題目:
- 一、Hadoop架構有哪些組件?分別有什么作用?
- 二、HDFS有哪些組件?分別有什么作用?
- 三、HDFS的優缺點是什么?
- 四、HDFS讀寫流程是什么?
- 五、MapReduce的優缺點是什么?
- 六、MapReduce的shuffle流程是什么?
- 七、Combiner是做什么的?一定要有嗎?使用Combiner時有什么限制條件?
- 八、Map端的join和Reduce的join的使用場景分別是什么?有什么區別?
- 九、Yarn的組件有哪些?分別有什么作用?
- 十、簡述一下Yarn的Job提交流程
- 十一、Hadoop自帶的作業調度器有哪幾種?分別是什么?
一、Hadoop架構有哪些組件?分別有什么作用?
1.HDFS-分布式檔案系統,解決分布式存盤
2.Mapreduce-分布式計算框架
3.Yarn-分布式資源管理系統
4.Common-支持所有其他模塊的公共工具程式
了解:Hadoop1.x中的Mapreduce同時處理業務邏輯運算和資源的調度,耦合性較大,并且存在只能運行Mapreduce程式這個問題,而在Hadoop2.x中,不僅分離了Mapreduce部分功能,將資源調度和運算分開,而且增加了Yarn,Yarn只負責資源調度,Mapreduce只負責運算,Yarn不僅能運行Mapreduce程式,還能運行Spark程式,Yarn目前發展成一個通用的資源調度框架,很多計算框架都支持在Yarn上運行,
二、HDFS有哪些組件?分別有什么作用?
Client(客戶端):
1.檔案上傳至HDFS中的時候會進行檔案切分,切分成一個一個的block,然后存盤,
2.查詢檔案時,會與NameNode進行互動,獲取檔案位置資訊,
3.會與DataNode互動,讀取或寫入資料,
4.client提供一些命令來管理HDFS,
5.client可以通過一些命令來訪問HDFS,
NameNode(元資料節點):
1.管理HDFS的名稱空間,
2.管理資料塊映射資訊及副本資訊,
3.處理客戶端的讀寫請求,
DataNode(實際存盤資料塊的節點):
1.實際存盤的資料塊,
2.執行資料塊的讀、寫操作,
Secondary NameNode:
1.輔助NameNode,分擔其作業量,
2.定期合并FSimage和Edits,并推送給NameNode,
3.在緊急情況下,可輔助恢復NameNode,
三、HDFS的優缺點是什么?
優點:
1.高容錯性
2.適合大資料處理
3.流式資料訪問,能保證資料的一致性
4.可構建在廉價的機器上,可以多副本機制,提高可靠性
缺點:
1.不合適低延時資料訪問
2.無法高效的對大量小檔案進行存盤
3.不支持并發寫入、檔案隨機修改場景
四、HDFS讀寫流程是什么?
讀資料流程:
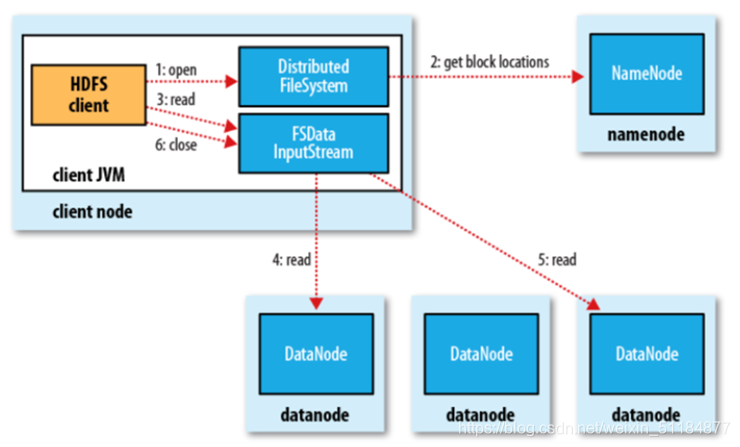
1.客戶端創建DFS(DistributedFileSystem)實體,
2.DFS向NameNode發起RPC(遠程程序呼叫)請求,獲得檔案開始部分或者全部block有序串列及DataNode地址,如果客戶端本身就是一個DataNode,那么它將從本地讀取檔案,
3.DFS會向客戶端回傳一個支持檔案定位的輸入流物件FSDIS(FileSystemDataInputStream),用于客戶端讀取資料,
4.客戶端呼叫read()方法,DFSIS(DistributedFileSystemInputStream)就會找出離客戶端最近的DataNode并連接,
5.DFSIS依次讀取第一批次的bock,如果第一批block都讀完了,重復2~5,直至所有批次的block全部讀取完成,
6.關閉DFSIS、FSDIS、DFS,
注意:NameNode只回傳客戶端請求包含塊的DataNode地址,并不是回傳請求塊的資料,最終讀取所有的block都會合并成一個完整的檔案,
寫資料流程:
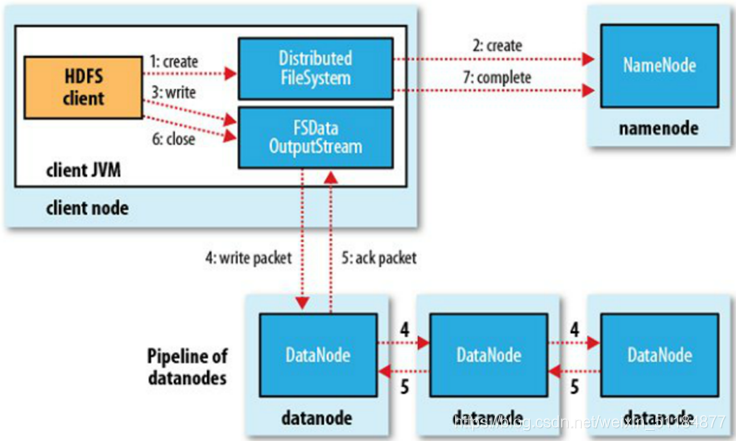
1.客戶端通過DFS模塊向NameNode請求上傳檔案,NameNode檢查目標檔案是否已經存在,父目錄是否已經存在,
2.NameNode回傳是否可以上傳,如果不能上傳,則會回傳例外,
3.如果可以上傳,那么客戶端就會切分并請求第一個block上傳到哪個DataNode服務器上,
4.NameNode回傳3個DataNode節點,假定分別為:dn1、dn2、dn3.
5.客戶端通過FSDOS(FileSystemDataOutputStream)模塊請求dn1上傳資料,dn1收到請求后會繼續呼叫dn2,然后dn2呼叫dn3,將這個通信管道建立完成,
6.dn1、dn2、dn3逐級應答客戶端,
7.客戶端開始王dn1上傳第一個block(先從磁盤讀取資料放到一個本地記憶體快取),以packet(64KB)為單位,dn1收到一個packet就會傳給dn2,dn2傳給dn3;dn1每傳一個packet,會放入一個應答佇列等待應答,
8.當一個block傳輸完畢后,客戶端再次請求NameNode上傳第二個block的服務器,(重復3~7)
五、MapReduce的優缺點是什么?
優點:
1.易于編程
2.可擴展性
3.高容錯性
4.高吞吐量
缺點:
1.難以實時計算
2.不適合流式計算
3.不適合有向圖(DAG)計算
六、MapReduce的shuffle流程是什么?
MapTask:
1.收集Mapper發送資料到環形緩沖區
2.環形緩沖區資料量達到80%時溢位
3.將所有小檔案磁區、排序、合并成一個大檔案
4.大檔案按照磁區、鍵值雙重排序
ReduceTask:
1.所有MapTask結束后ReduceTask啟動,并主動從所有的MapTask端,拉取屬于該磁區的資料的每個Maptask一個檔案
2.根據排序合并所有MapTask端的小檔案為一個大檔案
3.分組提取合并后資料資訊,一個分組一個Reducer
七、Combiner是做什么的?一定要有嗎?使用Combiner時有什么限制條件?
1.Combiner是一個特殊的reduce,它的存在就是提高當前網路IO傳輸的能力,也是MapReduce的一種優化手段,能減少Reducer提取資料的傳輸負載,
2.不一定要有,
3.要有相同的key才能使用Combiner,
八、Map端的join和Reduce的join的使用場景分別是什么?有什么區別?
map端join:
1.使用場景:大檔案+小檔案
2.map端快取多長表,提前處理業務邏輯,這樣增加map端業務,減少reduce端資料的壓力,盡可能減少資料傾斜,
reduce端join:
1.使用場景:大檔案+大檔案
2.shuffle階段出現大量的資料傳輸,效率很低
3.合并操作是在reduce階段完成的
4.map節點的運算負載很低,資源利用率不高
九、Yarn的組件有哪些?分別有什么作用?
ResourceManager(RM,全部資源管理器):
1.接收和處理客戶端(RunJar)的請求
2.管理NodeManager
3.啟動和管理AM(ApplicationMaster)
4.分配和調度資源
NodeManager(NM):
1.管理單節點資源
2.處理來自RM、AM的命令
ApplicationMaster(AM):
1.資料切分和劃分
2.程式資源的申請以及內部map和reduce任務的分配
3.任務的管理和容錯
Container:
1.對計算機資源(CPU、記憶體、網路、硬碟等)的封裝和抽象
十、簡述一下Yarn的Job提交流程
1.job提交:
· 客戶端呼叫job.waitForCompletion()方法,向整個集群提交MapReducejob
· 客戶端向ResourceManager申請一個job ID
· ResourceManager給客戶端回傳該job資源的提交路徑(臨時目錄+job ID生成的路徑)
· 客戶端提交jar包、切片資訊和組態檔到指定的資源提交路徑
· 客戶端提交完資源后,向ResourceManager申請運行MRAppMaster
2.jon初始化
· 當ResourceManager收到客戶端的請求之后,先將該job添加到容量調度器的佇列當中
· 通知一個空閑的NodeManager領取到該job
· 該NodeManager創建Container,并產生一個MRAppMaster
· 然后下載客戶端提交的資源到本地
3.任務分配
· MPAppMaster向ResourceManager申請多個運行MapTask任務資源
· ResourceManager將運行MapTask任務分配給另外兩個NodeManager,然后分別領取任務并創建容器
4.任務運行
· MRAppMaster向兩個接受到的任務的NodeManager發送程式啟動腳本,這兩個NodeManager分別啟動MapTask,然后MapTask對資料磁區排序等操作
· MRAppMaster等待所有MapTask運行完畢后,向RsourceManager申請容器,運行ReduceTask
· ReduceTask拷貝MapTask相應磁區的資料,然后進行操作
· 程式運行完畢后,MRAppMaster會向ResourceManager申請注銷自己
5.進度和狀態更新
· Yarn中的任務,將其進行和狀態(包括Container)回傳個MRAppMaster,客戶端每秒向MRAppMaster請求進度更新,展示給用戶
(時間間隔可以通過mapreduce.client.completion.pollinterval來設定)
6.job完成
· 除了向MRAppMaster請求job進度外,客戶端每5秒都會有通過呼叫waitForCompletion()來檢查job是否完成
· job完成后,MRAppMaster和Container會清理作業狀態,job的資訊會被歷史服務器存盤,以備之后用戶核查
(時間間隔可以通過mapreduce.client.completion.pollinterval來設定)
十一、Hadoop自帶的作業調度器有哪幾種?分別是什么?
1.先進先出調度器(FIFO):這是一種批量調度器,會先按照作業的優先級,再按照時間先后選擇被執行的作業,
2.容量調度器(Capacity Scheduler):該容器會對同一用戶提交的作業所占資源量進行限定,
3.公平調度器(Fair Scheduler):該調度器支持佇列多用戶,每個佇列中的資源可以配置,同一佇列中的作業公平共享佇列中的所有資源,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/231127.html
標籤:其他