
思維導圖在這個系列寫的差不多的時候再整理吧,
文章目錄
- 指標和動態記憶體分配
- 參考&
- 將參考用于結構
- 何時使用參考引數?
- 指標
- 指標和const
- 通過指標回傳字串的函式
- 通過指標回傳結構
- 函式指標
- 宣告函式指標
- 函式指標用武之地
- 關于指標的一些思考
- 陣列
- STL陣列Vector
- Vector基本函式使用
- Vector的資料結構
- 聯合體union
- LeetCode精選題集
- Vector篇
- 1、參考傳參
- 2、快慢指標
- 3、map、set的使用
- 結語
指標和動態記憶體分配
指標是C語言的基本概念,C語言中指標無處不在,實際上,每種資料型別,都有相應的指向T的指標型別,
指標型別變數存放的值,實際上就是記憶體地址,指標型別有兩個最基本的操作:
&:取地址操作
*:去參考 (間接參考)操作
參考&
首先,&不是地址運算子,而是型別識別符號的一種,就像*也不是指標運算子一樣,
就像char* 意為指向char的指標一樣,int& 意為指向int 的參考,
栗子來一顆:
int a;
int &at = a;
//上述宣告允許將at和a互換,它們指向相同的值和記憶體單元,就像連體嬰一樣,
上面這個栗子其實很有內涵在里面
我為什么不寫成下面這個形式呢?
int a;
int &at;
at = a;
在指標中是可以的,但是&不允許,&必須在宣告時將其初始化,
參考經常被用作函式引數,使得函式中的變數名成為呼叫程式中變數的別名,這種呼叫方法我一直搞得暈暈的,正好這次一次性根除,這種傳遞引數的方法稱為按參考傳遞,按參考傳遞允許被呼叫函式能夠訪問呼叫函式中的變數,這是C++相比C的一個超越,
來個經典的栗子:
void swap_a(int &a,int &b)
{
int temp;
temp = a;
a = b;
b = temp;
}
//順便來個指標的
void swap_b(int *a,int *b)
{
int temp;
temp = *a; //a,b是指標,*a,*b才是int
*a = *b;
*b = temp;
}
int main()
{
int a = 1;
int b = 2;
int c = 3;
int d = 4;
swap_a(a,b); //看仔細咯,這個是參考呼叫
swap_b(&a,&b); //看仔細咯,這個是指標呼叫
//如果理解不了,這樣理解:引數中的*和&只是走個過場,告訴人家那個引數是什么型別的
//呼叫函式時的引數是a,不是*a,也不是&a
//所以&a傳的這個a是一個int型別,而*a的這個a就是指標,地址,所以要取地址傳給它
//雖然我語文不好,但是都講到這份上了那應該是可以理解了
return 0;
}
如果你的意圖是讓函式使用傳給它的資訊,又不想把這些資訊進行改動,那么應該使用const,
將參考引數宣告為const資料的好處有這些:
防止無意中被修改,
使用const引數可以兼容非const傳參,
將參考用于結構
C++引入參考主要就是為了和結構和類,
它還通過讓函式回傳指向結構的參考而增添了一個有趣的特點,這與回傳結構有所不同,
//代碼太長,放段偽代碼吧
struct Str
{
};
Str& test(Str &a,const Str &b)
{
//從b中取值,對a進行填充
return a;//其實可以做void型別,沒必要多此一舉
}
int main()
{
Str a,b,c;
//b是有初值的,這是偽代碼
c = test(a,b);
return 0;
}
如果test函式回傳一個結構,而不是指向結構的參考,相當于把整個結構體復制到一個臨時位置,再將這個拷貝復制給c,但是現在回傳值為參考,將直接將a復制到c,效率更高,
回傳參考時最重要的一點是:應避免回傳函式終止時將不再存在的記憶體單元的參考,
下面是一個反面教材:
Str& test(const Str &d)
{
Str &e;
···
return e;
}
何時使用參考引數?
程式員能夠修改呼叫函式中的資料物件,
通過傳遞參考而不是整個資料物件,可以提高程式的運行速度,
指標
指標和const
將const用于指標有一些很微妙的地方,
可以用兩種不同的方式將const關鍵字用于指標,
int age = 20; const int * pt = &age;
//該宣告指出,pt指向一個const int,因此不能使用pt來修改這個值,
//現在來看一個很微妙的問題:其實age并不是一個常量,只是對于pt來說,它是一個常量,
//就是說age可以改,只不過不能用pt來改而已,
注意點:不允許將常量資料賦值給非常量指標,個中理由就不用多解釋了吧,
const int age = 20; int * pt = &age;
int sloth = 80; int * const finger = &sloth;
#這種宣告格式使得這個指標只能指向sloth,不過可以通過這個指標修改sloth的值,
通過指標回傳字串的函式
現在,假設需要一個回傳字串的函式,是的,函式無法回傳一個字串,但是可以回傳字串的地址,這樣效率更高,
void test(char *rc)
{
···
memset(rc,字串);
···
}
相當于是使用回呼函式,我個人比較喜歡這一套模式,
通過指標回傳結構
具體操作參考第二點,
當然,這里還有另外的應用場景:
void test2(const JieGouTi1 *a,JieGouTi2 *b)
{
//將a中的某些值賦值給b
}
//這里有一個注意點,傳進去賦值的結構體指標最好用const.
函式指標
關于為什么要使用函式指標,我的理解還不是很深刻,畢竟功力不足,但是我知道那些回呼函式都是用函式指標的,所以對函式指標必須要理解好,
這叫啥,“但行好事,莫問為啥”,
函式指標完成任務的流程是這樣的:
獲取函式的地址
宣告一個函式指標
使用函式指標來呼叫函式
獲取函式地址
獲取函式地址那是比較簡單的事,如果說 void Hanshu();這是一個函式,那么它的地址就是 Hanshu,
如果函式Hanshubaba();要呼叫這個函式,是這樣的:Hanshubaba(Hanshu);
切記不能寫成:Hanshubaba(Hanshu());
宣告函式指標
假設現在有這么一個函式:int test3(void *arg); //這個arg引數,回呼函式里面用,要解釋有點長,
現在要將之改成函式指標形式:int (*test3)(void *arg);
首先,將test3更換成(*test3),因此,(*test3)也是函式,那么test3就是函式指標,
為宣告優先級,需要將 *test3 括號起來,
函式指標用武之地
如果你非要我說函式指標存在的意義,那我也真不好給你扯個所以然出來,那我就,舉幾個用得到的地方吧:
自定義排序/搜索
不同的模式(如策略,觀察者)
回呼
關于指標的一些思考
前面說到,將指標作為引數傳入,在函式內部對指標進行修改,函式結束后指標的修改將被保留,
因為指標傳參代表著地址傳參,
解惑:如何讓對指標引數的修改不被保存,
看個栗子:
class B {
char* b;
public:
B() {
b = new char[5];
strcpy(b,"aaaa");
}
char* get_b() { return b; }
};
class A {
private:
char* a;
public:
A(B* temp) { a = temp->get_b(); };
void set_A() {
strcpy(a, "kkkk"); //頂替掉了
}
};
int main() {
B* b = new B();
A* a = new A(b);
a->set_A();
cout << b->get_b() << endl;
return 0;
}
結局列印出來的 b,就是“kkkk”,
那為什么會這樣?前面解釋過了,a、b都是對記憶體地址的映射,對a進行修改,就是對地址上的資料進行修改,而b只不過是地址的一個映射而已,讀取b,就是讀取地址上的東西,那本質已經被改了,讀出來的東西自然不一樣,
再看個例子:
void Del (POINT_T * the_head, int index)
{
POINT_T *pFree=NULL;
POINT_T *pNode=the_head;
int flag=0;
while (pNode->next!=NULL)
{
if(flag==index-1)
{
pFree=pNode->next; //再指向資料域就爆了
pNode->next=pNode->next->next;
free(pFree->pData);
free(pFree);
break;
}
pNode=pNode->next;
flag++;
}
}
這是鏈表的一個例子,那可能會納悶兒,為什么對 pNode執行了 pNode=pNode->next;操作,而the_head卻沒有跟著變呢?
原因很簡單,pNode->next也是一個映射地址,這句話的意思就是用一個新的地址映射,頂替掉那個舊的,使得指標pNode指向一塊新的地址,和the_head失去聯系,
陣列
我們把一組資料的集合稱為陣列(Array),它所包含的每一個資料叫做陣列元素(Element),所包含的資料的個數稱為陣列長度,
陣列是一個整體,它的記憶體是連續的;也就是說,陣列元素之間是相互挨著的,彼此之間沒有一點點縫隙,

不再贅言,
STL陣列Vector
C語言的陣列就不多說,STL的陣列那不能少說啊,
Vector是STL中一個很常用的容器,
作用:Vector可以理解為是一個可以存放 任意的、統一種類的資料的動態陣列,
能來看的對vector應該是有了解的,閑話不多說,
Vector的資料結構與array非常相似,不同的地方在于array是靜態的,一旦確定了范圍之后便不能改變(不定長陣列零擔別論),
要換個更大的空間是比較麻煩的,一切都得自己手動來,
Vector是動態分配空間的,相對比較友好,如果需要擴容的話它的內部機制會自己去處理,
Vector基本函式使用
- 創建
#include<vector>
vector<int> test; //初始化一個Vector實體,用于存放int型資料,實體名字叫test
vector<int> test2 = test; //以test1為標準創建test2
再看一個vector<int>test3(10);
創建一個vector容器,大小為10,內容默認置空
不是很建議這種做法啊,往里面插成段的值的時候只能插入第一個,后面就無法插入了,
再說了,你不用自己分配空間,STL都給你安排的好好的,
當然,初始化方式千千萬,放多了反而讓人眼花繚亂,會基本的最實用的夠了,
- 插入元素
test.insert(test.begin()+i,a); //在第i個元素前插入a
test.insert(test.begin()+i,te2.begin(),te2.end());
//插入一段相同資料型別資料,第一個引數放插入位置(指標/迭代器形式),第二三個引數放待插入元素起始位置
test.push_back(a); //往尾部插入
- 洗掉元素
test.erase(test.begin());
test.erase(test.begin(),test.begin()+5);//洗掉區間(第一個元素到第五個元素)
test.clear(); //清空
test.pop_back(); //洗掉尾部元素
洗掉呢,還有個比較靈活的方式:
test.erase(it); //這個it是迭代器
關于洗掉有一個必須·要注意的點:不要在foreach的時候進行洗掉操作,如果你一定要在遍歷的時候進行洗掉,你最好看一下下一行那個鏈接,
- 遍歷元素
當然,你可以使用陣列下標形式訪問元素,因為vector多載了 [] 操作,不過不建議,雖然是很方便,但是有諸多限制,要是隨便就任你操作資料,那人家封裝起來干什么?
我們應該養成使用下面這種迭代器訪問的方式,
vector<int>::iterator it; //初始化一個vector<int>型別的迭代器
for(it = test.begin();it!=test.end();it++) //從頭遍歷到尾
{
cout<<*it<<endl; //取出內容
}
關于迭代器還需要知道的是:vector的迭代器支持前后向,及多載了 +,—,++,-- 操作,
還有一個叫at()的函式,這個好用,
test.at(2); //用這個比直接用下標要好的地方在于它會檢測越界
(明面上是這么說啊,其實我自己寫代碼也喜歡用下標定位)
- 頭尾指標
這四個函式的區別要清楚:begin()、end()、front()、back(),我喜歡稱它們為頭尾指標,
我也不知道為什么有人要就這些區別長篇大論,
begin():指向容器的第一個元素的地址,
front():指向容器的第一個元素的值,
end():和begin()配套
back():和front()配套
- 容器容量
test.size(); //容器已存入資料量
test.capacity(); //容器還能存多少資料量
其實不用擔心容器不夠大,容量要滿的時候它會自己擴容,
- 排序
#include<algorithm>
/*test.*/sort(test.begin(),test.end()); //從頭到尾,默認從小到大排序
這里要非常注意,前面那個test. 被我注釋掉了,因為sort是屬于演算法范疇,不是容器的類方法,
//一般排序都是要自定義排序的:
bool Comp(const int &a,const int &b)
{
return a>b;
}
sort(test.begin(),test.end(),Comp); //這樣就降序排序,
- 其他
swap(test,test2); //交換test和test2中的資料
test.resize(20); //重置大小
reverse(test); //元素翻轉
如果要問為什么沒有 “修改資料的部分”,參見第四點“遍歷資料”,
10、unique()函式
這個函式用來清理容器中的重復項,但前提是容器經過排序了,
而且,它不提供洗掉操作,只是把重復項移到容器后面的部分,所以直接size()的話大小是不會變的,
如果要清理重復項,這樣:nums.erase(unique(nums.begin(),nums.end()),nums.end());
最后再提一下兩個頭檔案:
#include<vector> //vector類相關
#include<algorithm> //容器演算法
vector的元素不僅僅可以是int,double,string,還可以是結構體,但是要注意:結構體要定義為全域的,否則會出錯,
特別注意:
使用vector需要注意以下幾點:
1、如果你要表示的向量長度較長(需要為向量內部保存很多數),容易導致記憶體泄漏,而且效率會很低;
2、Vector作為函式的引數或者回傳值時,需要注意它的寫法:
double Distance(vector&a, vector&b) 其中的“&”絕對不能少!!!
Vector的資料結構
所謂動態增添大小,并不是在原有空間之后再開辟空間,顯然那也不太現實,
而是以原大小的兩倍大小尋找一塊新空間,將內容真實的拷貝過去,然后釋放原空間,
不過就算洗掉元素過半也不會將記憶體放出來,
但是,需要牢記的一點是:對于Vector的一切操作,一旦引起空間的重新分配,那么指向原有空間的迭代器將會全部失效,
關于這點,我也做了一個測驗代碼:
可測可不測,結果我都注釋好了
#include <iostream>
#include<vector>
using namespace std;
int main()
{
vector<int> vec1;
//vector<int>::iterator it1 = vec1.begin();
//放這里試試
vec1.push_back(1);
cout<<"left size :"<<vec1.capacity()<<endl; //1
vec1.push_back(6);
cout<<"left size :"<<vec1.capacity()<<endl; //2
vec1.push_back(5);
cout<<"left size :"<<vec1.capacity()<<endl; //4
vec1.push_back(4);
cout<<"left size :"<<vec1.capacity()<<endl; //4
vec1.push_back(3);
cout<<"left size :"<<vec1.capacity()<<endl; //8
//vector<int>::iterator it1 = vec1.begin();
//放這里試試
vec1.push_back(3);
cout<<"left size :"<<vec1.capacity()<<endl; //8
vec1.push_back(3);
cout<<"left size :"<<vec1.capacity()<<endl; //8
vec1.push_back(3);
cout<<"left size :"<<vec1.capacity()<<endl; //8
vec1.push_back(2);
cout<<"left size :"<<vec1.capacity()<<endl; //16
vector<int>::iterator it1 = vec1.begin();
//這個回圈用于在6之后插入4
while (it1 != vec1.end())
{
if (3 == *it1)
{
vec1.insert(it1+1, 4);
cout<<"insert:"<<*it1<<endl;
}
it1++;
}
//執行完插入操作,將值全部列印
for(it1 = vec1.begin();it1!=vec1.end();it1++)
{
cout<<*it1<<endl;
}
cout<<"it1over"<<endl;
//準備執行對元素‘3’的洗掉
vector<int>::iterator it2 = vec1.begin() ;
while (it2 != vec1.end())
{
if (3 == *it2)
{
//it2 =vec1.erase(it2);
vec1.erase(it2); //這里有沒有都一樣,都指向洗掉之后的那個位置
cout<<"delete:"<<*it2<<endl;
}
else
it2++;
}
//執行完洗掉操作,將容器資料進行列印
for(it2 = vec1.begin();it2!=vec1.end();it2++)
{
cout<<*it2<<endl;
}
cout<<"it2over"<<endl;
//為測驗方便,這里直接清空Vector,看看它放不放空間
vec1.clear();
cout<<"clear left size :"<<vec1.capacity()<<endl; //16
return 0;
}
聯合體union
聯合體,又叫共用體,很直接,就是多個資料共同使用同一塊空間,
分配空間準則:分配共用體中最大資料型別的空間大小,
記憶體共用準則:
- 同等大小的資料視為同一資料(這個要小心,例如long int 和int共存時,修改一個另一個就會隨之改變)
- 大型別優先初始化,看示例:
#include<iostream>
using namespace std;
union var{
long int l; //4個位元組
double i; //8個位元組
};
int main(){
union var v;
v.i = 6.2;
v.l = 5;
// v.i = 6.2; //如果放在這里,會將v.l覆寫
cout<<v.i<<endl;
cout<<v.l<<endl;
return 0;
}
可以拿去測驗,
根據union固定首地址和union按最大需求開辟一段記憶體空間兩個特征,可以發現,所有表面的定義都是虛的,所謂聯合體union,就是在記憶體給你劃了一個足夠用的空間,往里邊扔什么資料誰管得到?
這個如果有興趣的朋友可以自己去試一下將共用體物件強轉,
LeetCode精選題集
Vector篇
1、參考傳參
先來看個題目:
等下也是用這個題目
給定一個排序陣列,你需要在 原地 洗掉重復出現的元素,使得每個元素只出現一次,回傳移除后陣列的新長度,
不要使用額外的陣列空間,你必須在 原地 修改輸入陣列 并在使用 O(1) 額外空間的條件下完成,
示例 1:
給定陣列 nums = [1,1,2],
函式應該回傳新的長度 2, 并且原陣列 nums 的前兩個元素被修改為 1, 2,
你不需要考慮陣列中超出新長度后面的元素,
示例 2:
給定 nums = [0,0,1,1,1,2,2,3,3,4],
函式應該回傳新的長度 5, 并且原陣列 nums 的前五個元素被修改為 0, 1, 2, 3, 4,
你不需要考慮陣列中超出新長度后面的元素,
說明:
為什么回傳數值是整數,但輸出的答案是陣列呢?
請注意,輸入陣列是以「參考」方式傳遞的,這意味著在函式里修改輸入陣列對于呼叫者是可見的,
你可以想象內部操作如下:
// nums 是以“參考”方式傳遞的,也就是說,不對實參做任何拷貝
int len = removeDuplicates(nums);
// 在函式里修改輸入陣列對于呼叫者是可見的,
// 根據你的函式回傳的長度, 它會列印出陣列中該長度范圍內的所有元素,
for (int i = 0; i < len; i++) {
print(nums[i]);
}
來源:力扣(LeetCode)
鏈接:https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array
著作權歸領扣網路所有,商業轉載請聯系官方授權,非商業轉載請注明出處,
以前只知道指標有這種騷操作,現在知道參考也有這種騷操作了,
2、快慢指標
對于上面這題的題解,便可以采用快慢指標的辦法,

不用快慢指標也可以,不過本文不是為了說誰的辦法優秀,這題也不能體現出快慢指標的多少優越性,但是重要的是學到這個思路不是嗎,
可以考慮一下下面這道題:
給你一個包含 n 個整數的陣列 nums,判斷 nums 中是否存在三個元素 a,b,c ,使得 a + b + c = 0 ?請你找出所有滿足條件且不重復的三元組,
注意:答案中不可以包含重復的三元組,
示例:
給定陣列 nums = [-1, 0, 1, 2, -1, -4],
滿足要求的三元組集合為:
[
[-1, 0, 1],
[-1, -1, 2]
]
來源:力扣(LeetCode) 鏈接:https://leetcode-cn.com/problems/3sum
著作權歸領扣網路所有,商業轉載請聯系官方授權,非商業轉載請注明出處,
3、map、set的使用
以下是一個使用set的示例:
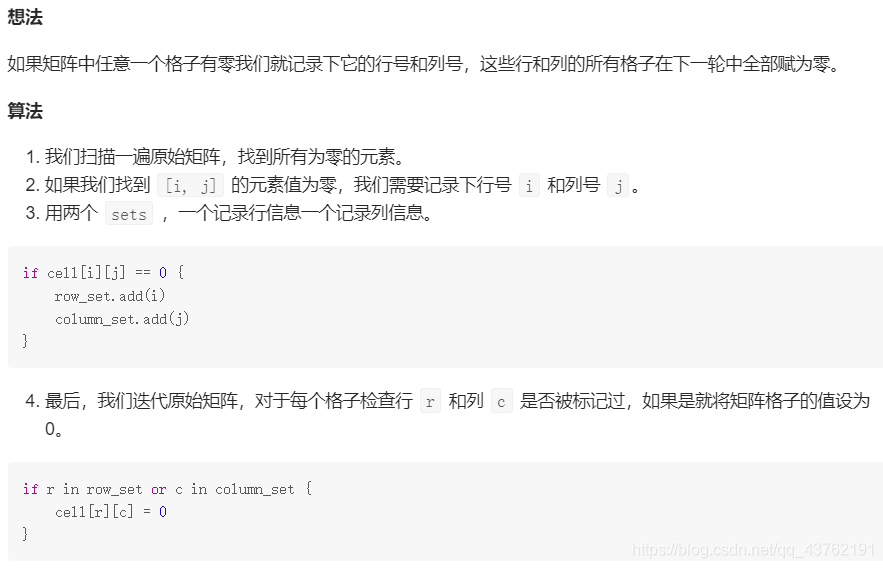
給定一個 m x n 的矩陣,如果一個元素為 0,則將其所在行和列的所有元素都設為 0,請使用原地演算法,
示例 1:
輸入:
[
[1,1,1],
[1,0,1],
[1,1,1]
]
輸出:
[
[1,0,1],
[0,0,0],
[1,0,1]
]
示例 2:
輸入:
[
[0,1,2,0],
[3,4,5,2],
[1,3,1,5]
]
輸出:
[
[0,0,0,0],
[0,4,5,0],
[0,3,1,0]
]
進階:
一個直接的解決方案是使用 O(mn) 的額外空間,但這并不是一個好的解決方案,
一個簡單的改進方案是使用 O(m + n) 的額外空間,但這仍然不是最好的解決方案,
你能想出一個常數空間的解決方案嗎?
來源:力扣(LeetCode) 鏈接:https://leetcode-cn.com/problems/set-matrix-zeroes
著作權歸領扣網路所有,商業轉載請聯系官方授權,非商業轉載請注明出處,
我的解法:
void setZeroes(vector<vector<int>>& matrix) {
if(matrix.empty())
return;
int r = matrix.size();
int c = matrix[0].size();
set<int> rs;
set<int> cs;
set<int>::iterator sit;
//將有0的行列提取出來
for (int i = 0; i < r; i++)
{
for (int j = 0; j < c; j++)
{
if (matrix[i][j] == 0)
{
rs.insert(j);
cs.insert(i);
}
}
}
if (!cs.empty())
{
int a = c;
vector<int> temp;
while (a > 0)
{
temp.push_back(0);
a--;
}
//將行清零
for (sit = cs.begin(); sit != cs.end(); sit++)
{
matrix[*sit] = temp;
}
}
//將列清零
if (!rs.empty())
{
for (sit = rs.begin(); sit != rs.end(); sit++)
{
for (int k = 0; k< r; k++)
{
matrix[k][*sit] = 0;
}
}
}
}
思路:
接下來是一個map的使用示例:
給定一個字串陣列,將字母異位詞組合在一起,字母異位詞指字母相同,但排列不同的字串,
示例:
輸入: ["eat", "tea", "tan", "ate", "nat", "bat"]
輸出:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]
說明:
所有輸入均為小寫字母,
不考慮答案輸出的順序,
來源:力扣(LeetCode) 鏈接:https://leetcode-cn.com/problems/group-anagrams
著作權歸領扣網路所有,商業轉載請聯系官方授權,非商業轉載請注明出處,
我的解法:
vector<vector<string>> groupAnagrams(vector<string>& strs)
{
vector<vector<string>> res;
map<string,vector<string>> vec;
if(strs.empty()) return res;
for(int i=0;i<strs.size();i++)
{
string temp=strs[i];
sort(temp.begin(),temp.end());
vec[temp].push_back(strs[i]);
}
map<string,vector<string>>::iterator it;
for(auto it=vec.begin();it!=vec.end();it++)
{
res.push_back(it->second);
}
return res;
}
思路:

自己試一題:
給定一個字串,請你找出其中不含有重復字符的 最長子串 的長度,
示例 1:
輸入: "abcabcbb"
輸出: 3
解釋: 因為無重復字符的最長子串是 "abc",所以其長度為 3,
示例 2:
輸入: "bbbbb"
輸出: 1
解釋: 因為無重復字符的最長子串是 "b",所以其長度為 1,
示例 3:
輸入: "pwwkew"
輸出: 3
解釋: 因為無重復字符的最長子串是 "wke",所以其長度為 3,
請注意,你的答案必須是 子串 的長度,"pwke" 是一個子序列,不是子串,
來源:力扣(LeetCode)
鏈接:https://leetcode-cn.com/problems/longest-substring-without-repeating-characters
著作權歸領扣網路所有,商業轉載請聯系官方授權,非商業轉載請注明出處,
結語
本來說呢,要把鏈表相關部分、堆疊相關部分也放進來,但是沒想到一個陣列講了這么多,
那就,下次吧,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/238113.html
標籤:其他