關于深度學習下目標檢測入門那點事
- 你需要知道的學前班知識
- 邊界框(Bounding Box)
- 交并比(IOU)
- 非極大值抑制(NMS)
- 評價引數
- 精確率(Precision)
- 召回率(Recall)
- P-R(Precision-Recall )曲線
- AP(Average Precision)與mAP(mean Average Precision)
- 準確率(Accuracy)
- 什么是目標檢測?
- 影像分類與目標檢測
- 檢測網路結構
- 檢測網路發展史
- 單階段與兩階段網路
- Anchor
- 如何學習一個新的檢測網路?
首先,如果你看到這篇博客,恭喜你,大概率你已經加入并成為了我們實驗室的一員,預祝你往后的科研生活豐富且逸趣橫生,
一個好的實驗室科研氛圍需要所有人一起努力,雖然說寫博客會耗費一些額外的時間,但為了更好地傳承、方便學習新的知識,我們開通了這個CSDN賬號,而這也是我們的第一篇博客,同時希望這個作業能夠一直堅持下去,往后還要依靠諸位,提前謝過,
寫自2020/12/10
你需要知道的學前班知識
如果你對目標檢測已經了然于胸,那這篇博客建議直接跳過,
如果你對目標檢測的基礎知識了如指掌,那First Part建議直接跳過,
如果你對深度學習網路一點都不了解,那這篇博客也建議先跳過,
邊界框(Bounding Box)
顧名思義,如果你看過一些目標檢測后的結果,你肯定會看到物體周圍都會圍有一個小框,這便是最終得到的檢測(Detection Result)框,當然,除了檢測框之外,還有真值(Ground Truth)框與預測(Predicted)框,這三種框本質上都可以被稱為Bounding Box(簡稱bbox),因為它都是為了表示物體位置資訊而生成的邊界框,首先,每個目標都會有一個表示它準確位置資訊的真值框,之后我們的網路在訓練程序中會根據真值框等資訊進行學習從而生成無數的預測框,最后,網路會層層篩選計算輸出最終的結果——檢測框,
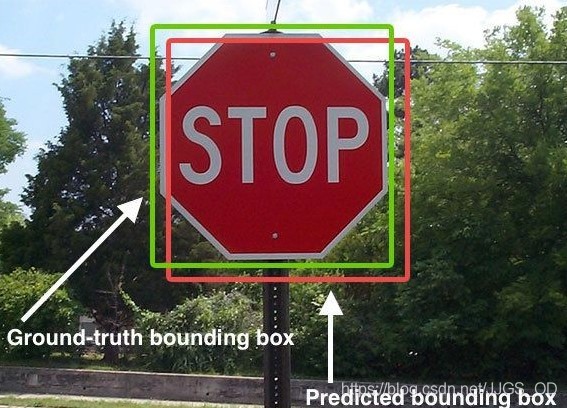
通常情況下,我們會將真值框直接稱為Ground Truth(簡稱GT),將經過網路預測所得出的邊界框(即Pred BBox)稱之為BBox,最終的檢測結果框稱為Detection Result(簡稱DT),如下圖中,綠色的框即為GT BBox,紅色的框則Pred BBox(圖源網路),
交并比(IOU)
在明確了BBox的概念之后,IOU便很好理解了,它其實就是一個用來篩選預測BBox衡量指標,話不多說,直接上圖(圖源網路),
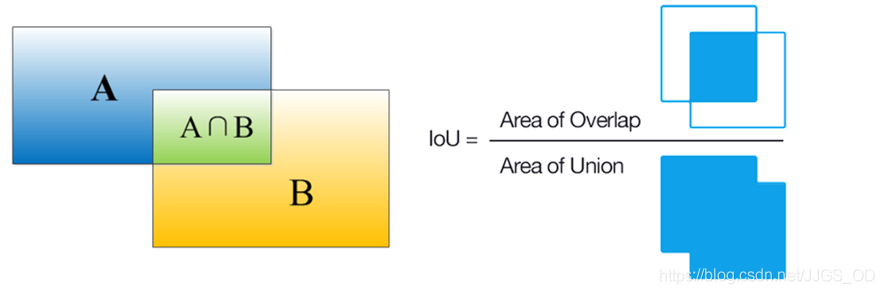
簡單點說,就是GT BBox與Pred BBox交集的面積 / 二者并集的面積,這個要是再不清楚就真的過分了啊,
非極大值抑制(NMS)
在學習目標檢測初期時候,我個人覺得這個概念相比于前面肯定還是有那么一點拗口的,不過理解了之后你會發現其實也就soso,它其實就是篩選我們預測框的一個方法,
這里我不打算再自己講述一遍了,因為博客的初衷也只是分享自己學習程序中的資料與心得,既然可以直接站在巨人的肩膀上,又何苦自己耗時耗力重新寫一遍呢是吧,前人栽樹后人乘涼嘛,
NMS概念
關于NMS解釋詳細的博客有很多,我這里粘貼其中一篇的地址在這里,如果還有問題歡迎私聊我,
評價引數
終于來到我們的重頭戲了,這一部分絕對可以算是我們學前班的畢業考試級別了,看懂不是最重要的,記住才是最重要的,像我就經常會被梁師兄提問,然后回答得磕磕絆絆記不清,還得你們惠師兄救場,哎,沒辦法,誰讓我這么菜呢,可千萬別像我學習啊,
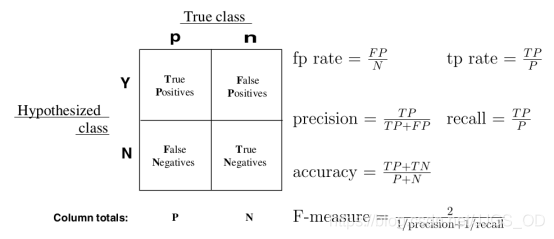
在學習評價引數指標之前,你需要先知道——
| 標簽 | 正例 (預測) | 負例(預測) |
|---|---|---|
| 正例(真實) | TP | FN |
| 負例(真實) | FP | TN |
記憶的話其實很簡單,第一個字母表示檢測正確與否,第二個字母表示預測目標結果為正樣本還是負樣本,然后進行排列組合就好,簡單解釋一下便是這樣(正樣本飛機,負樣本大雁):
TP:正樣本被正確識別為正樣本(飛機的圖片被正確的識別成了飛機)
TN:負樣本被正確識別為負樣本(大雁的圖片沒有被識別出來,系統正確地認為它們是大雁)
FP:負樣本被錯誤識別為正樣本(大雁的圖片被錯誤地識別成了飛機)
FN:正樣本被錯誤識別為負樣本(飛機的圖片沒有被識別出來,系統錯誤地認為它們是大雁)
在了解了TP、FP、TN、FN之后,我們便可以開始學習下面的引數含義了,
精確率(Precision)
Precision = TP/(TP+FP)
即識別出的正例目標中,包含識別正確的樣本所占的比例,
該怎么記憶呢?你可以這樣理解,精確精確,什么是精確,精確首先得是結果判斷為正確的,所以精確統計的就只是屬于識別結果為正樣本的那一部分,但凡我們識別結果為負樣本的全部不管,這樣就能和后面的準確率區分開了,
或者還有一種理解方式,就是我們最后的指標是要統計錯檢,這個便是我們的精確率,在檢出的所有結果中看看有多少是正確的,那么計算方式便顯而易見了,
召回率(Recall)
Recall = TP/(TP+FN)
即識別正確的正例目標占真實所有正例目標的比例,
這個又該怎么記憶呢?召回召回,什么叫召回,就是指原本為正樣本的資料有多少被我們正確檢測出來的,看看有多少真實目標被我們漏檢了的,這便是召回率,
P-R(Precision-Recall )曲線
P-R曲線顧名思義,是由Precision和Recal繪制的曲線,反應的是Precision和Recal之間的關系,我們通過改變識別閾值,使得系統依次能夠識別前K張圖片,閾值的變化同時會導致Precision與Recall值發生變化,從而得到不同多組的Precision與Recall值,從而繪制出曲線,
用以下檢測結果資料舉個例子(圖源網路):
比如閾值0.9,只有第一個樣本被我判斷為正例,那么我的Precision就是100%,但是Recall就是10%,閾值0.1,所有樣本都被我判斷為正例,Recall是100%,Precision就是50%,多次更改閾值之后,我們便可以將得到的Precision與Recall值繪制成下圖(圖源網路),


如果一個分類器的性能比較好,那么它應該有如下的表現:在Recall值增長的同時,Precision的值保持在一個很高的水平,而性能比較差的分類器可能會損失很多Precision值才能換來Recall值的提高,通常情況下,文章中都會使用Precision-recall曲線,來顯示出分類器在Precision與Recall之間的權衡,
AP(Average Precision)與mAP(mean Average Precision)
AP即某一類別全部影像中的平均精確度,這樣說其實很空,所以需要一個準確的計算方式,那就是Precision-recall 曲線下面的面積,通常來說一個越好的分類器,AP值越高,
mAP是對全部類別求平均AP值,其實就加和然后除以類別總數,得到的就是mAP的值,是不是很簡單,mAP的大小一定在[0,1]區間,越大越好,同時該指標是目標檢測演算法中最重要的一個,
一般情況下,單一目標我們會用到AP指標,多個目標時我們會用到mAP指標,
準確率(Accuracy)
Accuracy = (TP+TN)/ALL
即分對的樣本數除以所有的樣本數 ,
準確率一般用來評估模型的全域準確程度,不能包含太多資訊,無法全面評價一個模型性能,
最后,放一張總結的圖在這里(圖源網路)
什么是目標檢測?
目標檢測有多容易,誰看誰知道,
—— 魯迅
影像分類與目標檢測
按照我學習深度學習的程序,一開始接觸的便是分類網路,所以再介紹檢測網路之前,我覺得如果和分類網路做一個比較能夠好的幫助大家理解,
其實,分類的原理是輸入一張圖片,經過其中卷積、激活、池化等相關層,最后加入全連接層達到分類概率的效果,而對于目標檢測來說就不僅僅是分類這樣簡單的一個圖片輸出一個結果,而且還需要輸出圖片中目標的位置資訊,
說白了,目標檢測就是不僅要知道目標是什么,還要通過設計網路找到目標在哪,
所以,分類網路一定是目標檢測不可或缺的一部分,我們通常也將目標檢測網路中分類網路的部分稱之為骨干網路(Backbone),下面這張圖更好的說明了從分類到檢測的遞進關系(圖源網路),
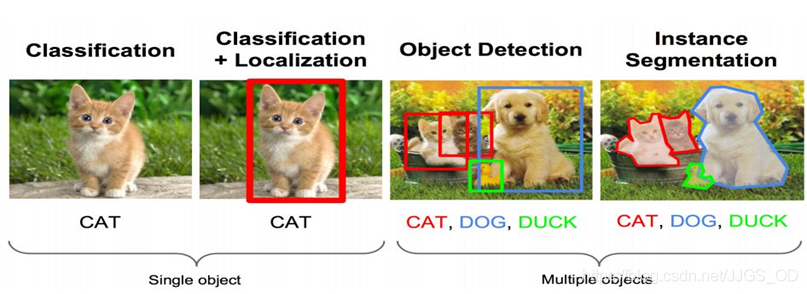 相比于影像分類網路,目標檢測網路的輸出是非結構化的,也就是說,它的輸出具有很強的不確定性,舉個例子,影像分類任務的輸入也是一張影像,輸出為一個標簽/類別,代表著這張圖的分類,因此分類任務的輸出是結構化的,有且僅有一個標簽;而目標檢測的輸出是影像中的所有目標(類別+位置),影像中到底有多少個目標是不確定的,這一特點非常重要,也正因為這一特點,目標檢測的性能度量方法要比影像分類任務復雜得多,
相比于影像分類網路,目標檢測網路的輸出是非結構化的,也就是說,它的輸出具有很強的不確定性,舉個例子,影像分類任務的輸入也是一張影像,輸出為一個標簽/類別,代表著這張圖的分類,因此分類任務的輸出是結構化的,有且僅有一個標簽;而目標檢測的輸出是影像中的所有目標(類別+位置),影像中到底有多少個目標是不確定的,這一特點非常重要,也正因為這一特點,目標檢測的性能度量方法要比影像分類任務復雜得多,
檢測網路結構
通常來說,一個目標檢測網路都可以被分為三個部分,
Detector = Backbone + Neck + Head
Backbone:上文已經提過,負責從影像中提取出些必要的特征資訊,
Neck:接在Backbone后面,負責更好地融合/提取Backbone所給出的Feature,從而提高網路的性能,
Head:其余后續的網路負責從這些特征中檢測目標的位置和類別,
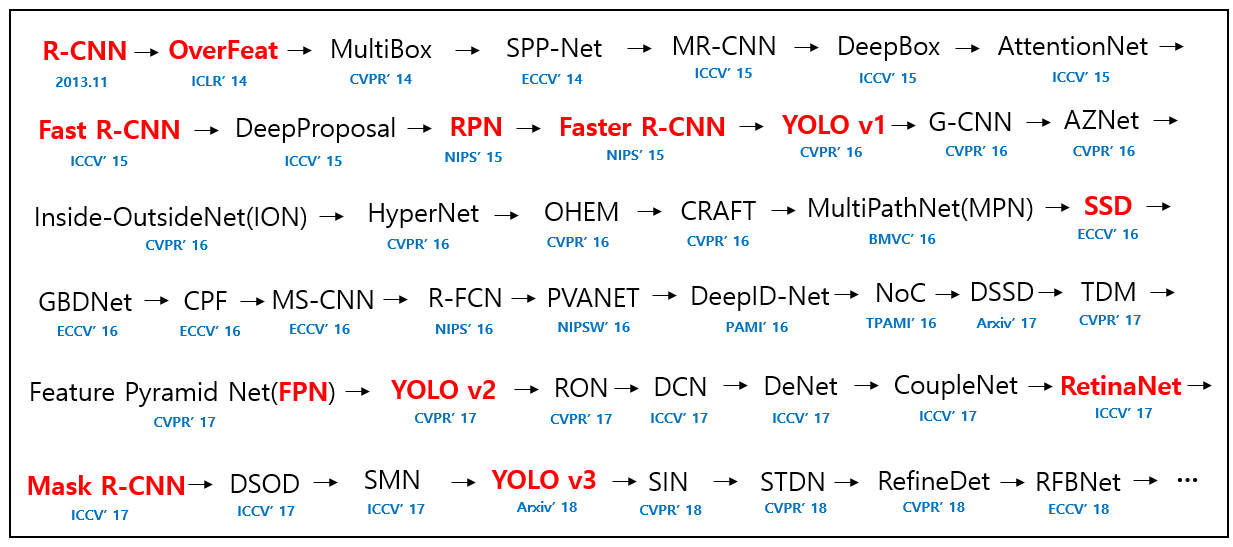
檢測網路發展史
其中紅色標注的為極其經典的網路(圖源論文:《Deep Learning for Generic Object Dection:A Survey》)
單階段與兩階段網路
| 單階段網路 | 兩階段網路 |
|---|---|
| 速度快,精度低 | 速度慢,精度高 |
Two-stage網路的第一個stage相當于先拿一個One-stage網路來做一次前景后景(目標與背景)的Classification + detection,這一程序被稱為候選區域網路(Region Proposals Network),這樣做的好處有可以選擇性的挑選樣本使得正負樣本更加均衡,然后再對候選區域分類和其位置精修,
One-stage網路則是用其他代替了Region Proposal階段,直接產生物體的類別概率和位置坐標值,經過單次檢測即可直接得到最終的檢測結果,因此有著更快的檢測速度,但面臨著正負樣本不均衡與精度不高等問題,
Anchor
在學習目標檢測網路程序中你一定不會對這個詞陌生,那么它究竟是什么,它到底是怎么樣生成的,它到底是個點還是個框?我找到一篇很好的講解放在這里,
Anchor的概念
如何學習一個新的檢測網路?
對于我這樣一個初學者來說,其實這個問題真的琢磨了很久,因為一開始的時候會覺得直接看英語原版論文更加生澀難懂,所以會在CSDN或者某乎上看別人總結好的中文講解,可是很多人的總結都是左一榔頭右一棒槌,導致一開始學習走了不少的彎路,后來慢慢的我總結了一條學習思路,可當我直接看原論文學習時候發現其實論文就是按照這條思路講解的……可能你們不會和我一樣蠢,但我還是先寫下來防患于未然,同時,其他師兄們可能還有他們的獨家學習秘訣,之后我也會讓他們補充在這里,作為這一篇博客最后的部分,希望能有助于你的目標檢測開啟之路事半功倍,
一般來說,學一個目標檢測網路分為以下三個步驟,
第一步:看網路結構
第二步:看檢測程序
第三步:看訓練方法
了解一個網路結構能夠更好地知道模塊直接的關聯,再根據每一個模塊的作用去學習網路的檢測程序,這便是一篇論文的主要思想,知道了這些之后再去學習網路的訓練方法,例如網路的損失函式,對正負樣本的處理等等,最后,作者通常會列出他的實驗程序,以及與其他網路的性能對比,可以更好的幫你復現網路與深入了解其他網路,
好了,關于深度學習目標檢測網路的基礎知識到這里就差不多結束了,如果還有遺漏或錯誤的地方,歡迎提醒以便我后期修改,或者你們直接登錄這個賬號修改就好,有什么問題或建議也可以直接和我說,我是鴿子王,下一次不一定什么時候再見,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/234935.html
標籤:其他
下一篇:ospf簡單實驗