??大家好,我是不溫卜火,是一名計算機學院大資料專業大三的學生,昵稱來源于成語—
不溫不火,本意是希望自己性情溫和,作為一名互聯網行業的小白,博主寫博客一方面是為了記錄自己的學習程序,另一方面是總結自己所犯的錯誤希望能夠幫助到很多和自己一樣處于起步階段的萌新,但由于水平有限,博客中難免會有一些錯誤出現,有紕漏之處懇請各位大佬不吝賜教!暫時只在csdn這一個平臺進行更新,博客主頁:https://buwenbuhuo.blog.csdn.net/,
PS:由于現在越來越多的人未經本人同意直接爬取博主本人文章,博主在此特別宣告:未經本人允許,禁止轉載!!!
目錄
- 推薦
- 一、分析網頁
- 1.1 嘗試獲取網頁內容
- 1.2 分析網頁(除錯界面發現問題)
- 1.3 分析字體
- 1.4 下載字體
- 二、如何查看woff檔案
- 2.1 下載
- 2.2 打開woff檔案
- 三、python讀取woff
- 四、決議資料
- 4.1 無加密資料決議
- 1. 店鋪名稱、URL及圖片
- 2. 星級
- 4.2 加密資料決議
- 1. 評論數
- 2. 人均消費
- 3. 商品型別
- 4. 區域地址
- 5. 詳細地址
- 五、完整代碼
- 六、運行結果

在上篇文章中我們已經講了js加密,這個需要使用者有基本的js閱讀和除錯能力,但是不一定都解決所有問題,不過可以提供這樣的流程和思路,
那么接下來我們再來看一種加密,css加密,這里我們以大眾點評為例,
推薦

???各位如果想要交流的話,可以加下QQ交流群:974178910,里面有各種你想要的學習資料,?
???歡迎大家關注公眾號【不溫卜火】,關注公眾號即可以提前閱讀又可以獲取各種干貨哦,同時公眾號每滿1024及1024倍數則會抽獎贈送機械鍵盤一份+IT書籍1份喲~?

一、分析網頁
大眾點評:https://www.dianping.com/
1.1 嘗試獲取網頁內容
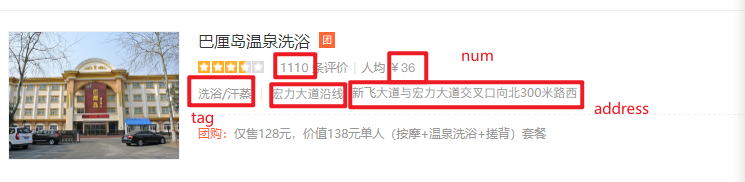
我們打開后隨便輸入個搜索內容,在此我們以洗浴為例,我們可以看到如下圖
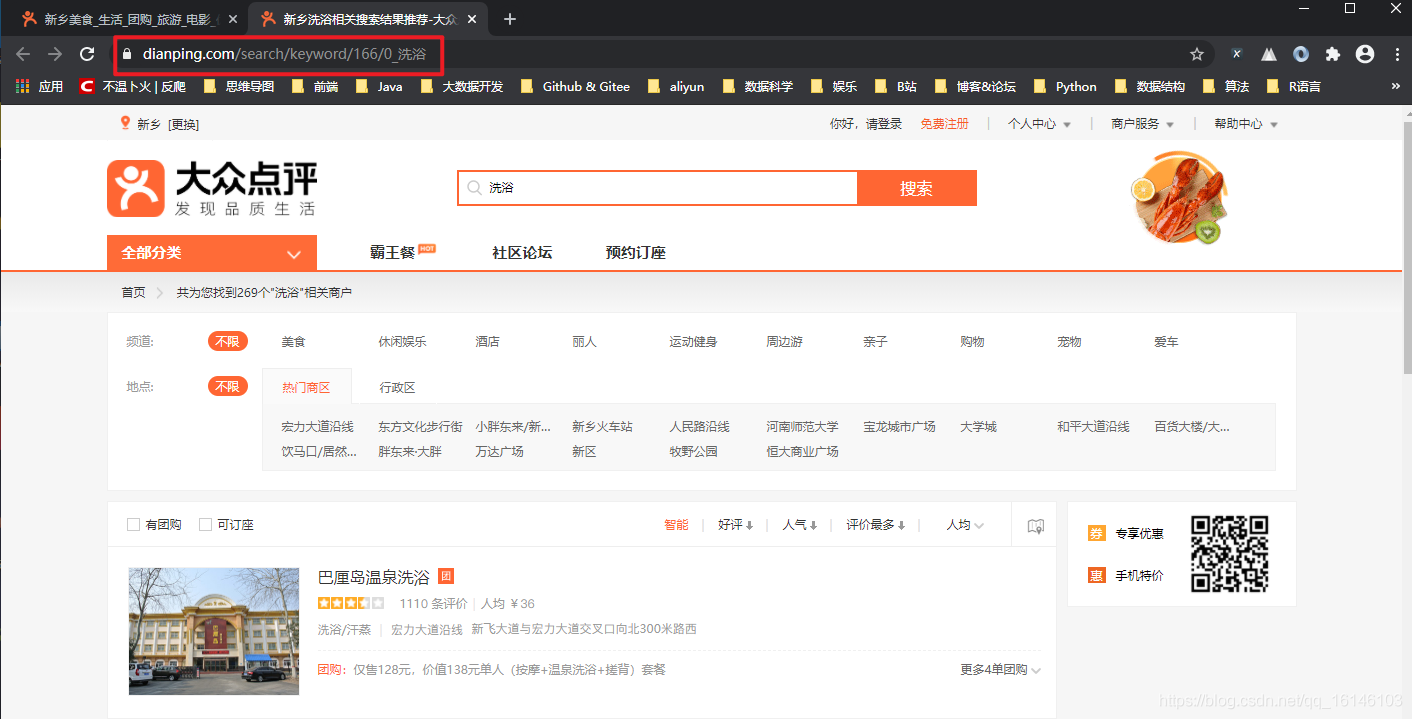
圖中的導航欄我們看到最后的洗浴是中文,那么這個時候我們就要有作為一名爬蟲愛好者的敏銳性,我們如果發現url中存在中文的話就需要立馬想到url編碼和解密,如果不進行解密的話,我們直接使用是無法的到結果的,如果不信的話,博主在此給出測驗,
首先,我們先把URL復制出來
https://www.dianping.com/search/keyword/166/0_%E6%B4%97%E6%B5%B4
我們可以看到中文復制出來就是一堆亂碼,然后我們測驗看能不能把內容輸出出來,代碼如下:
import requests
from urllib.parse import quote,unquote
url = "https://www.dianping.com/search/keyword/166/0_%E6%B4%97%E6%B5%B4"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
response = requests.get(url=url,headers=headers)
print(response.content.decode("utf-8"))
下面我們來看下結果,并查看是否存在有巴厘島溫泉洗浴
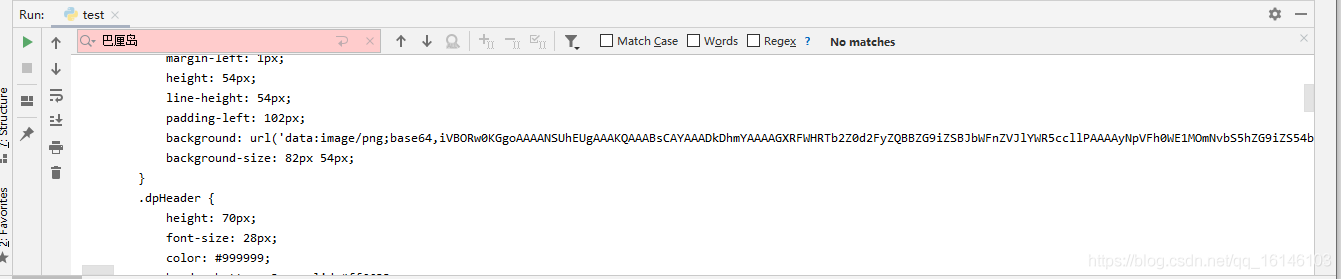
我們通過查看并沒有得到我們所預想的內容,這就代表我們嘗試列印內容失敗了,這個時候我們就需要決議那堆亂碼,想要決議在Python中很簡單,代碼如下:
from urllib.parse import quote,unquote
wd = "洗浴"
print(quote(wd))
print(unquote("%E6%B4%97%E6%B5%B4"))

🆗,知道如此,下面我們就開始再次嘗試獲取頁面內容,代碼如下:
import requests
from urllib.parse import quote,unquote
wd = "洗浴"
url = "https://www.dianping.com/search/keyword/166/0_{}".format(quote(wd))
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36",
"Cookie": "cy=166; cye=xinxiang; _lxsdk_cuid=1751ad609f6c8-0dcdc7e6277655-c781f38-1fa400-1751ad609f7c8; _lxsdk=1751ad609f6c8-0dcdc7e6277655-c781f38-1fa400-1751ad609f7c8; _hc.v=70a91160-e474-cf3e-0698-45733f3ee3c3.1602473037; s_ViewType=10; fspop=test; Hm_lvt_602b80cf8079ae6591966cc70a3940e7=1602473037,1602492673,1603287877,1603414224; _lx_utm=utm_source%3Dyoudao%26utm_medium%3Dorganic; Hm_lpvt_602b80cf8079ae6591966cc70a3940e7=1603415295; _lxsdk_s=175533f654a-5e4-832-9d2%7C%7CNaN"
}
response = requests.get(url=url,headers=headers)
print(response.content.decode("utf-8"))
下面看能不能獲取到內容
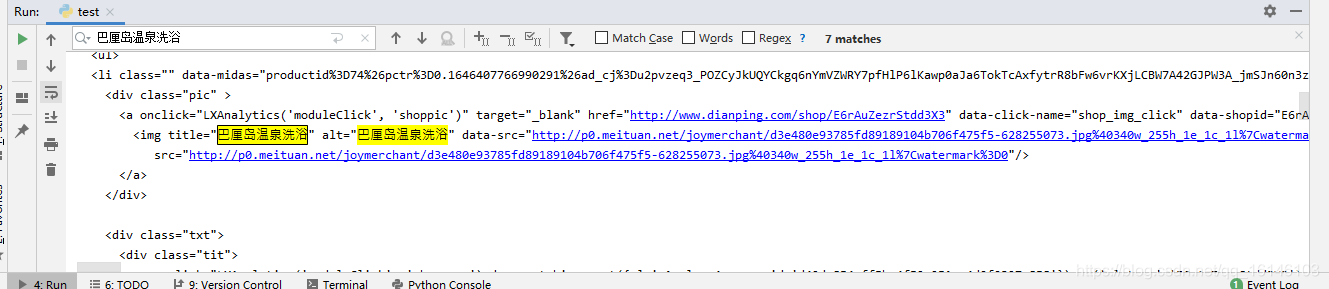
我們可以看到,全部內容我們已經能夠獲取到了,
1.2 分析網頁(除錯界面發現問題)
我們既然已經能列印出網頁的所有內容,那么接下來我們就可以分析網頁了,
下面我們分別進行分析:
- 1. 名稱(無加密)

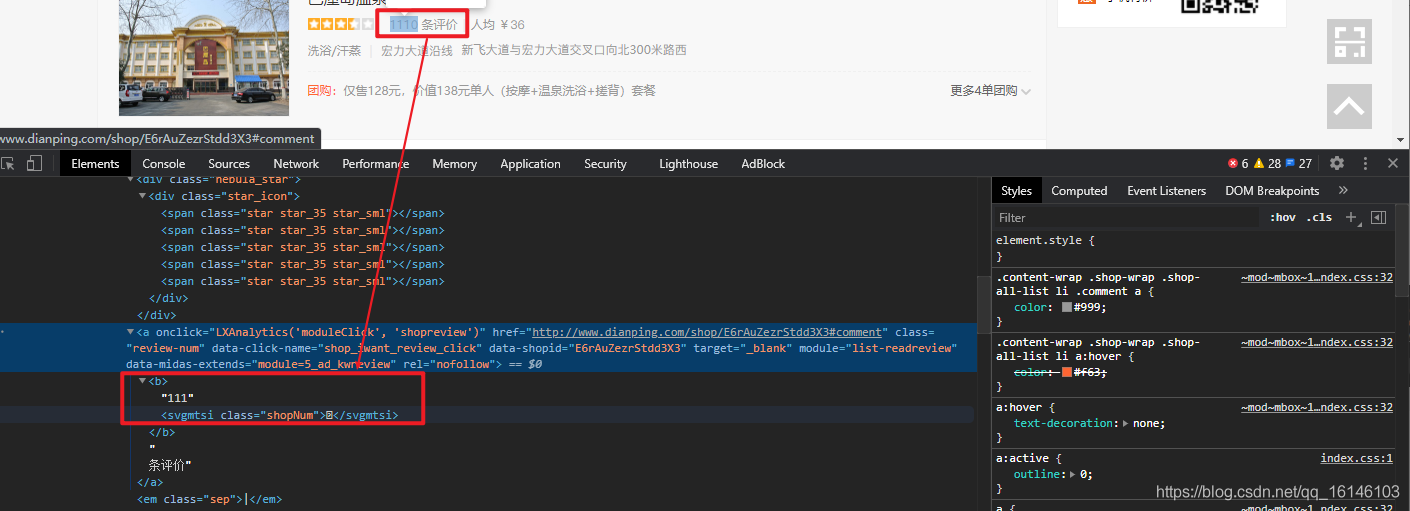
- 2. 評價數(有加密)
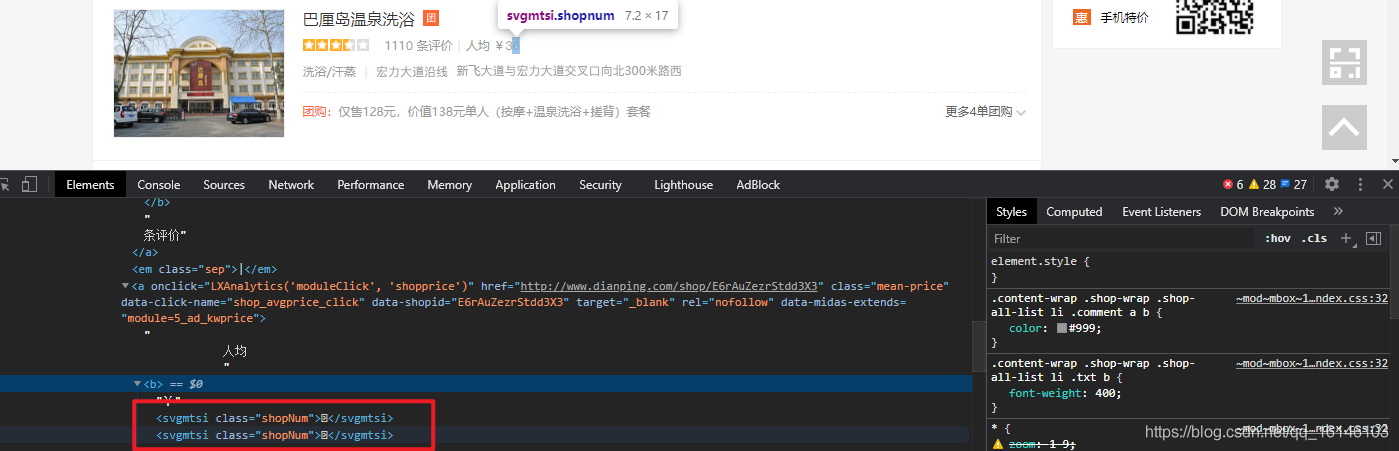
- 3. 人均消費(有加密)
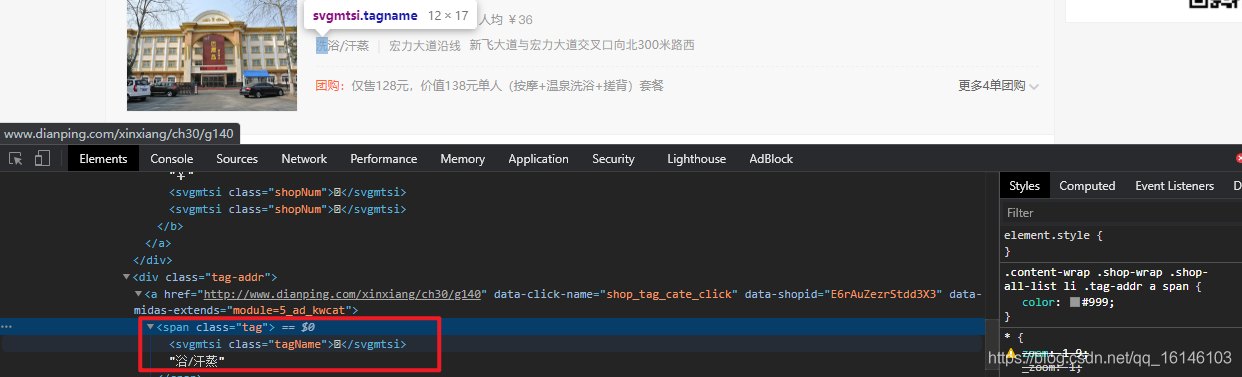
- 3. 型別(有加密)
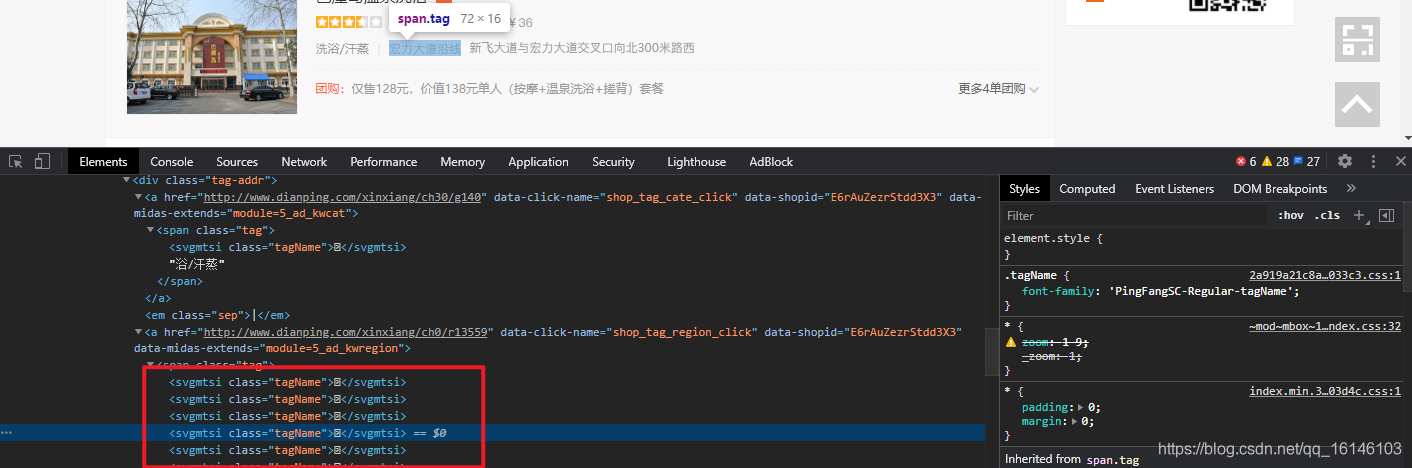
- 4. 區域地址(有加密)
- 5. 詳細地址(有加密)
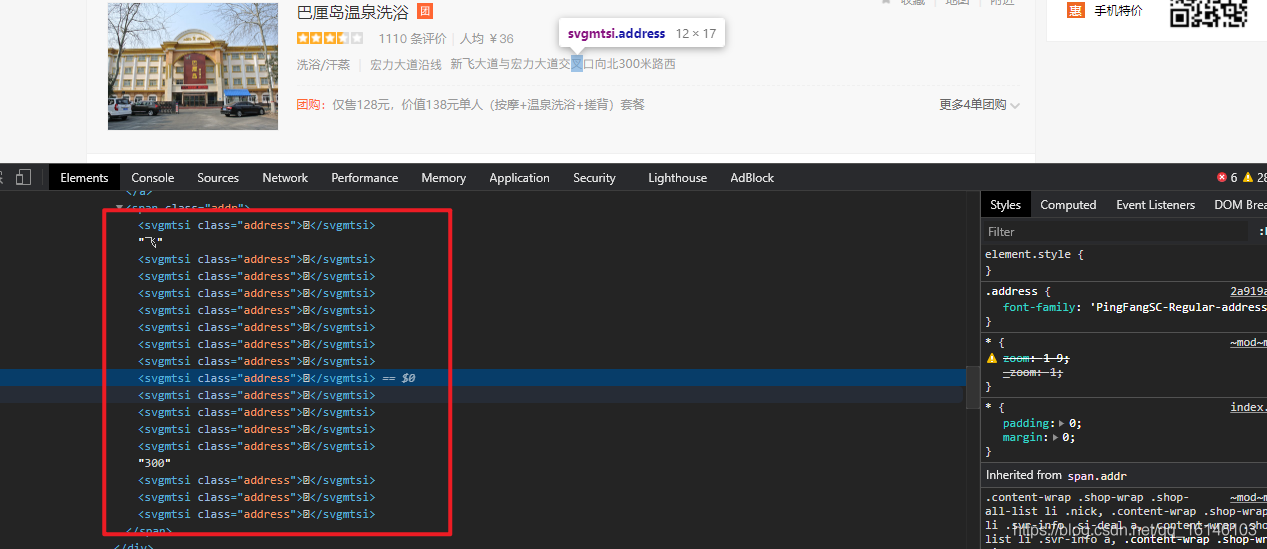
通過上述的查看網頁,我們發現這些資訊中,有的是正常的漢字,而有的則是未知的符號,這個時候我們在回應內容中再找一下,看看到底是什么東西,
我們這里以查找洗浴/汗蒸為例
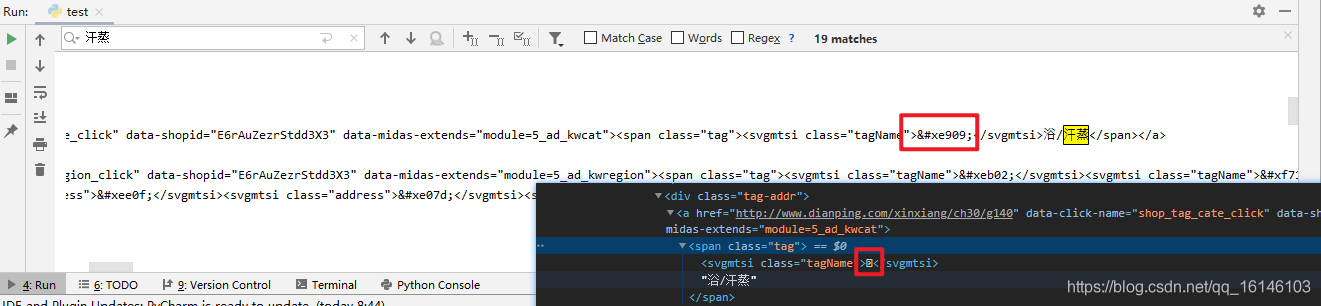
1.3 分析字體
我們通過開發者選項看到的特殊符號其實是一種字體,是大眾點評專門加密的一種CSS字體,
我們先把此部分的CSS復制出來!
@font-face {
font-family: "PingFangSC-Regular-reviewTag";
src: url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/f9935be8.eot");
src: url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/f9935be8.eot?#iefix") format("embedded-opentype"),url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/f9935be8.woff");
}
.reviewTag {
font-family: 'PingFangSC-Regular-reviewTag';
}
@font-face {
font-family: "PingFangSC-Regular-shopNum";
src: url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/c884993d.eot");
src: url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/c884993d.eot?#iefix") format("embedded-opentype"),url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/c884993d.woff");
}
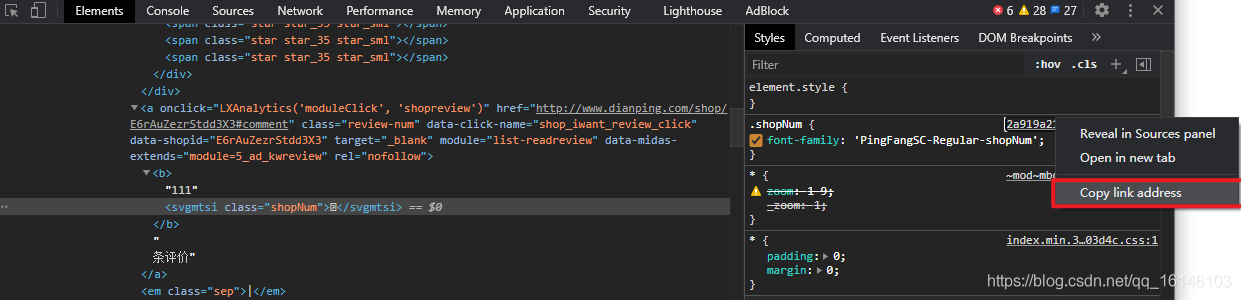
.shopNum {
font-family: 'PingFangSC-Regular-shopNum';
}
@font-face {
font-family: "PingFangSC-Regular-address";
src: url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/c884993d.eot");
src: url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/c884993d.eot?#iefix") format("embedded-opentype"),url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/c884993d.woff");
}
.address {
font-family: 'PingFangSC-Regular-address';
}
@font-face {
font-family: "PingFangSC-Regular-tagName";
src: url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/f58a3e31.eot");
src: url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/f58a3e31.eot?#iefix") format("embedded-opentype"),url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/f58a3e31.woff");
}
.tagName {
font-family: 'PingFangSC-Regular-tagName';
}
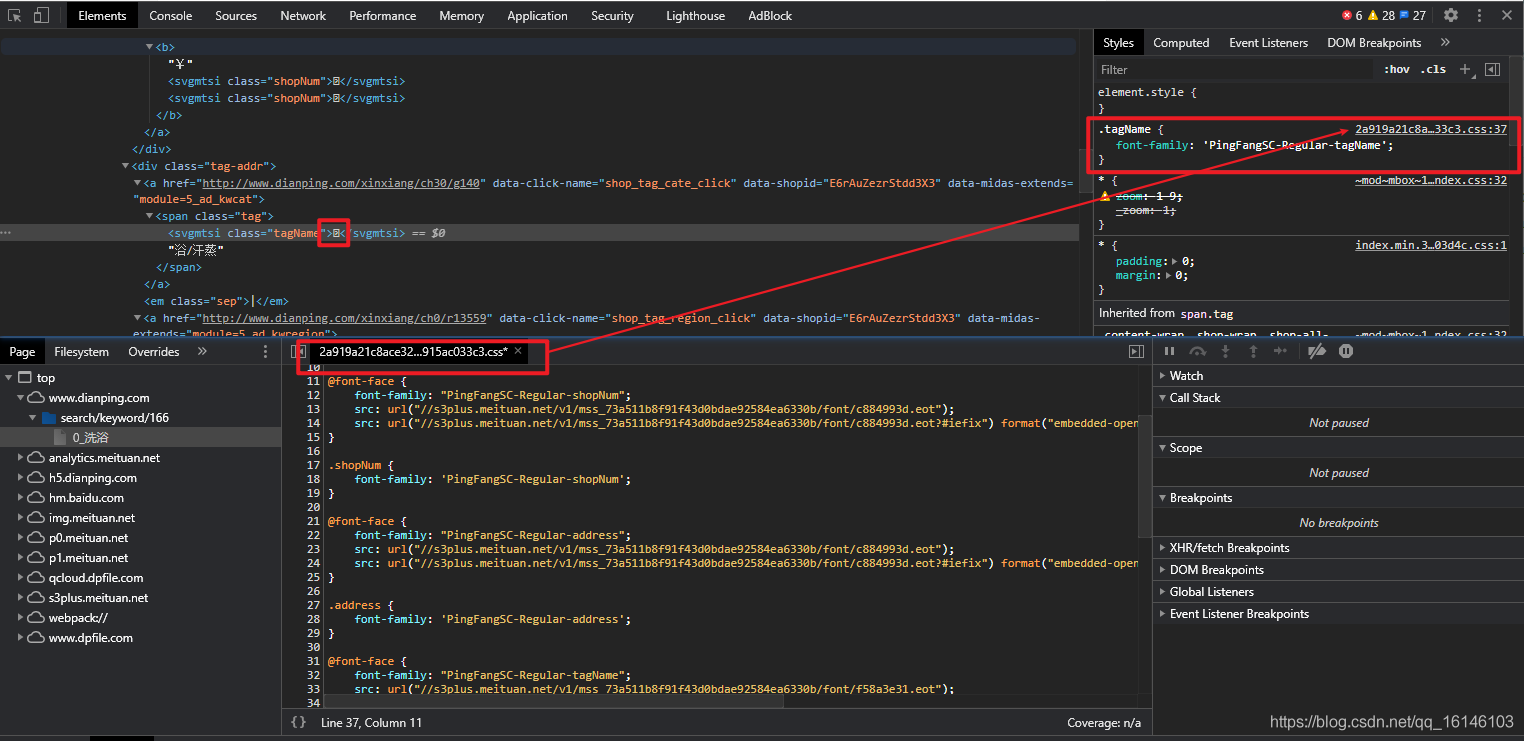
通過上述原始碼與圖片對比,我們可以看到雖然有四個woff檔案(woff檔案是字體檔案),但是有兩個是重復的,所以大眾點評的自定義字體初步判斷為三個,
1.4 下載字體
- 1. 我們先把css復制下來
url = "https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/b75a2a536f46287f7538c3a0b09f7e9d.css"
- 2. 嘗試列印下
import requests
url = "https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/b75a2a536f46287f7538c3a0b09f7e9d.css"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
response = requests.get(url=url, headers=headers)
content = response.content.decode("utf-8")
print(content)

- 3. 正則決議并列印
woff_url_list = re.findall(r'url\("(//s3plus\.meituan\.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/\w+?\.woff)"\)',
content)
print(woff_url_list)
for i in woff_url_list:
print(i)

- 4. 拼接字串并列印
woff_url_list = map(lambda x: "https:" + x, woff_url_list)
for woff_url in woff_url_list:
response = requests.get(url=woff_url, headers=headers)
content = response.content
filepath = woff_url.split("/")[-1]
with open(filepath,"wb") as file:
file.write(content)

二、如何查看woff檔案
如何打開woff檔案呢?之前百度提供了字體介面可以打開woff,但是現在暫時不能使用了,那可以使用fontcreator工具打開,先下載fontcreator,然后打開woff,
2.1 下載
下載地址:http://www.32r.com/soft/42836.html
注意:此下載鏈接并非官網,如果對此有疑惑的同學,可以自行下載其他,學長用的是這個,
如果不會使用可以查看幫助檔案,
2.2 打開woff檔案
我們首先需要找到我們下載woff檔案的目錄,
然后file—>open—>下載存盤檔案夾—>選中woff檔案—>打開
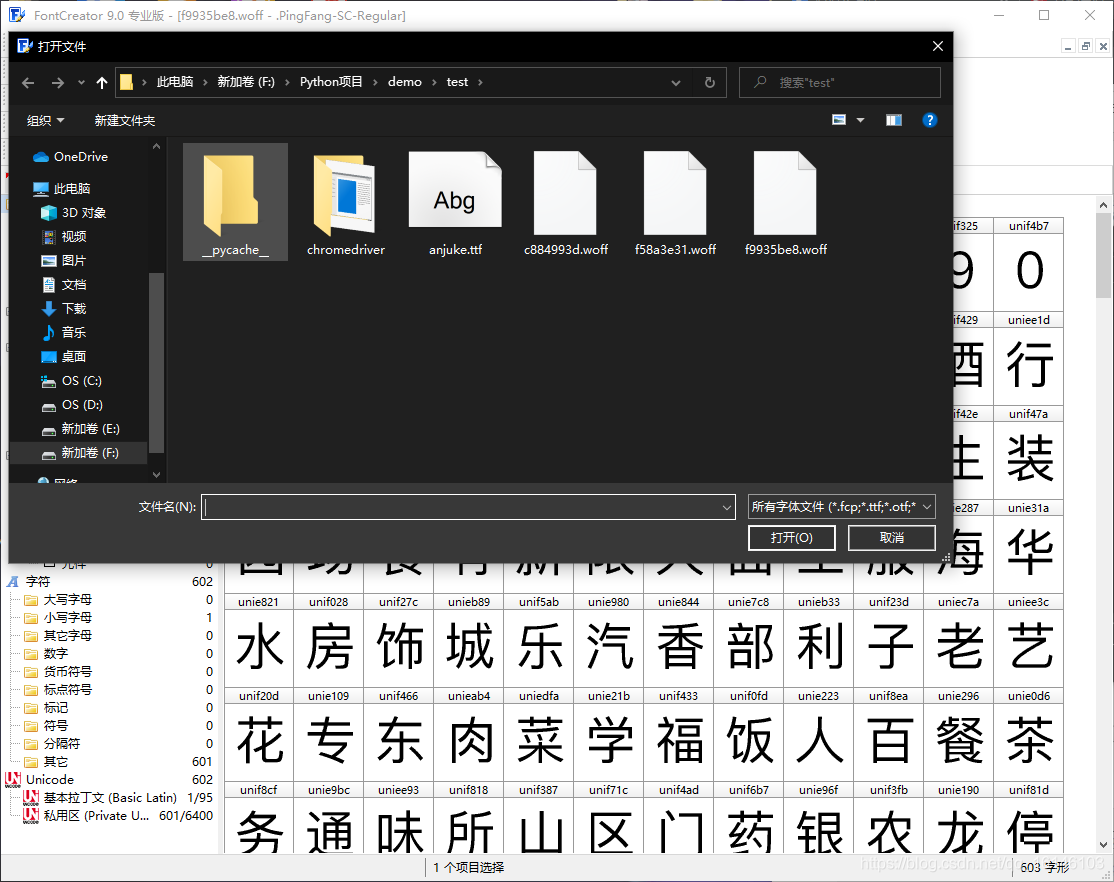
打開之后的樣子如下圖:
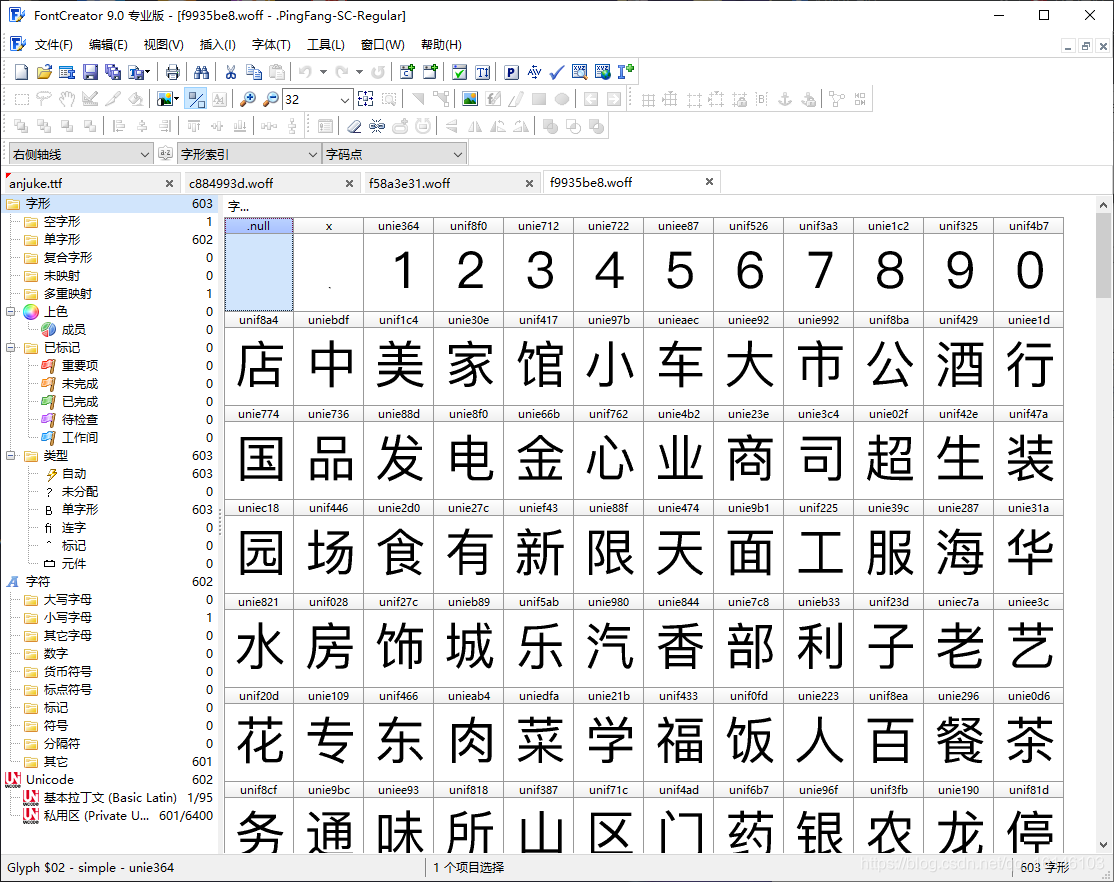
下面我們通過動圖來看一下三個檔案的區別:
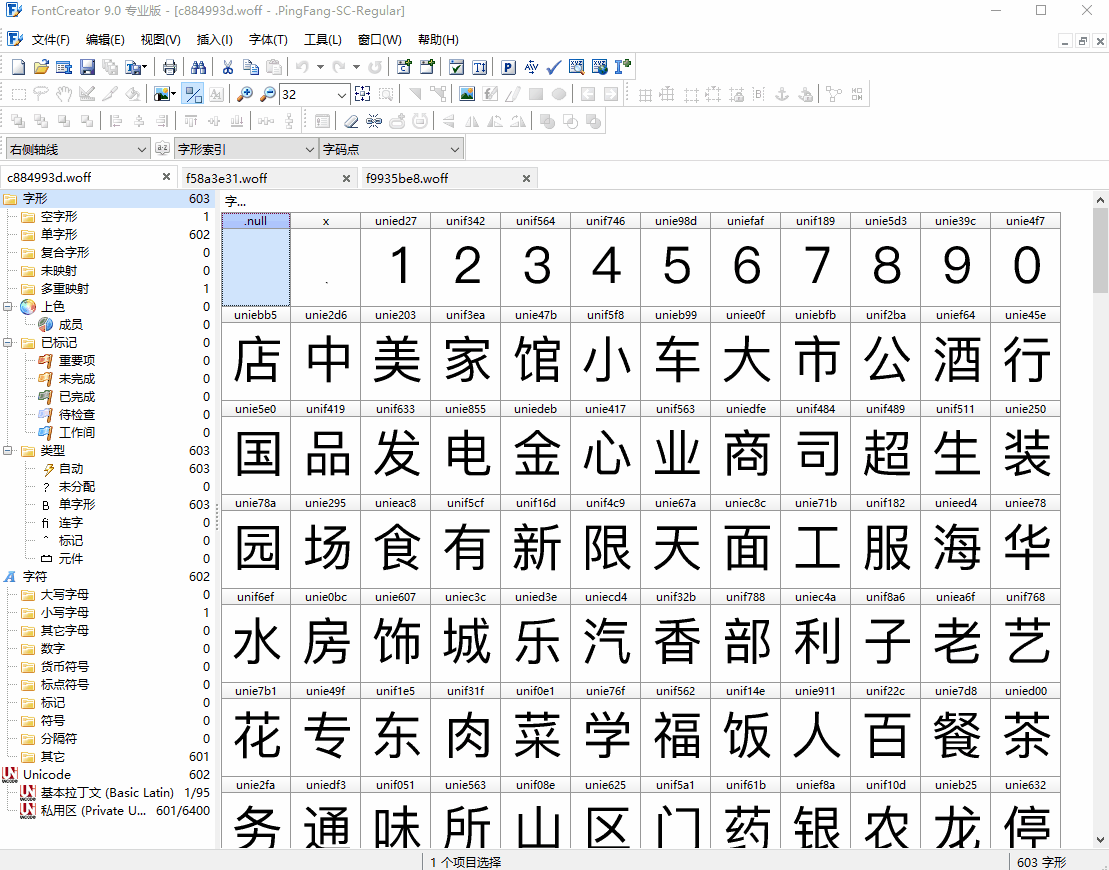
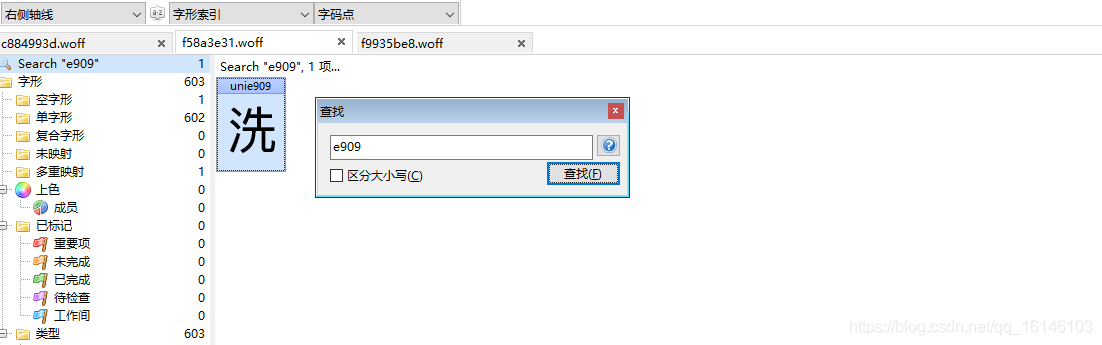
打開這個3個woff檔案發現文字內容和順序是一樣的,只是上面的uni符號不同,
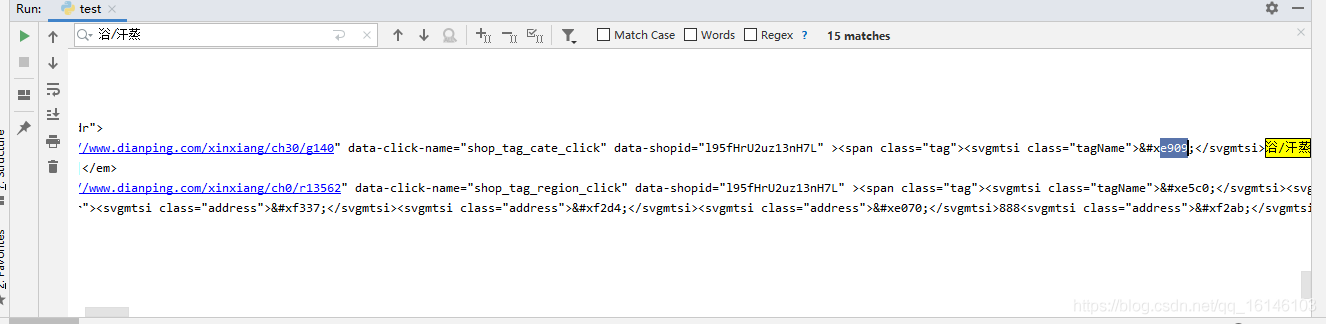
首先我們先來確定一下這個加密字體所對應的檔案名稱
通過上圖我們可以看到此部分對應的檔案名為:f58a3e31
woff檔案可以理解為鍵值對,鍵是uni+16進制的字符,值就是字體,復制回應內容中的字體,然后去woff,ctrl+f尋找,下面我們就來看一下,
三、python讀取woff
現在思路就是爬取網頁中的資訊,然后去對應的wolf檔案中去找對應的字體,那現在有個問題,woff檔案怎么轉鍵值對,目前沒有好的辦法,只能自己將字體一個一個復制出來,這里給大家準備一個復制出來整理之后的:
word_string='1234567890店中美家館小車大市公酒行國品發電金心業商司超生裝園場食有新限天面工服海華水房飾城樂汽香部利子老葉訓專東肉菜學福飯人百餐茶務通味所山區門藥銀農龍停尚安廣鑫一容動南具源興鮮記時機烤文康信果陽理鍋寶達地兒衣特產西批坊州牛佳化五米修愛北養賣建材三會雞室紅站德王光名麗油院堂燒江社合星貨型村自科快便日民營和活童明器煙育賓精屋經居莊石順林爾縣手廳銷用好客火雅盛體旅之鞋辣作粉包樓校魚平彩上吧保永萬物教吃設醫正造豐健點湯網慶技斯洗料配匯木緣加麻聯衛川泰色世方寓風幼羊燙來高廠蘭阿貝皮全女拉成云維貿道術運都口博河瑞宏京際路祥青鎮廚培力惠連馬鴻鋼訓影甲助窗布富牌頭四多妝吉苑沙恒隆春干餅氏里二管誠制售嘉長軒雜副清計黃訊太鴨號街交與叉附近層旁對巷棟環省橋湖段鄉廈府鋪內側元購前幢濱處向座下臬鳳港開關景泉塘放昌線灣政步寧解白田町溪十八古雙勝本單同九迎第臺玉錦底后七斜期武嶺松角紀朝峰六振珠局崗洲橫邊濟井辦漢代臨弄團外塔楊鐵浦字年島陵原梅進榮友虹央桂沿事津凱蓮丁秀柳集紫旗張谷的是不了很還個也這我就在以可到錯沒去過感次要比覺看得說常真們但最喜哈么別位能較境非為歡然他挺著價那意種想出員兩推做排實分間甜度起滿給熱完格薦喝等其再幾只現朋候樣直而買于般豆量選奶打每評少算又因情找些份置適什蛋師氣你姐棒試總定啊足級整帶蝦如態且嘗主話強當更板知己無酸讓入啦式笑贊片醬差像提隊走嫩才剛午接重串回晚微周值費性桌拍跟塊調糕'
這里將所有的文字按照順序復制組合成了一個字串,怎么確定順序呢?可以通過python讀取woff,找到對應的字體的順序數字,這樣拿這個數字去字串中通過下標獲取就可以了,
- 1. python讀取woff,需要安裝fonttools
pip install fonttools
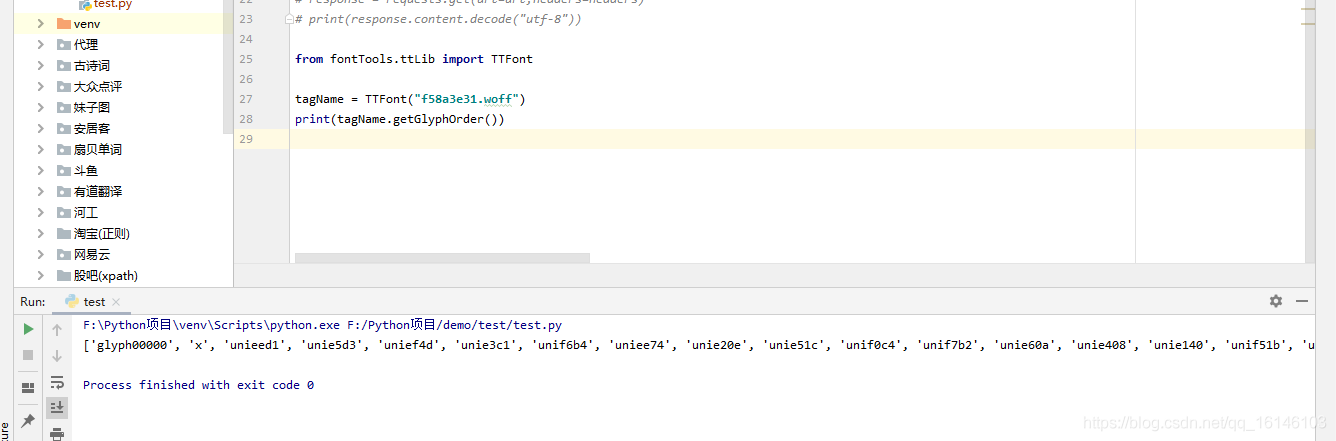
- 2. 使用fonttools讀取woff
from fontTools.ttLib import TTFont
tagName = TTFont("f58a3e31.woff")
print(tagName.getGlyphOrder())

接下來利用tagName.getGlyphOrder()結果為鍵和word_string為值,組成對應的字典:
from fontTools.ttLib import TTFont
tagName = TTFont("f58a3e31.woff")
print(tagName.getGlyphOrder())
tag_name_list = tagName.getGlyphOrder()
word_string ='1234567890店中美家館小車大市公酒行國品發電金心業商司超生裝園場食有新限天面工服海華水房飾城樂汽香部利子老葉訓專東肉菜學福飯人百餐茶務通味所山區門藥銀農龍停尚安廣鑫一容動南具源興鮮記時機烤文康信果陽理鍋寶達地兒衣特產西批坊州牛佳化五米修愛北養賣建材三會雞室紅站德王光名麗油院堂燒江社合星貨型村自科快便日民營和活童明器煙育賓精屋經居莊石順林爾縣手廳銷用好客火雅盛體旅之鞋辣作粉包樓校魚平彩上吧保永萬物教吃設醫正造豐健點湯網慶技斯洗料配匯木緣加麻聯衛川泰色世方寓風幼羊燙來高廠蘭阿貝皮全女拉成云維貿道術運都口博河瑞宏京際路祥青鎮廚培力惠連馬鴻鋼訓影甲助窗布富牌頭四多妝吉苑沙恒隆春干餅氏里二管誠制售嘉長軒雜副清計黃訊太鴨號街交與叉附近層旁對巷棟環省橋湖段鄉廈府鋪內側元購前幢濱處向座下臬鳳港開關景泉塘放昌線灣政步寧解白田町溪十八古雙勝本單同九迎第臺玉錦底后七斜期武嶺松角紀朝峰六振珠局崗洲橫邊濟井辦漢代臨弄團外塔楊鐵浦字年島陵原梅進榮友虹央桂沿事津凱蓮丁秀柳集紫旗張谷的是不了很還個也這我就在以可到錯沒去過感次要比覺看得說常真們但最喜哈么別位能較境非為歡然他挺著價那意種想出員兩推做排實分間甜度起滿給熱完格薦喝等其再幾只現朋候樣直而買于般豆量選奶打每評少算又因情找些份置適什蛋師氣你姐棒試總定啊足級整帶蝦如態且嘗主話強當更板知己無酸讓入啦式笑贊片醬差像提隊走嫩才剛午接重串回晚微周值費性桌拍跟塊調糕'
print(len(tag_name_list))
print(len(word_string))
tag_name_dict = {
tag_name_list[0]:"",
tag_name_list[1]:".",
}
for index,value in enumerate(word_string):
tag_name_dict[tag_name_list[index+2][3:]]=value
print(tag_name_dict)
print(tag_name_dict.get("e909"))

那接下來就可以找到回應資料中的符號去字典中找到文字就可以了,
四、決議資料
🆗,前面我們已經把字體分析并下載下載下來了,不僅如此,我們還發現我們想要爬取的資料包括加密和未加密,那么接下來我們就需要分別進行判定,
首先我們先分析下網頁的整體結構,
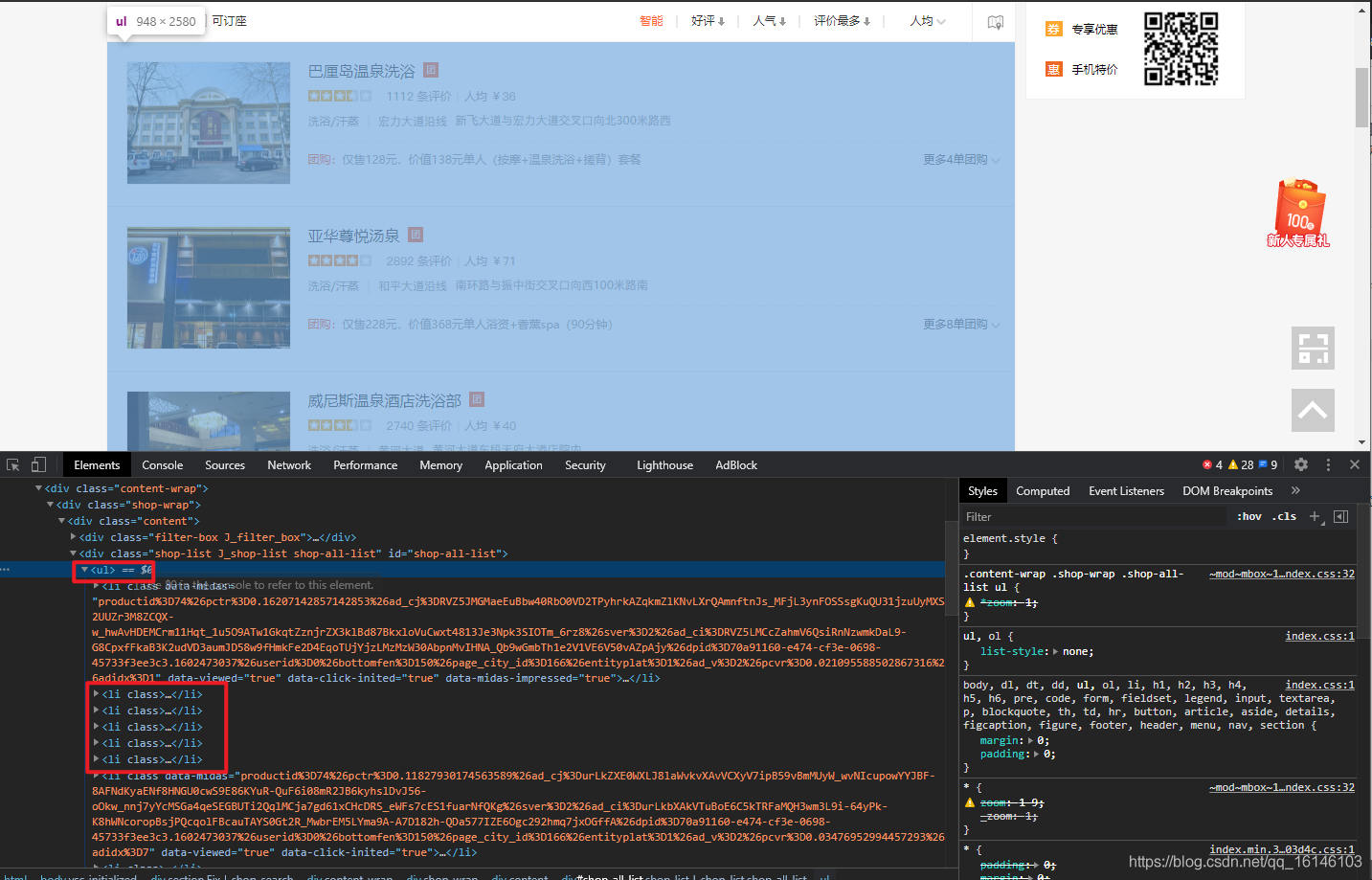
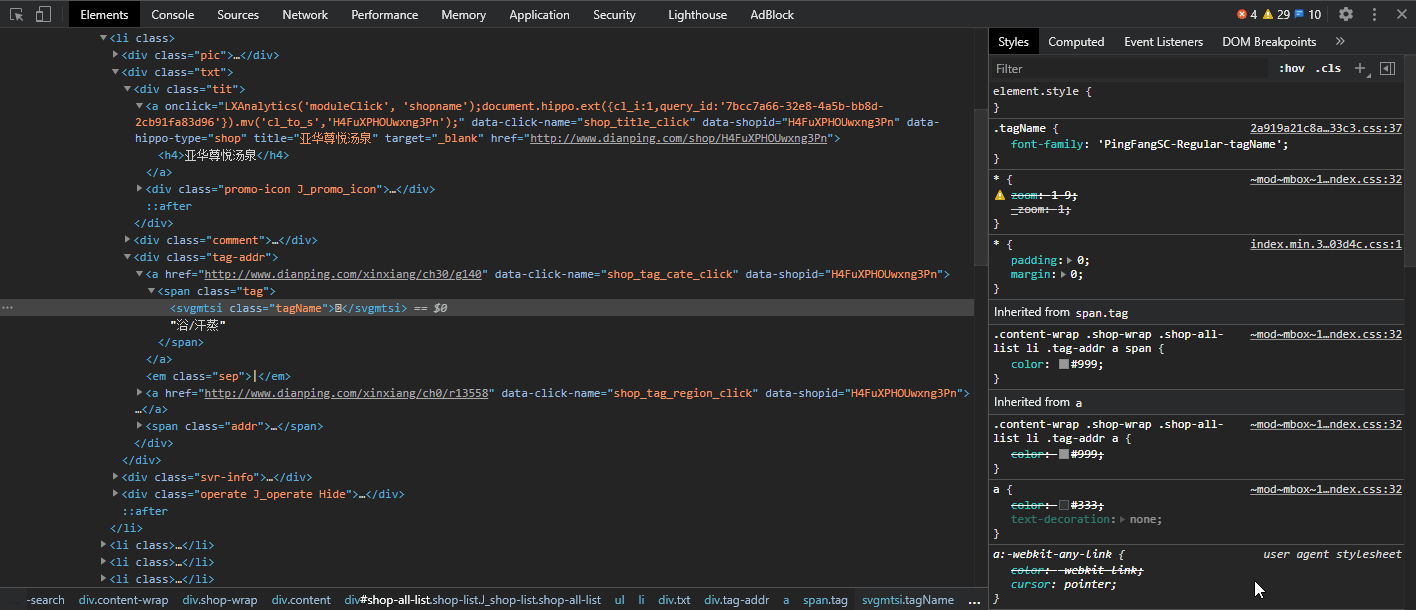
在進行決議之前,我們先對加密的內容進行字符的替換,這樣是為了避免決議css加密資料獲取后是unicode字串,
html = parse_url(data_url).decode("utf-8")
html = re.sub(r"&#x(\w+?);", r"*\1*", html)
至于為什么使用"&#x(\w+?);",我們可以看下圖:
那么現在,我們就可以通過xpath進行嘗試決議下,
xpath_obj = parse_html(html)
li_list = xpath_obj.xpath('//*[@id="shop-all-list"]/ul/li')
print(li_list)
print(len(li_list))
我們先來列印下所有的li_list以及其長度

通過列印,我們發現一頁共有15個資料,我們現在查看下網頁是不是有15個商品資訊,
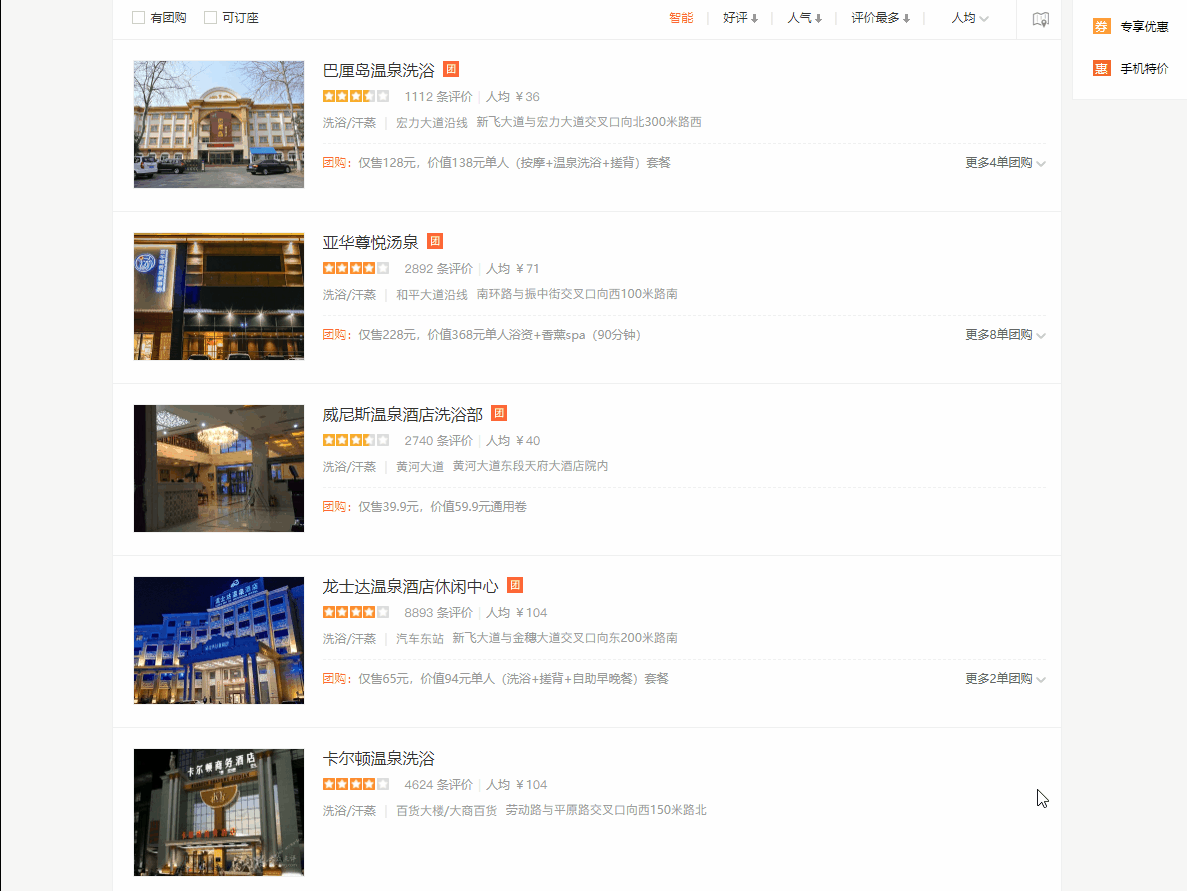
我們發現是對應的,那么接下來,我們就可以進行xpath決議了,
4.1 無加密資料決議
1. 店鋪名稱、URL及圖片
-
1. 查看圖片
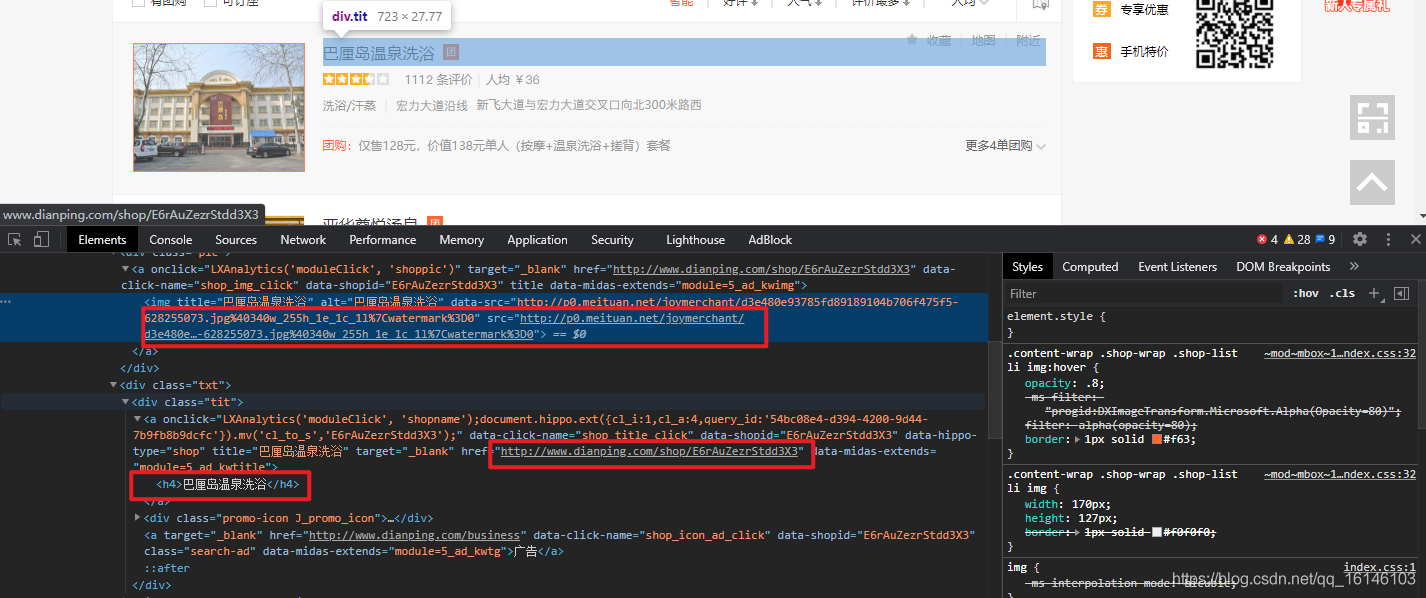
根據上圖,我們可以看到這些都是沒有加密的,那么這些都可以直接獲取的, -
2. xpath決議



-
3. 代碼實作
for li in li_list:
item = {}
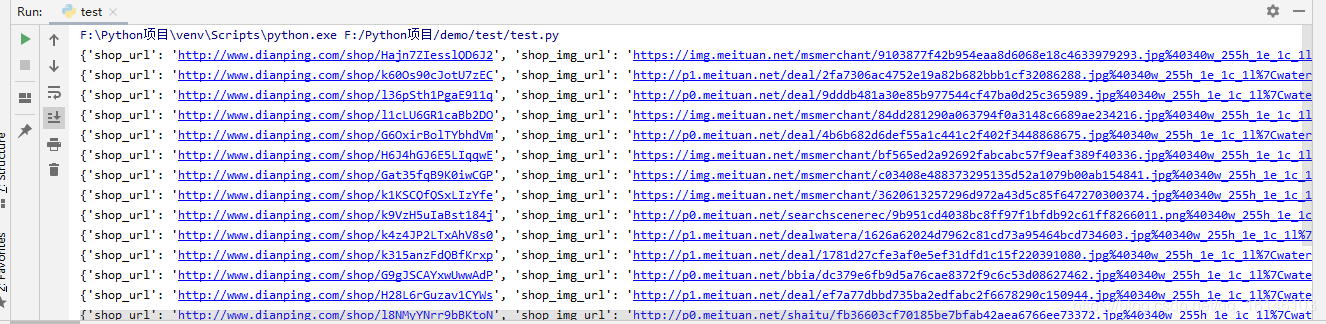
item["shop_url"] = li.xpath("./div[1]/a/@href")[0] # 店鋪的url
item["shop_img_url"] = li.xpath("./div[1]/a/img/@src")[0] # 店鋪圖片的url
item["shop_name"] = li.xpath("./div[1]/a/img/@title")[0] # 店鋪名稱
print(item)
- 4. 查看結果
2. 星級
- 1. 分析
我們首先先來看下網頁:
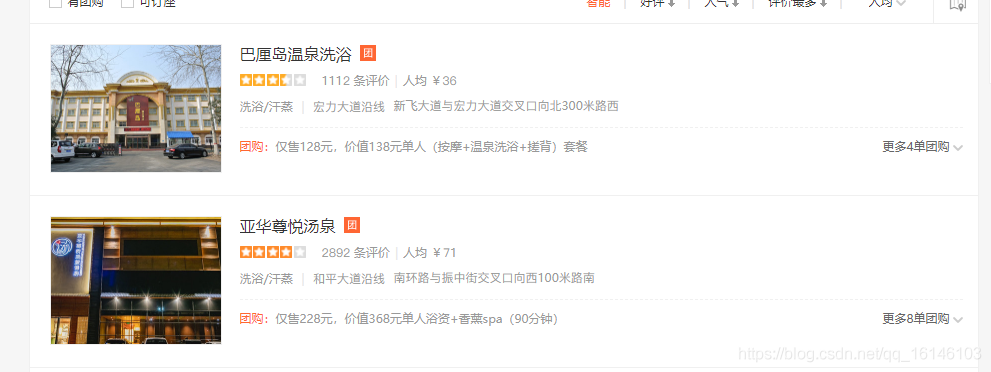
接下來我們看一下star的網頁原始碼

光看一個明白不了什么,那么接下來繼續查看下一個star
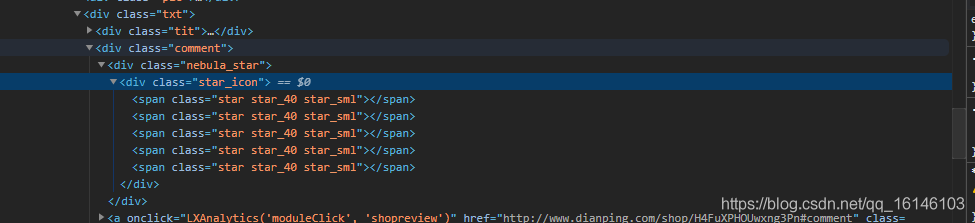
🆗,我們這就知道了,數字對應的是星級,10個數為一個星,
- 2. 代碼實作
經過上述的分析,我們不難發現此部分只需截取數字即可
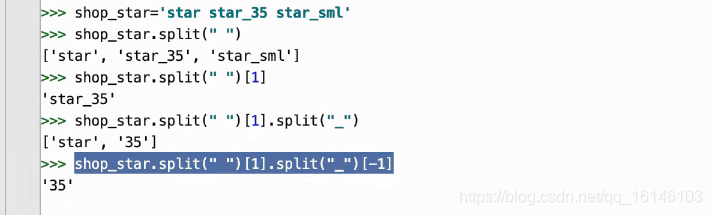
下面直接代碼實作
star_class = li.xpath('.//*[@class="star_icon"]/span[1]/@class')[0]
item["shop_star"] = star_class.split(" ")[1].split("_")[-1] # 店鋪評分
print(item)
4.2 加密資料決議
在講解加密資料決議之前,我們要先來說一下我們剛開始替換的特殊字符,也就是下面的這行代碼
html = re.sub(r"&#x(\w+?);", r"*\1*", html) # 替換特殊字符,避免決議css加密資料獲取后是unicode字串
我們剛開始替換的本意只是為了避免決議css加密資料獲取后是unicode字串,但是這個時候我們需要的正好是unicode,那么我們就需要對其進行解密,
解密的方式也很簡單,那就是對添加的*進行洗掉,
# 如果i是以*開頭和結尾的那么要把*去掉并加上uni
get_word(class_name, "uni" + i.strip("*")) if (i.startswith("*") and i.endswith("*")) else i for i in
li.xpath('./div[2]/div[2]/a[1]/b//text()')
通過上述代碼完成解密作業
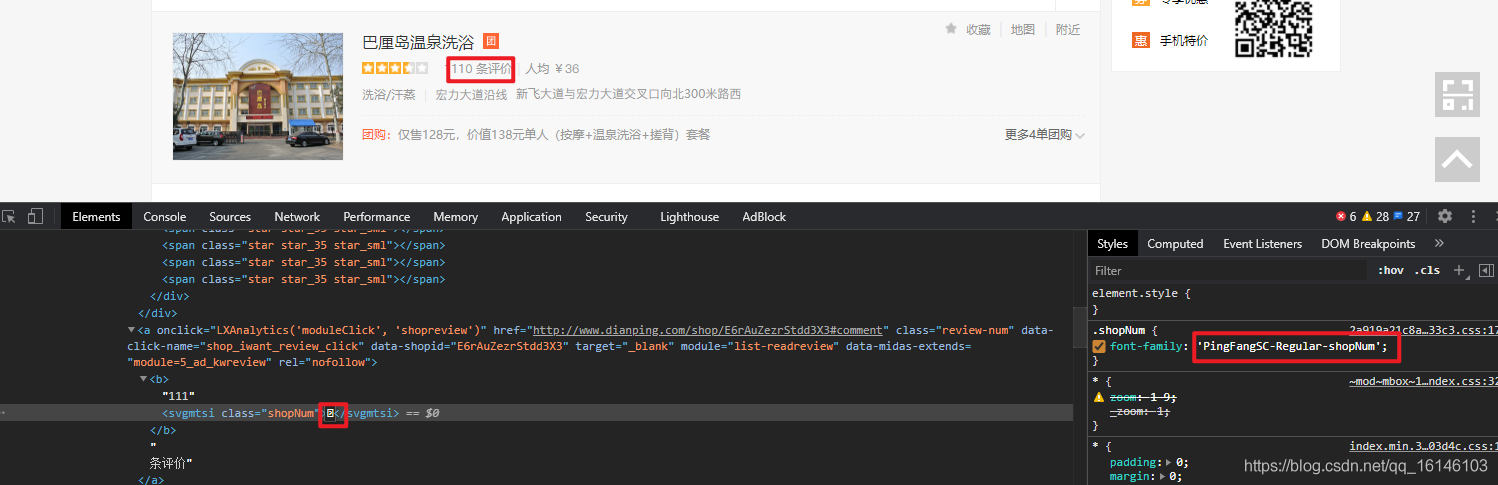
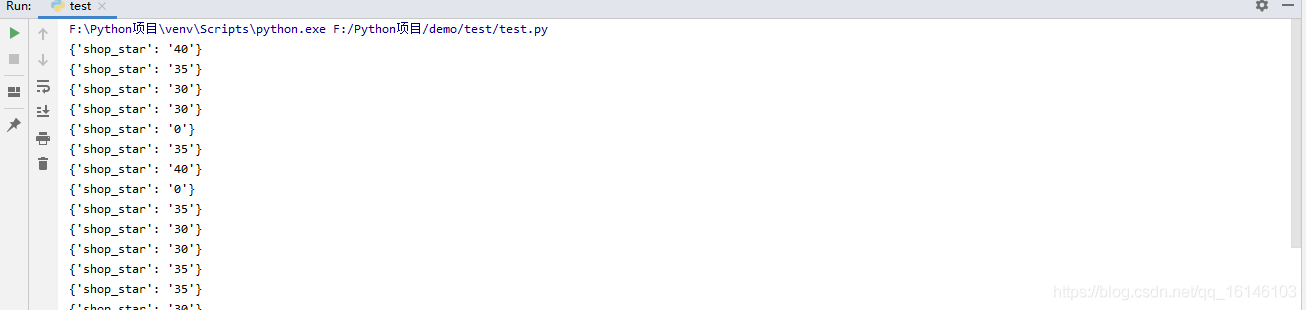
1. 評論數
class_name = li.xpath('./div[2]/div[2]/a[1]/b/svgmtsi/@class')
if class_name: # 有加密
class_name = class_name[0]
item["shop_comment_num"] = "".join(
[get_word(class_name, "uni" + i.strip("*")) if (i.startswith("*") and i.endswith("*")) else i for i in
li.xpath('./div[2]/div[2]/a[1]/b//text()')])
else: # 沒有加密
item["shop_comment_num"] = "".join(li.xpath('./div[2]/div[2]/a[1]/b//text()'))#評論數
print(item)
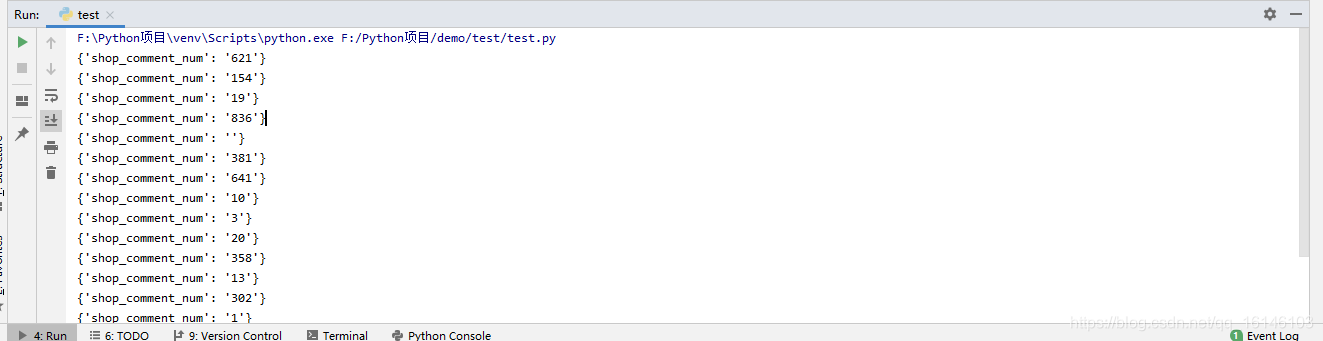
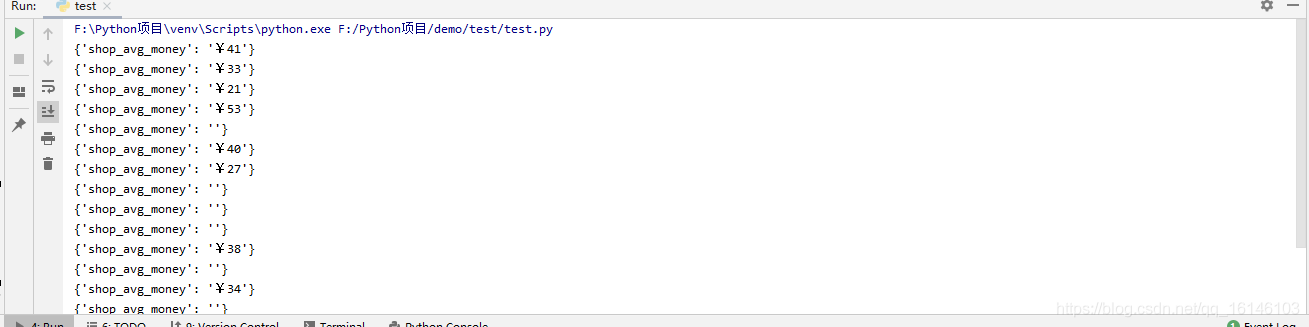
2. 人均消費
class_name = li.xpath('./div[2]/div[2]/a[2]/b/svgmtsi/@class')
if class_name: # 有加密
class_name = class_name[0]
item["shop_avg_money"] = "".join(
[get_word(class_name, "uni" + i.strip("*")) if (i.startswith("*") and i.endswith("*")) else i for i in
li.xpath('./div[2]/div[2]/a[2]/b//text()')])
else: # 沒有加密
item["shop_avg_money"] = "".join(li.xpath('./div[2]/div[2]/a[2]/b//text()'))#人均消費
3. 商品型別
class_name = li.xpath('./div[2]/div[3]/a[1]/span/svgmtsi/@class')
if class_name:
class_name = class_name[0]
item["shop_type"] = "".join(
[get_word(class_name, "uni" + i.strip("*")) if (i.startswith("*") and i.endswith("*")) else i for i in
li.xpath('./div[2]/div[3]/a[1]/span//text()')])
else:
item["shop_type"] = "".join(li.xpath('./div[2]/div[3]/a[1]/span//text()'))
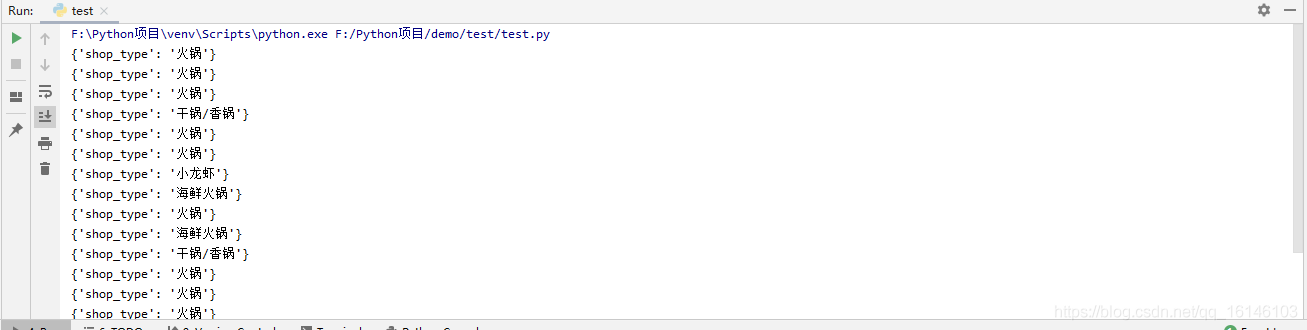
4. 區域地址
class_name = li.xpath('./div[2]/div[3]/a[2]/span/svgmtsi/@class')
if class_name:
class_name = class_name[0]
item["shop_address1"] = "".join(
[get_word(class_name, "uni" + i.strip("*")) if (i.startswith("*") and i.endswith("*")) else i for i in
li.xpath('./div[2]/div[3]/a[2]/span//text()')])#區域地址
else:
item["shop_address1"] = "".join(li.xpath('./div[2]/div[3]/a[2]/span//text()'))
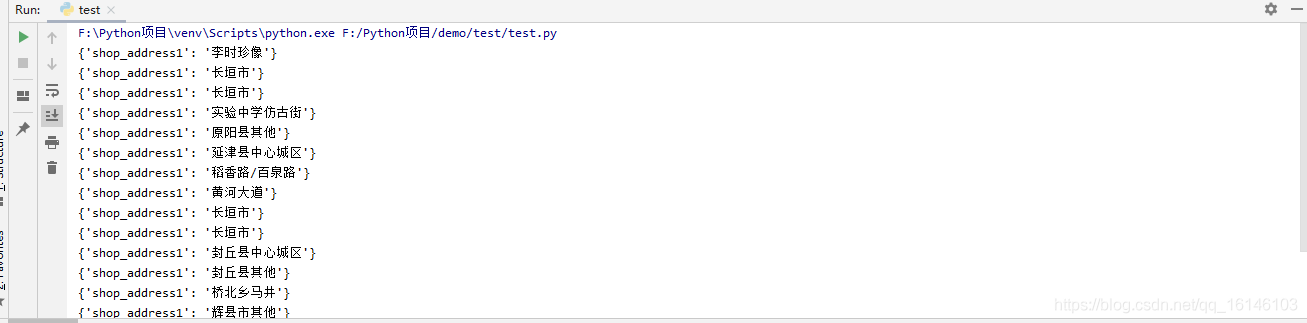
5. 詳細地址
class_name = li.xpath('./div[2]/div[3]/span[1]/svgmtsi/@class')
if class_name:
class_name = class_name[0]
item["shop_address2"] = "".join(
[get_word(class_name, "uni" + i.strip("*")) if (i.startswith("*") and i.endswith("*")) else i for i in
li.xpath('./div[2]/div[3]/span[1]//text()')])
else:
item["shop_address2"] = "".join(li.xpath('./div[2]/div[3]/span[1]//text()'))#詳細地址
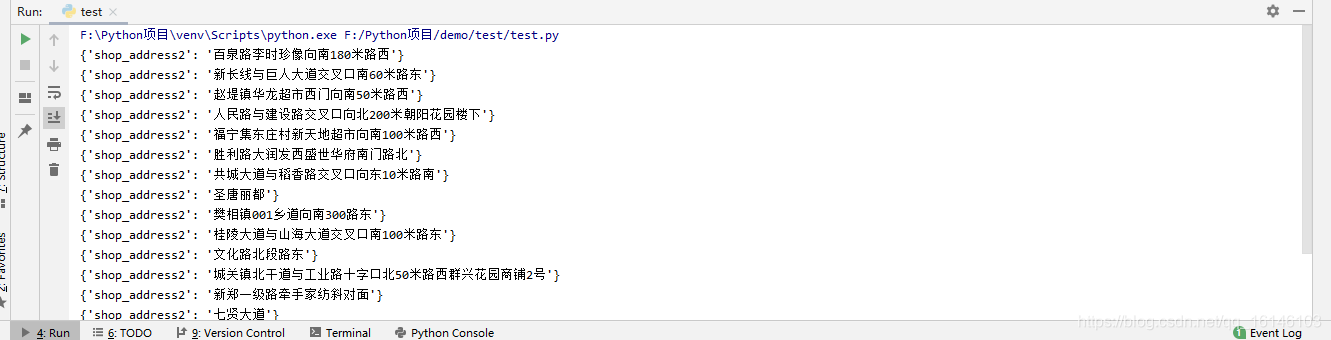
五、完整代碼
#!/usr/bin/env python
# encoding: utf-8
'''
@author 李華鑫
@create 2020-10-21 18:06
Mycsdn:https://buwenbuhuo.blog.csdn.net/
@contact: 459804692@qq.com
@software: Pycharm
@file: test.py
@Version:1.0
'''
import requests
import re
import csv
from urllib.parse import quote, unquote
from fontTools.ttLib import TTFont
from lxml import etree
kw = "大蝦"
page = 3
data_url = "https://www.dianping.com/search/keyword/166/0_{}/p{}".format(quote(kw),page)
css_url = "https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/c98b2eff300998c5ead0806616392718.css"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
#這里使用的是登錄成功后的cookie值,完成翻頁
"cookie":"cy=166; cye=xinxiang; _lxsdk_cuid=1751ad609f6c8-0dcdc7e6277655-c781f38-1fa400-1751ad609f7c8; _lxsdk=1751ad609f6c8-0dcdc7e6277655-c781f38-1fa400-1751ad609f7c8; _hc.v=70a91160-e474-cf3e-0698-45733f3ee3c3.1602473037; s_ViewType=10; fspop=test; _lx_utm=utm_source%3Dyoudao%26utm_medium%3Dorganic; thirdtoken=5aa19437-0035-4674-9190-c70e96879040; _thirdu.c=59d3f0429670580a7dcc7ec862021251; dplet=4808119962e3031ed4a6fd4245c9168d; dper=ca44d7e7084b3d21408f5d00fb216294c5c5f5a1ddf194a2463f8dabdc7d33697aaf6c4716cf66ad59f619083f368f4749284d8abaea2c63ed11302fb7b39543683c95c9742debc6e3d573faa6c809f007f8d43a9fc8ad7062daca33618146a8; ll=7fd06e815b796be3df069dec7836c3df; ua=dpuser_1347248252; ctu=920dfc17d3681bdbfe4ae1e91aa8c930f5fceac5db954e051167aafa53f3e29d; Hm_lvt_602b80cf8079ae6591966cc70a3940e7=1603440682,1603452564,1603454915,1603454940; Hm_lpvt_602b80cf8079ae6591966cc70a3940e7=1603454947; _lxsdk_s=1755556bdd3-ec-524-20f%7C%7C48"
}
def read_word_string():
with open("./word_string.txt", "r", encoding="utf-8") as file:
return file.read()
def parse_url(url):
"""決議url得到位元組"""
response = requests.get(url=url, headers=headers)
return response.content
def parse_html(html):
"""使用xpath決議html,回傳xpath物件"""
etree_obj = etree.HTML(html)
return etree_obj
def save_woff():
"""保存woff檔案"""
content = parse_url(css_url).decode("utf-8")
woff_url_list = re.findall(
r'url\("(//s3plus\.meituan\.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/\w+?\.woff)"\)', content)
woff_url_list = map(lambda x: "https:" + x, woff_url_list)
for woff_url in woff_url_list:
content = parse_url(woff_url)
filepath = woff_url.split("/")[-1]
with open(filepath, "wb") as file:
file.write(content)
print("保存成功!")
def get_word(name, key):
"""讀取指定的woff得到字體"""
word = None
if name == "tagName" or name == "shopNum":
woff_name = "f58a3e31.woff"
elif name == "address":
woff_name = "b88ff555.woff"
tag = TTFont(woff_name)
order_list = tag.getGlyphOrder()
index = order_list.index(key)
word = word_string[index - 2]
return word
def get_data():
"""獲取資料"""
html = parse_url(data_url).decode("utf-8")
html = re.sub(r"&#x(\w+?);", r"*\1*", html) # 替換特殊字符,避免決議css加密資料獲取后是unicode字串
xpath_obj = parse_html(html)
li_list = xpath_obj.xpath('//*[@id="shop-all-list"]/ul/li')
for li in li_list:
item = {}
item["shop_url"] = li.xpath("./div[1]/a/@href")[0] # 店鋪的url
item["shop_img_url"] = li.xpath("./div[1]/a/img/@src")[0] # 店鋪圖片的url
item["shop_name"] = li.xpath("./div[1]/a/img/@title")[0] # 店鋪名稱
star_class = li.xpath('.//*[@class="star_icon"]/span[1]/@class')[0]
item["shop_star"] = star_class.split(" ")[1].split("_")[-1] # 店鋪評分
class_name = li.xpath('./div[2]/div[2]/a[1]/b/svgmtsi/@class')
if class_name: # 有加密
class_name = class_name[0]
item["shop_comment_num"] = "".join(
[get_word(class_name, "uni" + i.strip("*")) if (i.startswith("*") and i.endswith("*")) else i for i in
li.xpath('./div[2]/div[2]/a[1]/b//text()')])
else: # 沒有加密
item["shop_comment_num"] = "".join(li.xpath('./div[2]/div[2]/a[1]/b//text()'))#評論數
class_name = li.xpath('./div[2]/div[2]/a[2]/b/svgmtsi/@class')
if class_name: # 有加密
class_name = class_name[0]
item["shop_avg_money"] = "".join(
[get_word(class_name, "uni" + i.strip("*")) if (i.startswith("*") and i.endswith("*")) else i for i in
li.xpath('./div[2]/div[2]/a[2]/b//text()')])
else: # 沒有加密
item["shop_avg_money"] = "".join(li.xpath('./div[2]/div[2]/a[2]/b//text()'))#人均消費
class_name = li.xpath('./div[2]/div[3]/a[1]/span/svgmtsi/@class')
if class_name:
class_name = class_name[0]
item["shop_type"] = "".join(
[get_word(class_name, "uni" + i.strip("*")) if (i.startswith("*") and i.endswith("*")) else i for i in
li.xpath('./div[2]/div[3]/a[1]/span//text()')])
else:
item["shop_type"] = "".join(li.xpath('./div[2]/div[3]/a[1]/span//text()'))
class_name = li.xpath('./div[2]/div[3]/a[2]/span/svgmtsi/@class')
if class_name:
class_name = class_name[0]
item["shop_address1"] = "".join(
[get_word(class_name, "uni" + i.strip("*")) if (i.startswith("*") and i.endswith("*")) else i for i in
li.xpath('./div[2]/div[3]/a[2]/span//text()')])#區域地址
else:
item["shop_address1"] = "".join(li.xpath('./div[2]/div[3]/a[2]/span//text()'))
class_name = li.xpath('./div[2]/div[3]/span[1]/svgmtsi/@class')
if class_name:
class_name = class_name[0]
item["shop_address2"] = "".join(
[get_word(class_name, "uni" + i.strip("*")) if (i.startswith("*") and i.endswith("*")) else i for i in
li.xpath('./div[2]/div[3]/span[1]//text()')])
else:
item["shop_address2"] = "".join(li.xpath('./div[2]/div[3]/span[1]//text()'))#詳細地址
print(item)
save(item)
def save(item):
"""將資料保存到csv中"""
with open("./大眾點評-{}.csv".format(kw), "a", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(item.values())
if __name__ == '__main__':
# save_woff()
word_string = read_word_string()
get_data()
六、運行結果
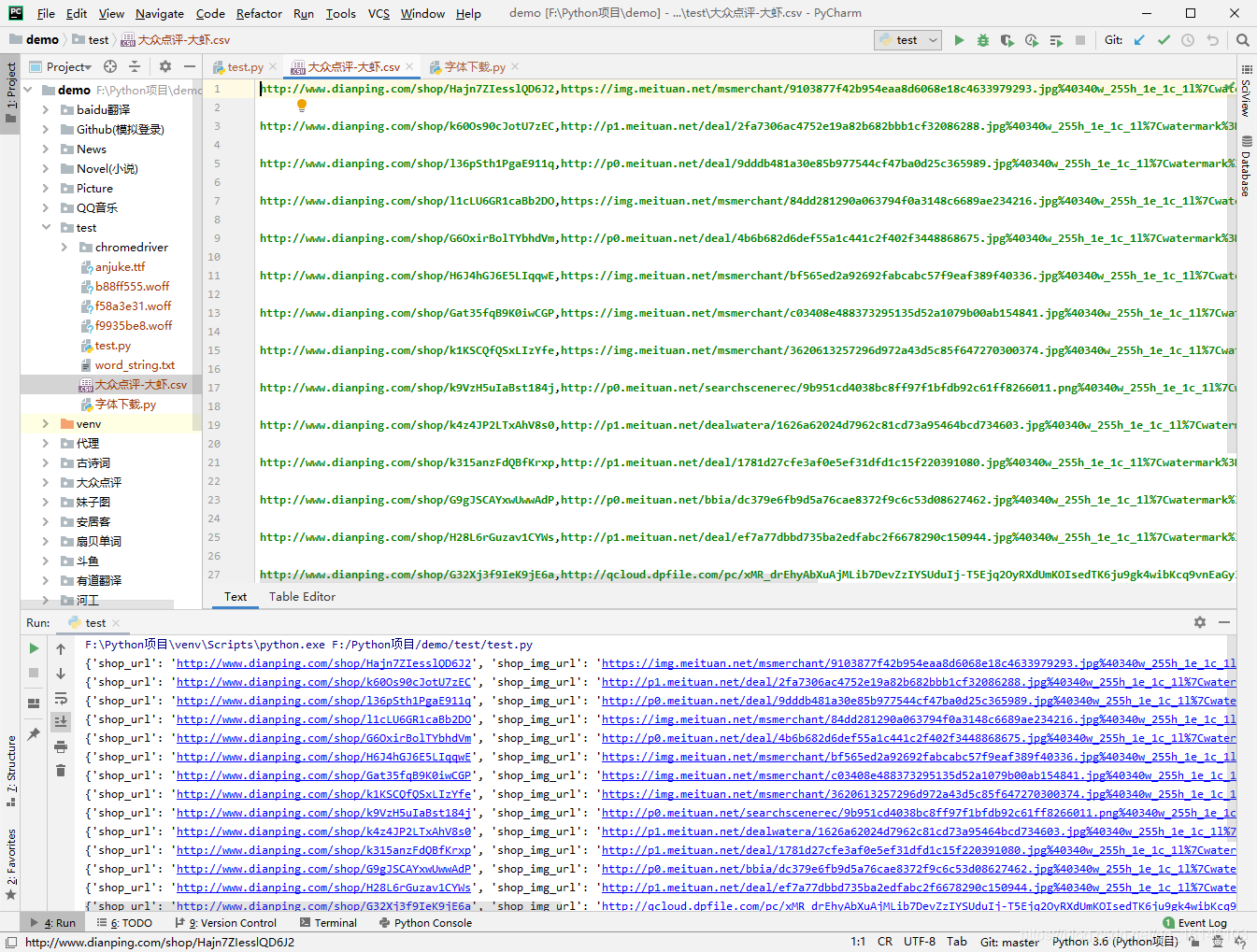
美好的日子總是短暫的,雖然還想繼續與大家暢談,但是本篇博文到此已經結束了,如果還嫌不夠過癮,不用擔心,我們下篇見!

??好書不厭讀百回,熟讀課思子自知,而我想要成為全場最靚的仔,就必須堅持通過學習來獲取更多知識,用知識改變命運,用博客見證成長,用行動證明我在努力,
??如果我的博客對你有幫助、如果你喜歡我的博客內容,請“點贊” “評論”“收藏”一鍵三連哦!聽說點贊的人運氣不會太差,每一天都會元氣滿滿呦!如果實在要白嫖的話,那祝你開心每一天,歡迎常來我博客看看,
??碼字不易,大家的支持就是我堅持下去的動力,點贊后不要忘了關注我哦!

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/224840.html
標籤:其他