一
1.總結一下你比較突出的專案
根據自身情況而定
2.tcp 三次握手四次斷開 并且每次發送資料包是什么 以及tcp是什么狀態
參考
tcp三次握手
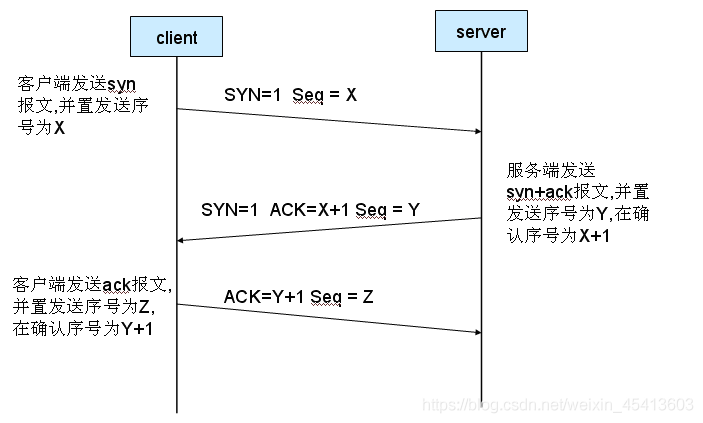
在TCP/IP協議中,TCP協議提供可靠的連接服務,采用三次握手建立一個連接,如圖1所示,
(1) 第一次握手:建立連接時,客戶端A發送SYN包(SYN=j)到服務器B,并進入SYN_SEND狀態,等待服務器B確認,
(2) 第二次握手:服務器B收到SYN包,必須確認客戶A的SYN(ACK=j+1),同時自己也發送一個SYN包(SYN=k),即SYN+ACK包,此時服務器B進入SYN_RECV狀態,
(3) 第三次握手:客戶端A收到服務器B的SYN+ACK包,向服務器B發送確認包ACK(ACK=k+1),此包發送完畢,客戶端A和服務器B進入ESTABLISHED狀態,完成三次握手,
完成三次握手,客戶端與服務器開始傳送資料,
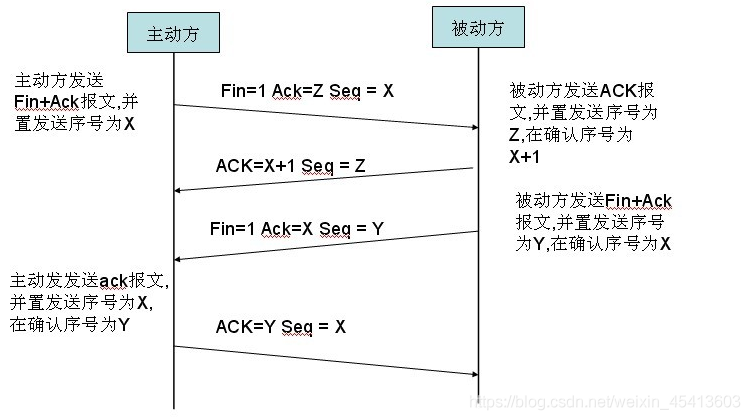
tcp四次斷開
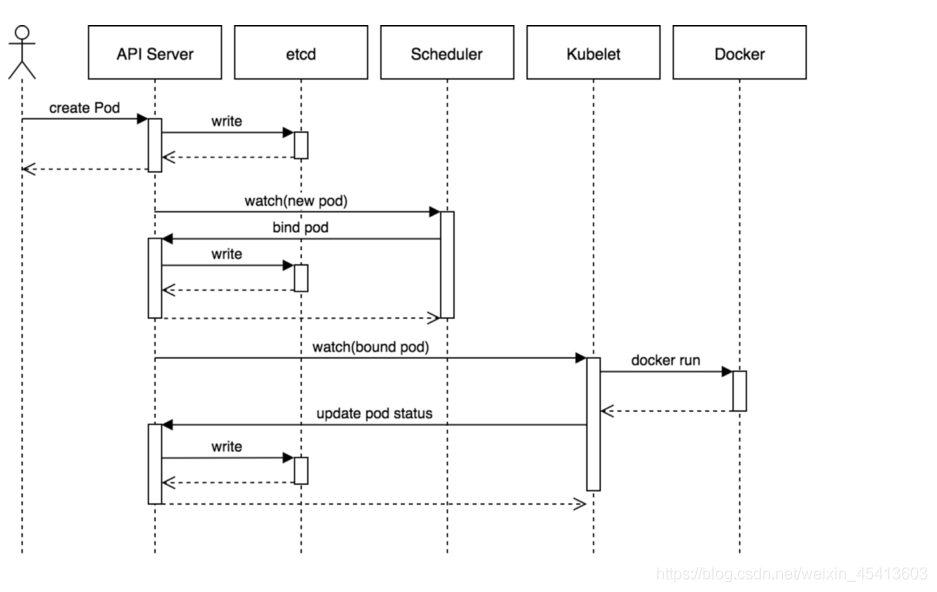
3.pod的創建程序
用戶通過 REST API 創建一個 Pod
apiserver 將其寫入 etcd
scheduluer 檢測到未系結 Node 的 Pod,開始調度并更新 Pod 的 Node 系結
kubelet 檢測到有新的 Pod 調度過來,通過 container runtime 運行該 Pod
kubelet 通過 container runtime 取到 Pod 狀態,并更新到 apiserver 中
1.k8s高可用架構 是怎樣的 包括api 以及調度器控制器怎么作業
這里master 有api-server 以及scheduler 和controller ,一般我們做的高可用只是針對api會做負載輪詢調度 也就是說在api的上層通過lb來做代理,scheduler以及controller都是一個作業其余沉睡 ,如果作業的掛掉了 ,那么沉睡的會被喚醒 也只會喚醒一個,這里具體是etcd中會有一把鎖 scheduler和controller會watch這把鎖 watch到的就會開始作業 ,沒有watch到的就會持續watch,
2.deployment 會有rs 那么 rs里面會有pod pod 最后名稱的哈希值是怎么計算的 為什么擴縮容的時候原有的pod 最后的后綴哈希值不會變 但是我滾動更新的時候就會發生變化
這個沒回答上來
3.deployment跟sts有什么本質的區別
deployment無序 sts是有序的 并且pv pvc也會略有不同 deployment pod公用一個 sts每個pod一個
4.怎么樣控制不同部門的管理(這里結合config 跟rbac)
通過rbac給用戶授權 不同的用戶對應不同的權限 clusterrolebinding clusterrole 以及role rolebinding
5.那么說一下controller的 原始碼架構 是怎樣的
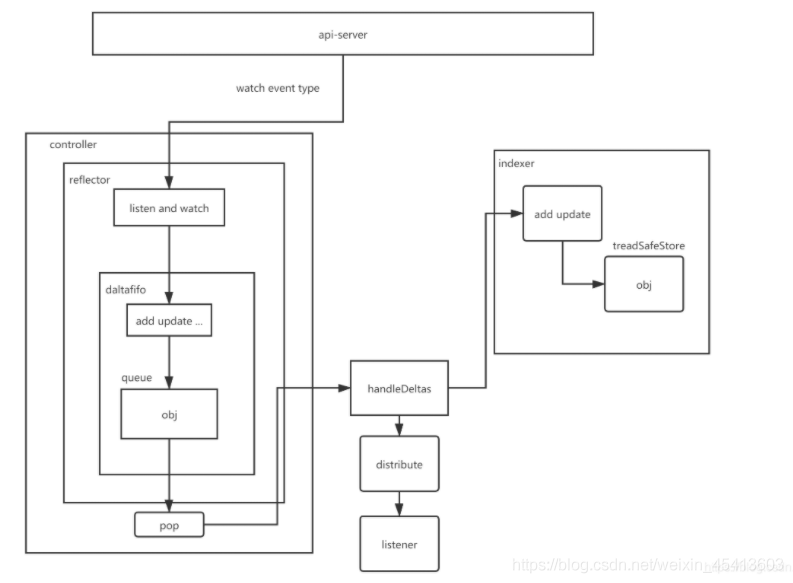
手繪圖 以及描述作業流程
https://blog.csdn.net/weixin_45413603/article/details/107217076
6.informer 承擔了一個什么樣的角色
7yaml 中會影響調度器的調度 的欄位有哪些
親和度
nodename
nodeselector
污點容忍度
request
8.request跟limit 有什么本質的區別
request會影響調度
limit會影響pod被kill掉
9.存活檢查跟就緒檢查有什么區別
存活失敗會導致pod重啟
就緒失敗在svc的ep上不會有pod ip也就是說不會給pod引入流量
10.前面你說到了request 會影響到調度器 也就是說預分配 需要滿足才可以調度那么 他怎么去判斷節點是否滿足條件
你在describe可以看到node的一些基礎資訊,他是通過這個來判斷 用
總記憶體- system預留-kube預留-pod已經使用 = 可用
以及limit會不會作為判斷的一個標準
limit不會影響調度
11.hpa 自定義以及k8s自帶的 也就是v1 v2版本
hpa基于記憶體cpu 那么如何能自定義指標
自定義需要用到prome的指標結合adapter
12.informer里面有什么
informer的架構 這里可以看一下
https://blog.csdn.net/weixin_45413603/article/details/107995986
13 如果寫了nodename 那么調度程序會不會走調度器
不會
1.prometheus 的架構
alertmanager 報警
webhook對接語音釘釘或者企業微信
grafana圖表展示
prometheus 資料處理
exporter 資料收集agent
2.你基于prometheus 怎么去做的 專案方面怎么做的監控
redis cluster
es cluster
基礎服務器以及k8s服務器
3.prometheus 你開發過什么
webhook and exporter
4.nginx 的log 只要404 狀態碼 的用戶請求uri 然后我只要前10
這里主要是結合cat grep awk sort uniq -c
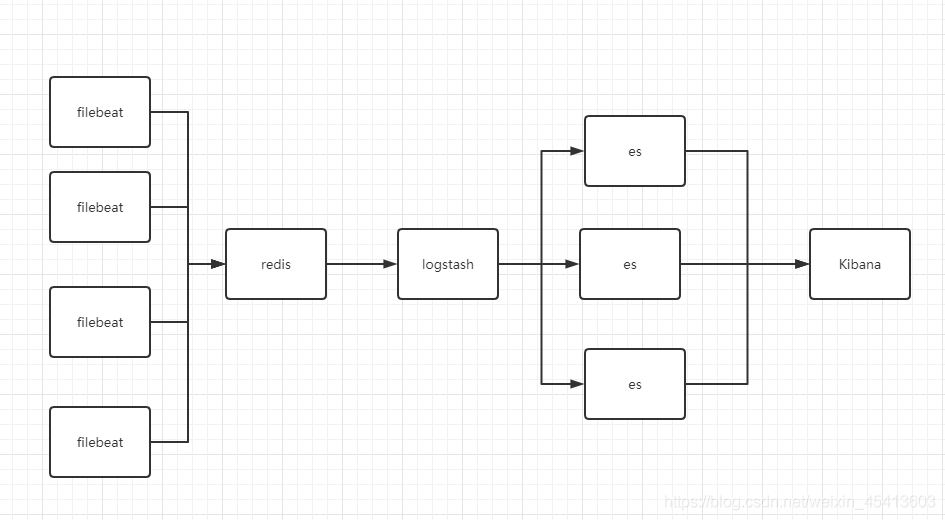
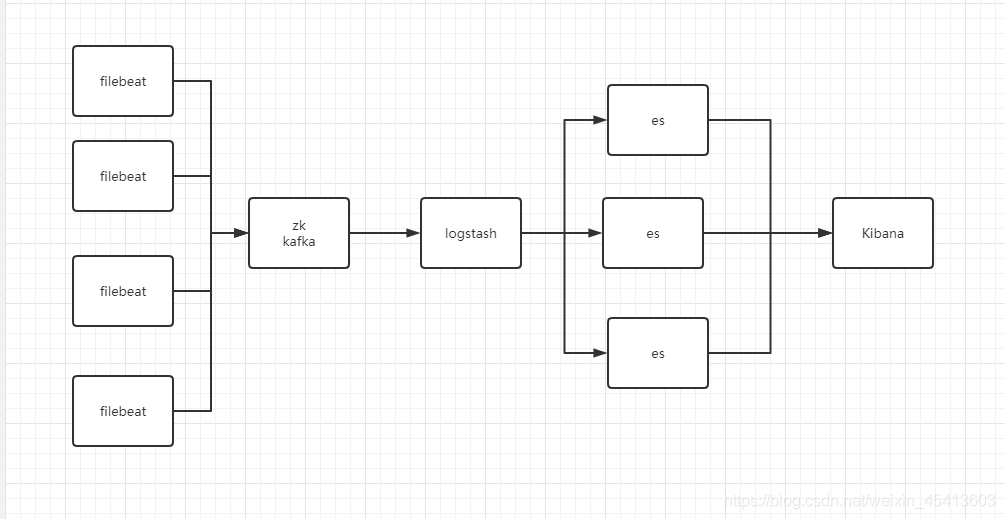
5. elk的常見架構 以及es的集群聯邦
6.prometheus 的集群
prometheus集群主要是圍繞多個prometheus共享一個tsdb 來做,但是資料量特別大之后特別消耗記憶體,這也只是解決了高可用問題
7.2xx 3xx 4xx 5xx 首先你怎么理解 狀態碼 200 正確 3xx重定向 4xx請求類 5xx 服務端錯誤
8.prometheus 遇到過瓶頸么怎么處理的
目前沒有 但是量大了記憶體消耗會很高
9.prometheus 你的資料量大概有多少
目前中間件部分 一個月30g k8s集群具體沒細看
10.接著前面的elk常見架構 的話
我回答說可以借助redis 或者kafka 以及zk 那么這兩個架構的區別在哪里
redis是一個記憶體行 如果突增或者資料量大了 可能記憶體打滿掛機 導致資料丟失
zk kafka是佇列
11.容器cni flannel calico 做namespace隔離 那么核心是canel 他的核心處理是怎么做的隔離 能做什么隔離
這塊沒有怎么回答 就是可以做ns的隔離以及黑白名單
12.pod一直處于CrashLoopBackOff需要進去除錯
這個可以使用ephemeralcontainers臨時容器
https://kubernetes.io/zh/docs/concepts/workloads/pods/ephemeral-containers/
或者在高版本k8s使用k8s-debug
1.prometheus 可以通過信號reload 組態檔也可以通過介面reload組態檔 但是當資料量特別大的時候 reload如果需要10分鐘以上 資料會出現斷層 那么這個有沒有什么好的處理方式,以及prometheus 啟動程序中 攜程處理 這塊涉及到了 prometheus的啟動流程的攜程組 加載方式
2.如果容器沒有bash 或者sh 也就是說沒有解釋器 那么我怎么進入容器
function e() {
set -u
ns=${2-"default"}
container_id=`kubectl -n $ns describe pod $1 | grep -Eo 'docker://.*$' | head -n 1 | awk -F '//' '{print $2}'`
if [ "$container_id" != "" ]
then
echo "container_id:$container_id"
pid=`docker inspect -f {{.State.Pid}} $container_id`
echo "pid:$pid"
echo "enter pod netns successfully for $ns/$1"
nsenter -n --target $pid
fi
}
3.在容器啟動失敗以后無限重啟 怎么進入容器排查問題
沒回答上來
4.然后就是基于k8s的污點以及親和度問了一些問題
親和度用的特別多以后有什么影響
對于調度器消耗會特別大
5.k8s使用grpc協議有沒有什么弊端
沒回答上來我對grpc不是很了解 我就知道他是http鏈接復用
二
1.linux oom
2.proc跟內核的區別
3.cpu使用率 cpu負載理解
4.tcp timeout
5.tcp狀態有哪些
6.503 502的區別
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/232680.html
標籤:其他