一、Redis基礎
重新整理了一下,這篇筆記之前還有一篇基礎相關的筆記:
Redis基礎:https://blog.csdn.net/m0_50662680/article/details/110948426
二、為什么Redis是單執行緒的?
官方回答:Redis是基于記憶體操作,CPU不是Redis的性能瓶頸,Redis的性能瓶頸是機器的記憶體大小、以及網路的帶寬,既然單執行緒容易實作,那就直接使用單執行緒來實作了
此外:使用單執行緒實作,那所有的命令就會排隊執行,不需要考慮各種同步問題和加鎖帶來的性能消耗問題,
既然CPU不是Redis的瓶頸,那么如果不想讓服務器的其他CPU閑置,可以考慮起多個Redis行程,因為Redis不是關系型資料庫,資料之間也沒有約束,這樣還能搭建集群,分壓分流,
三、為什么單執行緒這么快?
- Redis是一款記憶體資料庫,基于記憶體的讀寫速度本來就很快
- 如果使用多執行緒的話會有執行緒背景關系的切換,對于記憶體系統來說,單執行緒操作記憶體的效率才是最高的,
- Redis使用了epoll IO多路復用,可以實作用一條執行緒處理并發的網路請求
四、select、poll、epoll
select、poll、eopll是作業系統處理網路上傳輸過來的資料的不同實作,資料從經過網線流入網卡,網卡中的驅動程式會向CPU發出中斷信號,在互動系統中,中斷信號的優先級是很高的,CPU立刻去處理這個中斷資訊,CPU通過終端表找到相應的處理函式:
1、禁用網卡的中斷信號,告訴網卡下次有資料過來直接寫記憶體就ok
2、通過驅動程式申請、初始化一塊記憶體,將網卡中的資料寫進記憶體中
3、然后決議處理資料:作業系統先校驗資料是否符合os structure、資料往上層傳遞,Ehthernet校驗資料是否符合預期的格式,繼續向上層傳遞到ip層,再往上到tcp/udp層并按照指定的協議去決議
4、應用層想使用這部分資料就有一個拆包+格式校驗的程序
記憶體指的socket檔案的接受緩沖區
作為一個網路服務器同一時刻可能有多個socket和他建立連接與他進行資料的互動,這里的select、poll、epoll說的其實就是在眾多的socket中如何快速高效的找到接受緩沖區存在資料的socket檔案,然后交給應用層的代碼去處理它
Select模型
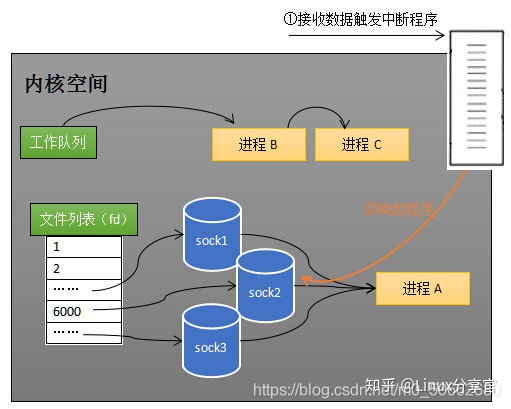
作系統為每一個Tcp連接都會相應的創建sock檔案,這些sock檔案隸屬于作業系統的檔案串列,
當sock收到了資料,會呼叫中斷程式喚醒行程A,將行程A從所有的Sock的等來佇列中移除,加入到內核空間的作業佇列中行程A只知道至少有一個sock的接受緩沖區已經由資料了,但是它不知道到底是哪個sock,所以它得通過遍歷sock串列的方式找到這個sock,
select的缺點和不足:
- 行程A需要添加進所有的sock的等待佇列中,這會進行一次遍歷,
- 當有sock就收到資料時,又得將行程A從所有的sock等待佇列中移除,這又是一次遍歷, 行程A尋找有資料的sock時,還會發生一次遍歷,
- 為了放置單個行程將系統的所有資源都耗干,linux會限制單個行程能打開的fd檔案句柄數,即使你可以修改配置,突破這會個限制
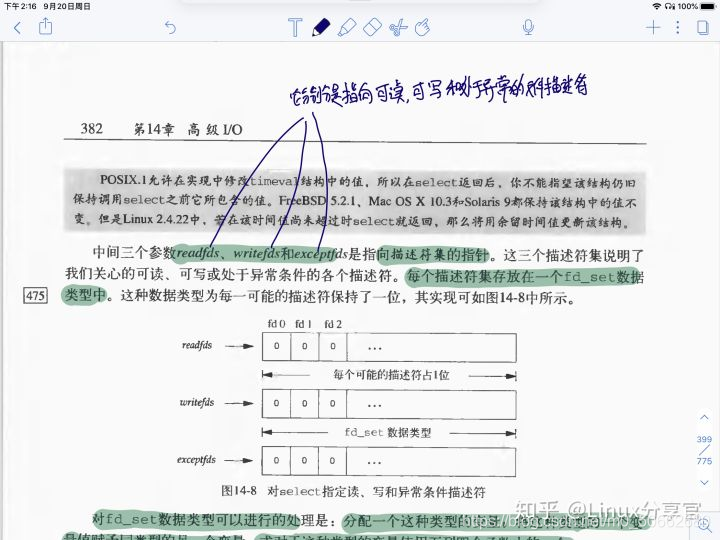
下圖截自《UNIX環境高級編程》第二版

上圖可以看到,使用select系統呼叫上有三個核心引數:分別是 readfds、writefds、exceptfds指向檔案描述符號指標,每個描述符都被放在fd_set中, 也就是說針對read、write、和except分別對應著一個獨立的fd_set , (并沒有網上流傳的陣列哦,至少《UNIX環境高級編程》是這樣講的)
下圖是截取自《UNIX環境高級編程》的關于fd_set的相關資訊,fd_set 是一個bit mask,不是陣列,
Poll模型
網上一直流傳著這樣一句話:poll本質上和select沒有區別,都會進行好幾次無謂的遍歷才能找到到底是那個sock檔案的接受緩沖區中接受到了資料,
下圖是我截自《UNIX環境高級編程》關于poll部分的內容

書中關于poll的描述,poll模型中定義了一個pollfd,對fd進行了封裝,也就是說,poll是使用陣列來保存fd的,就是上圖中的pollfd陣列
網上流傳的另一個版本就是說:poll使用鏈表維護著fd,所以poll沒有最大連接數的限制,這一點有待證實,至少《UNIX環境高級編程》中對鏈表的事只字未提
從書中的描述看,poll確實是用陣列來維護fd的,并且還自己封裝了個pollfd,維護的是pollfd陣列,那為什么poll沒有連接數的限制呢?
我是這樣理解的:select之所以受到能僅僅能打開1024的限制,是因為作業系統層面上默認就有對單個行程能打開fd的作出的限制,比如32位的OS默認就是1024,那我用poll同也會受到這個1024的限制,但是我能修改這個限制,讓他變得比1024大,比如改成10萬(只要你的服務器性能夠好就行,陣列中就能存更多的fd,遍歷處理起來就更快),所以這才會說,poll理論上可以沒有限制,
當然我上面說的不一定就對,如果你有更好的決議,歡迎留言,
Epoll模型
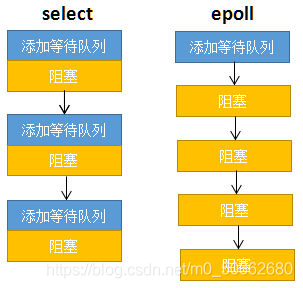
Epoll的設計目標就是優化掉Select 和 Poll模型中查找接收到資料的sock檔案時進行的無謂的遍歷操作,
看上圖:在select模型中,需要將行程添加進每一個sock的等待佇列,然后阻塞,假如10萬TCP連接對應著10萬個sock檔案,那這個添加+阻塞的操作就得重復10萬次
對于epoll來說可以看到,這個添加的程序只進行了一次…見下圖
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...)
listen(s, ...)
int epfd = epoll_create(...);
epoll_ctl(epfd, ...); //將所有需要監聽的socket添加到epfd中
while(1){
int n = epoll_wait(...)
for(接收到資料的socket){
//處理
}
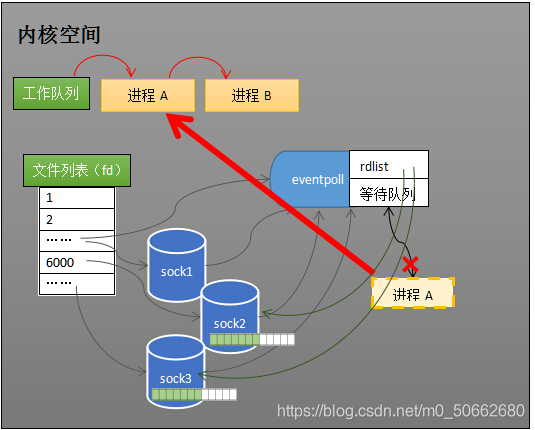
當執行系統呼叫 epoll_create(…) 內核會創建上圖中的eventpoll物件,eventpoll物件也隸屬于作業系統的檔案系統,此外所有的sock都注冊在eventpoll中,
行程不再注冊在每一個sock的等待佇列中,而是注冊在eventpoll的等待佇列中,此外,接受緩沖區存在資料的sock會被注冊進eventpoll的rdlist中,這樣當行程再次被喚醒添加到作業系統的作業佇列中時,從eventpoll的rdlist中就能確切的獲取到哪些sock是需要處理的sock,免去了遍歷之苦,
eventpoll中的資料結構
rdlist: 里面存放就緒列的socket,為了滿足快速方便洗掉、添加,它被設計成了雙向鏈表
epoll中也是需要保存受監視的sock,為了方便添加、搜索、檢索,被設計成紅黑樹,因為它的搜索、插入、洗掉的時間復雜度都是O(logN)
Epoll的連接數有上限,但是很大,1G記憶體的機器上可以打開10萬左右的連接,2G記憶體的機器可以打開20萬左右的連接,
五、Redis的事務
原子性:一組命令要么同時成功,要么同時失敗
但是redis中的每一條單獨的命令是有原子性的,但是Redis中的事務不能保證原子性
redis中的事務沒有隔離級別的概念,不可能出現臟讀、幻讀、不可重復讀
在redis中,事務的本質是一組命令的集合,一個事務中的所有命令都會有被序列化,在事務執行的程序中:順序、排他、一次性執行,
Redis事務的程序:
- 開啟事務
- 一連串普通命令
- 執行事務
# 開啟事務
127.0.0.1:16379> MULTI
OK
# 添加命令
127.0.0.1:16379> SET k1 v1
QUEUED
127.0.0.1:16379> SET k2 v2
QUEUED
# 執行事務
127.0.0.1:16379> EXEC
1) OK
2) OK
127.0.0.1:16379>
# 開啟事務
127.0.0.1:16379> MULTI
OK
# 添加命令
127.0.0.1:16379> set k3 v3
QUEUED
127.0.0.1:16379> SET k4 v4
QUEUED
# 取消事務
127.0.0.1:16379> DISCARD
OK
# 檢查結果,確實沒有執行剛剛添加的命令
127.0.0.1:16379> keys *
1) "k1"
2) "k2"
127.0.0.1:16379>
假設開啟時候后,多條命令中有一個命令出現運行時例外有什么影響?
出現例外的命令不會被執行,但是這個例外的命令不會影響它后面的命令執行,因為這個原因我們說redis的事務不支持原子性
# k1的值為字串
127.0.0.1:16379> set k1 "v1"
OK
# 開啟事務
127.0.0.1:16379> MULTI
OK
# 設定事務的值
127.0.0.1:16379> set k2 v2
QUEUED
# 對字串型別的值+1,會拋出運行時例外
127.0.0.1:16379> INCR k1
QUEUED
# 繼續添加兩個值
127.0.0.1:16379> set k3 v3
QUEUED
127.0.0.1:16379> set k4 v4
QUEUED
# 執行事務,看到,運行時例外的命令不會影響后續的命令執行
127.0.0.1:16379> exec
1) OK
2) (error) ERR value is not an integer or out of range
3) OK
4) OK
127.0.0.1:16379>
假設開啟時候后,多條命令中有一個命令出現編譯例外有什么影響?
出現編譯型例外,所有的命令都不會被執行
# 開啟事務
127.0.0.1:16379> MULTI
OK
# 往命令佇列中添加命令
127.0.0.1:16379> set k1 v1
QUEUED
127.0.0.1:16379> set k2 v2
QUEUED
# 故意添加一個語法錯誤的命令,導致編譯例外
127.0.0.1:16379> GETSET k3
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:16379> set k4 v4
QUEUED
# 執行事務
127.0.0.1:16379> exec
(error) EXECABORT Transaction discarded because of previous errors.
# 檢查結果,發現所有的命令都沒有被執行
127.0.0.1:16379> keys *
(empty list or set)
127.0.0.1:16379>
CAP理論
nosql同樣也有一套屬于自己的CAP
- C(Consistency 強一致性)
- A(Availability可用性)
- P(Partition tolerance磁區容錯性)
CAP 的理論核心是: 一個分布式的系統,不可能很好的滿足一致性,可用性,磁區容錯性這三個需求,最多同時只能滿足兩個.因此CAP原理將nosql分成了三大原則:
- CA- 單點集群,滿足強一致性和可用性,比如說oracle,擴展性收到了限制
- CP- 滿足一致性,和磁區容錯性Redis和MongoDB都屬于這種型別
- AP- 選擇了可用性和磁區容錯性,他也是大多數網站的選擇,容忍資料可以暫時不一致,但是不容忍系統掛掉
六、Redis的監控
redis可使用watch監視某一個key,然后開啟事務操作某一個key,當key沒有發生例外變動時,事務正常結束
一旦事務成功執行后,watch就會自動取消掉
127.0.0.1:16379> set money 100
OK
127.0.0.1:16379> set out 0
OK
# 監視key
127.0.0.1:16379> WATCH money
OK
127.0.0.1:16379> MULTI
OK
127.0.0.1:16379> DECRBY money 20
QUEUED
127.0.0.1:16379> INCRBY out 20
QUEUED
127.0.0.1:16379> exec
1) (integer) 80
2) (integer) 20
下面演示一個出現例外的例子:
事務中,添加watch的key被修改后,執行事務回傳nil,表示失敗
驗證了watch機制使用的是樂觀鎖機制
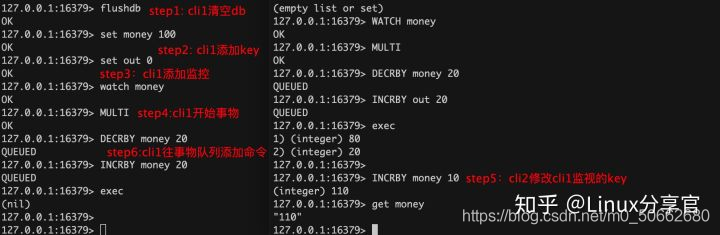
當遇到上面這種回傳nil的情況下,可以像下面這樣處理
# 取消監視(解鎖)
127.0.0.1:16379> UNWATCH
OK
# 重新監視
127.0.0.1:16379> watch money
OK
# 重新開啟事務
127.0.0.1:16379> MULTI
OK
127.0.0.1:16379>
七、Redis的組態檔
## 啟動redis的方式
./redis-server /path/to/redis.conf
# 可以像下面這樣讓在當前組態檔包含參考其他組態檔
include /path/to/local.conf
include /path/to/other.conf
# 指定哪些客戶端可以連接使用redis
Examples:
bind 192.168.1.100 10.0.0.1 # 指定ip
bind 127.0.0.1 ::1 # 僅限于本機可訪問
# 是否處于受保護的模式,默認開啟
protected-mode yes
# 對外暴露的埠
port 16379
# TCP的通用配置
tcp-backlog 511
timeout 0
tcp-keepalive 300
# 是否以守護行程的方式運行,默認為no
daemonize yes
# 如果行程在后臺運行,需要指定這個pid檔案
pidfile /var/run/redis_6379.pid
# 日志級別
# debug 測驗開發節點
# verbose (和dubug很像,會產生大量日志)
# notice (生產環境使用)
# warning (only very important / critical messages are logged)
loglevel notice
# 日志檔案名
logfile ""
# 資料庫的數量,默認16個
databases 16
# 是否總是顯示logo
always-show-logo yes
# 設定redis的登陸密碼(默認沒有密碼)
# 設定完密碼后,使用redis-cli登陸時,使用auth password 認證登陸
requirepass foobared
# 設定能連接上redis的客戶端的最大數量
maxclients 10000
# 給redis設定最大的記憶體容量
maxmemory <bytes>
# 記憶體達到上限后的處理策略
# volatile-lru -> 只針對設定了過期時間的key進行LRU移除
# allkeys-lru -> 洗掉LRU演算法的Key
# volatile-lfu -> 使用具有過期集的密鑰在近似的LFU中進行驅逐,
# allkeys-lfu -> 使用近似的LFU退出任何密鑰,
# volatile-random -> 隨機洗掉即將過期的key
# allkeys-random -> 隨機洗掉
# volatile-ttl -> 洗掉即將過期的
# noeviction -> 永不過期,回傳錯誤
maxmemory-policy noeviction
八、Redis的持久化
8.1、fork()系統呼叫
這里很突兀的來個fork()系統呼叫原因是應為:Redis的單執行緒的,那如果主執行緒去做這種耗時的IO同步操作時,Redis整體的性能會被拖垮的,
fork()它是一個系統呼叫,一般用它來創建一個和當前行程一模一樣的子行程,當在程式中呼叫它時,系統為新的行程分配存盤、資源,將原程式中的值也復制給他,
fork()函式呼叫一次會回傳兩次,在父行程得到的回傳值是子行程的pid,在子行程中得到的是0,出錯則回傳負數,
Redis的實作是通過fork()系統呼叫創建一個子行程, 由這個子行程去負責執行這些耗時的IO操作,父子行程會共享記憶體,然后被共享的這塊記憶體不可寫,新的資料寫入到新的記憶體檔案中
8.2、RDB
寫RDB檔案是Redis的一種持久化方式,在指定的時間間隔內將記憶體中的資料寫入到磁盤,RDB檔案是一個緊湊的二進制檔案,每一個檔案都代表了某一個時刻(執行fork的時刻)Redis完整的資料快照,恢復資料時,將快照檔案讀入記憶體即可,
RDB持久化的詳細程序:
Redis會通過系統呼叫fork()出一個子行程,父子行程是會共享記憶體的,父行程和子行程共享的這塊記憶體就是在執行fork操作那個時刻的記憶體快照,由linux的copy on write機制將父子行程共享的這塊記憶體標記為只讀狀態,
此時對子行程來說,它的任務就是將這塊只讀記憶體中的資料保存成RDB檔案,
對父行程來說它是有可能收到寫命令的,當父行程嘗試往這個加了只讀狀態的記憶體地址寫入資料時,就會觸發保護例外,執行linux的 copy on write,也就是將原來記憶體對應的資料頁復制出來一份后,然后對這個副本進行修改,
**這里就會出現一個丟資料的概念:**你想,fork出來的子行程將要保存的資料是執行fork系統呼叫那個時刻的記憶體中的資料,很快這個記憶體就被標記為只讀了,后續的增量資料沒有寫入到這個只讀記憶體中,那就算是RDB成功生成了,然后好巧,Redis掛了,這些增量的資料就會丟(所以得使用AOF輔助)
第二種RDB出現資料的丟失的情況是:RDB程序中,直接失敗了,檔案都沒生成,不光是增量資料,原來的資料都丟了,
RDB相關配置如下:
# 把下面的注釋打開就會禁用掉RDB的持久化策略
# save ""
# 快照相關,指的是在規定的時間內執行了多少次操作才會持久化到檔案
save 900 1 # 900秒內1次
save 300 10 # 300秒內10次
save 60 10000 # 60秒內1萬次
# 持久化出錯了,是否讓redis繼續作業
stop-writes-on-bgsave-error yes
# 是否壓縮RBD檔案(redis會采用LZF壓縮演算法進行壓縮)需要消耗CPU資源
rdbcompression yes
# 保存rbc檔案時是否檢驗rbd檔案格式
# 使用CRC64演算法進行資料校驗,但是這樣會增加大約 10%的性能消耗
rdbchecksum yes
# dump DB的檔案名
dbfilename dump.rdb
# rdb檔案的持久化目錄(當前目錄)
dir ./
觸發保存RDB檔案4種情況:
- 手動執行save命令、bgsave
- 滿足組態檔中配置的save相關配置項時,自動觸發
- 手動執行flushall
- 關閉redisshutdown
如何讓redis加載rdb檔案?
只需要將rdb檔案放在redis的啟動目錄下,redis其中時會自動加載它
RDB模式的優缺點:
優點:RDB程序中,由子行程代替主行程進行備份的IO操作,保證了主行程仍然提供高性能的服務,適合大規模的資料備份恢復程序,
缺點:
- 默認情況下,它是每隔一段時間進行一次資料備份,所以一旦出現最后一次持久化的資料丟失,將丟失大規模的資料,
- fork()子行程時會占用一定的記憶體空間,如果在fork()子行程的程序中,父行程夯住了,那也就是redis卡住了,不能對外提供服務,所以不要讓生成RDB檔案的時間間隔太長,不然每次生成的RDB檔案過大對Redis本身也是有影響的,
8.3、AOF
AOF是什么?
Append Only File,他也是Redis的持久化策略,即將所有的寫命令都以日志的方式追加記錄下來(只追加,不修改),恢復的時候將這個檔案中的命令讀出來回放,
當我們執行 flushall 命令,清空了redis在記憶體中的資料,appendonly.aof 同樣會記錄下這條命令,所以,我們想恢復資料的話,需要去除 appendonly.aof 里面的 flushall 命令
AOF相關的配置
# 默認不開啟aof
appendonly no
# aof檔案名
appendfilename "appendonly.aof"
# redis通過fsync()呼叫告訴作業系統實際在磁盤上寫入資料
# aof檔案落盤的策略
# appendfsync always 每次發生資料變更,立刻記錄到磁盤,但是導致redis吞吐量降低
# appendfsync everysec 可能會丟失1秒的資料
# appendfsync no
appendfsync everysec
# 當時用bfwriteaof時,fork一個子行程寫aof檔案,就算aof檔案很大,也不會阻塞主行程
# 意外情況:但是當主行程、子行程同時寫aof檔案時,可能會出現由于子行程大量的IO操作阻塞主行程
# 當出現這種意外情況時:設定這個引數為no,可以保證資料不會丟失,但是得容忍主行程被阻塞
# 當出現這種意外情況時:設定這個引數為yes,主行程不會被阻塞主,但是不保證資料安全性
# 綜上:如果應用無法忍受延遲:設定為yes,無法忍受資料丟失:設定為no
no-appendfsync-on-rewrite no
# 在當前aof檔案的體積超過上次aof檔案的體積的100%時,寫新檔案
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb # 最開始的aof檔案體積至少達到60M時才重寫
# 回放aof檔案時,如果最后一條命令存在問題,是否允許忽略
aof-load-truncated yes
# 是否允許AOF和RDB這兩種持久化方式并存
aof-use-rdb-preamble yes
當aof檔案出錯怎么辦?
redis為我們提供了修復aof檔案的工具
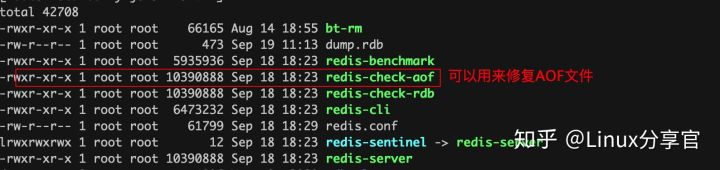
[root@instance-lynj0v9k-19 bin]# redis-check-aof --fix appendonly.aof
aof模式的優缺點優點:
- aof是用追加的形式寫,沒有隨機磁盤IO那樣的尋址開銷,性能還是比較高的,
- aof可以更好的保護資料不丟失或者盡可能的少丟失:設定讓redis每秒同步一次資料,即使redis宕機了,最多也就丟失1秒的資料,
- 即使aof真的體積很大,也可以設定后臺重寫,不影響客戶端的重寫,
- aof適合做災難性的誤洗掉緊急恢復:比如不小心執行了flushall,然后可以在發生rewrite之前 快速備份下aof檔案,去掉末尾的flushall,通過恢復機制恢復資料
缺點:使用aof一直追加寫,導致aof的體積遠大于RDB檔案的體積,恢復資料、修復的速度要比rdb慢很多,
aof的重寫
AOF采取的是檔案追加的方式,檔案的體積越來越大,為了優化這種現象,增加了重寫機制,當aof檔案的體積到達我們在上面的組態檔上的闋值時,就會觸發重寫策略,只保留和資料恢復相關的命令
手動觸發重寫
# redis會fork出一條新的行程
# 同樣是先復制到一份新的臨時檔案,最后再rename,遍歷每一條陳述句,記錄下有set的陳述句
bgrewriteaof
8.4、RDB和AOF的選擇
如果我們的redis只是簡單的作為快取,那兩者都不要也沒事
如果資料需要持久化,那不要僅僅使用RDB,因為一旦發生故障,你會丟失很多資料
同時開啟兩者: 在這種情況下,redis優先加載的是aof,因為它的資料很可能比rdb更全,但是并不建議只是用aof,因為aof不是那么的安全,很可能存在潛在的bug
推薦:
建議在從機slave上只備份rdb檔案,而且只要15分鐘備份一次就夠了,
如果啟動了aof,我們盡量減少rewrite的頻率,基礎大小設定為5G完全可以,起步也要3G,
如果我們不選擇aof, 而是選擇了主從復制的架構實作高可用同樣可以,能省掉一大筆IO操作,但是意外發生的話,會丟失十幾分鐘的資料,
九、發布訂閱
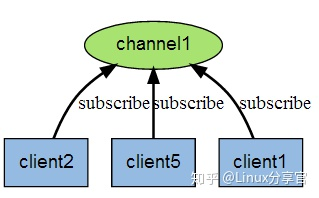
Redis的發布訂閱模型是一種:訊息通信方式,發布者發送到redis到佇列中,訊息的訂閱者可以接收到訊息,Redis的客戶端可以訂閱任意數量的訊息
應用場景:關注訂閱、訊息推送、實時廣播、網路聊天室
有新訊息通過 PUBLISH 命令發送給頻道 channel1 時, 這個訊息就會被發送給訂閱它的三個客戶端
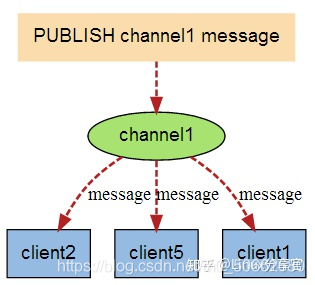
測驗發布、訂閱

十、主從復制
概念:和MySQL的主從復制的概念大同小異,分成leader節點和follower節點,主節點承接線上的寫流量,從節點承接線上的讀流量為主庫分流減壓,從庫的資料從主庫中同步過來
主從復制的作用:
- 理論上主庫從庫的資料是需要保持的,這也是一種資料冗余熱備份的機制
- 故障恢復:當leader節點出現故障時,可以由從節點提供服務,保證應用的可用性
- 負載均衡:在主從復制的接觸上,可以將客戶端的讀寫不同型別的流量分攤到不同的機器上,分流減壓
主從復制+哨兵,構建高可用的redis集群,解決了單點故障問題
十一、集群搭建及小實驗
redis默認自己就是一個主庫,所以我們搭建主從架構的redis,只需要配置Redis從庫,
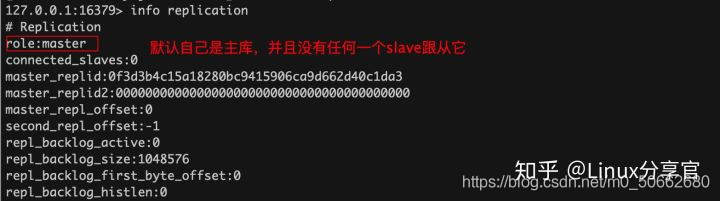
11.1、架構一:一主兩從
下面搭建這樣的一主兩從的redis集群
如果是在一臺服務器上啟動多臺Redis,需要修改一下組態檔中的埠、pid檔案名、日志名、dump.db名
啟動三臺redis
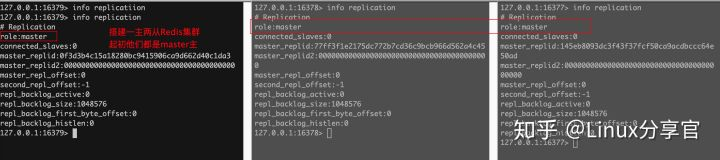
讓16378、16377認16379為leader,執行如下命令:
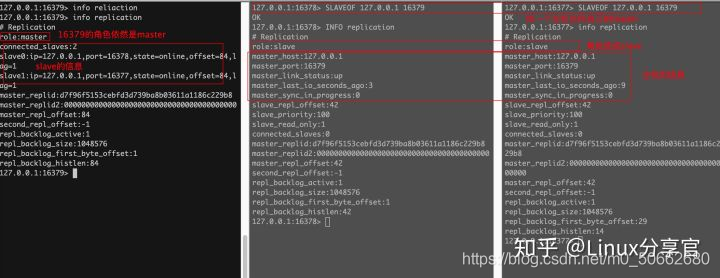
搭建完主從環境之后,查看是否可以從slave中寫入資料:
# 結果很明顯,不能寫入
127.0.0.1:16378> set k1 v0
(error) READONLY You can't write against a read only replica.
MySQL中只要你不設定從庫read only,從庫也是可以寫入的并產生自己的binlog的
測驗:從master寫入,從slave讀出

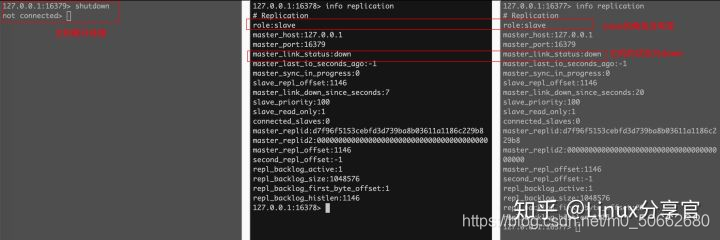
測驗:主機宕機,slave有什么表現
主機宕機后,從庫的role依然是slave,并且顯示master的狀態為down
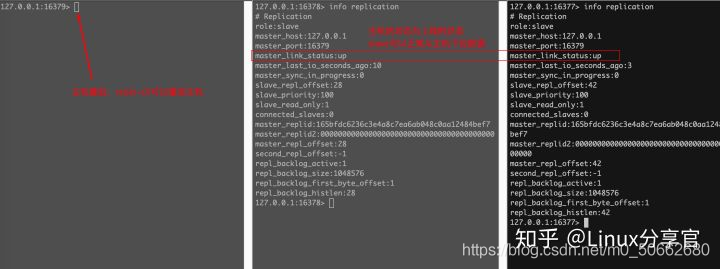
測驗:主機宕機后又重啟了,slave有什么表現
主機重啟后,slave會重連主機,主機的狀態為up,salve可以正常在主庫上同步資料
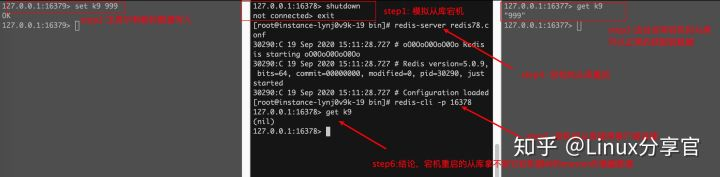
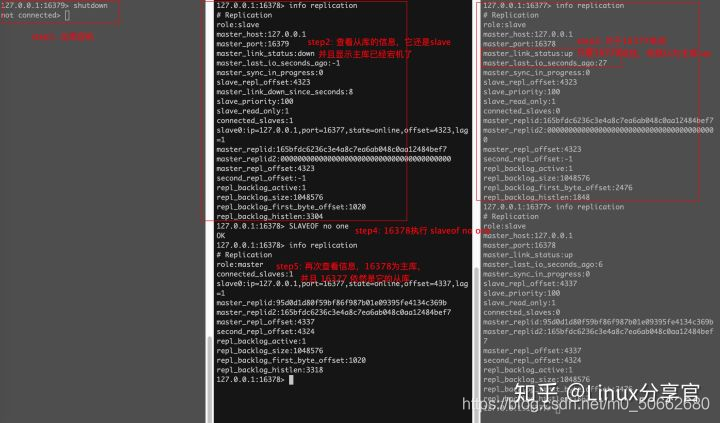
測驗:從機宕機,然后有新資料寫到了主庫,從機再重啟問:重啟后的從機能不能獲取到她宕機期間主庫的增量資料?
答案是:獲取不到了,因為如果是通過命令列搭建的主從,從庫一旦重啟,角色會變回master
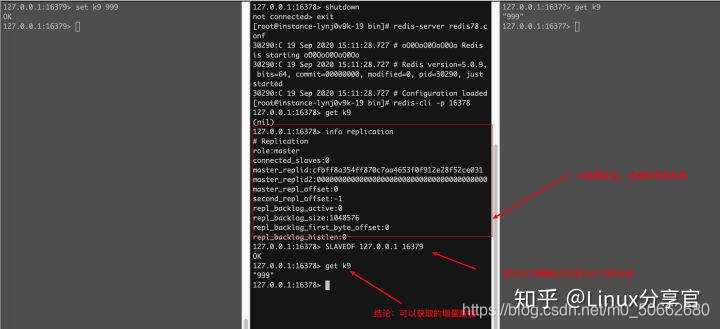
如果這時再把16378變成16379的從庫,問能不能獲取到增量資料呢?
全量復制和增量復制
從庫第一次連接到主庫上肯定會進行一次全量復制,即:master會啟動后臺的存盤行程,同時收集所有用于修改資料集的命令,在后臺完成同步,然后將整個資料檔案發送給slave,讓slave完成一次資料的全量復制
除第一次復制資料之外的主從復制都是增量復制,即master僅僅會將收到的增量寫命令發送給slave,
11.2、架構二
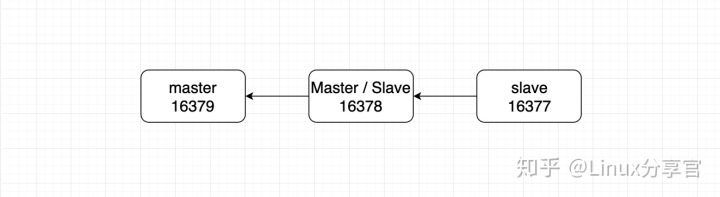
其中的17378既是Master又是Slave
對于16377來說,它確實認了16378為主,但是16378本身又是16379的slave,所以他們之間資料同步的走向是 : 16379 --> 16378 --> 16377 ,對于16378來說,即使有實體認它當master,它依然是不能寫
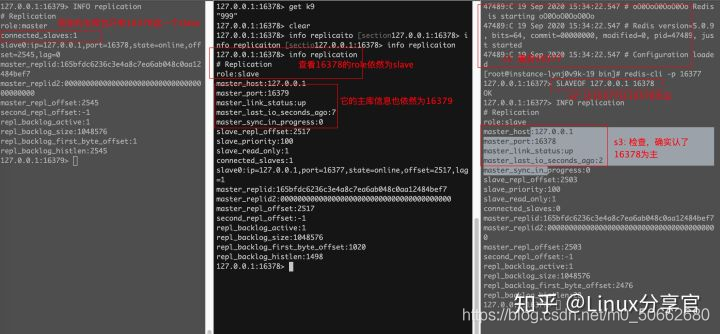
如果主庫16379宕機了,16378的狀態依然是slave,并且它能察覺master已經掛了,執行 slave no one, 可以將自己提升為master, 在整個程序中,16377不受影響
即使舊master開機重啟了,舊的master依然是master,也不能自動的加入到 16377 16378集群中
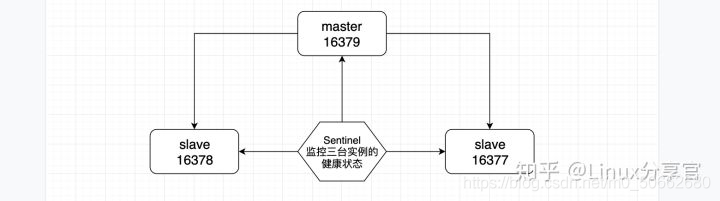
11.3、架構三:Sentinel
上面的兩種架構模式中,主庫掛了之后都需要人為的去選舉一個的新的master來承接讀流量
redis2.8之之后,提供了哨兵模式:哨兵監控到當主服務器掛了,發起投票選新主庫,實作自動的完成選主,承接線上寫流量,完成止損
哨兵作為一個獨立的行程存在,原理是:哨兵通過發送命令和redis服務器互動,從而監控運行整個集群中的多個Redis實體
Redis的哨兵在Redis 的安裝目錄下可以找到
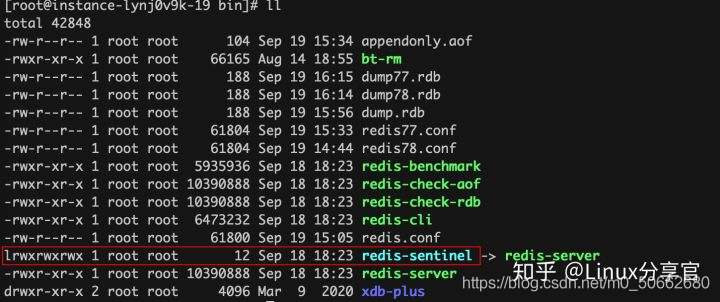
為了防護哨兵出現單點故障,所以通常使用多個哨兵對集群進行監控
集群中的每個哨兵彼此相互監控,每個哨兵也都監控著集群中的所有Redis實體
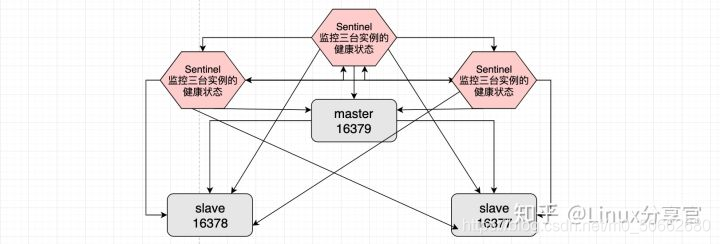
主觀下線和客觀下線
當一個哨兵發現master不可用時,系統不會馬上進行failover,僅僅是這一個哨兵主觀意義上認為這個master不可用,這時如果其他的哨兵也來探測master,并且大部分的哨兵都主觀認為master確實不可用了,哨兵們就會投票在slave中選出一個當得票最多的slave作為新的master,進行failover操作,
通過發布訂閱的模式,哨兵告訴自己監控的那些服務器將master切換為剛剛的票最多的那個實體,這個程序就叫做客觀下線,
集群搭建
首先是創建一主二從的redis集群, 此處省略,參照上面架構1部分即可
撰寫sentinel的組態檔,組態檔的名稱、配置項不能寫錯~
# myredis1 監控的這個redis實體啥
# 127.0.0.1 監控的這個redis實體的ip
# 16379 監控的這個redis實體的埠
# 1 監控的這個redis實體的掛了后,自動投票選主
sentinel monitor myredis1 127.0.0.1 16379 1
啟動sentinel
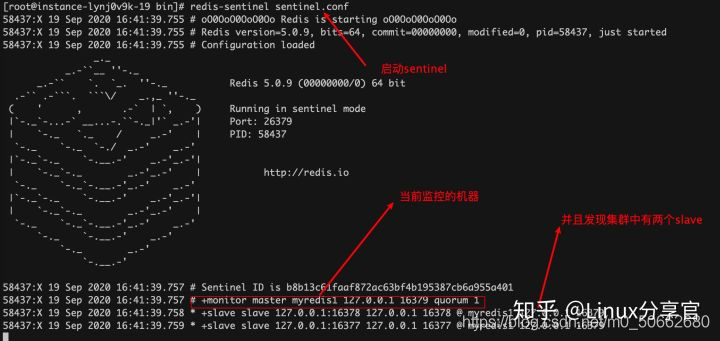
這樣,當master宕機后,哨兵會自動選擇一個新的slave作為新主,主庫重啟后,sentinel會將其作為slave自動加入到現有的redis集群中,
十二、快取穿透、快取擊穿、雪崩
快取穿透
比如這種應用場景:使用redis快取用戶資訊,當有新用戶注冊時先將用戶的資訊寫入Mysql,然后寫入Redis,有修改操作時,修改完MySQl中的資料后,同步的也會修改Redis中的資料,而且我們也沒有給Redis中的key設定過期時間,(這就意味著:資料庫中有指定的KV的資訊的話,快取中也會有,那當用戶查詢時快取中沒有的話,說明資料庫中99.999%也不會有)
這時候有大量的請求去訪問MySQL中都沒有都資料時,請求先打向了Redis,Redis中肯定也沒有存盤用戶查詢的資料,所以大量的請求一下子打到了資料庫上,瞬間擊垮資料庫,這種現象稱為快取穿透,
解決方案:
布隆過濾器:
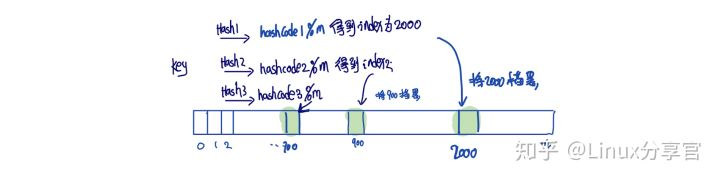
布隆過濾器可以理解成一個bit陣列,陣列中每一個非0即1
客戶端的請求統一先打向布隆過濾器,布隆過濾器放在應用的控制層,布隆過濾器中存在多個hash函式,分別對這個key進行hash得到hashcode,然后將hashcode%陣列長度,將算出來的下標標記為1,
key以此經過所有hash,再%size算出的下標對應的值,只要存在一個不為1的數,我們就認為key沒在快取中,直接丟棄用戶的這次請求,符合要求把請求打向Redis,從而避免這個請求對底層存盤的查詢壓力,
快取空物件:
當用戶查詢的時候,如果發現快取中沒有,就往快取中放置一個空的物件,然后回傳給用戶這個控物件,也能避免用戶的請求直接打向資料庫,
快取擊穿:
快取擊穿指的是Redis中確確實實存在用戶查詢的key,但是呢用戶的訪問頻率太猛烈了,導致Redis扛不住掛了,導致大量的請求直接打向資料庫,或者當某一個key的過期時間到了的瞬間,大量的請求打向資料庫導致資料庫直接掛了
解決方案:
設定key永不過期
加互斥鎖:對這個查詢操作添加分布式鎖,將原來的大并發直接訪問快取轉換成了并發獲取分布式鎖,只有獲取到分布式鎖后才能去查詢快取,
雪崩:
比我們啟動redis進行一些資料預熱,就是將一些資料庫中的資料提前匯入到redis中,然后給這些資料設定了過期時間,
搶購時間一到系統迎來了一大批并發,但是由于快取中的資料充足,所以能扛住這波并發,一段時間后,redis中的key集中式的過期了,這時再來一大批并發請求可能就直接將redis打垮,redis掛了后,大量的請求直接打向MySQL,導致MySQL跟著雪崩式的垮掉
解決方法:異地多活,添加redis的實體的數量
加分布式鎖
在應用和快取之間添加訊息中間件做緩沖
合理為不同的key設定不同的過期時間,放置快取中的key出現集中式過期的情況.

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/233536.html
標籤:其他