文章目錄
- 大數劇-storm
- 一、Storm是什么
- 二、Storm的特點
- 三、Storm的應用
- 四、Storm模型
- 五、概念
- 1. 拓撲(Topologies)
- 2. 元組(Tuple)
- 3. 流(Streams)
- 4. Spouts
- 5. Bolts
- 6. 任務(Tasks)
- 7. 組件(Component)
- 8. 流分組(Stream Grouping)
- 9. 可靠性(Reliability)
- 10. Workers(作業行程)
- 六、Storm中用到的技術
- 七、Storm架構思想
- 1. Storm和Hadoop架構組件功能對應關系
- 2. Storm集群模式
- 3. Storm的作業流程
- Storm作業流程示意圖
- 八、代碼實戰:單詞計數(WordCount)
- 1. 代碼:
- 2. WordCountTopology并行性
- 3. 給topology增加worker
- 4. 配置executor和task
- 5. 理解資料流分組
- 九、Storm 資料處理保障機制
- 1. spout的可靠性
- 2. bolt的可靠性
- 3. 可靠的單詞計數

大數劇-storm
一、Storm是什么
Storm是一個免費并開源的分布式實時計算系統,利用Storm可以很容易做到可靠地處理無限的資料流,像Hadoop批量處理大資料一樣,Storm可以實時處理資料,Storm簡單,可以使用任何編程語言,
在Storm之前,進行實時處理是非常痛苦的事情: 需要維護一堆訊息佇列和消費者,他們構成了非常復雜的圖結構,消費者行程從佇列里取訊息,處理完成后,去更新資料庫,或者給其他佇列發新訊息,
這樣進行實時處理是非常痛苦的,我們主要的時間都花在關注往哪里發訊息,從哪里接收訊息,訊息如何序列化,真正的業務邏輯只占了源代碼的一小部分,一個應用程式的邏輯運行在很多worker上,但這些worker需要各自單獨部署,還需要部署訊息佇列,最大問題是系統很脆弱,而且不是容錯的:需要自己保證訊息佇列和worker行程作業正常,
Storm完整地解決了這些問題,它是為分布式場景而生的,抽象了訊息傳遞,會自動地在集群機器上并發地處理流式計算,讓你專注于實時處理的業務邏輯,
二、Storm的特點
Storm有如下特點:
- 編程簡單:開發人員只需要關注應用邏輯,而且跟Hadoop類似,Storm提供的編程原語也很簡單
- 高性能,低延遲:可以應用于廣告搜索引擎這種要求對廣告主的操作進行實時回應的場景,
- 分布式:可以輕松應對資料量大,單機搞不定的場景
- 可擴展: 隨著業務發展,資料量和計算量越來越大,系統可水平擴展
- 容錯:單個節點掛了不影回應用
- 訊息不丟失:保證訊息處理
不過Storm不是一個完整的解決方案,使用Storm時你需要關注以下幾點: - 如果使用的是自己的訊息佇列,需要加入訊息佇列做資料的來源和產出的代碼
- 需要考慮如何做故障處理:如何記錄訊息佇列處理的進度,應對Storm重啟,掛掉的場景
- 需要考慮如何做訊息的回退:如果某些訊息處理一直失敗怎么辦?
三、Storm的應用
跟Hadoop不一樣,Storm是沒有包括任何存盤概念的計算系統,這就讓Storm可以用在多種不同的場景下:非傳統場景下資料動態到達或者資料存盤在資料庫這樣的存盤系統里(或資料是被實時操控其他設備的控制器(如交易系統)所消費)
Storm有很多應用:實時分析,在線機器學習(online machine learning),連續計算(continuous computation),分布式遠程程序呼叫(RPC)、ETL等,Storm處理速度很快:每個節點每秒鐘可以處理超過百萬的資料組,它是可擴展(scalable),容錯(fault-tolerant),保證你的資料會被處理,并且很容易搭建和操作,
四、Storm模型
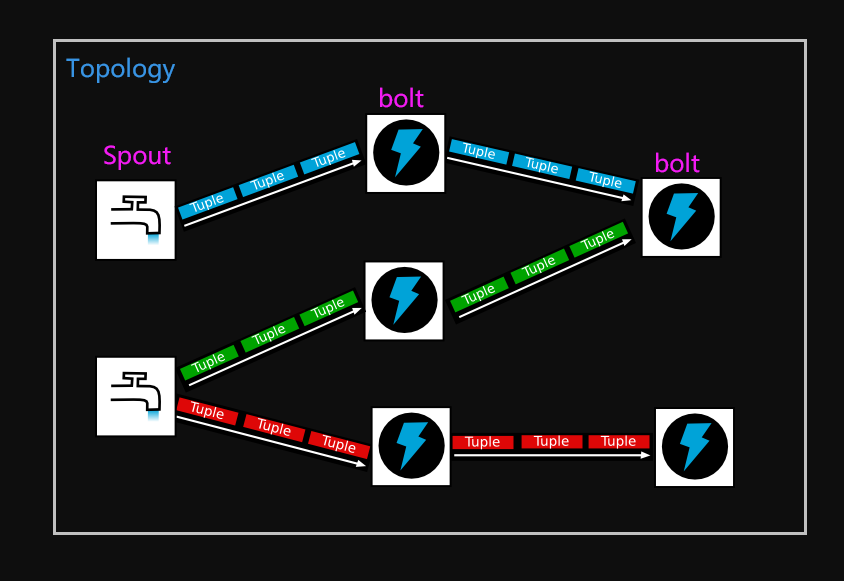
Storm實作了一個資料流(data flow)的模型,在這個模型中資料持續不斷地流經一個由很多轉換物體構成的網路,一個資料流的抽象叫做流(stream),流是無限的元組(Tuple)序列,元組就像一個可以表示標準資料型別(例如int,float和byte陣列)和用戶自定義型別(需要額外序列化代碼的)的資料結構,每個流由一個唯一的ID來標示的,這個ID可以用來構建拓撲中各個組件的資料源,
如下圖所示,其中的水龍頭代表了資料流的來源,一旦水龍頭打開,資料就會源源不斷地流經Bolt而被處理,圖中有三個流,用不同的顏色來表示,每個資料流中流動的是元組(Tuple),它承載了具體的資料,元組通過流經不同的轉換物體而被處理,
Storm對資料輸入的來源和輸出資料的去向沒有做任何限制,像Hadoop,是需要把資料放到自己的檔案系統HDFS里的,在Storm里,可以使用任意來源的資料輸入和任意的資料輸出,只要你實作對應的代碼來獲取/寫入這些資料就可以,典型場景下,輸入/輸出資料來是基于類似Kafka或者ActiveMQ這樣的訊息佇列,但是資料庫,檔案系統或者web服務也都是可以的,
五、概念
Storm并行度
在storm中,任務只是在集群中運行的一個Spout的bolt實體,理解并行性是如何作業的,我們必須首先解釋一個Storm集群拓撲參與
執行的四個主要組件:
- Nodes(機器):這些只是配置為Storm集群參與執行拓撲的部分的機器,Storm集群包含一個或多個節點來完成作業
- Workers(JVM):這些是在一個節點上運行獨立的JVM行程,每個節點配置一個或更多運行的worker,一個拓撲可以請求一個或更多的worker分配給它,
- Executors(執行緒):這些是worker運行在JVM行程一個Java執行緒,多個任務可以分配給一個Executor,除非顯式重寫,Storm將分配一個任務給一個Executor,
- Tasks(Spout/Bolt實體):任務是Spout和bolt的實體,在executor執行緒中運行nextTuple()和executre()方法,
1. 拓撲(Topologies)
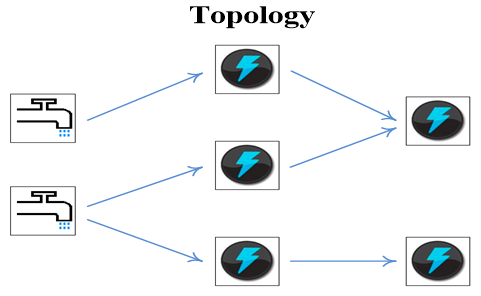
一個Storm拓撲打包了一個實時處理程式的邏輯,一個Storm拓撲跟一個MapReduce的任務(job)是類似的,主要區別是MapReduce任務最侄訓結束,而拓撲會一直運行(當然直到你殺死它),一個拓撲是一個通過流分組(stream grouping)把Spout和Bolt連接到一起的拓撲結構,圖的每條邊代表一個Bolt訂閱了其他Spout或者Bolt的輸出流,一個拓撲就是一個復雜的多階段的流計算,
2. 元組(Tuple)

元組是Storm提供的一個輕量級的資料格式,可以用來包裝你需要實際處理的資料,元組是一次訊息傳遞的基本單元,一個元組是一個命名的值串列,其中的每個值都可以是任意型別的,元組是動態地進行型別轉化的–欄位的型別不需要事先宣告,在Storm中編程時,就是在操作和轉換由元組組成的流,通常,元組包含整數,位元組,字串,浮點數,布林值和位元組陣列等型別,要想在元組中使用自定義型別,就需要實作自己的序列化方式,
3. 流(Streams)

流是Storm中的核心抽象,一個流由無限的元組序列組成,這些元組會被分布式并行地創建和處理,通過流中元組包含的欄位名稱來定義這個流,每個流宣告時都被賦予了一個ID,只有一個流的Spout和Bolt非常常見,所以提供了不需要指定ID來宣告一個流的函式(Spout和Bolt都需要宣告輸出的流),這種情況下,流的ID是默認的“default”,
4. Spouts

Spout(噴嘴,這個名字很形象)是Storm中流的來源,通常Spout從外部資料源,如訊息佇列中讀取元組資料并吐到拓撲里,Spout可以是可靠的(reliable)或者不可靠(unreliable)的,可靠的Spout能夠在一個元組被Storm處理失敗時重新進行處理,而非可靠的Spout只是吐資料到拓撲里,不關心處理成功還是失敗了,
Spout可以一次給多個流吐資料,此時需要通過OutputFieldsDeclarer的declareStream函式來宣告多個流并在呼叫SpoutOutputCollector提供的emit方法時指定元組吐給哪個流,
Spout中最主要的函式是nextTuple,Storm框架會不斷呼叫它去做元組的輪詢,如果沒有新的元組過來,就直接回傳,否則把新元組吐到拓撲里,nextTuple必須是非阻塞的,因為Storm在同一個執行緒里執行Spout的函式,
Spout中另外兩個主要的函式是ack和fail,當Storm檢測到一個從Spout吐出的元組在拓撲中成功處理完時呼叫ack,沒有成功處理完時呼叫fail,只有可靠型的Spout會呼叫ack和fail函式,更多細節可以查看Storm Java檔案和我的另外一篇文章:Storm如何保證可靠的訊息處理
5. Bolts
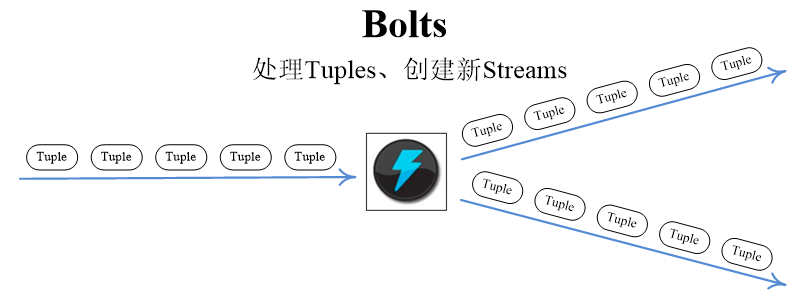
在拓撲中所有的計算邏輯都是在Bolt中實作的,一個Bolt可以處理任意數量的輸入流,產生任意數量新的輸出流,Bolt可以做函式處理,過濾,流的合并,聚合,存盤到資料庫等操作,Bolt就是流水線上的一個處理單元,把資料的計算處理程序合理的拆分到多個Bolt、合理設定Bolt的task數量,能夠提高Bolt的處理能力,提升流水線的并發度,
Bolt可以給多個流吐出元組資料,此時需要使用OutputFieldsDeclarer的declareStream方法來宣告多個流并在使OutputColletor的emit方法時指定給哪個流吐資料,
當你宣告了一個Bolt的輸入流,也就訂閱了另外一個組件的某個特定的輸出流,如果希望訂閱另一個組件的所有流,需要單獨挨個訂閱,InputDeclarer有語法糖來訂閱ID為默認值的流,例如declarer.shuffleGrouping(“redBolt”)訂閱了redBolt組件上的默認流,跟declarer.shuffleGrouping(“redBolt”, DEFAULT_STREAM_ID)是相同的,
在Bolt中最主要的函式是execute函式,它使用一個新的元組當作輸入,Bolt使用OutputCollector物件來吐出新的元組,Bolts必須為處理的每個元組呼叫OutputCollector的ack方法以便于Storm知道元組什么時候被各個Bolt處理完了(最終就可以確認Spout吐出的某個元組處理完了),通常處理一個輸入的元組時,會基于這個元組吐出零個或者多個元組,然后確認(ack)輸入的元組處理完了,Storm提供了IBasicBolt介面來自動完成確認,
必須注意OutputCollector不是執行緒安全的,所以所有的吐資料(emit)、確認(ack)、通知失敗(fail)必須發生在同一個執行緒里,更多資訊可以參照問題定位,
6. 任務(Tasks)
每個Spout和Bolt會以多個任務(Task)的形式在集群上運行,每個任務對應一個執行執行緒,流分組定義了如何從一組任務(同一個Bolt)發送元組到另外一組任務(另外一個Bolt)上,可以在呼叫TopologyBuilder的setSpout和setBolt函式時設定每個Spout和Bolt的并發數,
7. 組件(Component)
組件(component)是對Bolt和Spout的統稱
8. 流分組(Stream Grouping)
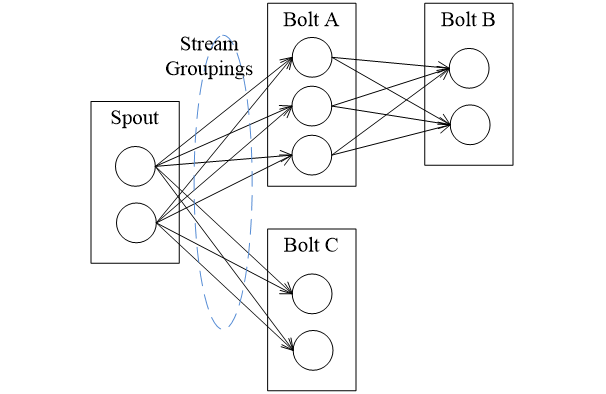
Storm中的Stream Groupings用于告知Topology如何在兩個組件間(如Spout和Bolt之間,或者不同的Bolt之間)進行Tuple的傳送,每一個Spout和Bolt都可以有多個分布式任務,一個任務在什么時候、以什么方式發送Tuple就是由Stream Groupings來決定的
在Storm中有七個內置的流分組策略,你也可以通過實作CustomStreamGrouping介面來自定義一個流分組策略:
-
洗牌分組(Shuffle grouping): 隨機分配元組到Bolt的某個任務上,這樣保證同一個Bolt的每個任務都能夠得到相同數量的元組,
-
欄位分組(Fields grouping): 按照指定的分組欄位來進行流的分組,例如,流是用欄位“user-id"來分組的,那有著相同“user-id"的元組就會分到同一個任務里,但是有不同“user-id"的元組就會分到不同的任務里,這是一種非常重要的分組方式,通過這種流分組方式,我們就可以做到讓Storm產出的訊息在這個"user-id"級別是嚴格有序的,這對一些對時序敏感的應用(例如,計費系統)是非常重要的,
-
Partial Key grouping: 跟欄位分組一樣,流也是用指定的分組欄位進行分組的,但是在多個下游Bolt之間是有負載均衡的,這樣當輸入資料有傾斜時可以更好的利用資源,這篇論文很好的解釋了這是如何作業的,有哪些優勢,
-
All grouping: 流會復制給Bolt的所有任務,小心使用這種分組方式,在拓撲中,如果希望某類元祖發送到所有的下游消費者,就可以使用這種All grouping的流分組策略,
-
Global grouping: 整個流會分配給Bolt的一個任務,具體一點,會分配給有最小ID的任務,
-
不分組(None grouping): 說明不關心流是如何分組的,目前,None grouping等價于洗牌分組,
-
Direct grouping:一種特殊的分組,對于這樣分組的流,元組的生產者決定消費者的哪個任務會接收處理這個元組,只能在宣告做直連的流(direct streams)上宣告Direct groupings分組方式,只能通過使用emitDirect系列函式來吐元組給直連流,一個Bolt可以通過提供的TopologyContext來獲得消費者的任務ID,也可以通過OutputCollector物件的emit函式(會回傳元組被發送到的任務的ID)來跟蹤消費者的任務ID,在ack的實作中,Spout有兩個直連輸入流,ack和ackFail,使用了這種直連分組的方式,
-
Local or shuffle grouping:如果目標Bolt在同一個worker行程里有一個或多個任務,元組就會通過洗牌的方式分配到這些同一個行程內的任務里,否則,就跟普通的洗牌分組一樣,這種方式的好處是可以提高拓撲的處理效率,因為worker內部通信就是行程內部通信了,相比拓撲間的行程間通信要高效的多,worker行程間通信是通過使用Netty來進行網路通信的,
9. 可靠性(Reliability)
Storm保證了拓撲中Spout產生的每個元組都會被處理,Storm是通過跟蹤每個Spout所產生的所有元組構成的樹形結構并得知這棵樹何時被完整地處
理來達到可靠性,每個拓撲對這些樹形結構都有一個關聯的“訊息超時”,如果在這個超時時間里Storm檢測到Spout產生的一個元組沒有被成功處理完,
那Sput的這個元組就處理失敗了,后續會重新處理一遍,
為了發揮Storm的可靠性,需要你在創建一個元組樹中的一條邊時告訴Storm,也需要在處理完每個元組之后告訴Storm,這些都是通過Bolt吐
元組資料用的OutputCollector物件來完成的,標記是在emit函式里完成,完成一個元組后需要使用ack函式來告訴Storm,
這些都在“保證訊息處理”一文中會有更詳細的介紹,
10. Workers(作業行程)
拓撲以一個或多個Worker行程的方式運行,每個Worker行程是一個物理的Java虛擬機,執行拓撲的一部分任務,例如,如果拓撲的并發設定成了300,
分配了50個Worker,那么每個Worker執行6個任務(作為Worker內部的執行緒),Storm會盡量把所有的任務均分到所有的Worker上,
六、Storm中用到的技術
ZeroMQ 提供了可擴展環境下的傳輸層高效訊息通信,一開始Storm的內部通信使用的是ZeroMQ,后來作者想把Storm移交給Apache開源基金
會來管理,而ZeroMQ的許可證書跟Apache基金會的政策有沖突,在Storm中,Netty比ZeroMQ更加高效,而且提供了worker間通信時的驗證機制,
所以在Storm0.9中,就改用了Netty,
Clojure Storm系統的實作語言,Clojure是由Rich Hicky作為一種通用語言發明的,它衍生自Lisp語言,簡化了多執行緒編程,
**Apache ZooKeeper **Zookeeper是一個實作高可靠的分布式協作的開源專案,Storm使用Zookeeper來協調集群中的多個節點,
七、Storm架構思想
1. Storm和Hadoop架構組件功能對應關系
Storm運行任務的方式與Hadoop類似:Hadoop運行的是MapReduce作業,而Storm運行的是“Topology”
但兩者的任務大不相同,主要的不同是:MapReduce作業最侄訓完成計算并結束運行,而Topology將持續處理訊息(直到人為終止)
| Hadoop | Storm | |
|---|---|---|
| 應用名稱 | Job | Topology |
| 系統角色 | JobTracker | Nimbus |
| TaskTracker | Supervisor | |
| 組件介面 | Map/Reduce | Spout/Bolt |
2. Storm集群模式
Storm集群采用“Master—Worker”的節點方式:
-
Master節點運行名為“Nimbus”的后臺程式(類似Hadoop中的“JobTracker”),負責在集群范圍內分發代碼、為Worker分配任務和監測故障
-
Worker節點運行名為“Supervisor”的后臺程式,負責監聽分配給它所在機器的作業,即根據Nimbus分配的任務來決定啟動或停止Worker行程,
一個Worker節點上同時運行若干個Worker行程 -
Storm使用Zookeeper來作為分布式協調組件,負責Nimbus和多個Supervisor之間的所有協調作業,借助于Zookeeper,若Nimbus行程或Supervisor行程
意外終止,重啟時也能讀取、恢復之前的狀態并繼續作業,使得Storm極其穩定
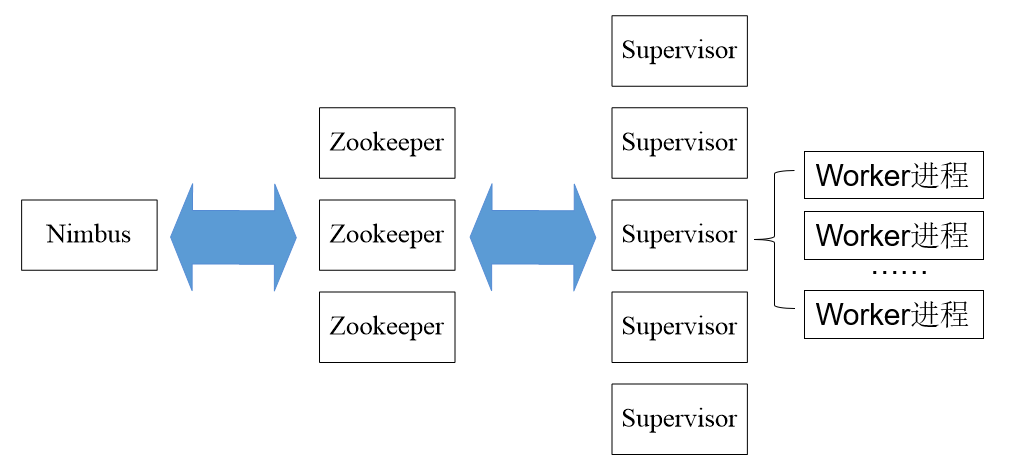
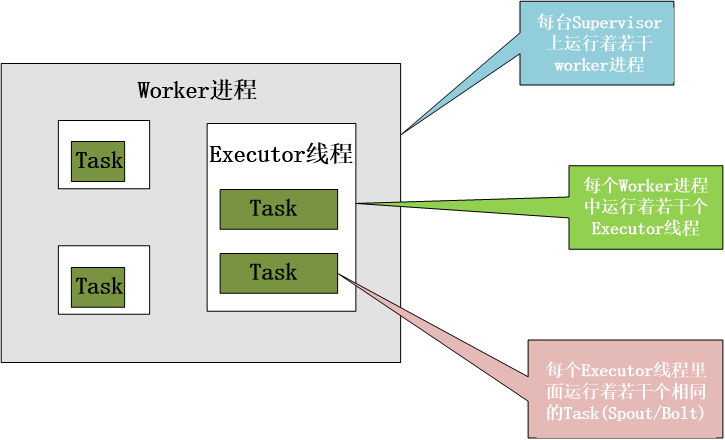
(1)worker(JVM行程):每個worker行程都屬于一個特定的Topology,每個Supervisor節點的worker可以有多個,每個worker對Topology中的每個組件(Spout或 Bolt
)運行一個或者多個executor執行緒來提供task的運行服務
(2)executor(執行緒):executor是產生于worker行程內部的執行緒,會執行同一個組件的一個或者多個task,
(3)task:實際的資料處理由task完成,在Topology的生命周期中,每個組件的task數目是不會發生變化的,而executor的數目卻不一定,executor數目小于等
于task的數目,默認情況下,二者是相等的
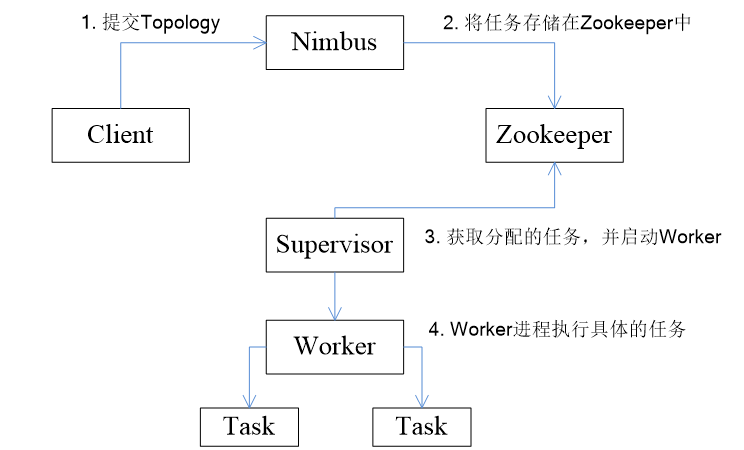
3. Storm的作業流程
- 所有Topology任務的提交必須在Storm客戶端節點上進行,提交后,由Nimbus節點分配給其他Supervisor節點進行處理
- Nimbus節點首先將提交的Topology進行分片,分成一個個Task,分配給相應的Supervisor,并將Task和Supervisor相關的資訊提交到Zookeeper集群上
- Supervisor會去Zookeeper集群上認領自己的Task,通知自己的Worker行程進行Task的處理
說明:在提交了一個Topology之后,Storm就會創建Spout/Bolt實體并進行序列化,之后,將序列化的組件發送給所有的任務所在的機器(即Supervisor節點)
,在每一個任務上反序列化組件
Storm作業流程示意圖
八、代碼實戰:單詞計數(WordCount)
1. 代碼:
pom.xml
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.1-incubating</version>
</dependency>
</dependencies>
1). SentenceSpout: 資料生成并以元組(tuple)形式發送
package cn.zhanghub.bigdata.storm;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
import java.util.Map;
/**
* SentenceSpout 組件,將陳述句作為資料源以元組(tuple)發出
* BaseRichSpout類是一個方便的類,它實作了ISpout和IComponent介面并提供默認的不需要的方法,
* 使用這個類,我們需只專注于我們所需要的方法,
* @author user
*/
public class SentenceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private String[] sentences = {"my dog has fleas", "i like cold beverages", "the dog ate my homework",
"don't have a cow man", "i don't think i like fleas"};
private int index = 0;
/**
* declareOutputFields()方法是Storm IComponent介面中定義的介面,所有的Storm組件(包括Spout和bolt)必須實作該方法,
* 它用于告訴Storm流組件將會發出的每個流的元組將包含的欄位,在這種情況下,我們定義的spout將發射一個包含一個欄位(“sentence”)
* 的單一(默認)的元組流,
* @param declarer
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
/*定義spout將發射一個包含一個欄位(“sentence”)的單一(默認)的元組流*/
declarer.declare(new Fields("sentence"));
}
/**
*open()方法中是ISpout中定義的介面,在Spout組件初始化時被呼叫,
* open()方法接受三個引數:
* 一個包含Storm配置的Map,
* 一個TopologyContext物件,它提供了關于組件在一個拓撲中的背景關系資訊,
* 一個SpoutOutputCollector物件提供發射元組的方法,
* 在這個例子中,我們不需要執行初始化,因此,open()實作簡單將SpoutOutputCollector物件的參考存盤在一個實體變數中 ,
* @param config 配置
* @param context topology 背景關系
* @param collector 提供發射元組的方法,
*/
@Override
public void open(Map config, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
/**
* nextTuple方法是所有 spout實作的核心所在,Storm通過主動呼叫這個方法向輸出的
* collctor 發射tuple,這個例子中,我們發射當前索引對應的陳述句,并且遞增索引指向下一
* 個陳述句,
*/
@Override
public void nextTuple() {
/**
* 將元組發射出去
*/
this.collector.emit(new Values(sentences[index]));
index++;
if (index >= sentences.length) {
index = 0;
}
Utils.sleep(1);
}
}
2). SplitSentenceBolt :實作單詞分割 blot
package cn.zhanghub.bigdata.storm;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.Map;
/**
*
* 實作單詞分割 blot
*
* BaseRichBolt類是IComponent和IBolt介面的一個簡便實作,繼承這個類,就不用去
* 實作本例不關心的方法,將注意力放在實作我們需要的功能上,
* @author user
*/
public class SplitSentenceBolt extends BaseRichBolt {
private OutputCollector collector;
/**
* prepare(方法在IBolt中定義,類同與ISpout介面中定義的open()方法,這個方法
* 在bolt初始化時呼叫,可以用來準備bolt 用到的資源,如資料庫連接,和SentenceSpout
* 類一樣,SplitSentenceBolt 類在初始化時沒有額外操作,因此prepare(方法僅僅保存
* OutputCollector物件的參考,
* @param config 配置資訊
* @param context 背景關系
* @param collector 提供發射元組的方法
*/
@Override
public void prepare(Map config, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/**
* SplitSentenceBolt 類的核心功能在execute()方法中實作,這個方法是IBolt介面定義
* 的,每當從訂閱的資料流中接收一個tuple,都會呼叫這個方法,本例中,execute( 方法按
* 照字串讀取“sentence"欄位的值,然后將其拆分為單詞,每個單詞向后面的輸出流發
* 射一個tuple,
* @param tuple
*/
@Override
public void execute(Tuple tuple) {
String sentence = tuple.getStringByField("sentence");
String[] words = sentence.split(" ");
for (String word : words) {
this.collector.emit(new Values(word));
}
}
/**
* 在declareOutputFields()方法中,SplitSentenceBolt 宣告了一個輸出流,每個tuple包
* 含一個欄位“word”,
* @param declarer 元組申明
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
3). WordCountBolt : 實作單詞計數 blot
package cn.zhanghub.bigdata.storm;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
/**
* 實作單詞計數 blot
* @author user
*/
public class WordCountBolt extends BaseRichBolt {
/**
* 必須要在prepare()方法中對不可序列化的物件進行實體化,
* (雖然HashMap是可序列化的)
*/
private OutputCollector collector;
private HashMap<String, Long> counts = null;
@Override
public void prepare(Map config, TopologyContext
context, OutputCollector collector) {
this.collector = collector;
this.counts = new HashMap<String, Long>();
}
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Long count = this.counts.get(word);
if(count == null){
count = 0L;
}
count++;
this.counts.put(word, count);
this.collector.emit(new Values(word, count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
4). WordCountTopology : 實作單詞計數 topology 拓撲
package cn.zhanghub.bigdata.storm;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import backtype.storm.utils.Utils;
/**
*實作單詞計數 topology 拓撲
* @author user
*/
public class WordCountTopology {
/**
* 首先定義字串常量,這將作ID為我們唯一標識Storm組件
*/
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology";
public static void main(String[] args) throws Exception {
SentenceSpout spout = new SentenceSpout();
SplitSentenceBolt splitBolt = new SplitSentenceBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
/* TopologyBuilder類提供了流式介面風格的API來定義topology組件之間的資料流, */
TopologyBuilder builder = new TopologyBuilder();
/* 注冊一個sentence spout并且賦值給其唯- - -的ID: */
builder.setSpout(SENTENCE_SPOUT_ID, spout);
/**
* 類TopologyBuilder的setBolt()方法會注冊一個bolt,并且回傳BoltDeclarer的實
* 例,可以定義bolt的資料源,這個例子中,我們將SentenceSpout的唯一ID賦值給
* shuffleGrouping() 方法確立了這種訂閱關系,shuffleGrouping()方法告訴Storm,要將
* 類SentenceSpout發射的tuple隨機均勻的分發給SplitSentenceBolt的實體,
*/
/* 注冊一個SplitSentenceBolt, 這個bolt訂閱SentenceSpout發射出來的資料流: */
// SentenceSpout --> SplitSentenceBolt
builder.setBolt(SPLIT_BOLT_ID, splitBolt).shuffleGrouping(SENTENCE_SPOUT_ID);
/**
* fieldsGrouping:需要將含有特定資料的tuple路由到特殊的bolt實體中,
* 在此我們使用類BoltDeclarer的fieldsGrouping()方法來保證所有“ word"欄位值相同的tuple會
* 被路由到同一個WordCountBolt實體中,
*/
/* 確立類SplitSentenceBolt和類theWordCountBolt之間的連接關系: */
// SplitSentenceBolt --> WordCountBolt
builder.setBolt(COUNT_BOLT_ID, countBolt).fieldsGrouping(SPLIT_BOLT_ID, new Fields("word"));
/**
*我們希望WordCountBolt發射的所有tuple 路由到唯一 的ReportBolt任務中,
* globalGrouping()方法提供了這種用法:
*/
// WordCountBolt --> ReportBolt
builder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(COUNT_BOLT_ID);
/**
* Storm的Config類僅僅是HashMap的之列,它定義了一系列配置Storm拓撲的運行時行為具體常量和方便的方法,
* 當提交一個拓撲時,Storm將合并其預定義的默認配置值和Congif實體的內容傳遞給submitTopology()方法,
* 并將結果分別傳遞給拓撲的spout的open()和bolt的prepare()方法,在這個意義上,配置引數的配置物件表示一組全域拓撲中的所有組件,
*/
Config config = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(TOPOLOGY_NAME, config, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();
}
}
2. WordCountTopology并行性
到目前為止,單詞計數的例子中,沒有顯式地使用任何Storm的并行api;相反,是允許Storm使用其默認設定,
在大多數情況下,除非覆寫,Storm將默認使用最大并行性設定,
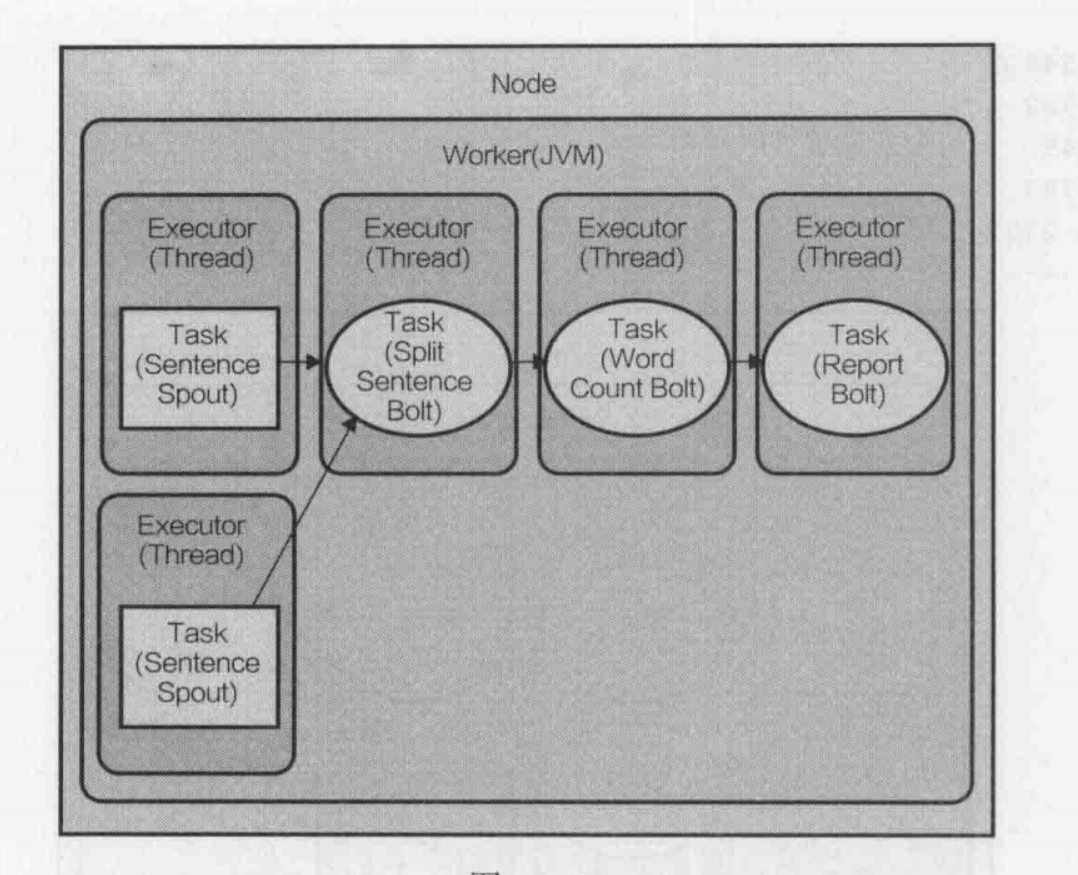
在改變拓撲結構的并行設定之前,讓拓撲在默認設定下,是如何將執行的:假設我們有一臺機器(節點),指定
一個worker的拓撲,并允許Storm每一個任務一個executor執行,執行的拓撲,
將會如下:
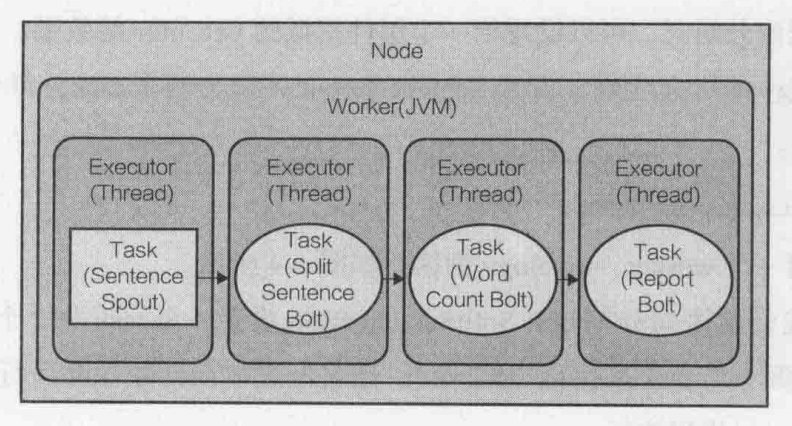
正如看到的,并行性只有執行緒級別(多個Executor),每個任務運行在一個JVM的一個單獨的執行緒內,那怎樣才能利用硬體更有
效地提高并行性?通過增加worker和executors的數量來運行拓撲,
3. 給topology增加worker
增加額外的worker是增加topology計算能力的簡單方法,為此Storm提供了API和修改配置項兩種修改方法,無論采取哪種方法,
spout 和bolt組件都不需要做變更,可以直接復用,
在單詞計數topology前面的版本中,引入了Config物件在發布時傳遞引數給submitTopology()方法,但是沒有做更多配置操作,
為了增加分配給一個topology的worker數量,
只需要簡單的呼叫一下Config物件的setNumWorkers()方法:
Config config = new Config();
config.setNumWorkers(2);
這樣就給topology分配了兩個worker而不是默認的一個,從而增加了topology 的計算資源,也更有效的利用了計算資源,還可以調整topology中的executor
個數以及每個executor分配的task數量,
4. 配置executor和task
Storm給topology中定義的每個組件建立一個task,默認的情況下,每個task分配一個executor,Storm的并發機制API對此提供
了控制方法,允許設定每個task對應的executor個數和每
個executor可執行的task的個數,
在定義資料流分組時,可以設定給一個組件指派的executor的數量,
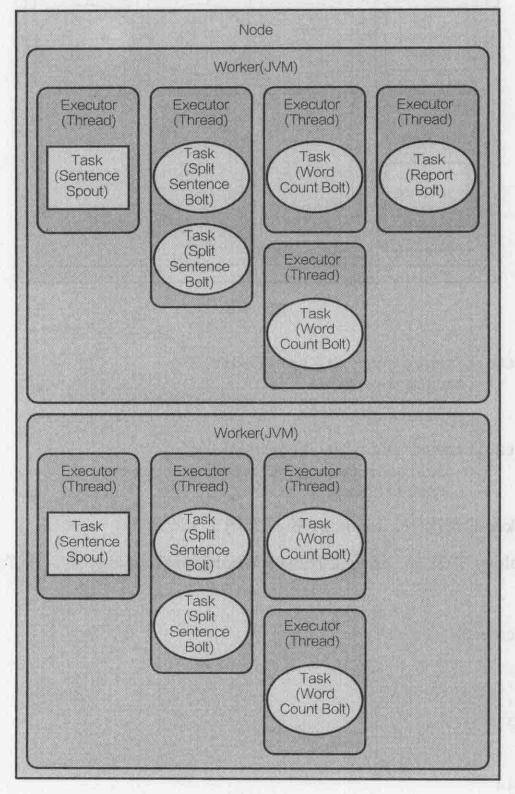
為了說明這個功能,修改topology的定義代碼,設定SentenceSpout 并發為兩個task,每個task指派各自的executor執行緒,
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
下一步,給陳述句分割bolt SplitSentenceBolt設定4個task和2個executor,每個executor執行緒指派2個task來執行(4/2=2),
還將配置單詞計數bolt 運行四個task,每個task由一一個
executor執行緒執行:
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2).setNumTasks(4)
.shuffleGrouping(SENTENCE_SPOUT_ID);
builder.setBolt(COUNT_BOLT_ID, countBolt, 4)
.fieldsGrouping(SPLIT_BOLT_ID, newFields("word"));
經過上述設定后的topology如下:
5. 理解資料流分組
資料流分組定義了一個資料流中的tuple如何分發給topology中不同bolt的task,舉
例說明,在并發版本的單詞計數topology中,SplitSentenceBolt 類指派了四個task資料
流分組決定了指定的一個tuple 會分發到哪個task上,
資料流分組除了前面提到的七個分組方式之外,還可以通過實作CustomStreamGrouping (自定義分組)
介面來自定義分組方式:
package cn.zhanghub.bigdata.storm;
import backtype.storm.generated.GlobalStreamId;
import backtype.storm.task.WorkerTopologyContext;
import java.io.Serializable;
import java.util.List;
/**
*
* 自定義分組 CustomStreamGrouping
* @author user
*/
public interface CustomStreamGrouping extends Serializable {
/**
* 在運行時呼叫,用來初始化分組資訊,分組的具體實作會使用這些資訊決定如何向接收task分發tuple,
* @param context WorkerTopologyContext物件提供了topology 的背景關系資訊
* @param stream GlobalStreamId提供了待分組資料流的屬性
* @param targetTasks 分組所有待選task的識別符號串列 ,通常,會將targetTasks的參考存在變數里作為chooseTasks()的引數,
*/
void prepare(WorkerTopologyContext context, GlobalStreamId stream, List<Integer> targetTasks);
/**
* chooseTasks
* @param taskId tuple的組件的id
* @param values tuple的組件的值
* @return tuple發送目標task的識別符號串列
*/
List<Integer> chooseTasks(int taskId, List<Object> values);
}
九、Storm 資料處理保障機制
Storm提供了一種API能夠保證spout發送出來的每個tuple都能夠執行完整的處理程序,在上面的例子中,不擔心執行失敗的情況,可以看
到在一個topology中一個spout的資料流會被分割生成任意多的資料流,取決于下游bolt的行為,
如果發生了執行失敗會怎樣?
舉個例子,考慮一個負責將資料持久化到資料庫的bolt, 怎樣處理資料庫更新失敗的情況?
1. spout的可靠性
在Storm中,可靠的訊息處理機制是從spout開始的,一個提供了可靠的處理機制的spout需要記錄它發射出去的tuple,當下游bolt處理tuple
或者子tuple失敗時spout能夠重新發射,
子tuple可以理解為bolt處理spout發射的原始tuple后,作為結果發射出去的tuple,
另外一個視角來看,可以將spout發射的資料流看作一個tuple樹的主干:
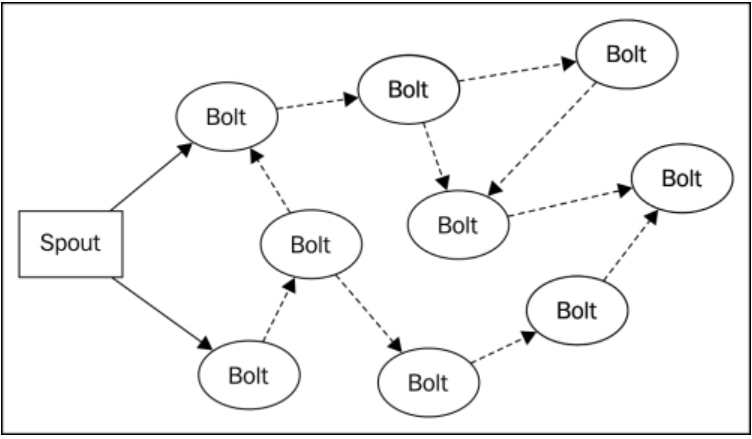
在圖中,實線部分表示從spout發射的原始主干tuple,虛線部分表示的子tuple都是源自于原始tuple,這樣產生的圖形叫做tuple樹,在有保障資料的處理過
程中,bolt每收到一個tuple,都需要向上游確認應答(ack)者報錯,對主干tuple中的一個tuple,如果tuple樹上的每個bolt進行了確認應答,spout會呼叫
ack方法來標明這條訊息已經完全處理了,如果樹中任何一個bolt 處理tuple報錯,或者處理超時,spout 會呼叫fail方法,
Storm的ISpout介面定義了三個可靠性相關的API: nextTuple, ack 和fail,
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}
前面說過,Storm 通過呼叫Spout的nextTuple()發送一個tuple,為實作可靠的訊息處理,首先要給每個發出的tuple帶上唯一的ID,并且將ID作為引數傳遞給SpoutOutputCollector
的emit)方法:
collector.emit(new Values("value1", "value2") ,msgId);
給tuple指定ID告訴Storm系統,無論執行成功還是失敗,spout 都要接收tuple樹上所有節點回傳的通知,如果處理成功,spout的ack()方法將會對編號是ID的訊息應答確
認,如果執行失敗或者超時,會呼叫fail() 方法,
2. bolt的可靠性
bolt要實作可靠的訊息處理機制包含兩個步驟:
- 當發射衍生的tuple時,需要錨定讀入的tuple
- 當處理訊息成功或者失敗時分別確認應答或者報錯
錨定一個tuple的意思是,建立讀入tuple和衍生出的tuple之間的對應關系,這樣下游的bolt就可以通過應答確認、報錯或超時來加人到tuple樹結構中,
可以通過呼叫OutputCollector中emit()的一個多載函式錨定一個或者一組tuple:
collector.emit(tuple, new Values(word));
這里,我們將讀人的tuple和發射的新tuple錨定起來,下游的bolt就需要對輸出的tuple進行確認應答或者報錯,
另外一個emit() 方法會發射非錨定的tuple:
collector.emit(new Values(word));
未錨定的元組不參與一個流的可靠性保證,如果一個非錨點元組下游失敗,它不會導致原始根元組的重發,
當處理完成或者發送了新tuple之后,可靠資料流中的bolt需要應答讀入的tuple:
this.collector.ack(tuple);
如果處理失敗,這樣的話spout必須發射tuple,bolt就要明確地對處理失敗的tuple報錯:
this.collector.fail(tuple)
如果因為超時的原因,或者顯式呼叫OutputColector.fail()方法,spout 都會重新發送
原始tuple,
3. 可靠的單詞計數
為了進一步說明可控性,需要增強SentenceSpout類,支持可靠的tuple發射方式,
需要記錄所有發送的tuple,并且分配一個唯一的ID,我們使用 HashMap<UUID, Values>來存盤已發送待確認的tuple,每當發送一個新的tuple,分配一個唯一的識別符號并且存盤
在我們的hashmap中,當收到一個確認訊息,從待確認串列中洗掉該tuple,如果收到報錯,從新發送tuple:
package cn.zhanghub.bigdata.storm;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
import java.util.Map;
import java.util.UUID;
import java.util.concurrent.ConcurrentHashMap;
/**
* 可靠的單詞計數 SentenceSpout
* @author user
*/
public class SentenceSpout2 extends BaseRichSpout {
private ConcurrentHashMap<UUID, Values> pending;
private SpoutOutputCollector collector;
private String[] sentences = {"my dog has fleas", "i like cold beverages", "the dog ate my homework",
"don't have a cow man", "i don't think i like fleas"};
private int index = 0;
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
@Override
public void open(Map config, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
this.pending = new ConcurrentHashMap<UUID, Values>();
}
@Override
public void nextTuple() {
Values values = new Values(sentences[index]);
UUID msgId = UUID.randomUUID();
this.pending.put(msgId, values);
this.collector.emit(values, msgId);
index++;
if (index >= sentences.length) {
index = 0;
}
Utils.sleep(1);
}
@Override
public void ack(Object msgId) {
this.pending.remove(msgId);
}
@Override
public void fail(Object msgId) {
this.collector.emit(this.pending.get(msgId), msgId);
}
}
為支持有保障的處理,需要修改bolt,將輸出的tuple和輸人的tuple錨定,并且應答確認輸人的tuple:
package cn.zhanghub.bigdata.storm;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.Map;
/**
* 可靠的單詞計數 ReliableSplitSentenceBolt
* @author user
*/
public class ReliableSplitSentenceBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map config, TopologyContext
context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String sentence = tuple.getStringByField("sentence");
String[] words = sentence.split(" ");
for(String word : words){
this.collector.emit(tuple, new Values(word));
}
this.collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/233114.html
標籤:其他
上一篇:MarkDown使用