文章目錄
- 寫在前面
- 批感知器演算法
- Ho Kashyap演算法
- MSE多類擴展方法
- Ref.
寫在前面
本博客為模式識別作業的記錄,實作批感知器演算法、Ho Kashyap演算法和MSE多類擴展方法,可參考教材
[
1
]
\color{#0000FF}{[1]}
[1],所用資料如下如所示:
批感知器演算法
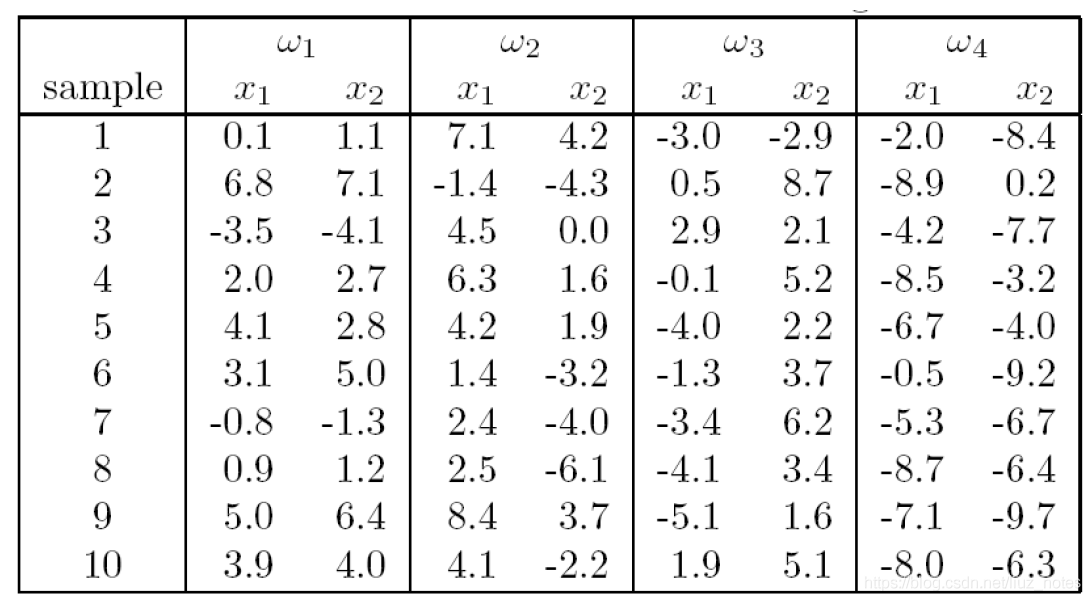
從 a = 0 \mathbf a=0 a=0開始迭代,分類 ω 1 \omega_1 ω1?和 ω 2 \omega_2 ω2?并計算最終的解向量,記錄下收斂的步數,

"""批感知器演算法"""
import matplotlib.pyplot as plt
import numpy as np
import math
data = np.loadtxt('data.txt')
trn_data1 = data[0:20, 0:2] # 問題一(1)
trn_lable1 = data[0:20, 2]
# trn_data1 = data[10:30, 0:2] # 問題一(1)
# trn_lable1 = data[10:30, 2]
plt.scatter(trn_data1[0:10, 0], trn_data1[0:10, 1], color='blue', marker='o', label=''r'$\omega_1$')
plt.scatter(trn_data1[10:20, 0], trn_data1[10:20, 1], color='red', marker='x', label=''r'$\omega_2$')
plt.xlabel(''r'$x_1$')
plt.ylabel(''r'$x_2$')
plt.legend(loc='upper left')
plt.title('Original Data')
plt.show()
X = np.hstack((np.ones((trn_data1.shape[0], 1)), trn_data1))
X1 = X[0:10, :]
X2 = -1 * X[10:20, :]
X = np.vstack((X1, X2)) # 規范化增廣樣本
w = np.zeros((3, 1), dtype='float32')
step = 0
for i in range(100):
if i == 0:
y_pred = np.where(np.dot(X, w) == 0)[0] # 統計分類錯誤的點數
else:
y_pred = np.where(np.dot(X, w) < 0)[0]
step += 1
print('第%2d次更新,分類錯誤的點個數:%2d' % (step, len(y_pred)))
if len(y_pred) > 0:
w += (np.sum(X[y_pred, :], axis=0)).reshape((3, 1))
else:
break
print('解向量為:', w)
x1 = np.array([-5, 8])
x2 = -1 * (w[1]*x1 + w[0])/w[2]
plt.scatter(trn_data1[0:10, 0], trn_data1[0:10, 1], color='blue', marker='o', label=''r'$\omega_1$')
plt.scatter(trn_data1[10:20, 0], trn_data1[10:20, 1], color='red', marker='x', label=''r'$\omega_2$')
plt.plot([x1[0], x1[1]], [x2[0], x2[1]], 'black')
plt.xlabel(''r'$x_1$')
plt.ylabel(''r'$x_2$')
plt.legend(loc='upper left')
plt.title('classified Data')
plt.show()
演算法在第24次更新收斂,此時解向量
a
=
(
34.0
,
?
30.4
,
34.1
)
\mathbf{a} = (34.0,?30.4, 34.1)
a=(34.0,?30.4,34.1)
Ho Kashyap演算法

"""Ho Kashyap演算法"""
import matplotlib.pyplot as plt
import numpy as np
import math
data = np.loadtxt('data.txt')
trn_data1 = data[0:10, 0:2] # 問題二(1)
trn_lable1 = data[0:10, 2]
temp = data[20:30, 0:2]
temp_lb = data[20:30, 2]
# trn_data1 = data[10:20, 0:2] # 問題二(2)
# trn_lable1 = data[10:20, 2]
# temp = data[30:40, 0:2]
# temp_lb = data[30:40, 2]
trn_data = np.vstack((trn_data1, temp))
trn_lable = np.vstack((trn_lable1, temp_lb))
# print(trn_data.shape, '\n', trn_lable.shape)
# print(trn_data)
plt.scatter(trn_data[0:10, 0], trn_data[0:10, 1], color='blue', marker='o', label=''r'$\omega_2$')
plt.scatter(trn_data[10:20, 0], trn_data[10:20, 1], color='red', marker='x', label=''r'$\omega_4$')
plt.xlabel(''r'$x_1$')
plt.ylabel(''r'$x_2$')
plt.legend(loc='upper left')
plt.title('Original Data')
plt.show()
X = np.hstack((np.ones((trn_data.shape[0], 1)), trn_data))
X1 = X[0:10, :]
X2 = -1 * X[10:20, :]
X = np.vstack((X1, X2)) # 規范化增廣樣本
w = np.random.randn(3, 1)
b = np.random.rand(X.shape[0], 1)
eta = 0.1
MAX_iteration = 1000
step = 0
acc = 0
for i in range(MAX_iteration):
e = np.dot(X, w) - b
e_p = 0.5 * (e + abs(e))
eta_k = eta/(i+1)
# if (e == 0).all():
if max(abs(e)) <= min(b):
print(e)
break
else:
b += 2 * eta_k * e_p
Y_p = np.linalg.pinv(X)
w = np.dot(Y_p, b)
step += 1
acc = (np.sum(np.dot(X, w) > 0)) / X.shape[0]
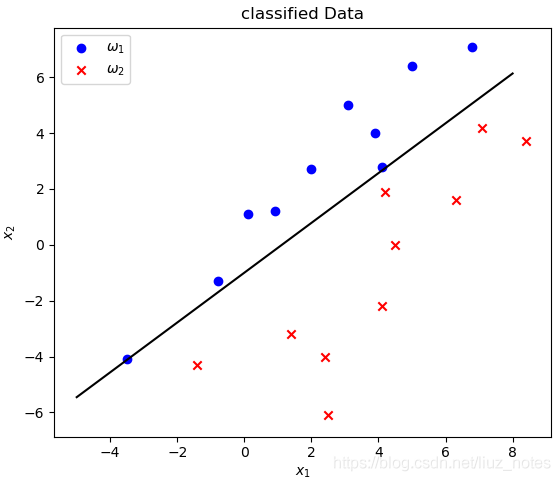
print('第%2d次更新, 分類準確率%f' % (step, acc))
# print(e, '\n')
if step == MAX_iteration and acc != 1:
print("未找到解,線性不可分!")
x1 = np.array([-8, 8])
x2 = -1 * (w[1]*x1 + w[0])/w[2]
plt.scatter(trn_data[0:10, 0], trn_data[0:10, 1], color='blue', marker='o', label=''r'$\omega_2$')
plt.scatter(trn_data[10:20, 0], trn_data[10:20, 1], color='red', marker='x', label=''r'$\omega_4$')
plt.plot([x1[0], x1[1]], [x2[0], x2[1]], 'black')
plt.xlabel(''r'$x_1$')
plt.ylabel(''r'$x_2$')
plt.text(3, -2, 'Accuracy: %.3f' % acc)
plt.legend(loc='upper left')
plt.title('classified Data')
plt.show()
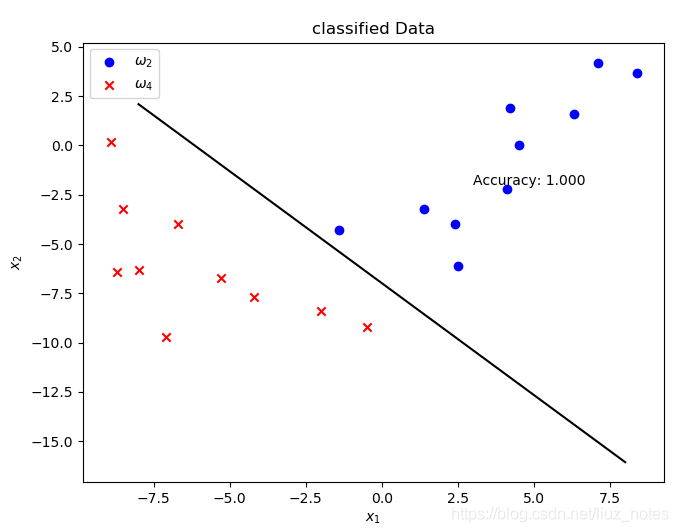
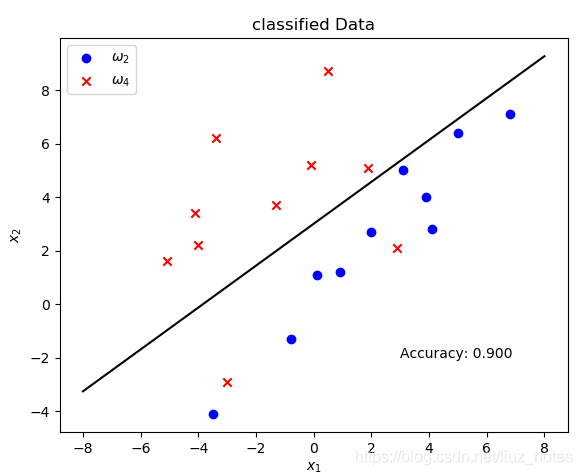
MSE多類擴展方法
首先根據訓練樣本計算出權值W,然后根據此權值和測驗樣本計算出預測值,并對該值取argmax 得到最終的輸出標簽,從而得到分類正確率為100%,
"""MSE多類擴展方法"""
import numpy as np
data = np.loadtxt('data.txt')
train_data = []
train_label = []
test_data = []
test_label = []
# 資料預處理
for i in [0, 10, 20, 30]:
temp_data = data[i:i+8, 0:2]
temp_label = data[i:i+8, 2]
train_data.append(temp_data)
train_label.append(temp_label)
test_data.append(data[i+8:i+10, 0:2])
test_label.append(data[i+8:i+10, 2])
train_data = np.array(train_data).reshape((32, 2))
train_label = np.array(train_label).reshape(-1).astype(int) - 1
test_data = np.array(test_data).reshape((8, 2))
test_label = np.array(test_label).reshape(-1).astype(int) - 1
train_label = np.eye(4)[train_label] # 32x4大小,one-hot向量矩陣
test_label = np.eye(4)[test_label] # 8x4大小
train_data = np.hstack((train_data, np.ones((train_data.shape[0], 1))))
test_data = np.hstack((test_data, np.ones((test_data.shape[0], 1))))
print(train_data.shape, train_label.shape)
print(test_data.shape, test_label.shape)
train_data = train_data.T # 按照課件的公式調整資料維度
train_label = train_label.T
test_data = test_data.T
test_label = test_label.T
print(train_data.shape, train_label.shape)
print(test_data.shape, test_label.shape)
lam = 1e-9
temp = np.linalg.inv(np.dot(train_data, train_data.T) + lam)
W = np.dot(np.dot(temp, train_data), train_label.T) # 3x4維
y_pred = np.dot(W.T, test_data)
index = np.argmax(y_pred, axis=0) # 得到每個樣本對應類別的值最大的索引
y_pred = np.eye(y_pred.shape[0])[index].T # 轉換為one-hot向量
wrong_num = sum(sum(y_pred - test_label))
acc = (1 - wrong_num / len(test_label)) * 100
print('分類正確率為:%.2f%% ' % acc)
Ref.
[1]Richard O. Duda. 模式分類[M]. 李宏東等譯. 機械工業出版社 中信出版社, 2003.
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/217018.html
標籤:其他
下一篇:pyqt5環境搭建