大家好,好久不見啦,最近快年底了,公司、部門事情太多:沖刺 KPI、做部門預算……所以忙東忙西的,寫文章就被耽擱了,再加上這篇文章比較硬,我想給大家講得通俗易懂,著實花了很多時間琢磨怎么寫,
話不多說,小故事開始,
前言
當架構師大劉看到實習生小李提交的記賬流水亂序的問題的時候,他知道沒錯了:這一次,大劉又要用一致性哈希這個老伙計來解決這個問題了,
嗯,一致性哈希,分布式架構師必備良藥,讓我們一起來嘗嘗它,
1. 滿眼都是自己二十年前的樣子,讓我們從哈希開始
在 N 年前,互聯網的分布式架構方興未艾,大劉所在的公司由于業務需要,引入了一套由 IBM 團隊設計的業務架構,
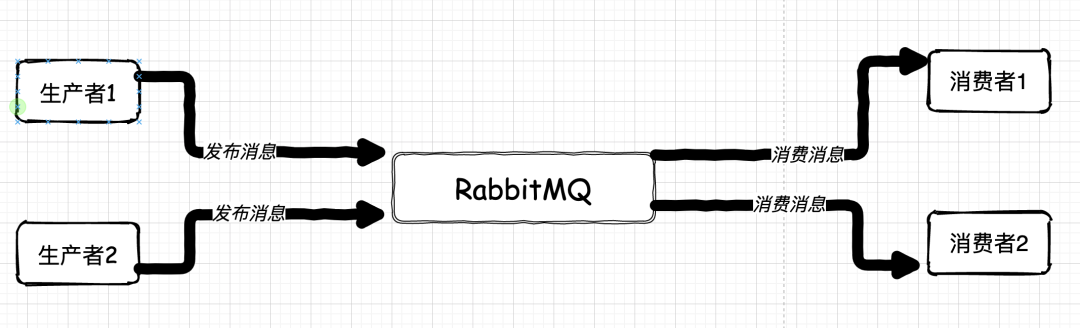
這套架構采用了分布式的思想,通過 RabbitMQ 的訊息中間件來通信,這套架構,在當時的年代里,算是思想超前,技術少見的黑科技架構了,
但是,由于當年分布式技術落地并不廣泛,有很多尚不成熟的地方,所以,這套架構在經年日久的使用中,一些問題逐漸突出,其中,最典型的問題有兩個:
- RabbitMQ 是個單點,它一壞掉,整個系統就會全部癱瘓,
- 收、發訊息的業務系統也是單點,任何一點出現問題,對應佇列的訊息要么無從消費,要么海量訊息堆積,
無論哪種問題,最終是整套分布式系統都無法使用,后續處理非常麻煩,
對于 RabbitMQ 的單點問題,由于當時 RabbitMQ 的集群功能非常弱,普通模式有 queue 本身的單點問題,所以,最終使用了 Keepalived 配合了兩臺無關系的 RabbitMQ 搞出了高可用,
而對于業務系統單點問題,從一開始著手解決的時候就出現了波折,一般來說,我們要解決單點問題,方法就是堆機器,堆應用,收發是單點,我們直接多部署幾個應用就可以了,如果僅僅從技術上看,無非就是多個收發訊息的應用大家一起競爭往 MQ 中放訊息拿訊息而已,
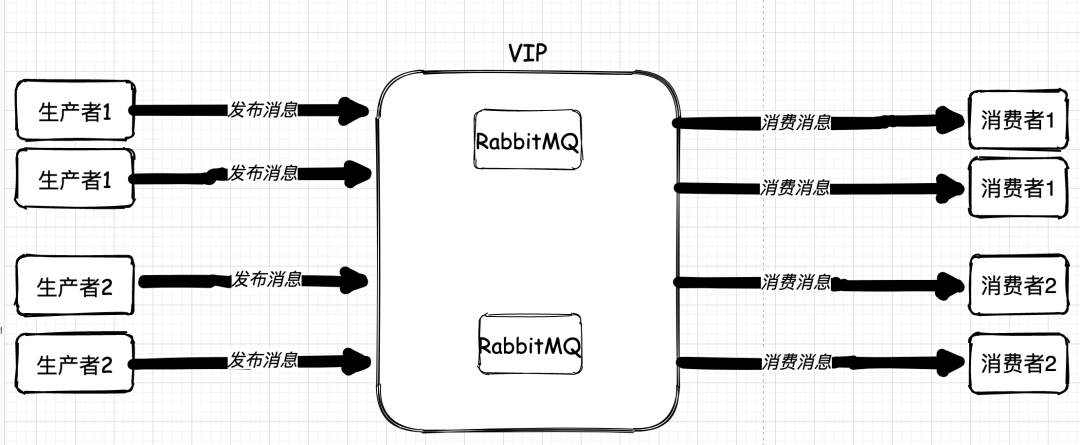
但是,恰恰就是在把收發訊息的應用集群化后,系統出現了問題,
本身這套系統架構會被應用到公司的多類業務上,有些業務對訊息的順序有著苛刻的要求,
比如,公司內部的 IM 應用,不管是點對點的聊天還是群聊訊息,都需要對話訊息嚴格有序,而當我們把生產訊息和消費訊息的應用集群化后,問題出現了:
聊天記錄出現了亂序
A 和 B 對話,會出現某些訊息沒有嚴格按照 A 發出的先后順序被 B 接收,于是整個聊天順序亂成了一鍋粥,
經過排查,發現問題的根源就在于應用集群上,由于沒有對應用集群收發訊息做特殊的處理,當 A 發出一條聊天資訊給B時,發送到 RabbitMQ 中的資訊會被在 B 處的消費端所爭搶,如果 A 在短時間內發出了幾條資訊,那么就可能會被集群中的不同應用搶走,
這時候,亂序的問題就出現了,雖然應用業務邏輯是相同的,但是這些集群中的應用依然可能在處理資訊速度上出現差異,最終導致用戶看到的聊天資訊錯亂,
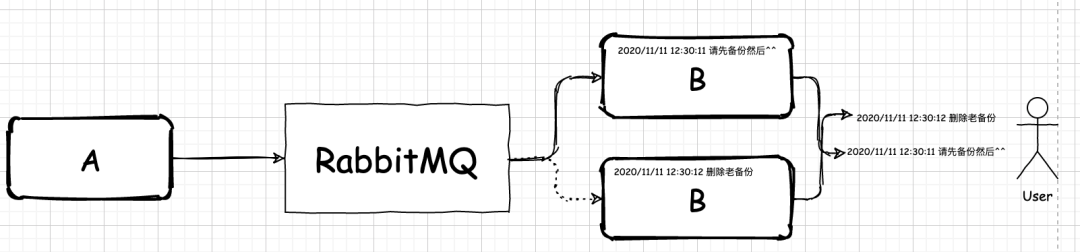
問題找到了,解決辦法是什么?
上面我們說過了,訊息順序錯亂是因為集群中不同應用搶訊息然后處理速度不一樣導致的,如果我們能保證 A 和 B 會話,從開始之后到會話結束之前,永遠只會被 B 所在的消費訊息集群應用中的同一個應用消費,那么我們就能保證訊息有序,這樣一來,我們就可以在消費訊息的那個應用中,對搶到的訊息進行排隊,然后依次處理,
那么,這種保證怎么實作呢?
首先,我們在 RabbitMQ 中會建立有相同前綴的佇列,后面跟著佇列編號,然后,集群中的不同應用會分別監聽這兩個有著不同編號的佇列,當在 A 發送資訊時,我們會對資訊做一次簡單的哈希:
m = hash(id) mod n
這里,id 是用戶的標識,n 是集群中 B 所在業務系統部署的數量,最終的 m 是我們需要發送到的目的佇列編號,
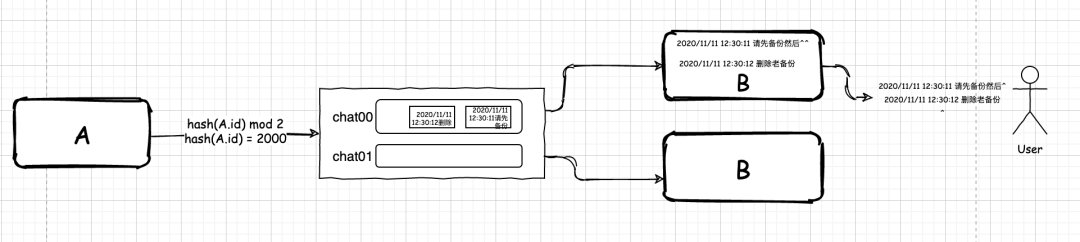
假設,hash(id) 的結果為 2000,n 為 2,經過計算 m = 0,此時,A 就會把他和 B 的對話資訊都發送到 chat00 的佇列里,B 收到訊息后,就會依次顯示給終端用戶,這樣,聊天亂序的問題就解決了,
那么,事情到此就結束了嗎?這個解決方案是完美的嗎?
2. 看來,我們需要增加應用數量了
隨著公司的發展,公司的人數也急劇上升,公司內部的 IM 使用人數也跟著多了起來,新問題又隨之出現了,
最主要的問題是,人們收到聊天資訊的速度變慢了,原因也很簡單,收取聊天資訊的集群機器不夠用了,解決辦法可以簡單直接點,再加臺機器就好了,
不過,由于收訊息的集群中新加入了一臺機器,這時候,我們還需要額外多作一些事情:
-
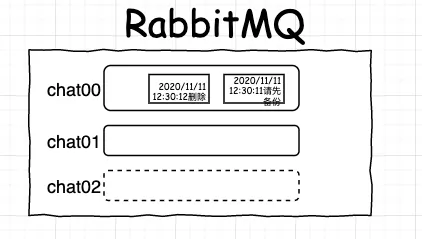
我們需要為新加入的這臺機器上的應用額外再多增加一個佇列 chat02,
-
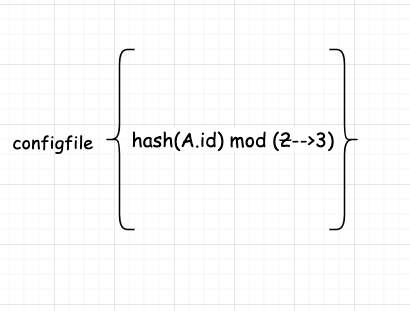
我們還需要修改下我們的分配訊息的規則,把原來的 hash(id) mod 2 修改為 hash(id) mod 3,
-
重新啟動發送訊息的專案,以便修改的規則生效,
-
把收訊息的應用部署到新機器上,
到這時,一切還都在可控范圍,開發人員只需要在需要的時候,新增加個佇列,然后把我們的分配規則小小的修改下即可,
但是,他們不知道的是,暴風雨就要來了,
3. 新的問題來了,也許這就是人生吧
由于公司內部很多人在使用這個 IM 工具,有些時候,為了方便,公司的客戶還有一些合作方也用起了這個 IM,這讓事情變得復雜了起來,起初,開發人員還是像往常一樣,每當人們抱怨說收訊息過慢的時候,他們就會加一臺機器,
最糟糕的是,公司的客戶也會抱怨,他們發現 IM 有時候徹底不可用,這可不是小事情,公司內部人員的問題還可以內部溝通解決,但是公司客戶的問題,大意不得,因為這關系到公司產品的名譽,
那么,這到底是怎么一回事呢?
原來,根本原因還在于每次修改完配置規則后的重啟服務,每次修改完配置規則,就需要規劃好一個恰當的停機時間,去重新對專案做個上線,
但是,這種方法在公司的客戶也使用這個 IM 后就行不通了,因為公司的客戶有不少是在國外的,也就是說,不管白天還是深夜,很可能總是有人在使用這個 IM,
這就迫使開發人員們,在增加機器時,還需要去和多方協調溝通出一個上線時間,然后發布公告,再去上線,這種反復溝通,再上線,再反復溝通,再上線直接把開發人員們折騰了個半死,
往往溝通完,上線時間直接被放到了半個月以后,而在這半個月里,開發人員還要承受無數內部 IM 使用人的口水,費心竭力的溝通,聲嘶力竭的解釋,缺眠少覺的上線,這一切的一切推動著開發人員們必須對眼前這套技術方案作出改變了,
4. 思路轉起來,佇列環起來
新的技術方案的需求本質就是:
無論是分配訊息規則變化還是集群機器添加都不能停機停服務
對于這種情況,一個很好的解決方案就是如果我們對專案組態檔進行動態的定時檢測,當發現變動時,重繪配置規則即可,
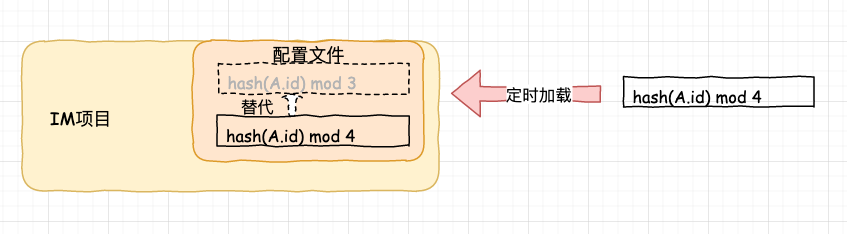
一切看上去很美好,采用了動態的定時檢測后,每當我們需要新增集群中的機器時,我們只需要如下三個步驟了:
- 增加一個佇列
- 修改分配訊息的規則
- 部署新的機器
客戶毫無感知,開發人員們也不需要和用戶們協調溝通出專門的上線安排,可是,這個方案也存在一些問題:
- 隨著我們的系統部署越來越多,我們需要手工修改規則的系統也越來越多,
- 如果消費機器宕機了,我們需要洗掉佇列,同時還需要去洗掉修改分配訊息的規則,等到機器恢復了,我們還要再把分配訊息的規則改回去,
這個分配訊息的規則真討厭啊,每次有變動,就要去關心這個分配訊息的規則,有沒有什么辦法能把這個分配變得更自動化一些呢?
如果我們假設在 MQ 中有 100 個收發聊天資訊的佇列(100:這是對我們的IM不可能達到的一個數字),我們只需要在配置規則中配置成:
hash(id) mod 100
然后,我們的發送訊息的應用啟動后,去動態的探測出真實的所有收發聊天資訊的佇列資訊,
當我們通過哈希算出的編號發現沒有真實對應的佇列存在時,就根據一定的規則,去找到一個真實存在的佇列,這個佇列,就是我們要發訊息的佇列,
如果我們做到這樣,那么以后,每次佇列有變化,無論增多還是減少,我們都不需要再去考慮分配規則的事情了,只需要移除有問題的佇列或者增加有對應消費者的佇列即可,
這個思想,就是一致性哈希的思想,
具體怎么做呢?
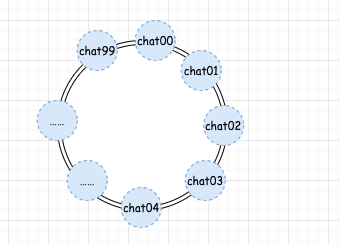
第一步,我們假設有個 100 個收發聊天資訊的佇列,并且這些佇列處于一個環上,
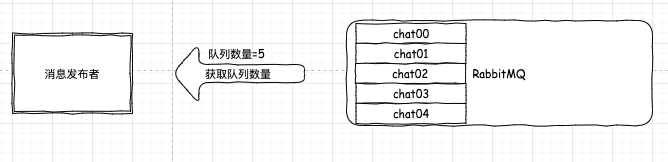
第二步,我們獲取到真實的收發聊天資訊的佇列數量,假設有 5 個,
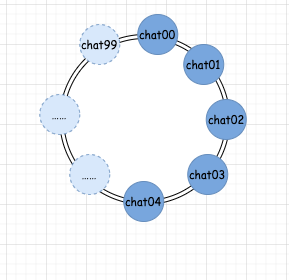
第三步,我們把真實的佇列映射到我們第一步假設的環中,
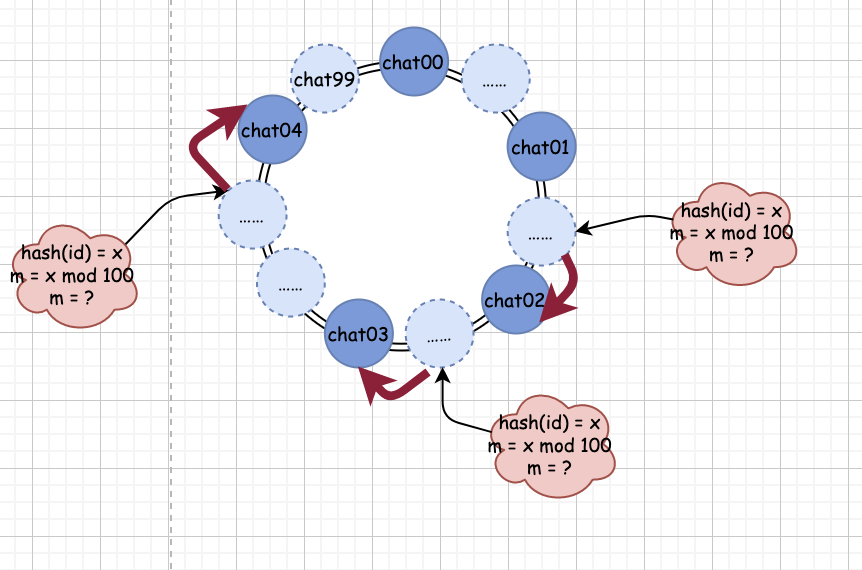
第四步,我們通過分配規則 hash(id) mod 100 計算出對應的佇列編號,
如果 hash(id) 的結果為 2000,那么算出的佇列編號 m = 0,這時候,我們一查,發現對應編號 0 的 chat00 佇列確實存在,那么就直接發送訊息到 chat00 中,
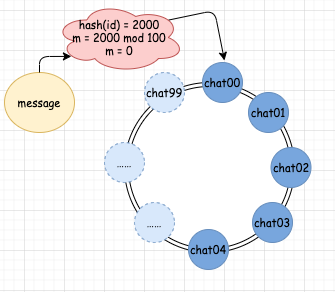
如果我們的 hash(id) 的結果為 1999,那么算出的佇列編號 m = 99,此時,我們去查佇列映射關系,發現 99 編號并沒有對應的真實佇列,這時候怎么辦?很簡單,我們順時針繼續往下找,找到誰了呢?0 對應的 chat00 佇列,這是真實存在的,這時候,我們就將訊息發送到 chat00 佇列中,
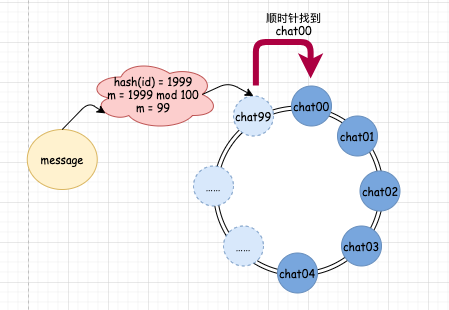
上面四步就是一個基本的一致性哈希演算法了,
那么,這套一致性哈希演算法滿足我們不想總是更新訊息分配規則的需求嗎?讓我們驗證一下:
-
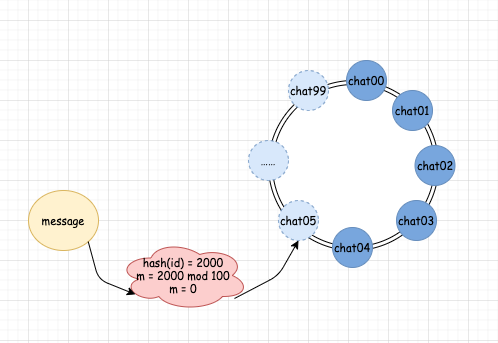
假設我們需要在消費資訊端集群增加一臺機器
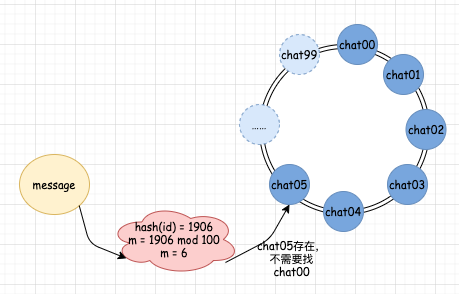
我們如果要增加一臺機器,那么同時我們也需要在 MQ 中增加一個佇列,這時候,我們的分配規則是 hash(id) mod 100,增加了佇列后,真實的佇列數假設為 6,此時,如果 hash(id) mod 100 的結果小于 6,那么分配的規則和沒有增加機器的時候規則一樣,以前分配到哪個佇列,現在還是分配到哪個佇列,但是對于結果等于 6 的情況,則發生了變化,資訊會被自動分配給 chat05,當分配給 chat05 后,新的消費者就會自動開始進入正常作業了,我們不需要做任何人工干預,也不需要考慮分配規則的變化,增加機器以前:
增加機器之后:
-
假設消費資訊端集群一臺機器宕機了
模擬宕機,此時我們會去減少一個佇列,減少后的真實佇列數量為 5,則正好和增加佇列相反,m = 5 時,那么行為不會有任何變化,以前分到哪個佇列,還是分到哪個佇列,如果 m = 6,由于已經不存在真實的佇列了,就會做順時針查找,結果找到 chat00,以前會分到 chat05 的就會被分到 chat00,而此時,chat00 由于正好有消費者,所以,系統的用戶是毫無感知的,我們也專心修復我們機器即可,當機器恢復后,就會和新增機器一樣,計算結果為 6 的資訊會被重新分配回 chat05,
目前,我們可以看到,當我們引入一致性哈希后,我們不管新增機器還是集群機器宕機,我只需要跟隨著機器的狀態,做一個操作即可:增加或者減少 MQ 中的佇列,一切簡單化了,
那么,這個方案是否依然還有問題呢?
5. 失衡的圓環,壓垮駱駝的可能只是一根稻草
假設我們目前有 5 個佇列存在,我們的分配規則是 m = hash(id) mod 100,那么,此時,問題就出來了,
如果 m 的值大于 5,由于沒有對應的真實佇列存在,系統就會順時針順著我們構造出來的哈希環找,最侄訓找到 chat00 這個佇列上,
然后,你會發現,只要是 m 值大于 5 的 id 對應用戶發的資訊,最終都會落入到 chat00 佇列中,
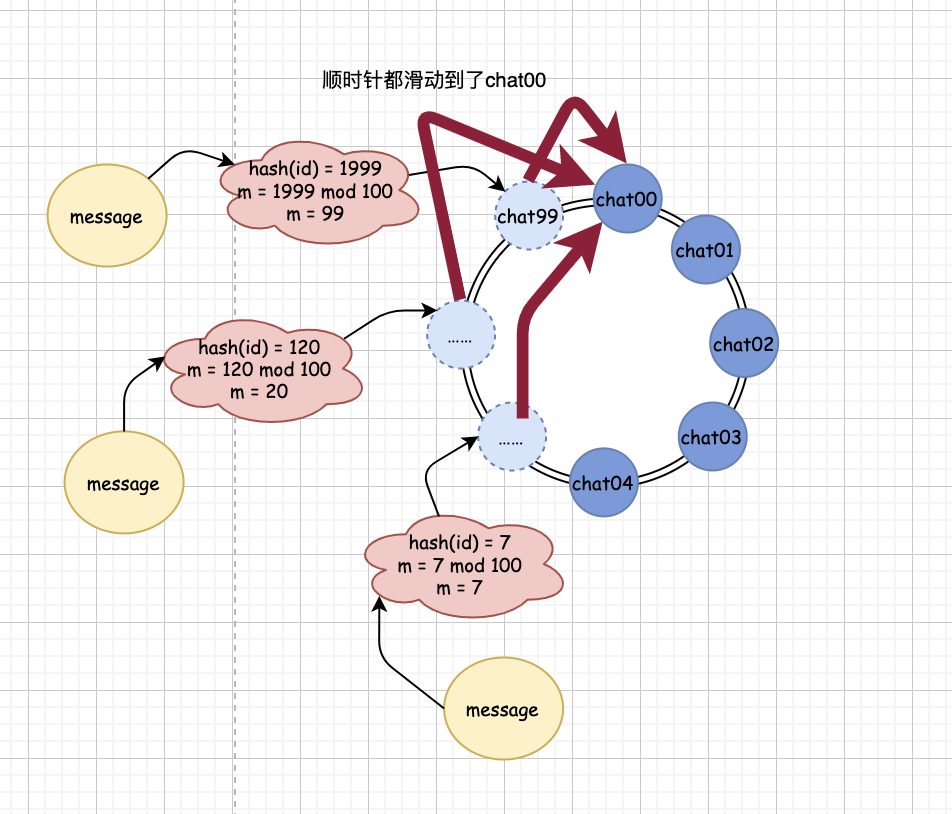
在極端情況下,如果大量的資訊涌入到 chat00 佇列里,由于對應 chat00 的消費者處理不過來,很可能會導致這個消費者的崩潰,
然后,去除佇列后,根據規則,又會有大量的資訊涌入到 chat00 后續的佇列 chat01 里,這些資訊又會導致 chat01 對應應用的崩潰,最終引發整個集群的崩潰,這就是雪崩效應,
我們需要一種更巧妙的辦法來解決這個問題,
6. 從實變虛,也許我們應該更敢想一些
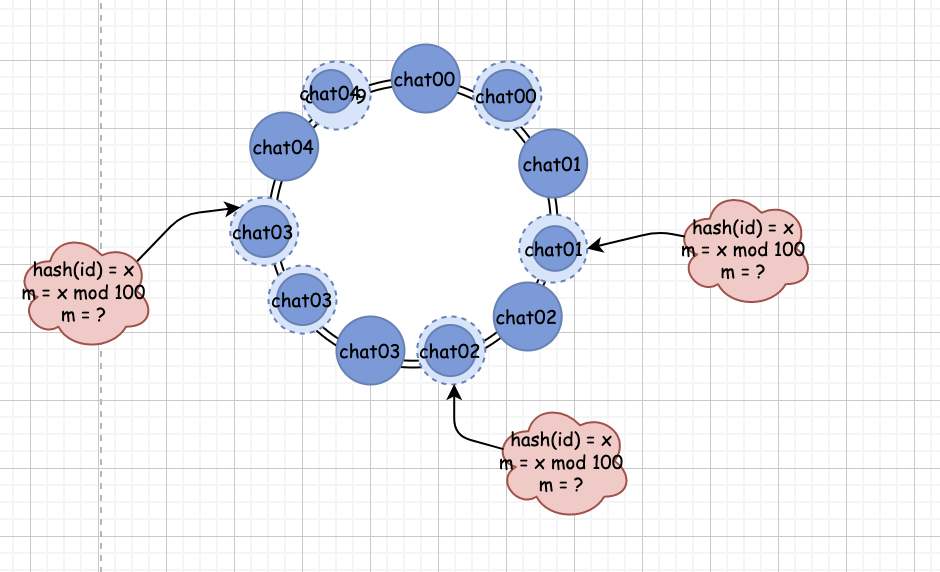
經過上面的論述,我們發現,我們在分配佇列時,之所以失衡,是因為我們的佇列在圓環上的分配失衡,
我們所有的真實佇列都是按照順時針依次排布在圓環上的,在上面的場景里,我們只有 5 個佇列,此時,我們假設會有 100 個佇列,那么,m = hash(id) mod 100 這個公式里:
m 大于 5 的概率為 95%
由于我們的 5 個佇列是按照編號順序依次排列的,那就說明所有 m 大于 5 的資訊就都會映射到一個不存在的佇列上,最終,根據規則,順時針滑到了 0 對應的 chat00 佇列中,
如果,我們可以讓真實存在的佇列均勻分布到環上,那么,這種嚴重失衡的現象還會再出現嗎?
從上面的圖我們可以看出,如果我們能讓真實的佇列均勻的在圓環上分布,那么這種嚴重失衡的現象就會得到極大的緩解,
那么如何讓這些佇列能均勻的分布在這個圓環中呢?還記得我們在苦惱分配資訊規則的不斷修改時,我們大膽的假設了一個我們的 IM 系統永遠也不可能達到的佇列數字嗎?
我們假設了 MQ 中有 100 個佇列,然后,我們去判斷這些佇列是否真實存在,不存在,我們就順時針滑動一直找到真實存在的佇列為止,
如果我們再大膽一點,偷偷的把我們的假設進一步優化,把一些本來需要判斷為不存在的佇列去映射到真正已經存在的佇列上,那么我們是不是就等于把這些真正存在的佇列均勻分布到這個圓環上了?
像上圖這種,把已經存在的少量佇列去映射到多個假設佇列的方法,就是一致性哈希的虛擬節點辦法,
而對于怎么讓少量的佇列映射到多個假設佇列,是有多種實作演算法存在的,
比如,我們可以把真實存在的佇列名加上一些編號去分別哈希一下, 像hash(chat00) mod 100,hash(chat00#1) mod 100,然后根據得到的余數,去把 chat00 這個真實佇列和對應余數的環中的位置映射上,
如果 hash(chat00) mod 100 = 31,那么 31 號的位置就對應于 chat00,以后所有 m = hash(id) mod 100 中 m = 31的所對應的訊息就會直接被發送到 chat00 佇列,
而 hash(00#1) mod 100 = 56,則 m = 56對應的訊息同樣也會直接發送到 chat00 佇列,
這樣,我們就間接的把 MQ 中的真實存在的佇列做了均勻化分布,從而大大減少了資訊失衡的現象,
7. 理解演算法的思想勝于演算法的實作
好了,通過實際場景來對于一致性哈希的思想就暫時剖析到這里了,
一致性哈希作為一種非常經典的演算法思想,被廣泛的用于各大分布式專案當中,用于解決各種分片問題,任務分發問題,
但是,在這里,我要糾正一個觀點:很多人都在網上說 redis 使用了一致性哈希,這是錯的,redis 只是使用了一致性哈希的思想,比如一致性哈希中的環分布,再比如虛擬節點對應真實節點的思想,
但是 redis 并沒有使用任何哈希演算法去計算分布,如果有興趣的讀者,可以仔細去看下有關內容,從 redis 的例子上來說,我們可以看到,只有理解了演算法的思想,我們才能更容易更靈活地因地制宜的分解、修正、改進演算法,讓演算法能更切合實際的融入到我們的專案之中,
通過這篇文章我們從哈希開始,一直到用到一致性哈希的虛擬節點分布,怎么樣,您覺得一致性哈希這道良藥味道如何呢?
第一次寫圖解的文章,大家包容一下直男的審美!
第一次寫圖解的文章,畫圖真是累吐血了!求大家看完點個贊,
我準備了一些純手打的高質量PDF:
深入淺出Java多執行緒、HTTP超全匯總、Java基礎核心總結、程式員必知的硬核知識大全、簡歷面試談薪的超全干貨,
別看數量不多,但篇篇都是干貨,看完的都說很肝,
領取方式:掃碼關注后,在公眾號后臺回復:666

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/225497.html
標籤:其他