首先, 這個Flash不是我們在瀏覽器用的Flash這種技術, 而是:

動作緩慢, 車速極快------閃電(Flash).
18年的某一個周末, 即興用Python寫了一個Virtual Actor模式的demo, 起了一個名字叫Flash, 是因為速度快如閃電------做framework快, 通過framework寫邏輯快.
所以大言不慚, 叫Flash, https://github.com/egmkang/flash. 第一個版本是asyncio寫的, 但是撰寫的程序中發現一旦少寫一點東西(async/await), bug會很難找. 這一點和C#是不太一樣的, 所以第一個版本可以跑之后, 花了一點時間把asyncio的代碼換成了gevent.
這邊主要來說說當時的想法, 以后未來如果要做類似的東西, 該如何選擇. (README里面的東西可能和實作沒多少關系......懶, 所以也不打算更改README, 錯了就錯了)
當時為了實作一個去中心化, 可以橫向擴容, 可以故障遷移的有狀態framework. (很顯然我對無狀態的東西一點興趣都沒有:-D)
所有有幾個關鍵點, 這邊簡單介紹一下(因為代碼不一定能跑起來, 但是思想可以):
1) RPC
這邊沒有使用第三方RPC庫, 而是選擇自己實作看了一個. 在Python這種語言里面, 實作一個RPC還是比較簡單的, 所需要的例如future/promise, 序列化庫, 協程, 還是就是Python是動態語言, 所以造一個Proxy物件比較簡單(C#里面是DispatchProxy).
future/promise選擇了gevent.event.AsyncResult.
序列化庫選擇了pickle, 序列化這邊做法實際上是有一點問題的, 第一個就是pickle效率較低, 資料比較大; 第二個就是RpcRequest/RpcResponse協議的設計不對, 因為Python的args是沒有經過序列化直接塞到RpcRequest里面的, 所以沒看出來有啥問題, 但是如果是其他語言這樣就行不通了. 所以比較科學的做法還是brpc那種, 包分成三部分: 包頭, meta, data. 其中meta用來形容data資料和請求的元資料, 這樣的話, args資料就不會被encode兩次. python里面可以這么搞不代表其他語言也可以這么搞.
Proxy物件的話, 是自己造的. 在rpc_proxy.py里面, 通過重寫__call__元方法, 實作比較復雜的功能. C#的DispatchProxy也能實作這種功能, 而且功能更強大, 型別還是安全的, Python里面做不到型別安全. 不支持動態代碼生成的語言做這個都不太好做, 例如golang/c++等.
哦, 還有就是網路庫里面一定要注意send和sendall這兩種東西的區別, 對于用戶來講sendall代碼容易撰寫, 但是用send實作就需要注意一下回傳值, 否則可能發了一半資料, 然后對面收到的流是斷的.
2) 服務發現
元資料存在etcd里面.
每個行程拉起來的時候, 通過uuid生成一個唯一的id, 當做ServerID, 然后組成一個MachineInfo, 然后就開啟了一個update_machine_member_info的死回圈, 去etcd里面不停的去更新自己的資訊(有一個5s的CD).
然后再開啟一個get_members_info死回圈去不停的刀etcd里面pull最新的membership資訊, 然后再保存到記憶體中.
這樣在MemberShipManager里面就可以不停的add_machine, remove_machine.
這樣做的話, 只需要經過幾個TTL, 集群的所有節點就能感知到成員的變更; 成員和etcd失聯, 那么就應該自己退出(Flash里面沒做).
3) 物件的定位
上面說了, 集群內的節點對其他節點的感知實際上是靠定時pull etcd資訊來獲得的, 那么新加入的節點, 就不能立馬提供服務, 否則集群元資料是不一致的. 例如5s間隔去pull, 那么3個interval之后, 其他節點大概率是能感知到節點的變更. 所以等一段時間再路由新的請求到新增服務器, 可以做到更好的一致性.
然后, MachineInfo內有服務器的負載資訊, 那么:
0> 先到行程內快取區尋找物件的位置, 看看最近是否有人請求過, 如果目標服務器健康(保持心跳), 那么直接回傳
1> 先去到etcd里面查詢物件的位置是否存在, 如果存在, 并且machine健康, 那么直接回傳(并快取)
2> 對物件上分布式鎖(通過etcd), 然后再做步驟1>, 還未找到物件的位置, 那么獲取到可以提供相應服務的machine串列, 通過負載權重, 隨機出來一個新的服務器, 然后保存etcd, 保存行程快取, 回傳
很明顯, 物件的定位是通過客戶端側+帶權重的Random來做的. 這只是一種選擇, 完成一個功能有很多選擇.
4) 故障遷移
物件的定位有一個檢測目標服務器是否健康的程序, 實際上就是目標服務器是否最近向etcd更新過自己的心跳, 如果更新過那么認為健康, 否則就是不健康.
那么, 當目標服務器不健康的時候, 就會觸發物件的再定位, 從而實作故障的遷移.
5) 可重入性
互聯網的服務不存在這個問題, 是因為互聯網的無狀態服務, 不存在排隊等候處理請求的程序.
但是在有狀態服務里面, 往往會對同一個用戶(或者其他單位)的請求進行排隊. 那么試想一下, 排隊處理A的請求, A又呼叫了B, B又呼叫了A. A的請求沒有回傳之前是不能處理其他的請求的, 所以這時候就死鎖了. 所以有狀態的Actor服務必須要處理這種情況.
這時候需要引入一點點代碼, 來看看RpcRequest的資料結構, 里面嗎包含了一個request_id, 但是在request_id之前有一個host. 實際上就是這倆資料, 決定了rpc請求的可重入性.
class RpcRequest:
def __init__(self):
self.clear()
def clear(self):
self.host = ""
if _global_id_generator is not None:
self.request_id = _global_id_generator.NextId()
else:
self.request_id = 0
self.entity_type = 0
self.entity_id = 0
self.method = ""
self.args = ()
self.kwargs = dict()
思考一下, Actor請求的一個請求是誰發出的? 肯定是外界系統產生的第一個請求, 那么這個請求沒有完成之前, 是不能處理其他請求的. 而中間的請求實際上都不是源頭. 所以我們只需要在源頭上面標記唯一ID, 中間傳染的路徑上面都用源頭的唯一ID, 所以系統里面有一個ActorContext的概念, 就是在保存這個資訊. Dispatch的程序也就變得比較簡單:
if entity.context().running is False:
gevent.spawn(lambda: _dispatch_entity_method_loop(entity))
if entity.context().host == request.host and entity.context().request_id <= request.request_id:
gevent.spawn(lambda: _dispatch_entity_method_anyway(entity, conn, request, response, method))
return
entity.context().send_message((conn, request, response, method))
如果物件的loop不在運行就拉起來, 如果現在正在處理的請求和當前需要被Dispatch的請求源自一個請求, 那么直接開啟一個協程去處理, 否則就塞進MailBox等候處理.
從而實作了可重入性.
Flash, 麻雀雖小五臟俱全, 實作不是很精良, 但是作為一個原型, 其目的已經達到. 可以對其實作進行反思, 組合出來更合理的分布式有狀態服務系統.
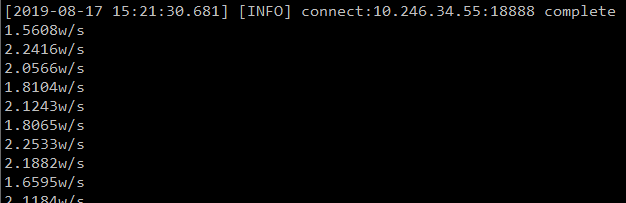
世人都說Python的性能差, 但是這個原型系統一秒可以跨行程進行1.5~2.2Wqps, 已經非常優秀了. 有沒有算過自己的系統到底要承載多少請求, Python真的就是系統的瓶頸?
參考:
0) Flash (https://github.com/egmkang/flash)
1) Orleans (https://dotnet.github.io/orleans/)
2) gevent (http://www.gevent.org/)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/228916.html
標籤:架構設計