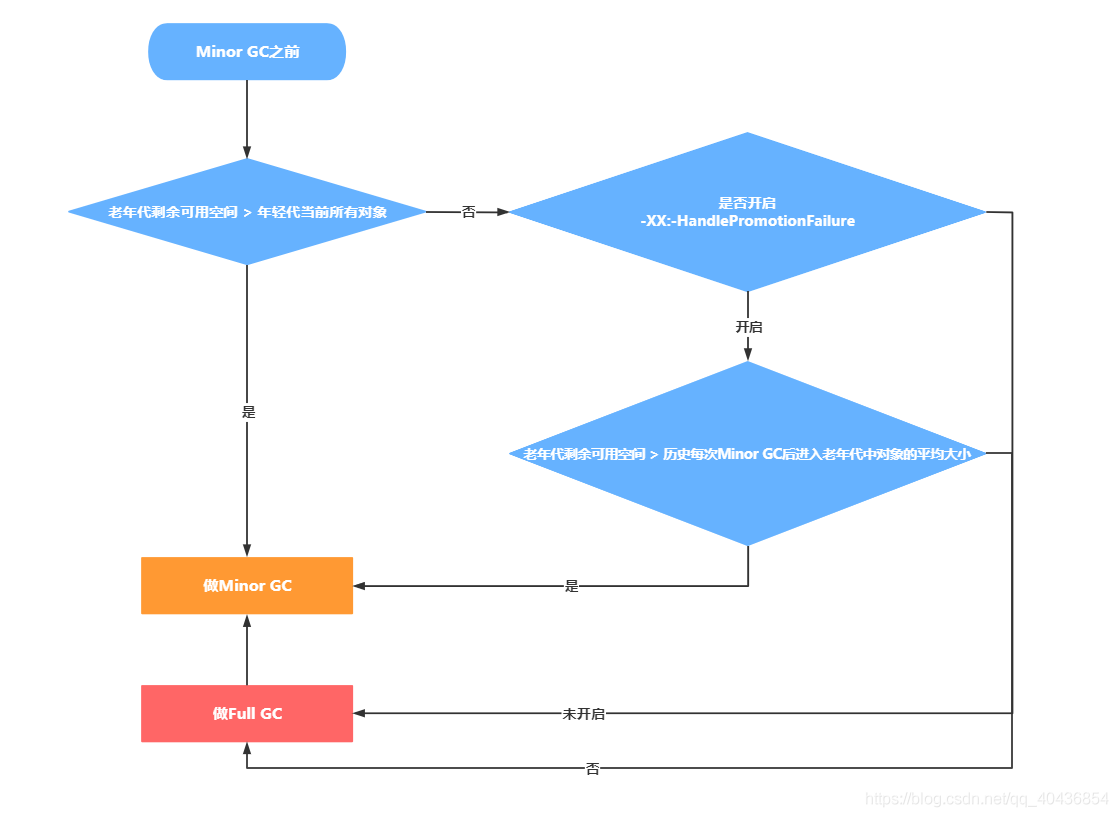
6.老年代空間分配擔保機制
年輕代每次Minor GC之前JVM都會計算下老年代剩余可用空間,如果這個可用空間小于年輕代里現有的所有物件大小之和(包括垃圾物件),就會看一個“-XX:-HandlePromotionFailure”(jdk1.8默認就設定了)的引數是否設定了,如果有這個引數,就會看看老年代的可用記憶體大小,是否大于之前每一次Minor GC后進入老年代的物件的平均大小,如果結果是小于或者之前說的引數沒有設定,那么就會觸發一次Full GC,對老年代和年輕代一起回收一次垃圾,如果回收完還是沒有足夠空間存放新的物件就會發生"OOM" ,當然,如果Minor GC之后剩余存活的需要挪動到老年代的物件大小還是大于老年代可用空間,那么也會觸發Full GC,Full GC完之后如果還是沒有空間放Minor GC之后的存活物件,則也會發生“OOM”,
四.聊聊物件記憶體回收
垃圾收集器回收堆中物件時,首先會判斷哪些物件是需要被回收的垃圾物件,這里就涉及到判斷垃圾物件的兩種方法:
參考計數法
在物件中添加一個參考計數器,每當有一個地方參考到這個物件,計數器就+1;當參考失效(比如將某個物件的參考賦值為null),計數器就 -1;當某個物件的計數器值為0時,說明這個物件沒有任何參考與之關聯,則該物件基本不太可能在其他地方被使用到,那么這個物件就成為可被回收的物件了,
優點:實作簡單,效率高,
缺點:沒有解決物件之間的環參考(回圈參考)問題,容易導致在環內的物件一直得不到回收,所以在Java中并沒有采用這種方式(Python采用的是參考計數法),
例如下面這段代碼就存在環參考問題:
public class ReferenceCountTest {
static class MyObj{
public Object instance = null;
}
public static void main(String[] args) {
// 創建兩個ReferenceCountTest物件分別被 object1 和 object2參考 此時 參考計數器都是 1
MyObj object1 = new MyObj();
MyObj object2 = new MyObj();
/**
* 這時讓object1和object2的成員變數交叉參考ReferenceCountTest物件,
* 形成參考倍訓,同時這兩個ReferenceCountTest物件的計數器都會加1 變為 2
* 這時候兩個ReferenceCountTest物件都有兩個參考
*/
object1.instance = object2;
object2.instance = object1;
/**
* 銷毀這兩個ReferenceCountTest物件中的一條參考,計數器減1 變為 1
* 此時這兩個ReferenceCountTest物件還剩下成員變數的那個參考,
* 但是被相互參考無法通過簡單的object = null進行回收,
*/
object1 = null;
object2 = null;
}
}可達性分析演算法
為了解決這個問題,在Java中采取了 可達性分析法,該方法的基本思想是通過一系列稱為“GC Roots”的物件作為起始點,從這些節點開始向下搜索,搜索走過的路徑稱為“參考鏈”,當一個物件到 GC Roots 沒有任何的參考鏈相連時(從 GC Roots 到這個物件不可達)時,證明此物件不可用,以下圖為例:
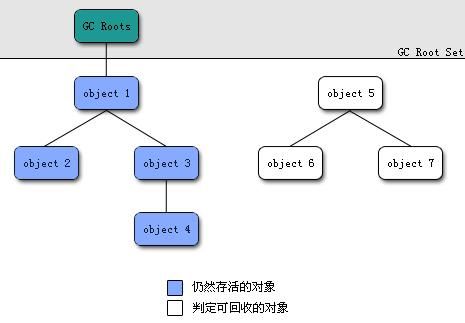
在Java語言中,可作為GC Roots的物件包含以下幾種:
- 虛擬機堆疊(堆疊幀中的本地變數表)中參考的物件,
- 方法區中靜態屬性參考的物件,
- 方法區中常量參考的物件,
- 本地方法堆疊中(Native方法)參考的物件,
談談參考型別
在JDK1.2之后,Java對參考的概念做了擴充,將參考分為強參考(Strong Reference)、軟參考(Soft Reference)、弱參考(Weak Reference)和虛參考(Phantom Reference)四種,這四種參考的強度依次遞減,
強參考:強參考是使用最普遍的參考,如果一個物件具有強參考,那垃圾回收器絕不會回收它,當記憶體空間不足,Java虛擬機寧愿拋出OutOfMemoryError錯誤,使程式例外終止,也不會靠隨意回收具有強參考的物件來解決記憶體不足的問題,
public static User user = new User();軟參考:將物件用SoftReference軟參考型別的物件包裹,如果一個物件只具有軟參考,則記憶體空間足夠,垃圾回收器就不會回收它;如果記憶體空間不足了,就會回收這些物件的記憶體,只要垃圾回收器沒有回收它,該物件就可以被程式使用,軟參考可用來實作記憶體敏感的高速快取,
public static SoftReference<User> user = new SoftReference<User>(new User());軟參考在實際中有重要的應用,例如瀏覽器的后退按鈕,按后退時,這個后退時顯示的網頁內容是重新進行請求還是從快取中取出呢?這就要看具體的場景:
(1)如果一個網頁在瀏覽結束時就進行內容的回收,則按后退查看前面瀏覽過的頁面時,需要重新構建,
(2)如果將瀏覽過的網頁存盤到記憶體中會造成記憶體的大量浪費,甚至會造成記憶體溢位,
弱參考:將物件用WeakReference軟參考型別的物件包裹,弱參考跟沒參考差不多,GC會直接回收掉,很少使用,
public static WeakReference<User> user = new WeakReference<User>(new User());虛參考:虛參考也稱為幽靈參考或者幻影參考,它是最弱的一種參考關系,幾乎不用,
如何判斷一個類是無用的類
方法區主要回收的是無用的類,怎么判斷一個類有用還是無用?
類需要同時滿足下面3個條件才能算是 “無用的類” :
- 該類所有的物件實體都已經被回收,也就是 Java 堆中不存在該類的任何實體,
- 加載該類的 ClassLoader 已經被回收,
- 該類對應的 java.lang.Class 物件沒有在任何地方被參考,無法在任何地方通過反射訪問該類的方法,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/216228.html
標籤:其他