文章目錄
- 一、 什么是Hive
- 二、 Hive的優缺點
- 2.1 優點
- 2.2 缺點
- 三、 Hive架構原理
- 3.1 用戶介面:Client
- 3.2 元資料:Metastore
- 3.3 結合Hadoop
- 3.4 驅動器:Driver
- 四、 Hive和資料庫比較
- 4.1 查詢語言
- 4.2 資料更新
- 4.3 執行延遲
- 4.4 資料規模
一、 什么是Hive
Hive是基于Hadoop的一個資料倉庫工具,可以將結構化的資料檔案映射為一張表,并提供類SQL查詢功能,
本質是:將HQL轉化成MapReduce程式:
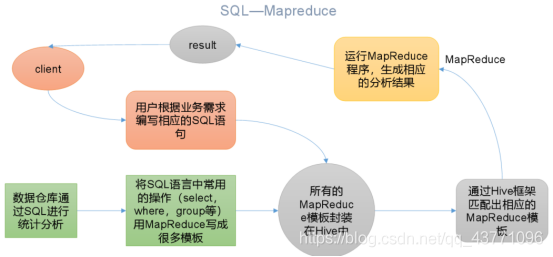
(1)Hive處理的資料存盤在HDFS
(2)Hive分析資料底層的實作是MapReduce
(3)執行程式運行在Yarn上
大部分SQL陳述句都封裝了MR程式(類SQL),之所以封裝成SQL是因為基本程式員都會這玩意,
基于MR處理: 開發者—>分析需求—>撰寫MR—>得到結果
基于Hive處理: 開發者—>分析需求—>撰寫SQL—>Hive將SQL轉化成MR—>得到結果
二、 Hive的優缺點
2.1 優點
(1)操作介面采用類SQL語法,提供快速開發的能力(簡單、容易上手),
(2)避免了去寫MapReduce,減少開發人員的學習成本,
(3)Hive的執行延遲比較高,因此Hive常用于資料分析,對實時性要求不高的場合,
(4)Hive優勢在于處理大資料,對于處理小資料沒有優勢,因為Hive的執行延遲比較高,
(5)Hive支持用戶自定義函式,用戶可以根據自己的需求來實作自己的函式,
2.2 缺點
1)Hive的HQL表達能力有限
(1)迭代式演算法無法表達,表達能力有限(復雜的邏輯演算法不好封裝)
(2)資料挖掘方面不擅長,由于MapReduce資料處理流程的限制(比較慢,因為底層的缺點也都還在),效率更高的演算法卻無法實作,
2)Hive的效率比較低
(1)Hive自動生成的MapReduce作業,通常情況下不夠智能化(機器翻譯比較死板,可能不是最優解,但是一定可以實作)
(2)Hive調優比較困難,粒度較粗(只能在框架的基礎上優化,不能深入底層MR程式優化)
三、 Hive架構原理
Hive都是用別人來存東西,自己一點都不存,只負責翻譯HQL成MR程式
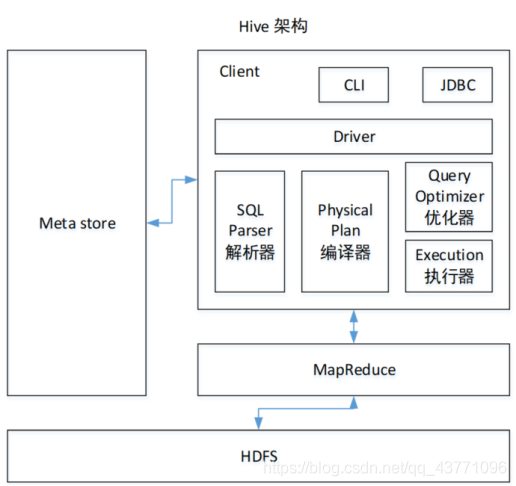
3.1 用戶介面:Client
CLI(command-line interface)、JDBC/ODBC(jdbc訪問hive)、WEBUI(瀏覽器訪問hive)
3.2 元資料:Metastore
HDFS資料檔案沒有被映射成資料庫的表結構,檔案中沒有這些資料的描述性陳述句(元資料),這個得自己定義,
元資料包括:表所屬資料庫(默認是default)、表的擁有者、表名及表的注釋、欄位及欄位的注釋、列/磁區欄位、表的型別(是否是外部表)、表資料所在目錄等,而表里面具體的內容則在HDFS里,很多框架比如Atlas就是監控元資料庫matestore中的表資訊來實作元資料管理,后面有時間會出一篇如何利用元資料庫制作企業數倉資料字典以及常用SQL查詢陳述句的文章;
元資料默認存盤在自帶的derby資料庫(小巧但是很多缺點,比如不支持并發連接,可以理解為輕量級的MySQL資料庫)中,一般都采用MySQL存盤Metastore(即換成用MySQL來存元資料),
3.3 結合Hadoop
使用HDFS進行存盤,使用MapReduce進行計算,
3.4 驅動器:Driver
(1)決議器(SQL Parser):將SQL字串轉換成抽象語法樹AST,這一步一般都用第三方工具庫完成,比如antlr;對AST進行語法分析,比如表是否存在、欄位是否存在、SQL語意是否有誤,
(2)編譯器(Physical Plan):將AST編譯生成邏輯執行計劃,
(3)優化器(Query Optimizer):對邏輯執行計劃進行優化,
(4)執行器(Execution):把邏輯執行計劃轉換成可以運行的物理計劃,
對于Hive來說,引擎就是MR/Spark/Tez,后面甚至可能會支持Flink,不同的引擎在SQL翻譯的邏輯和底層的程式是不一樣的,比如MR引擎會把SQL翻譯成MR,Spark引擎會把SQL翻譯成RDD程式,Tez引擎外面用的比較少,可以理解為在MR的基礎上做了DAG方向的基于記憶體的shuffle優化,
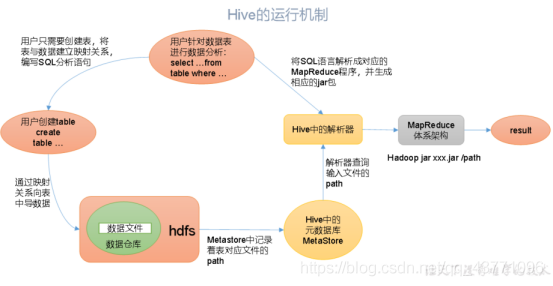
Hive通過給用戶提供的一系列互動介面,接收到用戶的指令(SQL),使用自己的Driver,結合元資料(MetaStore),將這些指令翻譯成MapReduce,提交到Hadoop中執行,最后,將執行回傳的結果輸出到用戶互動介面,
四、 Hive和資料庫比較
Hive不是資料庫!他只是框架!!只是用法比較像,因為95%以上SQL陳述句都封裝了MR程式,其實沒什么可比性,只是陳述句很像,
由于 Hive 采用了類似SQL 的查詢語言 HQL(Hive Query Language),因此很容易將 Hive 理解為資料庫,其實從結構上來看,Hive 和資料庫除了擁有類似的查詢語言,再無類似之處,本文將從多個方面來闡述 Hive 和資料庫的差異,資料庫可以用在 Online 的應用中,但是Hive 是為資料倉庫而設計的,清楚這一點,有助于從應用角度理解 Hive 的特性,
4.1 查詢語言
由于SQL被廣泛的應用在資料倉庫中,因此,專門針對Hive的特性設計了類SQL的查詢語言HQL,熟悉SQL開發的開發者可以很方便的使用Hive進行開發,
4.2 資料更新
由于Hive是針對資料倉庫應用設計的,而資料倉庫的內容是讀多寫少的,因此,Hive中不建議對歷史資料的改寫,所有的資料都是在加載的時候確定好的,而資料庫中的資料通常是需要經常進行修改的,因此可以使用 INSERT INTO … VALUES 添加資料,使用 UPDATE … SET修改資料,雖然HQL也可以但是這樣會慢,原理是先下載修改后上傳,
4.3 執行延遲
Hive 在查詢資料的時候,由于沒有索引,需要掃描整個表(如果沒有磁區分桶,則都是暴力掃描,復雜度都是ALL),因此延遲較高,另外一個導致 Hive 執行延遲高的因素是 MapReduce框架,由于MapReduce 本身具有較高的延遲,因此在利用MapReduce 執行Hive查詢時,也會有較高的延遲,相對的,資料庫的執行延遲較低,當然,這個低是有條件的,即資料規模較小,當資料規模大到超過資料庫的處理能力的時候,Hive的并行計算顯然能體現出優勢,
4.4 資料規模
由于Hive建立在集群上并可以利用MapReduce進行并行計算,因此可以支持很大規模的資料;對應的,資料庫可以支持的資料規模較小,能用MySQL算的就不要用Hive了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/222757.html
標籤:其他