C語言資料結構
文章目錄
- C語言資料結構
- 前言
- 1.時間復雜度和空間復雜度
- 1.1演算法效率的度量問題
- 1.2演算法時間復雜度
- 1.2.1常數階
- 1.2.2線性階
- 1.2.3平方階
- 1.2.4對數階
- 1.3常見的時間復雜度
- 1.3.1時間復雜度大小對比
- 1.4演算法的空間復雜度
- 2.線性表
- 2.1線性表的定義
- 2.2定義考題模擬
- 2.3常用函式的定義
- 2.3.1代碼示例:陣列實作線性表
- 2.3.2代碼示例:鏈表實作線性表
- 2.3.3代碼示例:實作線性表的并運算
- 3.堆疊
- 3.1堆疊的定義
- 3.2堆疊的順序存盤結構
- 3.2.1代碼示例:順序堆疊
- 3.3堆疊的鏈式存盤結構
- 3.3.1代碼示例:鏈式堆疊
- 4.佇列
- 4.1佇列的定義
- 4.2代碼示例:佇列的順序儲存結構
- 4.3代碼示例:佇列的鏈式儲存結構
- 5.字串
- 5.1字串的定義
- 5.2字串的比較
- 5.3代碼示例:字串的存盤結構
- 5.4代碼示例:比較倆字串是否一致
- 5.5代碼示例:倆字串是否匹配(是否為子串主串關系)
- 6.樹與二叉樹
- 6.1樹的定義
- 6.2基本術語
- 6.3樹的儲存結構
- 6.3.1雙親儲存結構
- 6.3.2孩子鏈存盤結構
- 6.3.3孩子兄弟鏈存盤結構
- 6.4二叉樹
- 6.4.1二叉樹的定義
- 6.4.1.1二叉樹和樹的區別
- 6.4.1.2滿二叉樹
- 6.4.1.3非空滿二叉樹
- 6.4.1.4非空完全二叉樹
- 6.4.2二叉樹的性質
- 6.4.3二叉樹的存盤結構
- 6.4.3.1二叉樹的順序存盤結構
- 6.4.3.2二叉樹的鏈式存盤結構
- 6.4.4二叉樹的遍歷
- 6.4.4.1先序遍歷
- 6.4.4.2中序遍歷
- 6.4.4.3后序遍歷
- 6.4.5代碼示例:二叉樹的運算實作
- 7.圖
- 7.1.圖的定義
- 7.2.圖的儲存結構
- 7.2.1鄰階矩陣(無向圖)
- 7.2.2鄰階矩陣(有向圖)
- 7.2.3鄰接矩陣(網)
- 7.2.4鄰接表(無向圖)
- 7.2.5鄰接表(有向圖)
- 7.2.6鄰接表(網)
- 7.2.7鄰接表和鄰接矩陣的代碼
- 7.3圖的遍歷
- 7.3.1深度優先遍歷
- 7.3.2廣度優先遍歷
- 7.3.3有向圖的遍歷代碼
前言
因為本人正在復習(預習)資料結構,所以本篇代碼并不保證完全正確,僅用作學習用途
1.時間復雜度和空間復雜度
1.1演算法效率的度量問題
接下來看一下這兩段代碼

- 第一種演算法執行了1+(n+1)+n=2n+2次,
- 第二種演算法,是1+1=2次
- 如果我們把回圈看做一個整體,忽略頭尾判斷的開銷,那么這兩個演算法其實就是n和1的差距,
接下來再看一個例子

- 這個例子中,回圈條件i從1到100,每次都要讓j回圈100次,如果非常較真的研究總共精確執行次數那是非常累的,
- 另一方面,我們研究演算法的復雜度,側重的是研究演算法隨著輸入規模擴大增長量的一個抽象,而不是精確地定位需要執行多少次,因為如果這樣的話我們就又得考慮回編譯器優化等問題,然后,然后就永遠也沒有然后了!
- 所以,對于剛才例子的演算法,我們可以果斷判定需要執行100^2次,
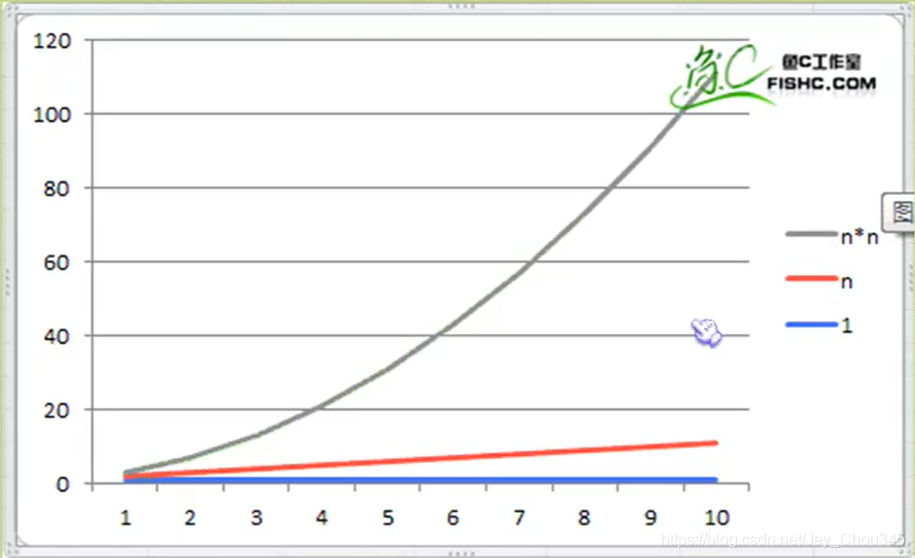
1.2演算法時間復雜度
演算法時間復雜度的定義:
在進行演算法分析時,陳述句總的執行次數T(n)是關于問題規模n的函式,進而分析T(n)隨n的變化情況并確定T(n)的數量級,演算法的時間復雜度,也就是演算法的時間量度記作:T(n)=0(f(n)),
它表示隨問題規模n的增大,演算法執行時間的增長率和f(n)的增長率相同,稱作演算法的漸近時間復雜度,簡稱為時間復雜度,其中f(n)是問題規模n的某個函式,
執行次數=>時間
這樣用大寫0()來體現演算法時間復雜度的記法,我們稱之為大0記法,
一般情況下,隨著輸入規模n的增大,T(n)增長最慢的演算法為最優演算法,
顯然,由此演算法時間復雜度的定義可知,
我們的三個求和演算法的時間復雜度分別為0(1),0(n),0(n^2), ( 1, n , n*n )
那么如何分析一個演算法的時間復雜度呢?
即如何推導大0階呢?我們給大家整理了以下攻略:
- 用常數1取代運行時間中的所有加法常數,在修改后的運行次數函式中, 只保留最高階項,
- 如果最高階項存在且不是1,則去除與這個項相乘的常數,
得到的最后結果就是大0階,
1.2.1常數階

0(8)? 這是初學者常常犯的錯誤,總認為有多少條陳述句就有多少,
分析下:
- 按照我們的概念“T(n)是關于問題規模n的函式”來說,這里大家表示對魚C的愛固然是好的,要支持的,要鼓勵的,要大力表彰的,但是,跟問題規模有關系嗎?沒有,跟問題規模的表親戚都沒關系!,所以我們記作0(1)就可以,
- 另外,如果按照攻略來,那就更簡單了,攻略第一條就說明了所有加法常數給他個0(1)即可,
1.2.2線性階

1.2.3平方階

n等于100, 也就是說外層回圈每執行一次,內層回圈就執行100次,那總共程式想要從這兩個回圈出來,需要執行100*100次, 也就是n的平方,所以這段代碼的時間復雜度為0(n^2),
那如果有三個這樣的嵌套回圈呢?
沒錯,那就是n^3啦,所以我們很容易總結得出,回圈的時間復雜度等于回圈體的復雜度乘以該回圈運行的次數,
注意:由于剛剛的執行回圈次數是一樣的,可以這么來算,但是如果不一樣呢?

分析下,
- 由于當i=0時,內回圈執行了n次,當i=1 時,內回圈則執行n-1次
- 當i=n-1時,內回圈執行1次,所以總的執行次數應該是:- n+(n-1)+(n-2)+…+1 = n(n+1)/2
大家還記得這個公式吧?恩恩,沒錯啦,就是搞死先生發明的演算法丫, - 那咱理解后可以繼續,n(n+1)/2 = n^2/2+n/2用我們推導大0的攻略,第一條忽略,因為沒有常數相加,第二條只保留最高項,所以n/2這項去掉,
- 第三條, 去除與最高項相乘的常數,最終得0(n^2),
1.2.4對數階

由于每次i*2之后,就舉例n更近一步,假設有x個2相乘后大于或等于n,則會退出回圈,
于是由2^x = n得到x = log(2)n,所以這個回圈的時間復雜度為0(logn),
1.3常見的時間復雜度
| 例子 | 時間復雜度 | 術語 |
|---|---|---|
| 5201314 | O(1) | 常數階 |
| 3n+4 | O(n) | 線性階 |
| 3n2+4n+5 | O(n2) | 平方階 |
| 3log(2)n+4 | O(logn) | 對數階 |
| 2n+3nlog(2)n+14 | O(nlogn) | nlogn階 |
| n3+2n2+4n+6 | O(n3) | 立方階 |
| 2n | O(2n) | 指數階 |
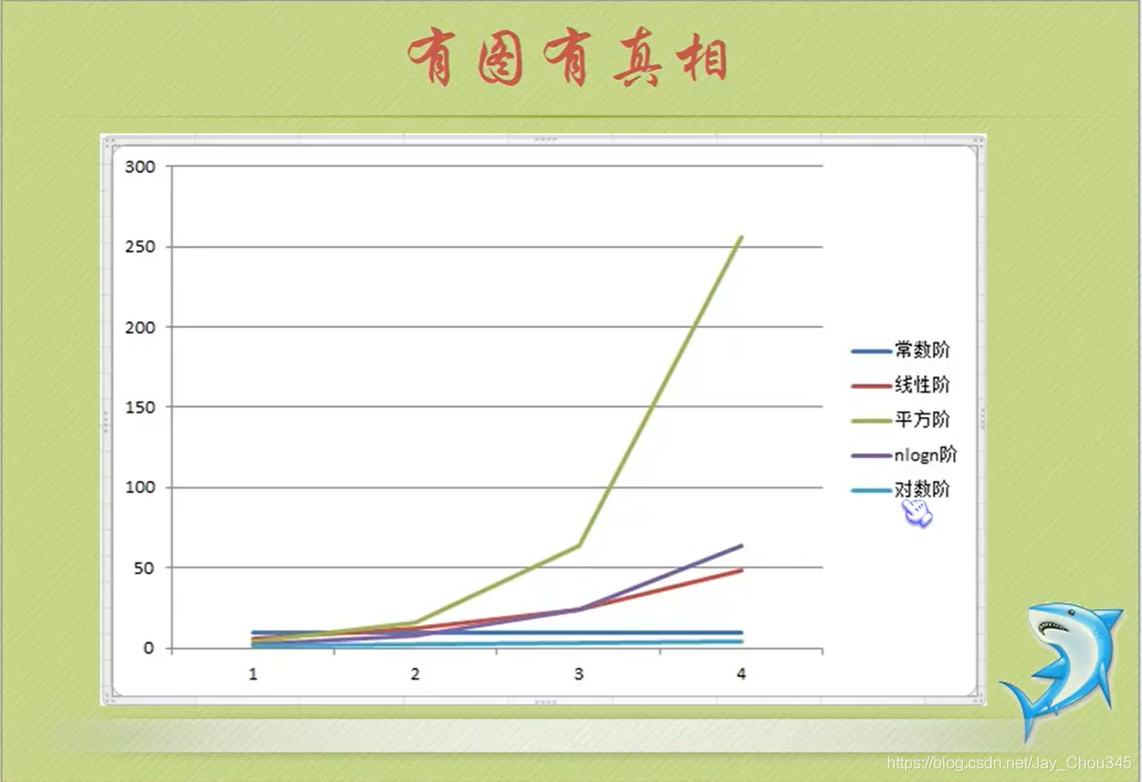
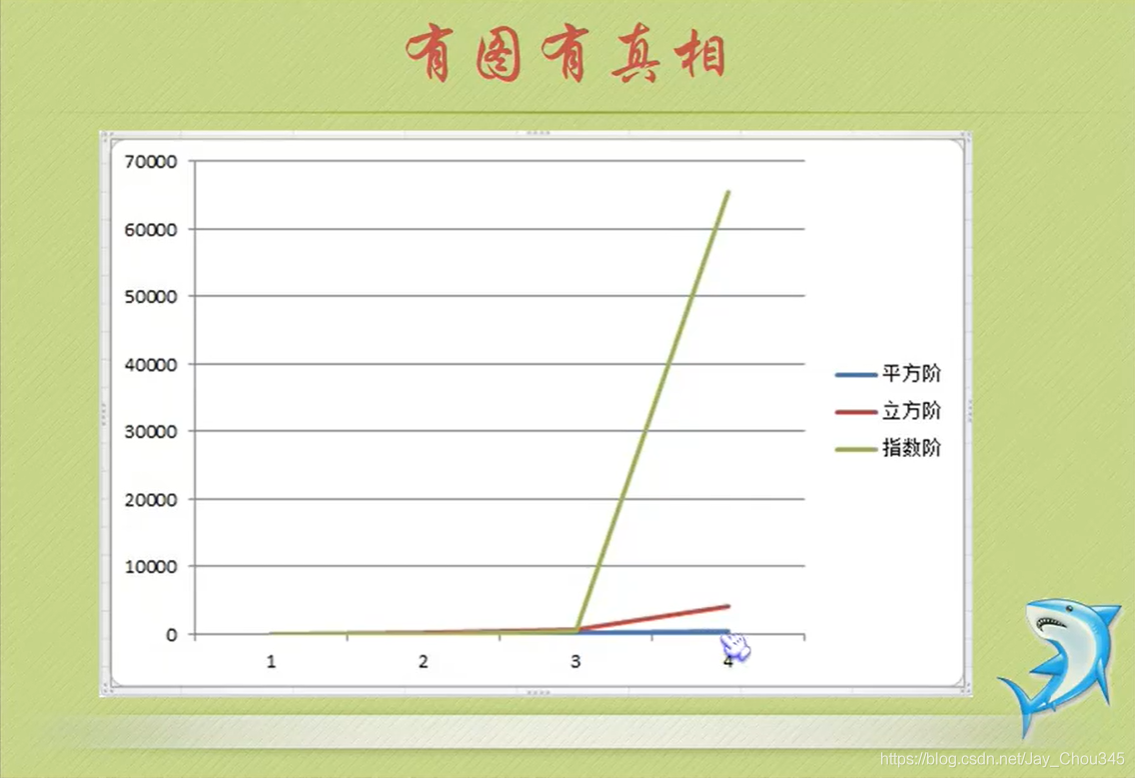
1.3.1時間復雜度大小對比
常用的時間復雜度所耗費的時間從小到大依次是
0(1) < 0(logn) < (n) < 0(nlogn) <0(n2) < 0(n3) < 0(2n) < 0(n!) <0(nn)
- 0(1),0(1ogn),0(n),0(n^2)我們前邊已經給大家舉例談過了,至于0(nlogn)我們將會在今后的
課程中介紹, - 而像0(n^3)之后的這些,由于n值的增大都會使得結果大得難以想象,我們沒必要去討論它們,
1.4演算法的空間復雜度
演算法的分析也是類似,我們查找一個有n個亂數字陣列中的某個數字,
最好的情況是第一個數字就是,那么演算法的時間復雜度為0(1),但也有可能這個數字就在最后一個位置,那么時間復雜度為0(n),
平均運行時間是期望的運行時間,最壞運行時間是一種保證,
在應用中,這是一種最重要的需求,通常除非特別指定,我們提到的運行時間都是最壞情況的運行時間,
- 通常,我們都是用時間復雜度”來指運行時間的需求,是用“空間復雜度”指空間需求,
- 當直接要讓我們求“復雜度”時,通常指的是時間復雜度,
- 顯然對時間復雜度的追求更是屬于演算法的潮流
2.線性表
2.1線性表的定義
線性表(List):
由零個或多個資料元素組成的有限序列,
這里需要強調幾個關鍵的地方:
- 首先它是一個序列, 也就是說元素之間是有個先來后到的,
- 若元素存在多個,則第一個元素無前驅,而最后一個元素無后繼,其他元素都有且只有一個前驅和后繼,
- 另外,線性表強調是有限的,事實上無論計算機發展到多強大,它所處理的元素都是有限的,
2.2定義考題模擬
請問公司的組織架構是否屬于線性關系?
分析:
一般公司的總經理管理幾個總監,每個總監管理幾個經理,每個經理都有各自的下屬和員工,
那這樣的組織架構是不是線性關系呢?
當然不是啦!
注意線性關系的條件是如果存在多個元素,則“第一個元素無前驅,而最后一個元素無后繼,其他元素都有且只有一個前驅和后繼,
那么班級里同學之間的友誼呢?
當然也不是,因為每個人都會跟許多同學建立純純的友誼關系,
好,再來一題,那如果是情侶間的愛情關系呢?哈,還是扯淡,這要是線性關系還哪里容得下第三者? !
最后一個問題,一個班級里的點名冊,是不是線性表?
是!!!
2.3常用函式的定義
- InitList(*L):初始化操作,建立一個空的線性表L,
- ListEmpty(L):判斷線性表是否為空表,若線性表為慷訓傳true,否則回傳false,
- ClearList(*L):將線性表清空, GetElem(L,i,*e):將線性表L中的第i個位置元素值回傳給e
- LocateElem(L,e):在線性表L中查找與給定值e相等的元素,如果查找成功,回傳該元素在表中序號表示成功;否則,回傳0表示失敗,
- ListInsert(*L,i,e):在線性表L中第i個位置插入新元素e,
- ListDelete(*L,i,*e):洗掉線性表L中第i個位置元素,并用e回傳其值,
- ListLength(L):回傳線性表L的元素個數,
2.3.1代碼示例:陣列實作線性表
#include<stdio.h>
#include<stdlib.h>
#define maxSize 100
typedef char DataType;
typedef struct node{
DataType data[maxSize];
int length;
}LinkNode;
//初始化
void initList(LinkNode &L){
L.length=0;
}
//創建
void CreatList(LinkNode &L,DataType a[],int n){
for(int i=0;i<n;i++){
L.data[L.length]=a[i];
L.length++;
}
}
//輸出
void DispList(LinkNode &L){
for(int i=0;i<L.length;i++){
printf("%c ",L.data[i]);
}
printf("\n\n");
}
//查找第i個元素的值
DataType GetElem(LinkNode &L,int i){
return L.data[i-1];
}
//查找位置
int FindLocation(LinkNode &L,DataType e){
for(int i=0;i<L.length;i++){
if(L.data[i]==e){
return ++i;
}
}
return -1;
}
//判斷空
bool EmptyList(LinkNode &L){
return (L.length==0);
}
//長度
int Length(LinkNode &L){
return L.length;
}
//指定位置插入
void Insert(LinkNode &L,int n,DataType e){
L.length++;
if(n<=L.length){
for(int i=L.length-1;i>=n-1;i--){
L.data[i+1]=L.data[i];
}
L.data[n-1]=e;
}
}
//指定位置洗掉
void Remove(LinkNode &L,int n){
for(int i=n-1;i<L.length-1;i++){
L.data[i]=L.data[i+1];
}
L.length--;
}
//清空
void ClearList(LinkNode &L){
L.length==0;
}
//正常添加
void addList(LinkNode &L,DataType e){
L.data[L.length]=e;
L.length++;
}
//主函式
int main(){
LinkNode L;
initList(L);
DataType a[]={'a','b','c','d'};
CreatList(L,a,4);
printf("輸出表:");
DispList(L);
printf("表的長度為%d\n\n",Length(L));
printf("表是否為空?:%s\n\n",EmptyList(L)?"表示空的":"表不是空的");
printf("第3個元素的值為%c\n\n",GetElem(L,3));
printf("b的位置是第%d個\n\n",FindLocation(L,'b'));
printf("在第三個位置插入t元素\n");
Insert(L,3,'t');
printf("插入完畢\n\n");
printf("輸出表:");
DispList(L);
printf("洗掉第4個元素\n");
Remove(L,4);
printf("輸出表:");
DispList(L);
printf("清空表");
ClearList(L);
}
2.3.2代碼示例:鏈表實作線性表
#include<stdio.h>
#include<stdlib.h>
#define maxSize 30
typedef int DataType;
typedef struct node{
DataType data;
struct node *next;
}CircNode;
//頭插法
void CreatListF(CircNode *&L,DataType a[],int n){
CircNode *s;
L=(CircNode *)malloc (sizeof (CircNode));
L->next=NULL;
for(int i=0;i<n;i++){
s=(CircNode *)malloc (sizeof (CircNode));
s->data=a[i];
s->next=L->next;
L->next=s;
}
}
//尾插法
void CreatListR(CircNode *&L,DataType a[],int n){
CircNode *s;
CircNode *r;//尾指標
L=(CircNode *)malloc (sizeof (CircNode));
r=L;
for(int i=0;i<n;i++){
s=(CircNode *)malloc (sizeof (CircNode));
s->data=a[i];
r->next=s;
r=s;
}
r->next=NULL;
}
//輸出
void DispList(CircNode *&L){
CircNode *p=L->next;
while(p!=NULL){
printf(" %d",p->data);
p=p->next;
}
printf("\n");
}
//查找第i個元素的值
bool GetElem(CircNode *L,int i,DataType &e){
CircNode *p=L;
int j=0;
while(j<i&&p!=NULL){
j++;
p=p->next;
}
if(p==NULL){
return false;
}else{
e=p->data;
return true;
}
}
bool Insert(CircNode *&L,int i,DataType e){
CircNode *p=L,*s;
int j=0;
while(j<i-1&&p!=NULL){
j++;
p=p->next;
}
if(p==NULL){
return false;
}else{
s=(CircNode *)malloc (sizeof (CircNode));
s->data=e;
s->next=p->next;
p->next=s;
}
}
bool EmptyList(CircNode *&L){
return (L->next==NULL);
}
int lenth(CircNode *&L){
int n=0;
CircNode *p=L->next;
while(p!=NULL){
n++;
p=p->next;
}
return n;
}
2.3.3代碼示例:實作線性表的并運算
#include<stdio.h>
#include<stdlib.h>
#define maxSize 100
typedef char DataType;
typedef struct node{
DataType data[maxSize];
int length;
}LinkNode;
//初始化
void initList(LinkNode &L){
L.length=0;
}
//創建
void CreatList(LinkNode &L,DataType a[],int n){
for(int i=0;i<n;i++){
L.data[L.length]=a[i];
L.length++;
}
}
//輸出
void DispList(LinkNode &L){
for(int i=0;i<L.length;i++){
printf("%c ",L.data[i]);
}
printf("\n\n");
}
//查找第i個元素的值
DataType GetElem(LinkNode &L,int i){
return L.data[i-1];
}
//查找位置
int FindLocation(LinkNode &L,DataType e){
for(int i=0;i<L.length;i++){
if(L.data[i]==e){
return ++i;
}
}
return -1;
}
//判斷空
bool EmptyList(LinkNode &L){
return (L.length==0);
}
//長度
int Length(LinkNode &L){
return L.length;
}
//指定位置插入
void Insert(LinkNode &L,int n,DataType e){
L.length++;
if(n<=L.length){
for(int i=L.length-1;i>=n-1;i--){
L.data[i+1]=L.data[i];
}
L.data[n-1]=e;
}
}
//指定位置洗掉
void Remove(LinkNode &L,int n){
for(int i=n-1;i<L.length-1;i++){
L.data[i]=L.data[i+1];
}
L.length--;
}
//清空
void ClearList(LinkNode &L){
L.length==0;
}
//正常添加
void addList(LinkNode &L,DataType e){
L.data[L.length]=e;
L.length++;
}
//并運算主函式
int main(){
LinkNode L1,L2,L3,L4;
initList(L1);
initList(L2);
initList(L3);
initList(L4);
int num=0;
DataType a1[]={'a','b','c','d','A'};
DataType a2[]={'A','B','C','D','a','b'};
CreatList(L1,a1,5);
CreatList(L2,a2,6);
printf("表L1的值為:");
DispList(L1);
printf("表L2的值為:");
DispList(L2);
for(int i=0;i<Length(L2);i++){
addList(L3,GetElem(L2,i+1));
}
for(int j=0;j<Length(L1);j++){
addList(L3,GetElem(L1,j+1));
}
printf("合并后的值為:");
DispList(L3);
for(int i=0;i<Length(L3);i++){
for(int j=0;j<Length(L3);j++){
if(GetElem(L3,j+1)==GetElem(L3,i+1)&&j!=i){
num++;
break;
}
}
if(num==0){
addList(L4,GetElem(L3,i+1));
}
num=0;
}
printf("實作了并運算之后的集合為:");
DispList(L4);
}
3.堆疊
3.1堆疊的定義
官方定義:堆疊(Stack)是一個后進先出(Lastin first out,LIFO) 的線性表,它要求只在表尾進行洗掉和插入操作,
小甲魚定義:所謂的堆疊,其實也就是一個特殊的線性表(順序表、鏈表),
但是它在操作上有一些特殊的要求和限制:
- 堆疊的元素必須“后進先出”,
- 堆疊的操作只能在這個線性表的表尾進行,
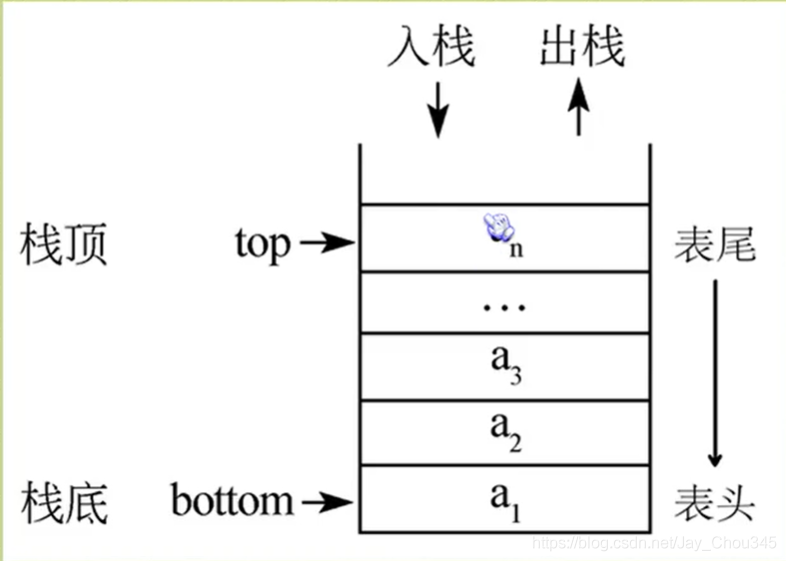
- 注:對于堆疊來說,這個表尾稱為堆疊的堆疊頂(top)相應的表頭稱為堆疊底(bottom),
堆疊的插入操作(Push),叫做進堆疊,也稱為壓堆疊入堆疊,類似子彈放入彈夾的動作,
堆疊的洗掉操作(Pop),叫做出堆疊,也稱為彈堆疊,如同彈夾中的子彈出夾,
3.2堆疊的順序存盤結構
因為堆疊的本質是一個線性表,線性表有兩種存盤形式,那么堆疊也有分為堆疊的順序存盤結構和堆疊的鏈式存盤結構,
最開始堆疊中不含有任何資料,叫做空堆疊,此時堆疊頂就是堆疊底,然后資料從堆疊頂進入,堆疊頂堆疊底分離,整個堆疊的當前容量變大,資料出堆疊時從堆疊頂彈出,堆疊頂下移,整個堆疊的當前容量變小,
3.2.1代碼示例:順序堆疊
#include<stdio.h>
#include<stdlib.h>
#define initSize 50
typedef int SElemType;
typedef struct{
SElemType *elem;
int maxSize,top;
}SeqStack;
/**
順序堆疊4要素
堆疊空:top=-1
堆疊滿:top=maxSize-1
進堆疊e操作:top++;將e放在top處
退堆疊操作:從top處取出元素,top--
**/
void InitStack(SeqStack &S){
S.elem=(SElemType *)malloc (initSize*sizeof(SElemType));
if(!S.elem){
printf("記憶體分配錯誤\n");
exit(1);
}
S.maxSize=initSize;
S.top=-1;
}
int Push(SeqStack &S,SElemType x){
if(S.top==S.maxSize-1)return 0;
S.elem[++S.top]=x;
return 1;
}
int Pop(SeqStack &S,SElemType &x){
if(S.top==-1)return 0;
x=S.elem[S.top--];
return 1;
}
int GetTop(SeqStack &S,SElemType &x){
if(S.top==-1)return 0;
x=S.elem[S.top];
return 1;
}
int StackEmpty(SeqStack &S){
return S.top==-1;
}
int StackFull(SeqStack &S){
return S.top==S.maxSize;
}
int StackSize(SeqStack &S){
return S.top+1;
}
int main(){
SeqStack K;
SElemType i;
InitStack(K);
printf("%s",StackEmpty(K)?"堆疊是空的\n":"堆疊不是空的\n");
printf("插入5個值,4、5、6、7、8\n");
Push(K,4);
Push(K,5);
Push(K,6);
Push(K,7);
Push(K,8);
int size=StackSize(K);
GetTop(K,i);
printf("插入成功,現在堆疊有%d個值,堆疊的top值是%d\n\n",size,i);
printf("",i);
printf("從top退堆疊一次\n");
Pop(K,i);
printf("成功退出值:%d\n",i);
size=StackSize(K);
GetTop(K,i);
printf("現在堆疊有%d個值,堆疊的top值是%d\n",size,i);
}
3.3堆疊的鏈式存盤結構
講完了堆疊的順序存盤結構,也給大家結合了一些例題演練,相信大家對堆疊再也不陌生了吧?
現在我們來看下堆疊的鏈式存盤結構,簡 稱堆疊鏈,(通常我們用的都是堆疊的順序存盤結構存盤,鏈式存盤我們作為一個知識點,大家知道就好! )
堆疊因為只是堆疊頂來做插入和洗掉操作,所以比較好的方法就是將堆疊頂放在單鏈表的頭部,堆疊頂指標和單鏈表的頭指標合二為一,
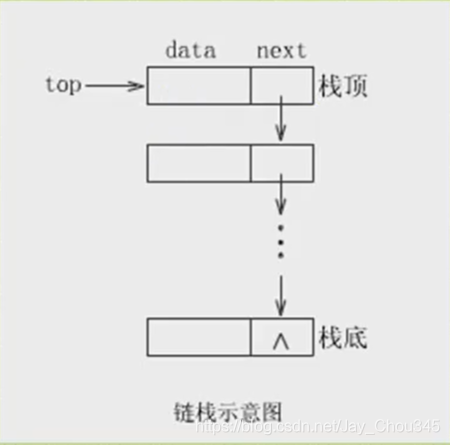
3.3.1代碼示例:鏈式堆疊
#include<stdio.h>
#include<stdlib.h>
typedef int SElemType;
typedef struct node{
SElemType data;
struct node *link;
}LinkNode,*LinkStack;
void InitStack(LinkStack &S){
S=NULL;
}
int Push(LinkStack &S,SElemType x){
LinkNode *p=(LinkNode *)malloc (sizeof(LinkNode));
p->data=x;
p->link=S;
S=p;
return 1;
}
int Pop(LinkStack &S,SElemType &x){
if(S==NULL)return 0;
LinkNode *p=S;
x=p->data;
S=p->link;
free(p);
return 1;
}
int GetTop(LinkStack &S,SElemType &x){
if(S==NULL)return 0;
x=S->data;return 1;
}
int StackEmpty(LinkStack &S){
return S==NULL;
}
int StackSize(LinkStack &S){
LinkNode *p=S;
int k=0;while(p!=NULL){
p=p->link;
k++;
}
return k;
}
int main(){
LinkStack K;
SElemType i;
InitStack(K);
printf("%s",StackEmpty(K)?"堆疊是空的\n":"堆疊不是空的\n");
printf("插入5個值,2,3,4,5,6\n");
Push(K,2);
Push(K,3);
Push(K,4);
Push(K,5);
Push(K,6);
int size=StackSize(K);
GetTop(K,i);
printf("插入成功,現在堆疊有%d個值,堆疊的top值是%d\n\n",size,i);
printf("",i);
printf("從top退堆疊一次\n");
Pop(K,i);
printf("成功退出值:%d\n",i);
size=StackSize(K);
GetTop(K,i);
printf("現在堆疊有%d個值,堆疊的top值是%d\n",size,i);
}
4.佇列
4.1佇列的定義
佇列(queue) 是只允許在一端進行插入操作,而在另一端進行洗掉操作的線性表,與堆疊相反,佇列是一種先進先出(First InFirst Out ,FIFO)的線性表,
與堆疊相同的是,佇列也是一種重要的線性結構,實作一個佇列同樣需要順序表或鏈表作為基礎,

4.2代碼示例:佇列的順序儲存結構
#include<stdio.h>
#include<stdlib.h>
#define initSize 50
/**
*對空條件:rear=front
*隊滿條件:Q.rear==Q.maxSize-1
*
*/
typedef int DataType;
typedef struct {
DataType *data;
int rear,front;
int maxSize;
}SeqQueue;
//初始化
void InitQueue(SeqQueue &Q){
Q.data=(DataType *)malloc(initSize*sizeof(SeqQueue));
Q.front=Q.rear=-1;
Q.maxSize=initSize;
}
//入隊
bool EnQueue(SeqQueue &Q,DataType e){
if(Q.rear==Q.maxSize-1){
return false;
}
Q.rear++;
Q.data[Q.rear]=e;
return true;
}
//出隊
bool DeQueue(SeqQueue &Q){
if(Q.front==Q.rear){
return false;
}
Q.front++;
return true;
}
//判空
bool QueueEmpty(SeqQueue &Q){
return (Q.front==Q.rear);
}
int main(){
SeqQueue sq;
InitQueue(sq);
printf("順序對sq是空的嗎?%s\n\n",QueueEmpty(sq)?"sq是空的":"sq不是空的");
EnQueue(sq,6);
EnQueue(sq,7);
EnQueue(sq,8);
EnQueue(sq,9);
printf("開始洗掉\n\n");
while(!QueueEmpty(sq)){
printf("成功洗掉元素->%d\n",sq.data[sq.front+1]);
DeQueue(sq);
}
printf("洗掉完畢,現在順序對sq是空的嗎?%s\n\n",QueueEmpty(sq)?"sq是空的":"sq不是空的");
}
4.3代碼示例:佇列的鏈式儲存結構
因為我沒有寫鏈隊的代碼,所以用了csdn別的博主的代碼
博客鏈接如右→博客鏈接
/**
*代碼來自@凌盛羽
*博客地址https://blog.csdn.net/Ceosat/article/details/103959740
*/
#include<stdio.h>
#include<stdlib.h>
//佇列節點
typedef struct Node
{
int dat;//結點值
struct Node *pNext;//下一個結點
}Node, *pNode;
//Node 等效于 struct Node
//*pNode 等效于 struct Node *
//鏈式佇列
typedef struct LinkQueue
{
struct Node * qFront;//隊首指標
struct Node * qRear;//隊尾指標
}LinkQueue, *pLinkQueue;
//LinkQueue 等效于 struct LinkQueue
//pLinkQueue 等效于 struct LinkQueue *
//創建鏈式佇列
LinkQueue * CreatLinkQueue(void)
{
pLinkQueue pHeadQueue = NULL;//鏈式佇列指標
pNode pHeadNode = NULL;//頭結點指標
//為鏈式佇列申請記憶體
pHeadQueue = (LinkQueue *)malloc(sizeof(LinkQueue));
if (pHeadQueue == NULL)
{
printf("鏈式佇列記憶體申請失敗,程式終止......\r\n");
while (1);
}
//為鏈式佇列頭結點申請記憶體
pHeadNode = (Node *)malloc(sizeof(Node));
if (pHeadNode == NULL)
{
printf("鏈式佇列頭結點記憶體申請失敗,程式終止......\r\n");
while (1);
}
pHeadQueue->qFront = pHeadNode;//隊首指向頭結點
pHeadQueue->qRear = pHeadNode;//隊尾指向頭結點
pHeadNode->pNext = NULL;//頭結點無下個結點
pHeadNode->dat = 0;//頭結點資料為零
printf("鏈式佇列創建成功......\r\n");
printf("頭結點:0x%08X 頭結點指標:0x%08X 隊首指標:0x%08X 隊尾指標:0x%08X\r\n", pHeadNode, pHeadNode->pNext, pHeadQueue->qFront, pHeadQueue->qRear);
return pHeadQueue;
}
//鏈式佇列資料入隊
void EnterLinkQueue(pLinkQueue queue, int value)
{
pNode newNode = NULL;//鏈式佇列入隊結點指標
//為鏈式佇列入隊結點申請記憶體
newNode = (Node *)malloc(sizeof(Node));
if (newNode == NULL)
{
printf("鏈式佇列入隊結點記憶體申請失敗......\r\n");
return;
}
queue->qRear->pNext = newNode;//入隊新結點為最后個結點
queue->qRear = newNode;//隊尾指向入隊新結點
newNode->pNext = NULL;//入隊新結點無下個結點
newNode->dat = value;//入隊值
printf("入隊成功!入隊值:%d ----> ", value);
printf("隊首結點指標:0x%08X 隊尾指標:0x%08X\r\n", queue->qFront, queue->qRear);
}
//判斷鏈式佇列是否為空
bool IsEmptyLinkQueue(pLinkQueue queue)
{
//隊首與隊尾指向同一節(首節點)點則佇列為空
if (queue->qFront == queue->qRear)
return true;
else
return false;
}
//遍歷鏈式佇列資料
void TraverseLinkQueue(pLinkQueue queue)
{
pNode queNode = NULL;//結點指標
if (IsEmptyLinkQueue(queue))
{
printf("鏈式佇列為空,遍歷失敗......\r\n");
return;
}
printf("鏈式佇列資料: ");
queNode = queue->qFront->pNext;//第一個有效結點
while (queNode != NULL)//最后一個結點結束
{
printf("%d ", queNode->dat);//結點資料
queNode = queNode->pNext;//下一個結點
}
printf("\r\n");
}
//鏈式佇列資料出隊
void OutLinkQueue(pLinkQueue queue, int * value)
{
pNode queNode = 0;//佇列結點指標
if (IsEmptyLinkQueue(queue))
{
printf("鏈式佇列為空,出隊失敗......\r\n");
*value = 0;
return;
}
if (queue->qFront->pNext == queue->qRear)//只有一個有效結點
queue->qRear = queue->qFront;//隊尾指標等于隊首指標
queNode = queue->qFront->pNext;//結點指標指向隊首有效結點
queue->qFront->pNext = queNode->pNext;//隊首結點指標指向下個結點
*value = queNode->dat;//出隊結點值
free(queNode);//釋放記憶體
printf("出隊成功!出隊值:%d ----> ", *value);
printf("隊首結點指標:0x%08X 隊尾指標:0x%08X\r\n", queue->qFront->pNext, queue->qRear);
}
//獲取鏈式佇列長度
int CountLinkQueue(pLinkQueue queue)
{
pNode queNode = NULL;//結點指標
int len = 0;
if (IsEmptyLinkQueue(queue))
{
printf("鏈式佇列為空......\r\n");
return len;
}
queNode = queue->qFront->pNext;//第一個有效結點
while (queNode != NULL)//最后一個結點結束
{
len++;
queNode = queNode->pNext;//下一個結點
}
printf("鏈式佇列長度: %d\r\n", len);
return len;
}
int main()
{
pLinkQueue Queue;
int delVal = 0;
Queue = CreatLinkQueue();//創建鏈式佇列
printf("\r\n");
EnterLinkQueue(Queue, 10);//鏈式佇列資料入隊
EnterLinkQueue(Queue, 20);
EnterLinkQueue(Queue, 30);
EnterLinkQueue(Queue, 40);
EnterLinkQueue(Queue, 50);
EnterLinkQueue(Queue, 60);
CountLinkQueue(Queue);//獲取鏈式佇列長度
TraverseLinkQueue(Queue);//遍歷鏈式佇列資料
printf("\r\n");
OutLinkQueue(Queue, &delVal);//鏈式佇列資料出隊
OutLinkQueue(Queue, &delVal);
OutLinkQueue(Queue, &delVal);
OutLinkQueue(Queue, &delVal);
OutLinkQueue(Queue, &delVal);
CountLinkQueue(Queue);//獲取鏈式佇列長度
TraverseLinkQueue(Queue);//遍歷鏈式佇列資料
printf("\r\n");
}
5.字串
5.1字串的定義
我們來研究下"串"這樣的資料結構:
定義:
串(String)是由零個或多個字符組成的有限序列,又名叫字串
- 一般記為S=“a1a2a3.,…an”(n>=0)
- 串可以是空串,即沒有字符,直接由表示(注意里邊沒有空格哦~),或者可以用希臘字母中φ來表示(讀fai,四聲)
- 子串與主串,例如"FishC"是“FishC. com’的子串,反之則倒過來,
5.2字串的比較
字串比較大小跟傳統的數字比較有點差別,很容易我們可以知道2比1要大,可要是“FishC”和“fishc.com”呢?要怎么比較?比長短?比大小?
比大小! 沒錯,比的就是字串里每個字符的ASCII碼大小,因為“F”=70,“f”=102,“f”>“F”
所以“fishc.com”>“FishC”
其實這樣的比較大小沒有多大意義,字串的比較我們更重視是否相等!
5.3代碼示例:字串的存盤結構
定義一個SqlString.h(接下來會進行呼叫這個頭檔案)
#include<stdio.h>
#define maxSize 100
typedef struct{
char str[maxSize];
int length;
}SqlString;
void CreatString(SqlString &s,char a[]){
s.length=0;
int i;
for(i=0;i<maxSize&&a[i]!='\0';i++){
s.str[s.length]=a[i];
s.length++;
}
}
void Disp(SqlString s){
int i=0;
printf("字串是->'");
while(i<s.length){
printf("%c",s.str[i]);
i++;
}
printf("'\t長度為:%d\n\n",s.length);
}
void StringCopy(SqlString &s1,SqlString &s2){
s2.length=s1.length;
for(int i=0;i<s1.length;i++){
s2.str[i]=s1.str[i];
}
}
bool StrEquals(SqlString s1,SqlString s2){
if(s1.length!=s2.length){
return false;
}else{
for(int i=0;i<s1.length;i++){
if(s1.str[i]!=s2.str[i]){
return false;
}
}
}
return true;
}
void ConnectString(SqlString &s1,SqlString &s2){
int mark=s1.length;
s1.length+=s2.length;
int j=0;
for(int i=mark;j<s2.length;i++){
s1.str[i]=s2.str[j];
j++;
}
}
5.4代碼示例:比較倆字串是否一致
#include"SqlString.h"
int main(){
SqlString s1,s2;
char a[6]={'C','h','i','n','a','\0'};
CreatString(s1,a);
Disp(s1);
printf("此時定義一個SqlString型別的s2,執行復制方法\n\n");
StringCopy(s1,s2);
printf("s1和s2相等嗎?:%s\n",StrEquals(s1,s2)?"s1與s2完全等值\n":"s1與s2不是完全相等的\n");
printf("s1和s2連接\n");
ConnectString(s1,s2);
Disp(s1);
}
5.5代碼示例:倆字串是否匹配(是否為子串主串關系)
#include"SqlString.h"
int BFString(SqlString T,SqlString P);
int KMPString(SqlString T,SqlString P,int next[]);
int main(){
//第一種情況
char s1[20]="abcdefghij";
char s2[10]="cdef";
SqlString T1,P1;
CreatString(T1,s1);
Disp(T1);
CreatString(P1,s2);
Disp(P1);
int result=BFString(T1,P1);
printf("%s",result==-1?"倆字串不匹配\n":"字串匹配\n");
if(result!=-1){
printf("字串位置為:%d\n\n",result);
}
//第二組情況
char s3[20]="abcuerghij";
char s4[10]="cdef";
SqlString T2,P2;
CreatString(T2,s3);
Disp(T2);
CreatString(P2,s4);
Disp(P2);
result=BFString(T2,P2);
printf("%s",result==-1?"倆字串不匹配\n":"字串匹配\n");
if(result!=-1){
printf("字串位置為:%d",result);
}
}
int BFString(SqlString T,SqlString P){
int i=0,j=0;
while(i<T.length&&j<P.length){
if(T.str[i]==P.str[j]){
i++;
j++;
}else{
i=i-j+1;
j=0;
}
}
if(j==P.length){
return (i-j);
}else{
return -1;
}
}
6.樹與二叉樹
6.1樹的定義
樹(Tree)是n(n>=0)個結點的有限集,
當n=0時成為空樹,在任意一棵非空樹中:
- 有且僅有一個特定的稱為根(Root)的結點;
- 當n>1時,其余結點可分為m(m>0)個互不相交的有限集T1、T2、Tm,其中每一個集合本身又是一棵樹,并且稱為根的子樹(SubTree),
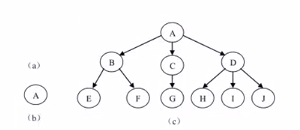
注意:
- n>0時,根結點是唯一的,堅決不可能存在多個根結點,
- m>0時,子樹的個數是沒有限制的,但它們互相是一定不會相交的,
6.2基本術語
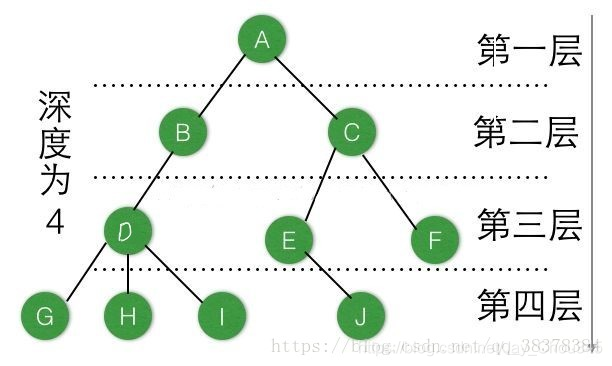
-
結點:樹中的一個獨立單位,包含一個資料元素及若干指向其子樹的分支,如圖中的每個字母都是一個結點,
-
結點的度:結點所擁有的子樹數稱為結點的度,如D的度為3,E的度數為1,
-
樹的度:樹的度是樹內各結點度的最大值,上圖的樹的度為3.
-
葉子:度為0的結點稱為葉子或終端結點,如上圖的G,H,I,J,F.
-
非終端結點:度不為0的結點稱為非終端結點或分支結點,除根結點之外,也稱為內部結點,如上圖的A,B,C,D,E.
-
雙親和孩子:若一個結點含有子結點,則這個結點稱為其子節點的雙親節點,如上圖的D的雙親結點為B
-
兄弟:具有同個雙親的結點互為兄弟結點,如上圖的G,I,H
-
祖先:從根到該結點所經分支上的所有結點,如上圖的J的祖先為A,C,E
-
子孫:以某個結點為根的子樹中的任一結點都是該根結點的子孫,如上圖B的子孫有D,G,H,I
-
層次:結點的層次從根開始定義,如上圖的層次說明,
-
堂兄弟:雙親在同一層的結點互為堂兄弟,例如結點D的堂兄弟為E,F.
-
樹的深度:樹中結點的最大層次稱之為樹的深度或高度,如上圖的深度為4.
-
有序樹和無序樹:如果將樹中結點的各子樹看成從左至右是由次序的,則稱該樹的為有序樹,否則為無序樹,
6.3樹的儲存結構
6.3.1雙親儲存結構
一種順序存盤結構,用一組連續空間存盤樹的所有結點,同時在每個結點中附設一個偽指標指示其雙親結點的位置
typedef struct{
ElemType data; //存放結點的值
int parent; //存放雙親的位置
} PTree[MaxSize] //PTree為雙親存盤結構型別
6.3.2孩子鏈存盤結構
每個結點不僅包含結點值,還包括指向所有孩子結點的指標
typedef struct{
ElemType data; //結點的值
struct node *sons[MaxSons]; //指向孩子結點
} TSonNode; //孩子鏈存盤結構中的結點型別
6.3.3孩子兄弟鏈存盤結構
為每個結點設計3個域,即一個資料元素域,一個指向該結點的左邊第一個孩子結點(長子)的指標域,一個指向該結點的下一個兄弟結點的指標域
typedef struct tnode{
ElemType data; //結點的值
struct tnode *hp; //指向兄弟
struct tnode *vp; //指向孩子結點
} TSBNode; //孩子兄弟鏈存盤結構中的結點型別
6.4二叉樹
6.4.1二叉樹的定義
二叉樹是一個有限的結點集合,這個集合或者為空,或者由一個根結點和兩課互不相交的稱為左子樹和右子樹的二叉樹組成
6.4.1.1二叉樹和樹的區別
- 度為2的樹中至少有一個結點的度為2,而二叉樹沒有這種要求
- 度為2的樹不區分左,右子樹,而二叉樹是嚴格區分左,右子樹的
6.4.1.2滿二叉樹
一棵二叉樹中所有分支結點都有左孩子結點和右孩子結點,并且葉子結點都集合在二叉樹的最下一層
6.4.1.3非空滿二叉樹
- 葉子結點都在最下一層
- 只有度為0和度為2的結點
6.4.1.4非空完全二叉樹
- 葉子結點只可能在最下面兩層中出現
- 對于最大層次中的葉子結點,都依次排列在該層最左邊的位置上
- 如果有度為1的結點,只可能出現一個,且該結點只有左孩子而無右孩子
- 按層次編號時,一旦出現編號為i的結點是葉子結點或只有左孩子,則編號大于i的結點均為葉子結點當結點總數n為奇數時,ni=0,當結點總數n為偶數時,n1=1
6.4.2二叉樹的性質
- 非空二叉樹上的葉子結點數等于雙分支結點數加1
- 非空二叉樹的第i層上最多有2i-1個結點(i≥1)
- 高度為n的二叉樹最多有2?-1個結點(n≥1)
- 具有n個(n>0)結點的完全二叉樹的高度為[log?(n+1)]或[log?n]+1
6.4.3二叉樹的存盤結構
6.4.3.1二叉樹的順序存盤結構
#define MAXSIZE 100
typedef TElemType SqBiTree[MAXSIZE];
SqBiTree bt;
假設為 typedef int sqBiTree[10] ,SqBiTree bt ,相當于定義一個int bt[10]
6.4.3.2二叉樹的鏈式存盤結構
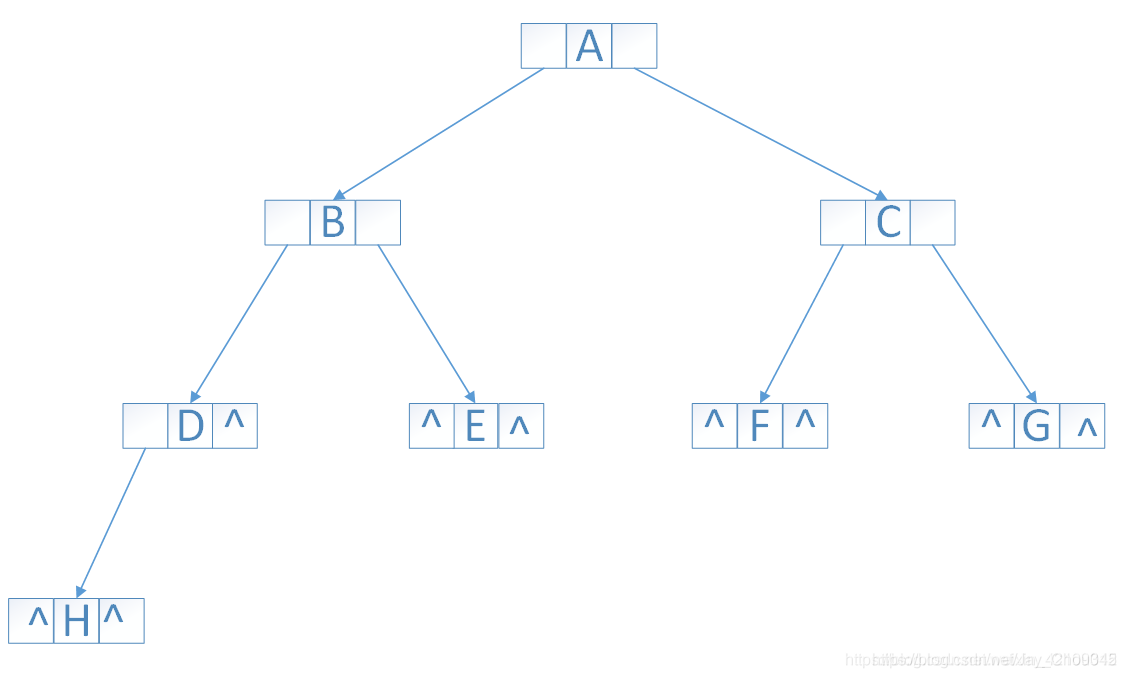
^代表的是空NULL
typedef struct node{
ElemType data; //資料元素
struct node *lchild; //指向左孩子結點
struct node *rchild; //指向右孩子結點
} BTNode;
6.4.4二叉樹的遍歷
6.4.4.1先序遍歷
void preOrder(BitTree t) //先序遍歷
{
if(t) //樹不為空
{
visit(t->data ); //訪問節點資料,自定義訪問函式visit
preOrder (t->lchild ); //遞回遍歷左子樹
preOrder (t->rchild ); //遞回遍歷右子樹
}
6.4.4.2中序遍歷
void inOrder(BitTree t) //中序遍歷
{
if(t) //樹不為空
{
inOrder (t->lchild );
visit(t->data ); //訪問節點資料
inOrder (t->rchild );
}
}
6.4.4.3后序遍歷
void postOrder(BitTree t) //后序遍歷
{
if(t) //樹不為空
{
postOrder (t->lchild );
postOrder (t->rchild );
visit(t->data ); //訪問節點資料
}
}
6.4.5代碼示例:二叉樹的運算實作
//創建二叉樹
int createBTNode(BTNode * &BT,char *str,int n);
//銷毀二叉樹
void destroyBTNode(BTNode * &BT);
//查找結點存在
BTNode *findBTNode(BTNode * &BT,char ch);
//求高度
int BTHeight(BTNode * &BT);
//輸出二叉樹
void displayBTNode(BTNode * &BT);
//先序遍歷
void preOrder(BTNode * &BT);
//中序遍歷
void inOrder(BTNode * &BT);
//后序遍歷
void postOrder(BTNode * &BT);
完整代碼如下
#include<stdio.h>
#include<malloc.h>
typedef struct node{
struct node *lchild; //指向左孩子節點
char data; //資料元素
struct node *rchild; //指向右孩子節點
}BTNode;
//創建二叉樹
int createBTNode(BTNode * &BT,char *str,int n);
//銷毀二叉樹
void destroyBTNode(BTNode * &BT);
//查找結點存在
BTNode *findBTNode(BTNode * &BT,char ch);
//求高度
int BTHeight(BTNode * &BT);
//輸出二叉樹
void displayBTNode(BTNode * &BT);
//先序遍歷
void preOrder(BTNode * &BT);
//中序遍歷
void inOrder(BTNode * &BT);
//后序遍歷
void postOrder(BTNode * &BT);
//創建
int createBTNode(BTNode * &BT,char *str,int n){
printf("%d ",n);
char ch=str[n]; //把第 n 個字符賦給ch,方便后面判斷
printf("%c \n",ch);
n=n+1;
if(ch!='\0'){ //如果 ch 不等于結束符就繼續創建,否則就結束
if( ch=='#'){ //以 # 號代表 NULL,下面沒有了
BT = NULL;
}
else{
BT = new BTNode; //新建一個二叉鏈
BT->data=ch; //把字符存入二叉鏈
n=createBTNode(BT->lchild,str,n); //左遞回創建
n=createBTNode(BT->rchild,str,n); //右遞回創建
}
}
return n; //回傳 n,記錄字串使用到哪里了
}
//摧毀
void destroyBTNode(BTNode * &BT){
if(BT!=NULL){
destroyBTNode(BT->lchild); //左遞回釋放記憶體
destroyBTNode(BT->rchild); //右遞回釋放記憶體
/*
free()釋放的是指標指向的記憶體!注意!釋放的是記憶體,不是指標!這點非常非常重要!
指標是一個變數,只有程式結束時才被銷毀,釋放記憶體空間,
原來指向這塊空間的指標還是存在!只不過現在指標指向的內容是未定義的,
因此,釋放記憶體后把指標指向NULL,防止指標在后面不小心又被參考了,非常重要啊這一點!
*/
free(BT);
BT=NULL;
}
}
//查找節點
BTNode *findBTNode(BTNode * &BT,char ch){
if(BT==NULL){ //空,回傳為空 NULL
return NULL;
}
else if(BT->data==ch){ //存在,提示存在并回傳資料
printf("存在該節點:%c",ch);
return BT;
}
else{
BTNode *p; //定義一個鏈表指標
p=findBTNode(BT->lchild,ch); //遞回查詢左子樹
if(p!=NULL){
return p; //左子樹已經找到
}
else{
return findBTNode(BT->rchild,ch); //遞回查詢右子樹
}
}
}
//求高度
int BTHeight(BTNode * &BT){
int lchildh;
int rchildh;
int h;
if(BT==NULL){
return 0; //空樹高度為0
}
else{
lchildh=BTHeight(BT->lchild); //求左子樹的高度
rchildh=BTHeight(BT->rchild); //求右子樹的高度
h=(lchildh>rchildh)?(lchildh+1):(rchildh+1); //比較左子樹和右子樹,高度高的再 +1(根節點) 就是樹的高度
return h;
}
}
//輸出
void displayBTNode(BTNode * &BT){
if(BT!=NULL){
printf("%c",BT->data);
if(BT->lchild!=NULL || BT->rchild!=NULL){
printf("(");
displayBTNode(BT->lchild);
printf(",");
displayBTNode(BT->rchild);
printf(")");
}
}
}
void displayBTNode1(BTNode * &BT){
if(BT!=NULL){
printf("%c",BT->data);
displayBTNode1(BT->lchild);
displayBTNode1(BT->rchild);
}
else{
printf("#");
}
}
//先序遍歷
void preOrder(BTNode * &BT){
if(BT!=NULL){ //判斷不為空
printf("%c",BT->data); //訪問根節點
preOrder(BT->lchild); //遞回,先序遍歷左子樹
preOrder(BT->rchild); //遞回,先序遍歷右子樹
}
}
//中序遍歷
void inOrder(BTNode * &BT){
if(BT!=NULL){
inOrder(BT->lchild);
printf("%c",BT->data);
inOrder(BT->rchild);
}
}
//后序遍歷
void postOrder(BTNode * &BT){
if(BT!=NULL){
postOrder(BT->lchild);
postOrder(BT->rchild);
printf("%c",BT->data);
}
}
int main(){
//例子:ABC###D##
BTNode *BT;
printf("輸入字串:");
char *str=(char *)malloc(sizeof(char) * 1024);
scanf("%s",str);
createBTNode(BT,str,0);
printf("二叉樹建立成功\n");
// destroyBTNode(BT);
// if(BT==NULL){
// printf("銷毀成功\n");
// }
printf("請輸入要查找的節點:");
char c='E';
printf("%c\n",c);
if(findBTNode(BT,c)==NULL){
printf("沒有此節點");
}
printf("\n");
int h=BTHeight(BT);
printf("樹的高度為:%d",h);
printf("\n");
printf("二叉樹為:");
displayBTNode(BT);
printf("\n");
printf("二叉樹為:");
displayBTNode1(BT);
printf("\n");
printf("先序遍歷結果:");
preOrder(BT);
printf("\n");
printf("中序遍歷結果:");
inOrder(BT);
printf("\n");
printf("后序遍歷結果:");
postOrder(BT);
printf("\n");
return 0;
}
結果
輸入字串:ABC###D##
0 A
1 B
2 C
3 #
4 #
5 #
6 D
7 #
8 #
二叉樹建立成功
請輸入要查找的節點:E
沒有此節點
樹的高度為:3
二叉樹為:A(B(C,),D)
二叉樹為:ABC###D##
先序遍歷結果:ABCD
中序遍歷結果:CBAD
后序遍歷結果:CBDA
7.圖
7.1.圖的定義
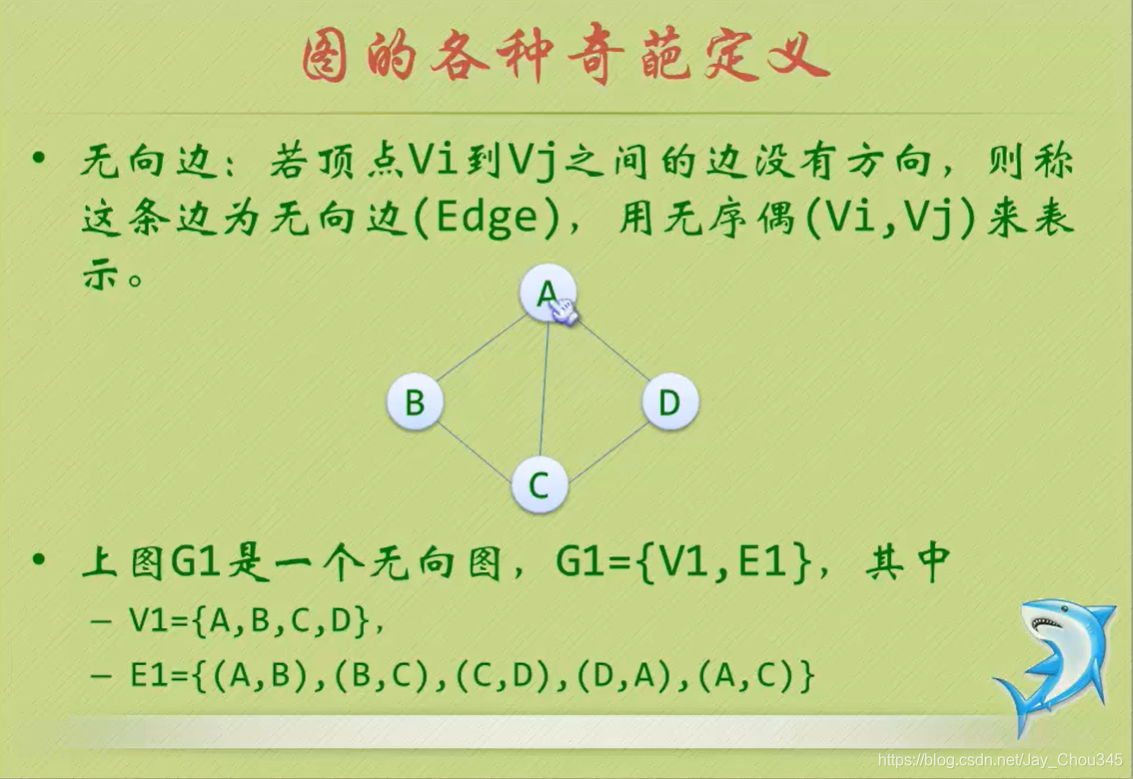
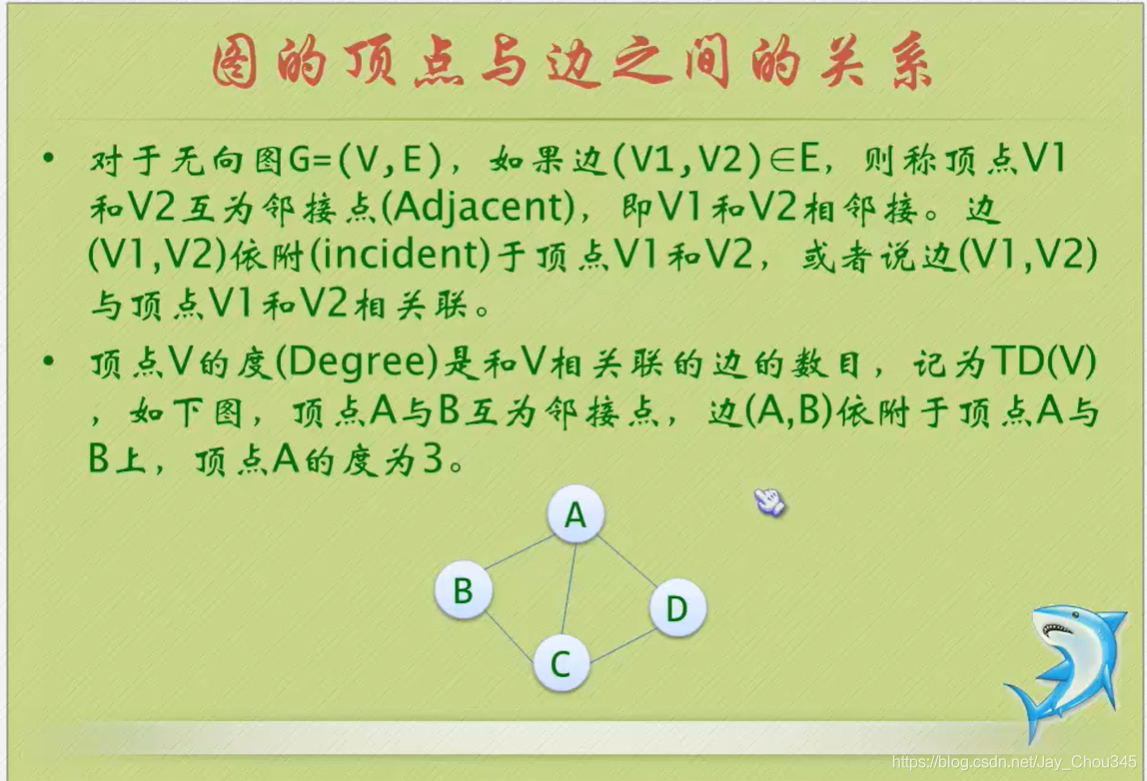
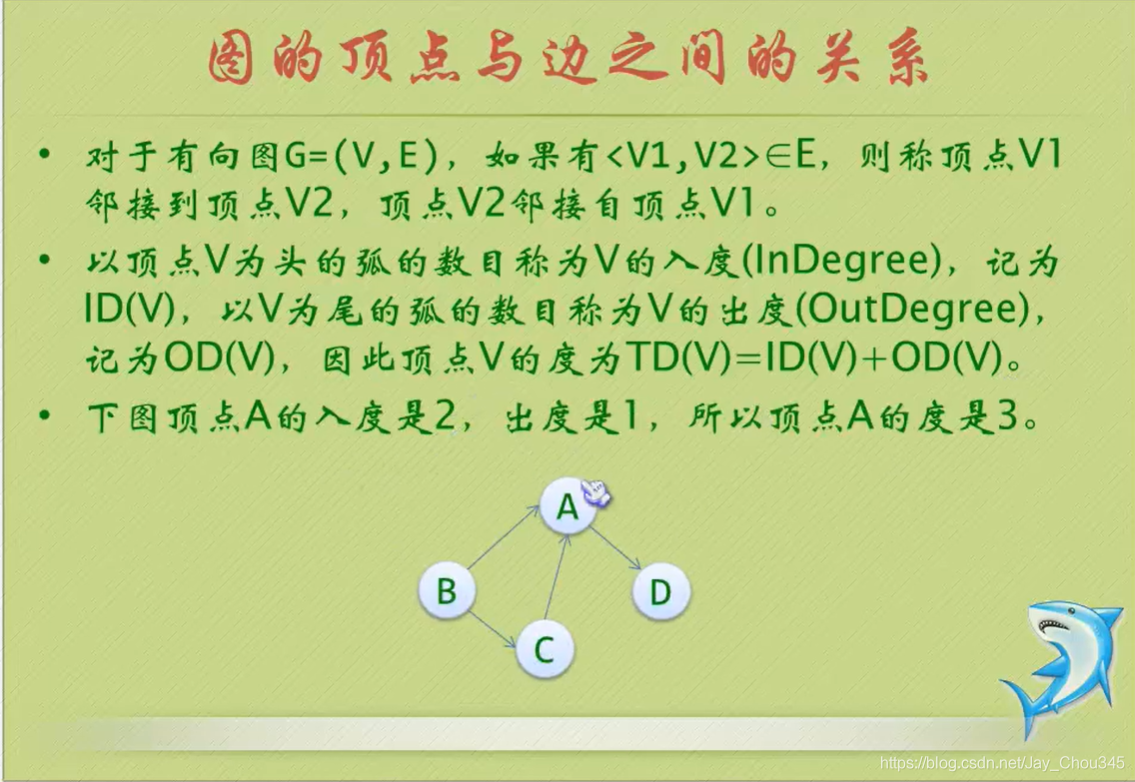
圖(Graph) 是由頂點的有窮非空集合和頂點之間邊的集合組成,通常表示為: G(V,E), 其中,G表示一個圖,V是圖G中頂點的集合,E是圖G中邊的集合,
對于圖的定義,我們需要明確幾個注意的地方:
- 線性表中我們把資料元素叫元素,樹中叫結點,在圖中資料元素我們則稱之為頂點(Vertex),
- 線性表可以沒有資料元素,稱為空表,樹中可以沒有結點,叫做空樹,而圖結構在咱國內大部分的教材中強調頂點集合V要有窮非實,
- 線性表中,相鄰的資料元素之間具有線性關系,樹結構中,相鄰兩層的結點具有層次關系,而圖結構中,任意兩個頂點之間都可能有關系,頂點之間的邏輯關系用邊來表示,邊集可以是空的,
無向邊
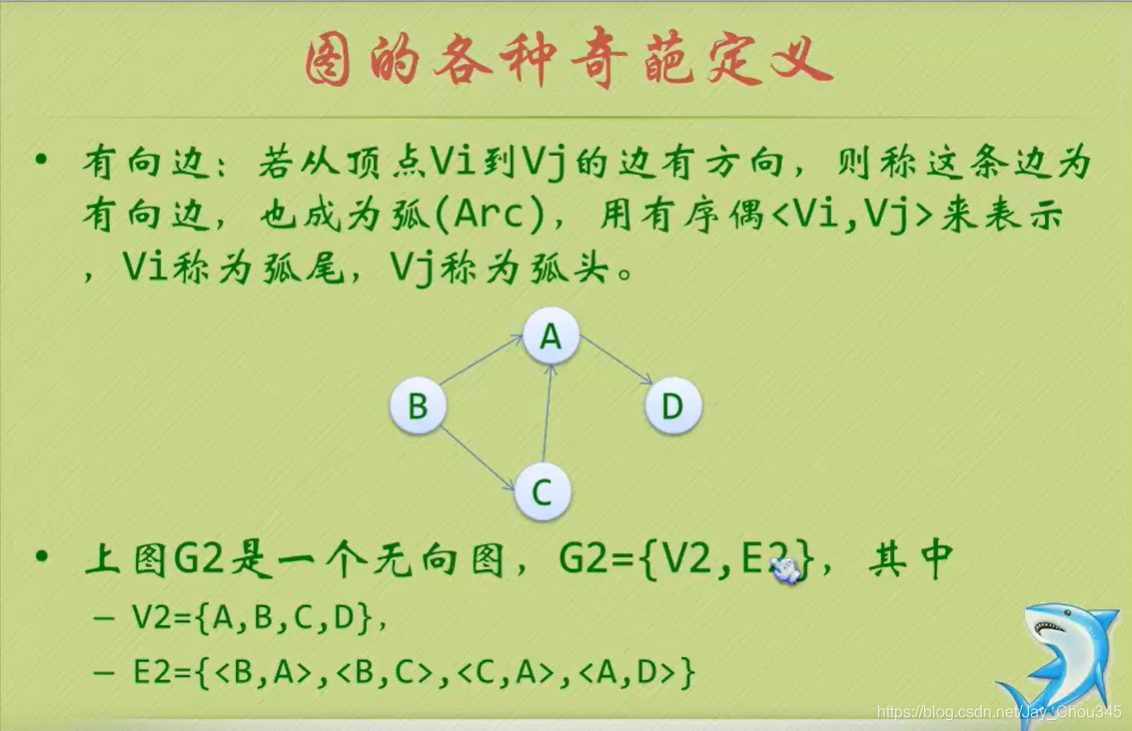
有向邊
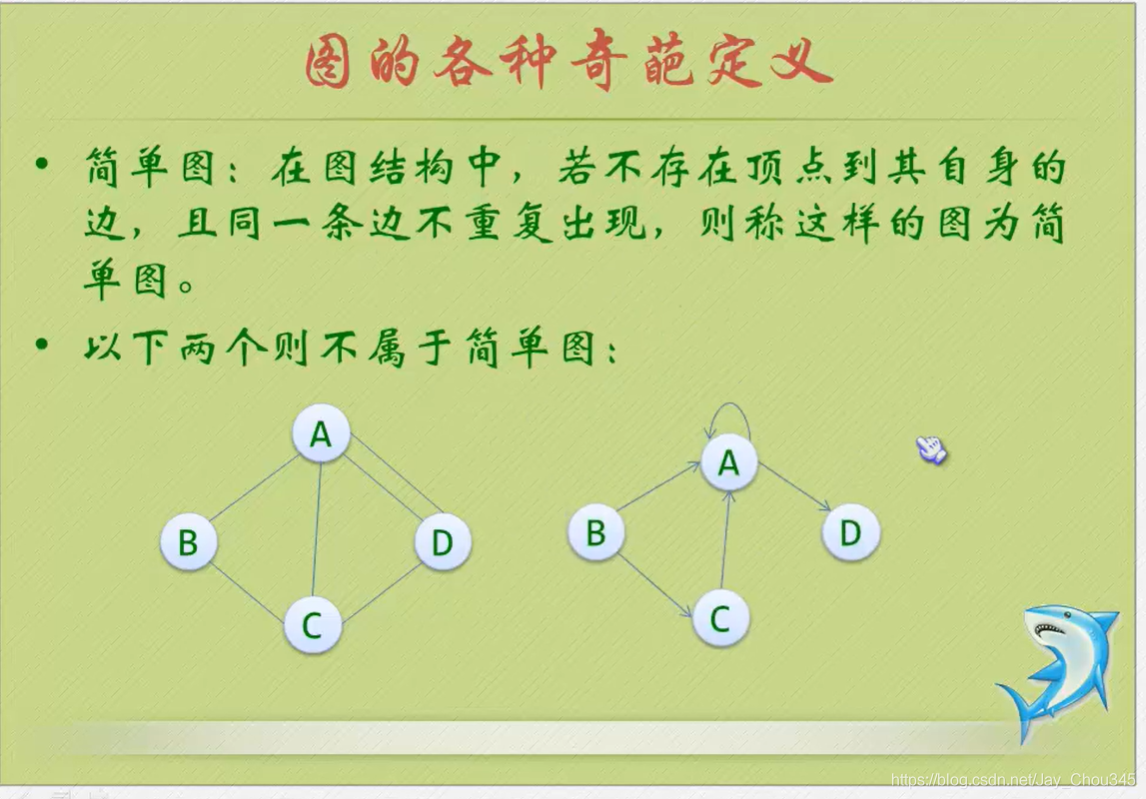
簡單圖
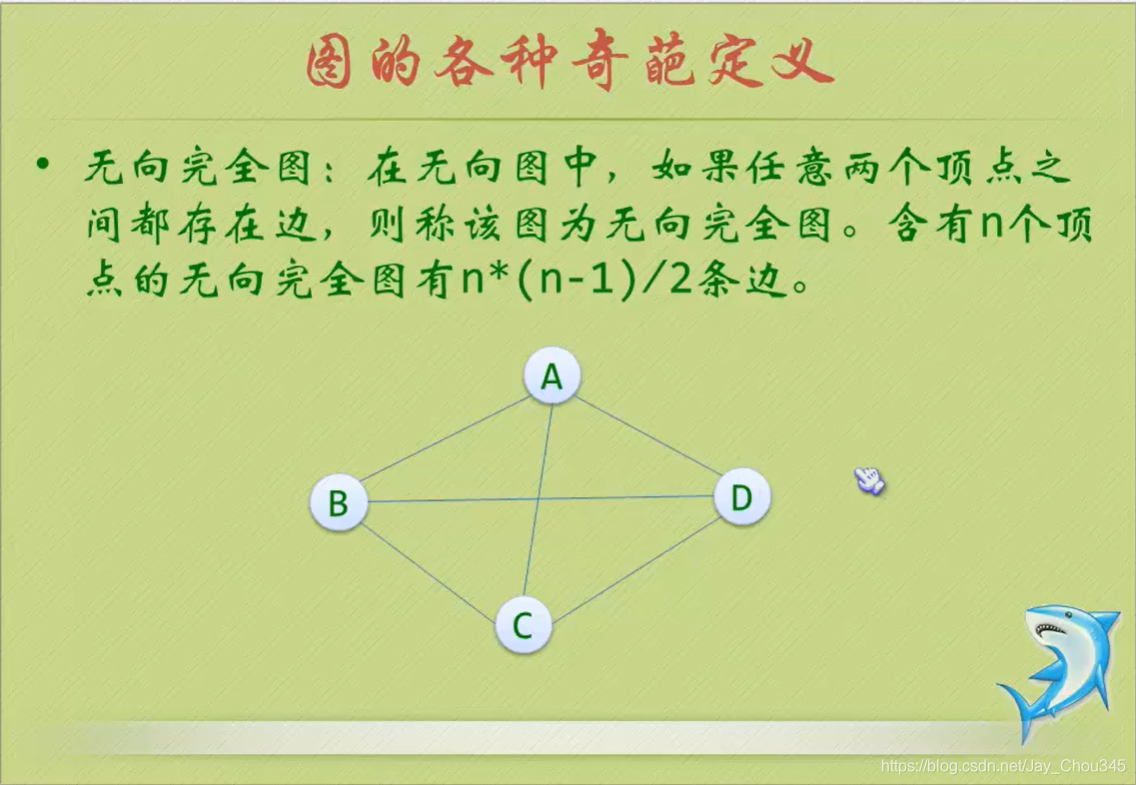
無向完全圖
有向完全圖
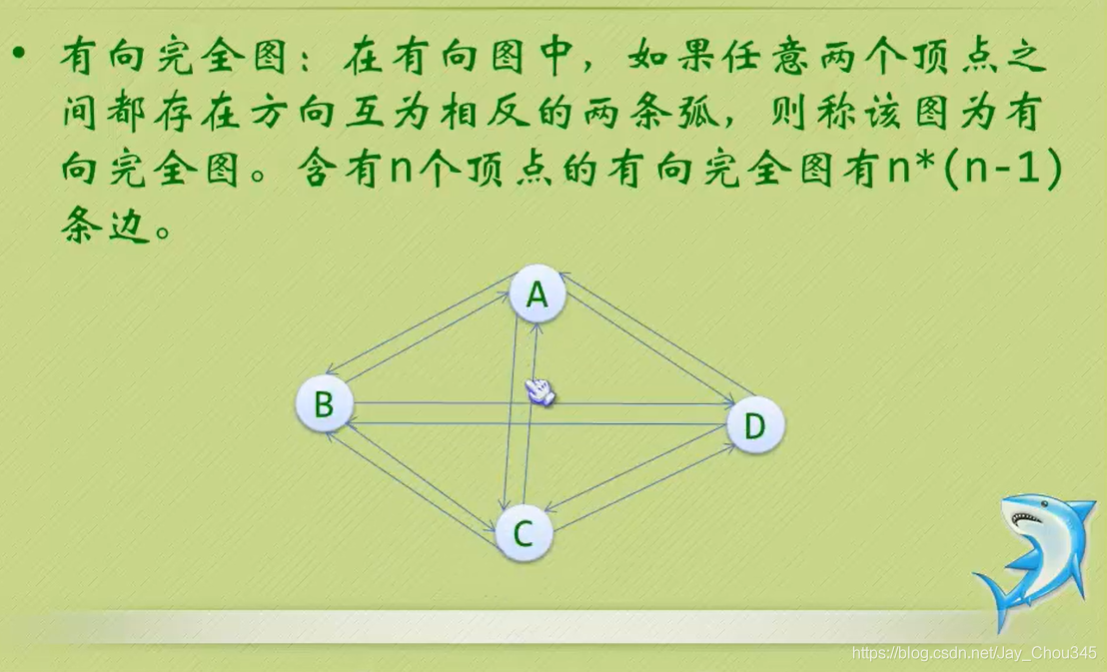
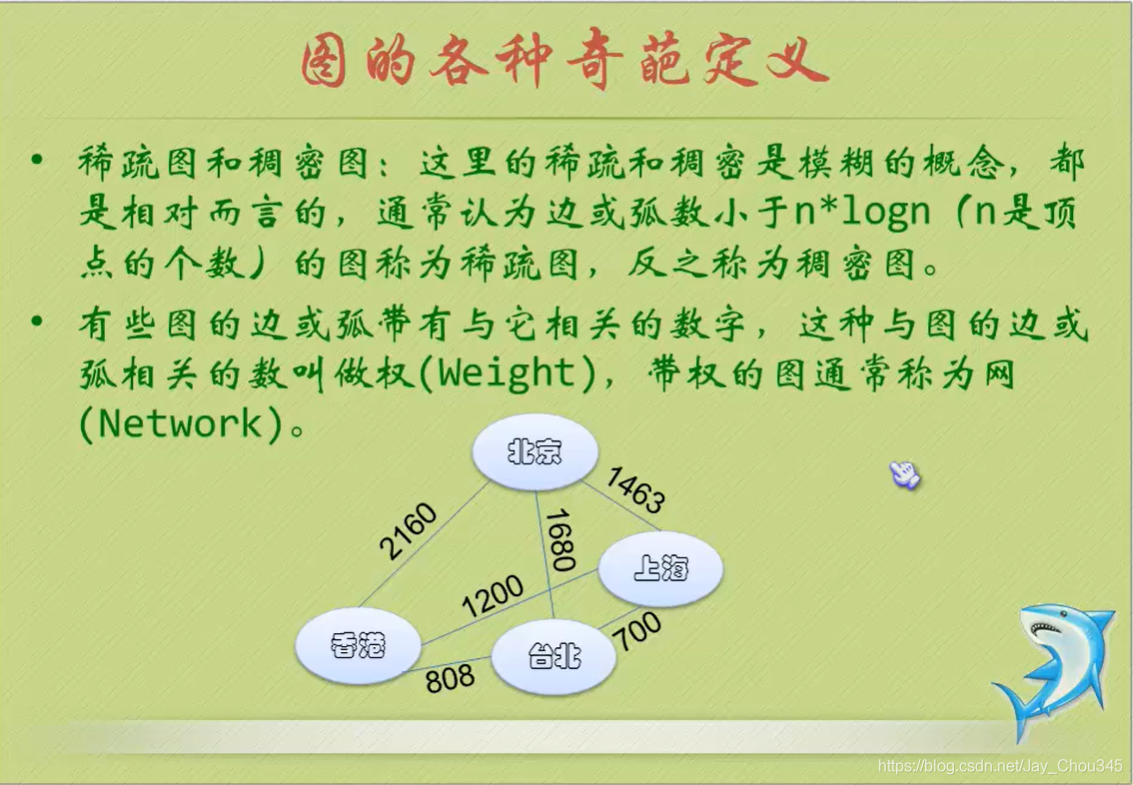
稀疏稠密圖
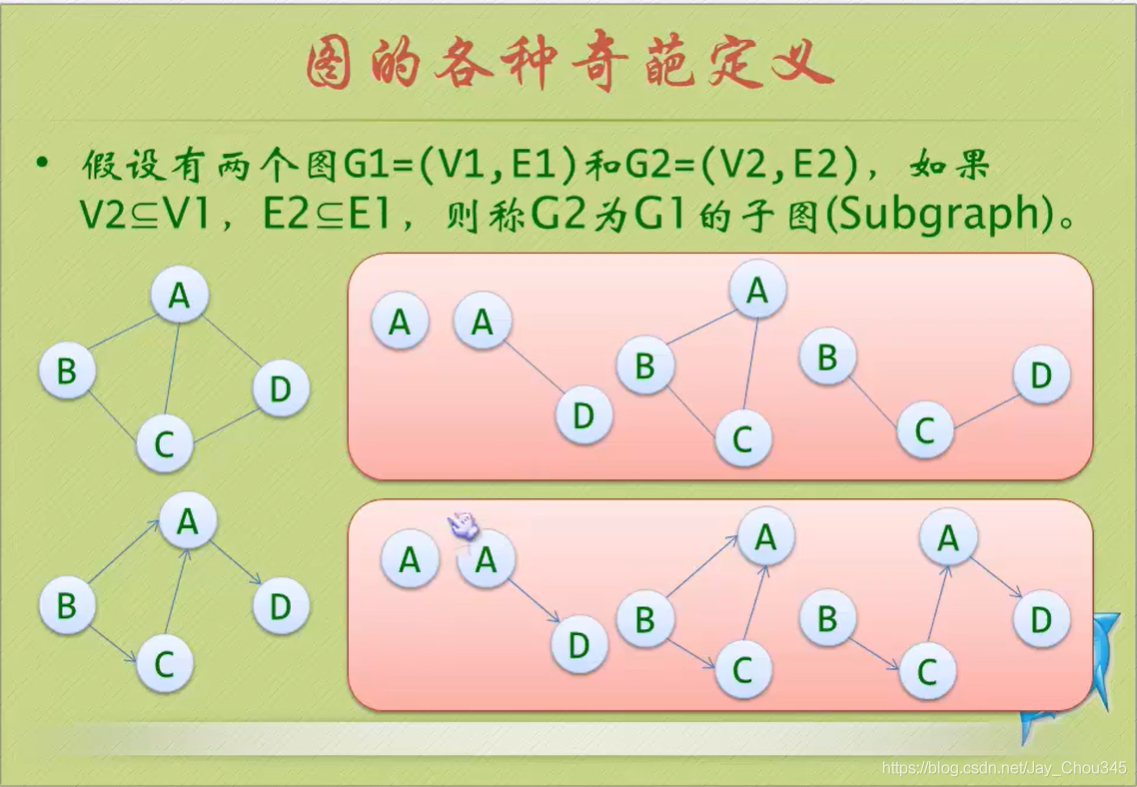
子圖
頂點與邊的關系
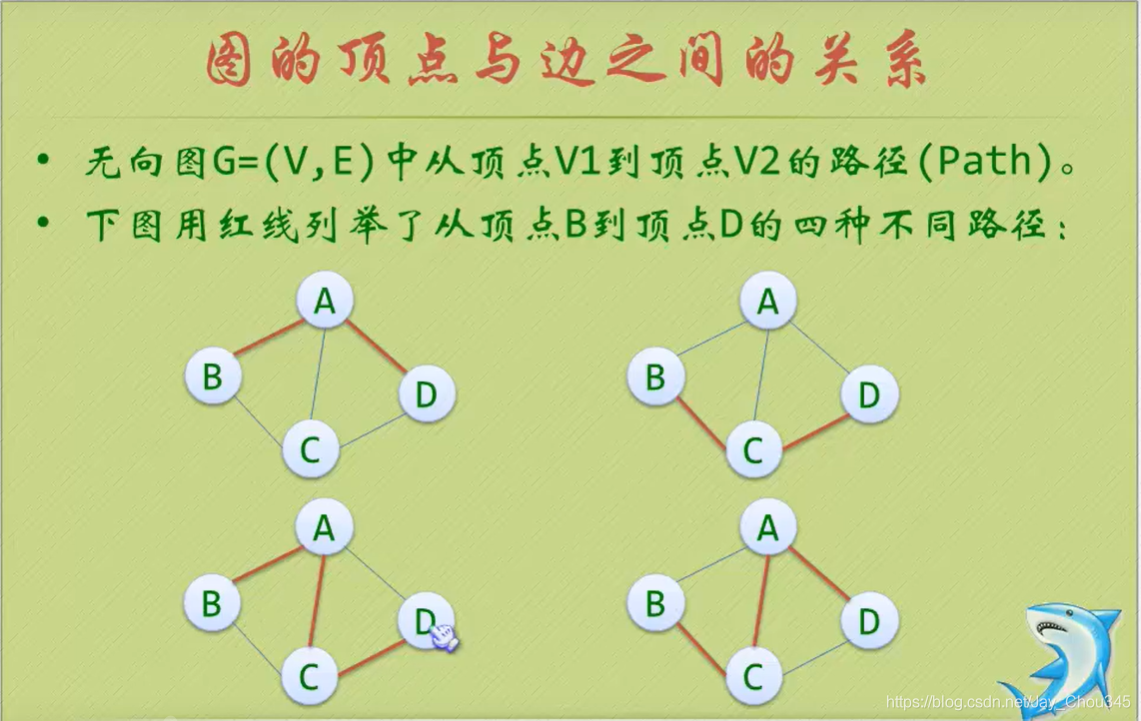
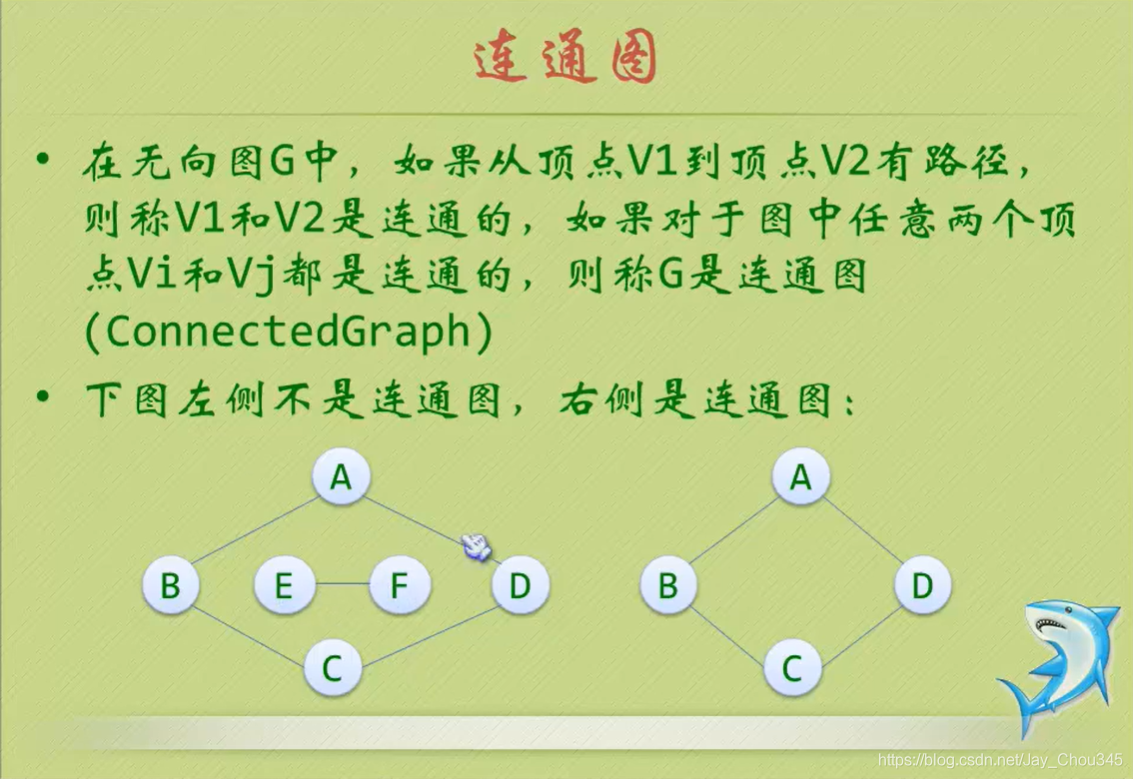
連通圖
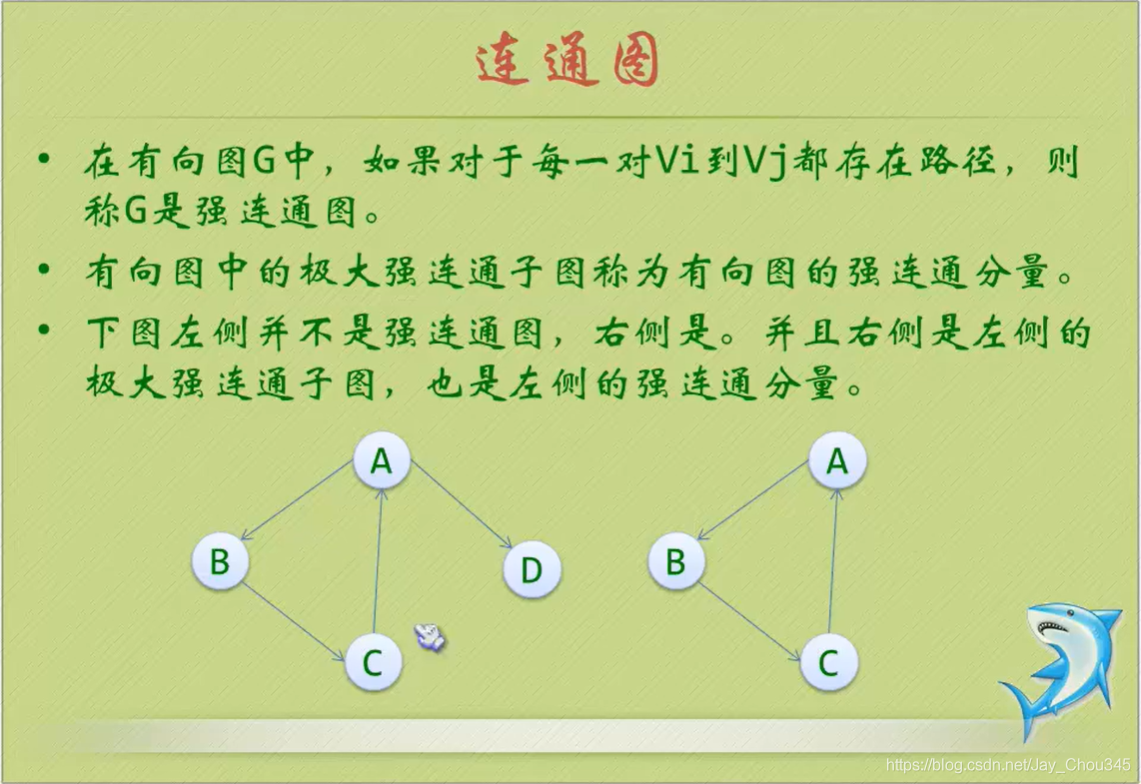
7.2.圖的儲存結構
圖的存盤結構相比較線性表與樹來說就復雜很多,
我們回顧下,對于線性表來說,是一對一的關系,所以用陣列或者鏈表均可簡單存放,樹結構是一對多的關系,所以我們要將陣列和鏈表的特性結合在一起才能更好的存放,
那么我們的圖,是多對多的情況,另外圖上的任何一個頂點都可以被看作是第一個頂點,任一頂點的鄰接點之間也不存在次序關系,
7.2.1鄰階矩陣(無向圖)
考慮到圖是由頂點和邊或弧兩部分組成,合在一起比較困難,那就很自然地考慮到分為兩個結構來分別存盤,
頂點因為不區分大小、主次,所以用一個一維陣列來存盤是狠不錯的選擇,
而邊或弧由于是頂點與頂點之間的關系,一維陣列肯定就搞不定了,那我們不妨考慮用一個二維陣列來存盤,
于是我們的鄰接矩陣方案就誕生了!
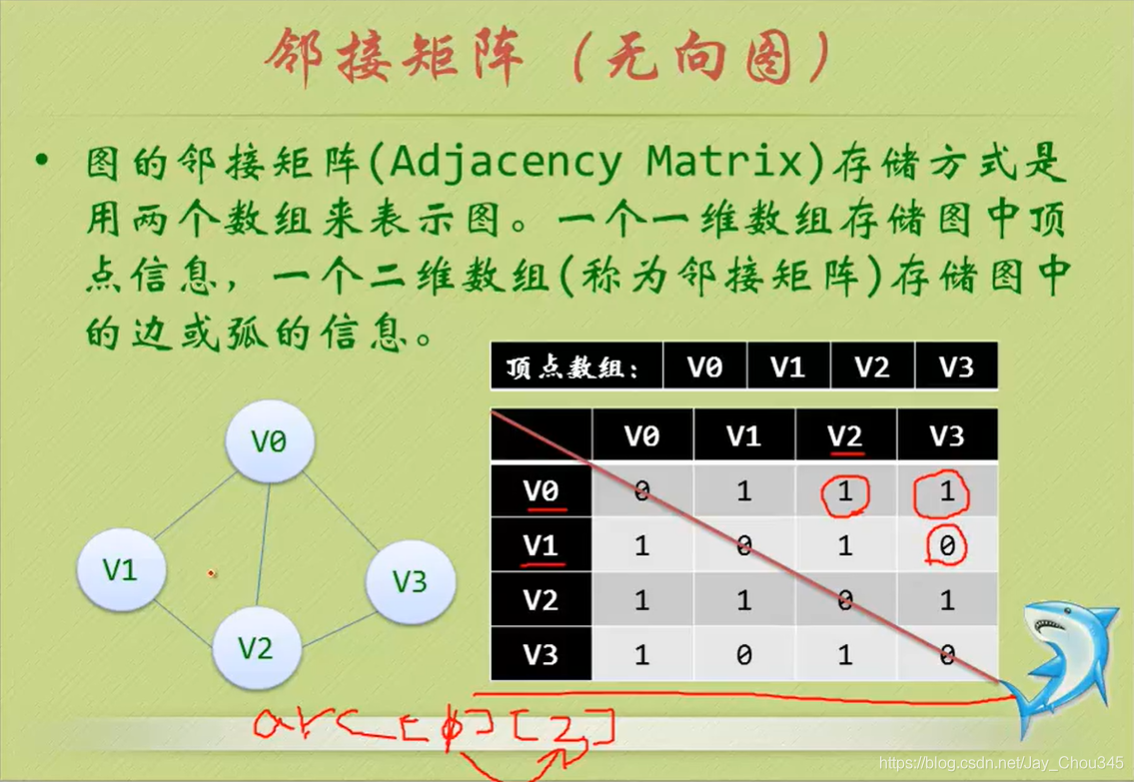
arc[0][1]=1代表V0到V1之間有邊
同理arc[1][3]=0代表V1到V3之間無邊
arc[x][x]永遠為0(本身和本身之間無邊)
我們可以設定兩個陣列,頂點陣列為vertex[4]={V0,V1,V2,V3},邊陣列arc[4][4]為對稱矩陣(0表示不存在頂點間的邊,1表示頂點間存在邊),
對稱矩陣:所謂對稱矩陣就是n階矩陣的元滿足a[i][j]=a[j]i, 即從矩陣的左上角到右下角的主對角線為軸,右上角的元與左下角相對應的元全都是相等的,
有了這個二維陣列組成的對稱矩陣,我們就可以很容易地知道圖中的資訊:
- 要判定任意兩頂點景否有邊無邊就非常容易了;
- 要知道某個頂點的度,其實就是這個頂點Vi在鄰接矩陣中第i行(或第i列)的元素之和;
- 求頂點Vi的所有鄰接點就是將矩陣中第i行元素掃描一遍,arc[i][j]為1就是鄰接點,
7.2.2鄰階矩陣(有向圖)
無向圖的邊構成了一個對稱矩陣,貌似浪費了一半的空間,那如果是有向圖來存放,會不會把資源都利用得很好呢?
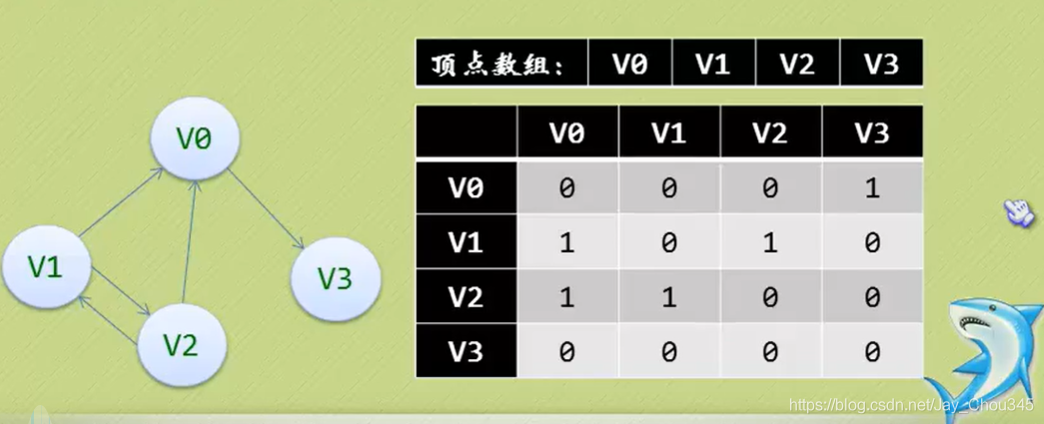
tips:先看行,再看列
arc[1][0]=1代表V1指向了V0
arc[1][4]=0代表V1沒有指向V3
arc[x][x]永遠為0
可見頂點陣列vertex[4]={V0,V1,V2,V3},弧陣列arc[4][4]也是一個矩陣
但因為是有向圖,所以這個矩陣并不對稱,例如由V1到V0有弧,得到arc[1][0]=1,而V0到V1沒有 弧,因此arc[0][1]=0,
另外有向圖是有講究的,要考慮入度和出度,頂點V1的入度為1,正好是第V1列的各數之和,頂點V1的出度為2,正好是第V2行的各數之和
tips:出、入 對應 行、列
7.2.3鄰接矩陣(網)
在圖的術語中,我們提到了網這個概念,事實上也就是每條邊上帶有權的圖就叫網,
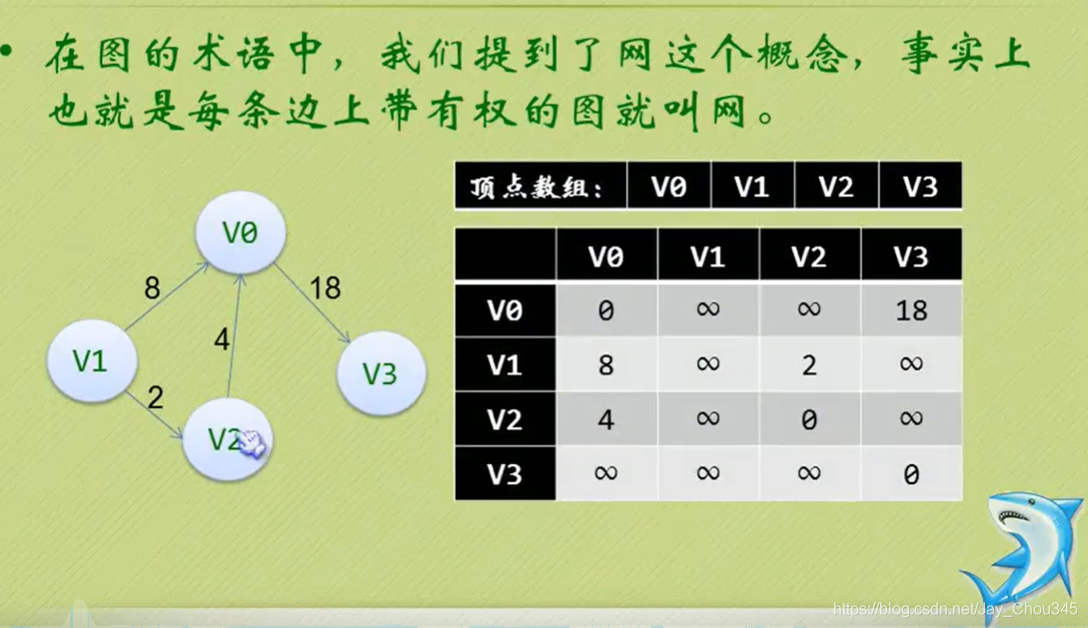
這里無窮符號表示一個計算機允許的、大于所有邊上權值的值,
7.2.4鄰接表(無向圖)
鄰接矩陣看上去是個不錯的選擇,首先是容易理解,第二是索引和編排都很舒服
但是我們也發現,對于邊數相對頂點較少的圖,矩陣結構無疑是存在對存盤空間的極大浪費,
因此我們可以考慮另外一種存盤結構方式,例如把陣列與鏈表結合一起來存盤,這種方式在圖結構也適用,我們稱為鄰接表(AdjacencyList),
鄰接表的處理方法是這樣:
- 圖中頂點用一個一維陣列存盤,當然,頂點也可以用單鏈表來存盤,不過陣列可以較容易地讀取頂點資訊,更加方便,
- 圖中每個頂點Vi的所有鄰接點構成一個線性表,由于鄰接點的個數不確定,所以我們選擇用單鏈表來存盤,
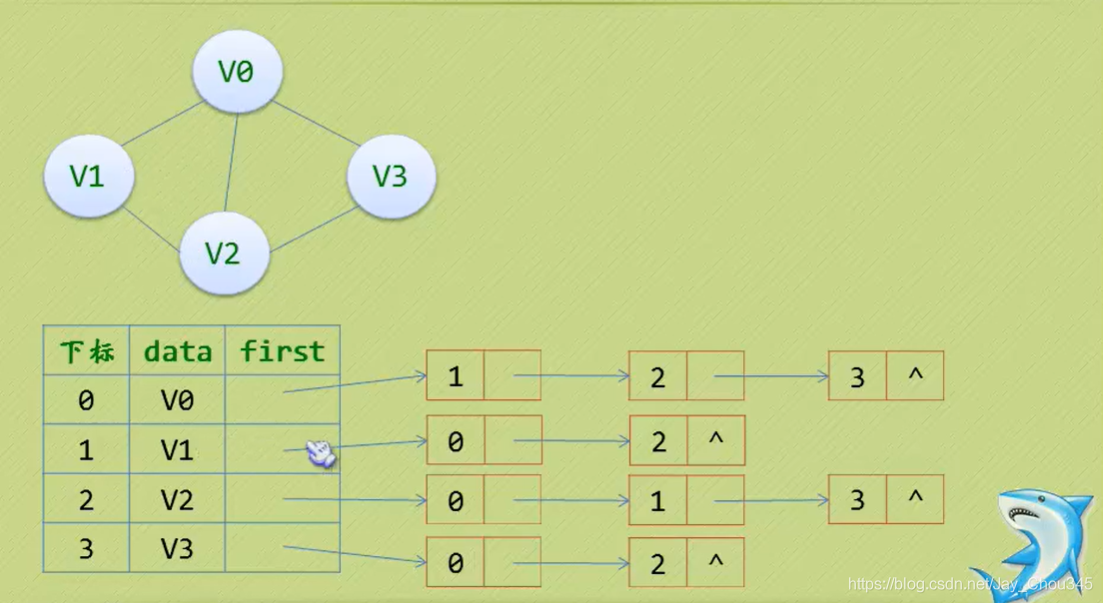
first指標依次指向下一個結點,最后一個結點的指標應該加上^代表沒有下一個結點(該結點為最后一個結點)
7.2.5鄰接表(有向圖)
若是有向圖,鄰接表結構也是類似的,我們先來看下把頂點當弧尾建立的鄰接表,這樣很容易就可以得到每個頂點的出度:
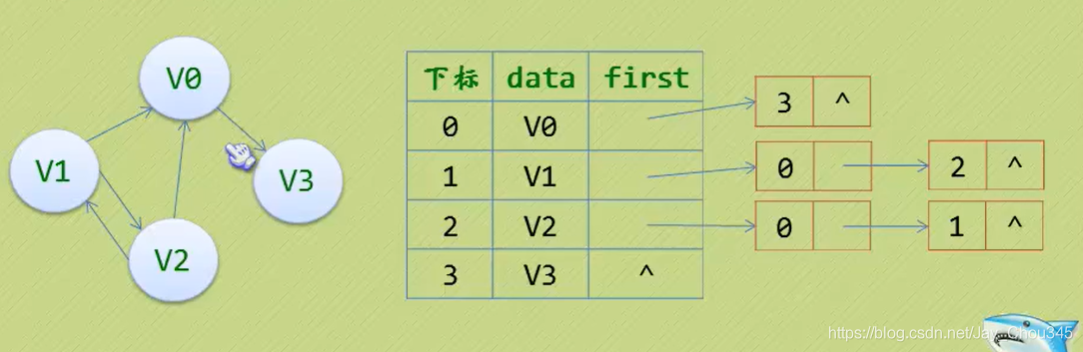
但也有時為了便于確定頂點的入度或以頂點為弧頭的弧,我們可以建立一個有向圖的逆鄰接表:
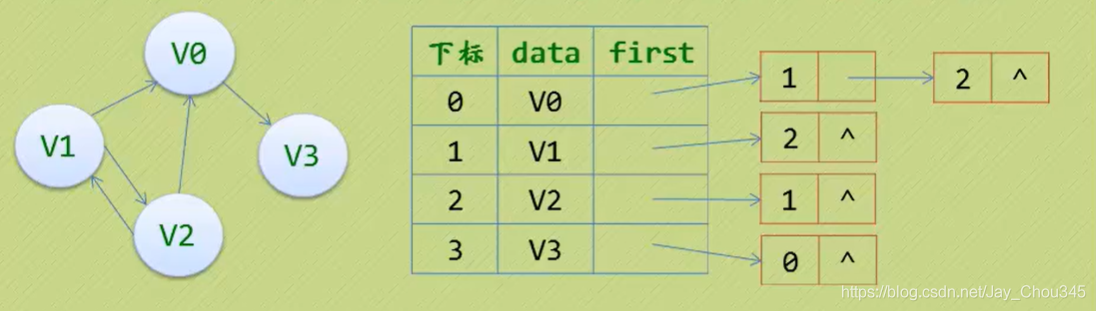
此時我們很容易就可以算出某個頂點的入度或出度是多少,判斷兩頂點是否存在弧也很容易實作,
7.2.6鄰接表(網)
對于帶權值的網圖,可以在邊表結點定義中再增加一個資料域來存盤權值即可:
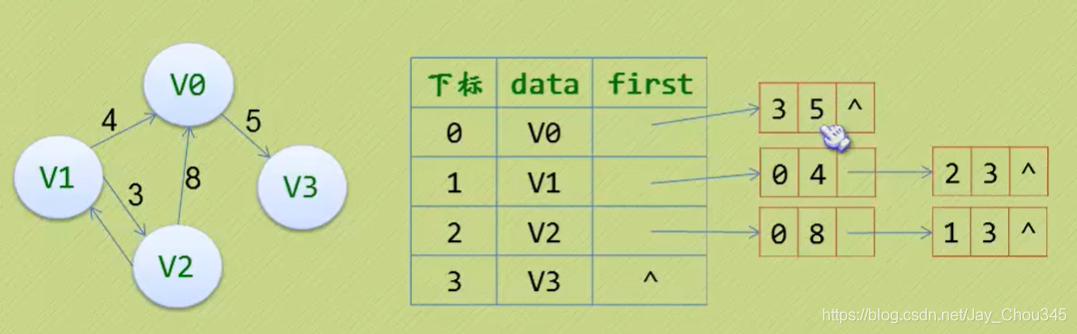
7.2.7鄰接表和鄰接矩陣的代碼
#include <stdio.h>
#include <stdlib.h>
#define INF 32767 //定義∞
#define MAXV 100 //最大頂點個數
typedef char DataType;
typedef struct
{
int no;
DataType info;
} VertexType; //頂點型別
typedef struct
{
int edges[MAXV][MAXV];//領接矩陣陣列
int n,e; //頂點數、邊數
VertexType vex[MAXV]; //存放頂點資訊
} MatGraph; //圖領接矩陣型別
typedef struct ANode
{
int adjvex; //該邊的鄰接點編號
struct ANode *nextarc; //指向下一條邊的指標
int weight; //該邊的權重
} ArcNode; //邊結點型別
typedef struct Vnode
{
DataType info; //頂點其他資訊
int count;
ArcNode *firstarc; //指向第一條邊
}VNode; //鄰接表頭結點型別
typedef struct
{
Vnode adjlist[MAXV];
int n,e;
}AdjGraph;
//創建圖的領接矩陣
void CreateMat(MatGraph &g,int A[MAXV][MAXV],int n,int e)
{
int i,j;
g.n=n;
g.e=e;
for(i=0;i<g.n;i++)
for(j=0;j<g.n;j++)
g.edges[i][j]=A[i][j];
}
//輸出領接矩陣g
void DispMat(MatGraph g)
{
int i,j;
for(i=0;i<g.n;i++)
{
for(j=0;j<g.n;j++)
if(g.edges[i][j]!=INF)
printf("%4d",g.edges[i][j]);
else
printf("%4s","∞");
printf("\n");
}
}
//鄰接表的基本運算
void CreateAdj(AdjGraph *&G,int A[MAXV][MAXV],int n,int e)
{
int i,j;
ArcNode *p;
G=(AdjGraph *)malloc(sizeof(AdjGraph ));
for(i=0;i<n;i++)
G->adjlist[i].firstarc=NULL;
for(i=0;i<n;i++)
for(j=n-1;j>=0;j--)
if(A[i][j]!=0&&A[i][j]!=INF)
{
p=(ArcNode*)malloc (sizeof(ArcNode));
p->adjvex=j;
p->weight=A[i][j];
p->nextarc=G->adjlist[i].firstarc;
G->adjlist[i].firstarc=p;
}
G->n=n;
G->e=n;
}
void DispAdj(AdjGraph *G)
{
ArcNode *p;
for(int i=0;i<G->n;i++)
{
p=G->adjlist[i].firstarc;
printf("%3d:",i);
while(p!=NULL)
{
printf("%3d[%d]->",p->adjvex,p->weight);
p=p->nextarc;
}
printf("^\n");
}
}
int main() {
MatGraph g;
AdjGraph *G;
int A[MAXV][MAXV]={{0,5,INF,7,INF,INF},{INF,0,4,INF,INF,INF},{8,INF,0,INF,INF,9},{INF,INF,5,0,INF, 6},{INF,INF,INF,5,0,INF},{3,INF,INF,INF,1,0}};
int n=6,e=10;
CreateMat(g,A,n,e);
printf("圖 G 的領接矩陣:\n");
DispMat(g);
CreateAdj(G,A,n,e);
printf("圖 G 的鄰接表:\n");
DispAdj(G);
}
7.3圖的遍歷
樹的遍歷我們談了四種方式,大家回憶一下,樹因為根結點只有一個,并且所有的結點都只有一個雙親,所以不是很難理解,
但是談到圖的遍歷,那就復雜多了,因為它的任一頂點都可以和其余的所有頂點相鄰接,因此極有可能存在重復走過某個頂點或漏了某個頂點的遍歷程序,
對于圖的遍歷,如果要避免以上情況,那就需要科學地設計遍歷方案,通常有兩種遍歷次序方案:他們是深度優先遍歷和廣度優先遍歷,
7.3.1深度優先遍歷
深度優先遍歷(DepthFirstSearch),也有稱為深度優先搜索,簡稱為DFS,
它的具體思想類似于課程開頭講的找鑰匙方案,無論從哪一間房間開始都可以,將房間內的墻角床頭柜、床上、床下、衣柜、電視柜等挨個尋找,做到不放過任何一個死角,當所有的抽屜、儲藏柜中全部都找遍,接著再尋找下一個房間,
我們可以約定右手原則:在沒有碰到重復頂點的情況下,分叉路口始終是向右手邊走,每路過一個頂點就做一個記號,
所以深度優先遍歷實際上就是一個遞回的程序
7.3.2廣度優先遍歷
廣度優先遍歷(BreadthFirstSearch)又稱為廣度優先搜索,簡稱BFS,
如果以之前我們找鑰匙的例子來講,運用深度優先遍歷意味著要先徹底查找完一個房間再開始另一個房間的搜索,
但我們知道,鑰匙放在沙發地下等犄角旮旯的可能性極低,因此我們運用新的方案:先看看鑰匙是否放在各個房間的顯眼位置,如果沒有,再看看各個房間的抽屜有沒有,這樣逐步擴大查找的范圍的方式我們稱為廣度優先遍歷
7.3.3有向圖的遍歷代碼
#include <stdio.h>
#include <malloc.h>
#define MAX 31
int visited[MAX];
typedef struct ArcNode
{
int adjvex; //該弧指向的頂點的位置
struct ArcNode *nextarc; //指向下一潭訓的指標
}ArcNode;
typedef struct VNode
{
char data; //頂點資訊
struct ArcNode *firstarc; //指向第一條依附該頂點的弧的指標
}VNode, AdjList[MAX];
typedef struct
{
AdjList adjlist;
int vexnum, arcnum; //圖的當前頂點數和弧數
}ALGraph;
void CreateDG(ALGraph *G); //創建鄰接表
void DispAdj(ALGraph *G); //輸出鄰接表
void DFS(ALGraph *G, int v); //深度優先遍歷
void BFS(ALGraph *G, int v); //廣度優先遍歷
void CreateDG(ALGraph *G)
{
int i, k, j, v1, v2;
ArcNode *p;
printf("輸入圖的頂點數和弧數:" );
scanf("%d,%d", &G->vexnum, &G->arcnum);
printf("\n");
for(i = 1; i <= G->vexnum; i++)
{
printf("輸入第%d個頂點資訊:", i);
scanf("%s", &G->adjlist[i].data);
}
printf("\n");
for(i = 1; i <= G->vexnum; ++i)
G->adjlist[i].firstarc = NULL;
for(k = 1; k <= G->arcnum; ++k)
{
printf("輸入第%d潭訓的弧尾和弧頭:", k);
scanf("%d,%d", &v1, &v2);
i = v1;
j = v2;
p = (ArcNode *)malloc(sizeof(ArcNode));
p->adjvex = j;
p->nextarc = G->adjlist[i].firstarc;
G->adjlist[i].firstarc = p;
}
printf("\n");
}
void DispAdj(ALGraph *G)
{
int i;
ArcNode *q;
for(i = 1; i <= G->vexnum; ++i)
{
q = G->adjlist[i].firstarc;
printf("%d", i);
while(q != NULL)
{
printf("->%d", q->adjvex);
q = q->nextarc;
}
printf("\n");
}
}
void DFS(ALGraph *G, int v)
{
ArcNode *p;
visited[v] = 1;
printf("%3d", v);
for(p = G->adjlist[v].firstarc; p != NULL; )
{
if(!visited[p->adjvex])
DFS(G, p->adjvex);
p = p->nextarc;
}
}
void BFS(ALGraph *G, int v)
{
ArcNode *p;
int queue[MAX], w, i;
int front = 0, rear = 0;
for(i = 0; i < MAX; i++)
visited[i] = 0;
printf("%3d", v);
visited[v] = 1;
rear = (rear + 1) % MAX;
queue[rear] = v;
while(front != rear)
{
front = (front + 1) % MAX;
w = queue[front];
p = G->adjlist[w].firstarc;
while(p != NULL)
{
if(visited[p->adjvex] == 0)
{
printf("%3d",p->adjvex);
visited[p->adjvex] = 1;
rear = (rear+1) % MAX;
queue[rear] = p->adjvex;
}
p = p->nextarc;
}
}
printf("%\n");
}
int main()
{
//int i, j, k;
ALGraph *G;
printf("\n");
G=(ALGraph *)malloc(sizeof(ALGraph));
CreateDG(G);
printf("圖的鄰接表為:\n");
DispAdj(G);
printf("\n");
printf("從頂點1開始的深度優先搜索:\n");
DFS(G, 1);
printf("\n");
printf("從頂點1開始的廣度優先搜索:\n");
BFS(G, 1);
printf("\n");
return 0;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/238108.html
標籤:其他