前言
資料結構,一門資料處理的藝術,精巧的結構在一個又一個演算法下發揮著他們無與倫比的高效和精密之美,在為資訊技術打下堅實地基的同時,也令無數開發者和探索者為之著迷,
也因如此,它作為博主大二上學期最重要的必修課出現了,由于大家對于上學期C++系列博文的支持,我打算將這門課的筆記也寫作系列博文,既用于整理、消化,也用于同各位交流、展示資料結構的美,
此系列文章,將會分成兩條主線,一條“資料結構基礎”,一條“資料結構拓展”,“資料結構基礎”主要以記錄課上內容為主,“拓展”則是以課上內容為基礎的更加高深的資料結構或相關應用知識,
歡迎關注博主,一起交流、學習、進步,往期的文章將會放在文末,
哈夫曼樹的背景
每一個傳奇的資料結構都會有屬于自己的傳奇故事
——尤市沃茨基碩的
哈夫曼樹的傳奇背景,是主角哈夫曼在攻讀博士學位期間,修習資訊論學科,導師讓同學們選擇學期考察的方案,可以選擇完成報告,或者參加考試,我們的dalao哈夫曼就選擇了完成一篇報告,
他遇到的報告題目為:尋找最有效的二進制編碼方案
他先是分析了前人的研究結果,發現前輩們的方案都并未很好的解決這個問題,尤其是不能證明其方案是最有效的,水不成論文的哈夫曼此時的心中一定是:

于是他決定先放棄對已有演算法的分析,自己研究一個新的演算法解決編碼問題:

最終,他發明了一個基于有序頻率二叉樹的編碼方案,并很快證明了他是最有效的演算法,這個演算法,青出于藍,超過了資訊創始人香農和他的導師,哈夫曼使用自底向上的方法構建二叉樹,避免了次優演算法Shannon-Fano編碼的最大弊端──自頂向下構建樹,
1952年,哈夫曼將這個發明整理成了學期報告《一種構建極小多余編碼的方法》(A Method for the Construction of Minimum-Redundancy Codes)一文,順利的完成了該科目的學習~~(這要是不過那可真說不過去了)~~ ,現在這種編碼方案一般就叫做哈夫曼(Huffman)編碼,

哈夫曼的編碼方案
哈夫曼遇到的問題,簡單來說,需要解決這么幾個關鍵問題:
- 編碼不能存在歧義,避免編碼的多義性,即不能有某個字符的編碼是另一個字符編碼的前綴
- 編碼應該盡可能的短,這要求采用不等長的編碼方案,并將出現頻率搞得字符賦予更短的編碼
- 編碼演算法產生的編碼方案應該唯一,避免編碼與解碼的不對應
- 編碼演算法效率應盡可能的高
哈夫曼定義了一種二叉樹,他的構建規則如下
- 對于所有字符,統計其出現的頻率,
- 定義二叉樹的結點,其中葉子結點的值為各個字符,權值為頻率
- 定義結點間的比較規則
-
- 頻率為第一關鍵字小頻率優先;
-
- 值為第二關鍵字,字符大于樹內結點
-
- 最早出現位置為第三關鍵字,更早出現的結點優先
- 每次挑選兩個權值最小的結點,創建新的結點作為兩節點父親,父節點的權值為兩子節點的和,且較小結點為左兒子,較大者為右兒子
- 重復上述程序,直至集合中剩余一個結點,該節點即為該二叉樹的根
依照這種規則建立起來的二叉樹,我們稱之為哈夫曼樹
如下就是一次構建哈夫曼樹的程序
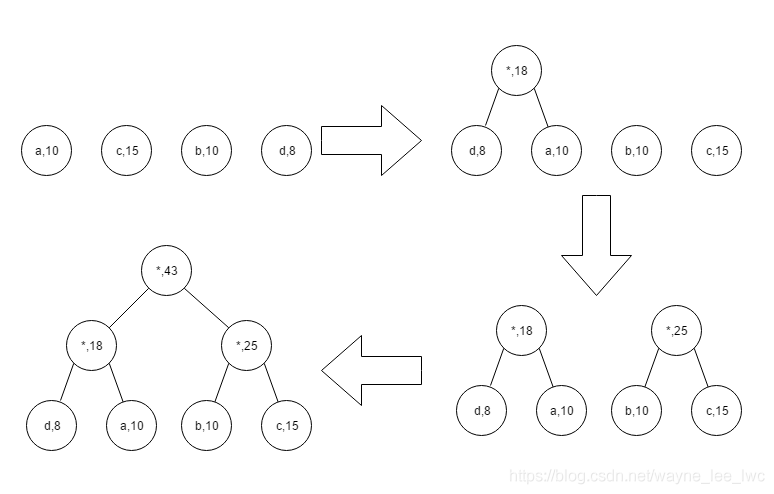
哈夫曼的編碼方案就是基于這樣一顆二叉樹進行的,我們規定,所有編碼從根節點開始,每次向左走編碼尾部追加’0’,向右走編碼尾部追加’1’,
在上圖中,四個字母的編碼方案如下:
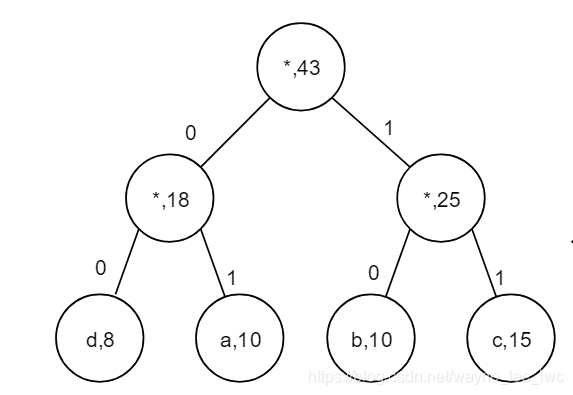
- d : 00 d:00 d:00
- a : 01 a:01 a:01
- b : 10 b:10 b:10
- d : 11 d:11 d:11
當然這個方案中四個字符的編碼長度相同且有規律,純屬巧合,一般情況下編碼長度是不相同的,
哈夫曼樹的實作
了解了哈夫曼樹的構建程序 ,下面一步我們就需要來想辦法實作構建哈夫曼樹的程序
首先呢,先來定義一下哈夫曼樹的結點型別,同時,我們要多載結點類的小于號用以比較:
class Node{
public:
char c; //結點字符,非字符結點默認為'z' + 1 = '{'
int value; //結點出現頻率
int idx; //結點出現最早時間
Node * left;
Node * right;
bool operator < (const Node & node){
if(value == node.value){
return idx < node.idx;
}
return value < node.value
}
};
為了演示哈夫曼樹的構建程序,我們擬定一個需求:
給定一個序列僅包含小寫字母,統計出每個字符的頻率,創建出它的哈夫曼樹,
傳統的實作方案
傳統與優化的解決方案的差別,主要在于如何尋找集合中最小的結點,傳統的方案是使用遍歷的方式尋找,優化的方案是使用二叉堆來優化這個程序,
話不多說,上代碼:
Node * character[26];//二十六個英文字母的結點陣列,沒出現的字母為空
Node * nodes[1000];//結點集合,每次從中挑選最小結點
int tot = 0;//結點集合規模
char str[10000];
int main(){
cin >> str;
int len = strlen(str);
for(int i = 0,c;i < len;i++){
c = str[i] - 'a';
if(character[c] == NULL){//如果該字母第一次出現,則創建結點并且記錄第一次出現位置
character[c] = new Node();
character[c]->c = str[i];
character[c]->idx = i;
character[c]->value = 1;
character[c]->left = NULL;
character[c]->right = NULL;
nodes[tot++] = character[c];//加入結點集合
}else{
character[c]->value++;
}
}
int cnt = tot;//總結點數量
int first;
int second;
Node * node;
while(cnt-- > 1){//總結點數量每次減一,總共回圈cnt-1次
first = -1;
second = -1;
for(int j = 0;j < tot;j++){
if(nodes[j] == NULL){
continue;
}
if(first == -1 || *nodes[j] < *nodes[first]){//注意這里是取值進行比較而非直接比較指標
second = first;
first = j;
}else if(second == -1 || *nodes[j] < *nodes[second]){
second = j;
}
}
//創建新的結點
node = new Node();
node->c = 'z' + 1;
node->value = nodes[first]->value + nodes[second]->value;
node->left = nodes[first];
node->right = nodes[second];
node->idx = len++;
nodes[tot++] = node;//添加新結點
nodes[first] = NULL;//洗掉合并的結點
nodes[second] = NULL;
}
Node * root = nodes[tot - 1];//哈夫曼樹根節點為最后加入集合的結點
}
使用堆優化
在前面的章節,我們介紹了二叉堆,這是個能夠快速存取最值的結構,在這里正是它大顯身手的地方,
如果讀者此時還沒有掌握二叉堆,可以先回去看一看,或者暫時跳過這段內容,不影響后續的閱讀
每次我們可以從堆中拿去兩個最小節點(堆頂取一次,彈一次,再取一次,再彈一次),創建一個新節點作為父節點,并將它存入堆中,
在具體實作之前,我們有必要先將二叉堆寫出來:
//C
Node * heap[2000];//堆得存盤
int tot = 0;//堆得規模
void down(int k){
int son = k << 1;
while(son <= tot){
if(son + 1 <= tot && *heap[son + 1] < *heap[son]){
son++;
}
if(*heap[k] < *heap[son]){
break;
}
Node * temp = heap[k];
heap[k] = heap[son];
heap[son] = temp;
k = son;
son <<= 1;
}
}
void up(int k){
int fa = k >> 1;
while(fa != 0){
if(*heap[fa] < *heap[k]){
break;
}
Node * temp = heap[k];
heap[k] = heap[fa];
heap[fa] = temp;
k = fa;
fa >>= 1;
}
}
void add(Node * node){
heap[++tot] = node;
up(tot);
}
Node * peak(){
return heap[1];
}
void pop(){
heap[1] = heap[tot--];
down(1);
}
堆實作了之后,我們使用堆再來進行構建的程序
Node * character[26];//二十六個英文字母的結點陣列,沒出現的字母為空
char str[10000];
int main(){
cin >> str;
int len = strlen(str);
for(int i = 0,c;i < len;i++){
c = str[i] - 'a';
if(character[c] == NULL){//如果該字母第一次出現,則創建結點并且記錄第一次出現位置
character[c] = new Node();
character[c]->c = str[i];
character[c]->idx = i;
character[c]->value = 1;
character[c]->left = NULL;
character[c]->right = NULL;
add(character[c]);
}else{
character[c]->value++;
}
}
int cnt = tot;//總結點數量
Node * first;
Node * second;
Node * node;
while(size > 1){//總結點數量每次減一,總共回圈cnt-1次
first = peak();
pop();
second = peak();
pop();
//創建新的結點
node = new Node();
node->c = 'z' + 1;
node->value = first->value + second->value;
node->left = first;
node->right = second;
node->idx = len++;
add(node);
}
Node * root = peak();//哈夫曼樹根節點
}
編碼與譯碼
獲取編碼
編碼方案在上文描述演算法的時候我們有提到過,要獲取所有的字符編碼,我們需要遍歷整顆哈夫曼樹,對于所有存放字符的葉子結點,應該獲取并記錄其編碼,
那么首先,我們應該有一個存放編碼的地方:
char * code[26];//26個小寫字母的編碼
接著,來遍歷這棵樹,當然,遍歷整棵樹獲取編碼的方式有很多,這里博主僅提供一種可供參考的方案:
void encode(char * s,int dep,Node * node){//當前編碼,深度,當前結點
if(node->left == NULL && node->right == NULL){//如果該結點為葉子結點,則獲取編碼
int c = node->c - 'a';
s[dep] = '\0';
code[c] = strdup(s);//根據當前編碼克隆一個字串并儲存
return;
}
s[dep] = '0';
encode(s,dep + 1,node->left);//遍歷左子樹,編碼追加0
s[dep] = '1';
encode(s,dep + 1,node->right);//遍歷右子樹,編碼追加1
}
完成編碼之后,在主函式中呼叫一下:
Node * root;
...//獲取根節點
char s[20];
encode(s,0,root);
for(int i = 0;i < 26;i++){//列印出出現字母的編碼
if(code[i] != NULL){
cout << (char)(i + 'a') << ":" << code[i] << endl;
}
}
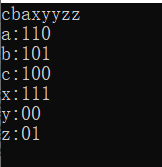
進行譯碼
一般來說,譯碼作業是在哈夫曼樹構建成功基礎上,給定一個編碼序列,將其翻譯成為原始碼,如果無法翻譯則給予提示,
例如,對于剛才展示的運行示例,如果給定編碼序列為:
110110101
110110101
110110101
則譯碼序列為:
a
a
b
aab
aab
若為:
11011010
11011010
11011010,則這個序列存在問題,因為沒有字符編碼為10
譯碼的程序本質上是在哈夫曼樹上跟著序列進行模擬
- 如果當前結點對應位為0,則下一位跳轉到左結點
- 如果當前結點對應位為1,則下一位跳轉到右結點
- 如果當前結點為葉子結點,則獲得一位譯碼,當前結點指向根節點,重復上述程序
- 如果當前結點對應最后一位編碼且非葉子結點,說明編碼存在問題,
用代碼實作以下:
char * decode(Node * root,char * target){//根節點,原碼
char result[50];//結果序列
int resultCnt = 0;//結果長度
int targetCnt = strlen(target);//當前對應原碼下標
Node * curr = root;//當前結點
for(int i = 0;i < targetCnt;i++){
if(target[i] == '0'){
curr = curr->left;
}else{
curr = curr->right;
}
if(curr->left == NULL && curr->right == NULL){//如果當前結點為葉子結點,獲取譯碼
result[resultCnt++] = curr->c;
curr = root;//當前結點指向頭結點
}
}
if(curr != root){//譯碼結束后不指向頭結點,原碼存在錯誤
return "INVALID";
}else{//原碼有效,回傳結果
result[resultCnt] = '\0';
return strdup(result);//克隆結果字串回傳
}
}
在主函式中呼叫測驗這個函式:
Node * root;
char str[100];
...
while(true){
cout << "請輸入原碼:";
cin >> str;
cout << "譯碼結果為:" << decode(root,str) << endl;
}
跑幾組資料試一試:
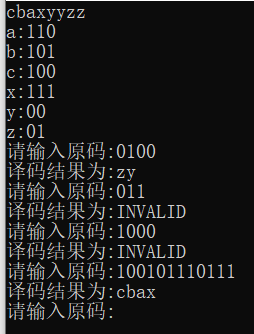
ok沒有問題~

完整的堆實作的代碼這里再放一下:
#include<iostream>
#include<cstring>
using namespace std;
class Node{
public:
char c; //結點字符,非字符結點默認為'z' + 1 = '{'
int value; //結點出現頻率
int idx; //結點出現最早時間
Node * left;
Node * right;
bool operator < (const Node & node){
if(value == node.value){
return idx < node.idx;
}
return value < node.value;
}
};
Node * character[26];
Node * heap[2000];
int tot = 0;
void down(int k){
int son = k << 1;
while(son <= tot){
if(son + 1 <= tot && *heap[son + 1] < *heap[son]){
son++;
}
if(*heap[k] < *heap[son]){
break;
}
Node * temp = heap[k];
heap[k] = heap[son];
heap[son] = temp;
k = son;
son <<= 1;
}
}
void up(int k){
int fa = k >> 1;
while(fa != 0){
if(*heap[fa] < *heap[k]){
break;
}
Node * temp = heap[k];
heap[k] = heap[fa];
heap[fa] = temp;
k = fa;
fa >>= 1;
}
}
void add(Node * node){
heap[++tot] = node;
up(tot);
}
Node * peak(){
return heap[1];
}
void pop(){
heap[1] = heap[tot--];
down(1);
}
char * code[26];
void encode(char * s,int dep,Node * node){//當前編碼,深度,當前結點
if(node->left == NULL && node->right == NULL){//如果該結點為葉子結點,則獲取編碼
int c = node->c - 'a';
s[dep] = '\0';
code[c] = strdup(s);//根據當前編碼克隆一個字串并儲存
return;
}
s[dep] = '0';
encode(s,dep + 1,node->left);//遍歷左子樹,編碼追加0
s[dep] = '1';
encode(s,dep + 1,node->right);//遍歷右子樹,編碼追加1
}
char * decode(Node * root,char * target){//根節點,原碼
char result[50];//結果序列
int resultCnt = 0;//結果長度
int targetCnt = strlen(target);//當前對應原碼下標
Node * curr = root;//當前結點
for(int i = 0;i < targetCnt;i++){
if(target[i] == '0'){
curr = curr->left;
}else{
curr = curr->right;
}
if(curr->left == NULL && curr->right == NULL){//如果當前結點為葉子結點,獲取譯碼
result[resultCnt++] = curr->c;
curr = root;//當前結點指向頭結點
}
}
if(curr != root){//譯碼結束后不指向頭結點,原碼存在錯誤
return "INVALID";
}else{//原碼有效,回傳結果
result[resultCnt] = '\0';
return strdup(result);//克隆結果字串回傳
}
}
char str[10000];
int main(){
cin >> str;
int len = strlen(str);
for(int i = 0,c;i < len;i++){
c = str[i] - 'a';
if(character[c] == NULL){//如果該字母第一次出現,則創建結點并且記錄第一次出現位置
character[c] = new Node();
character[c]->c = str[i];
character[c]->idx = i;
character[c]->value = 1;
character[c]->left = NULL;
character[c]->right = NULL;
add(character[c]);
}else{
character[c]->value++;
}
}
int cnt = tot;//總結點數量
Node * first;
Node * second;
Node * node;
while(tot > 1){//總結點數量每次減一,總共回圈cnt-1次
first = peak();
pop();
second = peak();
pop();
//創建新的結點
node = new Node();
node->c = 'z' + 1;
node->value = first->value + second->value;
node->left = first;
node->right = second;
node->idx = len++;
add(node);
}
Node * root = peak();//哈夫曼樹根節點
char s[20];
encode(s,0,root);
for(int i = 0;i < 26;i++){
if(code[i] != NULL){
cout << (char)(i + 'a') << ":" << code[i] << endl;
}
}
while(true){
cout << "請輸入原碼:";
cin >> str;
cout << "譯碼結果為:" << decode(root,str) << endl;
}
}
往期博客
- 【資料結構基礎】資料結構基礎概念
- 【資料結構基礎】線性資料結構——線性表概念 及 陣列的封裝
- 【資料結構基礎】線性資料結構——三種鏈表的總結及封裝
- 【資料結構基礎】線性資料結構——堆疊和佇列的總結及封裝(C和java)
- 【演算法與資料結構基礎】模式匹配問題與KMP演算法
- 【資料結構與演算法基礎】二叉樹與其遍歷序列的互化 附代碼實作(C和java)
- 【資料結構與演算法拓展】 單調佇列原理及代碼實作
- 【資料結構基礎】圖的存盤結構
- 【資料結構與演算法基礎】并查集原理、封裝實作及例題決議(C和java)
- 【資料結構與演算法拓展】二叉堆原理、實作與例題(C和java)
參考資料:
- 《資料結構》(劉大有,楊博等編著)
- 《演算法導論》(托馬斯·科爾曼等編著)
- 《圖解資料結構——使用Java》(胡昭民著)
- OI WiKi
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/226915.html
標籤:其他
上一篇:弄懂這些redis分布式鎖知識點,明天就去跟老板談漲薪!(建議收藏)
下一篇:帶你快速理解Zookeeper