什么是Kafka Connect
正如前面的文章所說,Debezium提供的各種Connector都是Kafka Connect的插件,運行于Kafka Connect的服務上,
首先我們要知道,Kafka的特性,例如,topic的磁區、I/O結合作業系統的頁快取(page cache)等,這些令Kafka具備了高吞吐量、低延時及高可用等優點,
由于Kafka的優點,當需要實作CDC(Changed Data Capture)時,即捕獲資料源的變動并同步至目標資料源,我們可以使用Kafka作為資料源和目標資料源之間的資料通道,
而作為開發人員只想專注于開發與資料源互動的代碼,至于怎樣開發Producer程式把捕獲的資料發布到Kafka、怎樣保證捕獲資料的服務高可用,他們不希望多花精力考慮,這時,可以使用Kafka Connect把上下游的資料源與Kafka串聯起來,而與資料源互動的業務代碼則以Connector的形式運行在Kafka Connect上,

如上圖所示,從捕獲資料源變動情況的Connector被稱為Source Connector,它們負責與資料源互動,把捕獲到的記錄放到一個集合里面(不一定是queue),然后,Kafka Connect會呼叫Connector對應的Task的poll方法從集合中獲取記錄,并發送至Kafka,
還有負責把記錄從Kafka拷貝至目標的Sink Connector,但由于Debezium的Connector只實作了Source Connector,下面只對Source Connector作說明,
2 Kafka Connect的相關概念
2.1 Worker
在Kafka Connect的集群中,集群中的Kafka Connect行程實體被稱為Worker,
2.2 Connector和Task
運行在Kafka Connect上的插件都包含SourceConnector和SourceTask抽象類的子類,
Connector
先看看SourceConnector的定義
SourceConnector
package org.apache.kafka.connect.source;
import org.apache.kafka.connect.connector.Connector;
/**
* SourceConnectors都繼承該類,負責從資料源捕獲資料變化情況
*/
public abstract class SourceConnector extends Connector {
@Override
protected SourceConnectorContext context() {
return (SourceConnectorContext) context;
}
}
Connector
package org.apache.kafka.connect.connector;
import org.apache.kafka.common.config.Config;
import org.apache.kafka.common.config.ConfigDef;
import org.apache.kafka.common.config.ConfigValue;
import org.apache.kafka.connect.errors.ConnectException;
import org.apache.kafka.connect.components.Versioned;
import java.util.List;
import java.util.Map;
public abstract class Connector implements Versioned {
protected ConnectorContext context;
/**
* 初始化Connector,注入ConnectorContext物件
* @param Connector可使用ConnectorContext的物件和Kafka Connect互動
*/
public void initialize(ConnectorContext ctx) {
context = ctx;
}
/**
* 初始化Connector,注入ConnectorContext物件和task的配置資訊
* @param ctx Connector可使用ConnectorContext的物件和Kafka Connect互動
* @param taskConfigs 任務的配置資訊
*/
public void initialize(ConnectorContext ctx, List<Map<String, String>> taskConfigs) {
context = ctx;
// Ignore taskConfigs. May result in more churn of tasks during recovery if updated configs
// are very different, but reduces the difficulty of implementing a Connector
}
/**
* 回傳ConnectorContext物件
* @return ConnectorContext的物件
*/
protected ConnectorContext context() {
return context;
}
/**
* 開啟Connector
* @param props 配置資訊
*/
public abstract void start(Map<String, String> props);
/**
* 重新配置Connector,會做重啟操作
* @param props 新的配置資訊
*/
public void reconfigure(Map<String, String> props) {
stop();
start(props);
}
/**
* 指定SourceTask的實作子類.
*/
public abstract Class<? extends Task> taskClass();
/**
* 從當前的配置資訊中提取Task所需的配置資訊,回傳的List包含多少個元素,就表示多少個Tasks
* @param maxTasks 一個Connector生成的Task數量
* @return Tasks的配置資訊,例如List包含2個元素,就會有2個Task作業
*/
public abstract List<Map<String, String>> taskConfigs(int maxTasks);
/**
* 停止Connector
*/
public abstract void stop();
/**
* 校驗Connector的配置資訊.
* @param connectorConfigs Connector的配置資訊
* @return 對connectorConfigs進行校驗后,回傳最終的配置資訊
*/
public Config validate(Map<String, String> connectorConfigs) {
ConfigDef configDef = config();
if (null == configDef) {
throw new ConnectException(
String.format("%s.config() must return a ConfigDef that is not null.", this.getClass().getName())
);
}
List<ConfigValue> configValues = configDef.validate(connectorConfigs);
return new Config(configValues);
}
/**
* 定義該Connector的配置資訊
* @return 該Connector的配置資訊.
*/
public abstract ConfigDef config();
}
Connector里面定義了很多方法,我們后面會結合PostgreSQL Connector去詳細說明這些方法,
從上面的代碼,我們可以看出,Connector并沒有直接跟資料源互動,它的主要任務是生成配置資訊及告訴Kafka Connect:請把我的作業拆分成n個Task:
Config validate(Map<String, String> connectorConfigs): 校驗創建Connector時候傳入的配置資訊,并根據這些資訊生成Config物件,這個Config物件將被Kafka Connect使用,Class<? extends Task> taskClass():指定真正與資料源互動的Task的實作類,List<Map<String, String>> taskConfigs(int maxTasks):生成Connector對應的Task的配置資訊,例如,maxTasks為3,表示整個作業由3個Task共同完成,回傳的List應該也包含3個元素,
Task
下面看SourceTask的抽象類代碼:
package org.apache.kafka.connect.source;
import org.apache.kafka.connect.connector.Task;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.List;
import java.util.Map;
/**
* SourceTask負責從資料源捕獲資料供Kafka Connect發布至Kafka.
*/
public abstract class SourceTask implements Task {
protected SourceTaskContext context;
/**
* 初始化SourceTask.
*/
public void initialize(SourceTaskContext context) {
this.context = context;
}
/**
* 對Task進行一次性配置,并開始Task的作業.
* @param props Task的配置資訊
*/
@Override
public abstract void start(Map<String, String> props);
/**
* 提取Task從資料源捕獲的記錄
*
* @return 捕獲的記錄
*/
public abstract List<SourceRecord> poll() throws InterruptedException;
/**
* 提交位移資訊
*/
public void commit() throws InterruptedException {
// This space intentionally left blank.
}
/**
* 停止該Task的運行
*/
@Override
public abstract void stop();
@Deprecated
public void commitRecord(SourceRecord record) throws InterruptedException {
// This space intentionally left blank.
}
/**
* 當Kafka Connect成功發送poll()的記錄到Kafka后,呼叫此方法回傳已發送成功的記錄,具體的實作可以從SourceRecord中提取位移資訊
* @param record 已成功發送的記錄
* @param metadata Kafka Broker的元資料
* @throws InterruptedException
*/
public void commitRecord(SourceRecord record, RecordMetadata metadata)
throws InterruptedException {
// by default, just call other method for backwards compatibility
commitRecord(record);
}
}
從上面的代碼,我們可以看出,Task才是真正與資料源和Kafka Connect互動的物件:
List<SourceRecord> poll():Task把資料捕獲后存進一個集合中,如queue,Kafka Connect呼叫poll()方法從集合中彈出記錄發送到Kafka,commitRecord(SourceRecord record, RecordMetadata metadata):成功把記錄發送到Kafka后,Kafka Connect呼叫commitRecord()方法回傳已被成功發送的記錄物件,一般的實作會從record獲取位移資訊,注意,這個位移不是Kafka消費的offset,而是Task讀取資料源的進度資訊,例如,PostgreSQL Connector獲取的是WAL的LSN,commit(): 一般這個方法會把commitRecord()方法獲取的記錄的位移資訊發布到Kafka進行持久化,
3 Kafka Connect的運行模式
Kafka Connect支持單機(standalone)和分布式(distributed)兩種部署方式,
3.1 standalone
一個Kafka Connect的行程負責運行所有的Connector和Task,在生產環境并不建議使用,
3.2 distributed
distributed模式為Kafka Connect提供了可擴展性和自動容錯能力,多個擁有相同group.id的Kafka Connect行程組成了集群,其中作為leader的worker負責Connector和Task的分配,保證Connector和Task平均分配到各worker上運行,
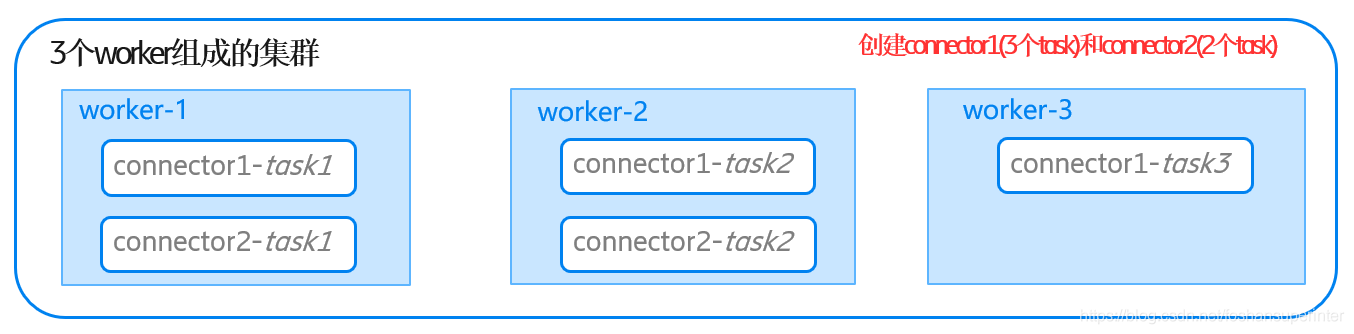
上圖展示了,向一個擁有3個worker的Kafka Connect集群創建2個Connector,1個Connector有3個Task,另外一個Connector有2個Task,Connector和Task的分配情況,
4 集群管理
Kafka Connect 使用了Kafka的組管理協議保證集群的高可用性,集群的管理程序跟Kafka Consumer集群的rebalance相似,區別在Kafka Consumer的leader負責分配partition,而Kafka Connect集群的leader則負責分配Connector和Task,
以下情況都會導致Connector和Task重新分配(rebalance):
- 當Connector剛被創建的時候
- 當Connector被洗掉的時候
- 當有新的worker加入集群,它會想coordinator發送join request,從而觸發rebalance,
- 當有worker正常退出集群,它會向coordinator發送leave request,從而觸發rebalance,
- 當coordinator檢測到有worker行程崩潰,會通過心跳告訴其他worker重新發送join request,
下面通過一個例子演示Kafka Connect是如何保證集群的高可用性的,
Group1集群有3個workers運行著connector1和connector2,各有3個tasks,各worker跟被選為coordinator的broker通過心跳協議保持通訊,
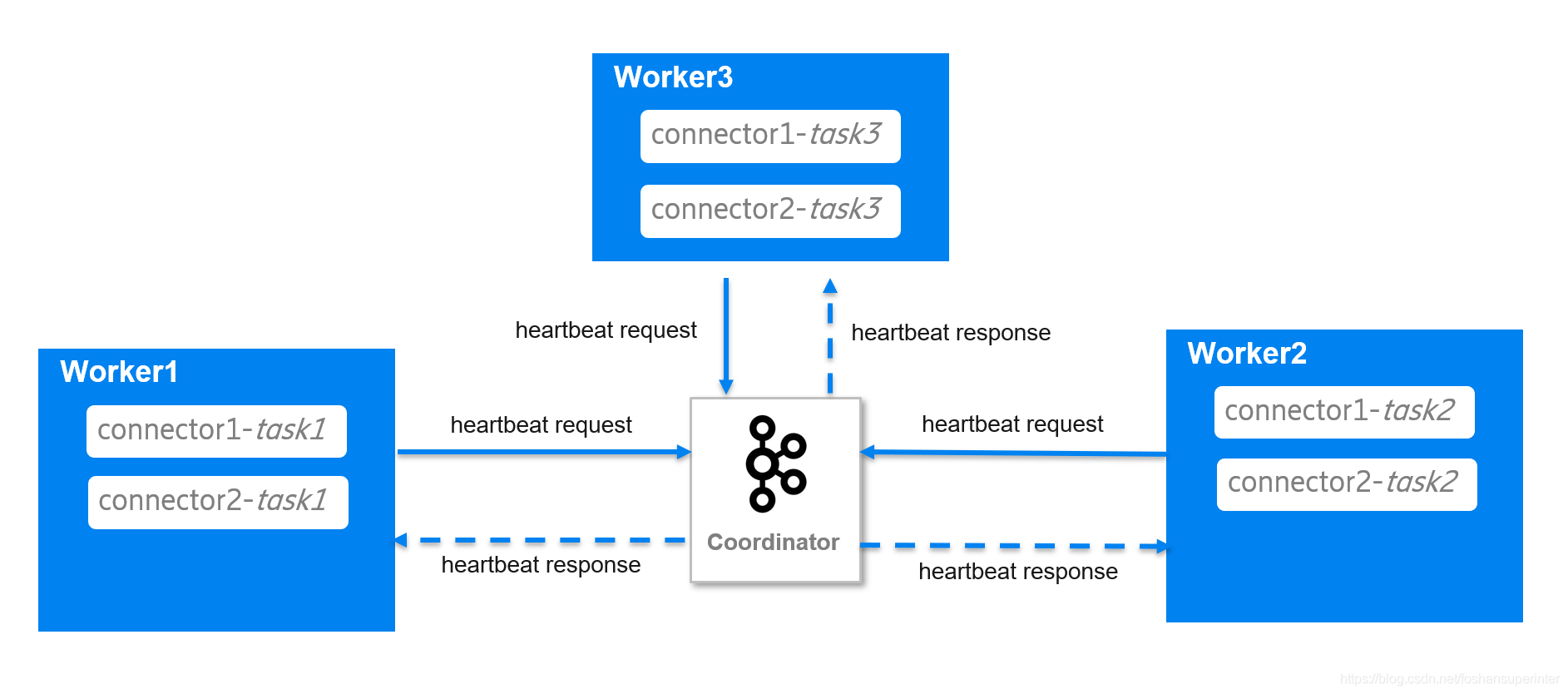
現在worker3由于某些原因崩潰了
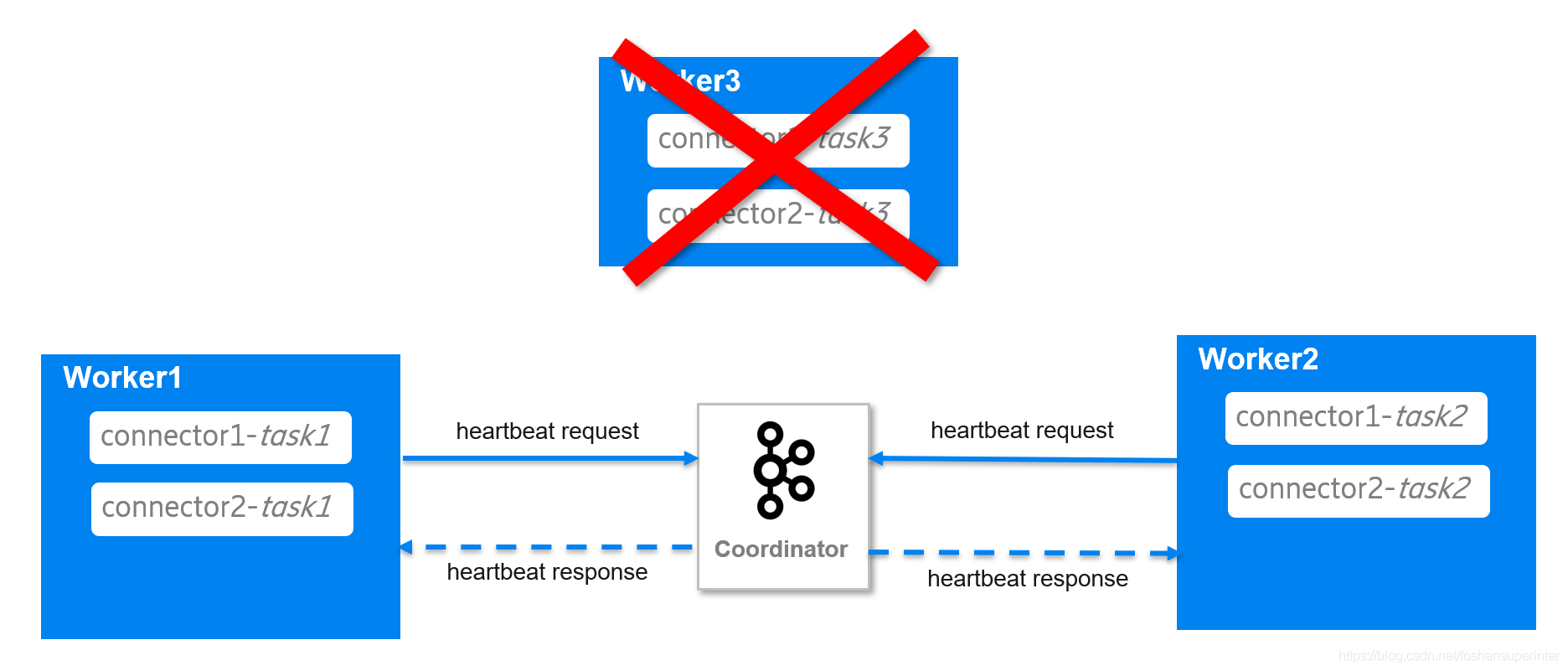
Coordinator在檢測到worker3崩潰后,在回應worker1和worker2的心跳資訊中,包含了要求它們重新入組的資訊,
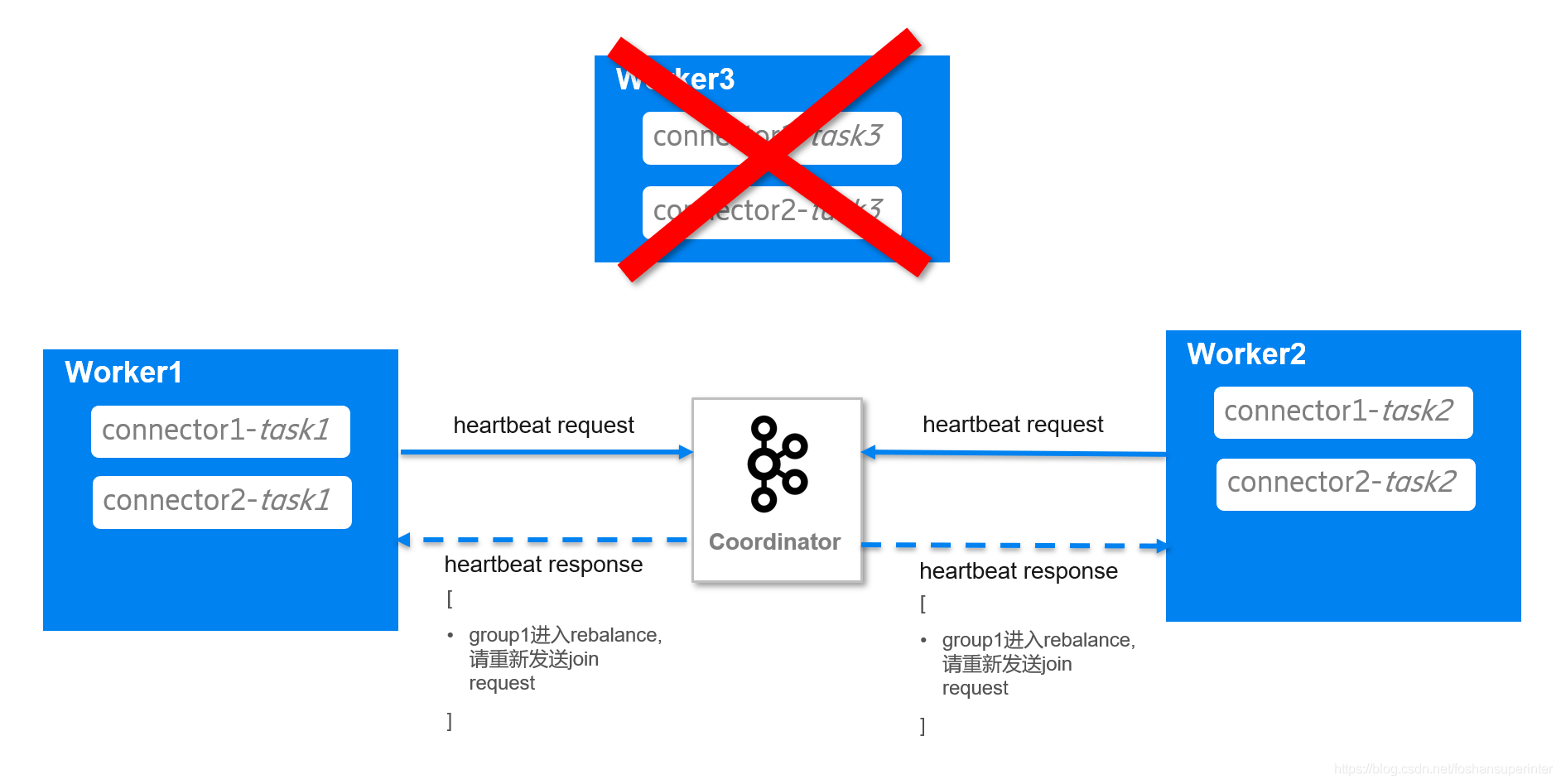
于是worker1和worker2重新發送入組請求,并在請求中帶上各自正在負責的Connector和Task情況,
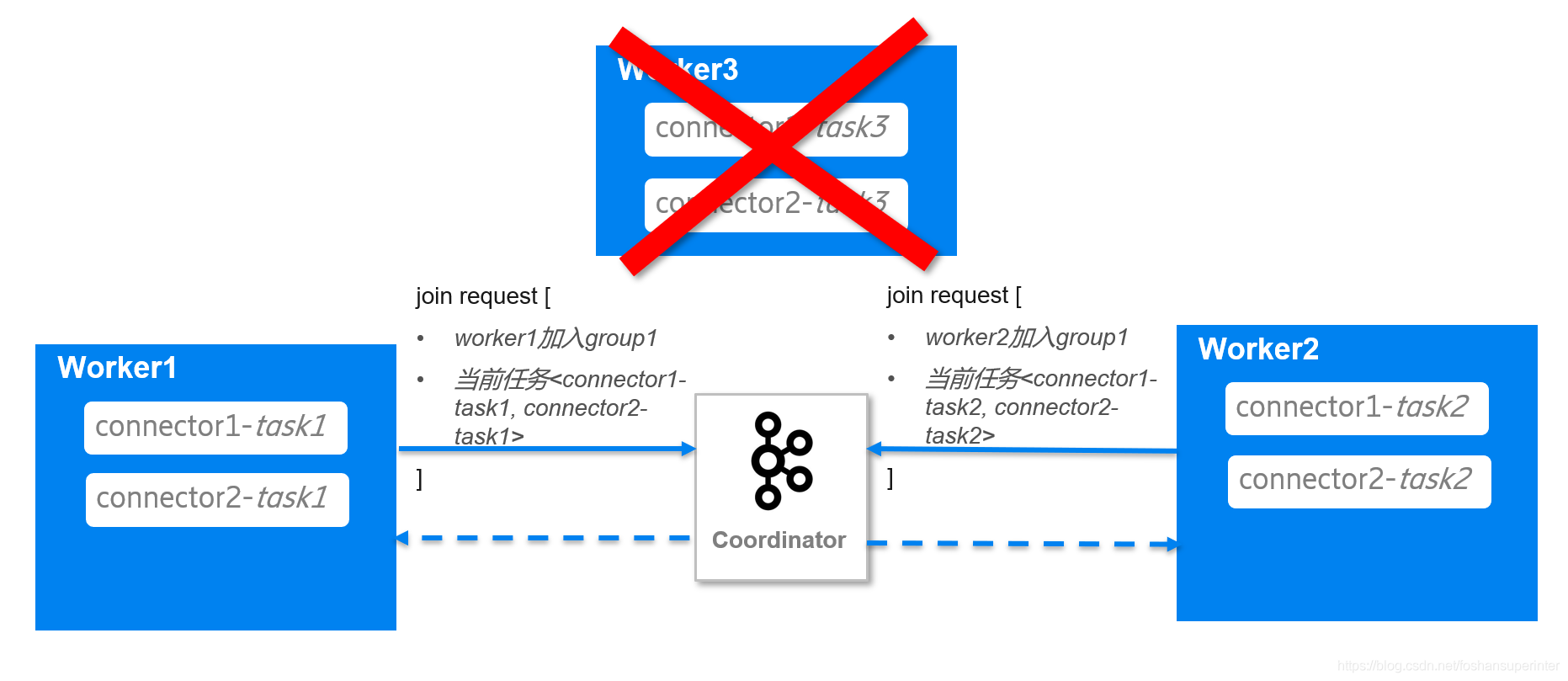
Coordinator收到worker1和worker2的入組資訊后,把worker1選為leader,并告訴worker1已成功入組及worker1和worker2正在運行的Connector和Task情況;通知worker2已經入組,
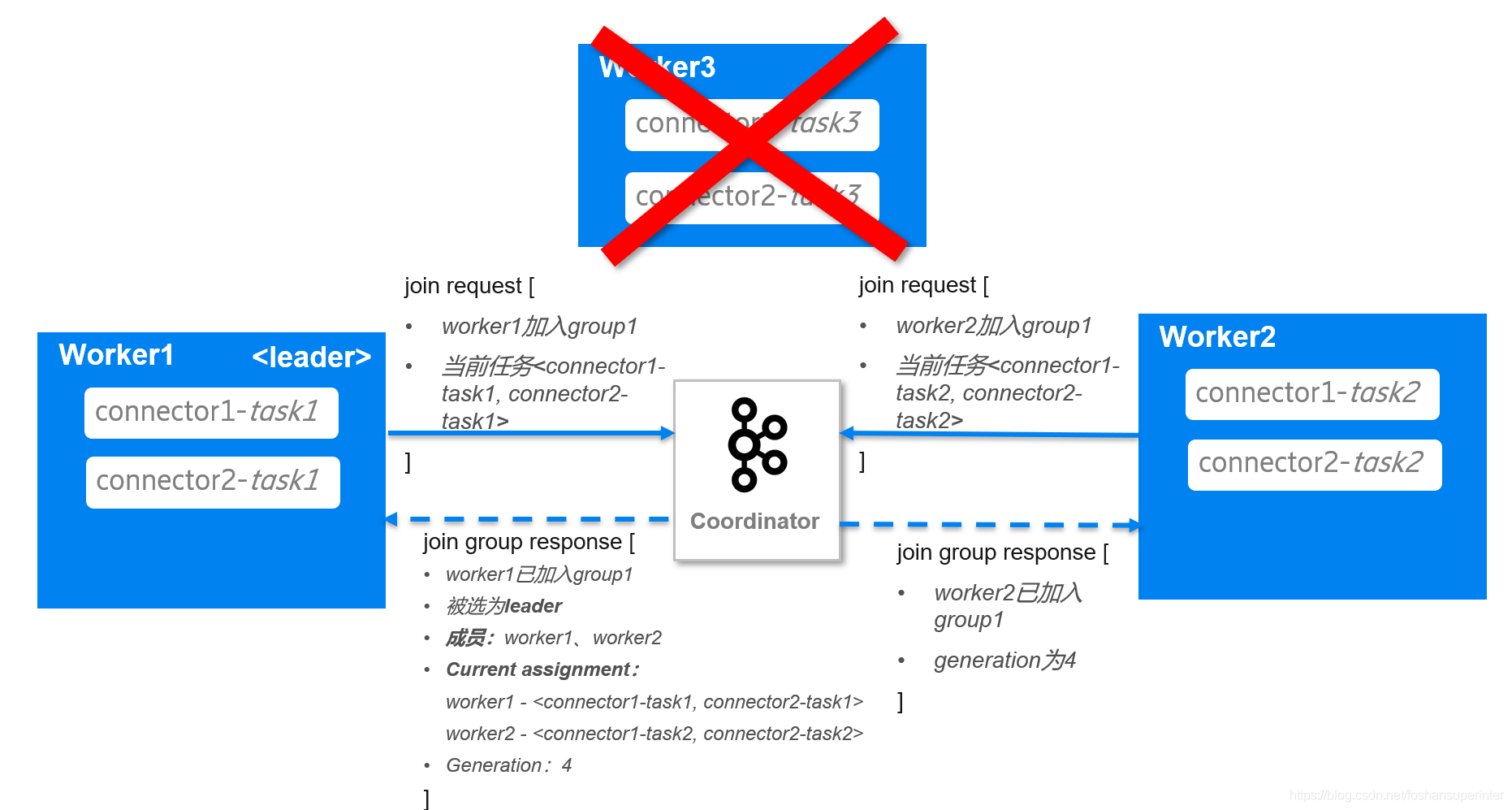
worker1會對比當前Connector和Task運行情況,發現connector1-task3和connector2-task沒有被運行,于是在sync group的請求中告訴Coordinator把connector1-task3分配給worker1,connector2-task3分配給worker2,
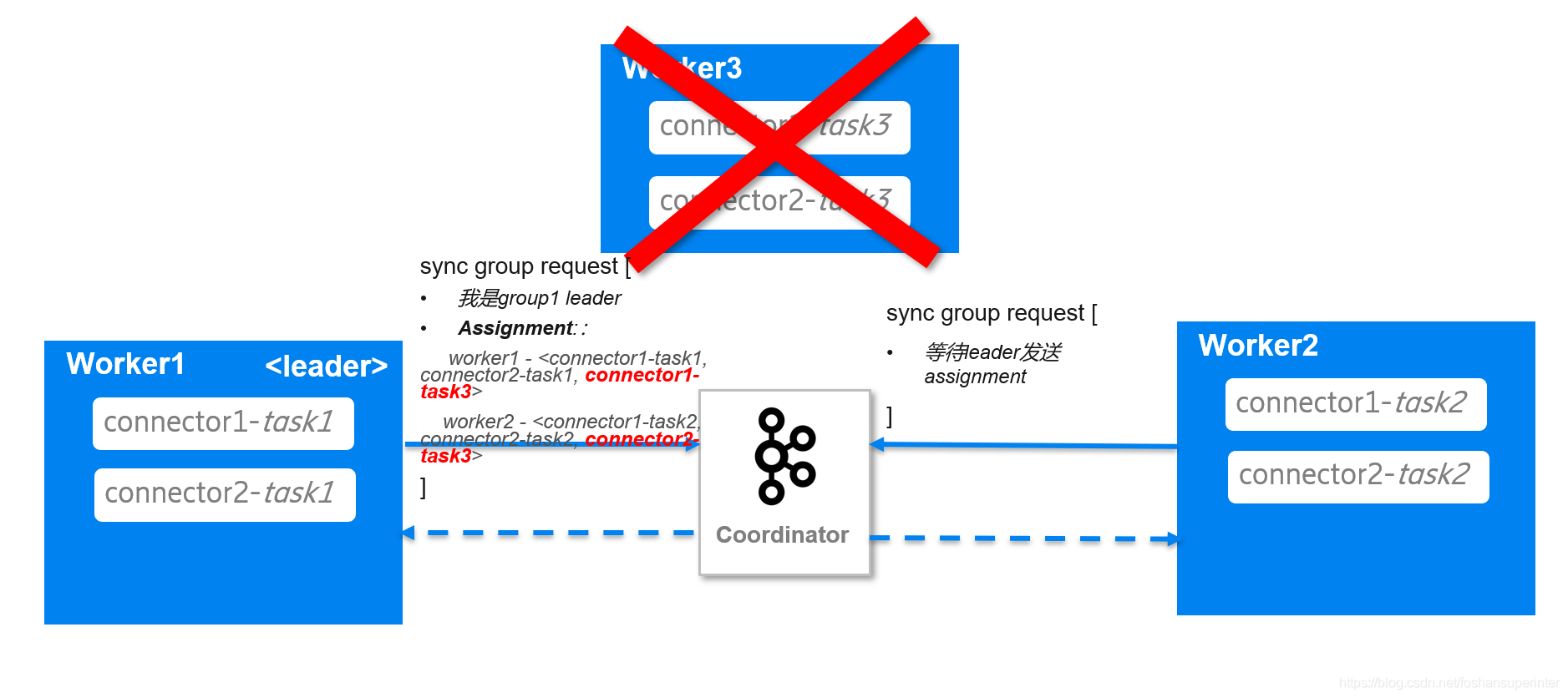
Coordinator收到leader的sync group請求后,提取請求中的分配結果,分別發給worker1和worker2,
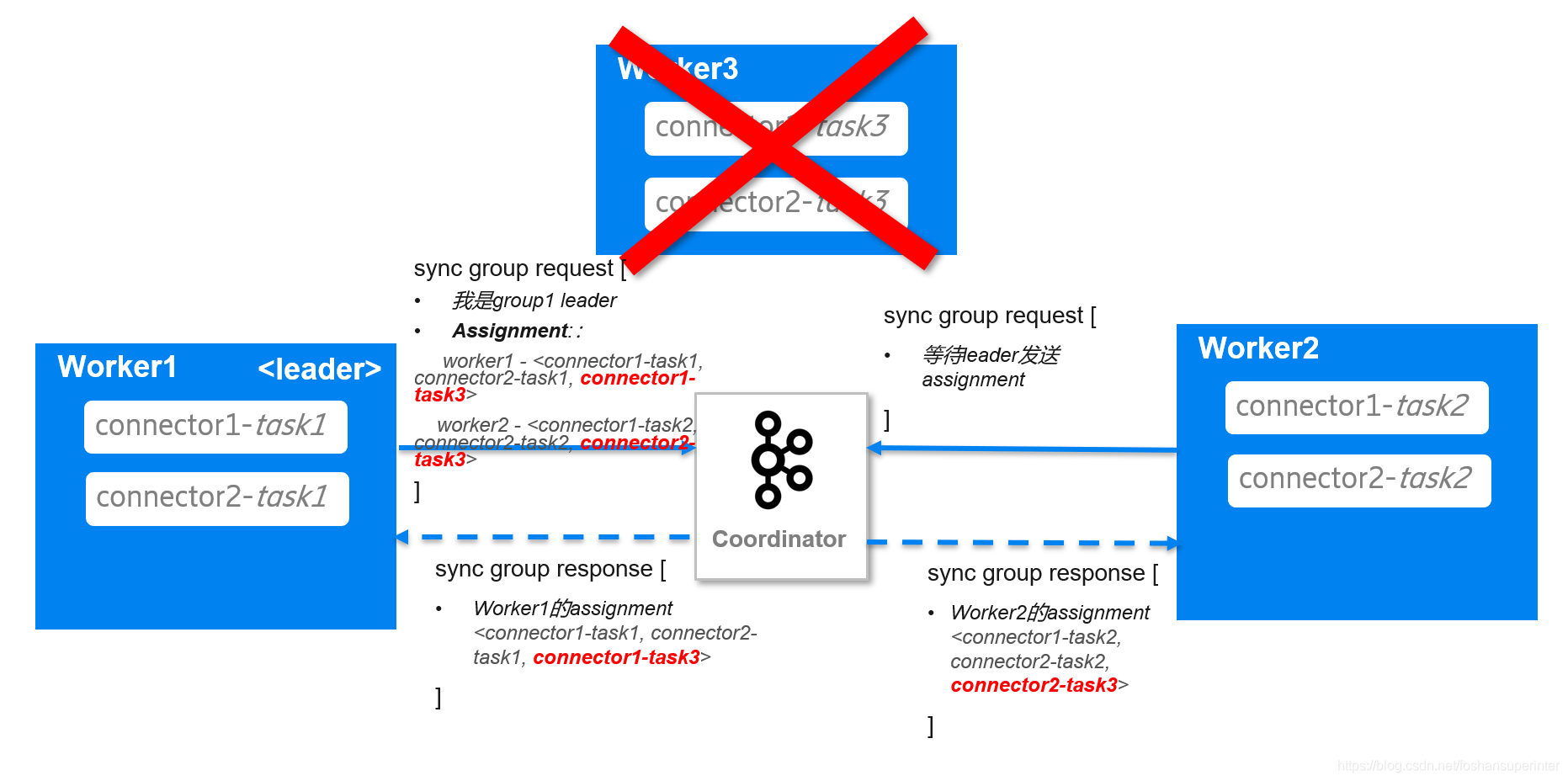
最后worker1發覺connector1-task3未運行,于是就運行connector1-task3了,同樣worker2發覺connector2-task3未運行,便運行它,
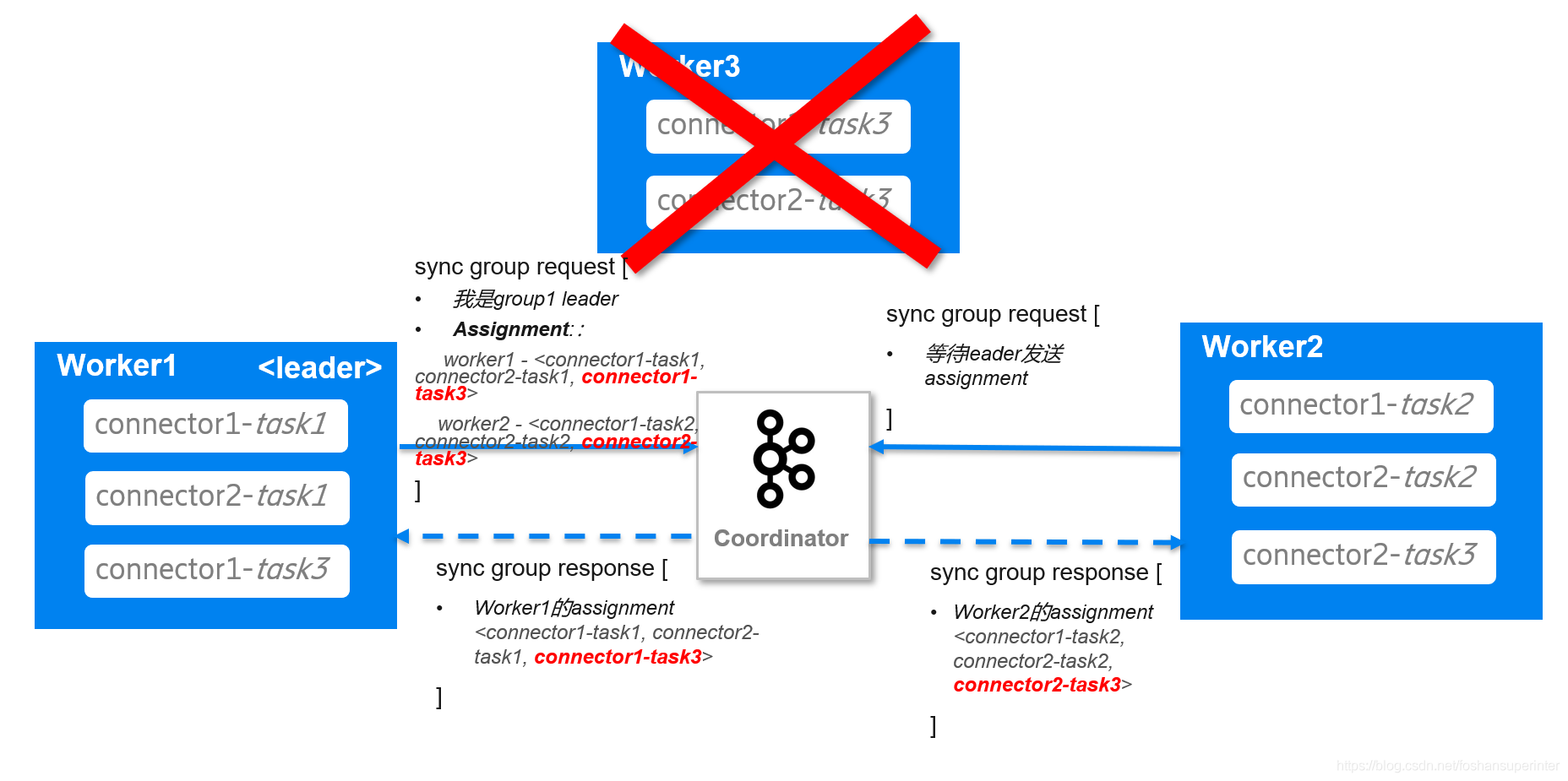
通過上面的例子,我們知道了,Kafka Connect是利用了Kafka的組管理協議保證集群的高可用性,這與Kafka Consumer集群分配Partition是非常類似的,在以后的章節,我們會嘗試分析PostgreSQL Connector的代碼,看看它是如何把PostgreSQL和Kafka Connect串聯起來的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/233540.html
標籤:其他