前言
本人大三軟體工程大資料專業,在此領域本人有諸多不明確疑問,可能文章會有些許錯誤,望大家在評論區指正,本篇文章錯誤將會不斷更正維護,
提示:以下是本篇文章正文內容,下面案例可供參考
一、Hadoop1.0
Hadoop1.0即第一代Hadoop,由分布式存盤系統HDFS和分布式計算框架MapReduce組成,其中HDFS由一個NameNode和多個DateNode組成,MapReduce由一個JobTracker和多個TaskTracker組成,
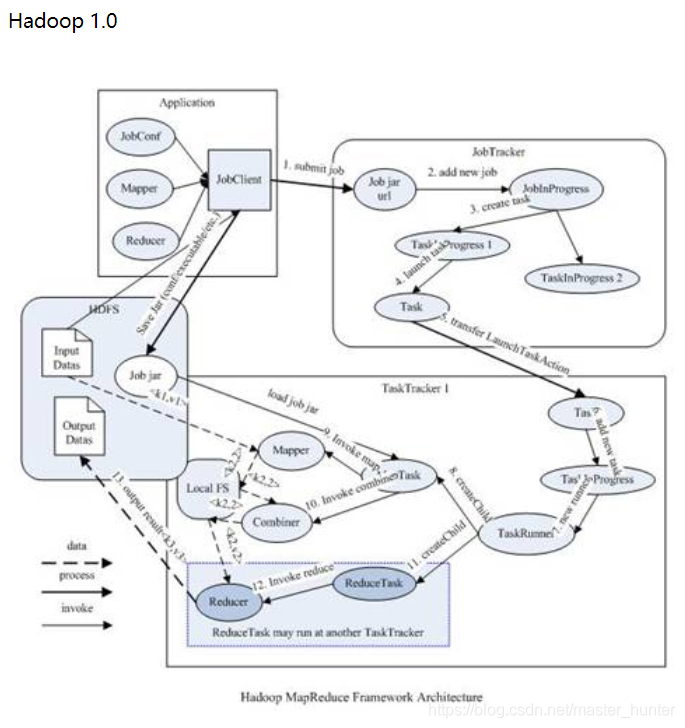
1.1HDFS1.0
HDFS采用了主從(Master/Slave)結構模型,一個HDFS集群包括一個名稱節點和若干個資料節點,名稱節點作為中心服務器,負責管理檔案系統的命名空間及客戶端對檔案的訪問,其中,master主節點稱之為Namenode節點,而slave從節點稱為DataNode節點,
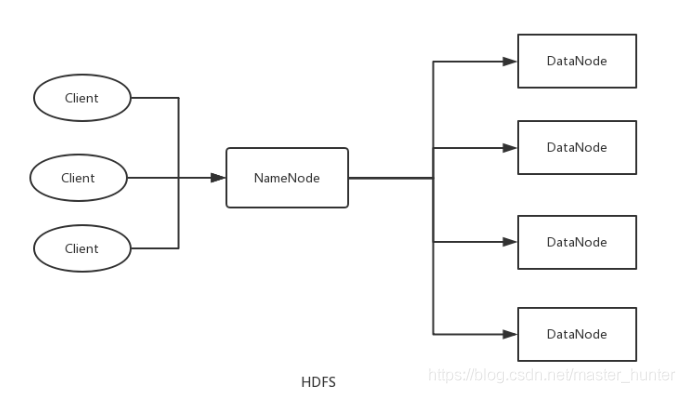
- NameNode管理著整個檔案系統,負責接收用戶的操作請求
- NameNode管理著整個檔案系統的目錄結構,所謂目錄結構類似于我們Windows作業系統的體系結構
- NameNode管理著整個檔案系統的元資料資訊,所謂元資料資訊指定是除了資料本身之外涉及到檔案自身的相關資訊
- NameNode保管著檔案與block塊序列之間的對應關系以及block塊與DataNode節點之間的對應關系
對于第三點名稱節點保存元資料:
(1).在磁盤上:Fslnage和EditLog
(2).在記憶體中:映射資訊,即檔案包含哪些塊,每個塊存盤在哪個資料節點
| NameNode | DataNode |
| 保存元資料 | 存盤檔案內容 |
| 元資料保存在記憶體中 | 檔案內容保存在磁盤 |
| 保存檔案,block,datanode之間的映射關系 | 維護了block id到datanode本地檔案的映射關系 |
namenode有且只有一個,雖然可以通過SecondaryNameNode與NameNode進行資料同步備份,但是總會存在一定的延時,如果NameNode掛掉,但是如果有部份資料還沒有同步到SecondaryNameNode上,還是可能會存在著資料丟失的問題,
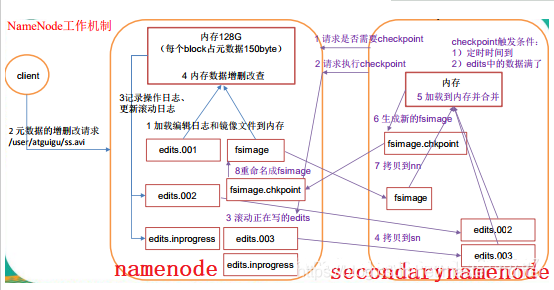
第二名稱節點會定期與第一名稱節點通信,
缺陷:
- 單點故障問題:NameNode含有我們用戶存盤檔案的全部的元資料資訊,當我們的NameNode無法在記憶體中加載全部元資料資訊的時候,集群就面臨崩潰,第二名稱節點無法解決單點故障問題,
- 不可以水平擴展,不過可以縱向擴展增加硬碟,但是不方便不靈活,單臺機器的NameNode必然有到達極限的地方,
- 系統整體性能受限于單個名稱節點的吞吐量,
- 單個名稱節點難以提供不同程式之間的隔離性
- Secondaryname只有冷備份作用,
1.2MadReduce1.0
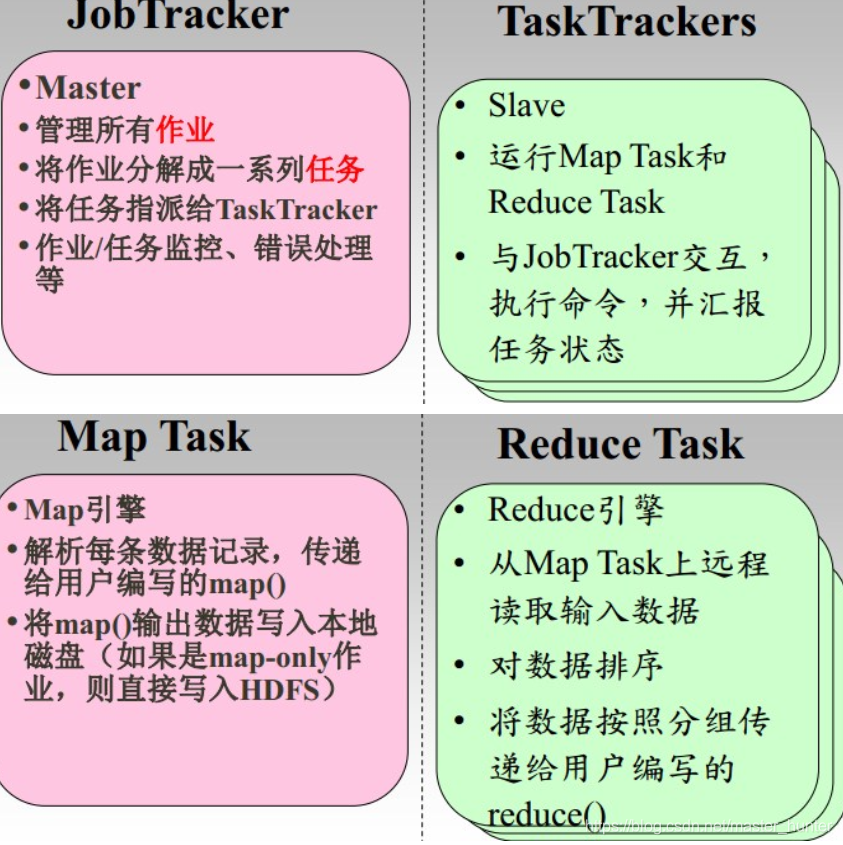
對MapReduce來說,同樣時一個主從結構,是由一個JobTracker(主)和多個TaskTracker(從)組成,
MapReduce1.0既是有一個計算框架,也是一個資源管理調度框架,
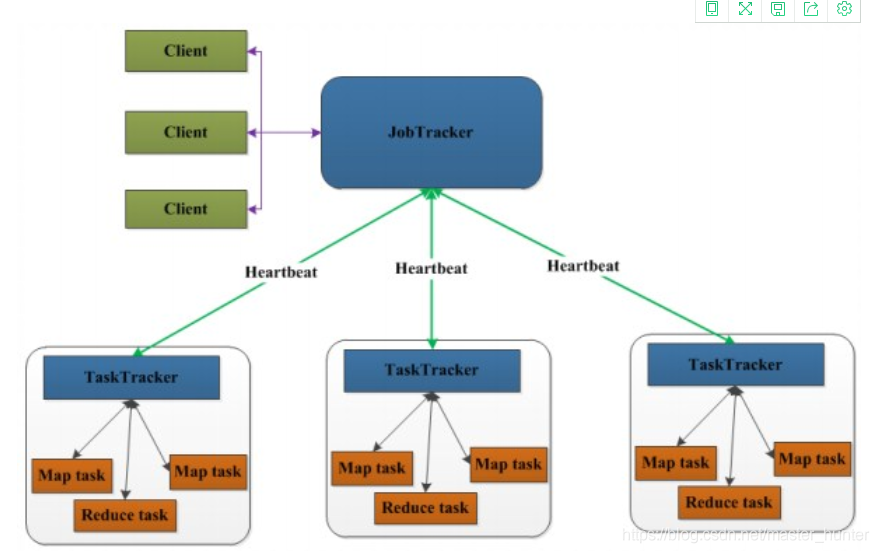
可以看得出JobTracker相當于是一個資源管理調度器,必然要面對大量的任務處理,而且出現錯誤集群必然崩潰,
各個角色的功能:
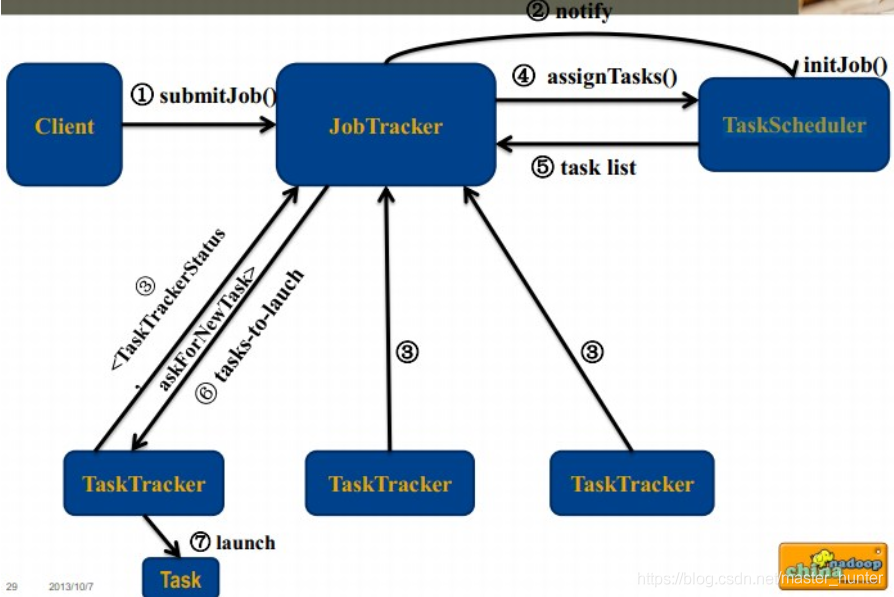
作業調度流程圖:
缺陷:
- 存在單點故障問題,一旦Master節點壞掉即JobTracker故障,其他節點不能再作業,
- JobTacker作業過重,如果任務多時開銷太大,
- 容易出現記憶體溢位,分配資源只考慮MapReduce任務數,不考慮CPU、記憶體,
- 資源劃分不合理(強制劃分為slot,包括Map slot和Reduce slot)
二、Hadoop2.0
相對于Hadoop1.0來說,2就好多,這也是毋庸置疑的,總不可能越更新越差吧,
我們來詳細了解一下2版本究極加了哪些東西,
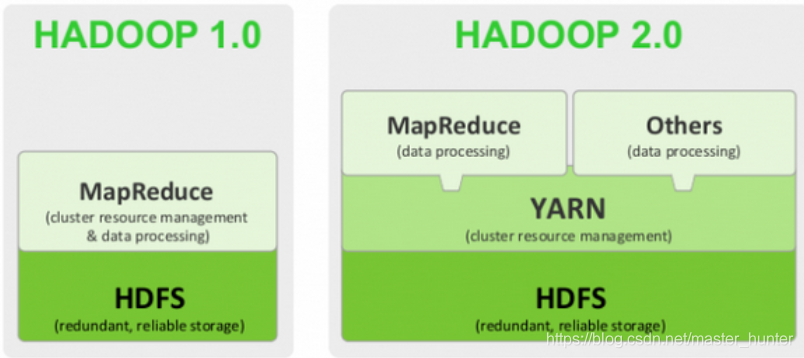
2.1HDFS2.0
2.1.1HDFS HA
HDFS HA(High Availability)是為了解決單點故障問題而設計,
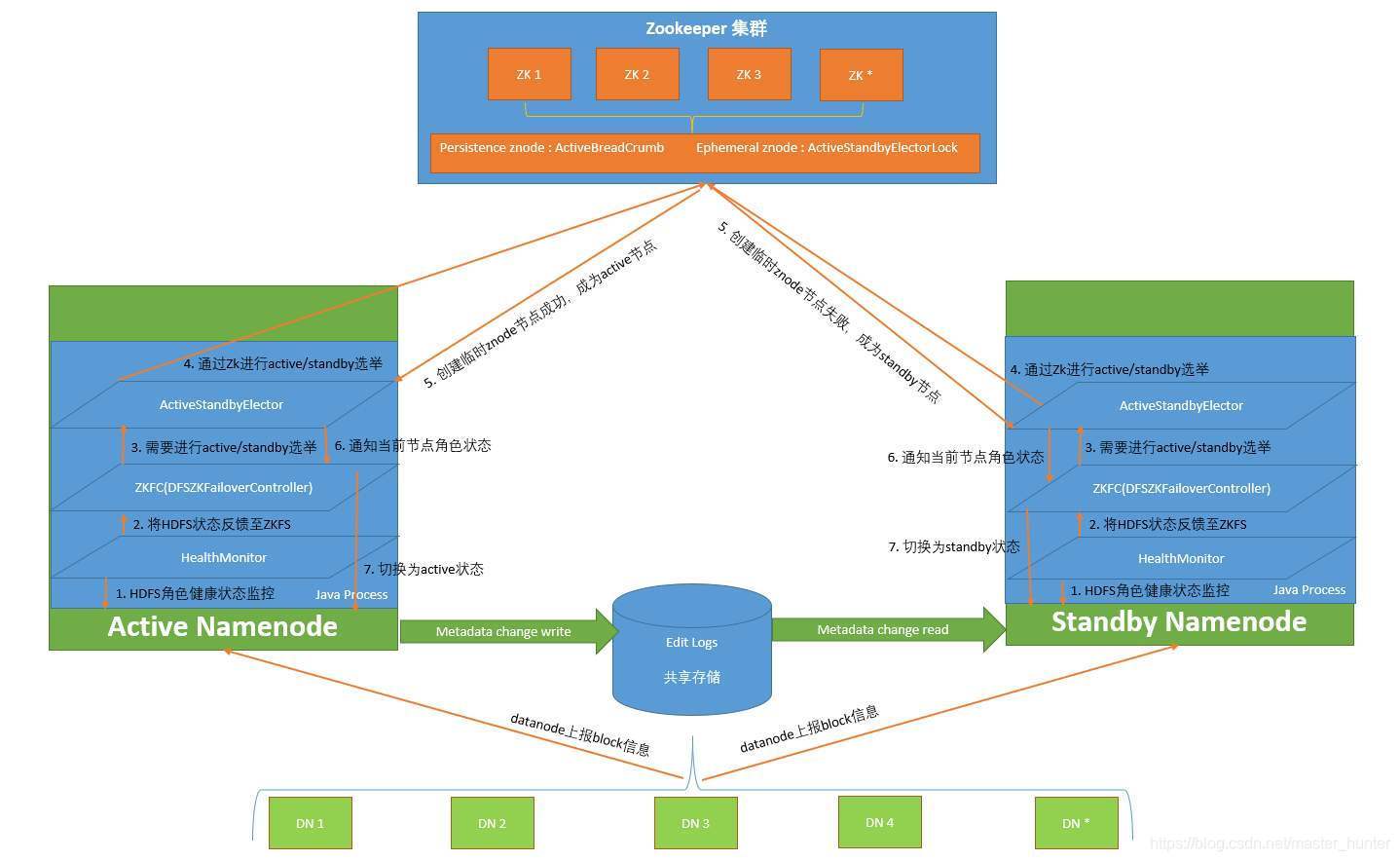
JN:JounrnalNode日志節點,在學習期間一般使用3個節點來部署JN,
ZKFC:全稱是ZooKeeper Failover Controller,這個一個單獨的行程,其數量和NN數量一樣,負責監控NN節點的健康狀態,同時向ZK發送心跳表明它還在作業和NN的狀態,如果NN掛了,就可以讓ZK馬上選舉出新的NN(其實就是讓standbyNN的狀態切換稱active),所以ZKFC是NN的一個守護行程,其一般會和其對應的NN部署在同一個節點上,
ZK:ZooKeeper,當一個activeNN掛掉以后,從standbyNN節點中選舉新的NN來充當activeNN對外提供服務,一個是部署奇數臺的,這里建議當你的集群規模是在50臺一下的時候,ZK一般部署7個節點;50~100臺時,ZK在9或者11個節點;100以上就部署11個節點以上吧,但并部署越多越好的,ZK行程越多需要計算的時間就越多,選舉的時間就越長,所以合適就好,
HA集群設定了兩個名稱節點,“活躍(Active)”和“待命(Standby)”以至于不會落入單點故障,處于活躍狀態的名稱節點負責對外處理所有客戶端的請求,而處于待命狀態的名稱節點則作為備用節點,保存了足夠多的系統元資料,當名稱節點出現故障時提供快速恢復能力,也就是說,在HDFS HA中,處于待命狀態的名稱節點提供了“熱備份”,一旦活躍名稱節點出現故障,就可以立即切換到待命名稱節點,不會影響到系統的正常對外服務,
由于待命名稱節點是活躍的“熱備份”,因此活躍名稱節點的狀態資訊必須實時同步到待命名稱節點,兩種名稱節點的狀態同步,可以借助于一個共享存盤系統來實作,比如NFS(Network File System)、QJM(Quorum Journal Manager)或者Zookeeper,活躍名稱節點將更新資料寫入到共享存盤系統,待命名稱節點會一直監聽該系統,一旦發現有新的寫入,就立即從公共存盤系統中讀取這些資料并加載到自己的記憶體中,從而保證與活躍名稱節點狀態完全同步,此外,名稱節點中保存了資料庫(block)到實際存盤位置的映射資訊,即每個資料塊是由哪個資料節點存盤的,當一個資料節點加入HDFS集群時,它會把自己所包含的資料塊串列報告給名稱節點,此后會通過“心跳”的方式定期執行這種告知操作,以確保名稱節點的塊映射是最新的,
2.1.2HDFS Federation(聯邦)
HDFS1.0采用單名稱節點的設計,還存在可擴展性、性能和隔離性等問題,而HDFS聯邦可以很好地解決上述三個方面的問題,
- HDFS聯邦采用多個相互獨立的名稱節點,使得HDFS的命名服務能夠水平擴展,這些名稱節點分別進行各自命名空間和塊的管理,相互之間是聯邦(Federation)關系,不需要批次協調,并且向后兼容
- HDFS聯邦中,所有名稱節點會共享底層的資料節點存盤資源,資料節點向所有名稱節點匯報
- 屬于同一個命名空間的塊構成一個“塊池”
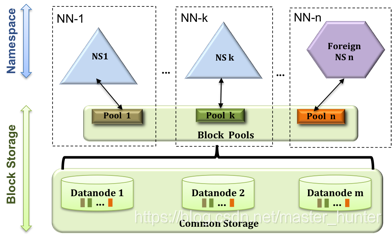
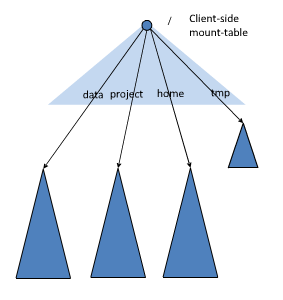
- 對于聯邦中多個命名空間,可以采用客戶端掛載表(Client Side Mount Table)方式進行資料共享和訪問
- 客戶可以訪問不同的掛載點來訪問不同的子命名空間
- 把各個命名空間掛載到全域“掛載表”(mount-table)中,實作資料全域共享
- 同樣的命名空間掛載到個人的掛載表中,就稱為應用程式課件的命名空間
HDFS Federation設計可以解決單名稱節點存在的以下幾個問題:
- HDFS集群擴展性,多個名稱節點各自分管一部分目錄,使得一個集群可以擴展到更多節點,不再像HDFS1.0中那樣由于記憶體的限制制約檔案存盤數目
- 性能更高效,多個名稱節點管理不同的資料,且同時對外提供服務,將為用戶提供更好的讀寫吞吐率,
- 良好的隔離性,用戶可根據需要將不同業務資料交由不同名稱節點管理,這樣不同業務之間影響很小,
需要注意的是,HDFS Federation并不能解決單點故障問題,也就是說,每個名稱節點都存在在單點故障問題,需要為每個名稱節點部署一個后備名稱節點,以應對名稱節點掛掉對業務產生的影響,
2.2YARN
YARN設計思路是將原JobTacker三大功能拆分
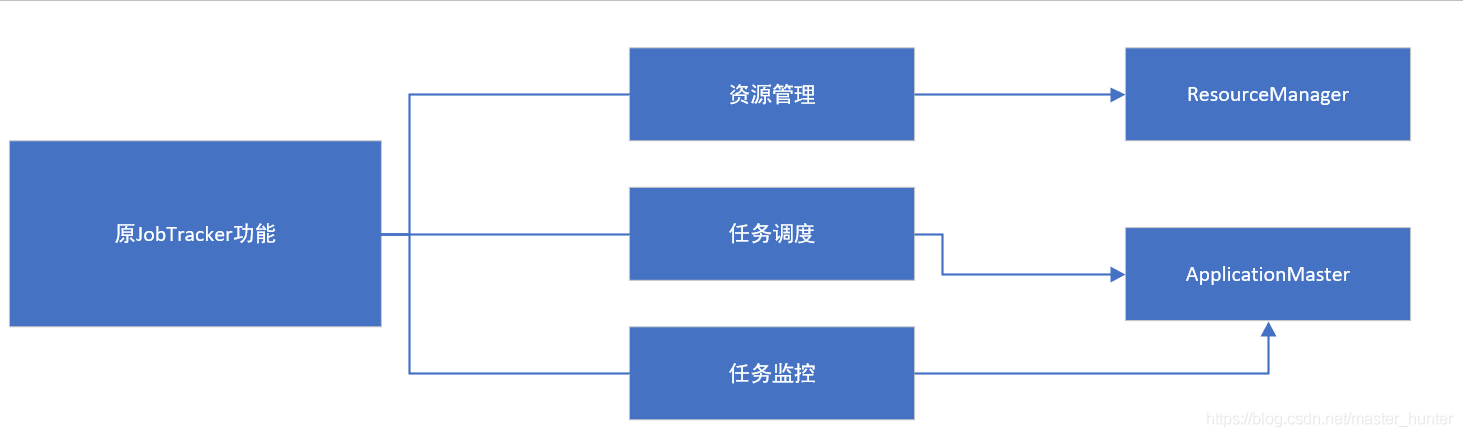
Hadoop2.0以后,MapReduce1.0中的資源管理調度功能,被單獨分離出來形成了YARN,它是一個純粹的資源管理調度框架,而不是一個計算框架,被剝離了資源管理調度功能的MapReduce就變成了MapReduce2.0,它是運行在YARN之上的一個純粹的計算框架,不再自己負責資源調度管理服務,而是由YARN為其提供資源管理調度服務,
YARN作業調度流程
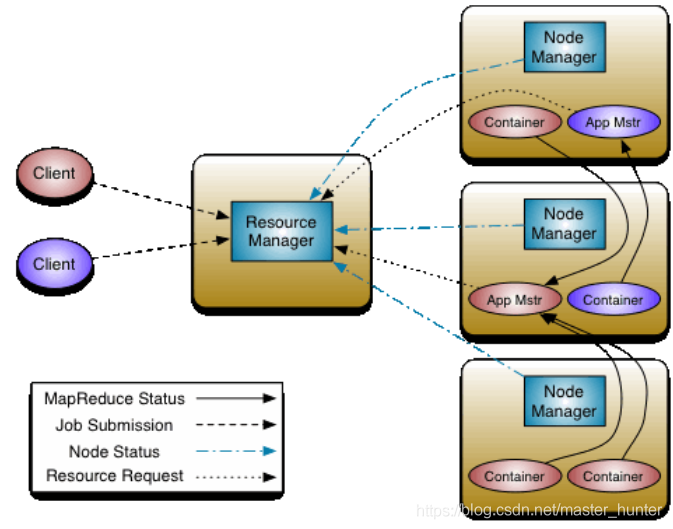
2.2.1ResourceManager
- 處理客戶端請求
- 啟動/監控ApplicationMaster
- 監控NodeManager
- 資源分配與調度
ResourceManager 擁有系統所有資源分配的決定權,負責集群中所有應用程式的資源分配,擁有集群資源主要、全域視圖,因此為用戶提供公平的,基于容量的,本地化資源調度,根據程式的需求,調度優先級以及可用資源情況,動態分配特定節點運行應用程式,它與每個節點上的NodeManager和每一個應用程式的ApplicationMaster協調作業,
ResourceManager的主要職責在于調度,即在競爭的應用程式之間分配系統中的可用資源,并不關注每個應用程式的狀態管理,
ResourceManager主要有兩個組件:Scheduler和ApplicationManager:Scheduler是一個資源調度器,它主要負責協調集群中各個應用的資源分配,保障整個集群的運行效率,Scheduler的角色是一個純調度器,它只負責調度Containers,不會關心應用程式監控及其運行狀態等資訊,同樣,它也不能重啟因應用失敗或者硬體錯誤而運行失敗的任務,
調度器被設計成一個可插拔的組件,YARN不僅自身提供了許多種直接可用的調度器,也應許用戶根據自己的需求設計調度器,
容器(Container)作為動態資源分配單位,每個容器中都封裝了一定數量的CPU、記憶體、磁盤等資源,從而限定每個應用程式可以使用的資源量,
2.2.2ApplicationMaster
- 為應用程式申請資源,并分配給內部任務
- 任務調度、監控與容錯
ApplicationManager主要負責接收job的提交請求,為應用分配第一個Container來運行ApplicationMaster,還有就是負責監控ApplicationMaster,在遇到失敗時重啟ApplicationMaster運行的Container
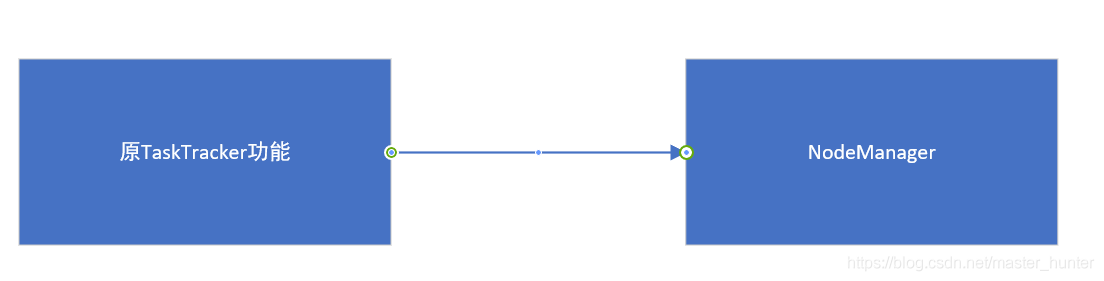
2.2.3NodeManager
- 單個節點上的資源管理
- 處理來自ResourceManager的命令
- 處理來自ApplicationMaster的命令
NodeManager是yarn節點的一個“作業行程”代理,管理hadoop集群中獨立的計算節點,主要負責與ResourceManager通信,負責啟動和管理應用程式的container的生命周期,監控它們的資源使用情況(cpu和記憶體),跟蹤節點的監控狀態,管理日志等,并報告給RM,
NodeManager在啟動時,NodeManager向ResourceManager注冊,然后發送心跳包來等待ResourceManager的指令,主要目的是管理resourcemanager分配給它的應用程式container,NodeManager只負責管理自身的Container,它并不知道運行在它上面應用的資訊,在運行期,通過NodeManager和ResourceManager協同作業,這些資訊會不斷被更新并保障整個集群發揮出最佳狀態
總結
Hadoop1.0主要存在以下不足:
- 抽象層次低,需要人工編碼
- 表達能力有限
- 開發者自己管理作業之間的依賴關系
- 難以看到程式整體邏輯
- 執行迭代操作效率低
- 資源浪費
- 實時性差
Hadoop的優化與發展主要體現在兩個方面:
- 一方面是Hadoop自身兩大核心組件MapReduce和HDFS的架構設計改進
- 另一方面是Hadoop生態系統其它組件的不斷豐富,加入了Pig、Tez、Spark和Kafka等新組件
參閱:
https://www.cnblogs.com/listenfwind/p/10121817.html
https://blog.csdn.net/u012050154/article/details/52353545
https://www.cnblogs.com/51runsky/p/4572428.html
https://www.cnblogs.com/xd502djj/p/4433020.html
https://blog.csdn.net/liweihope/article/details/88888644
https://www.cnblogs.com/ilifeilong/p/10617062.html
https://blog.csdn.net/weixin_43267534/article/details/84581262
https://www.cnblogs.com/zsql/p/11636112.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/227512.html
標籤:其他