導言
我們知道,當下流行的MQ非常多,不過很多公司在技術選型上還是選擇使用Kafka,與其他主流MQ進行對比,我們會發現Kafka最大的優點就是吞吐量高,實際上Kafka是高吞吐低延遲的高并發、高性能的訊息中間件,配置良好的Kafka集群甚至可以做到每秒幾十萬、上百萬的超高并發寫入,
除此之外,在熱招的Java架構師崗位面試中,Kafka相關的面試題被面試官問到的幾率也是非常大的,所以擁有一定年限的開發者,搞懂Kafka是很有必要的,
那么怎么才能有效且快速學習Kafka呢?
大佬的筆記必不可少:騰訊技術官手擼筆記分享,全新演繹“Kafka部署實戰”,已開源,
《Kafka筆記》完整pdf版下載:一鍵三連后“加我VX小助理”即可免費獲取到!


一、初識Kafka(Kafka入門)
①Kafka基本概念

②安裝與配置

③生產與消費

④服務端引數配置

二、生產者
①客戶端開發(必要的引數配置+訊息的發送+序列化+磁區器+生產者攔截器)

②原理分析(整體架構+元資料的更新)

③重要的生產者引數

三、消費者
①消費者與消費組
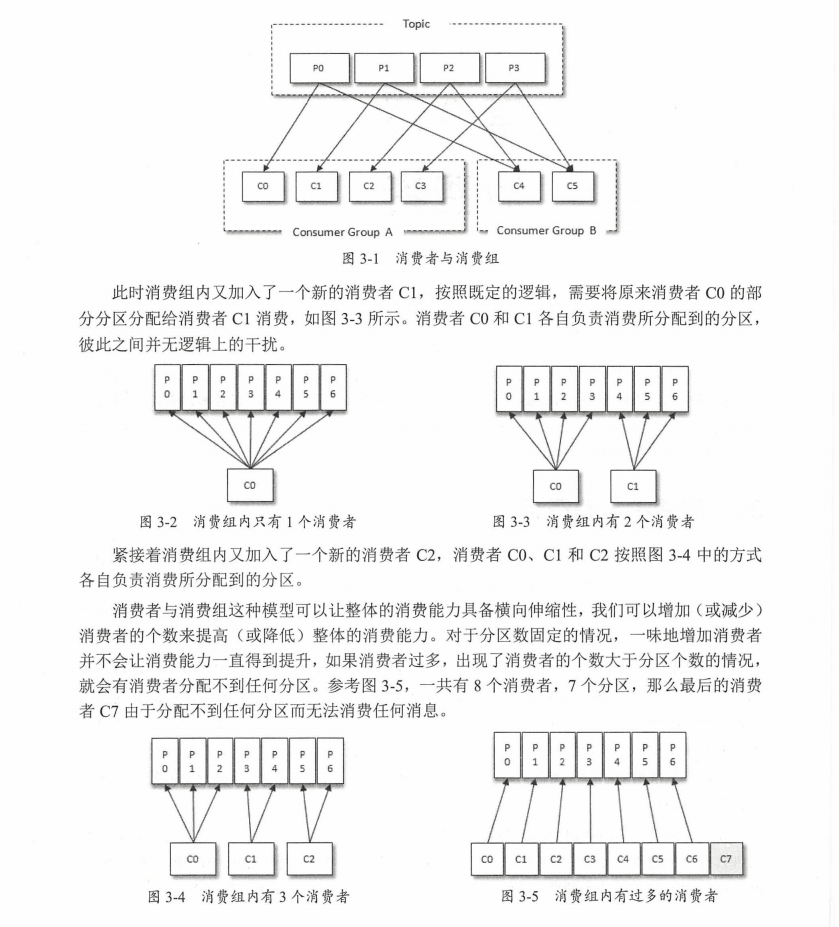
②客戶端開發(必要的引數配置+訂閱主題與磁區+反序列化+訊息消費+位移提交+控制或關閉消費+指定位移消費+再均衡+消費者攔截器+多執行緒實作+重要的消費者引數)

四、主題與磁區
①主題的管理(創建主題+磁區副本的分配+查看主題+修改主題+配置管理+主題端引數+洗掉主題)

②初始Kafka AdminClient(基本使用+主題合法性驗證)

③磁區的管理(優先副本的選舉+磁區重分配+復制限流+修改副本因子)

④如何選擇合適的磁區數(性能測驗工具+磁區數越多吞吐量就越高嗎+磁區數的上限+參考因素)

五、日志存盤
①檔案目錄布局

②日志格式的演變(v0版本+v1版本+訊息壓縮+變長欄位+v2版本)

③日志索引(偏移量索引+時間戳索引)

④日志清理(日志洗掉+日志壓縮)

⑤磁盤存盤(頁快取+磁盤I/O流程+零拷貝)

六、深入服務端
①協議設計
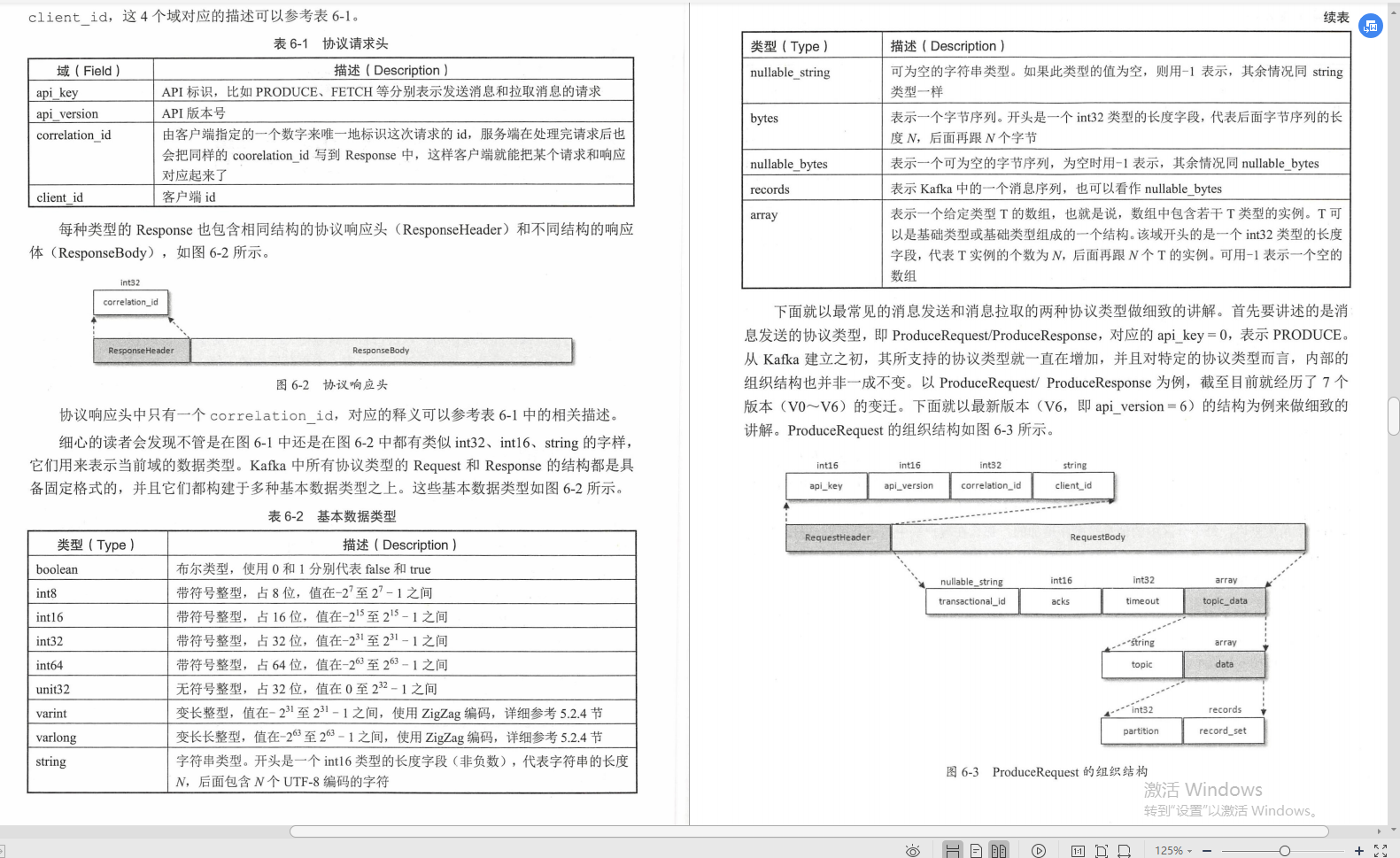
②時間輪

③延時操作

④控制器(控制器的選舉及例外恢復+優雅關閉+磁區leader的選舉+引數解密)

⑤引數解密(broker.id+bootstrap.servers+服務端引數串列)

七、深入客戶端
①磁區分配策略(RangeAssignor分配策略+RoundRobinAssignor分配策略+StickyAssignor分配策略+自定義磁區分配策略)

②消費者協調器和組協調器(舊版消費者客戶端的問題+再均衡的原理)
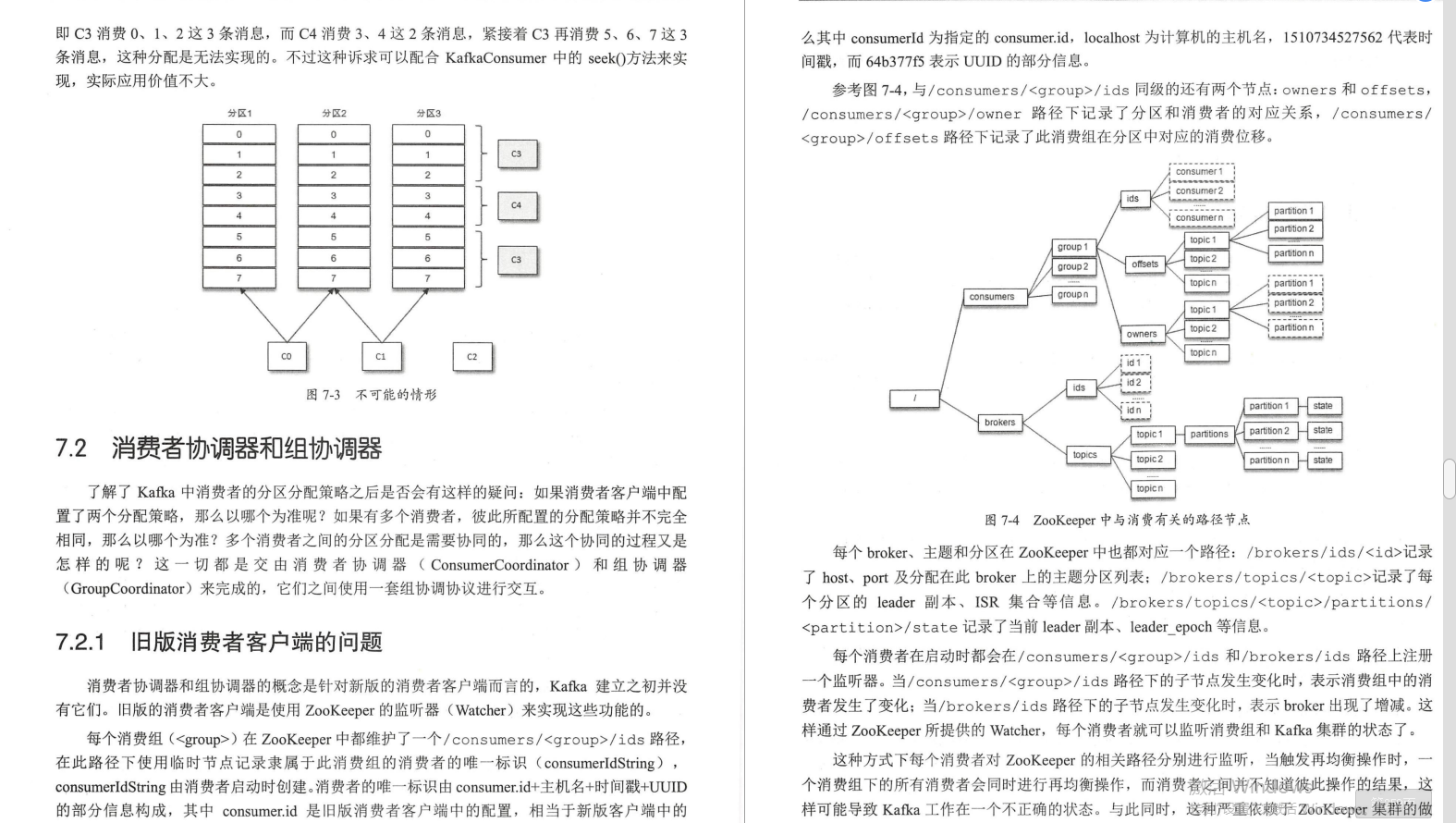
③_consumer_offsets剖析

④事務(訊息傳輸保障+冪等+事務)
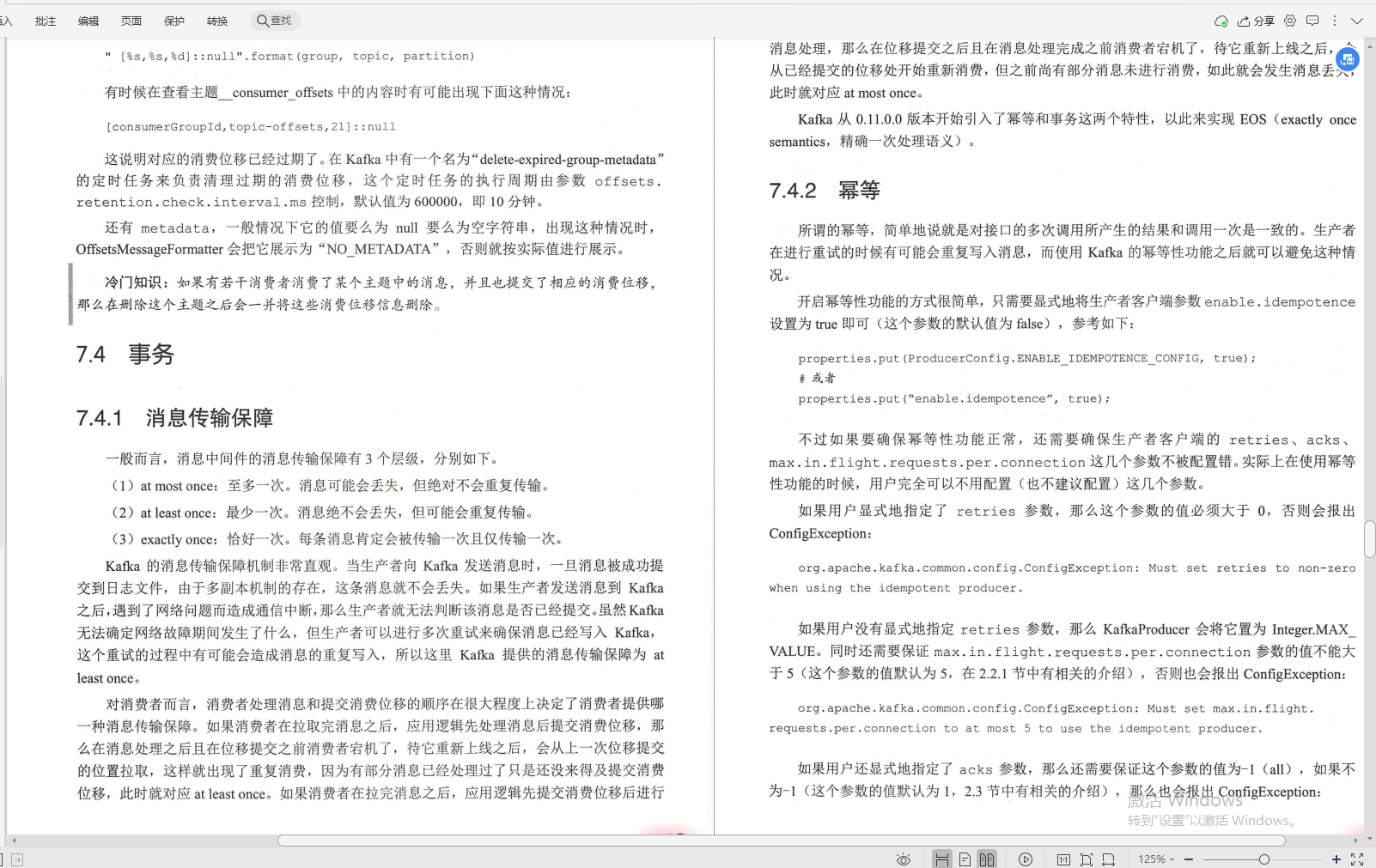
八、可靠性探究
①副本剖析(失效副本+ISR的伸縮+LEO與HW+Leader Epoch的介入+為什么不支持讀寫分離)

②日志同步機制

③可靠性分析

九、Kafka應用
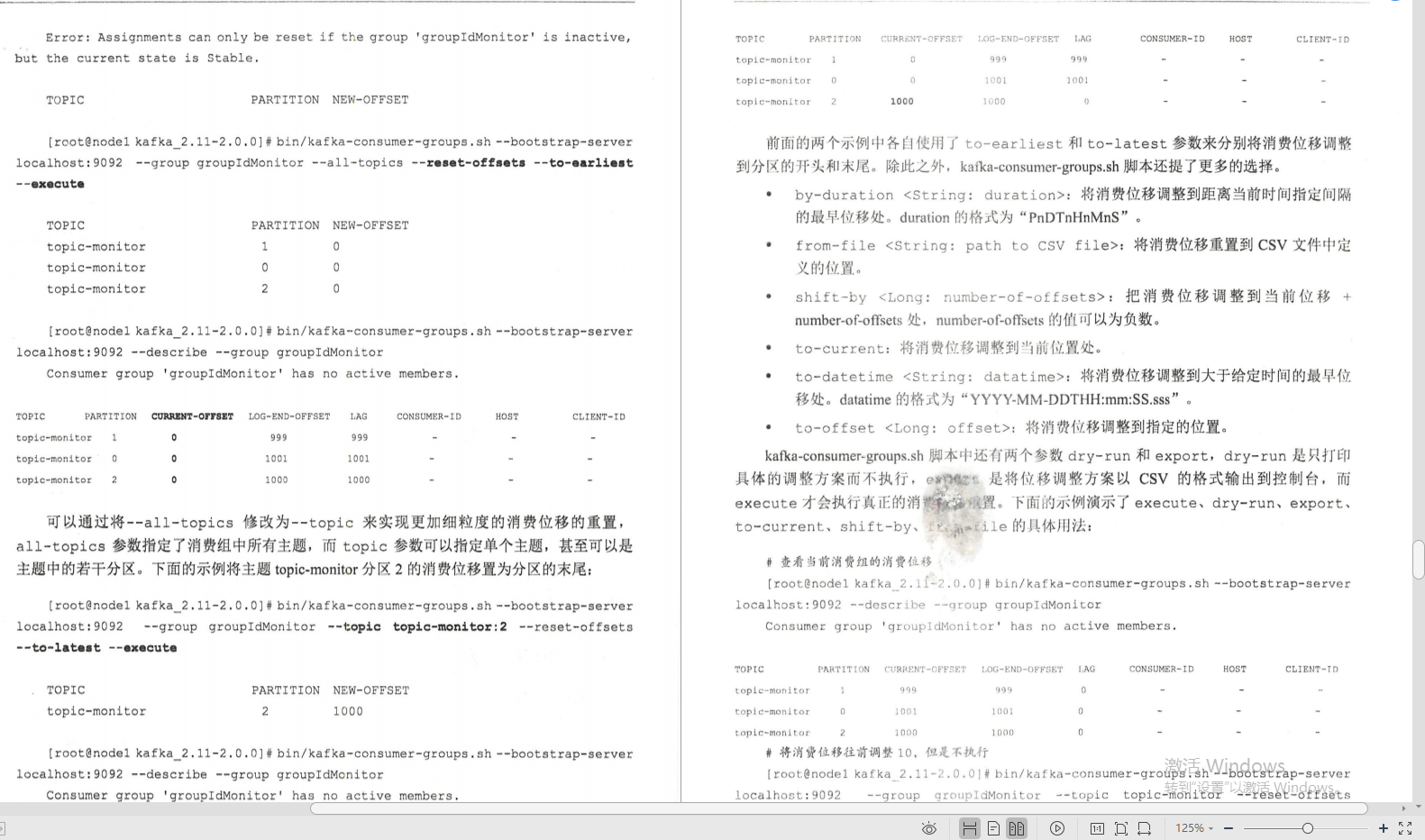
①命令列工具(消費組管理+消費位移管理+手動洗掉訊息)
②Kafka Connect(獨立模式+REST API+分布式模式)

③Kafka Mirror Maker

④Kafka Streams

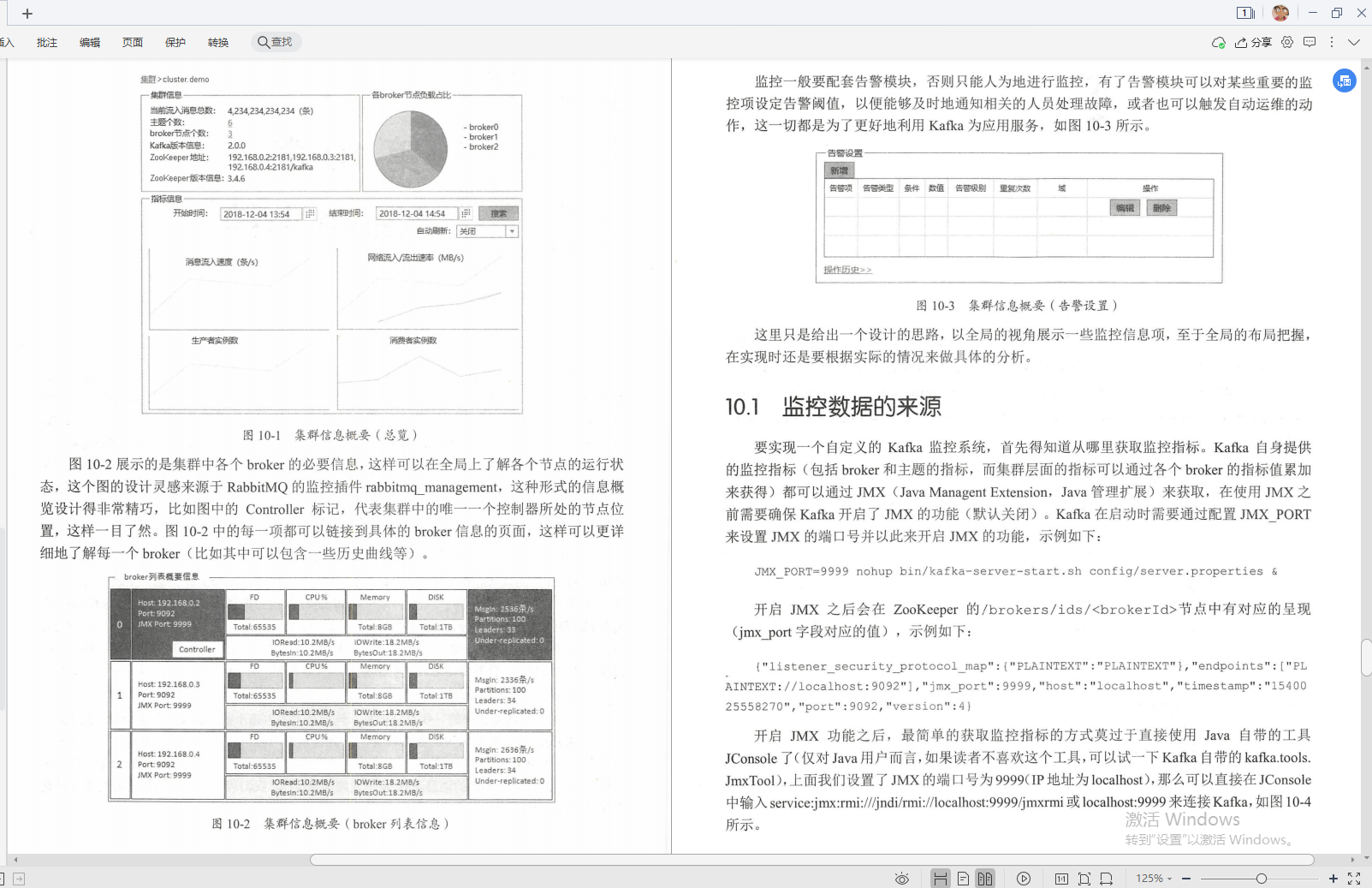
十、Kafka監控
①監控資料的來源(OneMinuteRate+獲取監控指標)
②消費滯后

③同步失效磁區

④監控指標說明

⑤監控模塊

十一、高級應用
①過期時間(TTL)
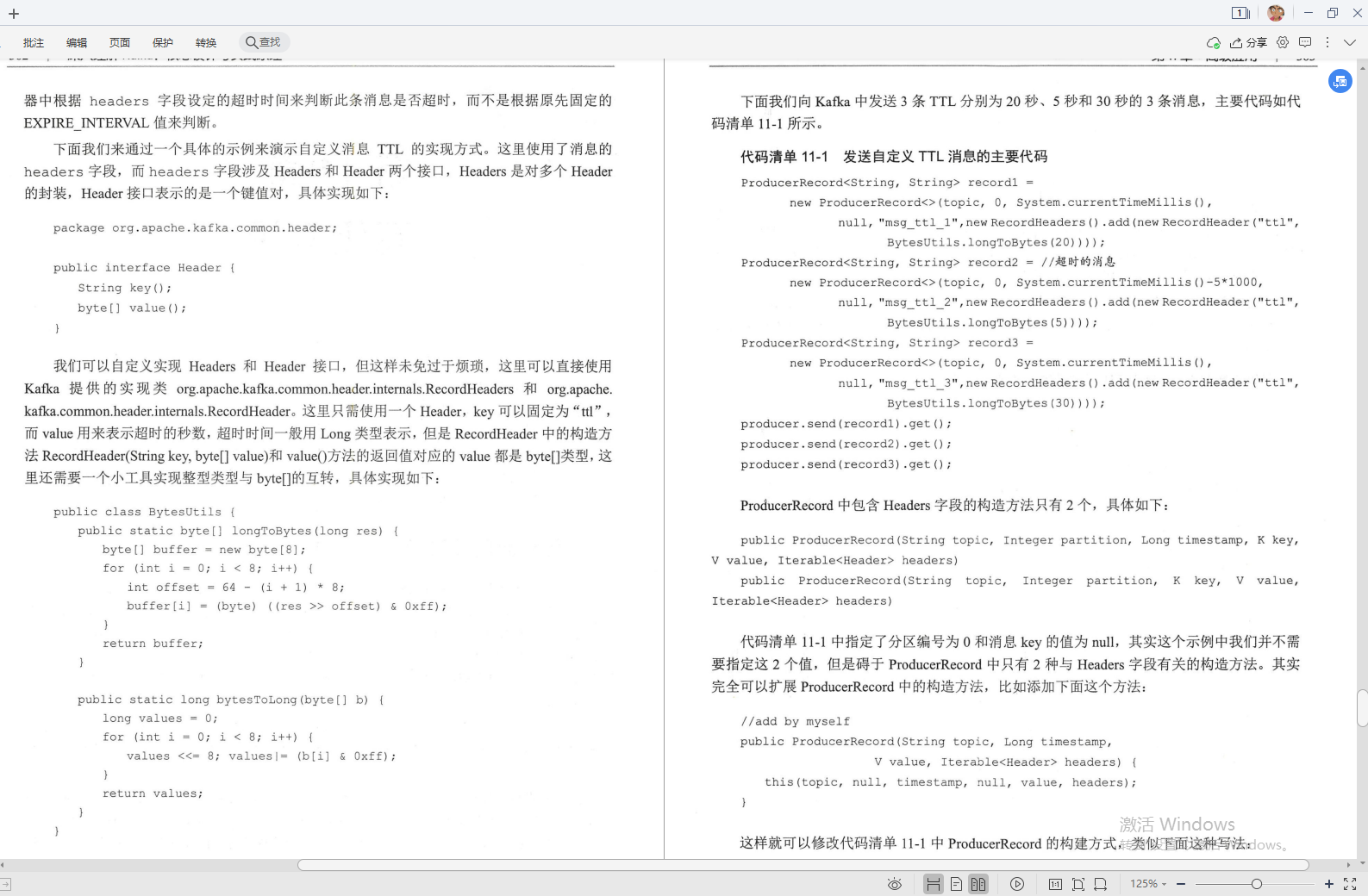
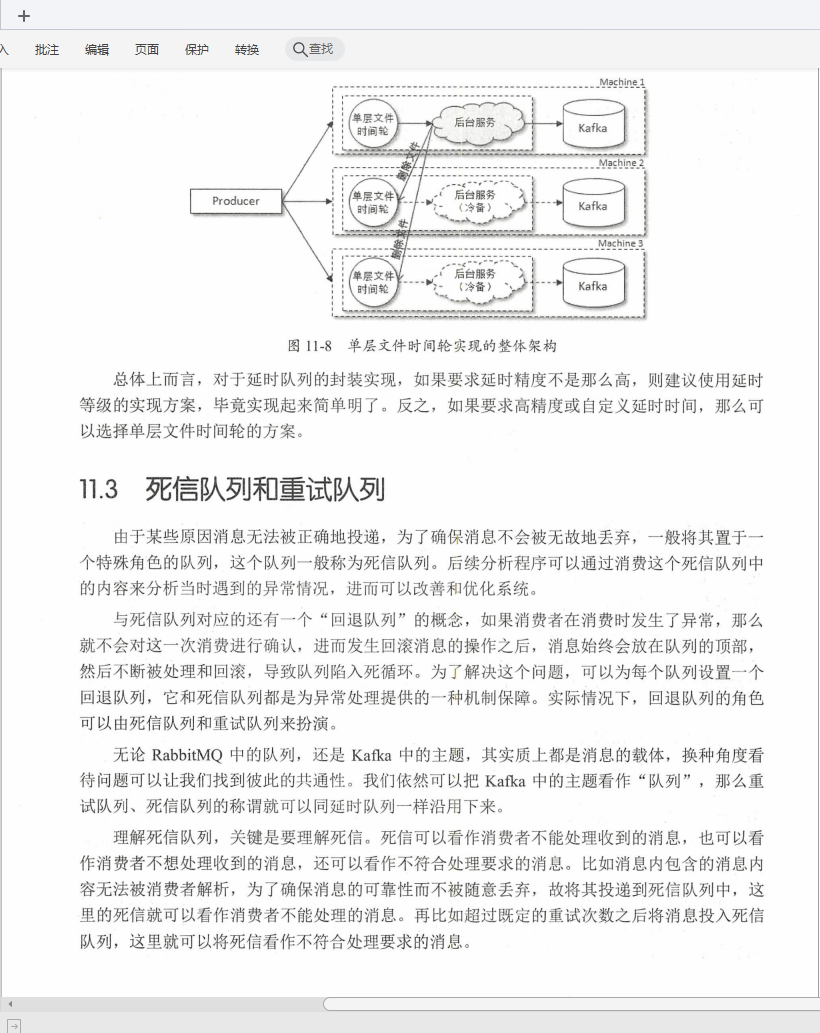
②延時佇列

③死信佇列和重試佇列
④訊息路由
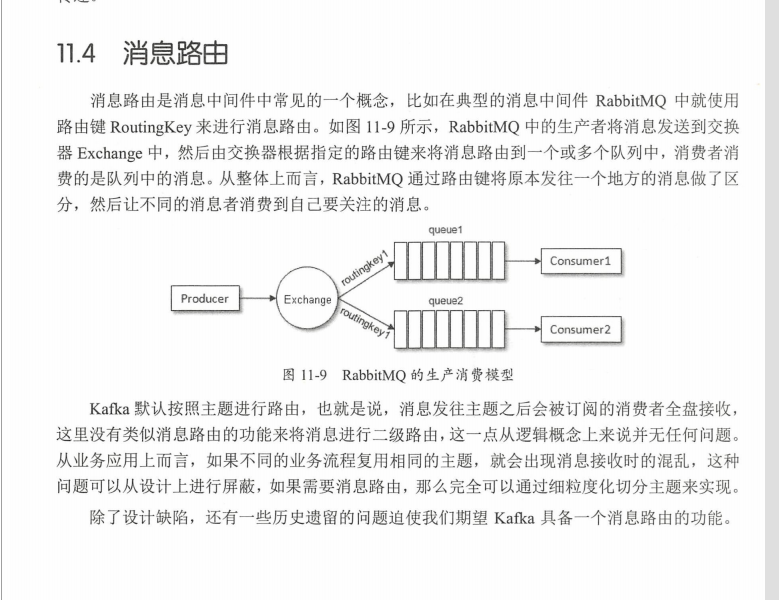
⑤訊息軌跡
⑥訊息審計

⑦訊息代理(快速入門+REST API介紹及示例+服務端配置及部署+應用思考)

⑧訊息中間件選型(各類訊息中間件簡述+選型要點概述+訊息中間件選型誤區探討)

十二、Kafka與Spark的集成
①Spark的安裝及簡單應用

②Spark編程模型

③Spark的運行結構

④Spark Streaming簡介

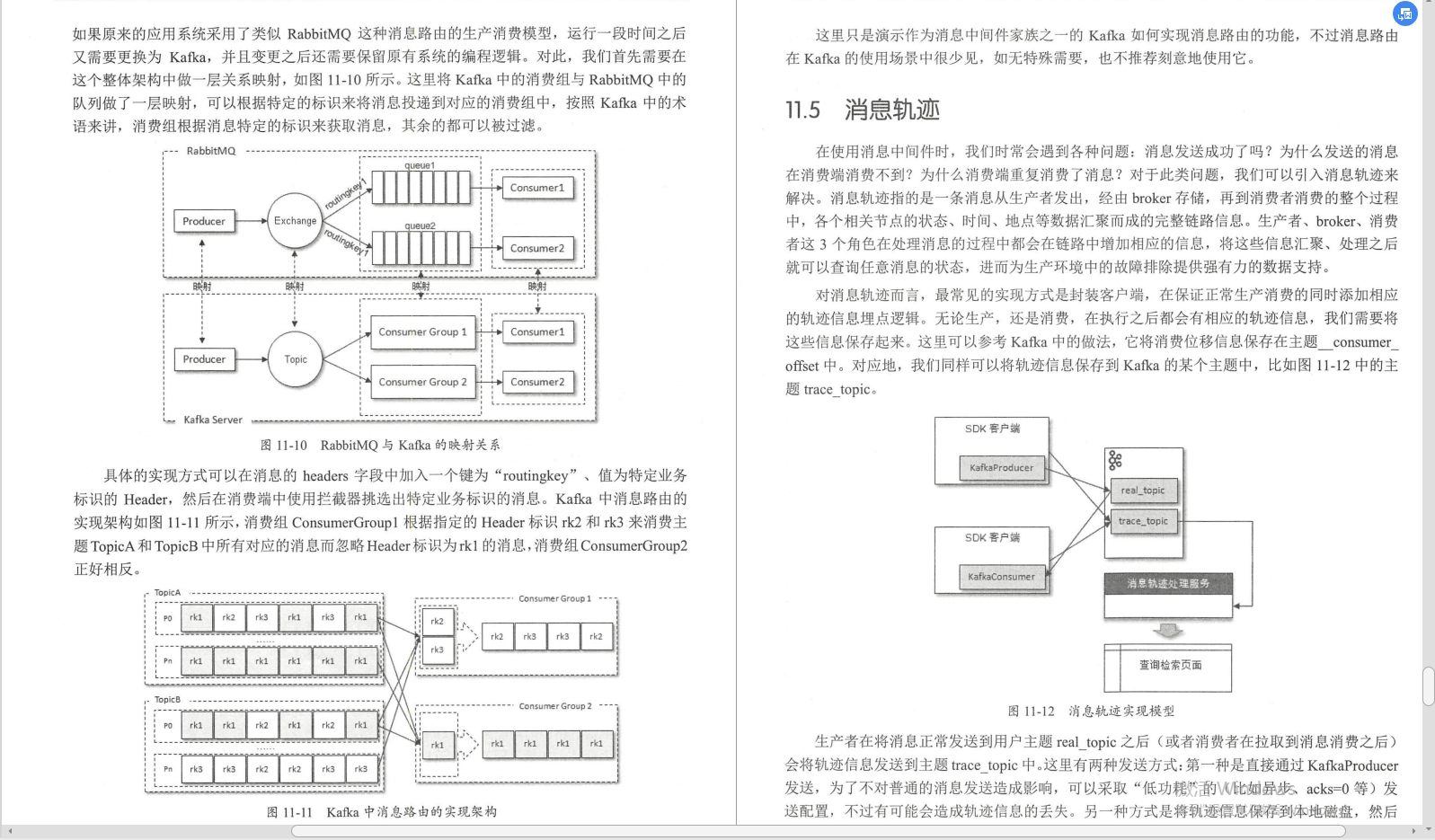
⑤Kafka與Spark Streaming的整合
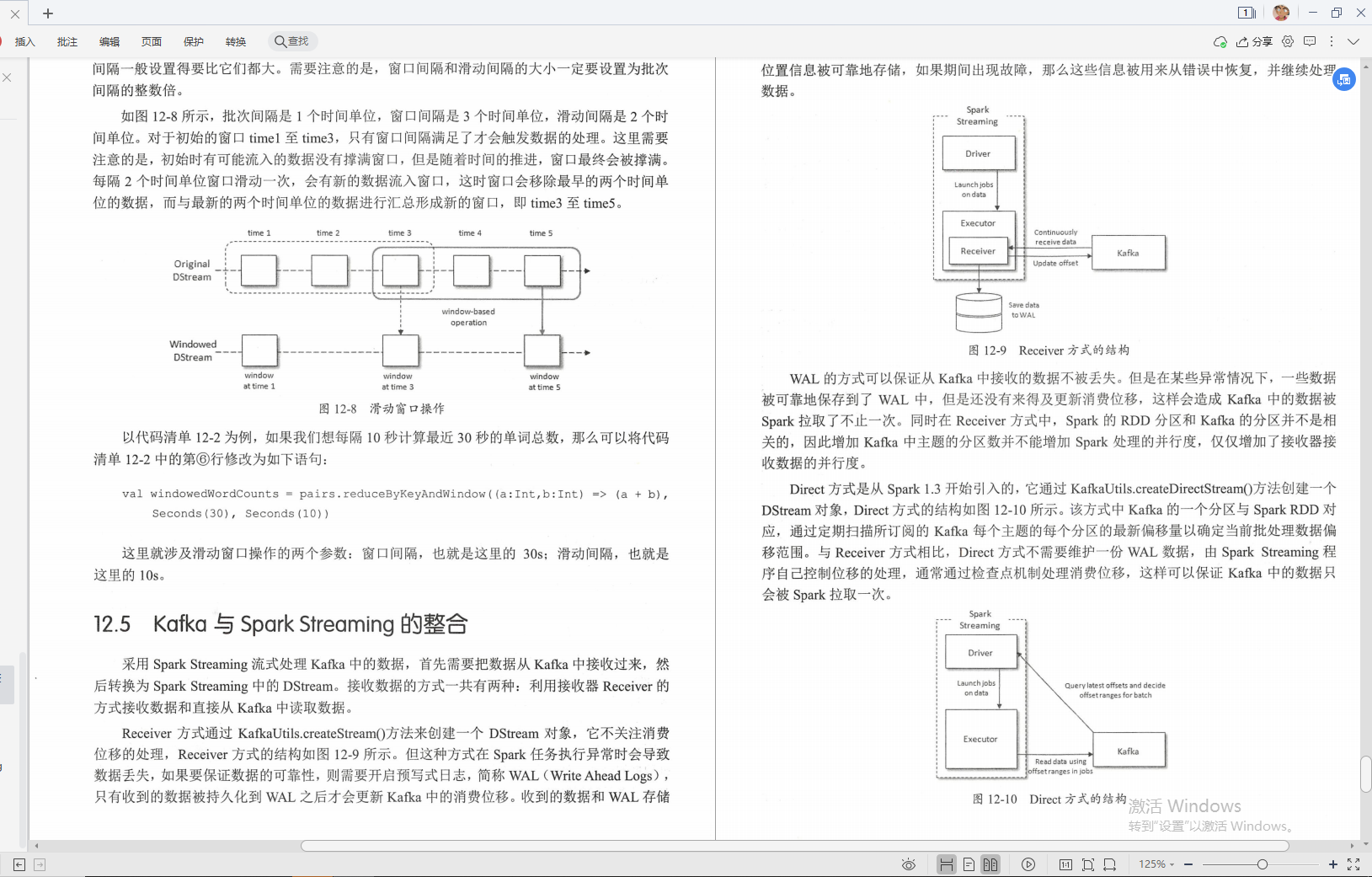
⑥Spark SQL

⑦Structured Streaming

⑧Kafka與Structured Streaming的整合
總結
Kafka的探討就在這里,只能展示部分內容,實際上筆記內詳細記載了Kafka的實踐內容,包括大量的代碼實作形式,
如果你對自己的職業生涯有清晰的規劃路線,想要往更長遠的方向去發展,那么學習Kafka,想必刻不容緩,
這份《Kafka筆記》免費分享,有需要的可以一鍵三連后“加我VX小助理”即可免費獲取到!

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/229134.html
標籤:其他