回首資料平臺建設心路,探索資料架構新方向
- 一、引言
- 二、對平臺的簡單認識
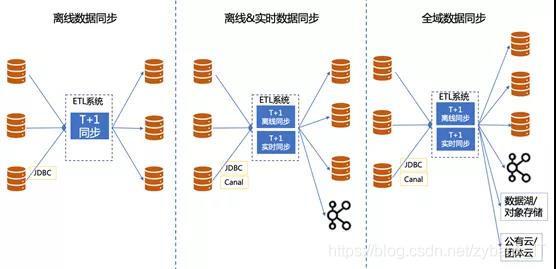
- (一)關于資料集成
- (二)更好的離線計算
- (三)離線&實時&AI
- 三、平臺發展新機遇
- 四、平臺建設挑戰
- (一)資料開發全鏈路
- (二)資料“超市”建設
- (三)換種角度看產品
- (四)建設資料聯邦
- 五、平臺未來展望
一、引言
本人錢包里有幾百塊一直沒有花出去的現金,在錢包中睡了大概有幾個月,不是我這幾個月沒花錢,而是因為這幾個月身邊結婚的少了,禮金——現金于我的最大使用場景,尤其今年新冠肺炎疫情的發生,培養了人們諸多新型消費習慣,無接觸購物、直播帶貨、社區團購等新渠道、新服務不斷涌現,隨著寬帶基礎設施的完善、5G時代的到來,在線娛樂、在線教育、在線醫療、短視頻直播等接受度越來越高,但現金支付的場景越來越少,幾乎日常生活中全部的支付場景已經線上化,數字化的時代已經悄然來臨,作為一個大資料從業者,我主要從事著資料平臺開發的作業,大資料平臺該如何建設和發展的問題經常會讓我陷入沉思,這里從個人角度出發,分享我對資料平臺與資料架構的淺薄觀點,
二、對平臺的簡單認識
(一)關于資料集成
資料集成指的是將多種、多樣的資料進行匯聚的一種行為,大資料中我們常用ETL來進行更加詳細的表達這種行為,ETL是每個大資料平臺不可或缺的一部分,宗旨一般都是為企業提供穩定、可靠、安全的資料傳輸服務,多年前以DataX為代表的離線資料同步工具已經具備了多源異構資料同步能力,而近年來離線存盤體系并沒有發生大面積的更迭,所以如果一個ETL產品的定位是離線資料同步,那經過這幾年的沉淀和發展其產品應該已經足夠成熟,
但是技術的推陳出新總是讓人措手不及,當前階段新的業務需求和下游技術的發展都對更具時效性的ETL提出了訴求,比如需要目標端對接更多管道類大資料組件(如:Kafka、Pulsar等)以及源頭端需要適配更多接資料庫及組件(如:Canal、Databus、Maxwell、Debezium等),而下一階段將資料“入湖上云”更是一個觸手可及的市場,可以肯定的是各大云廠商會帶著自己的遷移工具到企業中去,而一個橫向的、跨云的資料同步服務工具也會有市場空間的,綜上來講,一個離線資料同步產品如果想快速回應新的訴求并抓住下一階段的市場機會,一次系統架構調整相比較于在現有產品上添磚加瓦應該是更具有意義的,或者說一個全新的技術體系產品也可能是更好的選擇,
(二)更好的離線計算
根據專家估計,隨著近年來資料規模呈幾何級數高速增長,到2030年需要處理的資料量會大大超過處理能力的上限,從而導致大量資料因無法或來不及處理,而處于未被利用、價值不明的狀態,這些資料被稱為“暗資料”,由此引起的整個網路、存盤、計算、傳輸、結構等方面的變革我們暫且不展開,本文我們將討論內容限定為企業內部,那么從谷歌發布大資料的三篇文論至今,大資料的存盤和計算的技術已經很成熟,現有的計算框架足以應對當前的計算需求,但,也只是應對,企業級計算能力的前提下,如何更好的將金融、證券、保險等行業的跑批耗時大幅度的壓縮,我認為可以從以下三方面入手:
-
打造存算分離的架構
通過將資料的存盤和計算分離,存算分離能夠有效避免服務器的浪費、降低服務器更新頻率、提高可擴展性、提高資源利用率,才能做到動態的向計算密集型作業分配更多的算力(算力的潮汐),最終成為降低企業IT成本的直接、有效手段, -
優化存盤
在資料方面通過對現有資料進行去重、拉鏈、生命周期管理、冷熱資料分離、清理外圍資料等方面的優化,降低存盤清理,提高資料價值密度,在存盤架構方面通過對資料塊大小調整、小檔案管理、元資料管理等一些方法,有效降低NameNode請求壓力,從而大幅的提高NameNode在線率, -
磁盤故障感知
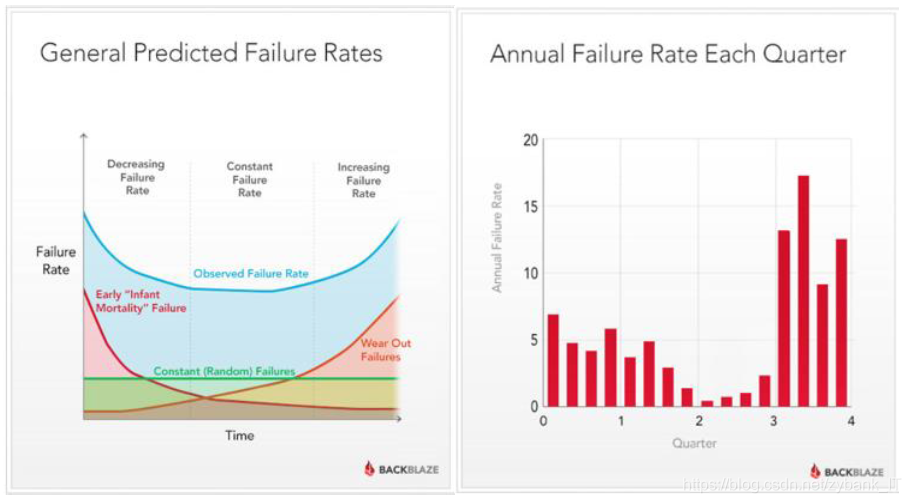
根據上面“硬碟驅動器故障浴盆曲線”(左圖)及“前四年硬碟驅動器故障率”(右圖)可以看出,硬碟故障是影響跑批時效性的一個定時炸彈,不管近年來的磁盤質量有多大提升,也只不過是延長了故障爆發的時間而已,所以在這樣的情況下,做到磁盤故障感知尤其的重要,我認為磁盤故障處理與感知有下面三個階段:- 現階段:發現故障->隔離壞盤->磁盤換新->資料平衡
- 下一階段:預測->重點觀察->隔離壞盤->磁盤換新->資料平衡,本階段的難點作業在于“預測”,我認為可以根據磁盤的生產時間、上架時間、良品率、同型被更換數量、近期R/W速度波動……等等指標進行建模,實作磁盤的故障預測,并根據實際結果對模型調優,
- 最終階段:通過存算分離的架構,將計算任務上收而非當前的下放,接下來將資料上云,進一步釋放本地存盤壓力,解放資料運維作業,專注云上計算,
(三)離線&實時&AI
有一句話是:“實時計算不會取代離線計算”,談“替換”需要太大的勇氣,更何況在一些傳統資料架構企業或業績導向企業,實時計算更多的是在扮演一些體驗優化、離線計算功能補充的角色,當前的應用深度和企業資料架構并不利于使實時計算成為一個業務驅動引擎,而在諸如滴滴、順豐等互聯網與物流企業中,他們對實時計算有天然的需求,便捷的實時資料獲取,使得實時計算平臺可以實作大量的低延時業務的需求;阿里巴巴內部已經基于實時計算引擎(Flink)改造出了一個通用演算法平臺(Alink),可以看到的是在不久的未來,離線、實時、AI一定是朝著融合的方向發展,這里我們可以先看一下目前實時計算的架構圖,如下:
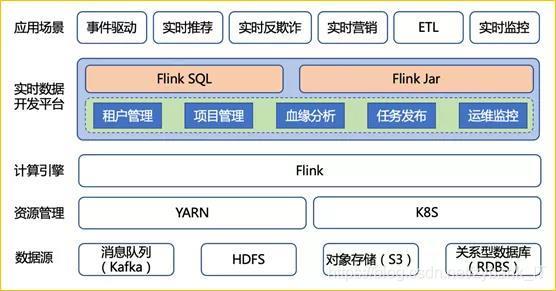
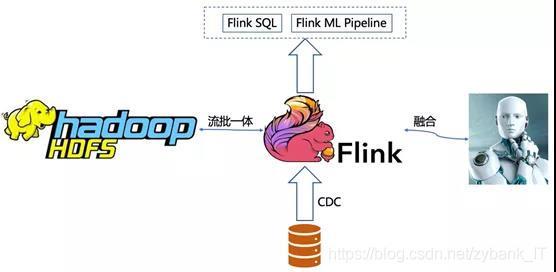
相對低成本的實時資料獲取是實時計算發展的基礎,得益于Flink技術的繁榮發展,未來的實時計算將會成為一座橋梁,一邊連接傳統的離線計算一邊探索與AI的融合,簡單羅列如下:
- 基于Hive元資料且特定場景下的流批一體;
- 實時計算支持特征工程、在線學習、在線預測等 AI 場景;
- 擺脫中間件以來,不斷完善的CDC能力;
- Flink中更強大的復雜事件處理(CEP)服務;
三、平臺發展新機遇
如今塞班、黑莓紛紛退出歷史舞臺,三星手機的銷量也今非昔比,這么多年技術領域不變的是一直在變化,而在變的只是變化周期和速度,2C或靠平臺運營來實作公司主要收入的商業模式更容易收到技術革新的沖擊或帶動,在數字化轉型的大趨勢下,以推動企業現有架構變革或希望通過新技術、新思路來豐富業務增長點的探索顯得迫切而有必要,所以在渠道拓展方面對新技術的嗅探、新產品的范訓、新的對外合作模式的創新等,都是一些具體的方式;在技術方面進行探索,最大化的通過技術的變革來創新業務模式、升華服務質量,比如:
- 推進HTAP的研究和探索,更快捷的支撐實時決策場景;
- 擁抱云計算,推進海量資料的敏感欄位加密技術,實作將密態資料或非敏感資料上云,降低企業內部存盤、運維成本,實作更快的基于云的彈性計算;
- 通過邊緣計算,集合內部大資料平臺和云上資源,對IoT、客戶、設備等資料進行計算和模型預測;
- 豐富平臺產品矩陣,隨著5G、云計算、邊緣計算的到來,首先對現有系統進行云原生改造;其次積極探索新技術可能拉動的產品真空,豐富產品矩陣;
- 加快聯邦技術落地,通過資料聯邦與聯邦學習,降低資料存盤和使用成本,擴大模型訓練集,提高訓練效果;
- 推進流批一體落地,借助Hive的統一元資料與Flink的流批一體技術,在資料湖的基礎上加快流批一體技術的落地,推動全面實時化;
四、平臺建設挑戰
建設并非因為要建設而建設,建設是為了更好的解決需求、完成目標,而平臺的不斷演進可以更好的服務現有需求并開創新的可能,
(一)資料開發全鏈路
對大資料平臺而言,資料的抽取、存盤、加工、管理、開放運營等是大資料的核心能力,資料開發平臺等系統的投產極大程度降低了資料的加工、使用門檻,滿足了基本的資料研發需要,但是在元資料管理、資料研發規范性、資料質量把關、安全審計等治理方面仍然存在較大的改進空間,通過更接下來的平臺建設進一步提升易用性、提升資料穩定性、提高資料質量和資料安全、增強資料調度能力,進而在資料融合加工基礎上進一步的完善資料治理體系,從而實作更好的資料開放共享,以便更快捷的支撐應用系統的建設和成長顯得尤為重要,
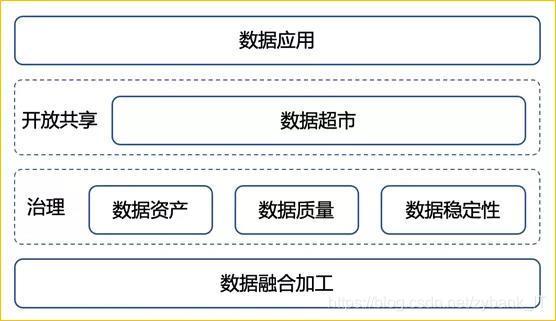
(二)資料“超市”建設
資料能說話、資料助決策,大企業中對資料的訴求和使用好比家庭購物買菜,菜市場和超市都可以買菜,但是菜市場具有占地面積大、對周圍交通及環境影響大的特點,而超市則顯得比較靈活和便捷,能夠更好的適應城區,目前很多業務場景下對資料的使用好像在菜市場買菜,需要接觸每個攤位主(資料負責人/提數人員/……),分別溝通來買菜(提數)并逐個結算,而超市則提供了磁區、分類、分級的產品供應,并實作了自由選擇、統一結算的服務,并且超市往往對顧客隔離了材料加工、包裝(資料加工)的程序,更好的購物環境、更優質的服務、更快捷的體驗,所以建設好我們的資料超市不但是對我們資料的梳理和分類,實作資料運營也將會把我們的資料服務能力提升到一個新的臺階,給資料使用人員一種更好的使用體驗,
(三)換種角度看產品
-
打造云產品
軟體運行的環境從主機到虛擬機再到發展到容器,企業降本的訴求一直反壓著技術進行著不斷的變革,云的出現不僅改變了傳統IT行業的構架,更是加速了傳統行業的轉型和升級,節約了傳統企業的IT投入,更是為Paas、SaaS提供了極大的便利,積極擁抱云原生技術,深入推進企業上云,加速企業數字化改造, -
用產品的眼光看產品
傳統的以小組為單位的產品布局提供了很明確的產品責任人和發展模式,其產品的發展方向和速度往往由上層和內部因素共同決定,而面對飛速發展的技術變革、跨產品發展需求等,此模式比較容易形成“畫地為牢”的局限性,反而不容易做到快速搶占新產品市場、實作跨界產品需求,所以如果我們反問自己,什么是對這個產品最好的?哪個方向的迭代對產品更好?本產品是否要集成其他小組已有產品的功能?本產品是否具有市場競爭力以及前瞻性?
互聯網下的產品往往是“跨界”的,此類產品往往不會過于聚焦于單一的某個功能,但往往是以某個核心功能為中心的上下游功能共同組成了本產品的功能矩陣,實作產品即決方案,提升產品的市場競爭力,降低產品在企業落地難度,
(四)建設資料聯邦
“眾人拾柴火焰高”,以一個企業內部的資料積累來進行用戶行為屬性判斷、標簽加工等事情還是略顯薄弱,如果能夠實作通過獲取外部資料、三方行為資料的使用,通過全天候、多維度的行為分析來最終判定一個主體的屬性和標簽,將會有利于更好的對主體把控,通過資料上云,實作行業云內資料的共享,實作本地資料與云上資料的聯邦,外部產品矩陣、外部資料聯邦等等,目的就是對內部提供更加優質的服務,實作更多、更好的產品范訓、更精確的客戶定位、賦能業務、最終實作更好的實作數字化轉型,
五、平臺未來展望
中原銀行經過4年的大資料平臺建設,已經從原始的人海戰術實作了大資料系統的平臺化,這很大程度上要歸功于我們在大資料平臺建設的輕裝上陣和極有魄力的領導力,回顧過去展望未來,大資料平臺的演進之路大致如下:

在2020年末2021伊始的時間節點,結合業界發展趨勢,我認為下一代的大資料平臺發展將會形成人工智能和大資料的雙引擎局面,對人工智能而言則是需要探索與大資料的融合,于大資料而言,除了與人工智能的融合外也要快速實作新一代的資料存盤、計算、使用等方面的變革,基于這個想法大資料平臺建設架構大致如下:
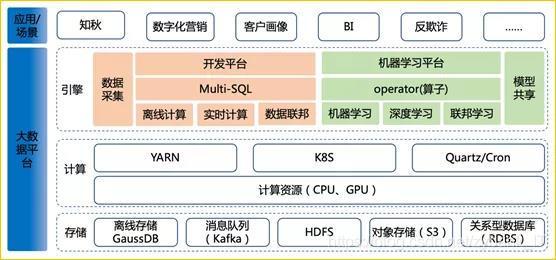
最后,希望大資料平臺每年都有更好的呈現,每一次陣痛的變革都是為了堅守最原始的初心,
作者:思甜,資料銀行部
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/236054.html
標籤:其他
下一篇:react路由嵌套路由及路由傳參