前言
本篇文章我們來探討一下并發設計模型,
可以使用不同的并發模型來實作并發系統,并發模型說的是系統中的執行緒如何協作完成并發任務,不同的并發模型以不同的方式拆分任務,執行緒可以以不同的方式進行通信和協作,
并發模型和分布式系統很相似
并發模型其實和分布式系統模型非常相似,在并發模型中是執行緒彼此進行通信,而在分布式系統模型中是 行程 彼此進行通信,然而本質上,行程和執行緒也非常相似,這也就是為什么并發模型和分布式模型非常相似的原因,
分布式系統通常要比并發系統面臨更多的挑戰和問題比如行程通信、網路可能出現例外,或者遠程機器掛掉等等,但是一個并發模型同樣面臨著比如 CPU 故障、網卡出現問題、硬碟出現問題等,
因為并發模型和分布式模型很相似,因此他們可以相互借鑒,例如用于執行緒分配的模型就類似于分布式系統環境中的負載均衡模型,
其實說白了,分布式模型的思想就是借鑒并發模型的基礎上推演發展來的,
認識兩個狀態
并發模型的一個重要的方面是,執行緒是否應該共享狀態,是具有共享狀態還是獨立狀態,共享狀態也就意味著在不同執行緒之間共享某些狀態
狀態其實就是資料,比如一個或者多個物件,當執行緒要共享資料時,就會造成 競態條件 或者 死鎖 等問題,當然,這些問題只是可能會出現,具體實作方式取決于你是否安全的使用和訪問共享物件,
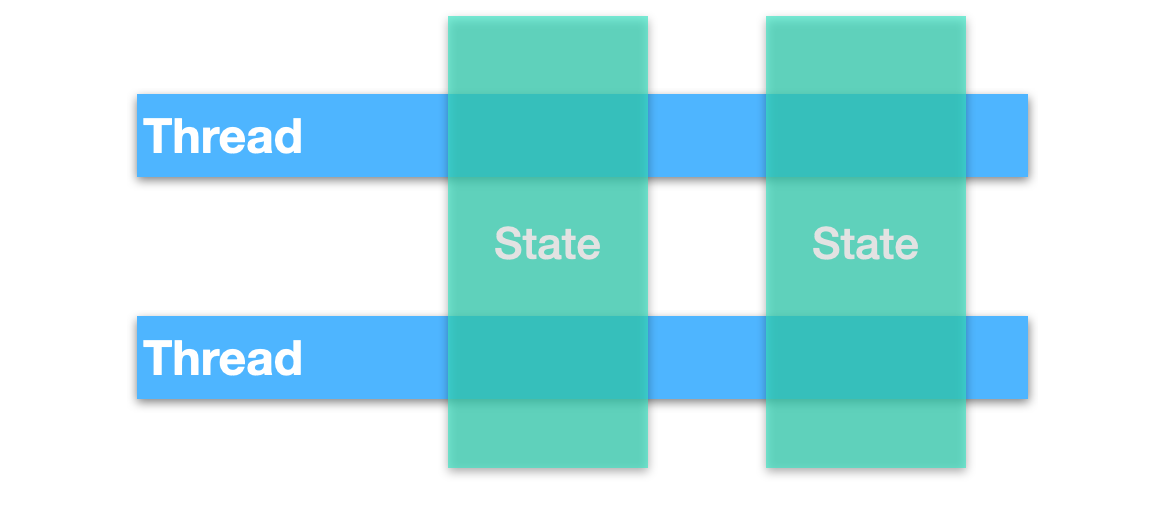
獨立的狀態表明狀態不會在多個執行緒之間共享,如果執行緒之間需要通信的話,他們可以訪問不可變的物件來實作,這是一種最有效的避免并發問題的一種方式,如下圖所示
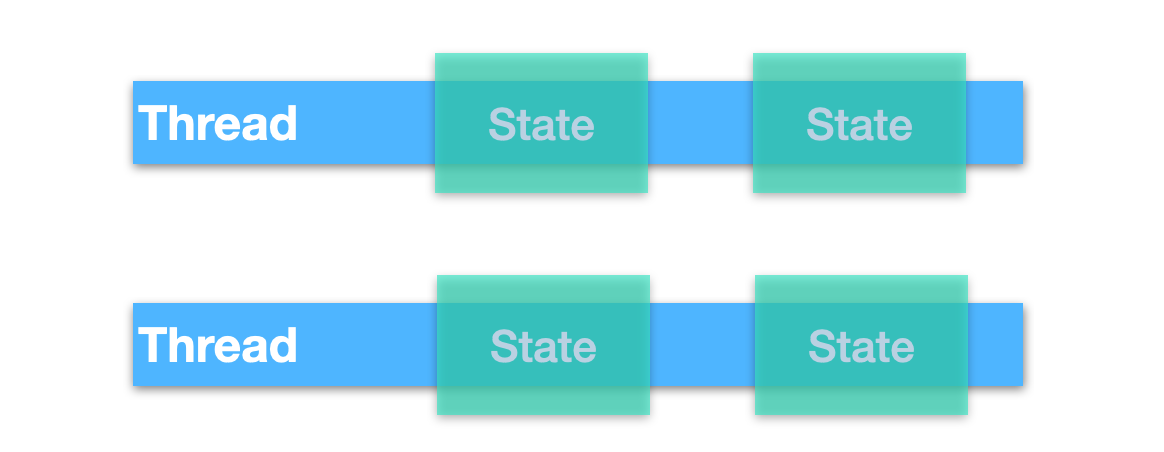
使用獨立狀態讓我們的設計更加簡單,因為只有一個執行緒能夠訪問物件,即使交換物件,也是不可變的物件,
并發模型
并行 Worker
第一個并發模型是并行 worker 模型,客戶端會把任務交給 代理人(Delegator),然后由代理人把作業分配給不同的 工人(worker),如下圖所示
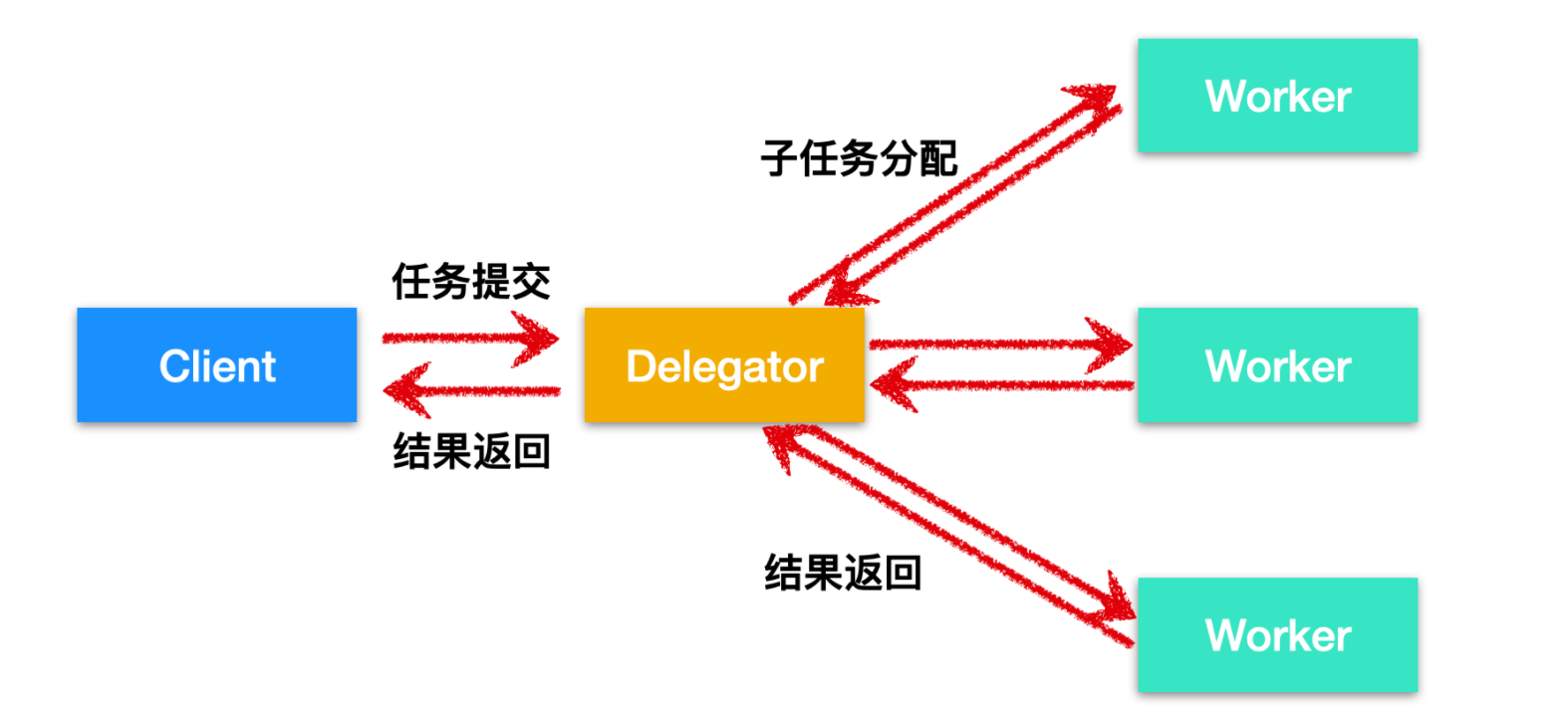
并行 worker 的核心思想是,它主要有兩個行程即代理人和工人,Delegator 負責接收來自客戶端的任務并把任務下發,交給具體的 Worker 進行處理,Worker 處理完成后把結果回傳給 Delegator,在 Delegator 接收到 Worker 處理的結果后對其進行匯總,然后交給客戶端,
并行 Worker 模型是 Java 并發模型中非常常見的一種模型,許多 java.util.concurrent 包下的并發工具都使用了這種模型,
并行 Worker 的優點
并行 Worker 模型的一個非常明顯的特點就是很容易理解,為了提高系統的并行度你可以增加多個 Worker 完成任務,
并行 Worker 模型的另外一個好處就是,它會將一個任務拆分成多個小任務,并發執行,Delegator 在接受到 Worker 的處理結果后就會回傳給 Client,整個 Worker -> Delegator -> Client 的程序是異步的,
并行 Worker 的缺點
同樣的,并行 Worker 模式同樣會有一些隱藏的缺點
共享狀態會變得很復雜
實際的并行 Worker 要比我們圖中畫出的更復雜,主要是并行 Worker 通常會訪問記憶體或共享資料庫中的某些共享資料,
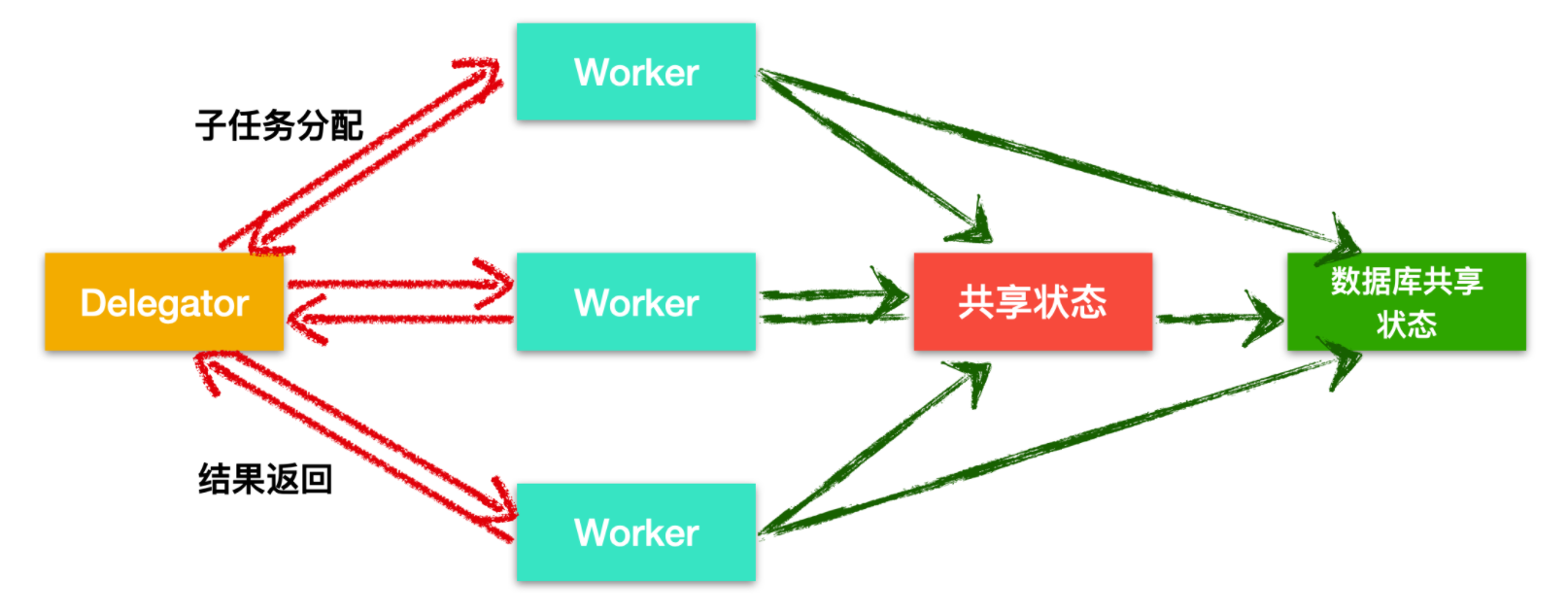
這些共享狀態可能會使用一些作業佇列來保存業務資料、資料快取、資料庫的連接池等,在執行緒通信中,執行緒需要確保共享狀態是否能夠讓其他執行緒共享,而不是僅僅停留在 CPU 快取中讓自己可用,當然這些都是程式員在設計時就需要考慮的問題,執行緒需要避免 競態條件,死鎖 和許多其他共享狀態造成的并發問題,
多執行緒在訪問共享資料時,會丟失并發性,因為作業系統要保證只有一個執行緒能夠訪問資料,這會導致共享資料的爭用和搶占,未搶占到資源的執行緒會 阻塞,
現代的非阻塞并發演算法可以減少爭用提高性能,但是非阻塞演算法比較難以實作,
可持久化的資料結構(Persistent data structures) 是另外一個選擇,可持久化的資料結構在修改后始侄訓保留先前版本,因此,如果多個執行緒同時修改一個可持久化的資料結構,并且一個執行緒對其進行了修改,則修改的執行緒會獲得對新資料結構的參考,
雖然可持久化的資料結構是一個新的解決方法,但是這種方法實行起來卻有一些問題,比如,一個持久串列會將新元素添加到串列的開頭,并回傳所添加的新元素的參考,但是其他執行緒仍然只持有串列中先前的第一個元素的參考,他們看不到新添加的元素,
持久化的資料結構比如 鏈表(LinkedList) 在硬體性能上表現不佳,串列中的每個元素都是一個物件,這些物件散布在計算機記憶體中,現代 CPU 的順序訪問往往要快的多,因此使用陣列等順序訪問的資料結構則能夠獲得更高的性能,CPU 高速快取可以將一個大的矩陣塊加載到高速快取中,并讓 CPU 在加載后直接訪問 CPU 高速快取中的資料,對于鏈表,將元素分散在整個 RAM 上,這實際上是不可能的,
無狀態的 worker
共享狀態可以由其他執行緒所修改,因此,worker 必須在每次操作共享狀態時重新讀取,以確保在副本上能夠正確作業,不在執行緒內部保持狀態的 worker 成為無狀態的 worker,
作業順序是不確定的
并行作業模型的另一個缺點是作業的順序不確定,無法保證首先執行或最后執行哪些作業,任務 A 在任務 B 之前分配給 worker,但是任務 B 可能在任務 A 之前執行,
流水線
第二種并發模型就是我們經常在生產車間遇到的 流水線并發模型,下面是流水線設計模型的流程圖

這種組織架構就像是工廠中裝配線中的 worker,每個 worker 只完成全部作業的一部分,完成一部分后,worker 會將作業轉發給下一個 worker,
每道程式都在自己的執行緒中運行,彼此之間不會共享狀態,這種模型也被稱為無共享并發模型,
使用流水線并發模型通常被設計為非阻塞I/O,也就是說,當沒有給 worker 分配任務時,worker 會做其他作業,非阻塞I/O 意味著當 worker 開始 I/O 操作,例如從網路中讀取檔案,worker 不會等待 I/O 呼叫完成,因為 I/O 操作很慢,所以等待 I/O 非常耗費時間,在等待 I/O 的同時,CPU 可以做其他事情,I/O 操作完成后的結果將傳遞給下一個 worker,下面是非阻塞 I/O 的流程圖
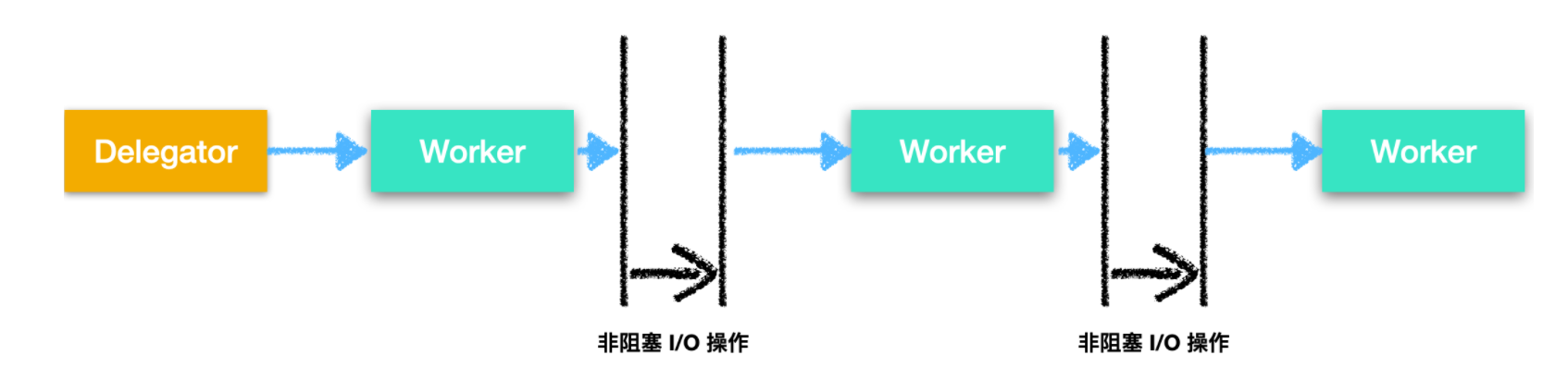
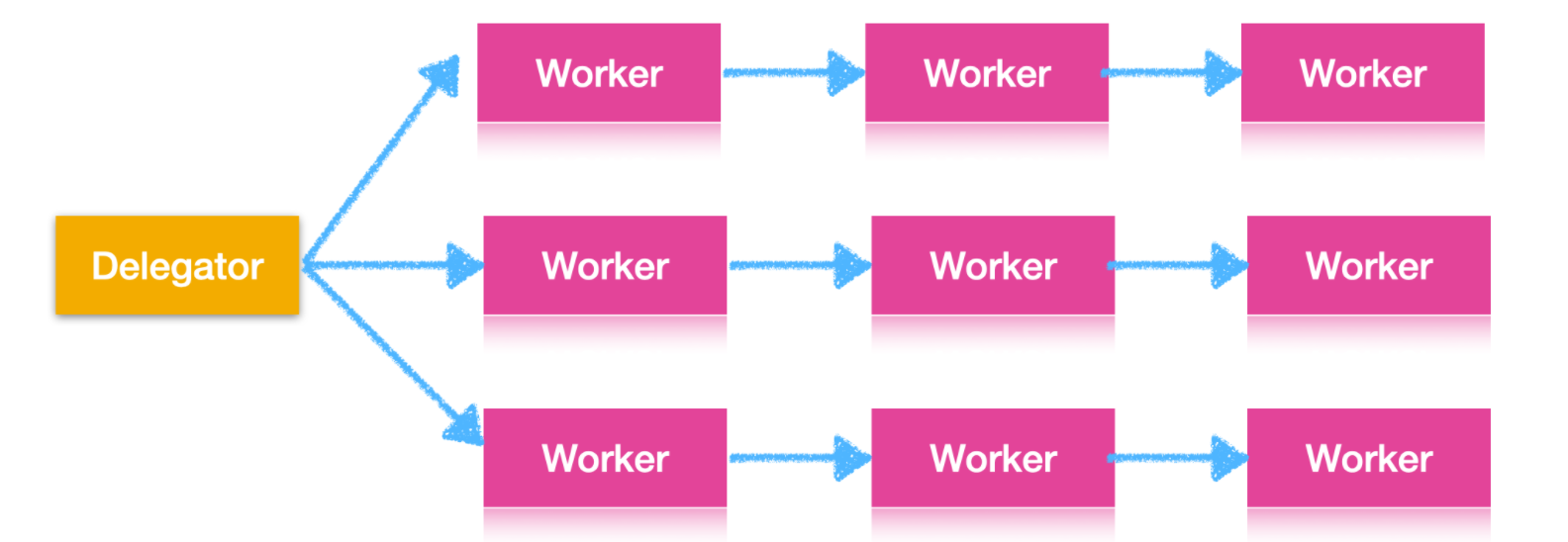
在實際情況中,任務通常不會按著一條裝配線流動,由于大多數程式需要做很多事情,因此需要根據完成的不同作業在不同的 worker 之間流動,如下圖所示
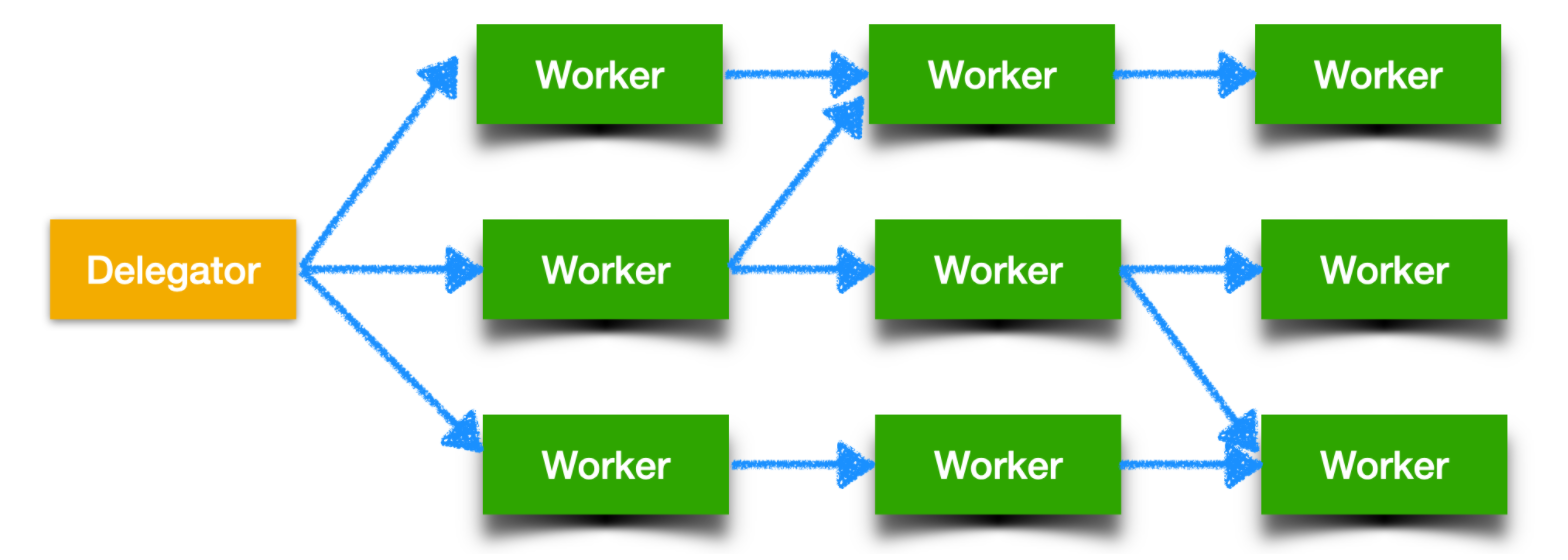
任務還可能需要多個 worker 共同參與完成
回應式 - 事件驅動系統
使用流水線模型的系統有時也被稱為 回應式 或者 事件驅動系統,這種模型會根據外部的事件作出回應,事件可能是某個 HTTP 請求或者某個檔案完成加載到記憶體中,
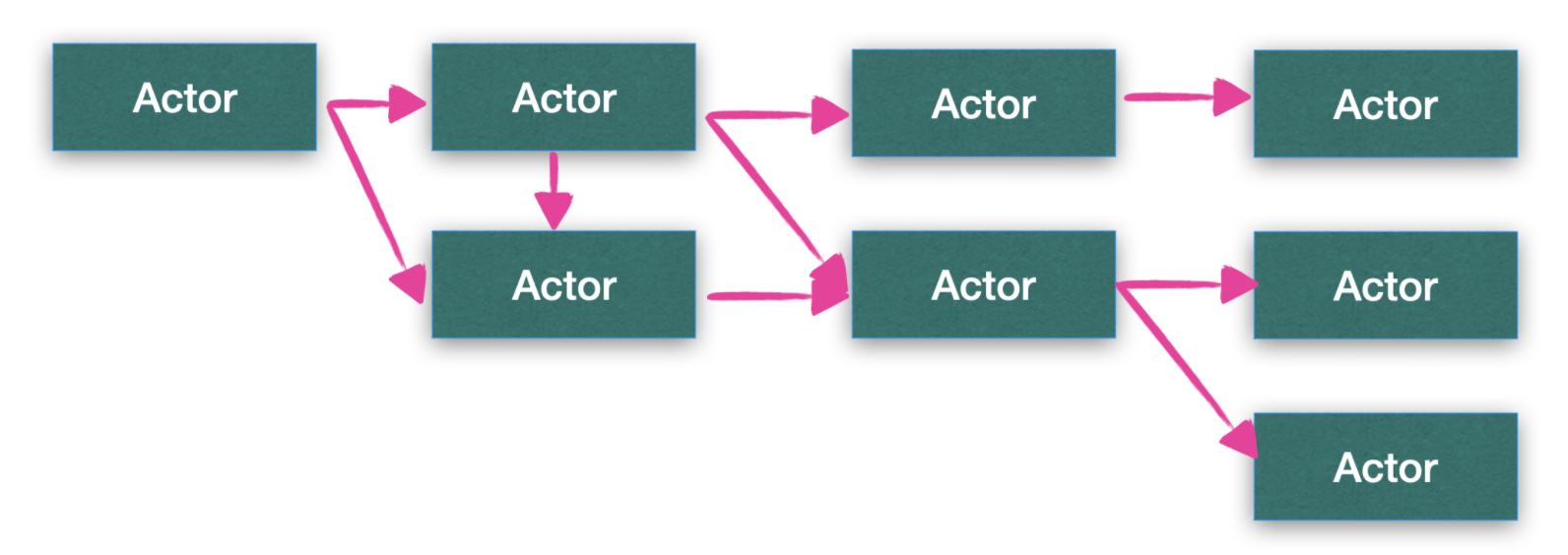
Actor 模型
在 Actor 模型中,每一個 Actor 其實就是一個 Worker, 每一個 Actor 都能夠處理任務,
簡單來說,Actor 模型是一個并發模型,它定義了一系列系統組件應該如何動作和互動的通用規則,最著名的使用這套規則的編程語言是 Erlang,一個參與者Actor對接收到的訊息做出回應,然后可以創建出更多的 Actor 或發送更多的訊息,同時準備接收下一條訊息,
Channels 模型
在 Channel 模型中,worker 通常不會直接通信,與此相對的,他們通常將事件發送到不同的 通道(Channel)上,然后其他 worker 可以在這些通道上獲取訊息,下面是 Channel 的模型圖
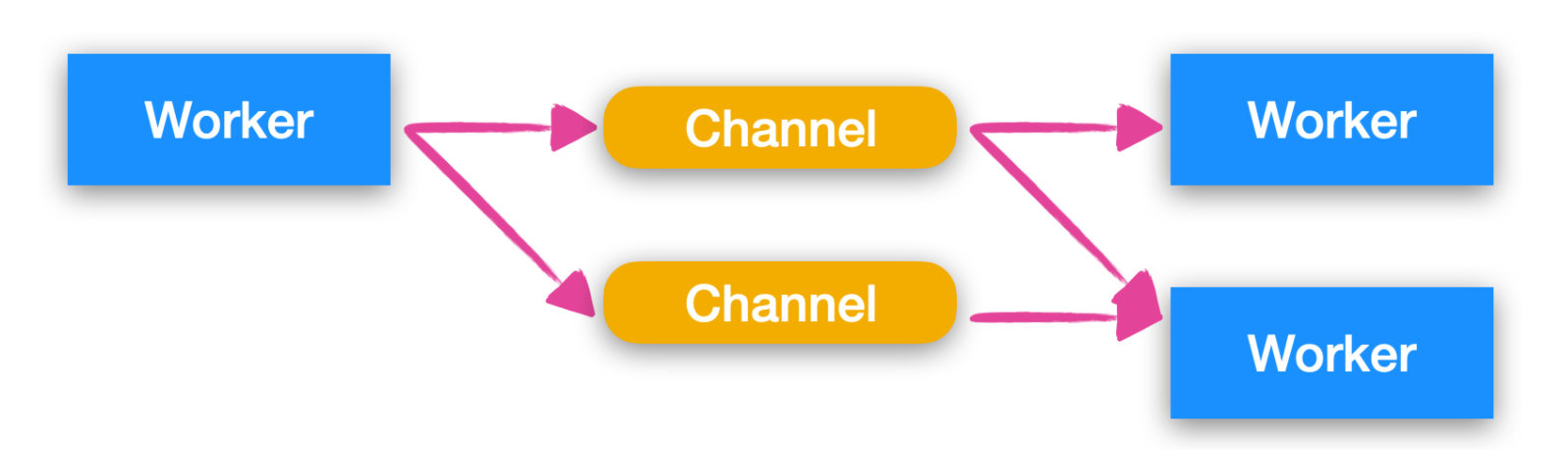
有的時候 worker 不需要明確知道接下來的 worker 是誰,他們只需要將作者寫入通道中,監聽 Channel 的 worker 可以訂閱或者取消訂閱,這種方式降低了 worker 和 worker 之間的耦合性,
流水線設計的優點
與并行設計模型相比,流水線模型具有一些優勢,具體優勢如下
不會存在共享狀態
因為流水線設計能夠保證 worker 在處理完成后再傳遞給下一個 worker,所以 worker 與 worker 之間不需要共享任何狀態,也就不用無需考慮以為并發而引起的并發問題,你甚至可以在實作上把每個 worker 看成是單執行緒的一種,
有狀態 worker
因為 worker 知道沒有其他執行緒修改自身的資料,所以流水線設計中的 worker 是有狀態的,有狀態的意思是他們可以將需要操作的資料保留在記憶體中,有狀態通常比無狀態更快,
更好的硬體整合
因為你可以把流水線看成是單執行緒的,而單執行緒的作業優勢在于它能夠和硬體的作業方式相同,因為有狀態的 worker 通常在 CPU 中快取資料,這樣可以更快地訪問快取的資料,
使任務更加有效的進行
可以對流水線并發模型中的任務進行排序,一般用來日志的寫入和恢復,
流水線設計的缺點
流水線并發模型的缺點是任務會涉及多個 worker,因此可能會分散在專案代碼的多個類中,因此很難確定每個 worker 都在執行哪個任務,流水線的代碼撰寫也比較困難,設計許多嵌套回呼處理程式的代碼通常被稱為 回呼地獄,回呼地獄很難追蹤 debug,
函式性并行
函式性并行模型是最近才提出的一種并發模型,它的基本思路是使用函式呼叫來實作,訊息的傳遞就相當于是函式的呼叫,傳遞給函式的引數都會被拷貝,因此在函式之外的任何物體都無法操縱函式內的資料,這使得函式執行類似于原子操作,每個函式呼叫都可以獨立于任何其他函式呼叫執行,
當每個函式呼叫獨立執行時,每個函式都可以在單獨的 CPU 上執行,這也就是說,函式式并行并行相當于是各個 CPU 單獨執行各自的任務,
JDK 1.7 中的 ForkAndJoinPool 類就實作了函式性并行的功能,Java 8 提出了 stream 的概念,使用并行流也能夠實作大量集合的迭代,
函式性并行的難點是要知道函式的呼叫流程以及哪些 CPU 執行了哪些函式,跨 CPU 函式呼叫會帶來額外的開銷,
好了今天就先說到這里
大家看完有什么不懂的可以在下方留言討論也可以關注.
謝謝你的觀看,
覺得文章對你有幫助的話記得關注我點個贊支持一下!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/229444.html
標籤:其他