原理
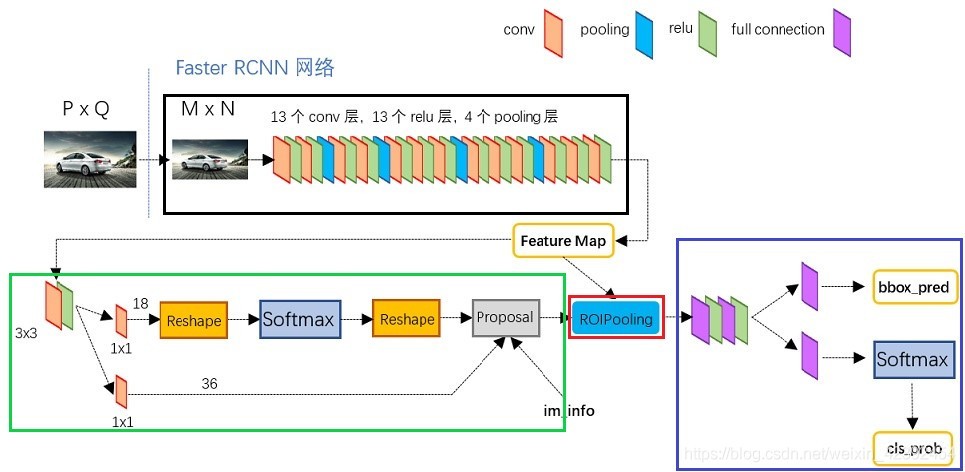
Faster RCNN主要可以分為四個內容:
- Conv layers,作為一種CNN網路目標檢測方法,Faster RCNN首先使用一組基礎的conv+relu+pooling層提取image的feature maps,該feature maps被共享用于后續RPN層和全連接層,
- Region Proposal Networks,RPN網路用于生成區域建議框,該層通過softmax判斷anchors屬于前景或者背景,再利用預測框回歸修正anchors獲得精確的建議框,
- Roi Pooling,該層收集輸入的feature maps和建議框,綜合這些資訊后提取proposal feature maps,送入后續全連接層判定目標類別,
- Classification,利用proposal feature maps計算proposal的類別,同時再次bounding box regression獲得檢測框最終的精確位置,
Conv layers
圖中黑色方框的內容就是Conv layers,實際上就是傳統影像分類中的經典網路,比如VGG、ResNet,在目標檢測中是作為特征提取的骨干網路,它不直接參與框的預測,而是輸出特征層,所以,它的最后一層不是輸出類別數,而是輸出一個寬高可變的特征層,
Region Proposal Networks
上圖綠框內展示了RPN網路的具體結構,可以看到RPN網路實際分為2條線,上面一條通過softmax分類anchors獲得前景和背景分類(通道數為18是2x9,一共有9個先驗框,2是采用多分類交叉熵,若采用二元交叉熵就是1),下面一條用于計算對于anchors的bounding box regression偏移量,以獲得精確的proposal(這里同理是4x9,4則是代表候選框在rpn上的坐標),這里的proposal也就是建議框,在建議框內的物體在圖中是屬于前景的,所以在RPN網路這一部分,模型只會分出前景和背景,
而最后的proposal層則負責綜合positive anchors和對應bounding box regression偏移量獲取proposals,同時剔除太小和超出邊界的proposals,其實整個網路到了Proposal Layer這里,就完成了相當于目標定位的功能,
Roi Pooling
將輸入的特征層看作是影像,用rpn生成的候選框截取的影像,然后resize成 pool_size * pool_size的大小,這樣處理后,即使大小不同的proposal輸出結果都是固定大小,實作了固定長度輸出,
Classification
從ROI Pooling層獲取到固定大小的proposal feature maps后,送入后續網路,可以看到做了如下2件事:
- 通過全連接和softmax對proposals進行分類,這實際上已經是識別的范疇了
- 再次對proposals進行bounding box regression,獲取更高精度的rect box
但在實際的代碼中,還需要對ROI Pooling層的輸出進行常規的卷積、AveragePooling、Flatten的操作后才能進行最后的物體具體分類和預測框回歸操作,所以從整體上看來,Faster RCNN的網路是分成兩步走的,第一步是backbone->rpn輸出物體大致位置的建議框,第二步是對建議框里面的內容進行詳細的分類和位置預測,這也就是Two-Stage目標檢測網路的架構了,
如何訓練Faster RCNN
Faster RCNN的訓練也是分兩步走
- 進行backbone-rpn的訓練,此時會進行第一次反向傳播,并且rpn網路會輸出一個預測結果作為后續classifier的資料輸入,如果這里沒有訓練好進而會導致classifier的訓練沒有資料輸入,所以有時候會直接跳過這一步,
- 根據rpn網路輸出結果對classifier進行訓練,
那么值得一提的是,在訓練程序中,訓練資料有可能會存在正負樣本不均衡的情況,如背景數量遠遠大于前景數量或者情況相反,那么Faster RCNN則會將正負樣本的數量都限制在128個,如果影像中的正樣本少于128個,將使用負樣本填充小批量資料,
代碼
- Tensorflow2實作的Faster RCNN參考代碼(覺得有用可以點個star哦)
Reference
- 一文讀懂Faster RCNN
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/232675.html
標籤:其他