小白可參考 大佬請欣賞
想爬取的內容
在廣州港務局網站有每天的出海航道船舶總計劃,爬取2019年每天的計劃資料,
需要用到的庫
沒安裝過的可以 win+r 輸入 cmd,之后輸入:pip install 庫名,等待安裝即可,
爬取串列中的url
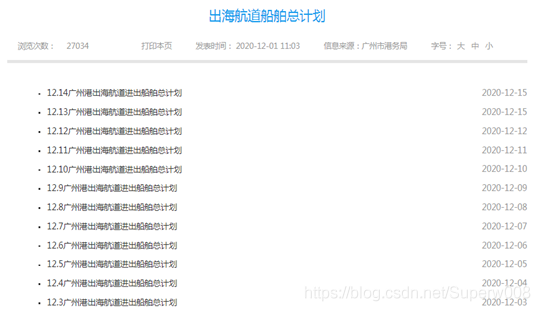
右鍵查看網頁源代碼,發現計劃表存在一個鏈接中,

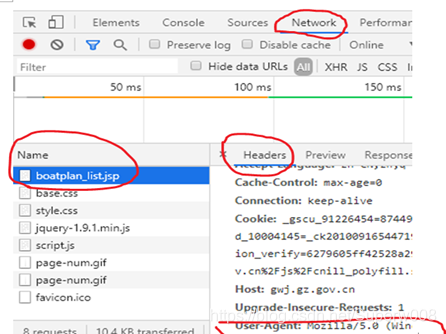
點擊該鏈接,進入網頁,找網頁的Headers,否則爬取內容為空,Headers在網頁按F12,之后按F5重繪,找到Network下的引數,需要Headers下的User-Agent,復制粘貼即可,
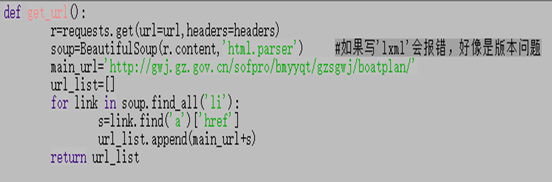
分析網頁源代碼中的結構,每天的計劃的網頁鏈接都是在‘http://gwj.gz.gov.cn/sofpro/bmyyqt/gzsgwj/boatplan/’之后加上 " li " 標簽下的 " a " 的 " href " 后面所跟的鏈接,

得到每天詳細船舶計劃的鏈接,代碼如下:
翻頁爬取
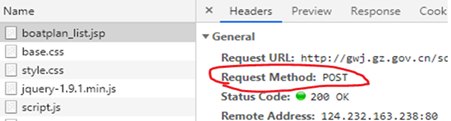
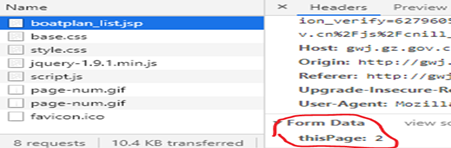
由于需要爬取的內容分布在多頁上,因此需要進行翻頁,點擊“下一頁”之后發現網頁的鏈接沒有變,查了一下說是基于js的翻頁(咱也不懂,但這不重要),觀察第二頁網頁的Network引數,發現請求方式變成了post,并且多了一個Form Data引數:thisPage:2,再去翻第3頁,發現thisPage:3,那就可以通過這個來實作翻頁,
設定一個字典
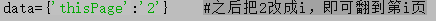
之后修改函式get_url中的第一行,其他不需要變
讀取內容并寫入csv檔案
觀察每一天調度總計劃的源代碼,發現所需要的資訊在<div class=’ boatplan-table-scroll’>的 " tr " 的 " td " 中,由于想將資料按月存盤,所以沒有將表頭寫入,全部爬取之后再在每個月的csv檔案中加title,

創建一個csv檔案

先找到 “ div class ”,再找到所有 “ tr ”,在每個 “ tr ” 中再找所有 “ td ”,將每個 “ td ” 下的內容寫入,

總代碼
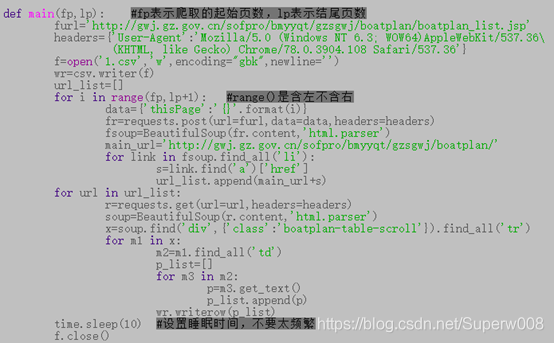
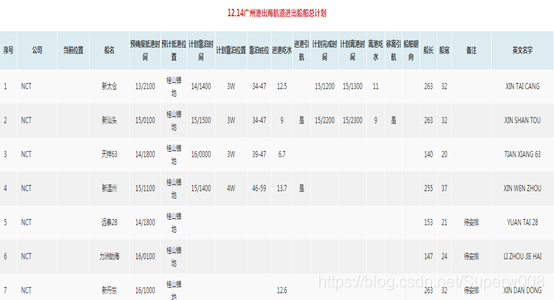
爬取的部分結果:

———————————結束啦——————————
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/236142.html
標籤:其他